python知网爬虫论文pdf下载+立即可用(动态爬虫)
文章目录
- 使用
- 代码
使用
自己工作需要,分享出来,刚刚修改完。
知需要修改keyword就可以完成自动搜索和下载同时翻页。
但是需要安装Chrome,也支持linux爬虫,也要安装linux Chrome非可视化版。
代码
import selenium.webdriver as webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import Chrome, ChromeOptions
import time
import json
import pandas as pd
import requestspapers_info_list = []
one_paper = {}keyword = "你的query" # 搜索关键词# 设置options参数,以开发者模式运行
option = ChromeOptions()
option.add_experimental_option("excludeSwitches", ["enable-automation"])# 解决报错,设置无界面运行
option.add_argument('--no-sandbox')
option.add_argument('--disable-dev-shm-usage')
option.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
option.add_argument("--headless")
option.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避buguser_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
option.add_argument(f'user-agent={user_agent}')url = "https://kns.cnki.net/kns8s/defaultresult/index?crossids=YSTT4HG0%2CLSTPFY1C%2CJUP3MUPD%2CMPMFIG1A%2CWQ0UVIAA%2CBLZOG7CK%2CEMRPGLPA%2CPWFIRAGL%2CNLBO1Z6R%2CNN3FJMUV&korder=SU&kw=" + str(keyword)
driver = webdriver.Edge(option)
driver.get(url)while (True):# 等待新界面加载完毕time.sleep(3)papers = driver.find_elements(By.XPATH, '//div[@id="gridTable"]//table[@class="result-table-list"]/tbody/tr')basestr = '//div[@id="gridTable"]//table[@class="result-table-list"]/tbody/tr'for i, li in enumerate(papers):# passname = li.find_element(By.CSS_SELECTOR, value='td.name a').textname_link = li.find_element(By.CSS_SELECTOR, value='td.name a').get_attribute("href")author = li.find_element(By.CSS_SELECTOR, value='td.author').textsource = li.find_element(By.CSS_SELECTOR, value='td.source a').textsource_link = li.find_element(By.CSS_SELECTOR, value='td.source a').get_attribute("href")print(source_link)date = li.find_element(By.CSS_SELECTOR, value='td.date').text # 发表日期data = li.find_element(By.CSS_SELECTOR, value='td.data').text # 数据库来源try:quote = li.find_element(By.CSS_SELECTOR, value='td.quote').textexcept:quote = Nonetry:downloadCount = li.find_element(By.CSS_SELECTOR, value='td.download').textexcept:downloadCount = Nonetry:operat = li.find_element(By.CSS_SELECTOR, value='td.operat a.downloadlink.icon-download')href = operat.get_attribute("href") # caj下载链接except:href = Noneprint("\n\n\n")print("文章名称:", name) # 文章名字print("作者:", author) # 作者名字print("文章来源:", source) # 文章来源# print(source_link) # 期刊链接print("发表日期:", date) # 发表日期print("数据库:", data) # 数据库if quote: print("被引次数: ", quote) # 引用次数if downloadCount: print("下载次数: ", downloadCount) # 下载次数# 查看文章详细信息new_driver = webdriver.Chrome(option)new_driver.get(name_link)try:institute = new_driver.find_element(By.CSS_SELECTOR, value='div.brief h3:nth-last-child(1)').text # 机构信息except:institute = "无机构信息"print("机构: ", institute)try:infos = new_driver.find_elements(By.CSS_SELECTOR, value='div.doc-top div.row')except:infos = []for info in infos:print(info.text.strip()) # 摘要、关键词等信息try:pdf_link = new_driver.find_element(By.CSS_SELECTOR, value='#pdfDown').get_attribute("href")except:pdf_link = ""print("pdf下载地址: ", pdf_link) # pdf下载地址,该pdf地址似乎直接复制到浏览器会报错说应用来源错误...,所以下面直接点击按钮实现自动下载pdftext = requests.get(pdf_link)with open('./pdf/' + name + '.pdf', 'wb') as f:f.write(text.content)f.close()time.sleep(3) # 等待页面加载完毕new_driver.find_element(By.CSS_SELECTOR, value='#pdfDown').click()time.sleep(3) # 等待pdf下载完毕# 查看期刊详细信息new_driver2 = webdriver.Chrome(option)new_driver2.get(source_link)# infobox = new_driver.find_element(By.XPATH, '//*[@id="qk"]//dd[@class="infobox"]')try:new_driver2.find_element(By.XPATH, '//a[@id="J_sumBtn-stretch"]').click() # 展开详细信息except:pass # 无需展开try:listbox = new_driver2.find_element(By.XPATH, '//dd[@class="infobox"]/div[@class="listbox clearfix"]')text = listbox.textexcept:text = "本期刊缺乏信息"print("--------本期刊详细信息---------")print("期刊名:", source)print(text) # 期刊详细信息new_driver2.quit()new_driver.quit()# 模拟点击下一页try:driver.find_element(By.XPATH, '//*[@id="PageNext"]').click()except:breakdriver.quit()相关文章:
)
python知网爬虫论文pdf下载+立即可用(动态爬虫)
文章目录 使用代码 使用 自己工作需要,分享出来,刚刚修改完。 知需要修改keyword就可以完成自动搜索和下载同时翻页。 但是需要安装Chrome,也支持linux爬虫,也要安装linux Chrome非可视化版。 代码 import selenium.webdriver …...

