全量知识系统中的翻译器以及百度文库AI应用中心给出的答复
Q1. 下面是全量知识系统中的翻译器的规划(参考前一篇:全量知识系统 之 “百度翻译”。从“全量知识系统的翻译器”起。链接在下面)。下面的文字分5次发出。链接:
全量知识系统 之 “百度翻译”-CSDN博客
第一次回答: 全量知识系统中的翻译器
一、引言
在知识系统中,翻译器扮演着至关重要的角色。它不仅涉及不同语言之间的转换,还涉及从自然语言到机器语言的转换。本文将对全量知识系统中的翻译器进行详细的规划和描述。
二、全量知识系统的语言分类
在全量知识系统中,我们将语言抽象化,划分为三个大类:自然语言、人工语言和形式语言。
- 自然语言:指的是日常使用的、不受控的语言,如中文、英文等。
- 人工语言:是专门为特定目的或应用设计的语言,如AI语言。
- 形式语言:一种更加数学化的语言,常用于逻辑、计算机编程等领域。
三、翻译器的双重功能
在全量知识系统中,翻译器具有双重功能:
- 普通意义上的翻译:
- 自然语言翻译:涉及不同语种之间的转换,如中文到英文。这种翻译支持多对多,条件数称为“随机数条件”。
- 人工语言翻译:发生在两个不同角色的人工语言之间。它允许为空,这种条件数称为“操作数条件”。
- 形式语言翻译:涉及两种不同风格的编程语言之间的转换。这种翻译是一对一的,条件数称为“机器数条件”。
- 其他意义上的翻译:
- 除了上述的普通语言翻译外,翻译器在全量知识系统中还具有更深层次的功能,如将自然语言转化为机器可理解的逻辑语言,或将高级编程语言转化为底层机器语言等。
四、翻译器的设计与实现
针对上述的双重功能,我们需要对翻译器进行详细的设计和规划:
- 架构设计:翻译器应采用模块化设计,每个模块负责处理特定类型的语言转换。
- 算法选择:对于自然语言翻译,可以采用深度学习等先进算法;对于形式语言和人工语言的翻译,则可能需要更数学化和逻辑化的方法。
- 知识库建立:需要建立一个全面的知识库,包括各种语言的词汇、语法规则等,以支持翻译器的工作。
五、总结与展望
全量知识系统中的翻译器是一个复杂而重要的组件。它不仅实现了不同语言之间的转换,还促进了自然语言与机器语言之间的沟通。随着技术的不断发展,我们有理由相信,未来的翻译器会更加智能、高效,为知识的传递和应用提供更强有力的支持。
第二次回答:全量知识翻译器进阶功能
全量知识系统中的翻译器及其高级功能
一、引言
全量知识系统中的翻译器不仅负责不同语言之间的转换,还承担着更深层次的功能,如语言模型级之间的映射和与元级、元元级设施之间的交互。本文将详细探讨这些高级功能及其在全量知识系统中的应用。
二、语言类型之间的转换
翻译器首先能够实现不同语言类型之间的转换,包括自然语言、人工语言和形式语言。这种转换不仅涉及词汇和语法的转换,还包括语义和上下文的准确传达。
三、元级和元元级之间的转换
除了语言类型之间的转换,翻译器还能够实现元级和元元级之间的转换。元级是对知识系统进行描述和组织的层级,而元元级则是对元级进行进一步抽象和描述的层级。这种转换使得翻译器能够在不同层级之间进行灵活的知识表示和推理。
四、AI翻译器及其功能
在人工语言的翻译器中,我们特别提到了“AI翻译器”。AI翻译器专注于有限固定状态且被称为“组态”的AI部分的翻译,这些AI部分通常指的是移动机器人系统。在全量知识系统中,机器人(AI)被分为公共、特定领域和专属行业三类应用场景的AI组件。因此,AI翻译器也有三个版本:基础版、扩展版和增强版。这三个版本分别关注通用大模型、领域专业模型和特定行业模型的翻译需求。
五、语言模型级映射与元级、元元级设施的交互
除了上述功能外,翻译器还涉及语言模型级之间的映射以及与元级、元元级设施的交互。这种映射和交互使得翻译器能够在不同层级和模型之间进行准确的知识转换和应用。例如,它可以将低层级的语言模型映射到高层级的元级或元元级设施上,从而实现更高级别的知识表示和推理。
六、总结与展望
全量知识系统中的翻译器是一个高度复杂且功能强大的组件。它不仅实现了不同语言类型之间的转换,还涉及元级和元元级之间的转换以及语言模型级之间的映射和交互。随着技术的不断进步和应用场景的不断拓展,我们有理由相信未来的翻译器将更加强大、智能和灵活,为知识的传递和应用提供更为强大的支持。
第三次回答:AI翻译三版本解析
