解释一下分库分表的概念和优缺点。如何设计一个高性能的数据库架构?
解释一下分库分表的概念和优缺点。
分库分表是数据库架构优化的常见手段,主要用于解决单一数据库或表在数据量增大、访问频率提高时面临的性能瓶颈和扩展性问题。
概念:
分库(Sharding-Database):
将原本存储在一个数据库中的数据分散存储到多个数据库上。
根据业务的不同,可以将相关的表分组并放到不同的数据库中。
例如,一个电商系统可以根据用户ID的范围将用户数据分散到多个数据库上。
分表(Sharding-Table):
将原本存储在一个表中的数据分散存储到多个表中。
分表可以基于一定的规则,如哈希、范围等,将数据分散到不同的表中。
例如,一个订单表可以根据订单ID的哈希值分散到多个订单表中。
优点:
性能提升:通过分散数据和查询负载,可以提高系统的吞吐量和响应速度。
扩展性增强:可以轻松地通过增加数据库或表的数量来扩展系统的处理能力。
高可用性:通过数据备份和冗余设计,可以提高系统的可用性和容错能力。
缺点:
复杂性增加:分库分表会增加系统的复杂度,需要更多的代码和配置文件来管理。
事务管理:在分库分表中,需要特别注意事务的管理,以保持数据的一致性和完整性。
数据迁移与整合:在分库分表后,需要进行数据迁移和整合,以保持系统的正常运行。
性能调优:分库分表后,需要对每个数据库或表进行性能调优,以确保整体性能的优化。
总之,分库分表是一种有效的数据库架构优化手段,但在实施时需要综合考虑其优缺点,并根据实际情况进行合理的设计和管理。
设计一个高性能的数据库架构需要综合考虑多个方面,包括硬件资源、数据库软件选择、数据模型设计、索引优化、查询性能、数据分区、读写分离、缓存策略、故障恢复和监控等。以下是一些关键步骤和建议,用于设计一个高性能的数据库架构:
如何设计一个高性能的数据库架构?
需求分析:
了解业务需求和预期的数据量。
分析查询模式,包括读写比例、查询复杂性、数据热点等。
评估系统的可用性、可扩展性和数据一致性要求。
硬件和基础设施:
选择高性能的服务器硬件,包括CPU、内存、存储和网络。
使用高速存储解决方案,如SSD,以提高I/O性能。
部署冗余硬件以支持高可用性,例如使用负载均衡器、备份服务器等。
数据库软件选择:
根据需求选择合适的数据库管理系统(DBMS),如关系型数据库(RDBMS)、NoSQL数据库或分布式数据库。
考虑数据库软件的性能、可靠性、扩展性、社区支持和成本等因素。
数据模型设计:
设计合理的数据模型,确保数据的一致性和完整性。
避免数据冗余,减少不必要的表连接和查询复杂性。
使用合适的数据类型和约束,优化数据存储和检索。
索引优化:
根据查询需求创建适当的索引,提高查询性能。
定期分析索引的使用情况,删除无用或低效的索引。
考虑使用复合索引、覆盖索引等高级索引策略。
查询性能优化:
对关键查询进行性能分析,使用查询优化器或EXPLAIN等工具。
避免使用低效的查询语句,如SELECT * 语句、全表扫描等。
使用缓存和预加载策略,减少数据库访问次数。
数据分区:
将数据分散到不同的物理存储区域,提高查询性能和管理效率。
根据业务逻辑选择合适的分区键,如时间、地理位置等。
使用数据库提供的分区功能,如MySQL的分区表、Oracle的表分区等。
读写分离:
将读操作和写操作分散到不同的数据库实例上,提高系统吞吐量。
使用主从复制或集群技术实现读写分离。
确保数据一致性和故障恢复策略。
缓存策略:
使用内存缓存技术,如Redis、Memcached等,减少数据库访问压力。
缓存热点数据和查询结果,提高响应速度。
使用缓存失效策略,确保数据的一致性。
故障恢复和备份:
部署备份和恢复策略,确保数据的安全性和可用性。
定期进行数据备份,包括全量备份和增量备份。
使用数据库提供的恢复功能,如日志恢复、快照恢复等。
监控和维护:
部署监控工具,监控数据库性能、资源使用情况和错误日志。
定期分析监控数据,识别性能瓶颈和问题。
实施定期维护计划,如清理无用数据、优化数据库表等。
可扩展性设计:
设计可扩展的数据库架构,支持业务的快速发展。
使用分布式数据库或数据库集群,提高系统的可扩展性。
考虑使用容器化技术(如Docker)和自动化部署工具(如Kubernetes),简化扩展过程。
设计高性能的数据库架构是一个持续的过程,需要不断根据业务需求和技术发展进行调整和优化。同时,保持对新技术和新方法的关注,以便及时将最新的最佳实践应用到数据库架构中。
相关文章:

解释一下分库分表的概念和优缺点。如何设计一个高性能的数据库架构?