DataFunSummit 2023:洞察现代数据栈技术的创新与发展(附大会核心PPT下载)
随着数字化浪潮的推进,数据已成为企业竞争的核心要素。为了应对日益增长的数据挑战,现代数据栈技术日益受到业界的关注。DataFunSummit 2023年现代数据栈技术峰会正是在这样的背景下应运而生,汇聚了全球数据领域的精英,共同探讨现…...

运行 Jmeter 文件生成 HTML 测试报告,我选择 ANT 工具
概述 ant 是一个将软件编译、测试、部署等步骤联系在一起加以自动化的一个工具,大多用于 Java 环境中的软件开发。 在与 Jmeter 生成的 jmx 文件配合使用中,ant 会完成jmx计划的执行和生成jtl文件,并将jtl文件转化为html页面进行查看。 还可…...
TensorRT是什么,有什么作用,如何使用
TensorRT 是由 NVIDIA 提供的一个高性能深度学习推理(inference)引擎。它专为生产环境中的部署而设计,用于提高在 NVIDIA GPU 上运行的深度学习模型的推理速度和效率。以下是关于 TensorRT 的详细介绍: TensorRT 是 NVIDIA 推出的…...

同比和环比
1.同比就是今年的某时期与去年这个时期 进行对比 (消除季节性差异) 例子:2018年一季度销量 2019年一季度销量 上升/下滑 2.环比是今年的某个时期与当前上一个时期进行对比(两个时期是连续的) 例子:2024年1月 营收额1000万元 2024年2月营收额3000万元 同比增长...

js中批量修改对象属性
首先,有这个对象 let a {id: 1,name: 张三,age: 18,sex: 0 }需求:同时修改name,id,并添加一个新属性c 常规写法: a.id 2; a.name 李四; a.c 1;但这种写法遇到批量就会很麻烦 解决方法: 方法1: 使用Object.assi…...

应用案例 | Softing echocollect e网关助力汽车零部件制造商构建企业数据库,提升生产效率和质量
为了提高生产质量和效率,某知名汽车零部件制造商采用了Softing echocollect e多协议数据采集网关——从机器和设备中获取相关数据,并直接将数据存储在中央SQL数据库系统中用于分析处理,从而实现了持续监控和生产过程的改进。 一 背景 该企业…...

