【xv6操作系统】Lab systems calls
一、实验前须知
阅读 xv6 文档的第 2 章和第 4 章的 4.3 节和 4.4 节以及相关源文件:
系统调用的用户空间代码在 user/user.h 和 user/usys.pl 中。
内核空间代码在 kernel/syscall.h 和 kernel/syscall.c 中。
与进程相关的代码在 kernel/proc.h 和 kernel/proc.c 中。
二、基础知识
第二章 操作系统组织结构
一个操作系统必须满足3点要求:多路复用、隔离、交互;
Xv6采用宏内核设计;
xv6运行在多核risc-v微处理单元;
risc-v是一个64位cpu,并且xv6用”LP64”( L:long类型,P:pointer类型在c语言中是64位,int是32位)C写的。
(一)抽象物理资源
实现强隔离。例如,
1.unix应用与内存交互仅通过文件系统的open、read、write、close system call,而不是直接读写硬盘。
2.unix进程使用exec来构建他们的内存镜像,而不是直接与物理内存交互。这允许操作系统决定一个进程该在内存中的哪个位置。如果内存紧张,操作系统甚至可能将进程的一些数据存储到硬盘上。
许多形式的unix进程间交互通过文件描述符发生。
(二)user mode、supervisor mode、system calls
强隔离需要一个坚固的边界。如果程序出错,我们不想让操作系统失败,或其他应用失败。操作系统应该能够清理失败应用,并继续运行其他应用。为了实现强隔离,操作系统必须这么安排:应用不能更改(甚至读)操作系统的数据结构和指令,应用不能访问其他进程的内存。
cpu为强隔离提供硬件支持。例如:risc-v有3种cpu执行指令的模式:machine mode、supervisor mode、user mode。
在machine mode下执行的指令有全部权限。cpu从machine mode开始启动。machine mode绝大多数用于配置一台电脑。xv6在machine mode下执行几行代码,然后切换到supervisor mode。
在supervisor mode中,cpu被允许执行权限指令:例如,启用、禁用中断,读写寄存器(保存页表地址)等等。如果一个应用在user mode下尝试执行权限指令,cpu不会执行这个指令,而是切换到supervisor mode下终止应用,因为这个应用做了它不该做的事。在kernel space(或in supervisor mode)中运行的软件称作kernel。
将cpu从user mode切换到supervisor mode,从kernel声明的入口点处进入kernel(risc-v提供ecall指令达到这个目的)。一旦cpu切换到supervisor mode,kernel会校验system call参数,决定应用是否被允许执行请求操作,然后拒绝它或者执行它。kernel控制过渡到supervisor mode的入口是很重要的事;如果一个应用可以决定kernel入口,一个恶意程序可以进入到kernel中逃脱参数校验的点。
(三)kernel组织
设计问题的关键是:操作系统的哪部分应该运行在supervisor mode下。一种可能是整个操作系统搁置在kernel中,因此所有system calls的实现运行在supervisor mode下。这个组织叫做monolithic kernel。
在宏内核下,操作系统各部分之间协作更容易。例如:一个操作系统可能有一个buffer cache,它可以被file system和virtual memory system共享。
monolithic组织的一个缺点是:操作系统不同部分间的接口通常是复杂的(我们将在之后文中看到),因此操作系统开发人员很容易犯错。在monolithic kernel中,一个错误是致命的,因为一个supervisor mode下的错误通常将导致kernel挂掉。如果kernel挂掉了,计算机停止工作,因此所有应用也挂掉。计算机必须重启。
为了减少kernel错误风险,os设计者会最小化操作系统代码(运行在supervisor mode下)的体积,并在用户mode下执行操作系统块。这个kernel组织称作microkernel。