解释一下分库分表的概念和优缺点。 分库分表是数据库架构优化的常见手段,主要用于解决单一数据库或表在数据量增大、访问频率提高时面临的性能瓶颈和扩展性问题。 概念: 分库(Sharding-Database): 将原本存储在一个…...
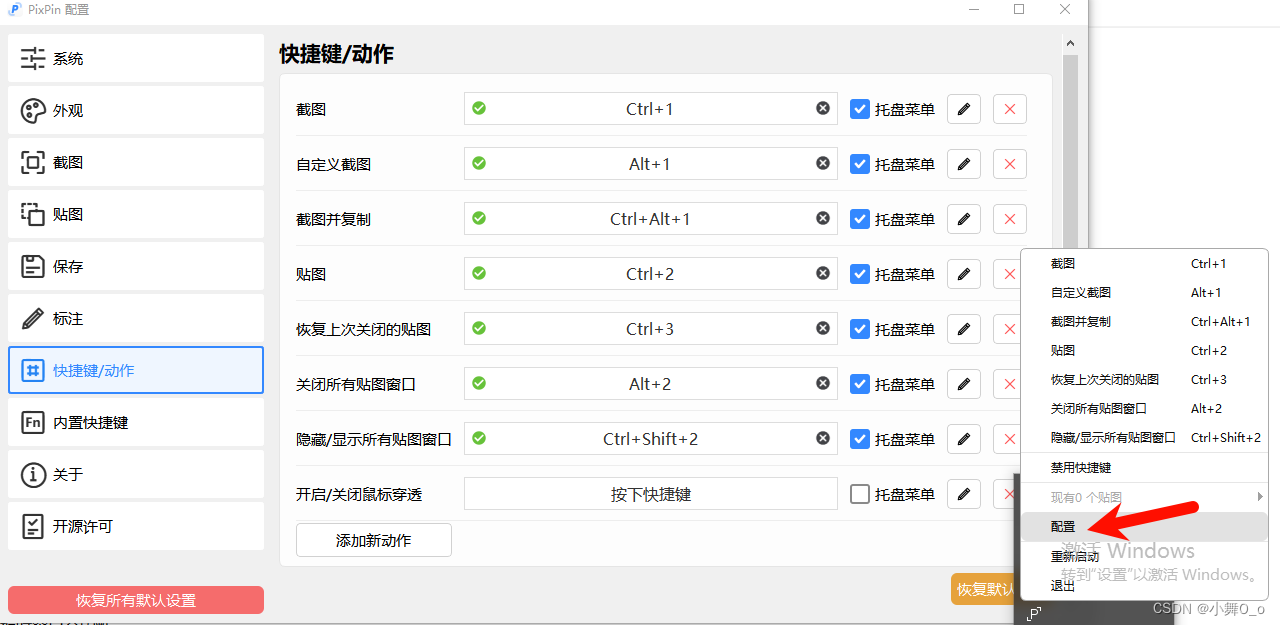
功能强大使用简单的截图/贴图工具,PixPin
一、下载链接 PixPin 截图/贴图/长截图/文字识别/标注 | PixPin 截图/贴图/长截图/文字识别/标注 (pixpinapp.com) 二、功能 截图/贴图/长截图/文字识别/标注 三、安装教程 根据提示安装即可: 四、快捷键 1.软件自带快捷键(右击PixPin查看 )…...