使用大带宽服务器对网站有什么好处?
近年来大带宽服务器频频出现在咱们的视野当中,选用的用户也在与日增长。那么究其主要原因是什么?租用大带宽服务器的好处又有哪些? 今天德迅云安全带您来了解下。1.有效提升网站访问速度 一般来说,正规的网站对用户体验度都是非常有讲究的,…...
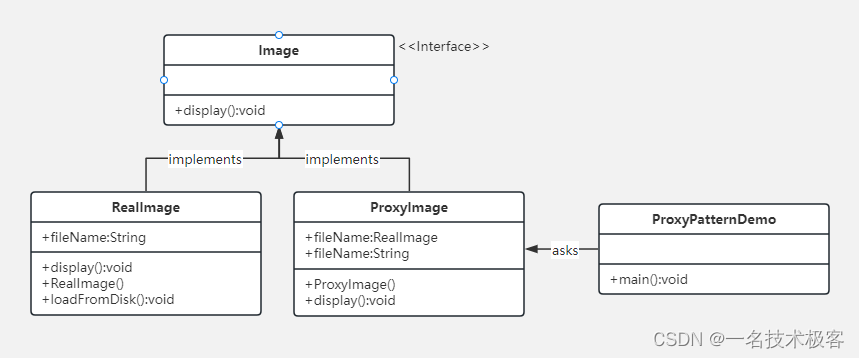
17-Java解释器模式 ( Interpreter Pattern )
Java解释器模式 摘要实现范例 解释器模式(Interpreter Pattern)实现了一个表达式接口,该接口解释一个特定的上下文 这种模式被用在 SQL 解析、符号处理引擎等 解释器模式提供了评估语言的语法或表达式的方式,它属于行为型模式 …...
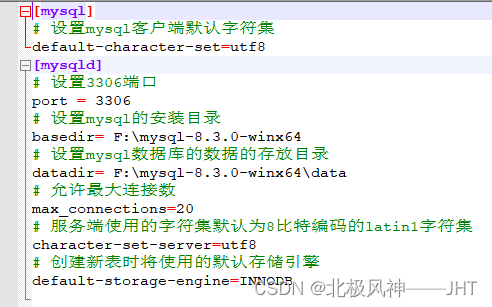
