【论文笔记】Language Models are Few-Shot Learners
Language Models are Few-Shot Learners
回顾一下第一代 GPT-1 :
- 设计思路是 “海量无标记文本进行无监督预训练+少量有标签文本有监督微调” 范式;
- 模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm);
- 下游各种具体任务的适应是通过在模型架构的输出后增加线性权重 W y W_{y} Wy 实现,且微调过程解码器架构也会进行参数微调,迁移的解码器模块越多效果越好;
- 针对不同具体任务对应的数据集采用遍历式方法将数据集增加若干 token 作为输入;
- 微调过程考虑到文本数据集较大时会额外增加预训练型的损失函数;
- 字节对编码。
回顾一下第二代 GPT-2 :
- 背景:“预训练+微调范式” 、 “无监督训练后的模型直接用于特定任务中也具有一定程度的表现” 以及 “多任务学习在 NLP 中存在数据集难以快速制作” 问题;
- 设计思路:使用更大的模型容量(网络参数)以及更大的数据集(网页级别的参数),在输入特定任务的文本前言下(将描述任务的文本输入至模型中)实现 zero-shot 的多任务自然语言任务处理能力;
- 模型架构:基于 GPT-1 的改进(Layernorm、初始化、词汇表数量以及上下文长度);
- 预训练数据集:作者自己制作的 WebText 数据集,经过网页爬取,并经过一些工具进行处理;
- 使用改进的 BPE 用于输入表征;
- (我觉得有意义的)进行了数据集重叠性分析,以验证预训练的模型是 “记忆” 还是 “真的生成” 。
文章目录
- Language Models are Few-Shot Learners
- Abstract
- 1 Introduction
- 2 Approach
- Fine-Tuning (FT)
- Few-Shot (FS)
- One-Shot (1S)
- Zero-Shot (0S)
- 2.1 Model and Architectures
- 2.2 Training Dataset
- 2.3 Training Process
- 2.4 Evaluation
- 3 Results
- 3.1 Language Modeling, Cloze, and Completion Tasks
- 3.2 Question Answering
- 3.3 Translation
- 3.4 SuperGLUE
- 4 Measuring and Preventing Memorization Of Benchmarks
- 5 Limitations
- 6 Related Work
- scale on language model performance
- building multi-task models
- 7 Conclusion
- 8. Appendix
- A. Details of Common Crawl Filtering
- B Details of Model Training
- C Details of Test Set Contamination Studies
- D Total Compute Used to Train Language Models
Abstract
扩大语言模型的规模可以极大地提高任务无关 few-shot 的性能,甚至可以与之前 SOTA 微调方法相媲美。这篇文章中,作者训练了拥有 1750 亿个参数的自回归语言模型 GPT-3,比以往任何 非稀疏语言模型 多出 10 倍,并测试了其在 few-shot 设置中的性能。在所有任务中,GPT-3 都是在没有梯度更新或微调的情况下应用的,纯粹通过文本形式的模型交互来特定化任务和 few-shot 演示。GPT-3 在许多 NLP 数据集上都取得了很好的性能,包括翻译、问题回答和完形填空任务。作者还发现:在一些数据集上,GPT-3 的 few-shot 学习仍然很吃力,同时也发现了在一些数据集上,GPT-3 面临着在大型网络语料库中训练方法问题。
1 Introduction
NLP 已经从 学习任务特定的表征和设计任务特定的架构 转向使用 任务无关的预训练和与任务无关的架构 。这种转变导致许多具有挑战性的 NLP 任务取得了实质性进展,例如阅读理解、问答、文本蕴涵等。尽管训练得到的架构和初始表征与特定任务无关,但最终实现任务特定的架构和初始表征步骤仍然存在:对大型特定任务的样本数据集进行微调,以便让任务无关的模型适应待执行任务。
【作者设计思路一】上一篇 GPT-2 的工作表明,这最后一步微调过程可能没有必要。GPT-2 证明了,单个预训练语言模型可以 zero-shot 式任务迁移来执行标准 NLP 任务,而无需用数据集进行微调。虽然 GPT-2 的工作是一个新颖的概念证实性工作,但 GPT-2 在最好的情况下的性能只匹配单个数据集上的一些监督学习基线。在大多数任务中,表现甚至还远低于简单的监督学习基线。
【作者设计思路二】GPT-2 的工作观察到在任务迁移和同一个数量级的语言建模损失上, GPT-2 系列模型呈现出相对一致的对数线性趋势。这项工作对对数损失的规模放缩行为进行了更严格的研究,并确定了平滑的缩放趋势。在这项工作中,作者通过将先前确定的对数形式规模扩张现象的推断另外扩展两个数量级,凭经验测试是否会继续提高语言模型性能。
