深入揭秘Lucene:全面解析其原理与应用场景(一)
本系列文章简介:
本系列文章将深入揭秘Lucene,全面解析其原理与应用场景。我们将从Lucene的基本概念和核心组件开始,逐步介绍Lucene的索引原理、搜索算法以及性能优化策略。通过阅读本文,读者将会对Lucene的工作原理有更深入的了解,并能够将其应用于实际的搜索引擎开发中。欢迎大家订阅《Java技术栈高级攻略》专栏,一起学习,一起涨分!
目录
1、Lucene简介与背景
1.1 Lucene的起源和发展历程
1.2 Lucene在全文搜索领域的重要地位
2、Lucene的基本原理
2.1 倒排索引的概念和实现方式
2.2 段落索引的概念和实现方式
2.3 文本分析和标准化处理
3、Lucene的搜索算法
3.1 BM25算法
3.2 向量空间模型
3.3 TF-IDF算法
4、Lucene的高级特性
4.1 跨语言搜索支持
4.2 分布式搜索与扩展性
4.3 高亮显示与片段提取
5、Lucene的性能优化
6、Lucene在实际应用中的应用场景
7、Lucene的未来发展方向
8、结语
1、Lucene简介与背景
1.1 Lucene的起源和发展历程
Lucene是由Doug Cutting于1999年创建的一个全文搜索引擎库。Doug Cutting最初是为了创建一个基于全文搜索的邮件存档系统而开始开发Lucene。
在最初的几年里,Lucene主要被用于开发用于搜索和索引大规模文本数据的应用程序。随着Lucene的功能和性能不断提升,它逐渐被广泛应用于各种领域,如搜索引擎、电子商务、知识管理等。
2001年,Apache Software Foundation 接管了Lucene项目,并将其作为Apache的开源项目进行维护和发展。在Apache的支持下,Lucene得到了更多的开发者和用户的参与,其功能和性能也得以不断改进。
随着Lucene的发展,其生态系统也逐渐形成。相关项目如Solr和Elasticsearch等基于Lucene的搜索引擎系统相继出现,为Lucene的应用提供了更多的功能和扩展性。
目前,Lucene已经成为了一个非常成熟和强大的全文搜索引擎库,被广泛应用于众多的应用和系统中。它的发展历程充满了合作和开源社区的力量,得到了全球开发者和用户的认可和支持。
1.2 Lucene在全文搜索领域的重要地位
Lucene在全文搜索领域具有非常重要的地位。它是一个开源的全文搜索引擎库,提供了强大的文本搜索和分析功能,能够快速而高效地处理大规模的文本数据。
以下是Lucene在全文搜索领域的重要地位:
-
高性能:Lucene使用倒排索引(Inverted Index)的数据结构,能够在非常短的时间内快速定位到包含关键词的文档,实现了非常高效的搜索。
-
分词与分析:Lucene提供了丰富的分词和分析功能,可以对文本进行分词、词干化、停用词过滤等处理,提高搜索的准确性和效果。
-
可扩展性:Lucene的设计模块化且可扩展,可以根据需要扩展和定制各种功能,如自定义分词器、自定义查询、自定义排序等。
-
多语言支持:Lucene支持多种语言的分词和搜索,可以处理不同语言的文本数据,提供全球化的搜索能力。
-
商业应用广泛:Lucene被广泛应用于各种商业项目中,如搜索引擎、电子商务等领域。很多大型互联网公司和搜索引擎都使用了Lucene作为其搜索引擎的核心技术。
总之,Lucene在全文搜索领域的高性能、灵活性和可扩展性使其成为一个非常重要的工具和技术。它的存在和应用对于提升搜索引擎的效率和用户体验起到了重要作用。
2、Lucene的基本原理
2.1 倒排索引的概念和实现方式
倒排索引(inverted index)是一种常用于信息检索的数据结构,用于快速查询某个词在文档中的位置。它的基本原理是将文档集合中的每个词都映射到出现该词的文档列表,而不是将文档映射到词的列表。