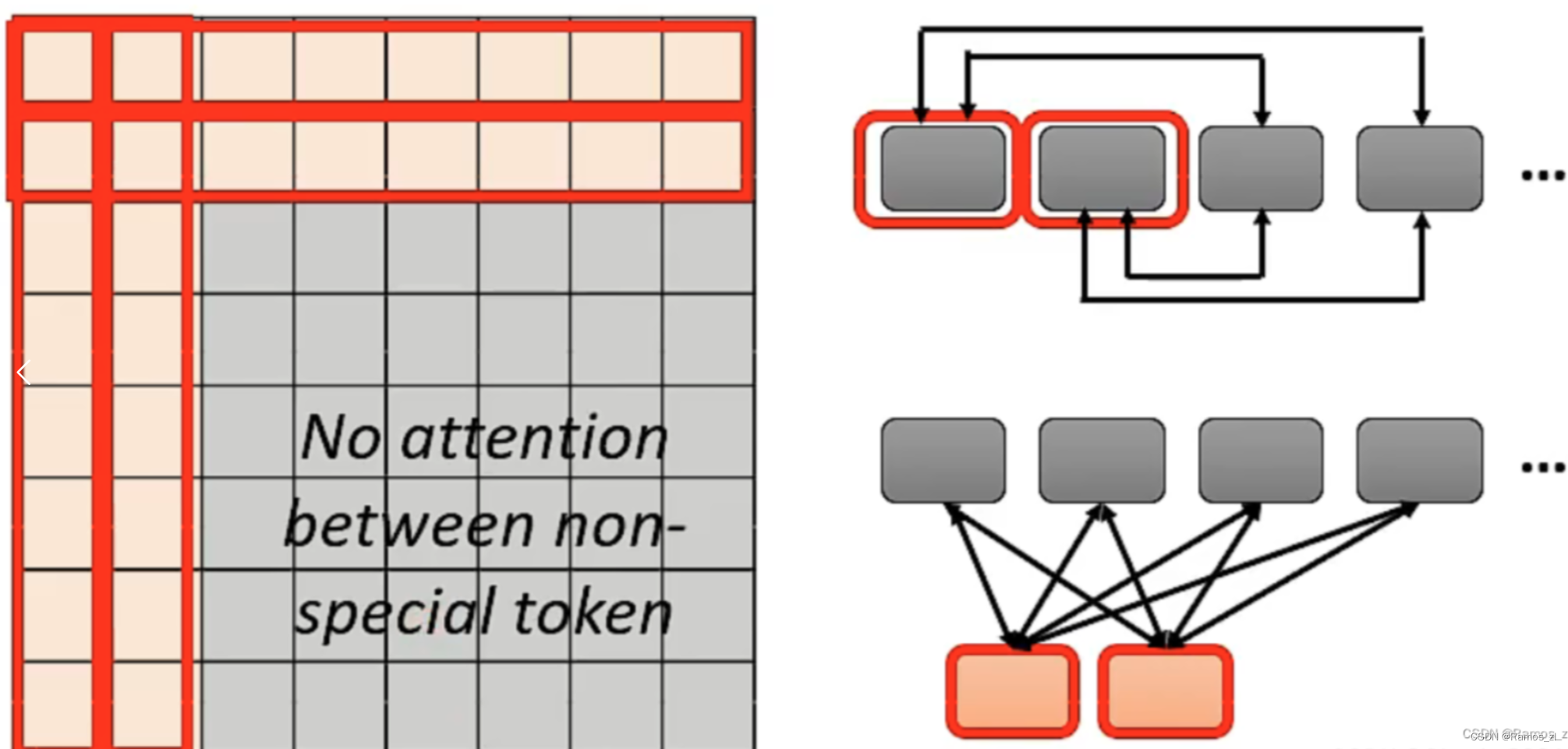
机器学习周报第32周
目录 摘要Abstract一、文献阅读1.论文标题2.论文摘要3.论文背景4.论文方案4.1 多视角自注意力网络4.2 距离感知4.3 方向信息4.4 短语模式 二、self-attention 摘要 本周学习了多视角自注意力网络,在统一的框架下联合学习输入句子的不同语言学方面。具体来说&#x…...

人工智能|机器学习——DBSCAN聚类算法(密度聚类)
1.算法简介 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,簇集的划定完全由样本的聚集程度决定。聚集程度不足以构成簇落的那些样本视为噪声点,因此DBSCAN聚类的方式也可以用于异常点的检测。 2.算法原…...

Excel F4键的作用
目录 一. 单元格相对/绝对引用转换二. 重复上一步操作 一. 单元格相对/绝对引用转换 ⏹ 使用F4键 如下图所示,B1单元格引用了A1单元格的内容。此时是使用相对引用,可以按下键盘上的F4键进行相对引用和绝对引用的转换。 二. 重复上一步操作 ⏹添加或删除…...