mysql的安装启动
下载 2.解压后放在某个目录下: 3.修改系统变量 4.修改配置文件 (创建一个ini文件放在解压后的目录下) 内容如下 5.初始化mysql 1.用管理员模式下输入: mysqld --initialize --console C:\WINDOWS\system32>mysqld --initia…...
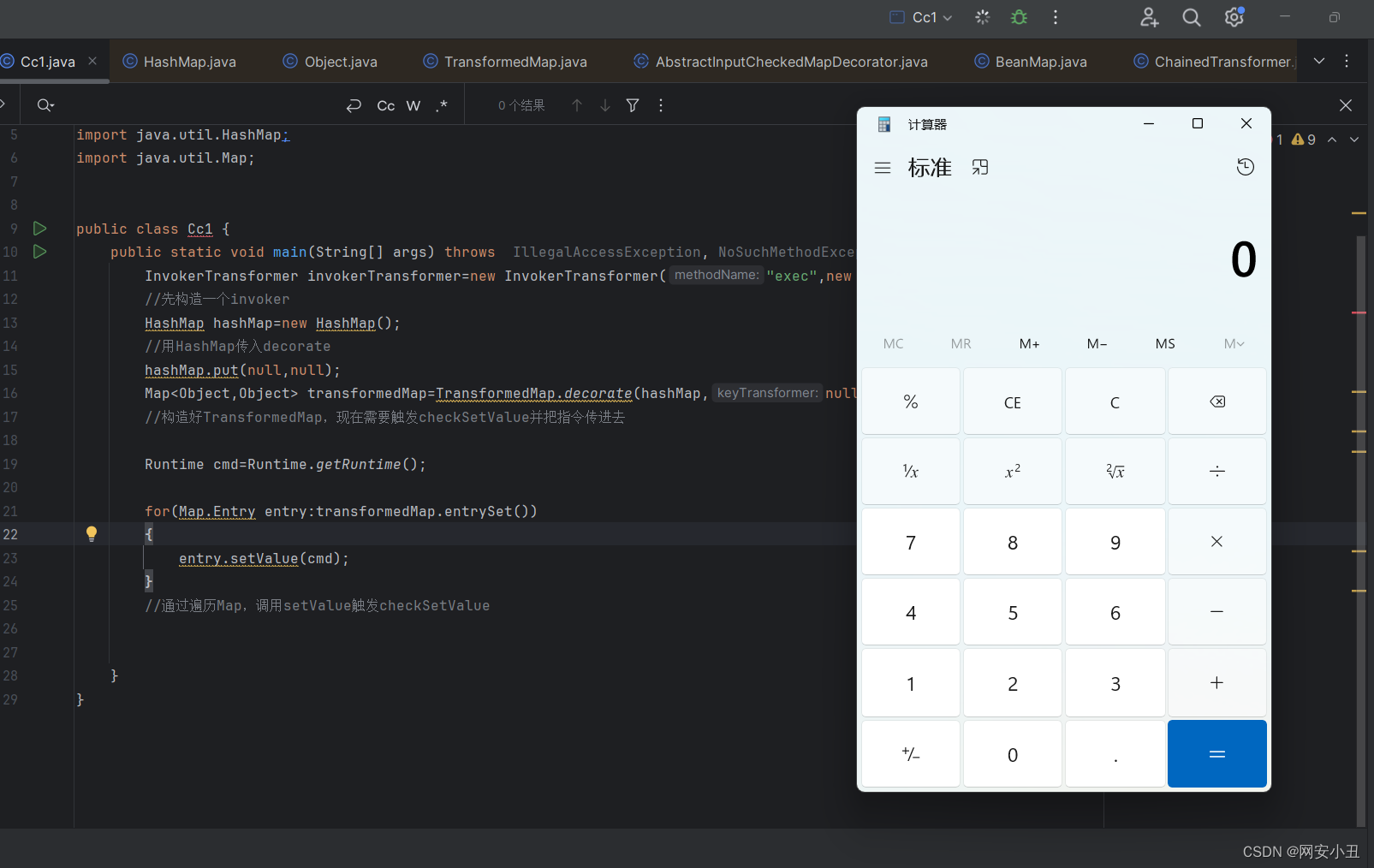
[Java安全入门]三.CC1链
1.前言 Apache Commons Collections是一个扩展了Java标准库里的Collection结构的第三方基础库,它提供了很多强大的数据结构类型和实现了各种集合工具类。Commons Collections触发反序列化漏洞构造的链叫做cc链,构造方式多种,这里先学习cc1链…...