倒排索引的实现方式通常包括以下几个步骤:
- 文档分词:将每个文档进行分词,将文档中的每个词提取出来。
- 构建索引表:遍历所有的文档,对于每个词,将其映射到出现该词的文档列表。索引表可以使用哈希表、有序数组等数据结构来存储。
- 优化索引:为了减小索引的大小和提高查询效率,可以对索引进行一些优化,如压缩存储、合并相似的文档列表等。
- 查询处理:当用户输入一个查询词时,查询处理过程会根据倒排索引表,快速找到包含该词的文档列表,然后根据查询条件进行筛选和排序,返回最相关的文档结果。
Lucene是一个开源的全文搜索引擎库,它的核心就是基于倒排索引的信息检索引擎。Lucene提供了丰富的API和功能,可以用于构建各种类型的搜索引擎应用。
在Lucene中,倒排索引是由一个名为倒排列表(Inverted List)的数据结构来表示的。倒排列表存储了词项和文档的对应关系,对于每个词项,倒排列表记录了包含该词项的文档ID和出现位置等信息。
Lucene的倒排索引还提供了一些额外的功能和优化,如词项的存储和压缩方式、词项频率和位置信息的存储、权重计算和评分等。
总结起来,Lucene的倒排索引是通过将文档映射到词项的列表来实现的,通过这种方式可以快速定位包含特定词项的文档并支持高效的全文搜索。通过优化和扩展倒排索引的功能,Lucene可以实现更多的搜索相关功能,如词项频率和距离的计算、布尔查询、模糊匹配等。
2.2 段落索引的概念和实现方式
Lucene是一个开源的全文检索引擎库,它提供了一个高效、可扩展的搜索功能。Lucene的基本原理之一是段落索引,它是指将文本分割成若干段落,并为每个段落创建索引。
段落索引的实现方式主要包括以下几个步骤:
-
文本分割:Lucene使用一个叫做分词器(Tokenizer)的组件将文本分割成若干段落。分词器可以根据具体的需求来定义分割规则,例如按照空格、标点符号或者其他自定义的规则来分割文本。
-
词汇表的建立:Lucene使用一个称为词汇表(Vocabulary)的数据结构来存储所有出现在文本中的唯一单词。在建立词汇表时,Lucene会去重并对单词进行排序,以提高检索效率。
-
倒排索引的构建:Lucene通过倒排索引(Inverted Index)的方式将每个单词和出现该单词的段落关联起来。倒排索引的数据结构包括索引词项(Term)和包含该词项的段落的列表。通过倒排索引,可以快速地找到包含特定单词的段落。
-
搜索:当用户输入一个检索词时,Lucene会在词汇表中查找该单词,并获取到包含该单词的段落列表。然后,Lucene根据这些段落列表来计算每个段落的相关度得分,并按照相关度排序返回结果。
段落索引的概念和实现方式使得Lucene能够高效地进行全文检索。通过将文本分割成若干段落,并为每个段落创建索引,Lucene能够在大规模的文档集合中快速地找到相关的段落。同时,倒排索引的数据结构也提供了高效的搜索和排序功能。
2.3 文本分析和标准化处理
Lucene的基本原理之一是文本分析和标准化处理。这个过程是在建立索引和搜索时对文本进行处理和转换的关键步骤。
文本分析是将输入的文本数据划分为一个个的词(token)。这个过程被称为分词(tokenization),主要通过空格、标点符号等进行划分。分词的目的是将文本划分为可以进行索引和搜索的最小单元。
标准化处理是对划分后的词进行规范化和转换。主要包括以下几个步骤:
-
小写转换(Lowercasing):将所有的词转换为小写形式,这样可以避免搜索时的大小写差异。
-
去除停用词(Stop words removal):停用词是一些常见的词,如"and"、"the"等,它们在搜索时往往没有实质性的含义,可以被忽略掉。
-