前端实现跨域的六种解决方法
本专栏是汇集了一些HTML常常被遗忘的知识,这里算是温故而知新,往往这些零碎的知识点,在你开发中能起到炸惊效果。我们每个人都没有过目不忘,过久不忘的本事,就让这一点点知识慢慢渗透你的脑海。 本专栏的风格是力求简洁…...
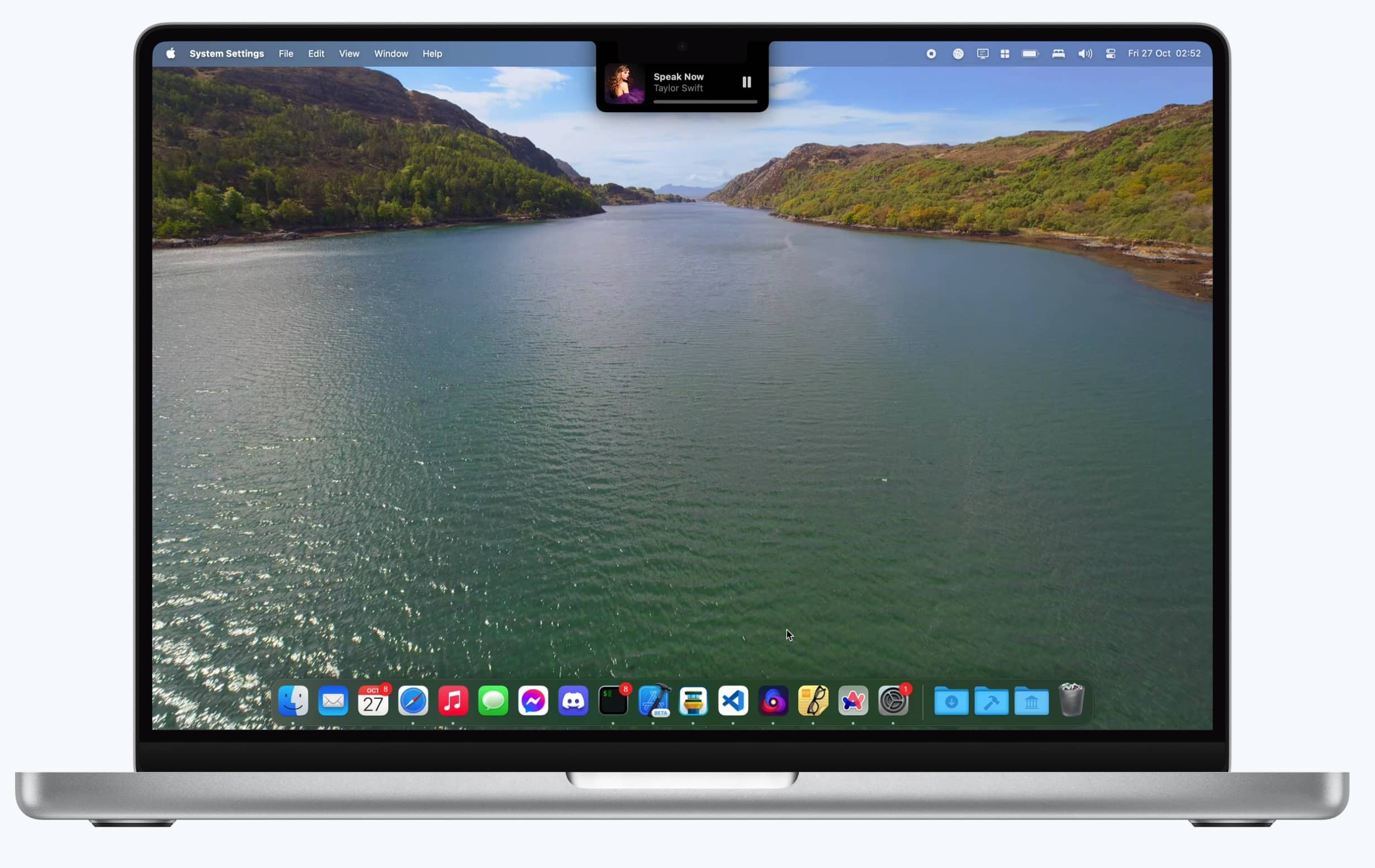
macOS上实现「灵动岛」效果
自从Apple iPhone推出了「灵动岛」功能后,用户们就被其优雅的设计和强大的功能所吸引。然而,作为macOS用户,我们一直在等待这一功能能够在我们的设备上实现。现在,随着新的应用程序的推出,我们终于可以在我们的Mac上体…...