通过上述两个设计思路,作者训练 1750 亿个参数的自回归语言模型, GPT-3 ,并测试其迁移学习能力。
作者(其实都是同一家公司同一批人hhhhh)提到,虽然 GPT-2 那篇论文把工作描述为 “zero-shot 任务迁移” ,但 GPT-2 那篇论文有时会提供上下文中相关任务的示例,比如翻译任务和文本总结任务。由于使用了有效的特定任务数据集的训练样本,在这样的情况下可以更好地描述为 zero-shot 或 few-shot 式任务迁移。作者详细研究了这些 one-shot 和 few-shot 设定,并将它们与仅使用自然语言描述或调用要执行的任务的 zero-shot 设定进行比较。
在 SuperGLUE 数据集上 GPT 的性能随着模型尺寸的增大而增加。 K = 32 K = 32 K=32 意味着模型在每个任务显示 32 个小样本示例,在 SuperGLUE 中的 8 个任务中总共有 256=32*8 个小样本例子。BERT-Large 参考模型在 SuperGLUE 训练集(125K 样本)上进行了微调,而 BERT++ 首先在 MultiNLI(392K 样本)和SWAG(113K 示例)上进行了微调,然后对 SuperGLUE 训练集(总共 630K 微调示例)进一步微调。从表格中也可以看到,1. 经过两阶段的 BERT++ 微调仅仅比单阶段的 BERT-Large 指标高了一点点;2. GPT-3 的 zero-shot 性能还没有达到微调的两个 BERT 模型,但是增加若干少样本就能达到或者超越微调的两个 BERT 模型。3. 较小的模型 GPT-2 系列也存在这样的规律,但是在少参数(小于 10 亿参数数量)的模型上表现较差。这也验证了 GPT-2 模型中在多任务学习下 few-shot 仍然比微调模型差。
在 SuperGLUE 数据集上 GPT-3 的性能随着上下文中小样本数量的增加而增加。BERT-Large 和 BERT++ 之间的性能差异大致相当于 GPT-3 与上下文中 1 个小样本示例和 8 个小样本示例之间的差异。
所有 42 个精度基准的综合性能。虽然 zero-shot 性能随着模型大小的增加而稳步提高,但 few-shot 性能提高得更快,这表明较大的模型更精通上下文学习。


作者发现: one-shot 和 few-shot 性能通常比真正的 zero-shot 能要高得多,因此可以把语言模型也可以理解为元学习器(meta-learner),其中基于缓慢的外环(outer-loop,训练预训练数据集语言知识)梯度下降的学习与快速上下文学习(in-context learning,在模型的上下文中激活实现特定任务)相结合。
在 NLP 任务上,GPT-3 在 zero-shot 和 one-shot 中取得了良好的结果,在 few-shot 中甚至能与 SOTA 竞争,甚至偶尔超过微调而来的 SOTA 。例如,GPT-3 在 zero-shot 中的 CoQA 数据集上达到 81.5 F1,在 one-shot 中的 CoQA 数据集上达到 84.0 F1,在 few-shot 中达到 85.0 F1。类似地,GPT-3 在 zero-shot 中的 TriviaQA 数据集上达到 64.3% 的准确率,在 one-shot 中达到 68.0% ,在 few-shot 中达到 71.2% 的准确率,最后一个相比于在同一设置中操作的 微调模型 是最先进的。
作者还训练了一系列较小的模型(从 1.25 亿个参数到 130 亿个参数),以便在 zero-shot 、 one-shot 和 few-shot 中与 GPT-3 比较性能。在所有三种设置下,1. 大多数任务指标都随着模型容量呈现出相对平滑的提升(呈现出线性对数式提升);2. zero-shot 、 one-shot 和 few-shot 之间的差距往往随着模型容量的增加而增长,这可能表明较大的模型是更熟练的元学习者。
2 Approach
基本的预训练方法,包括模型架构、数据集和训练过程,类似于 GPT-2 论文中描述。GPT-3 相对直接地扩展了模型的大小、数据集的大小和多样性,以及训练的长度。对上下文学习的使用也类似于 GPT-2 (GPT-2 里面提到一种就是输入特定的某篇文档和一个问题然后进行QA回答),但在这项工作中,作者系统地探索了在上下文中学习的不同设置。
Fine-Tuning (FT)
通过训练任务特定的数千个有监督标签来更新预训练模型的权重。微调的主要优点是在许多基准测试上具有强大的性能。主要的缺点是每个任务都需要一个新的大型数据集,可能出现不良的泛化(OOD数据的不良处理),以及可能利用训练数据的虚假特征。这篇论文关注于与任务无关的性能,将微调的工作留给未来。
Few-Shot (FS)
模型在推理时被给予了一些任务特定的演示文本/句子(GPT-2 中描述为 conditioning),但没有更新权重。一个具体用例是,通常有一个上下文和一个期望的补全(例如一个英语句子和汉语翻译),并通过给出 K K K 个上下文和补全的例子,然后是最后一个上下文示例,期望模型输出补全内容。这里给出 K = 2 K=2 K=2 个情况。
Translate Chinese sentences to English sentences.
