Python爬虫——scrapy-4
目录
免责声明
目标
过程
先修改配置文件
再修改pipelines.py
最后的结果是这样的
read.py
pipelines.py
items.py
settings.py
scrapy日志信息以及日志级别
settings.py文件设置
用百度实验一下
指定日志级别
WARNING
日志文件
注意
scrapy的post请求
简介
爬取百度翻译
总结
免责声明
本文章仅用于学习交流,无任何商业用途
目标
这次我们要学习把爬取到的数据存入数据库之中
过程
先修改配置文件
settings中添加下面的内容
# todo 配置 mysql数据库 # 这里是我的阿里云地址,你填你mysql的地址 DB_HOST = 'xx.xx.xx.xx' DB_PORT = 3306 DB_USER = 'root' DB_PASSWORD = '12345678' DB_NAME = 'spider01' DB_CHARSET = 'utf-8'
再修改pipelines.py
添加下面的代码
class MysqlPipeline:def process_item(self, item, spider):return item再添加配置
ITEM_PIPELINES = {"scrapy_readbook_090.pipelines.ScrapyReadbook090Pipeline": 300,# MysqlPipeline"scrapy_readbook_090.pipelines.MysqlPipeline": 301
}
。。。。
最后的结果是这样的
read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_090.items import ScrapyReadbook090Itemclass ReadSpider(CrawlSpider):name = "read"allowed_domains = ["www.dushu.com"]start_urls = ["https://www.dushu.com/book/1188_1.html"]rules = (Rule(LinkExtractor(allow=r"/book/1188_\d+\.html"),callback="parse_item",# true代表是否跟进# 打开follow为true就会爬取全部网页follow=True),)def parse_item(self, response):img_list = response.xpath('//div[@class="bookslist"]//img')for img in img_list:name = img.xpath('./@alt').extract_first()img_src = img.xpath('./@data-original').extract_first()book = ScrapyReadbook090Item(name=name, src=img_src)yield book
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass ScrapyReadbook090Pipeline:def open_spider(self, spider):self.fp = open('book.json', 'w', encoding='utf-8')def process_item(self, item, spider):self.fp.write(str(item))return itemdef close_spider(self, spider):self.fp.close()# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysqlclass MysqlPipeline:def open_spider(self, spider):settings = get_project_settings()self.host = settings['DB_HOST']self.port = settings['DB_PORT']self.user = settings['DB_USER']self.password = settings['DB_PASSWORD']self.name = settings['DB_NAME']self.charset = settings['DB_CHARSET']self.connect()def connect(self):self.conn = pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,db=self.name,charset=self.charset)# 可执行sql语句self.cursor = self.conn.cursor()def process_item(self, item, spider):sql = 'insert into book2(name,src) values("{}","{}")'.format(item['name'], item['src'])# 执行SQL语句self.cursor.execute(sql)# 提交self.conn.commit()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ScrapyReadbook090Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()name = scrapy.Field()src = scrapy.Field()settings.py
# Scrapy settings for scrapy_readbook_090 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = "scrapy_readbook_090"SPIDER_MODULES = ["scrapy_readbook_090.spiders"]
NEWSPIDER_MODULE = "scrapy_readbook_090.spiders"# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "scrapy_readbook_090 (+http://www.yourdomain.com)"# Obey robots.txt rules
ROBOTSTXT_OBEY = True# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "scrapy_readbook_090.middlewares.ScrapyReadbook090SpiderMiddleware": 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "scrapy_readbook_090.middlewares.ScrapyReadbook090DownloaderMiddleware": 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}# todo 配置 mysql数据库
DB_HOST = '8.137.20.36'
# 端口号要是整形
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = '12345678'
DB_NAME = 'spider01'
# utf-8的 - 不要写
DB_CHARSET = 'utf8'# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {"scrapy_readbook_090.pipelines.ScrapyReadbook090Pipeline": 300,# MysqlPipeline"scrapy_readbook_090.pipelines.MysqlPipeline": 301
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
最后是找到了4000条数据