图2.1阐述了微内核设计。在这个图中,文件系统作为一个用户级别的进程运行。为了允许应用和file server交互,kernel提供一个内部进程交互机制来让用户进程之间发送消息。例如:如果一个像shell这样的应用想读写文件,它向file server发消息并等待响应。
因为xv6不提供一些服务,它的内核比一些微内核小,但xv6的理念是monolithic。
(四)代码:xv6组织
xv6 kernel源码在kernel子目录中。资源被分成多个文件,跟随了模块化理念。内部模块接口定义在defs.h(kernel/defs)中。
(五)进程概览
xv6中的隔离单元是进程(正如其他unix中一样)。进程抽象阻止一个进程破坏、侦测另外一个进程的内存、cpu、文件描述符等等。也阻止一个进程破坏kernel本身,因此一个进程不能推翻kernel隔离机制。
为了帮助强制隔离,进程为程序提供一个私有内存系统或者地址空间(看起来是),其他进程不能读写。进程也给程序提供它自己的cpu(看起来是)来执行程序的指令。
xv6使用页表(硬件实现)来给每个进程分配自己的地址空间。risc-v页表翻译一个虚拟地址(risc-v指令操作的地址)到物理地址(cpu分配给主存的地址)。
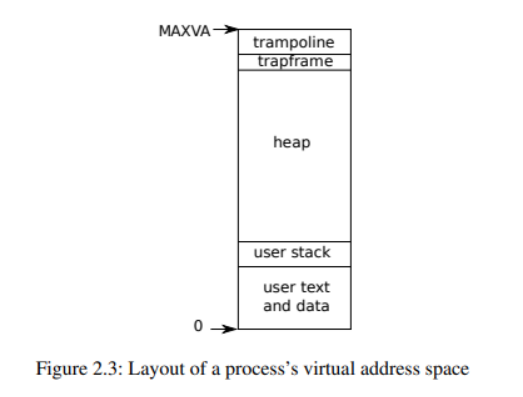
xv6为每个进程保留一个独立的页表(定义了进程的地址空间)。正如图2.3阐述的那样,一个地址空间包括进程的用户内存(起始于虚拟内存地址0)。首先是指令,紧跟全局变量,然后栈,最后是一个堆(进程可以根据需要拓展)。
一些因素限制进程地址空间的最大尺寸:risc-v上面的指针是64位的;在页表中查找虚拟地址时,硬件仅使用低39位;xv6仅使用39位中的38位。因此最大地址是238-1=0x3fffffffff,这是最大虚拟地址(MAXVA max virtual address, kernel/riscv.h:348)。在xv6地址空间顶部保留一个page用作trampoline和一个page匹配进程的trapframe来切换到kernel,正如我们将在第四章解释的那样。
xv6 kernel给每个进程保留了许多个state,这些state集合在一起组成一个结构体struct_proc(kernel/proc.h)。
每个进程有一个执行线程,执行进程指令。一个线程可能会被挂起,然后再唤醒。在两个进程之间透明地切换,kernel挂起当前运行线程,并且唤醒另外一个进程的线程。thread的多个state(本地变量、函数调用返回地址)被存储在线程栈中。
每个进程有两个栈:一个用户栈,一个kernel栈。当进程正在执行用户指令,仅它的用户栈在使用,它的内核栈是空的。当进程进入kernel(system call或interrupt),kernel代码在进程kernel stack;当进程在kernel中时,它的用户栈仍然保留存储的数据,但不会被使用。因此kernel仍然可以执行,即使进程已经毁坏了它的用户stack。
一个进程通过执行risc-v的ecall指令可以做一个system call。这个指令提升硬件权利,改变程序计数器到一个kernel定义的入口。代码在入口处切换到kernel stack,并执行system call实现的kernel指令。当system call完成后,kernel切换回用户栈,通过调用sret指令返回到用户空间,这个指令拉低了硬件权利级别,并在system call指令之后恢复执行用户指令。
当执行进程在用户空间中时,xv6引发paging硬件来使用一个进程的p->pagetable。
(六)现实世界
现代操作系统支持一个进程中多个线程,让一个进程利用多个cpu。进程支持多线程的机器(xv6不支持)有很多,包含潜在的接口改变(例如:linux的clone、fork变形),来控制进程(多线程共享)的各方面。
(七)traps和system calls
调用system call
用户代码为exec在寄存器a0和a1放置参数,并把system call序号放到a7。system call序号匹配入口在syscalls数组,一个函数指针表(kernel/syscall.c:108)。ecall指令traps into kernel并执行uservec、usertrap,然后syscall,正如我们上面看到的。
syscall(kernel/syscall.c:133)从trapframe存的a7取得system call序号,并用它在system calls中找出。对于第一个system call,a7包含SYS_exec(kernel/syscall.h:8),结果是调用system call 实现函数sys_exec。
当system call实现函数返回,syscall记录它的返回值在p->trapframe->a0。这将导致原始用户空间call exec()返回该值,因为risc-v的c调用约定是将返回值放到a0。system call约定返回负值来表明错误,0或正值表明成功。如果system call序号无效,syscall打印一个错误,并返回-1。
system call参数
system call kernel实现需要找出user code传递的参数。kernel trap代码保存用户寄存器到当前进程的trap frame,kernel code可以访问。函数argint,argaddr,和argfd,从trap frame获取第n个system call参数,作为整数、指针、文件描述符。他们都调用argraw来获取对应保存参数的寄存器(kernel/syscall.c:35)。
一些system call传递指针作为参数,并且kernel必须使用那些指针来读取或写user内存。exec system call,传递kernel一个指针数组,来标识用户空间的字符串参数。这些指针有两个挑战。首先用户程序可能是有bug或恶意的,并且可能传给kernel一个无效指针或一个欺骗kernel访问kernel 内存(而不是user内存)的指针。第二,xv6 kernel page table映射不同于user page table映射,因此kernel不会使用原始指令来加载或存储用户提供地址。
The kernel implements functions that safely transfer data to and from user-supplied addresses. fetchstr是一个例子(kernel/syscall.c:25)。file system calls例如exec使用fetchstr从用户空间来获取字符串文件名参数。fetchstr调用copyinstr来做这个工作。
三、实验开始
新建文件夹,重新使用下面的命令下载代码作为实验 2 工作区。
$ git clone git://g.csail.mit.edu/xv6-labs-2020
$ cd xv6-labs-2020
$ git checkout syscall
四、System call tracing
1. 实验目的
添加一个系统调用跟踪功能,该功能可以在以后的实验中为你提供帮助。
你将创建一个新的 trace 系统调用来控制跟踪。