Chinese: 新年快乐!
<sep>English: Happy new year!Chinese: 我吃苹果!
<sep>English: I eat an apple!Chinese: 你好吗?
<sep>English: # 期望模型输出补全
通常将 K K K 设置在 10 到 100 的范围内,因为这是在模型的上下文窗口中可以容纳的例子数量( n c t x = 2048 n_{ctx} = 2048 nctx=2048)。few-shot 的主要优点是大大减少了对任务特定数据的需求;主要的缺点是,这种方法获得的结果迄今为止,比 SOTA 微调模型要差得多;仍然需要少量任务特定的数据。
这里描述的语言模型的 few-shot 学习与机器学习领域中使用的 few-shot 学习有相似之处——都涉及基于广泛任务分布的任务级学习,然后快速适应新的任务。
One-Shot (1S)
K = 1 K=1 K=1 的 few-shot 情形
Zero-Shot (0S)
K = 0 K=0 K=0 的 few-shot 情形,只有一个对任务的自然语言描述。
虽然在本文中提出的 few-shot 的结果达到了最高的性能,但 one-shot 甚至有时 one-shot ,似乎是与人类表现最公平的比较,并且是未来工作的重要目标。
2.1 Model and Architectures
使用与 GPT-2 相同的模型和架构,包括其中描述的调整模型初始化、预归一化和可逆标记化,不同之处在于 GPT-3 使用了交替的密集和局部带状稀疏注意模式,类似于 Sparse Transformer。为了研究性能对模型大小的关系,训练了 8 种不同大小的模型,从 1.25 亿个参数到 1750 亿个参数,最后一个称为 GPT-3 的模型。这个模型尺寸范围能够用于测试前人工作中引入的缩放定律。训练时候,沿着深度和宽度维度跨 GPU 划分每个模型,以最小化节点之间的数据传输。
2.2 Training Dataset
创建预训练数据集,做了如下步骤:
- 基于高质量的参考语料库的相似性,下载和过滤 CommonCrawl 数据集;
- 在数据集中执行在文档级别模糊重复数据删除,防止冗余,并保持验证集的完整性;
- 添加已知的高质量参考语料库(GPT-2 的 WebText 数据集、基于互联网的图书语料库 Books1 和 Books2 和英文维基百科)训练混合增广 CommonCrawl 数据集和增加其多样性。
2.3 Training Process
正如在前人工作中所发现的,更大的模型通常可以使用更大的批处理规模,但需要更小的学习率。在训练过程中测量梯度噪声尺度,并使用梯度噪声尺度来指导对批量大小的选择。
为了在不耗尽内存的情况下训练较大的模型,使用了矩阵乘法、模型并行的跨网络层中的模型混合训练。所有的模型都是在一个高带宽集群的一部分上的 V100 GPU 上进行训练的。
2.4 Evaluation
对于 few-shot ,通过从任务的训练集中随机抽取 K K K 个小样本来评估评估过程中的每个案例,根据任务由 1 或 2 个换行分隔。对于 LAMBADA 数据集和 Storycloze 数据集,没有可用的监督训练集,所以从开发集中提取 conditioning 的文本,并进行评估测试。
对于 zero-shot 和 one-shot ,对于某些任务,除了演示文本或没有演示文本之外,还使用自然语言提示词;在特定任务上也会改变输出答案的格式。
在自由形式文本补全任务中,使用与前人工作相同参数的集束搜索:光束宽度为 4 ,长度惩罚为 α = 0.6 α = 0.6 α=0.6 。
3 Results
3.1 Language Modeling, Cloze, and Completion Tasks
测试了 GPT-3 在传统的语言建模任务和相关任务上的性能。在 Penn Tree Bank 数据集上计算了 zero-shot 困惑度指标。省略了 4 个与维基百科相关的任务和 one-billion word benchmark 数据集(GPT的那波人似乎并不喜欢这个数据集),因为这些数据集的很大一部分包含在训练集中。GPT-3 模型在 Penn Tree Bank 数据集以 15 个点的巨大优势创造了一个新的 SOTA 。
LAMBADA 数据集要求该模型来预测一个段落的最后一个单词。尽管前人指出 扩大语言模型的规模在这个基准测试上产生的收益在递减 ,但发现 zero-shot 的 GPT-3 比之前的 SOTA 额外获得了 8% 的实质性收益。
对于 few-shot 使用一种填空格式来鼓励语言模型只生成一个单词 Alice was friends with Bob. Alice went to visit her friend, ____. Bob 。通过这种格式,GPT-3 比以前的 SOTA 增长了 18% 以上,性能随着模型的大小而顺利提高。然而,填空格式在 one-shot 场景下并不是有效的,它的表现总是比 zero-shot 设置更差,这可能是因为所有的模型都需要若干示例来识别完型填空的模式。对测试集成分分析发现,训练数据中似乎存在很大一部分 LAMBADA 数据集(也就是发生了显著的数据重叠),但第 4 节中进行的分析表明对性能的影响可以忽略不计。