可能是io进服务器的顺序问题,军娃不是最后一个,但是一页40本书,一共100页也是没有一点毛病了。(* ^ ▽ ^ *)
scrapy日志信息以及日志级别
Scrapy是一个基于Python的网络爬虫框架,它提供了强大的日志功能。Scrapy的日志信息以及日志级别如下:
-
DEBUG:调试级别,用于输出详细的调试信息,一般在开发和测试阶段使用。
-
INFO:信息级别,用于输出一些重要的信息,如爬虫的启动信息、请求的URL等。
-
WARNING:警告级别,用于输出一些不太严重的警告信息,如某个网页的解析出错,但不影响整个爬虫的执行。
-
ERROR:错误级别,用于输出一些错误信息,如爬虫的配置出错、网络连接异常等。
-
CRITICAL:严重级别,用于输出一些非常严重的错误信息,如爬虫的关键逻辑出错、无法连接到目标网站等。
默认的日志级别是DEBUG
Scrapy的日志信息可以在控制台中直接输出,也可以保存到文件中。可以通过设置Scrapy的配置文件或使用命令行参数来调整日志级别和输出方式。
以下是Scrapy的日志信息的示例:
2021-01-01 12:00:00 [scrapy.core.engine] INFO: Spider opened
2021-01-01 12:00:01 [scrapy.core.engine] DEBUG: Crawled 200 OK
2021-01-01 12:00:01 [scrapy.core.engine] DEBUG: Crawled 404 Not Found
2021-01-01 12:00:02 [scrapy.core.engine] WARNING: Ignoring response <404 Not Found>
2021-01-01 12:00:02 [scrapy.core.engine] DEBUG: Crawled 200 OK
2021-01-01 12:00:02 [scrapy.core.engine] ERROR: Spider error processing <GET http://example.com>: Error parsing HTML
2021-01-01 12:00:03 [scrapy.core.engine] DEBUG: Crawled 200 OK
2021-01-01 12:00:03 [scrapy.core.engine] INFO: Closing spider (finished)
2021-01-01 12:00:03 [scrapy.statscollectors] INFO: Dumping Scrapy stats
settings.py文件设置
默认的级别是DEBUG,会显示上面的所有信息
在配置文件中 settings.py
LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后最有一定是 .log
LOG_LEVEL : 设置日志的等级,就是显示那些,不显示那些
用百度实验一下
先把 “君子协议” 撕碎
# ROBOTSTXT_OBEY = True指定日志级别
WARNING
在settings.py中添加下述代码
# 指定日志的级别
LOG_LEVEL = 'WARNING'
==========是我在log.py中添加要打印的
就可以发现没有日志了
日志文件
我们先把上面配置的等级删除掉,再加上下述的代码
# 日志文件
LOG_FILE = 'logDemo.log'运行