词干提取(Stemming):词干提取是将词的不同形态转换为它们的原始形态,以减少词形的变化对搜索结果的影响。例如,词干提取将"running"和"ran"都转换为"run"。
-
同义词扩展(Synonym expansion):在建立索引时,可以将文本中的某些词替换为它们的同义词,以便扩大搜索范围。
通过文本分析和标准化处理,可以将输入的文本数据转换为适合进行索引和搜索的形式。这样就能够更准确地匹配搜索关键字,并提高搜索结果的相关性。
3、Lucene的搜索算法
3.1 BM25算法
BM25(Best Match 25)是一种常用于搜索引擎中的文本检索算法,也是Lucene搜索引擎中常用的算法之一。它是根据文档和查询之间的关系来评估文档的相关性,并根据相关性进行排序。
BM25算法的核心思想是使用统计学原理来计算文档和查询之间的相关性。它考虑了文档中各个词项的权重、查询词频、文档长度等因素,通过计算一个分数来衡量文档和查询之间的相关性。
具体来说,BM25算法中的评分公式如下:
score(D,Q) = ∑((IDF(q) * tf(q, D) * (k1 + 1)) / (tf(q, D) + k1 * (1 - b + b * (|D| / avgdl))))
其中,D表示文档,Q表示查询,q表示查询中的一个词项,tf(q, D)表示词项q在文档D中的频率,k1和b是调节参数,IDF(q)表示词项q的逆文档频率,avgdl表示平均文档长度。
BM25算法通过计算每个文档和查询之间的得分,然后根据得分对文档进行排序,以便返回相关性较高的文档。它考虑了词项的权重、词频以及文档长度等因素,能够有效地提高搜索的准确性和相关性。
在Lucene中,BM25算法作为默认的评分算法被广泛应用于文本搜索和检索任务中,可以通过调整k1和b参数来优化搜索结果。
3.2 向量空间模型
Lucene的搜索算法之一是基于向量空间模型的检索算法。向量空间模型基于向量的概念,其中每个文档和查询都表示为一个向量,向量的维度是所有词项的集合。通过计算文档向量和查询向量之间的相似度,可以确定最匹配的文档。
要计算文档和查询之间的相似度,可以使用不同的方法,其中常见的方法包括余弦相似度和Jaccard相似度。
-
余弦相似度(Cosine Similarity):余弦相似度是基于向量的夹角来衡量文档和查询的相似度。它通过计算文档向量和查询向量的内积除以它们的模(即向量的长度)的乘积来计算。余弦相似度的取值范围在-1到1之间,越接近1表示相似度越高。
-
Jaccard相似度:Jaccard相似度是基于向量的交集和并集来衡量文档和查询的相似度。它通过计算文档向量和查询向量的交集大小除以它们的并集大小来计算。Jaccard相似度的取值范围在0到1之间,越接近1表示相似度越高。
在Lucene中,可以使用TF-IDF(Term Frequency-Inverse Document Frequency)来对文档和查询的向量进行加权。TF-IDF分别衡量了词项在文档中的频率和在整个语料库中的重要性。
综上所述,Lucene的向量空间模型搜索算法基于计算文档和查询之间的相似度来确定匹配的文档,并使用TF-IDF来加权向量。这种算法可以在大规模语料库中高效地进行文本检索。
3.3 TF-IDF算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于评估一个词语对于一个文件集或一个语料库中的某个文件的重要程度的统计方法。TF-IDF算法的基本思想是:如果一个词在一个文件中出现的频率越高,同时在整个文件集中出现的频率越低,那么该词对于该文件的区分能力越强,也就是越重要。
具体来说,TF(Term Frequency)表示一个词在一个文件中出现的频率,即该词在该文件中出现的次数除以该文件中总的词数。这个值越大,表示该词在文件中的重要性越高。