HellaSwag 数据集涉及到选择一个故事的最佳结局。这些故事的反向挖掘/推理为对语言模型很困难,而对人类来说仍然很容易。GPT-3 优于微调的 1.5B 参数的语言模型,但仍然相当低于微调的多任务模型 ALUM 实现的总体SOTA 。
StoryCloze 2016 数据集涉及到为五个冗长的故事选择正确的结尾句子。在这里,GPT-3 比以前的 zero-shot 结果提高了大约 10% ,但总体上仍然比使用基于 BERT 模型的微调 SOTA 低 4.1% 。
3.2 Question Answering
本部分衡量 GPT-3 处理各种问答任务的能力。首先,讨论涉及回答有关广泛事实知识问题的数据集。在 “闭卷” 设置(即没有条件性信息/文章)中进行评估。在 TriviaQA 数据集上,GPT-3 的 zero-shot 结果经比经过微调的 T5-11B 高出 14.2%,并且在预训练期间也比具有问答定制预测的版本高出 3.8% 。one-shot 结果提高了 3.7%,并与开放域问答系统的 SOTA 相匹配,该系统不仅对 21M 文档的 15.3B 参数密集向量索引进行了微调,而且还利用了学习的检索机制。GPT-3 的 few-shot 结果进一步将性能再提高了 3.2% 。在自然问题(Natural Questions, NQs)上中,GPT-3 的表现优于经过微调的 T5 的 11B+SSM 语言模型。NQs 数据集中的问题倾向于细粒度的维基百科知识,这可以用来测试 GPT-3 的能力限制和广泛的预训练知识分布。
ARC 是一个常识推理数据集,收集了 3 年级到 9 年级科学考试的多项选择题。在数据集的 “Challenge” 版本上,当过滤掉简单的统计或信息检索方法无法正确回答的问题时,GPT-3 接近于经过微调的 RoBERTa 基线的性能。在数据集的 “Easy” 版本上,轻微地超越了微调的 RoBERTa 基线,但是这两个版本还是没有超过微调的 RoBERTa 基线达到的 SOTA 水平。
在两个阅读理解数据集上评估 GPT-3 。在自由形式对话数据集 CoQA 数据集上,few-shot 的 GPT-3 的表现与人类基线相差不超过 3 个点。在测试离散推理和计算能力的 DROP 数据集上,few-shot 的 GPT-3 的表现优于原始论文中经过微调 BERT 基线,但仍远低于人类表现和 SOTA 用符号系统增强神经网络。
3.3 Translation
| language | number of words | percentage of total words | 百分比 | 含义 |
|---|---|---|---|---|
| 1 | en | 181014683608 | 92.64708% | 英语 |
| 2 | fr | 3553061536 | 1.81853% | 法语 |
| 3 | de | 2870869396 | 1.46937% | 德语 |
| 4 | es | 1510070974 | 0.77289% | 西班牙语 |
| 5 | it | 1187784217 | 0.60793% | 意大利语 |
在收集 GPT-3 的训练数据时,使用了在互联网中反映的语言分布的、未经过滤的文本数据集(主要是 Common Crawl 数据集)。因此,虽然 GPT-3 的训练数据主要由英语组成(93%),但也包括 7% 的非英语内容。现有的无监督机器翻译方法通常将在一对单语数据集上的预训练与反向翻译结合起来,以一种可控的方式连接这两种语言。相比之下,GPT-3 从混合了多种语言的训练数据中学习。此外,one/few-shot 设置并不能严格地与之前的无监督工作相比,因为它们在上下文中使用了少量成对的例子。
zero-shot 的 GPT-3 的性能低于最近的无监督神经机器翻译的结果,但 one-shot 设置将性能提高了 7 BLEU,并且接近之前工作的性能相当。 few-shot 的 GPT-3 进一步提高了另外 4 个 BLEU,从而获得了与之前的无监督神经机器翻译工作相似的平均性能。对于所研究的三种输入语言,GPT-3 在翻译成英语时显着优于先前的无监督神经机器翻译工作,但在翻译成其他方向时表现不佳:英语罗马语翻译的表现是一个明显的异常值,比之前的无监督NMT工作更差超过 10 点。这可能是一个弱点,因为重复使用了 GPT-2 的字节级 BPE tokenizer,该 tokenizer 几乎完全是为英语的训练数据集而开发的。对于法语英语翻译和德语英语翻译,few-shot 的 GPT-3 表现优于能找到的最佳监督结果,但由于对文献不熟悉,而且这些基准似乎没有竞争力,不怀疑这些结果代表了真实的 SOTA 。对于罗马语英语翻译,few-shot 的 GPT-3 非常接近整体 SOTA ,这是通过无监督的预训练、对 608K 标记的样本的微调和反向翻译来实现的。
3.4 SuperGLUE
SuperGLUE 基准是数据集的标准化集合。在 few-shot 设置中,对所有任务使用了 32 个样本示例,这些示例是从训练集中随机采样的。对于除 WSC 和 MultiRC 之外的所有任务,采样了一组新的示例以在每个问题的上下文中使用。将 K K K 值提高到 32,并注意到随着模型大小和上下文中示例数量的增加,few-shot SuperGLUE 分数稳步提高,这表明上下文学习带来的好处越来越多。