它应该有一个参数,一个整数“mask(掩码)”,其指定要跟踪的系统调用。例如,为了跟踪 fork 系统调用,程序调用 trace (1 << SYS_fork) ,其中 SYS_fork 是来自 kernel/syscall.h 的系统调用号。
如果掩码中设置了系统调用的编号,则必须修改 xv6 内核以在每个系统调用即将返回时打印出一行。
该行应包含 进程 ID 、系统调用名称 和 返回值 ;您不需要打印系统调用参数。 trace 系统调用应该为调用它的进程和它随后派生的任何子进程启用跟踪,但不应影响其他进程。
2. 实验要求及提示
将 $U/_trace 添加到 Makefile 的 UPROGS 中
运行 make qemu , 你将看到编译器无法编译 user/trace.c ,因为系统调用的用户空间存根还不存在:将系统调用的原型添加到 user/user.h ,将存根添加到 user/usys.pl ,以及将系统调用号添加到 kernel/syscall.h 中。 Makefile 调用 perl 脚本 user/usys.pl ,它生成 user/usys.S ,实际的系统调用存根,它使用 RISC-V ecall 指令转换到内核。修复编译问题后,运行 trace 32 grep hello README ;它会失败,因为你还没有在内核中实现系统调用。
在 kernel/sysproc.c 中添加一个 sys_trace() 函数,该函数通过在 proc 结构中的新变量中记住其参数来实现新系统调用(请参阅 kernel/proc.h )。从用户空间检索系统调用参数的函数位于 kernel/syscall.c 中,你可以在 kernel/sysproc.c 中查看它们的使用示例。
修改 fork() (参见 kernel/proc.c )以将跟踪的掩码从父进程复制到子进程。
修改 kernel/syscall.c 中的 syscall() 函数以打印跟踪输出。你将需要添加要索引的系统调用名称数组。
3. 实验步骤
作为一个系统调用,我们先要定义一个系统调用的序号。系统调用序号的宏定义在 kernel/syscall.h 文件中。我们在 kernel/syscall.h 添加宏定义,模仿已经存在的系统调用序号的宏定义,我们定义 SYS_trace 如下:
#define SYS_trace 22
查看了一下 user 目录下的文件,发现官方已经给出了用户态的 trace 函数( user/trace.c ),所以我们直接在 user/user.h 文件中声明用户态可以调用 trace 系统调用就好了。
但有一个问题,该系统调用的参数和返回值分别是什么类型呢?接下来我们还是得看一看 trace.c 文件,可以看到 trace(atoi(argv[1])) < 0 ,即 trace 函数传入的是一个数字,并将返回值和 0 进行比较,结合实验提示,我们知道传入的参数类型是 int ,返回值类型也是 int 。这样就可以把 trace 这个系统调用加入到内核中声明了:
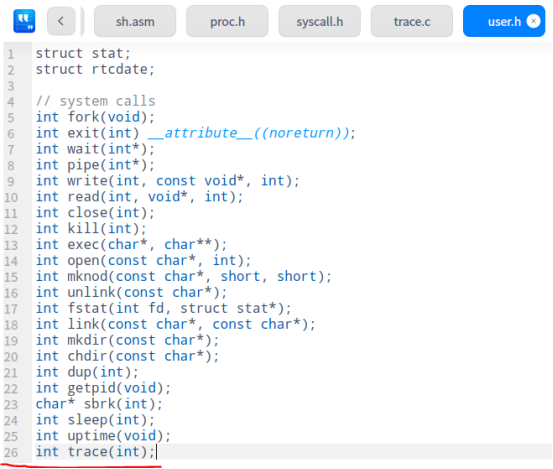
接下来我们查看 user/usys.pl 文件,这里 perl 语言会自动生成汇编语言 usys.S ,是用户态系统调用接口。所以在 user/usys.pl 文件加入下面的语句:
entry("trace");
查看上一次实验编译后的 usys.S 文件,可以看到如下的代码块:
.global fork
fork:
li a7, SYS_fork
ecall
ret
li a7, SYS_fork 指令就是把 SYS_fork 的系统调用号放入 a7 寄存器,使用 ecall 指令进入系统内核。
执行ecall指令之后,cpu跳转到 kernel/syscall.c 中 syscall 那个函数处,执行此函数。下面是 syscall 函数的源码:
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
num = p->trapframe->a7;:从寄存器 a7 中读取系统调用号,放入num中。
接下来是 p->trapframe->a0 = syscalls[num](); 语句,通过调用 syscalls[num](); 函数,把返回值保存在了 p->trapframe->a0中。我们看看 syscalls[num](); 函数,这个函数在当前文件中。我们把新增的 trace 系统调用添加到其中:
static uint64 (*syscalls[])(void) = {
...
[SYS_trace] sys_trace,
};
接下来在文件开头(kernel/syscall.c)给内核态的系统调用 trace 加上声明
extern uint64 sys_trace(void);
在实现这个函数之前,我们可以看到实验最后要输出每个系统调用函数的调用情况,依照实验说明给的示例,可以知道最后输出的格式如下:
<pid>: syscall <syscall_name> -> <return_value>
其中, <pid> 是进程序号, <syscall_name> 是系统调用名称, <return_value> 是该系统调用的返回值。注意:冒号和 syscall 中间有个空格。
根据提示,我们的 trace 系统调用应该有一个参数,一个整数“mask(掩码)”,其指定要跟踪的系统调用。所以,我们在 kernel/proc.h 文件的 proc 结构体中,新添加一个变量 mask ,使得每一个进程都有自己的 mask ,即要跟踪的系统调用。
struct proc {
...
int mask; // Mask
};
然后我们就可以在 kernel/sysproc.c 给出 sys_trace 函数的具体实现了,只要把传进来的参数给到现有进程的 mask 就好了:
uint64
sys_trace(void)
{
int mask;
// 取 a0 寄存器中的值返回给 mask
if(argint(0, &mask) < 0)
return -1;
// 把 mask 传给现有进程的 mask
myproc()->mask = mask;
return 0;
}
接下来我们就要把输出功能实现,因为 RISCV 的 C 规范是把返回值放在 a0 中,所以我们只要在调用系统调用时判断是不是 mask 规定的输出函数,如果是就输出。
在proc 结构体(见 kernel/proc.h )自己定义一个数组,作为调用的系统调用名称。我这里直接在 kernel/syscall.c 中定义了,这里注意系统调用名字一定要按顺序,第一个为空,当然你也可以去掉第一个空字符串,但要记得取值的时候索引要减一,因为这里的系统调用号是从 1 开始的。
static char *syscall_names[] = {
"", "fork", "exit", "wait", "pipe",
"read", "kill", "exec", "fstat", "chdir",
"dup", "getpid", "sbrk", "sleep", "uptime",
"open", "write", "mknod", "unlink", "link",
"mkdir", "close", "trace"};