为什么虚拟dom比真实dom更快
虚拟DOM(Virtual DOM)之所以在某些情况下比直接操作真实DOM更快,主要有以下几个原因: 批量更新:虚拟DOM可以将多个DOM操作批量更新为一次操作。当需要对真实DOM进行多次修改时,直接操作真实DOM会导致浏览器…...

力扣---腐烂的橘子
题目: bfs思路: 感觉bfs还是很容易想到的,首先定义一个双端队列(队列也是可以的~),如果值为2,则入队列,我这里将队列中的元素定义为pair<int,int>。第一个int记录在数组中的位…...
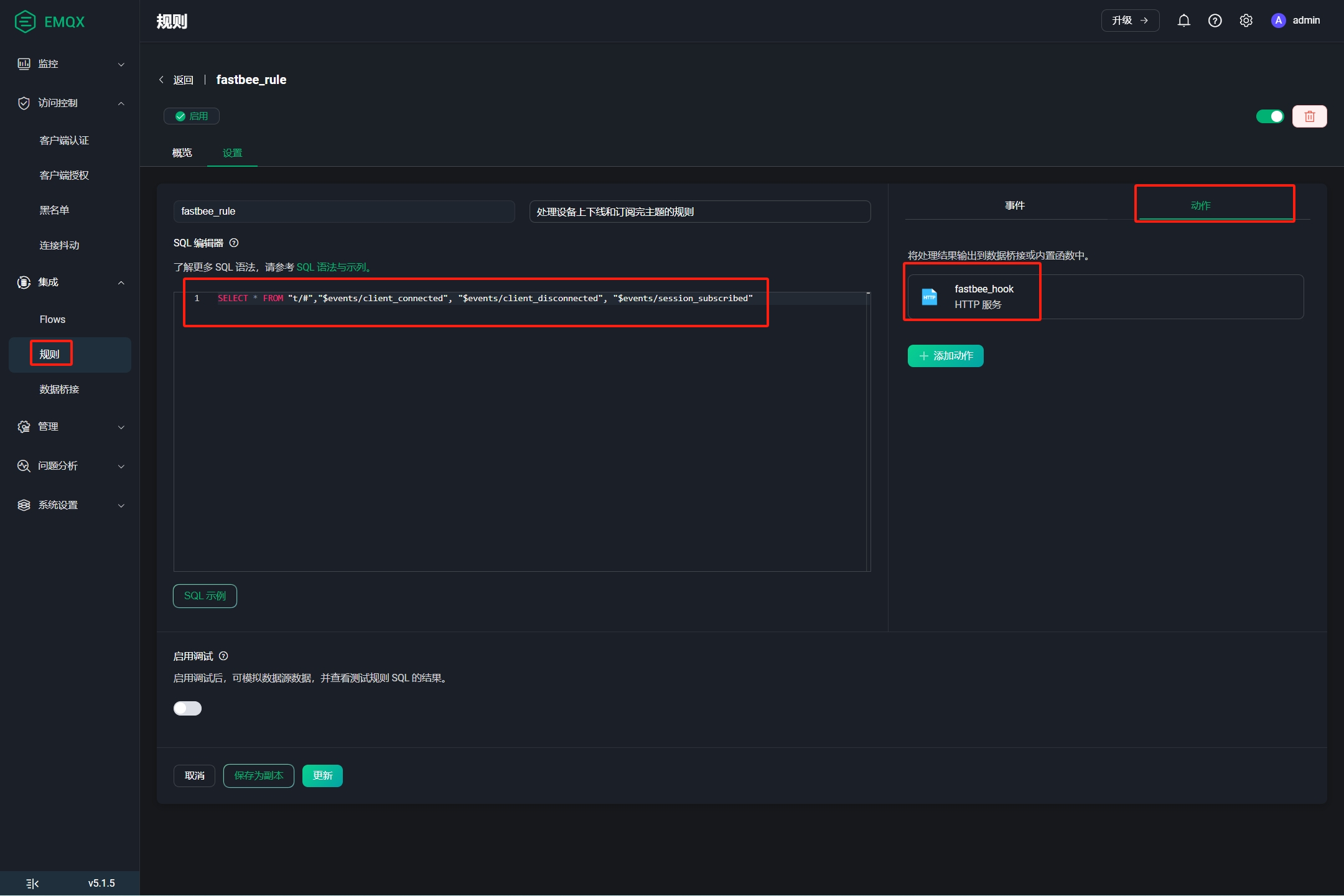
【开源物联网平台】FastBee使用EMQX5.0接入步骤
🌈 个人主页:帐篷Li 🔥 系列专栏:FastBee物联网开源项目 💪🏻 专注于简单,易用,可拓展,低成本商业化的AIOT物联网解决方案 目录 一、将java内置mqtt broker切换成EMQX5…...

【数学】【组合数学】1830. 使字符串有序的最少操作次数
作者推荐 视频算法专题 本博文涉及知识点 数学 组合数学 LeetCode1830. 使字符串有序的最少操作次数 给你一个字符串 s (下标从 0 开始)。你需要对 s 执行以下操作直到它变为一个有序字符串: 找到 最大下标 i ,使得 1 < i…...
面试问题准备 二分法/DFS/BFS/快排)
算法(数据结构)面试问题准备 二分法/DFS/BFS/快排
一、算法概念题 1. 二分法 总结链接几种查找情况的模板另一个好记的总结总结:搜索元素两端闭,while带等,mid1,结束返-1 搜索边界常常左闭右开,while小于,mid看边界开闭,闭开,结束i…...