基础版B(Basic Version)
基础版B是AI翻译器的最基础版本,它提供了从一种语言到另一种语言的基本翻译功能。这个版本主要基于大规模语料库进行训练,能够处理常见的翻译任务。基础版B的特点是翻译准确、速度快,能够满足大多数日常翻译需求。
在知识表示上,基础版B主要依赖传统的基于规则的方法,同时也结合了一些简单的机器学习方法来提高翻译的性能。它并不支持复杂的语义理解和上下文分析,但对于一般性的文本翻译已经足够。
扩展版E(Extended Version)
扩展版E在基础版B的基础上进行了功能扩展和优化。它增加了对特定领域和行业术语的支持,使得翻译更加专业和准确。同时,扩展版E还支持用户的自定义需求,用户可以根据自己的需要调整翻译的参数和策略。
在知识表示上,扩展版E采用了更先进的神经网络模型,能够更好地捕捉语言的上下文信息和语义关系。此外,它还引入了术语库和记忆库的功能,可以自动参考之前的翻译结果和术语库来提高翻译的准确性和效率。
增强版A(Advanced Version)
增强版A是AI翻译器的最高级版本,它结合了最新的机器学习和人工智能技术,提供了更加智能和高效的翻译服务。增强版A不仅能够处理复杂的语义理解和上下文分析任务,还能够支持用户的DIY请求,根据用户的需求进行个性化的翻译。
在知识表示上,增强版A采用了仿生模型和神经元计算等先进技术,能够模拟人类大脑的工作方式,实现更加自然和准确的翻译。此外,增强版A还支持与其他AI系统的集成和交互,可以实现更加复杂和多样化的翻译任务。
总的来说,基础版B、扩展版E和增强版A分别代表了AI翻译器的不同发展阶段和功能特点。用户可以根据自己的需求和场景选择合适的版本进行使用。随着技术的不断进步和应用场景的不断拓展,我们期待未来的AI翻译器能够提供更加智能、高效和个性化的翻译服务。
第四次回答:AI核心技术与模型解析
数据形式化的机器学习、虚拟-符号学的概率统计模型,这些都是现代人工智能领域的重要组成部分。现在,我来为您解释这些概念,并探讨它们之间的关系。
数据形式化的机器学习:
机器学习是人工智能的一个子领域,专注于使用算法使计算机系统能够从数据中“学习”并进行自主决策。数据形式化指的是将原始数据转换为适用于机器学习算法的结构化形式。这通常涉及数据预处理、特征提取和特征选择等步骤,以便机器学习模型能够有效地利用这些数据。
虚拟-符号学的概率统计模型:
虚拟-符号学是探讨虚拟世界中符号和意义的学问,它结合了符号学和计算机科学等领域的知识。概率统计模型则是用来描述和分析随机现象的数学工具。在虚拟-符号学的背景下,概率统计模型可以用于理解和模拟虚拟世界中的不确定性、预测和决策等问题。
AI大模型翻译:
AI大模型通常指的是大规模、复杂的机器学习模型,如深度学习模型,它们需要大量的数据和计算资源来训练。在翻译领域,AI大模型可以用于实现自然语言处理任务,如机器翻译、文本生成等。标准字典库和语料库是机器翻译中不可或缺的资源,它们为翻译模型提供了语言知识和实际的语言使用示例。
模板、模式匹配和对象配对:
这些概念在机器学习和符号学中都非常重要。模板是一种预先定义的结构或模式,用于指导搜索或匹配过程。模式匹配指的是在数据中寻找与特定模板相匹配的模式。对象配对则是将不同的数据对象按照某种标准或规则进行匹配。在机器学习中,这些技术常用于数据预处理、特征提取和分类等任务。
现实模型、因果关系模型和机器学习模型:
这三个模型代表了不同学科领域中的知识和方法。现实模型通常是描述现实世界的物理或数学模型,它强调事物的本质属性和相互关系。因果关系模型则关注事物之间的因果联系,它试图揭示事件之间的内在逻辑和规律。机器学习模型则是一种基于数据的模型,它通过学习数据中的规律和模式来预测和决策。这三个模型在人工智能领域都有广泛的应用,它们可以相互补充和结合,以更全面地理解和解决复杂的问题。
综上所述,数据形式化的机器学习、虚拟-符号学的概率统计模型以及AI大模型翻译等概念都是现代人工智能领域的重要组成部分。它们各自具有独特的特点和应用领域,但也可以相互融合和借鉴,以推动人工智能技术的不断发展和进步。
第五次回答:全量知识翻译器规划提要
引言
全量知识系统旨在建立一个集成多源信息、高效处理和精确翻译的综合平台。该系统利用先进的机器学习技术,结合虚拟-符号学理论和概率统计模型,以提供准确、实时的翻译服务。本规划提要旨在明确翻译器的设计目标、技术路线和实施步骤。