进程序号直接通过 p->pid 就可以取到,函数名称需要从我们刚刚定义的数组中获取,即 syscall_names[num] ,其中 num 是从寄存器 a7 中读取的系统调用号,系统调用的返回值就是寄存器 a0 的值了,直接通过 p->trapframe->a0 语句获取即可。注意上面说的那个空格。
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
// 下面是添加的部分
if((1 << num) & p->mask) {//p->mask为输入的掩码,num为当前系统调用的序号
printf("%d: syscall %s -> %d\n", p->pid, syscall_names[num], p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
然后在 kernel/proc.c 中 fork 函数调用时,添加子进程复制父进程的 mask 的代码:
int
fork(void)
{
...
pid = np->pid;
np->state = RUNNABLE;
// 子进程复制父进程的 mask
np->mask = p->mask;
...
}
最后在 Makefile 的 UPROGS 中添加:
UPROGS=\
...
$U/_trace\
4. 实验结果
编译并运行 xv6 进行测试。
$ make qemu
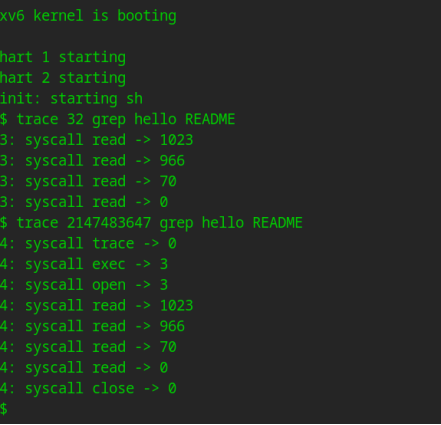
只要和 2的系统调用号次幂相与之后为真(如2147483647与当前系统调用号相与),就会被打印出来
退出 xv6 ,运行单元测试检查结果是否正确。
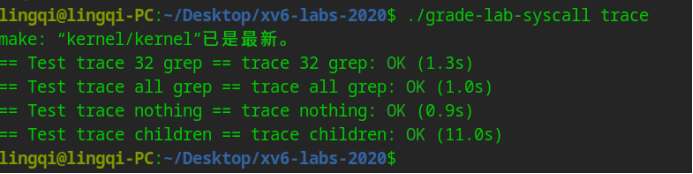
五、Sysinfo
1.实验要求
在本实验中,您将添加一个系统调用 sysinfo ,它收集有关正在运行的系统信息。系统调用接受一个参数:一个指向 struct sysinfo 的指针(参见 kernel/sysinfo.h )。内核应该填写这个结构体的字段: freemem 字段应该设置为空闲内存的字节数, nproc 字段应该设置为状态不是 UNUSED 的进程数。我们提供了一个测试程序 sysinfotest ;如果它打印 “sysinfotest:OK” ,则实验结果通过测试。
2.实验提示
将 $U/_sysinfotest 添加到 Makefile 的 UPROGS 中。
运行 make qemu , 你将看到编译器无法编译 user/sysinfotest.c 。添加系统调用 sysinfo ,按照与之前实验相同的步骤。要在 user/user.h 中声明 sysinfo() 的原型,您需要预先声明 struct sysinfo :
struct sysinfo;
int sysinfo(struct sysinfo *);
修复编译问题后,运行 sysinfotest 会失败,因为你还没有在内核中实现系统调用。
sysinfo 需要复制一个 struct sysinfo 返回用户空间;有关如何使用 copyout() 执行此操作的示例,请参阅 sys_fstat() ( kernel/sysfile.c ) 和 filestat() ( kernel/file.c )。
要收集空闲内存量,请在 kernel/kalloc.c 中添加一个函数。
要收集进程数,请在 kernel/proc.c 中添加一个函数。
3.实验步骤
跟上个实验一样,首先定义一个系统调用的序号。系统调用序号的宏定义在 kernel/syscall.h 文件中。我们在 kernel/syscall.h 添加宏定义 SYS_sysinfo 如下:
#define SYS_sysinfo 23
在 user/usys.pl 文件加入下面的语句:
entry("sysinfo");
然后在 user/user.h 中添加 sysinfo 结构体以及 sysinfo 函数的声明:
struct stat;
struct rtcdate;
// 添加 sysinfo 结构体
struct sysinfo;
// system calls
...
int sysinfo(struct sysinfo *);
在 kernel/syscall.c 中新增 sys_sysinfo 函数的定义:
extern uint64 sys_sysinfo(void);
在 kernel/syscall.c 中函数指针数组新增 sys_trace :
[SYS_sysinfo] sys_sysinfo,
记得在 kernel/syscall.c 中的 syscall_names 新增一个 sys_trace :
static char *syscall_names[] = {
"", "fork", "exit", "wait", "pipe",
"read", "kill", "exec", "fstat", "chdir",
"dup", "getpid", "sbrk", "sleep", "uptime",
"open", "write", "mknod", "unlink", "link",
"mkdir", "close", "trace", "sysinfo"};
接下来我们就要开始写相应的函数实现了。
首先我们写获取可用进程数目的函数实现。通过阅读 kernel/proc.c 文件可以看到下面的语句:
struct proc proc[NPROC];
这是一个进程数组的定义,这里保存了所有的进程。
我们再阅读 kernel/proc.h 查看进程结构体的定义:
enum procstate { UNUSED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
int mask; // Mask
};
可以看到,进程里面已经保存了当前进程的状态,所以我们可以直接遍历所有进程,获取其状态判断当前进程的状态是不是为 UNUSED 并统计数目就行了。当然,通过 proc 结构体的定义,我们知道使用进程状态时必须加锁,我们在 kernel/proc.c 中新增函数 nproc 如下,通过该函数以获取可用进程数目:
// Return the number of processes whose state is not UNUSED
uint64
nproc(void)
{
struct proc *p;
// counting the number of processes
uint64 num = 0;
// traverse all processes
for (p = proc; p < &proc[NPROC]; p++)
{
// add lock
acquire(&p->lock);
// if the processes's state is not UNUSED
if (p->state != UNUSED)
{
// the num add one
num++;
}
// release lock
release(&p->lock);
}
return num;
}
接下来我们来实现获取空闲内存数量的函数。可用空间的判断在 kernel/kalloc.c 文件中。