Unity3d C#实现文件(json、txt、xml等)加密、解密和加载(信息脱敏)功能实现(含源码工程)
前言 在Unity3d工程中经常有需要将一些文件放到本地项目中,诸如json、txt、csv和xml等文件需要放到StreamingAssets和Resources文件夹目录下,在程序发布后这些文件基本是对用户可见的状态,造成信息泄露,甚至有不法分子会利用这些…...

解释一下分库分表的概念和优缺点。如何设计一个高性能的数据库架构?
解释一下分库分表的概念和优缺点。 分库分表是数据库架构优化的常见手段,主要用于解决单一数据库或表在数据量增大、访问频率提高时面临的性能瓶颈和扩展性问题。 概念: 分库(Sharding-Database): 将原本存储在一个…...
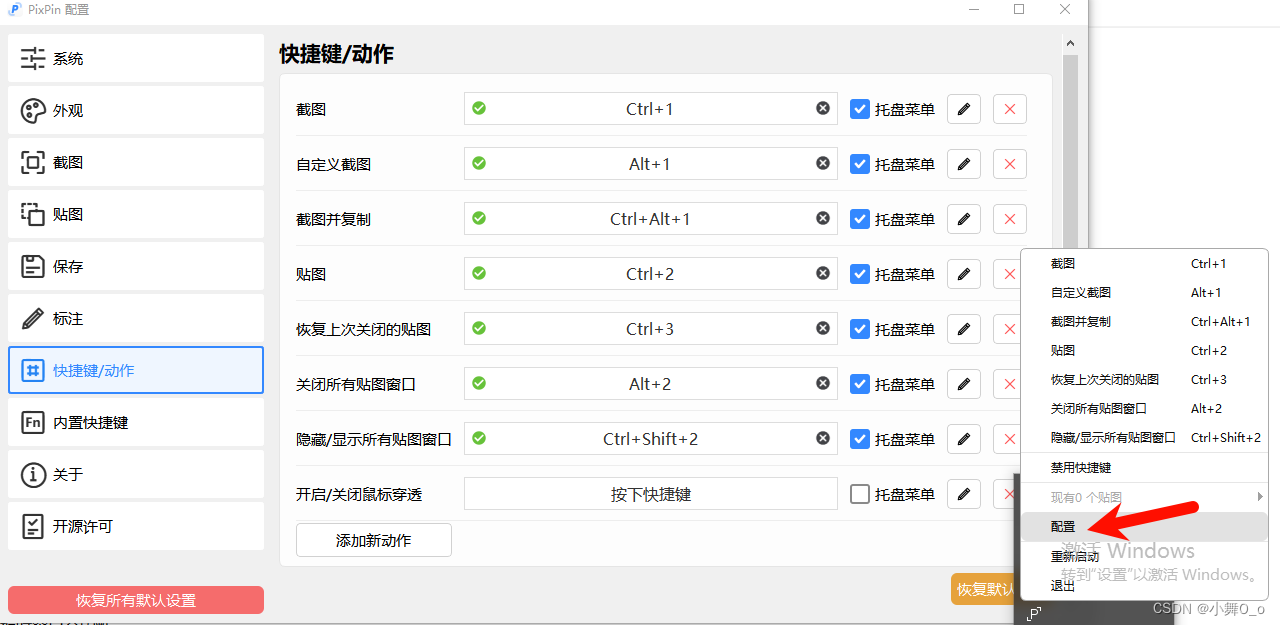