IDF(Inverse Document Frequency)则表示一个词在整个文件集中的出现频率的倒数,即文件集中总的文件数除以该词出现的文件数取对数。这个值越大,表示该词在文件集中的重要性越低。
TF-IDF的计算方法是将一个词在一个文件中的TF值乘以该词在整个文件集中的IDF值。这样计算出的TF-IDF值越大,表示该词对于该文件的重要性越高。
在Lucene中,TF-IDF算法常用于计算一个词在一个文档中的权重,从而用于衡量该文档与查询的相关性。Lucene的搜索算法会根据词语的TF-IDF值将相关性高的文档排在前面。
总结起来,TF-IDF算法在Lucene中被用于评估一个词对于一个文件的重要程度。通过计算词在文件中的TF值和在整个文件集中的IDF值,可以得到一个词的TF-IDF值,从而衡量该词对于该文件的重要性。
4、Lucene的高级特性
4.1 跨语言搜索支持
Lucene是一种开源的全文搜索引擎库,它提供了许多高级特性,其中之一是跨语言搜索支持。
在传统的全文搜索中,通常只能针对单一语言进行搜索。但是,随着全球化和多语言环境的发展,跨语言搜索变得越来越重要。Lucene通过提供多种技术和算法来支持跨语言搜索。
首先,Lucene提供了一些语言处理器(Language Analyzers),这些处理器可以对文本进行分词、词干提取等操作,以便更好地处理跨语言搜索。这些语言处理器可以针对不同的语言进行定制和配置。
其次,Lucene还提供了语言检测器(Language Detector),可以自动检测给定文本的语言,并根据文本的语言选择适当的分析器进行处理。这在处理不同语言的文本集合时非常有用。
此外,Lucene还支持多语言搜索。它可以处理包含多种语言的文本,允许用户在不同语言之间进行搜索,并返回匹配的结果。Lucene使用的是基于向量空间模型的方法来计算文本之间的相似度,从而实现多语言搜索。
总之,Lucene的跨语言搜索支持使得用户可以更好地处理跨语言环境下的全文搜索需求,并提供了多种技术和算法来支持这一功能。
4.2 分布式搜索与扩展性
Lucene提供了分布式搜索和扩展性的高级特性,这使得它能够处理大规模数据集和高并发的搜索请求。
分布式搜索是指将搜索索引分布在多台机器上,并且在分布式环境下进行搜索。这样可以提高搜索的吞吐量和性能,并且可以处理更大规模的数据集。Lucene使用了一种称为分片的技术,将索引分成多个分片存储在不同的机器上,然后通过协调节点将搜索请求分发给适当的分片进行处理。这种分布式搜索的架构可以动态地增加或减少节点数量,以适应不同的负载需求。
另外,Lucene还具有良好的扩展性,可以方便地将其集成到现有的系统中,并根据具体需求进行定制和扩展。它提供了一些扩展点和接口,允许用户自定义索引和搜索的行为。例如,可以通过实现自定义的分析器、查询解析器或评分算法来改变搜索的行为。此外,Lucene还支持插件机制,允许用户通过添加自定义插件来增加新的功能或集成其他系统。
通过分布式搜索和扩展性的特性,Lucene可以处理大规模的数据集和高并发的搜索请求,并且可以灵活地根据需求进行定制和扩展。这使得Lucene成为一个强大而灵活的搜索引擎库,适用于各种应用场景和需求。
4.3 高亮显示与片段提取
Lucene提供了高亮显示和片段提取的功能,用于在搜索结果中突出显示与查询匹配的关键词,并提取包含关键词的片段。
高亮显示可以通过使用highlighter类来实现。首先,需要定义一个fragmenter,它用于将文本分成较小的片段。然后,可以使用highlighter类来将查询与文本进行匹配,并返回高亮显示的结果。可以选择不同的高亮显示方式,例如使用HTML标签包裹匹配的关键词。
片段提取可以通过使用fragmenter类来实现。通过设置适当的片段大小,可以从文本中提取出包含关键词的片段。可以选择提取原始文本中的片段,或者使用高亮显示的方式进行提取。