这里定义了一个链表,每个链表都指向上一个可用空间,这里的 kmem 就是一个保存最后链表的变量。
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
继续分析文件kernel/kalloc.c可知,这里把从 end (内核后的第一个地址) 到 PHYSTOP (KERNBASE + 128*1024*1024) 之间的物理空间以 PGSIZE 为单位全部初始化为 1 ,然后每次初始化一个 PGSIZE,就把上一次初始化好的页放到当前页的下一个,然后把当前页挂在了 kmem.freelist 上,所以 kmem.freelist 永远指向最后一个可用页,那我们只要顺着这个链表往后走,直到 NULL 为止。所以我们就可以在 kernel/kalloc.c 中新增函数 free_mem ,以获取空闲内存数量:
// Return the number of bytes of free memory
uint64
free_mem(void)
{
struct run *r;
// counting the number of free page
uint64 num = 0;
// add lock
acquire(&kmem.lock);
// r points to freelist
r = kmem.freelist;
// while r not null
while (r)
{
// the num add one
num++;
// r points to the next
r = r->next;
}
// release lock
release(&kmem.lock);
// page multiplicated 4096-byte page
return num * PGSIZE;
}
然后在 kernel/defs.h 中添加上述两个新增函数的声明:
// kalloc.c
...
uint64 free_mem(void);
// proc.c
...
uint64 nproc(void);
接下来我们按照实验提示,添加 sys_sysinfo 函数的具体实现,这里提到 sysinfo 需要复制一个 struct sysinfo 返回用户空间,根据实验提示使用 copyout() 执行此操作,我们查看 kernel/sysfile.c 文件中的 sys_fstat() 函数,如下:
uint64
sys_fstat(void)
{
struct file *f;
uint64 st; // user pointer to struct stat
if(argfd(0, 0, &f) < 0 || argaddr(1, &st) < 0)
return -1;
return filestat(f, st);
}
这里可以看到调用了 filestat() 函数,该函数在 kernel/file.c 中,如下:
// Get metadata about file f.
// addr is a user virtual address, pointing to a struct stat.
int
filestat(struct file *f, uint64 addr)
{
struct proc *p = myproc();
struct stat st;
if(f->type == FD_INODE || f->type == FD_DEVICE){
ilock(f->ip);
stati(f->ip, &st);
iunlock(f->ip);
if(copyout(p->pagetable, addr, (char *)&st, sizeof(st)) < 0)
return -1;
return 0;
}
return -1;
}
我们可以知道,复制一个 struct sysinfo 返回用户空间需要调用 copyout() 函数,上面是一个例子,我们来查看一下 copyout() 函数的定义( kernel/vm.c ):
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
该函数其实就是把在内核地址 src 开始的 len 大小的数据拷贝到用户进程 pagetable 的虚地址 dstva 处,所以 sys_sysinfo 函数实现里先用 argaddr 函数读进来我们要保存的在用户态的数据 sysinfo 的指针地址,然后再把从内核里得到的 sysinfo 开始的内容以 sizeof(info) 大小的的数据复制到这个指针上。模仿上面filestat()函数,我们在 kernel/sysproc.c 文件中添加 sys_sysinfo 函数的具体实现如下:
// add header
#include "sysinfo.h"
uint64
sys_sysinfo(void)
{
// addr is a user virtual address, pointing to a struct sysinfo
uint64 addr;
struct sysinfo info;
struct proc *p = myproc();
if (argaddr(0, &addr) < 0)
return -1;
// get the number of bytes of free memory
info.freemem = free_mem();
// get the number of processes whose state is not UNUSED
info.nproc = nproc();
if (copyout(p->pagetable, addr, (char *)&info, sizeof(info)) < 0)
return -1;
return 0;
}
最后在 user 目录下添加一个 sysinfo.c 用户程序:
#include "kernel/param.h"
#include "kernel/types.h"
#include "kernel/sysinfo.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
// param error
if (argc != 1)
{
fprintf(2, "Usage: %s need not param\n", argv[0]);
exit(1);
}
struct sysinfo info;
sysinfo(&info);
// print the sysinfo
printf("free space: %d\nused process: %d\n", info.freemem, info.nproc);
exit(0);
}
最后在 Makefile 的 UPROGS 中添加:
$U/_sysinfotest\
$U/_sysinfo\
4.实验结果
编译并运行 xv6 进行测试。
$ make qemu
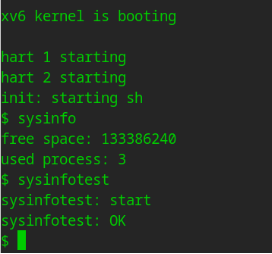
退出 xv6 ,运行单元测试检查结果是否正确。
./grade-lab-syscall sysinfo
通过测试样例。