世界依然清晰
但是日志已经存储在日志文件中了
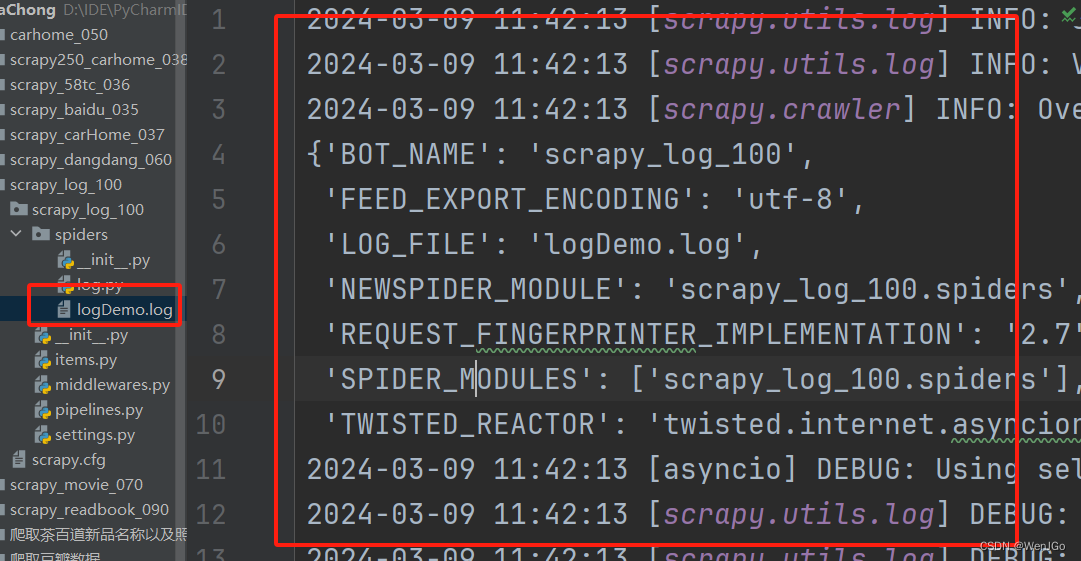
注意
其实一般来说不要修改log的等级,如果报错也太难发现是什么问题了,所以一般为了控制台别打印那么多东西
scrapy的post请求
简介
在Scrapy中进行POST请求可以通过scrapy.FormRequest类来实现。下面是一个使用Scrapy进行POST请求的示例:
import scrapyclass MySpider(scrapy.Spider):name = 'example.com'start_urls = ['http://www.example.com/login']def parse(self, response):# 提取登录页的csrf tokencsrf_token = response.css('input[name="csrf_token"]::attr(value)').get()# 构建POST请求的表单数据formdata = {'username': 'myusername','password': 'mypassword','csrf_token': csrf_token}# 发送POST请求yield scrapy.FormRequest(url='http://www.example.com/login', formdata=formdata, callback=self.after_login)def after_login(self, response):# 检查登录是否成功if response.url == 'http://www.example.com/home':self.log('Login successful')# 处理登录成功后的响应数据# ...else:self.log('Login failed')
在上面的示例中,首先在parse方法中抓取登录页,并提取登录页的csrf token。然后构建一个包含用户名、密码和csrf token的字典,作为formdata参数传递给FormRequest对象。最后使用yield关键字发送POST请求,并指定回调函数after_login来处理登录后的响应。
在after_login方法中,可以根据响应的URL来判断登录是否成功。如果URL为登录后的首页URL,则登录成功,否则登录失败。可以在登录成功时做进一步的处理,如抓取用户信息,然后在控制台或日志中输出相应的信息。
需要注意的是,Scrapy的POST请求默认使用application/x-www-form-urlencoded方式来编码数据。如果需要发送JSON或其他类型的请求,可以通过设置headers参数来指定请求头,如:yield scrapy.FormRequest(url='http://www.example.com/login', formdata=formdata, headers={'Content-Type': 'application/json'}, callback=self.after_login)。
另外,如果需要在POST请求中上传文件,可以使用scrapy.FormRequest的files参数,将文件的路径作为值传递给表单字段。更多关于POST请求的用法和参数配置,请查阅Scrapy官方文档。
爬取百度翻译
只需要修改testpost.py这个自己创建的文件就行了
import scrapy
import jsonclass TestpostSpider(scrapy.Spider):name = "testpost"allowed_domains = ["fanyi.baidu.com"]# post请求如果没有参数,那抹这个请求将没有任何的意义# 所以 start_urls 也是没有用# 而且 parse 方法也没有用了# 所以直接注释掉# TODO# start_urls = ["https://fanyi.baidu.com/sug"]## def parse(self, response):# print("==========================")# post请求就使用这个方法def start_requests(self):url = 'https://fanyi.baidu.com/sug'data = {'kw': 'final'}yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)def parse_second(self, response):content = response.textobj = json.loads(content, encoding='utf-8')print(obj)
总结
从2月29号,到今天3月9号,一共过去了十天,完成了爬虫的入门,从urllib到scrapy,这条路很长但是也很简单,中间的配置Python软件包的版本问题时常可以阻碍我的脚步,但是我都一一将他们解决,困难毕竟只是困难,人定胜天,我命由我不由天,加油!!!ヾ(◍°∇°◍)ノ゙
ヾ( ̄▽ ̄)Bye~Bye~
完结撒花
相关文章:
Python爬虫——scrapy-4
目录 免责声明 目标 过程 先修改配置文件 再修改pipelines.py 最后的结果是这样的 read.py pipelines.py items.py settings.py scrapy日志信息以及日志级别 settings.py文件设置 用百度实验一下 指定日志级别 WARNING 日志文件 注意 scrapy的post请求 简介 …...
美团春招编程第一场第三题
美团春招编程第一场第三题 题目 解答 思路-暴力解法 pair中存储从原点到包含当前元素的0,1数量,得到二维数组mat; 从头到尾遍历尺寸为i*i的矩形,计算完美矩形数量 #include <iostream> #include <vector> using namespace std;int main()…...