使用高亮显示和片段提取功能可以提高用户体验,使用户更容易找到相关的信息。它们通常用于搜索引擎和文本分析工具中。
5、Lucene的性能优化
详见《深入揭秘Lucene:全面解析其原理与应用场景(二)》
6、Lucene在实际应用中的应用场景
详见《深入揭秘Lucene:全面解析其原理与应用场景(二)》
7、Lucene的未来发展方向
详见《深入揭秘Lucene:全面解析其原理与应用场景(二)》
8、结语
总而言之,Lucene是一个功能强大且灵活的搜索引擎库,它的原理和应用场景相当广泛。无论是构建搜索引擎、实现文本分析工具还是构建信息检索系统,Lucene都是一个不可或缺的利器。通过了解Lucene的原理和应用,我们可以更好地应用它来解决不同的文本搜索和信息检索问题。
希望本文能够给大家提供关于Lucene的深入理解,帮助大家在实际项目中更好地应用Lucene,并为搜索和信息检索领域的发展做出贡献。
相关文章:
)
深入揭秘Lucene:全面解析其原理与应用场景(一)
本系列文章简介: 本系列文章将深入揭秘Lucene,全面解析其原理与应用场景。我们将从Lucene的基本概念和核心组件开始,逐步介绍Lucene的索引原理、搜索算法以及性能优化策略。通过阅读本文,读者将会对Lucene的工作原理有更深入的了解…...
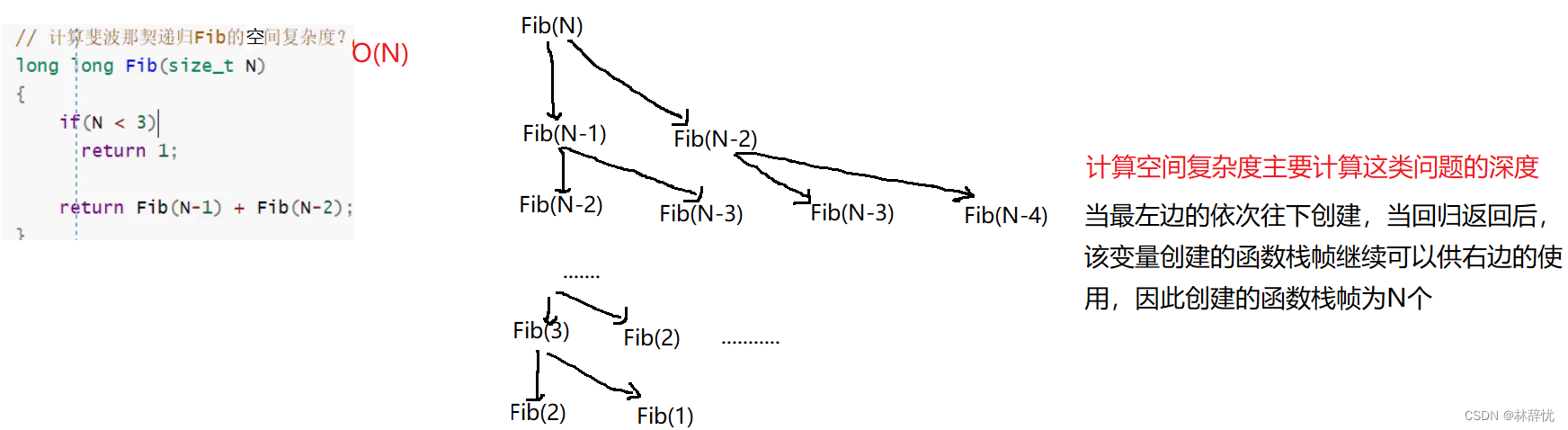
拿捏算法的复杂度
目录 前言 一:算法的时间复杂度 1.定义 2.简单的算法可以数循环的次数,其余需要经过计算得出表达式 3.记法:大O的渐近表示法 表示规则:对得出的时间复杂度的函数表达式,只关注最高阶,其余项和最高阶…...
)
C语言实战—猜数字游戏(涉及循环和少部分函数内容)
对于前面一些内容的总结 不妨跟着一起试试吧 折半查找算法(二分查找) 比如我买了一双鞋,你好奇问我多少钱,我说不超过300元。你还是好奇,你想知道到底多少,我就让 你猜,你会怎么猜?…...
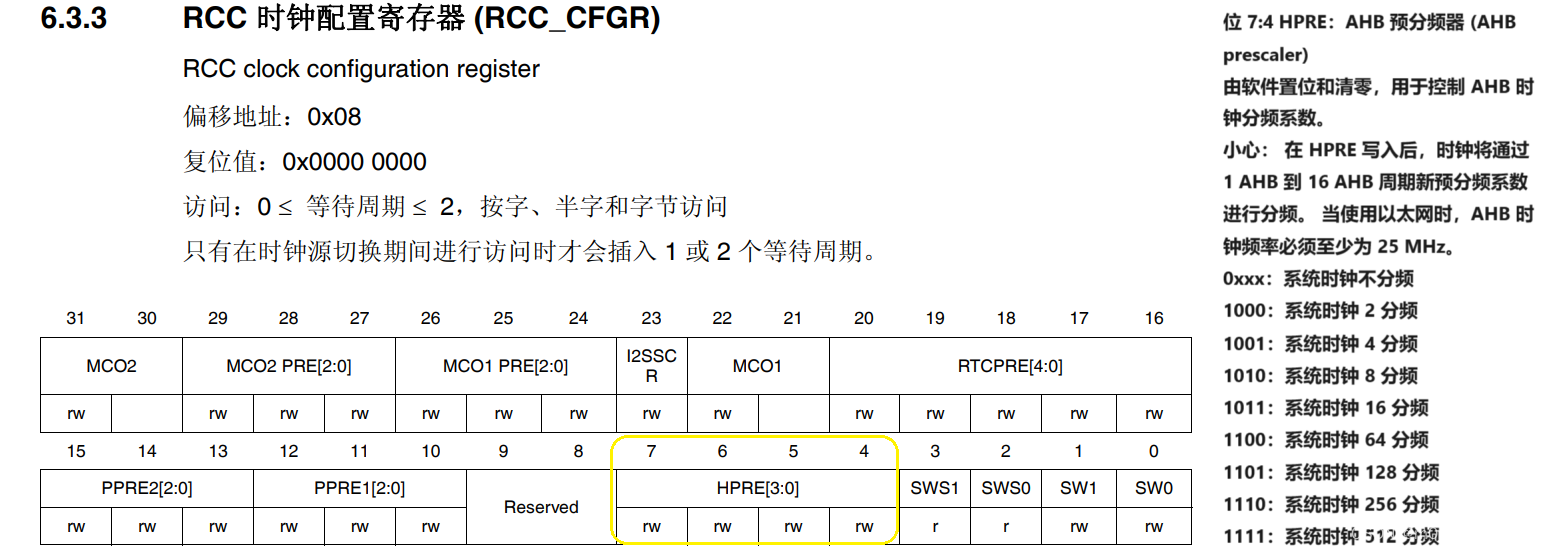
#define MODIFY_REG(REG, CLEARMASK, SETMASK)
#define MODIFY_REG(REG, CLEARMASK, SETMASK) WRITE_REG((REG), (((READ_REG(REG)) & (~(CLEARMASK))) | (SETMASK))) 这个宏 MODIFY_REG 是在嵌入式编程中,它用于修改一个寄存器的特定位,而不影响其他位。这个宏接受三个参数ÿ…...
使用 Docker 部署 Stirling-PDF 多功能 PDF 工具
1)Stirling-PDF 介绍 大家应该都有过这样的经历,面对一堆 PDF 文档,或者需要合并几个 PDF,或者需要将一份 PDF 文件拆分,又或者需要调整 PDF 中的页面顺序,找到的线上工具 要么广告满天飞,要么 …...
springcloud第3季 项目工程搭建与需求说明1
一 需求说明 1.1 实现结构图 订单接口调用支付接口 二 工程搭建 2.1 搭建工程步骤...
外包干了3个月,技术退步明显。。。。
先说一下自己的情况,本科生,2019年我通过校招踏入了南京一家软件公司,开始了我的职业生涯。那时的我,满怀热血和憧憬,期待着在这个行业中闯出一片天地。然而,随着时间的推移,我发现自己逐渐陷入…...
Redis特性与应用场景
Redis是一个在内存中存储数据的中间件,用于作为数据库,用于作为数据缓存,在分布式系统中能够发挥重要作用。 Redis的特性 1.In-memory data structures: MySQL使用表的方式存储数据,这意味着数据通常存储在硬盘上,并且…...