六、参考文档
[1] 操作系统实验Lab 2:system calls(MIT 6.S081 FALL 2020)_编写 system_call.c 文件输出进程号 pid-CSDN博客
[2] Russ Cox, Frans Kaashoek, Robert Morris, xv6: A simple, Unix-like teaching operating system, 2020.
相关文章:
【xv6操作系统】Lab systems calls
一、实验前须知 阅读 xv6 文档的第 2 章和第 4 章的 4.3 节和 4.4 节以及相关源文件: 系统调用的用户空间代码在 user/user.h 和 user/usys.pl 中。 内核空间代码在 kernel/syscall.h 和 kernel/syscall.c 中。 与进程相关的代码在 kernel/proc.h 和 kernel/proc.c…...

python的scripts文件夹作用
Windows系统: Scripts文件夹通常位于Python的安装目录下,如C:\Python\Scripts。该文件夹内包含了各种有用的工具,例如pip、virtualenv等,这些工具有助于管理和配置Python环境和依赖包。 Linux系统: 在Linux系统中&…...

Discuz论坛网站报错Discuz!Database Error(0)notconnect的解决办法
运营服务器大本营有段时间了,在运营期间遇到两次Discuz!Database Error(0)notconnect报错,和你们分享遇到Discuz报错的解决办法,希望可以帮助到你。 首先网站报错(0)notconnect&…...