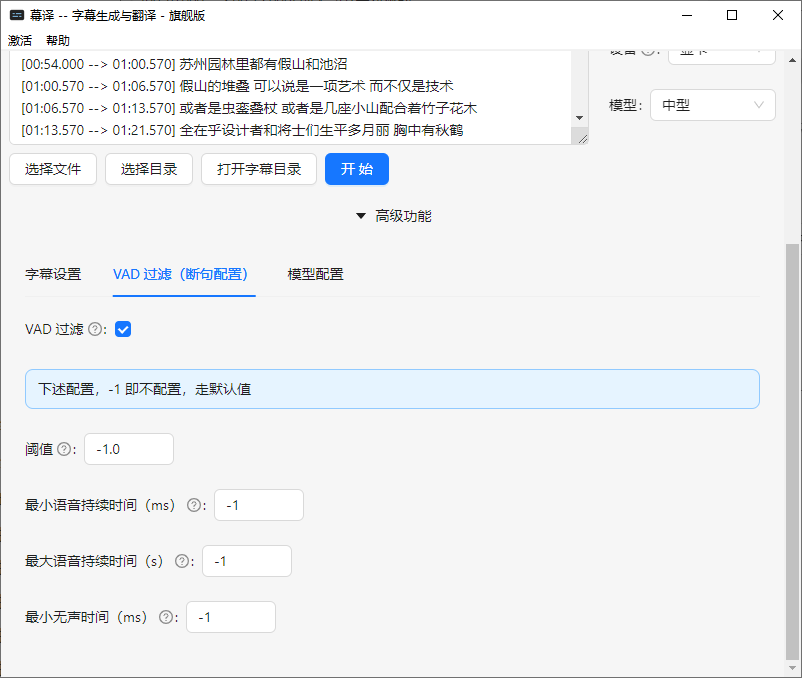
幕译--本地字幕生成与翻译--Whisper客户端
幕译–本地字幕生成与翻译 本地离线的字幕生成与翻译,支持GPU加速。可免费试用,无次数限制 基于Whisper,希望做最好的Whisper客户端 功能介绍 本地离线,不用担心隐私问题支持GPU加速支持多种模型支持(中文、英语、日…...
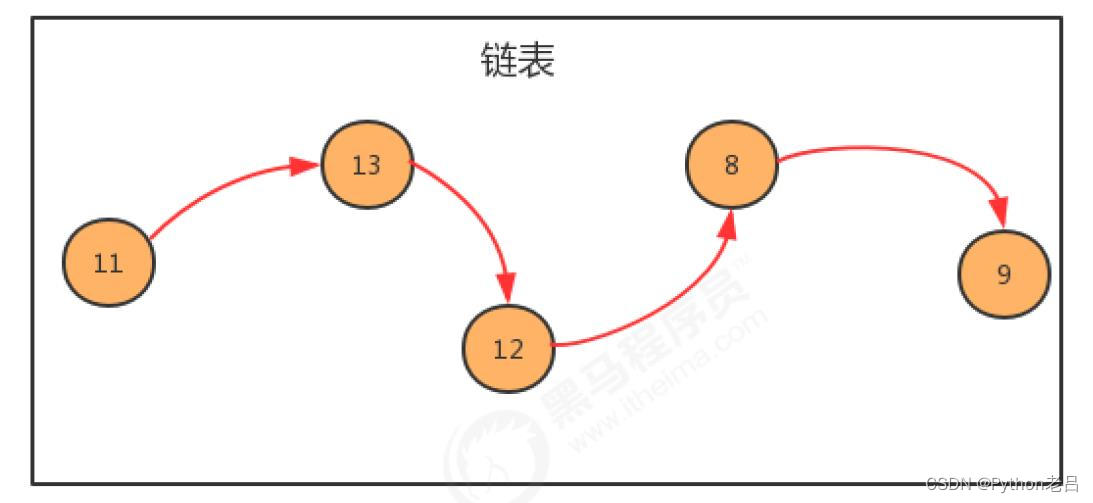
链表基础知识详解
链表基础知识详解 一、链表是什么?1.链表的定义2.链表的组成3.链表的优缺点4.链表的特点 二、链表的基本操作1.链表的建立2.链表的删除3.链表的查找4.链表函数 一、链表是什么? 1.链表的定义 链表是一种物理存储单元上非连续、非顺序的存储结构…...