openssl3.2 - exp - 可以在命令行使用的口令算法名称列表
文章目录 openssl3.2 - exp - 可以在命令行使用的口令算法名称列表概述笔记测试工程实现备注整理 - 总共有126种加密算法可用于命令行参数的密码加密算法备注END openssl3.2 - exp - 可以在命令行使用的口令算法名称列表 概述 上一个笔记openssl3.2 - exp - PEM <…...
模板不存在:./Application/Home/View/OnContact/Index.html 错误位置
模板不存在:./Application/Home/View/OnContact/Index.html 错误位置FILE: /home/huimingdedhpucixmaihndged5e/wwwroot/ThinkPHP123/Library/Think/View.class.php LINE: 110 TRACE#0 /home/huimingdedhpucixmaihndged5e/wwwroot/ThinkPHP123/Library/Think/View.class.php(…...

复杂的数据类型如何转成字符串!
1.首先,会调用 valueOf 方法,如果方法的返回值是一个基本数据类型,就返回这个值, 如果调用 valueOf 方法之后的返回值仍旧是一个复杂数据类型,就会调用该对象的 toString 方法, 如果 toString 方法调用之后…...
云原生构建 微服务、容器化与容器编排
第1章 何为云原生,云原生为何而生 SOA也就是面向服务的架构 软件架构的发展主要经历了集中式架构、分布式架构以及云原生架构这几代架构的发展。 微服务架构,其实是SOA的另外一种实现方式,属于SOA的子集。 在微服务架构下,系统…...
-饿汉式单例、懒汉式单例、代码块、static的注意事项)
JavaSE——面向对象高级一(2/4)-饿汉式单例、懒汉式单例、代码块、static的注意事项
目录 static的注意事项 static相关:代码块 单例设计模式 饿汉式单例 懒汉式单例 static的注意事项 类方法中可以直接访问类的成员,不可以直接访问实例成员。 public class Student{//定义一个类变量和一个实例变量static String schoolName;int s…...