掌握mysql,看完这篇文章就够了
数据库 对大量数据进行存储和管理(增删改查) 客户端: 黑窗口终端navicat 熊掌软件数据库分类: 关系型数据库 通过表与表产生关联关系,每个表中都存储结构化数据,支持sql结构化查询语言MysqlOracleSQLS…...

守护Web安全:了解Web攻击与防护策略
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

变换,动画
面试题——需求:在不知道父元素与子元素的宽高时 如何让子元素在父元素内居中? 1.定位 父相子绝 2.子元素 top:50% left:50% 3.子元素 transform: translate(-50%,-50%) .parent{height: 500px;background-color: red;position: relative;}.c…...
深度解析速卖通商品详情API:Python实战与高级技术探讨
速卖通商品详情API接口实战:Python代码示例 一、准备工作 在开始之前,请确保你已经完成了以下步骤: 在速卖通开放平台注册账号并创建应用,获取API密钥。阅读速卖通商品详情API接口的文档,了解接口的使用方法和参数要…...

背包问题算法
背包问题算法 0-1背包问题二维数组一维数组 完全背包问题二维数组一维数组 多重背包问题一维数组 0-1背包问题 问题:背包的容量为9,有重量分别为[2, 4, 6, 9]的四个物品,价值分别为[3, 4, 5, 6],求背包能装的物品的最大价值是多少…...
echarts柱状图可鼠标左击出现自定义弹框,右击隐藏弹框并阻止默认右击事件
每项x轴数据对应有两条柱图和一条阴影效果是学习其它博客得到的效果,这个是学习的原文链接:echarts两个合并柱体(普通柱状图象形柱图)共享一个柱体阴影 因为这次情况比较特殊,不仅需要自定义弹框内容,而且…...
存算一体成为突破算力瓶颈的关键技术?
大模型的训练和推理需要高性能的算力支持。以ChatGPT为例,据估算,在训练方面,1746亿参数的GPT-3模型大约需要375-625台8卡DGX A100服务器训练10天左右,对应A100 GPU数量约3000-5000张。 在推理方面,如果以A100 GPU单卡…...

Pytorch_1_基本语法
一、Pytorch的基本元素操作 1.引入torch from __future__ import print_function import torch 2.创建矩阵 x torch.empty(5,3) print(x) 3.输出结果: tensor([[7.9191e34, 1.1259e24, 1.2359e-42], [4.0824e-40, 1.1379e-35, 2.5353e30], [8.…...

2024上海国际玻璃纤维及新材料展览会
2024上海国际玻璃纤维及新材料展览会 时间:2024年12月18~20日 地点:上海新国际博览中心 ◆ 》》》展会概况: 玻璃纤维是一种性能优异的无机非金属材料,比有机纤维耐温高,不燃,抗腐ÿ…...

云计算项目九:K8S安装
K8S安装 Kube-master安装 按照如下配置准备云主机 防火墙相关配置:禁用selinux,禁用swap,且在firewalld-*。上传kubernetes.zip 到跳板机 配置yum仓库(跳板机) 跳板机主机配置k8s软件源服务端 [rootjs ~]# yum -y…...
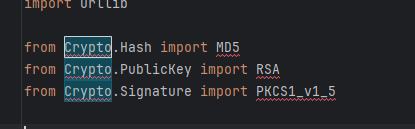
sign加密方法生成
1. 引入包的问题 2. 原因 .pycrypto、pycrytodome和crypto是一个东西,crypto在python上面的名字是pycrypto,它是一个第三方库,但是已经停止更新 3. 解决方法 --直接安装:pip install pycryptodome 3.但是,在使用的时…...

【Linux】编译器-gcc/g++使用
个人主页 : zxctscl 文章封面来自:艺术家–贤海林 如有转载请先通知 文章目录 1. 前言2. 初见gcc和g3. 程序的翻译过程3.1 预处理3.1.1 宏替换 去注释 头文件展开3.1.2 条件编译 3.2 编译3.3 汇编3.4 链接 4. 链接4.1 动态链接4.2 静态链接 1. 前言 在之…...
 函数:筛选可迭代对象元素)
Python 中的 filter() 函数:筛选可迭代对象元素
在 Python 中,filter() 函数是一个非常有用的内置函数,用于根据指定条件过滤可迭代对象中的元素。本文将深入探讨 filter() 函数的用法、工作原理以及常见应用场景,以帮助大家更好地理解和运用这个函数。 什么是 filter() 函数? …...

Java高频面试之并发篇
有需要互关的小伙伴,关注一下,有关必回关,争取今年认证早日拿到博客专家 并行和并发有什么区别? 并行是同时执行多个任务,而并发是多个任务在一段时间内交替执行。并行(Parallel)是指同时执行多个任务或操作,通过同时…...
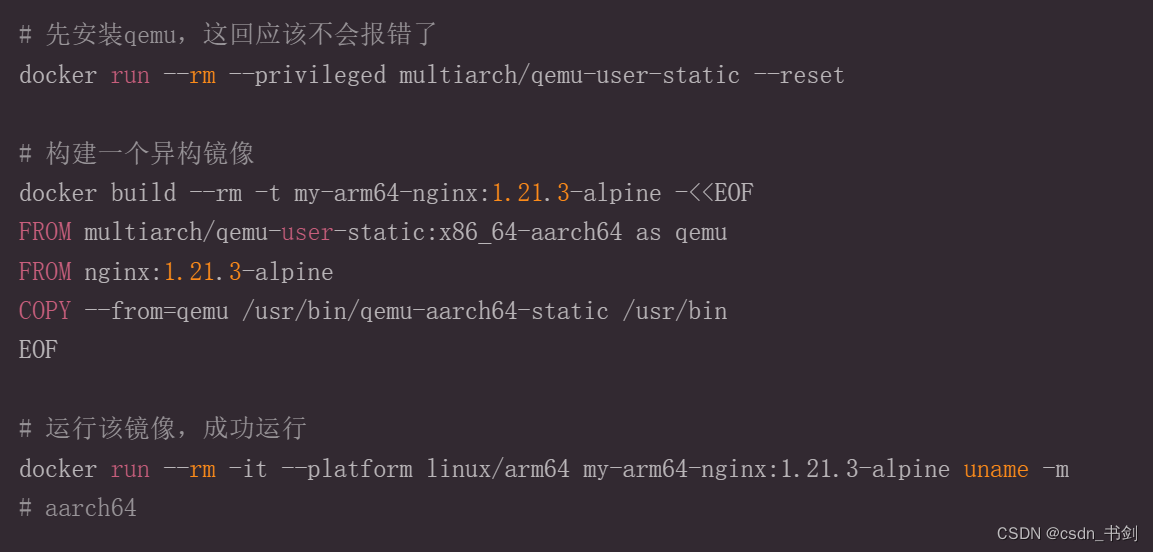
docker 运行异构镜像
概述 关于docker镜像在不同的cpu架构下运行报错的解决办法,作者踩坑验证,在此分享经验 某次工作遇到需要银行内部部署docker镜像,由于行内已经开始走信创的路线,使用鲲鹏系统,arm架构,记过就遇到了standa…...