GPT-prompt大全
ChatGPT目前最强大的的工具是ChatGPT Plus,不仅训练数据更新到了2023年,而且还可以优先访问新功能。对于程序员来说,升级到ChatGPT Plus,将会带来更多的便利和效率提升。 根据 升级ChatGPT Plus保姆级教程,1分钟就可以…...

的发射点2
☞ 通用计算机启动过程 1️⃣一个基础固件:BIOS 一个基础固件:BIOS→基本IO系统,它提供以下功能: 上电后自检功能 Power-On Self-Test,即POST:上电后,识别硬件配置并对其进行自检,…...
)
深入揭秘Lucene:全面解析其原理与应用场景(一)
本系列文章简介: 本系列文章将深入揭秘Lucene,全面解析其原理与应用场景。我们将从Lucene的基本概念和核心组件开始,逐步介绍Lucene的索引原理、搜索算法以及性能优化策略。通过阅读本文,读者将会对Lucene的工作原理有更深入的了解…...
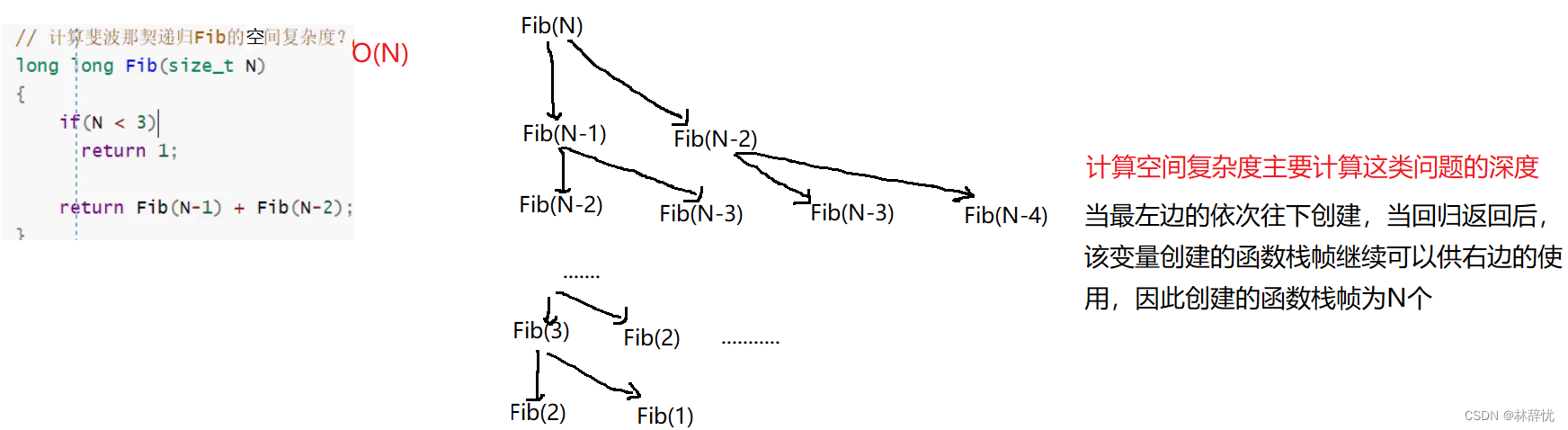
拿捏算法的复杂度
目录 前言 一:算法的时间复杂度 1.定义 2.简单的算法可以数循环的次数,其余需要经过计算得出表达式 3.记法:大O的渐近表示法 表示规则:对得出的时间复杂度的函数表达式,只关注最高阶,其余项和最高阶…...
)
C语言实战—猜数字游戏(涉及循环和少部分函数内容)
对于前面一些内容的总结 不妨跟着一起试试吧 折半查找算法(二分查找) 比如我买了一双鞋,你好奇问我多少钱,我说不超过300元。你还是好奇,你想知道到底多少,我就让 你猜,你会怎么猜?…...