一、系统概述
全量知识系统翻译器是一个基于机器学习的自然语言处理工具,能够实现多语言之间的精确翻译。系统采用数据形式化的方法,将原始语言数据转化为结构化的信息,以便进行高效的处理和翻译。同时,结合虚拟-符号学的理论,系统能够理解和处理语言中的符号和意义,提高翻译的准确性和质量。
二、技术路线
1. 数据预处理
在数据形式化阶段,首先需要对原始语言数据进行预处理。这包括清洗数据、去除噪声、分词、词性标注等步骤。此外,还需要进行句子结构分析和语义理解,以便更好地捕捉语言中的深层信息。
2. 特征提取与选择
通过机器学习算法,从预处理后的数据中提取出关键的特征。这些特征将作为翻译模型的重要输入,直接影响翻译的准确性和效率。
3. 翻译模型构建
基于提取的特征,构建适合多语言翻译的机器学习模型。这里可以采用深度学习、神经网络等先进的机器学习技术,以提高翻译的准确性和流畅性。
4. 后处理与优化
对翻译结果进行后处理,包括语法校正、语义调整等步骤。同时,通过反馈机制收集用户的反馈意见,对模型进行持续优化和改进。
三、数据库结构
1. 数据存储
设计合理的数据库结构,用于存储原始语言数据、预处理后的数据、特征信息以及翻译结果等。同时,还需要建立索引机制,以提高数据检索的速度和效率。
2. 模型存储
为机器学习模型提供专门的存储空间,以便快速加载和部署。同时,还需要记录模型的版本信息和训练参数,以便进行模型的更新和替换。
四、程序接口
1. 用户接口
设计简洁明了的用户界面,提供多语言支持,方便用户进行翻译操作。同时,提供实时反馈和错误信息提示,帮助用户更好地理解和使用系统。
2. API接口
提供标准化的API接口,供其他系统或应用调用。这些接口应支持多种数据传输格式(如JSON、XML等),并具备高效的数据处理能力。
五、待完善部分
1. 机器学习模型选择与优化
需要进一步明确选择哪些机器学习模型(如循环神经网络、卷积神经网络等)用于翻译任务,并详细规划如何对这些模型进行优化和调参,以提高翻译效果。
2. 多语言支持
规划如何实现对多种语言的支持,包括语言模型的构建、语料的收集和处理等。
3. 性能优化与扩展性
探讨如何提高系统的处理速度和翻译效率,以及如何设计系统架构以实现良好的扩展性。
六、总结与展望
本规划提要为全量知识系统翻译器的设计和实现提供了详细的指导。通过综合运用机器学习、虚拟-符号学和概率统计模型等技术,我们有信心构建一个高效、准确、可扩展的翻译系统,为用户提供优质的翻译服务。未来,我们将继续关注领域内的最新技术进展,持续优化和完善系统,以满足不断变化的市场需求。
相关问题:机器学习优化数据形式化
机器学习可以通过多种方式优化数据形式化过程。数据形式化是将原始数据转换为适合机器学习算法处理的结构化形式的过程。以下是机器学习如何在这一过程中发挥作用的几个方面:
- 特征提取和选择:机器学习算法可以帮助从原始数据中提取有用的特征,这些特征对于模型的训练和预测至关重要。通过特征提取,可以降低数据的维度,去除冗余和噪声,从而提高模型的性能。特征选择则是从提取的特征中选择最相关和最有用的特征,进一步简化数据形式化过程。
- 数据预处理:机器学习需要对数据进行清洗、去噪、归一化等预处理步骤,以消除数据中的异常值、缺失值和噪声,提高数据质量。此外,还可以通过数据变换等方法,将数据转换为更适合机器学习算法处理的形式。
- 模型选择和调优:不同的机器学习模型对数据形式化的要求不同。通过选择合适的模型和调优参数,可以使数据形式化过程更加高效和准确。例如,某些模型可能更适合处理特定类型的数据或解决特定的问题,而其他模型则可能在处理不同类型的数据时表现更好。
- 自动化和集成化:机器学习还可以帮助实现数据形式化过程的自动化和集成化。通过自动化工具和框架,可以简化数据形式化的步骤和流程,减少人工干预和错误。同时,通过将不同的数据处理工具和机器学习算法集成在一起,可以形成一个完整的数据处理和分析管道,从而更高效地实现数据形式化。
总之,机器学习可以通过多种方式优化数据形式化过程,使数据处理更加高效、准确和自动化。这不仅可以提高机器学习模型的性能,还可以促进数据科学和人工智能领域的发展。
相关文章:

全量知识系统中的翻译器以及百度文库AI应用中心给出的答复
Q1. 下面是全量知识系统中的翻译器的规划(参考前一篇:全量知识系统 之 “百度翻译”。从“全量知识系统的翻译器”起。链接在下面)。下面的文字分5次发出。链接: 全量知识系统 之 “百度翻译”-CSDN博客 第一次回答:…...
抓包工具获取请求信息
Charles 下载安装 下载 官方下载地址:https://www.charlesproxy.com/latest-release/download.do 下载后傻瓜式安装就好,这个官方的需要激活,可以选择绿色版或者学习版 绿色版 绿色中文版:https://soft.kxdw.com/pc/Charles.z…...

【Java Web】秒懂CSS样式!
目录 一、CSS的使用 二、CSS引用方式 三、CSS三大选择器 四、CSS浮动 五、CSS定位 六、CSS盒子模型 一、CSS的使用 css层叠样式表能够对网页中标签元素位置的排版进行像素级别的精确控制,支持几乎所有的字体和字号样式,拥有对网页对象和模型的样式…...

Go微服务: 基于net/rpc/jsonrpc模块实现微服务跨语言调用
概述 Golang 提供 net/rpc/jsonrpc 库来实现rpc方法采用 json 方式进行数据编解码,支持跨语言调用 这里实现跨语言示例 1 )go 服务端 package main import ( "log" "net" "net/rpc" "net/rpc/jsonrpc" )…...

Guitar Pro 8.1中文版永久许可证激活2024最新24位注册激活码生成器
Guitar Pro是一款非常受欢迎的音乐制作软件,它可以帮助用户创建和编辑各种音乐曲谱。从其诞生以来就送专门为了编写吉他谱而研发迭代的。 尽管这款产品可能已经成为全球最受欢迎的吉他打谱软件,在编写吉他六线谱和乐队总谱中始终处于行业领先地位&#…...
练习题)
自然语言处理(NLP)练习题
问题:什么是自然语言处理(NLP)? 答案:自然语言处理(NLP)是一种人工智能技术,旨在让计算机理解和处理人类语言。NLP涉及语言学、计算机科学和人工智能等多个领域,旨在开发…...

P2386 放苹果
题目传送门 题目描述 把 m 个同样的苹果放在n 个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法。(5,1,15,1,1 和 1,1,51,1,5 是同一种方法) 输入格式 第一行是测试数据的数目 t,以下每行均包括二个整…...
TI IWR6843ISK ROS驱动程序搭建
1、设备准备 1.1 硬件设备 1)TI IWR 6843 ISK 1块 2)Micro USB 数据线 1条 1.2 系统环境 1)VMware Workstation 15 Player 虚拟机 2)Ubuntu18.04 并安装有 ROS1 系统 如若没有安装 ROS 系统,可通过如下指令进行…...
【Godot4自学手册】第二十节增加游戏的打击感,镜头震颤、冻结帧和死亡特效
这节我主要学习增加游戏的打击感。我们通过镜头震颤、冻结帧、增加攻击点特效,增加死亡。开始了。 一、添加攻击点特效 增加攻击点特效就是,在攻击敌人时,会在敌人受击点显示一个受击动画。 1.添加动画。 第一步先做个受击点动画。切换到…...