练习3-8 查询水果价格
探索--题目集索引 给定四种水果,分别是苹果(apple)、梨(pear)、桔子(orange)、葡萄(grape),单价分别对应为3.00元/公斤、2.50元/公斤、4.10元/公斤、10.20元…...
 。void f(int *p){ *p = 5;}int main(void){ int a, *p; a = 10;)
PTA 对于下列程序,正确的是() 。void f(int *p){ *p = 5;}int main(void){ int a, *p; a = 10;
对于下列程序,正确的是() 。 void f(int *p) {*p 5; } int main(void) {int a, *p;a 10;p &a;f(p);printf(“%d”, (*p));return 0; }A.5 B.6 C.10 D.11 答:A 解析:这里考察当是指针作为函数的参数。这里将 p …...

接手一个烂摊子之后:金仓数据库开发规范实战笔记
接手一个烂摊子之后:金仓数据库开发规范实战笔记 从一个凌晨三点的故障说起 去年接手一个电商中台项目,上线才两个月就开始频繁出问题。 最严重的一次是凌晨三点,订单创建接口大面积超时。排查到最后发现是一张订单表,三个月的数据…...

漫画下载革命:8大网站一网打尽,打造你的个人漫画图书馆
漫画下载革命:8大网站一网打尽,打造你的个人漫画图书馆 【免费下载链接】comics-downloader tool to download comics and manga in pdf/epub/cbr/cbz from a website 项目地址: https://gitcode.com/gh_mirrors/co/comics-downloader 在数字阅读…...

5分钟快速上手VADER情感分析:社交媒体文本情感识别的终极指南
5分钟快速上手VADER情感分析:社交媒体文本情感识别的终极指南 【免费下载链接】vaderSentiment VADER Sentiment Analysis. VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically a…...

Windows 10终极去臃肿方案:Windows10Debloater专业深度指南
Windows 10终极去臃肿方案:Windows10Debloater专业深度指南 【免费下载链接】Windows10Debloater Script to remove Windows 10 bloatware. 项目地址: https://gitcode.com/gh_mirrors/wi/Windows10Debloater Windows 10系统预装的"臃肿软件"问题一…...
)
告别绿屏!5分钟学会用FFmpeg命令行无损转换AVC编码MP4视频(保姆级参数详解)
5分钟掌握FFmpeg:AVC编码MP4视频无损转换实战指南 每次遇到视频播放时出现绿屏、卡顿或音画不同步,都让人抓狂。这背后往往是AVC编码的兼容性问题在作祟——不同设备对H.264标准的支持程度参差不齐。作为从业多年的多媒体工程师,我发现最可靠…...

Pyfa终极指南:快速掌握EVE Online舰船配置工具
Pyfa终极指南:快速掌握EVE Online舰船配置工具 【免费下载链接】Pyfa Python fitting assistant, cross-platform fitting tool for EVE Online 项目地址: https://gitcode.com/gh_mirrors/py/Pyfa Pyfa是一款专为EVE Online玩家设计的免费开源舰船配置助手&…...

从RKE到PKE:汽车无钥匙进入系统的演进与安全挑战
1. 从遥控到无感:汽车钥匙的技术革命 还记得十几年前开车门的情景吗?你得从口袋里摸出钥匙,对准车门按下解锁键,听到"滴"的一声才能拉开车门。现在很多车主可能已经习惯了这样的场景:走近车辆时车门自动解锁…...

别再只把Kibana当查询工具了!手把手教你用Dev Tools Console玩转ES数据增删改查
解锁Kibana Dev Tools Console的隐藏力量:从零构建员工管理系统实战指南 当你第一次打开Kibana时,可能被那些炫酷的仪表盘和可视化图表吸引。但今天,我要带你探索一个被严重低估的神器——Dev Tools Console。这绝不是简单的查询窗口…...

从北邮网安复试笔记看考研面试:如何用一个月时间系统梳理计算机核心八股文?
计算机考研复试30天冲刺指南:从知识框架构建到面试话术设计 复试准备的核心逻辑与认知重构 考研复试本质上是一场多维能力评估,尤其在计算机/网络安全领域,考官关注的不仅是知识储备量,更是知识结构化能力与工程思维。传统"八…...
)
倍福PLC编程避坑指南:TwinCAT 2里那些新手容易搞混的功能块(R_TRIG、TON、CASE详解)
倍福PLC编程实战避坑:TwinCAT 2三大核心功能块深度解析 第一次在TwinCAT 2环境中完成控制逻辑编程后,发现状态机跳转异常、定时器不按预期工作?这可能是许多倍福PLC开发者共同的经历。本文将聚焦三个最易引发困惑的功能块——R_TRIG边沿检测、…...