排序之冒泡排序
通过连续地比较与交换相邻元素实现排序。这个过程就像气泡从底部升到顶部一样,因此得名冒泡排序。 流程: 首先,对 n 个元素执行“冒泡”,将数组的最大元素交换至正确位置。接下来,对剩余 n−1 个元素执行“冒泡”&…...

【NR技术】 3GPP支持无人机服务的关键性能指标
1 性能指标概述 5G系统传输的数据包括安装在无人机上的硬件设备(如摄像头)收集的数据,例如图片、视频和文件。也可以传输一些软件计算或统计数据,例如无人机管理数据。5G系统传输的业务控制数据可基于应用触发,如无人机上设备的开关、旋转、升…...
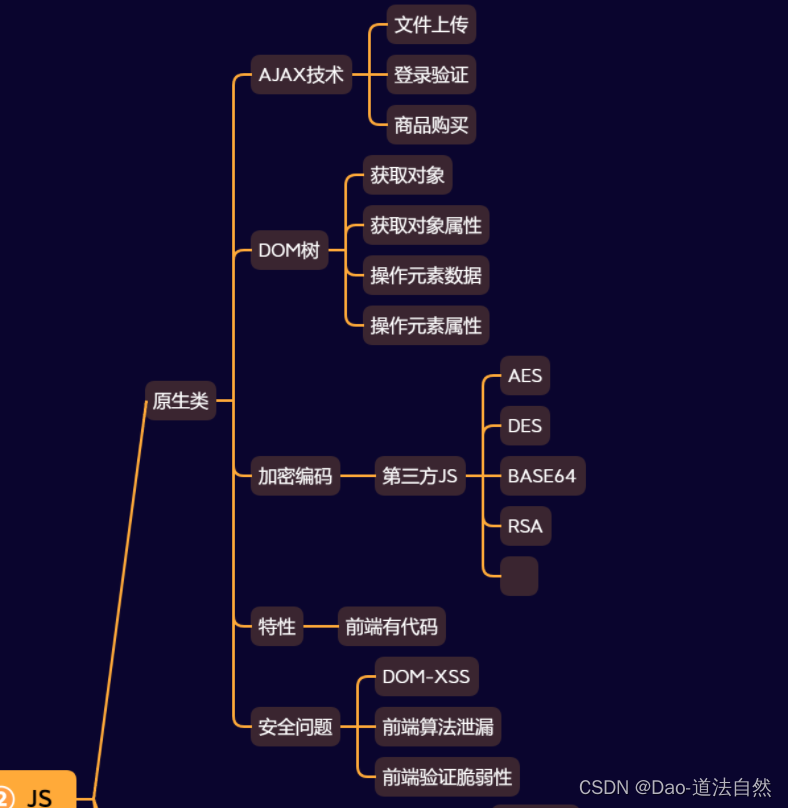
Day29:安全开发-JS应用DOM树加密编码库断点调试逆向分析元素属性操作
目录 JS原生开发-DOM树-用户交互 JS导入库开发-编码加密-逆向调试 思维导图 JS知识点: 功能:登录验证,文件操作,SQL操作,云应用接入,框架开发,打包器使用等 技术:原生开发&#x…...
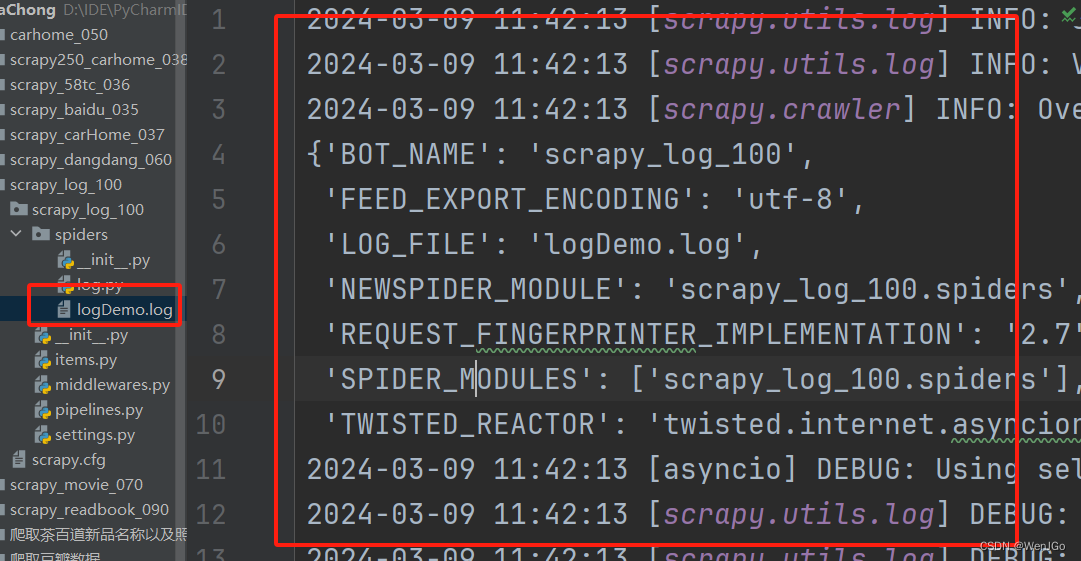
Python爬虫——scrapy-4
目录 免责声明 目标 过程 先修改配置文件 再修改pipelines.py 最后的结果是这样的 read.py pipelines.py items.py settings.py scrapy日志信息以及日志级别 settings.py文件设置 用百度实验一下 指定日志级别 WARNING 日志文件 注意 scrapy的post请求 简介 …...
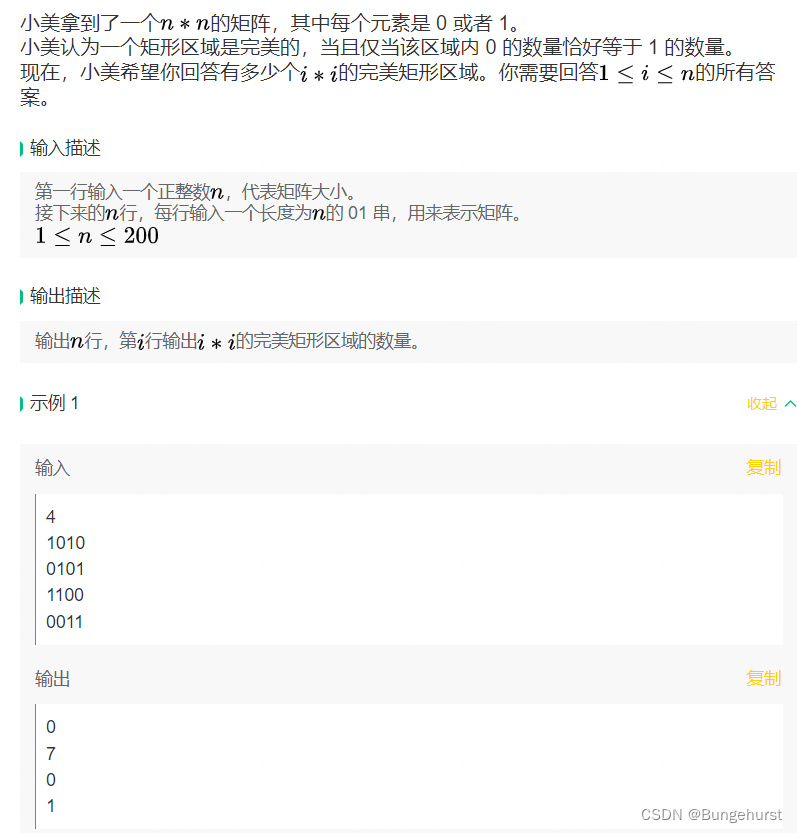
美团春招编程第一场第三题
美团春招编程第一场第三题 题目 解答 思路-暴力解法 pair中存储从原点到包含当前元素的0,1数量,得到二维数组mat; 从头到尾遍历尺寸为i*i的矩形,计算完美矩形数量 #include <iostream> #include <vector> using namespace std;int main()…...