[论文笔记] Open-Sora 1、sora复现方案概览
GitHub - hpcaitech/Open-Sora: Unofficial implementation of OpenAIs Sora Open-Sora已涵盖: 提供完整的Sora复现架构方案,包含从数据处理到训练推理全流程。 支持动态分辨率,训练时可直接训练任意分辨率的视频,无需进行缩放。 支持多种模型结构。由于Sora实际模型结构未…...

持续更新 | 与您分享 Flutter 2024 年路线图
作者 / Michael Thomsen Flutter 是一个拥有繁荣社区的开源项目,我们致力于确保我们的计划公开透明,并将毫无隐瞒地分享从问题到设计规范的所有内容。我们了解到许多开发者对 Flutter 的功能路线图很感兴趣。我们往往会在一年中不断更改并调整这些计划&a…...

Go语言数据结构(二)堆/优先队列
文章目录 1. container中定义的heap2. heap的使用示例3. 刷lc应用堆的示例 更多内容以及其他Go常用数据结构的实现在这里,感谢Star:https://github.com/acezsq/Data_Structure_Golang 1. container中定义的heap 在golang中的"container/heap"…...
)
NERF论文笔记(1/2)
NeRF:Representing Scene as Neural Radiance Fields for View Synthesis 笔记 摘要 实现了一个任意视角视图生成算法:输入稀疏的场景图像,通过优化连续的Volumetric场景函数实现;用全连接深度网络表达场景,输入是一个连续的5维…...

深入理解nginx一致性哈希负载均衡模块[上]
1. 引言 在现代的网络应用中,负载均衡是一个至关重要的组件。它能够分配流量到多个服务器上,实现高可用性和性能扩展。Nginx是一个广泛使用的高性能Web服务器和反向代理服务器,其负载均衡模块提供了多种算法来实现流量的分发。其中࿰…...

【Linux】Docker安装
卸载旧版Docker 新版docker无法覆盖旧版的,所以需要先卸载原来的旧版本 yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-selinux \docker-engine-selinux \docker-eng…...

动态SLAM论文阅读笔记
近期阅读了许多动态SLAM相关的论文,它们基本都是基于ORB-SLAM算法,下面简单记录一下它们的主要特点: 1.DynaSLAM 采用CNN网络进行分割多视图几何辅助的方式来判断动态点,并进行了背景修复工作。 2.Detect-SLAM 实时性问题&…...

数据挖掘:航空公司的客户价值分析
需求分析 理解并掌握聚类分析方法,掌握数据的标准化,掌握寻找最佳聚类数,掌握聚类的绘图,掌握聚类分析的应用场景。 系统实现 实验流程分析 借助航空公司数据,对客户进行分类对不同类别的客户进行特征分析…...

GIS之深度学习08:安装GPU环境下的pytorch
环境: cuda:12.1.1 cudnn:12.x pytorch:2.2.0 torchvision:0.17.0 Python:3.8 操作系统:win (本文安装一半才发现pytorch与cuda未对应,重新安装了cuda后才开始的&a…...

防患未然,OceanBase巡检工具应用实践——《OceanBase诊断系列》之五
1. OceanBase为什么要做巡检功能 尽管OceanBase拥有很好的MySQL兼容性,但在长期的生产环境中,部署不符合标准规范、硬件支持异常,或配置项错误等问题,这些短期不会出现的问题,仍会对数据库集群构成潜在的巨大风险。为…...
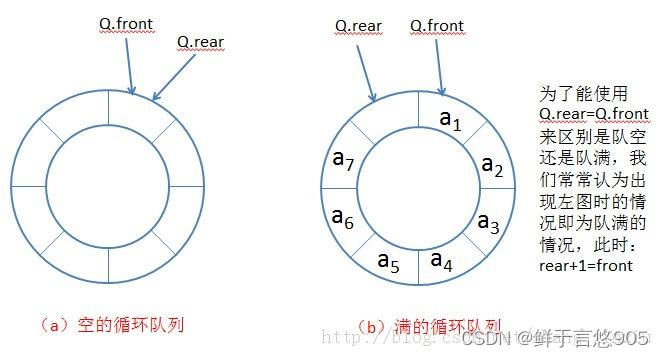
数据结构从入门到精通——队列
队列 前言一、队列1.1队列的概念及结构1.2队列的实现1.3队列的实现1.4扩展 二、队列面试题三、队列的具体实现代码Queue.hQueue.ctest.c队列的初始化队列的销毁入队列出队列返回队头元素返回队尾元素检测队列是否为空检测元素个数 前言 队列是一种特殊的线性数据结构ÿ…...