GPT-3 在不同任务上的表现存在很大差异。在 COPA 和 ReCoRD 数据集上,GPT-3 在 one/few-shot 设置中实现了接近 SOTA 的性能,其中 COPA 数据集仅落后几分,在排行榜上排名第二,第一名由经过微调的、具有 11 B 参数的 T5 模型保持。在 WSC、BoolQ、MultiRC 和 RTE 数据集上的性能是合理的,大致与微调后的 BERT-Large 相匹配。在 CB 数据集上,在 few-shot 设置中看到了 75.6% 的效果。 但是 GPT-3 在 WiC 数据集上存在显著不足,其 few-shot 设置下性能相当于随机机会。为 WiC 尝试了多种不同的措辞和表述(涉及确定两个句子中是否使用相同含义的单词),但没有一个能够实现出色的性能。这说明了一种现象,且在附加材料中运行的其他实验内也看到了这一现象 —— 在一些涉及比较两个句子或片段的任务中,GPT-3 在 one/few-shot 设置中似乎很弱。这也可以解释同样遵循这种格式的 RTE 和 CB 数据集得分相对较低的原因。尽管有这些弱点,GPT-3 在 8 个任务中的 4 个上仍然优于微调的 BERT ,而在两个任务上,GPT-3 接近于微调的 110 亿参数模型达到的 SOTA 。
4 Measuring and Preventing Memorization Of Benchmarks
数据集和模型大小比 GPT-2 使用的数据集和模型大小大约大两个数量级,并且包含大量 Common Crawl 数据集,从而增加了污染和记忆的可能性(污染和记忆的意思是:测试集中存在和训练集中相似度较高的样本,导致模型直接回忆训练的内容即可,而并没有测试)。另一方面,正是由于数据量大,即使是 GPT-3 175B,相对于重复数据删除的保留验证集进行测量,其训练集也不会出现显着的过拟合。对于每个基准测试,实验都会生成一个 “干净” 的版本,删除所有可能泄漏的示例,泄漏的示例大致定义为与预训练集中的任何内容有 13-gram 重叠的示例(或者当长度短于 13 时的整个重叠示例)。然后,在这些 “干净” 的基准上评估 GPT-3 ,并与原始分数进行比较。如果 “干净” 的基准分数与整个数据集的分数相似,则表明即使存在污染,也不会对报告的结果产生显着影响(在所有都是未曾见过示例的数据集上测试的成绩,一定小于等于包含见过的(存在重叠部分)的示例的数据集上的成绩)。在大多数情况下,性能变化可以忽略不计,并且实验中并没有看到任何证据表明污染水平和性能差异之间存在相关性。作者的结论是:要么实验的保守方法大大高估了污染,要么污染对性能影响不大。
5 Limitations
在文本合成方面,GPT-3 样本有时仍然会在文档级别上进行语义重复,在足够长的段落中开始失去连贯性,自相矛盾,并且偶尔包含不合逻辑的句子或段落。
实验不包括任何双向架构或其他训练目标,例如去噪。实验的设计决策是以在从经验上认为生成式模型在双向性的任务上可能表现更差,例如填空任务、涉及回顾和比较两个内容的任务(ANLI、WIC 数据集)或需要重新阅读或仔细考虑很长的文章,然后生成一个非常简短的答案(QuAC, RACE 数据集)。
作者在实验中对每个 token 的权重相等(同等重要性),并且缺乏对预测最重要的内容和不太重要的概念的有区别做法。前人工作展示了对感兴趣的实体进行 定制预测 的好处。对于自监督的目标,特定任务依赖于将所需的任务数据集的知识强制纳入预测问题,而最终,有用的语言系统(例如虚拟助手)可能更好地被认为是采取目标导向的行动,而不仅仅是做出预测。(也就是说,对于虚拟助手更像强化学习的用户询问状态 s s s 而产生助手说的内容 a a a ,而非一直去预测用户询问状态 s s s 接下来会说什么。)最后,大型预训练语言模型并不基于其他经验领域,例如视频或现实世界的物理交互,因此缺乏大量关于世界的背景(在 GPT-3 版本中很难将这个模型描述成 “世界模拟器” )。
由于所有这些原因,扩大纯自监督预测的规模很可能会达到极限(线性对数趋势),而使用不同的方法进行增强很可能是必要的。在这方面,有希望的未来发展方向可能包括1. 从人类中学习目标函数;2. 通过强化学习进行微调;3. 添加额外的模态,如图像,以提供基础和更好的世界模型。(从 GPT-3 开始才有 “偏好对齐” 、 “多模态” 相关的方法,这说明单一模态的规模扩大并非让能力无限方法,还是 follow 对数线性)
自己想了解更多关于 LLM + RL 相关的文章,因此这里高亮一下。。。
Fine-Tuning Language Models from Human Preferences
通过询问人类问题来构建奖励模型,奖励学习过程可以使强化学习能够应用于用人类判断定义奖励的任务。大多数奖励学习工作都使用模拟环境,但有关价值观的复杂信息通常用自然语言表达,作者相信语言奖励学习是使强化学习在现实世界任务中实用和安全的关键。在本文中,基于生成预训练语言模型方面的进展,将奖励学习应用于四种自然语言任务:具有积极情绪或物理描述性语言的连续文本,以及 TL;DR 、CNN 和 Daily Mail 数据集上的文本总结/摘要生成任务。对于风格延续,仅通过人类评估的 5000 次比较就取得了良好的结果。