BulingBuling - 《金钱心理学》 [ The Psychology of Money ]
金钱心理学 摩根-豪泽尔 关于财富、贪婪和幸福的永恒课程 The Psychology of Money Morgan Housel Timeless Lessons on Wealth, Greed, and Happiness 内容简介 [ 心理学 ] [ 金钱与投资 ] Whats it about? [ Psychology ] [ Money & Investments ] 《金钱心理学》&…...

急速建立网站方法
急速建立网站方法 WordPress: 简介: WordPress是一种广泛用于建设博客、网站的免费开源内容管理系统(CMS)。它具有友好的用户界面和丰富的插件生态系统,使得用户可以轻松创建和管理网站。特点: 主题和插件支…...

Avidemux视频剪辑入门指南:快速掌握开源视频编辑工具
Avidemux视频剪辑入门指南:快速掌握开源视频编辑工具 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款简单易用的开源视频编辑软件,专为快速剪辑、格式转换和…...

华为设备DHCP中继与多网段地址分配实战
1. 华为设备DHCP中继实战场景解析 想象一下你负责维护一个大型企业园区网络,办公楼、研发中心和访客区域分布在不同的楼层和区域。每个区域都需要独立的网络隔离和IP地址分配策略。如果给每个区域单独部署DHCP服务器,不仅成本高,管理起来也相…...

超越K因子:基于奈奎斯特判据的ADS射频稳定性深度解析
1. K稳定性因子的局限性:为什么我们需要奈奎斯特判据? 作为一名射频工程师,我在设计MMIC功放时经常遇到一个令人头疼的问题:明明晶体管栅长已经很小了,加上稳定电路后增益却从15dB骤降到不足10dB。这种"高增益与稳…...

Tesseract OCR 字库优化实战:从数据准备到模型部署
1. 为什么需要自定义Tesseract字库? 第一次用Tesseract识别公司内部文档时,我发现一个奇怪现象:系统生成的报表识别准确率只有60%,但扫描的印刷体文档却能到95%。后来才发现,我们用的是一种特殊等宽字体,而…...

uniapp H5 项目实战:集成mui-player实现HLS监控视频流的流畅播放与异常处理
1. 为什么选择mui-player处理HLS监控视频流 在开发监控类H5应用时,视频流的稳定播放是个硬需求。我去年接手过一个智慧园区项目,需要在uniapp里实现多路监控画面的低延迟展示。当时测试了五六种播放方案,最终mui-player以92%的首帧打开率和自…...

【PX4-ROS2实战】MAVROS2版本兼容性解析:从Foxy到Humble的px4.launch启动避坑指南
1. MAVROS2与PX4通信的版本陷阱 第一次在Humble上跑通px4.launch时,我盯着终端里那个ValueError发了十分钟呆——这场景太熟悉了,三年前在Foxy上踩过同样的坑。MAVROS2作为PX4飞控与ROS2生态的桥梁,版本兼容性问题就像定时炸弹,每…...

如何通过fp-ts实现模块化设计:从单体到微模块的函数式架构演进指南
如何通过fp-ts实现模块化设计:从单体到微模块的函数式架构演进指南 【免费下载链接】fp-ts Functional programming in TypeScript 项目地址: https://gitcode.com/gh_mirrors/fp/fp-ts fp-ts是TypeScript中函数式编程的重要库,它通过模块化设计帮…...

nli-distilroberta-base实战教程:3步部署句子关系判断Web服务
nli-distilroberta-base实战教程:3步部署句子关系判断Web服务 1. 项目概述 自然语言推理(Natural Language Inference, NLI)是NLP领域的重要任务,用于判断两个句子之间的逻辑关系。nli-distilroberta-base是基于DistilRoBERTa模型的轻量级NLI服务&…...

Embedding List 检索策略:多向量何时值得做,模型与策略如何匹配
01 为什么需要多向量检索? 在传统的稠密检索(Dense Retrieval)中,一个文档被编码为单个向量,检索时通过 ANN(近似最近邻)算法快速找到与查询最相似的文档。这种方式简单高效,但存在…...

2026论文降AIGC工具实测:高效过审的靠谱工具盘点
临近2026年毕业季,不少同学都在为毕业论文的两项检测发愁:一是重复率达标,二是AIGC疑似度符合学校要求。继知网在2025年底完成AIGC检测系统升级后,主流平台的检测逻辑已经从单纯的文本重合比对,转向语义连贯性、文本特…...