BulingBuling - 《金钱心理学》 [ The Psychology of Money ]
金钱心理学 摩根-豪泽尔 关于财富、贪婪和幸福的永恒课程 The Psychology of Money Morgan Housel Timeless Lessons on Wealth, Greed, and Happiness 内容简介 [ 心理学 ] [ 金钱与投资 ] Whats it about? [ Psychology ] [ Money & Investments ] 《金钱心理学》&…...

急速建立网站方法
急速建立网站方法 WordPress: 简介: WordPress是一种广泛用于建设博客、网站的免费开源内容管理系统(CMS)。它具有友好的用户界面和丰富的插件生态系统,使得用户可以轻松创建和管理网站。特点: 主题和插件支…...
Java EE之wait和notify
一.多线程的执行顺序 由于多个线程执行是抢占式执行,就会导致顺序不同,同时就会导致出现问题,就比如俩个线程同时对同一个变量进行修改,我们难以预知执行顺序。 但在实际开发中,我们希望代码按一定的逻辑顺序执行&am…...
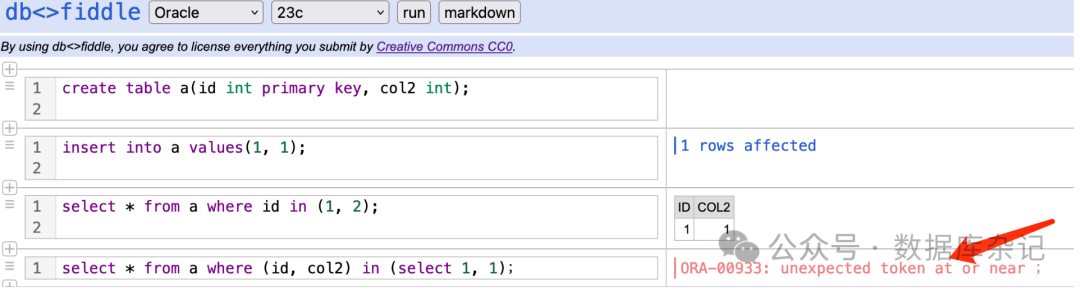
PostgreSQL中In, Exists在SQL查询中到底有无区别
前言 SQL查询当中,In和Exists子查询到底有无区别?记得很多年以前,确实是有相关的使用戒条的,或者说存在一些使用的惯用法。试图完全抹开两者的区别,就有点过了。 两者的主要区别: 从目的上讲,…...

Netty Review - 探究Netty服务端主程序无异常退出的背后机制
文章目录 概述故障场景尝试改进问题分析铺垫: Daemon线程Netty服务端启动源码分析逻辑分析 如何避免Netty服务端意外退出最佳实践 概述 在使用Netty进行服务端程序开发时,初学者可能会遇到各种问题,其中之一就是服务端意外退出的问题。这种问…...
【兔子机器人】修改GO电机id(软件方法、硬件方法)
一、硬件方法 利用上位机直接修改GO电机的id号: 打开调试助手,点击“调试”,查询电机,修改id号,即可。 但先将四个GO电机连接线拔掉,不然会将连接的电机一并修改。 利用24V电源给GO电机供电。 二、软件方…...