最后,GPT-3 的大小使其部署具有挑战性。任务特定的蒸馏值得在这个新的模型规模上进行探索。
6 Related Work
scale on language model performance
前人的工作发现:随着自回归语言模型的规模扩大,学者发现损失呈现一个平滑的幂律趋势。
第一条主线:在扩大语言模型的方法上,已经出现了通过增加参数、计算或两者都有的不同方法来扩大语言模型。作者的工作与通过增加参数和大致按比例增加 FLOPS-per-token 来增加 transformer 大小的方法最一致。
第二条主线:不仅增加模型参数,还使用条件计算框架进行计算。具体来说,混合专家模型(Mixture of Expert, MoE)已经产生了 1000 亿个参数的语言模型和 500 亿个参数的翻译模型。降低模型计算成本的一种方法例如 ALBERT 或对特定任务的蒸馏方法。
第三种主线:通过自适应计算时间和通用 transformer 等方法,在不增加参数的情况下增加计算量。
building multi-task models
用自然语言给出任务指令:在监督学习、上下文学习和多任务微调中存在。多任务学习已经显示出一些突出的初步结果,且多阶段微调已经产生了 SOTA 或能和 SOTA 竞争的结果。从元学习的角度,元学习在语言模型中得到了应用,但效果有限,也没有系统的研究。元学习的其他用途包括 matching networks 、 RL 2 ^{2} 2 、 learning to optimize 和 MAML 算法。作者的用上下文填充模型的方法在结构上与 RL 2 ^{2} 2 最为相似,因为 RL 2 ^{2} 2 的原理是在内部循环(inner-loop)适应任务,而外部循环(outer-loop)更新权重——而作者的方法内循环执行 one/few-shot 上下文学习,但之前的工作已经探索了其他 few-shot 学习方法。
过去两年语言模型的算法创新是巨大的,包括基于去噪的双向性结构、前缀语言模型、编码器-解码器架构、训练过程中的随机排列、采样效率架构、数据和训练改进以及嵌入的参数效率。结合其中一些算法进步可能会提高 GPT-3 在下游任务上的性能,尤其是在微调设置中。
7 Conclusion
作者提出了一个 1750 亿个参数的语言模型,该模型在许多 NLP 任务的 zero/one/few-shot 的基准测试中显示出强大的性能,在某些情况下几乎与特定任务的微调 SOTA 模型相匹配,以及在动态定义的任务中生成高质量的样本和强大的定性性能。在不使用微调的情况下记录了大致可预测的性能扩展趋势。还讨论了此类模型的社会影响。尽管存在许多限制和弱点,但这些结果表明,大语言模型可能是开发适应性强的通用语言系统的重要组成部分。
8. Appendix
A. Details of Common Crawl Filtering
为了提高 Common Crawl 数据集的质量,作者开发了一种自动过滤方法来删除低质量的文档。使用原始的 WebText 作为 高质量文档的代理 ,训练了一个分类器来区分高质量文档与原始低质量的 Common Crawl 数据集。然后,使用该分类器对 Common Crawl 进行重新采样,对分类器预测的质量较高的文档进行优先级排序。
分类器使用逻辑回归分类器进行训练,该分类器具有 Spark 标准 tokenizer 和 HashingTF 的功能。对于正面示例,使用一系列精选数据集(例如 WebText、Wikiedia 和网络图书语料库)作为正面示例;对于负面示例,使用一部分未过滤的 Common Crawl 数据集。使用这个分类器总体重新抽样的 Common Crawl 文档进行评分。
np.random.pareto(alpha) > 1 − document_score
选择了 α \alpha α = 9 ,以便主要获取分类器得分高的文档,但仍包括一些分布外的文档。选择 α \alpha α 是为了匹配 Common Crawl 数据集在 WebText 上的分类器的分数分布。这种重新加权提高了质量,这是通过一系列分布外的生成文本样本的损失来衡量的。
在帕累托分布中,如果 X 是一个随机变量, 则 X 的概率分布如下面的公式所示:
P ( X > x ) = ( x x m i n ) − k P(X>x)=\big(\frac{x}{x_{min}}\big)^{-k} P(X>x)=(xminx)−k
为了进一步提高模型质量并防止过度拟合(随着模型容量的增加,这变得越来越重要),使用 Spark 的 MinHashLSH 实现(具有 10 个哈希值)对每个数据集中的文档进行模糊去重(即删除与其他文档高度重叠的文档),使用于用于上面的分类。还从 Common Crawl 数据集中模糊地删除了 WebText 数据集的内容。总体而言,这使数据集大小平均减少了 10% 。
B Details of Model Training
优化器: β 1 = 0.9 β_1=0.9 β1=0.9 、 β 2 = 0.95 β_2 = 0.95 β2=0.95 和 α = 1 0 − 8 \alpha=10^{−8} α=10−8 的 Adam 优化器