ESP32开发板到手后,除了点灯还能干啥?从Hello World到连接天猫精灵的完整项目实战
ESP32开发板实战:从点灯到智能家居语音控制的全链路开发指南 刚拿到ESP32开发板时,大多数人的第一个项目往往是点亮LED——这确实是验证硬件工作的好方法。但这款售价不到50元的开发板,实际上隐藏着足以支撑完整物联网项目的强大能力。本文将…...

告别手动配置:用Docker Compose一键部署EPICS + Asyn + StreamDevice开发环境
容器化革命:用Docker Compose重构EPICS开发环境的最佳实践 在实验物理和工业控制系统(EPICS)领域,开发环境的搭建一直是工程师们面临的第一个挑战。传统的手动安装方式不仅步骤繁琐,还常常因为系统环境差异导致各种兼容…...

RevokeMsgPatcher 2.1:Windows平台消息防撤回与多开技术解决方案
RevokeMsgPatcher 2.1:Windows平台消息防撤回与多开技术解决方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://…...

番茄小说下载器完整指南:打造个人离线图书馆的终极解决方案
番茄小说下载器完整指南:打造个人离线图书馆的终极解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾经在地铁里信号断断续续,想看的章节…...
)
你的LoRA微调为什么效果差?可能是这5个参数没调对(LLaMA-Factory实战避坑)
你的LoRA微调为什么效果差?可能是这5个参数没调对(LLaMA-Factory实战避坑) 当你在LLaMA-Factory中进行LoRA微调时,是否遇到过模型表现不如预期的情况?许多开发者在使用LoRA这种高效的参数高效微调方法时,常…...

用MicroPython点亮ESP32:驱动ST7735S TFT-LCD显示自定义图像
1. 准备工作:搭建ESP32与ST7735S的硬件舞台 第一次玩ESP32驱动TFT屏时,我对着密密麻麻的引脚图发呆了半小时。后来发现只要抓住几个关键点,接线就像拼乐高一样简单。你需要准备以下硬件: ESP32开发板(推荐NodeMCU-32S&…...
)
Stata实战:用twoway函数一步步画出漂亮的Logistic回归交互效应图(附不孕症数据)
Stata数据可视化进阶:打造学术级Logistic回归交互效应图 第一次在学术会议上看到那些色彩协调、信息密度极高的统计图表时,我意识到数据可视化远不止是把数字变成图形那么简单。作为经常处理医学研究数据的分析师,我发现很多同行在Stata中能跑…...
)
Qwen3-0.6B-FP8效果实测:古文翻译任务BLEU得分达72.3(超越FP16基线)
Qwen3-0.6B-FP8效果实测:古文翻译任务BLEU得分达72.3(超越FP16基线) 1. 引言:当小模型遇上极致量化 最近在尝试各种轻量化大模型部署方案时,我发现了一个很有意思的现象:很多开发者还在用FP16甚至FP32精度…...
深度解析:BitTorrent Tracker服务器列表的技术价值与实践应用
深度解析:BitTorrent Tracker服务器列表的技术价值与实践应用 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 在P2P文件共享生态系统中,Tracker服务…...

星空派GD32F303开发板开箱实录:从零配置Keil MDK到点亮第一颗LED
星空派GD32F303开发板开箱实录:从零配置Keil MDK到点亮第一颗LED 拆开星空派GD32F303开发板的包装盒,映入眼帘的是一块做工精致的蓝色PCB板,板载资源标注清晰——这正是国产MCU新秀GD32F303系列的代表作。作为ARM Cortex-M4内核的性价比之选…...