Spring MVC | Spring MVC 的“核心类” 和 “注解”
目录: Spring MVC 的“核心类” 和 “注解” :1.DispatcherServlet (前端控制器)2.Controller 注解3.RequestMapping 注解3.1 RequestMapping 注解的 “使用”标注在 “方法” 上标注在 “类” 上 3.2 RequestMapping 注解的 “属性” 4.组合注解4.1 请求处理方法的…...
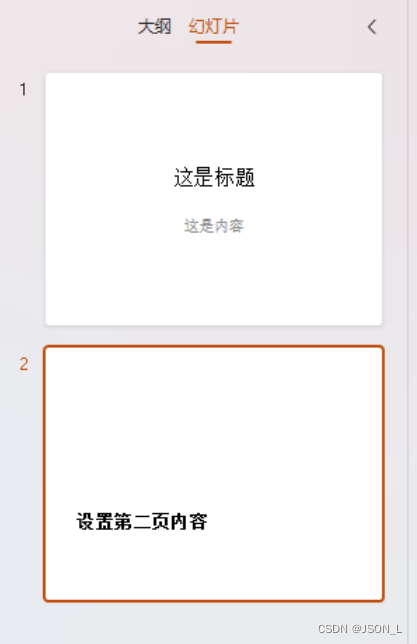
Python 创建PPT
本篇为如何使用Python来创建ppt文件。 创建PPT 安装必要的库 命令如下: pip install python-pptx 安装过程: 创建ppt文件 在当前目录下创建一个test的ppt文件。其中包含两页,分别使用了不同的布局。 第一页设置了标题和内容。第二页只设…...
【工具】Git的24种常用命令
相关链接 传送门:>>>【工具】Git的介绍与安装<< 1.Git配置邮箱和用户 第一次使用Git软件,需要告诉Git软件你的名称和邮箱,否则无法将文件纳入到版本库中进行版本管理。 原因:多人协作时,不同的用户可…...
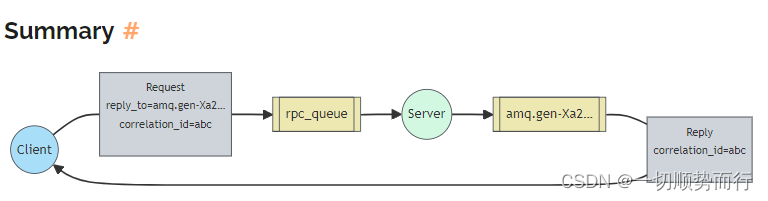
rabbitmq 基本总结
rabbitmq 的基本概念 vhost、broker、producer、 consumer、 exchange、 queue、 routing key rabbitmq 常用的队列类型,工作队列(简单队列),pub/sub, routing key, topic 模式 <dependency><groupId>com.rabbitmq&l…...

7、Copmose自定义颜色和主题切换
Copmose自定义颜色和主题切换 一起颜色的设置的都是在res/values/colors里面去做颜色, 但是当使用compose的时候,抛弃了使用了ui.theme底下的Color.kt和Theme.kt 但是默认使用的是MaterialTheme主题,里面的颜色字段不能定义,因此…...

js-判断变量是否定义
if (typeof myVar undefined) {// myVar (未定义) 或 (已定义但未初始化) } else {// myVar (已定义和已初始化) } 参考 https://www.cnblogs.com/redFeather/p/17662966.html...
视频远程监控平台EasyCVR集成后播放只有一帧画面的原因排查与解决
智慧安防视频监控平台EasyCVR能在复杂的网络环境中(专网、局域网、广域网、VPN、公网等)将前端海量的设备进行统一集中接入与视频汇聚管理,平台可支持的接入协议包括:国标GB28181、RTSP/Onvif、RTMP,以及厂家的私有协议…...

Pulsar 社区周报 | No.2024.03.08 Pulsar-Spark Connector 助力实时计算
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,…...