梯度裁剪:梯度的全局范数裁剪为 1.0
学习率衰减:使用余弦衰减将学习率降低到其值的 10%
Token:超过 2600 亿个 token 参与训练;在 2600 亿个 token 之后,继续以原始学习率的 10% 训练。
Warmup:前 3.75 亿个 token 有一个线性的 LR 预热;
批量大小:根据模型大小在训练前 4-120 亿个 token 中,逐渐将批量大小从小值 32k 个 token 线性增加到全值。
权重衰减:所有模型都使用 0.1 的权重衰减来提供少量的正则化。
在训练过程中,总是在完整的 n c t x = 2048 n_{ctx}=2048 nctx=2048 token 上下文窗口的序列上进行训练,当文档短于 2048 token 时,将多个文档打包到单个序列中,以提高计算效率。具有多个文档的序列不会以任何特殊方式进行屏蔽,而是使用特殊的文本标记结尾来分隔序列中的文档,从而为语言模型提供必要的信息来推断由文本标记结尾分隔的上下文是不相关的。这允许有效的训练,而不需要任何特殊的序列特异性掩蔽。
C Details of Test Set Contamination Studies

我们尝试通过搜索本工作中使用的所有测试/开发集与训练数据之间的 13 13 13−gram 重叠来从训练数据中删除出现在基准测试中的文本,并且删除了冲突的 13 13 13−gram 及其周围的 200 个字符窗口,将原始文档分割成多个部分。出于过滤目的,将 gram 定义为小写、空格分隔的单词,不带标点符号。长度少于 200 个字符的片段将被丢弃。分割成 10 多份的文件被认为受到污染并被完全删除。
最初,在一次重叠测试时删除了整个文档,但这过度惩罚了长文档,例如把整本书籍当成负样本。负样本的一个例子可能是基于维基百科的测试集,其中维基百科的文章引用了书中的一行。忽略了与 10 多个训练文档相匹配的 13-gram,因为检查显示其中大多数包含常见的文化短语、法律样板或可能确实希望模型学习的类似内容,而不是与测试集不期望的特定重叠。
在第 4 节中的基准重叠分析中,使用可变数量的单词 N N N 来检查每个数据集的重叠,其中 N N N 是单词的第 5 百分位示例长度,忽略所有标点符号、空格和大小写。由于在 N N N 值较低时出现虚假碰撞,在非合成任务上使用最小值为 8 。出于性能原因,我们为所有任务的 N N N 设置最大值为 13 。与 GPT-2 使用 bloom 过滤器来计算测试污染的概率边界不同,使用 Apache Spark 来计算所有训练集和测试集之间的精确碰撞。计算测试集和完整训练语料库之间的重叠,即使只对过滤掉 40% 的 Common Crawl 数据集进行了训练。
作者定义 “脏” 的示例定义为:与任何训练文档有任何 N N N-gram 重叠的示例,将 “干净” 示例定义为没有重叠的示例。尽管一些测试部分没有标记,但测试和验证部分具有相似的污染水平。由于此分析揭示了一个错误,上述过滤方法在书籍等长文档上失败。出于成本考虑,在训练数据集的校正版本上重新训练模型是不可行的。因此,几个语言建模基准加上 Children’s Book Test 几乎完全重叠,因此未包含在本文中。
为了了解看到一些数据对模型执行下游任务有多大帮助,按 ”脏度“ 过滤每个验证和测试集。然后,对仅干净的示例进行评估,并报告干净分数与原始分数之间的相对百分比变化。如果干净得分比总体得分差 1% 或 2% 以上,则表明模型可能对其所看到的示例过度拟合。如果干净的分数明显更好,我们的过滤方案可能会优先将更容易的示例标记为脏的。
在过滤过程(除了文字扰乱任务)中,对于包含从网络(例如 SQuAD 数据集,取自维基百科)的背景信息(但不是答案)或长度小于 8 个单词的示例的数据集,此重叠指标往往会显示较高的误报率。这种技术似乎无法给出良好信号的一个例子是 DROP 数据集,这是一项阅读理解任务,其中 94% 的示例都是 “脏” 的。回答问题所需的信息位于提供给模型的段落中,因此在训练期间看到该段落但没有看到问题和答案并不构成作弊。我们确认每个匹配的训练文档仅包含源段落,而不包含数据集中的任何问题和答案。对于性能下降的更可能的解释是,过滤后剩下的 6% 的示例的分布与 “脏” 示例的分布略有不同。
D Total Compute Used to Train Language Models

从右侧开始向左移动,从每个模型训练所用的训练 token 的数量开始。由于 T5 使用编码器-解码器模型,因此在前向传播或后向传播期间,每个 token 只有一半参数处于活动状态。然后我们注意到,每个 token 都涉及前向传递中每个活动参数的一次加法和一次乘法。结合前两个数字,得到每个参数的总失败次数每个 token 。将此值乘以总训练令牌和总参数,以得出训练期间使用的总失败次数。报告失败次数和 petaflop/s-day(每个都是 8.64e+19 次失败)。
相关文章:
【论文笔记】Language Models are Few-Shot Learners
Language Models are Few-Shot Learners 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm)&a…...