功能强大使用简单的截图/贴图工具,PixPin
一、下载链接 PixPin 截图/贴图/长截图/文字识别/标注 | PixPin 截图/贴图/长截图/文字识别/标注 (pixpinapp.com) 二、功能 截图/贴图/长截图/文字识别/标注 三、安装教程 根据提示安装即可: 四、快捷键 1.软件自带快捷键(右击PixPin查看 )…...
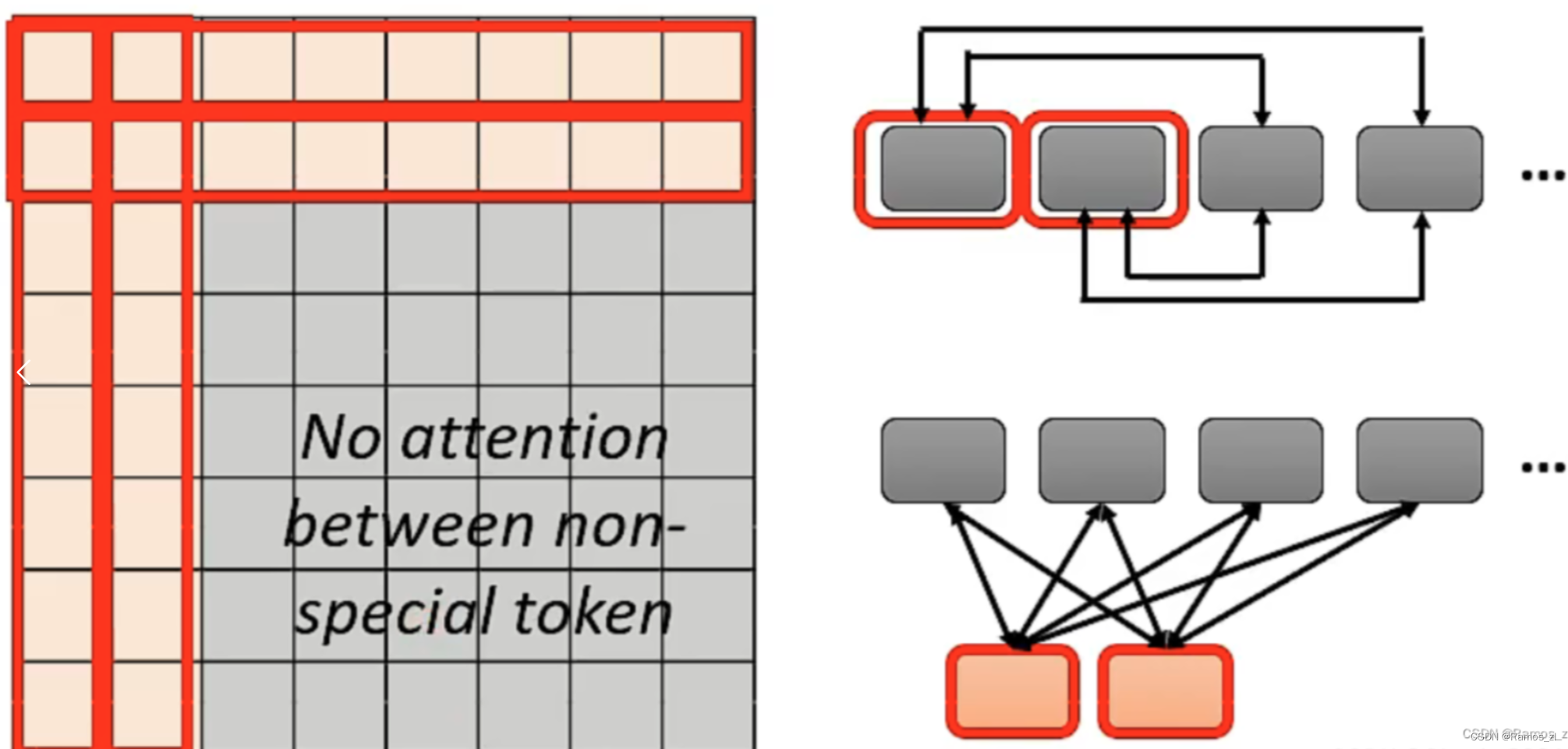
机器学习周报第32周
目录 摘要Abstract一、文献阅读1.论文标题2.论文摘要3.论文背景4.论文方案4.1 多视角自注意力网络4.2 距离感知4.3 方向信息4.4 短语模式 二、self-attention 摘要 本周学习了多视角自注意力网络,在统一的框架下联合学习输入句子的不同语言学方面。具体来说&#x…...