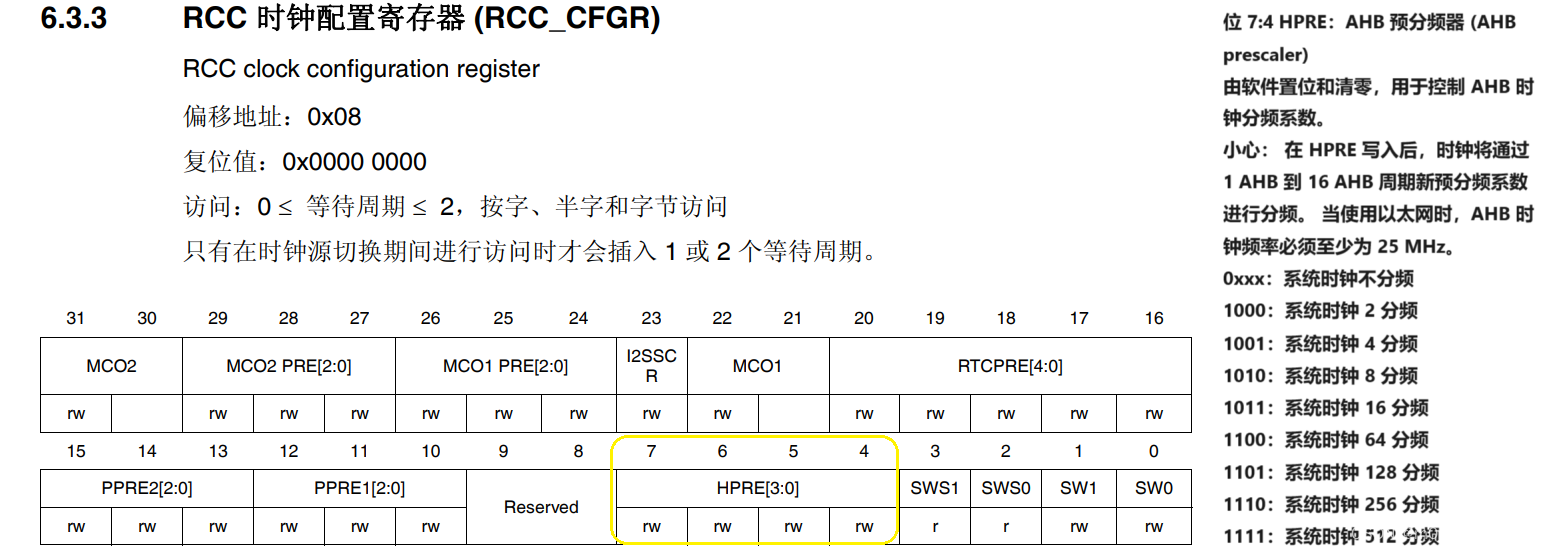
#define MODIFY_REG(REG, CLEARMASK, SETMASK)
#define MODIFY_REG(REG, CLEARMASK, SETMASK) WRITE_REG((REG), (((READ_REG(REG)) & (~(CLEARMASK))) | (SETMASK))) 这个宏 MODIFY_REG 是在嵌入式编程中,它用于修改一个寄存器的特定位,而不影响其他位。这个宏接受三个参数ÿ…...
使用 Docker 部署 Stirling-PDF 多功能 PDF 工具
1)Stirling-PDF 介绍 大家应该都有过这样的经历,面对一堆 PDF 文档,或者需要合并几个 PDF,或者需要将一份 PDF 文件拆分,又或者需要调整 PDF 中的页面顺序,找到的线上工具 要么广告满天飞,要么 …...
springcloud第3季 项目工程搭建与需求说明1
一 需求说明 1.1 实现结构图 订单接口调用支付接口 二 工程搭建 2.1 搭建工程步骤...
外包干了3个月,技术退步明显。。。。
先说一下自己的情况,本科生,2019年我通过校招踏入了南京一家软件公司,开始了我的职业生涯。那时的我,满怀热血和憧憬,期待着在这个行业中闯出一片天地。然而,随着时间的推移,我发现自己逐渐陷入…...
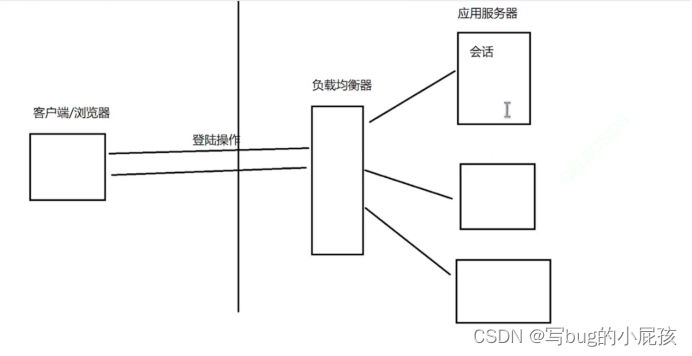
Redis特性与应用场景
Redis是一个在内存中存储数据的中间件,用于作为数据库,用于作为数据缓存,在分布式系统中能够发挥重要作用。 Redis的特性 1.In-memory data structures: MySQL使用表的方式存储数据,这意味着数据通常存储在硬盘上,并且…...