Redis--线程模型详解
Redis线程模型 Redis内部使用的文件事件处理器(基于Reactor模式开发的)file event handler是单线程的,所以Redis线程模型才叫单线程模型,它采用IO多路复用机制同时监听多个socket,当被监听的socket准备好执行accep、r…...

[备赛笔记]——5G大唐杯(5G考试等级考考试基础试题)
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...

【解读】OWASP 大语言模型(LLM)安全测评基准V1.0
大语言模型(LLM,Large Language Model)是指参数量巨大、能够处理海量数据的模型, 此类模型通常具有大规模的参数,使得它们能够处理更复杂的问题,并学习更广泛的知识。自2022 年以来,LLM技术在得到了广泛的应…...
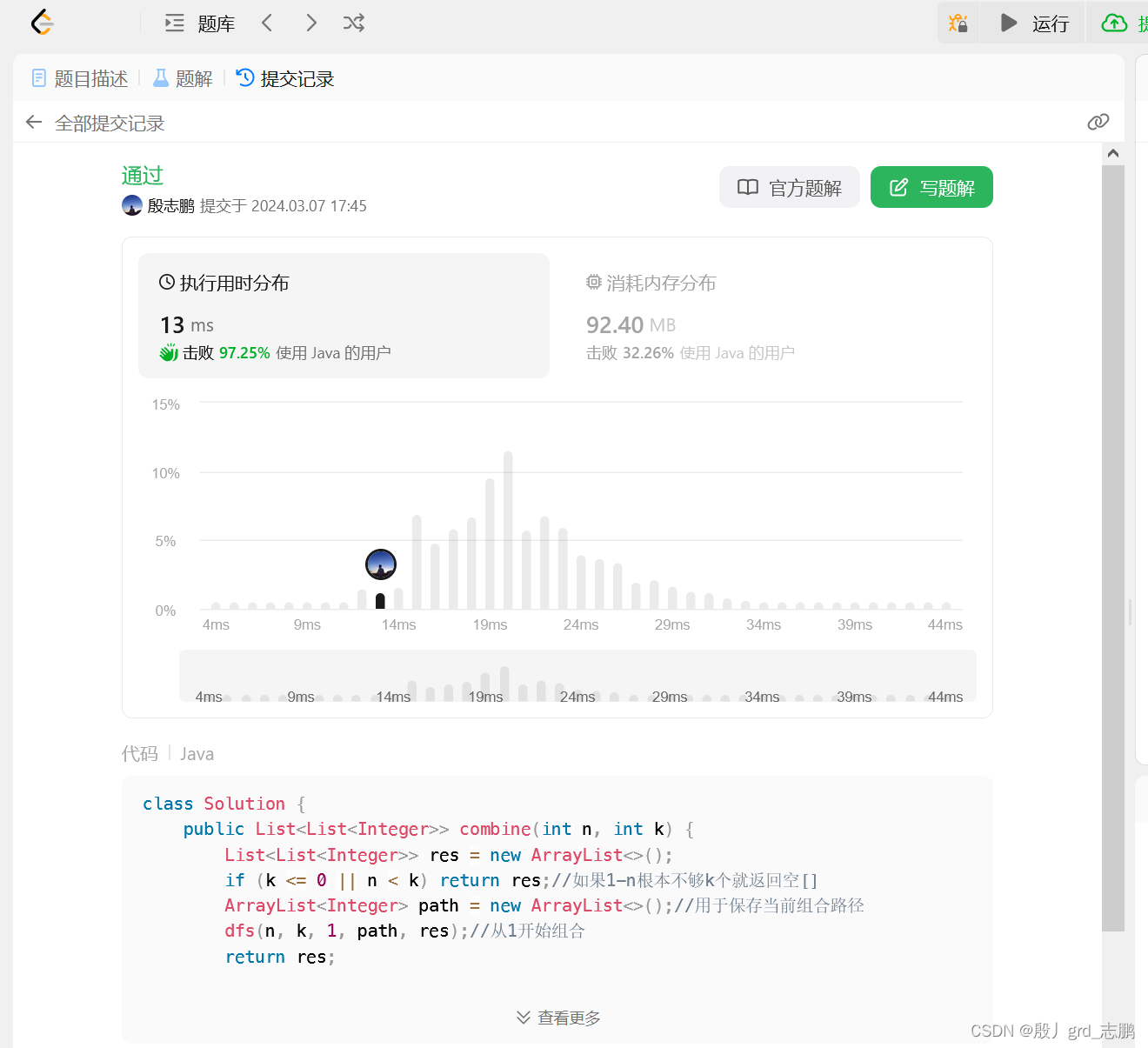
java数据结构与算法刷题-----LeetCode77. 组合
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 文章目录 1. 递归实现 解题思路 这种题只能暴力求解,枚举所有可…...