避开S32K144 GPIO的5个常见坑:从引脚复用、中断配置到数字滤波
避开S32K144 GPIO的5个常见坑:从引脚复用、中断配置到数字滤波 在嵌入式开发中,GPIO(通用输入输出)接口看似简单,却隐藏着许多容易忽视的细节。尤其是对于NXP的S32K144系列MCU,其GPIO模块与PORT模块的协同工…...

车载以太网在OTA升级中的关键技术解析与实践
1. 车载以太网与OTA升级的技术融合 我第一次接触车载以太网OTA升级项目是在2022年,当时为某车企开发智能座舱系统升级方案。相比传统CAN总线,以太网带来的最直观改变就是传输速率——从几百kbps直接跃升到百兆甚至千兆级别。这种带宽提升对OTA升级意味着…...

测试左移与右移平衡:工作流优化
在快速迭代的软件交付环境中,测试左移(Shift-Left Testing)和测试右移(Shift-Right Testing)已成为提升质量与效率的核心策略。测试左移强调在开发生命周期早期介入测试,而测试右移聚焦于生产环境的持续验证…...

忍者像素绘卷惊艳效果:浮雕式UI+硬边阴影+像素橙主色调实拍展示
忍者像素绘卷惊艳效果:浮雕式UI硬边阴影像素橙主色调实拍展示 1. 视觉革命:当忍者美学遇上像素艺术 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,它彻底颠覆了传统数字艺术创作方式。这款工具将忍者文化的热血精神与16-B…...

告别“假性忙碌”:如何区分生产性努力与表演性努力?
目录 01 先分清两种“努力” 02 三个信号,测测你是不是在假性忙碌 信号一:你的日程表被琐事填满,核心目标纹丝不动 信号二:你害怕停下来,一有空闲就心慌 信号三:你总是在救火,但从不防火…...

2026年企业网盘排行榜:10大主流方案安全性与协作效率深度实测
在数字化办公高度普及的2026年,公司文件共享网盘早已超越了单纯的“云端U盘”媒介,进化为企业数字资产管理与协同办公的底层核心引擎。面对市面上琳琅满目的系统,“哪款好”不再只聚焦于空间大小,而是更关乎数据安全、权限控制、传…...

淘特API签名破解实录:从抓包到算法还原的完整踩坑指南
淘特API签名逆向工程实战:从抓包到算法还原的深度解析 1. 逆向工程基础与环境准备 逆向分析电商平台API签名机制的第一步是搭建合适的分析环境。对于淘特APP的x-sign参数分析,我们需要准备以下工具链: 抓包工具:Charles或Fiddler用…...

从KITTI到LVI-SAM:高效数据集转换实战指南
1. KITTI数据集与LVI-SAM的兼容性挑战 第一次接触KITTI数据集时,我被它丰富的传感器数据震撼到了——64线激光雷达、立体相机、GPS/IMU组合导航,简直就是自动驾驶研究的黄金标准。但当我尝试把这些数据喂给LVI-SAM时,系统直接报错拒绝接收。这…...

告别抓包:一个Xposed模块教你监控抖音App的本地数据变化
深度解析:如何通过Xposed模块实现抖音App本地数据监控 在移动应用开发与测试领域,数据监控一直是提升效率的关键环节。传统依赖网络抓包的方式不仅操作繁琐,还容易遗漏客户端本地的关键数据变化。本文将介绍一种基于Xposed框架的创新方案&…...

好写作AI的AIPPT秘籍:让论文变身炫酷学术秀的魔法棒
在学术的浩瀚宇宙中,每一篇论文都是一颗独特的星辰,蕴含着研究者的智慧与心血。然而,如何让这些星辰在学术会议的舞台上璀璨夺目,吸引众人的目光?答案或许就藏在好写作AI的AIPPT功能里——这根神奇的魔法棒,…...