openssl3.2 - exp - 可以在命令行使用的口令算法名称列表
文章目录 openssl3.2 - exp - 可以在命令行使用的口令算法名称列表概述笔记测试工程实现备注整理 - 总共有126种加密算法可用于命令行参数的密码加密算法备注END openssl3.2 - exp - 可以在命令行使用的口令算法名称列表 概述 上一个笔记openssl3.2 - exp - PEM <…...

实战技巧|用命令行彻底清除顽固文件和文件夹
1. 为什么有些文件和文件夹无法删除? 你有没有遇到过这种情况:明明已经关闭了所有程序,但某个文件就是删不掉?系统总是弹出"文件正在使用"或"需要管理员权限"的提示。这种情况在Windows系统中相当常见&#x…...

TMS320F28P550SJ9新手避坑指南:从空工程导入、Sysconfig配置到成功点灯的全流程复盘
TMS320F28P550SJ9开发实战:从零搭建LED控制工程的避坑手册 第一次接触德州仪器C2000系列微控制器时,那种既兴奋又忐忑的心情我至今记忆犹新。作为工业控制领域的明星芯片,TMS320F28P550SJ9以其强大的实时处理能力和丰富的外设接口著称&#x…...

终极罗技PUBG鼠标宏指南:5步实现精准压枪射击
终极罗技PUBG鼠标宏指南:5步实现精准压枪射击 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 绝地求生(PUBG)…...

Meshlab新手必看:STL模型中心化与Poisson采样点云化完整流程
Meshlab新手必看:STL模型中心化与Poisson采样点云化完整流程 刚接触三维建模时,我总被各种专业软件的操作界面吓退——直到遇见Meshlab这款开源神器。它就像一位耐心的导师,用简洁的界面承载着强大的三维处理能力。特别是在处理3D扫描获得的S…...

数据库备份恢复方案
数据库备份恢复方案:企业数据安全的生命线 在数字化时代,数据已成为企业的核心资产。数据库作为存储和管理数据的关键系统,其安全性直接影响业务连续性。一次意外的数据丢失或系统崩溃,可能导致巨额经济损失甚至企业信誉受损。一…...
)
AIStarter后端开发最新进度:注册用户完善 + 角色权限 + 应用市场审核功能已上线(附新旧版本对比)
## 前言:革命尚未成功,同志仍需努力很多粉丝关心我为什么天天熬夜到凌晨三四点发视频。其实正如那句老话:“革命尚未成功,同志仍需努力”。作为一名开发者,为了保证项目开发与视频更新同步进行,老婆的督促也…...
)
保姆级教程:在Ubuntu 22.04上,用LLaMA-Factory微调DeepSeek-R1-1.5B模型(附完整数据集与避坑指南)
零基础实战:Ubuntu 22.04环境下DeepSeek-R1-1.5B模型微调全流程解析 在开源大模型技术爆发的当下,个性化微调已成为开发者释放模型潜力的关键技能。本文将带您完整走通从环境配置到模型部署的每个环节,特别针对Ubuntu 22.04系统和DeepSeek-R1…...

幼儿园自主游戏:核心内涵、实践体系与发展价值
幼儿园自主游戏是幼儿在安全环境下,依兴趣自主选择内容、材料、伙伴与玩法,自发探索、自由表达的主体性活动,是学前教育的基本形态与幼儿发展的核心路径。它彻底区别于教师主导的指令式游戏,核心是尊重幼儿主体地位,让…...

【CVE-2023-49103】ownCloud graphapi第三方库敏感信息泄露漏洞深度剖析
1. 漏洞背景与影响范围 ownCloud作为一款广泛使用的开源私有云解决方案,近期曝出的CVE-2023-49103漏洞让不少企业捏了把冷汗。这个高危漏洞的核心在于graphapi组件对第三方库GetPhpInfo.php的调用机制存在设计缺陷。我在实际安全评估中发现,受影响版本会…...
)
从理论到仿真:用Simulink离散积分器一步步还原电机电流环PI控制(附模型文件)
从理论到仿真:用Simulink离散积分器一步步还原电机电流环PI控制(附模型文件) 在电机控制领域,PI控制器因其结构简单、鲁棒性强等优势,成为电流环设计的首选方案。但许多工程师在从理论公式转向仿真实现时,…...