KMS智能激活脚本终极指南:3分钟免费激活Windows和Office全版本
KMS智能激活脚本终极指南:3分钟免费激活Windows和Office全版本 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?面对复杂的激活流程和高昂的…...

鸣潮自动化助手终极指南:从零开始构建你的游戏智能管家
鸣潮自动化助手终极指南:从零开始构建你的游戏智能管家 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves 你是否厌倦了在…...

终极指南:如何用PHP快速实现HTML转PDF的完整教程
终极指南:如何用PHP快速实现HTML转PDF的完整教程 【免费下载链接】html2pdf OFFICIAL PROJECT | HTML to PDF converter written in PHP 项目地址: https://gitcode.com/gh_mirrors/ht/html2pdf html2pdf是一个强大的PHP HTML转PDF库,能够帮助开发…...

2025届最火的十大AI论文方案解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术写作进程里,恰当地选用 AI 工具能够明显地提高效率。当下主流的论文 AI 网…...

用Python实战一阶微分方程:从分离变量到伯努利方程求解可视化
用Python实战一阶微分方程:从分离变量到伯努利方程求解可视化 微分方程作为描述动态系统的重要工具,在物理、工程、生物等领域有着广泛应用。但对于许多编程爱好者来说,数学理论与代码实现之间总有一道难以跨越的鸿沟。本文将带你用Python的S…...
从Transformer到SASRec:图解自注意力如何重塑序列推荐系统
从Transformer到SASRec:图解自注意力如何重塑序列推荐系统 想象一下,当你在电商平台浏览商品时,系统仿佛能读懂你的心思,精准推荐你下一步可能感兴趣的内容。这背后隐藏着一个关键技术——自注意力机制。2018年,一篇名…...

Qwen3-ASR-1.7B多场景落地:从会议转写到教学评估全覆盖
Qwen3-ASR-1.7B多场景落地:从会议转写到教学评估全覆盖 1. 语音识别新选择:Qwen3-ASR-1.7B来了 如果你正在寻找一个既强大又实用的语音识别方案,Qwen3-ASR-1.7B绝对值得关注。这个模型来自阿里通义千问团队,拥有17亿参数&#x…...
实战:从概念到UI交互的“标签”艺术)
Qt 动态属性(Dynamic Property)实战:从概念到UI交互的“标签”艺术
1. 动态属性:Qt界面开发的"智能标签" 第一次接触Qt动态属性时,我把它想象成便利贴。就像我们会在办公桌上给文件贴便利贴做标记一样,动态属性就是给Qt控件贴的"智能标签"。这个标签可以随时贴上、撕下,完全不…...

JS逆向实战 - 数美滑块验证码的协议破解与自动化对抗
1. 数美滑块验证码的协议层对抗全景 第一次遇到数美滑块验证码是在某次数据采集项目中,当时连续触发滑块导致采集中断,我才意识到这个看似简单的拼图背后藏着复杂的协议体系。数美验证码的核心防御机制建立在完整的请求-响应协议链上,从初始化…...

GELU激活函数:为什么它正在取代ReLU成为深度学习的新宠?
1. GELU激活函数:从数学原理到实际价值 第一次听说GELU激活函数时,我和大多数人的反应一样:为什么要在ReLU已经如此成功的情况下,引入这个看起来更复杂的替代品?直到在BERT模型的源码中看到它的身影,才意识…...