解决:Glide 在回调中再次加载图片报错
一、问题说明 Glide 加载图片时监听了回调,并在失败时再次加载其它图片后报错。 代码: Glide.with(mContext).load(imgTeacher).listener(new RequestListener<Drawable>() {Overridepublic boolean onLoadFailed(Nullable GlideException e, O…...

Java学习笔记之IDEA的安装与下载以及相关配置
1 IDEA概述 IDEA全称IntelliJ IDEA,是用于Java语言开发的集成环境,它是业界公认的目前用于Java程序开发最好的工具。 集成环境: 把代码编写,编译,执行,调试等多种功能综合到一起的开发工具。 2 IDEA…...
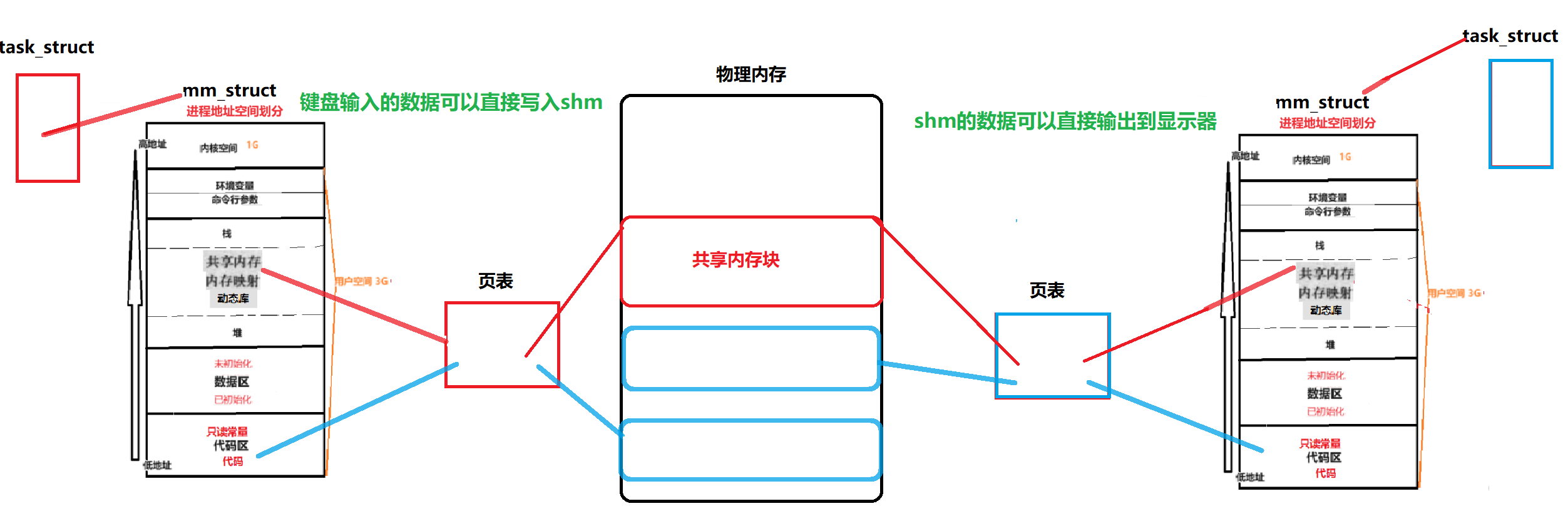
【共享内存】System V共享内存{通信原理/相关接口/代码测试}
文章目录 1.初识共享内存1.0浅谈System V1.1什么是共享内存?1.2Linux-System V共享内存1.3图解共享内存1.4对共享内存的理解 2.创建共享内存2.1共享内存如何创建?2.2代码运行与测试2.3shm与pipe的区别2.4shm缺乏访问控制 3.代码理解shm3.1Log.hpp3.2comm…...
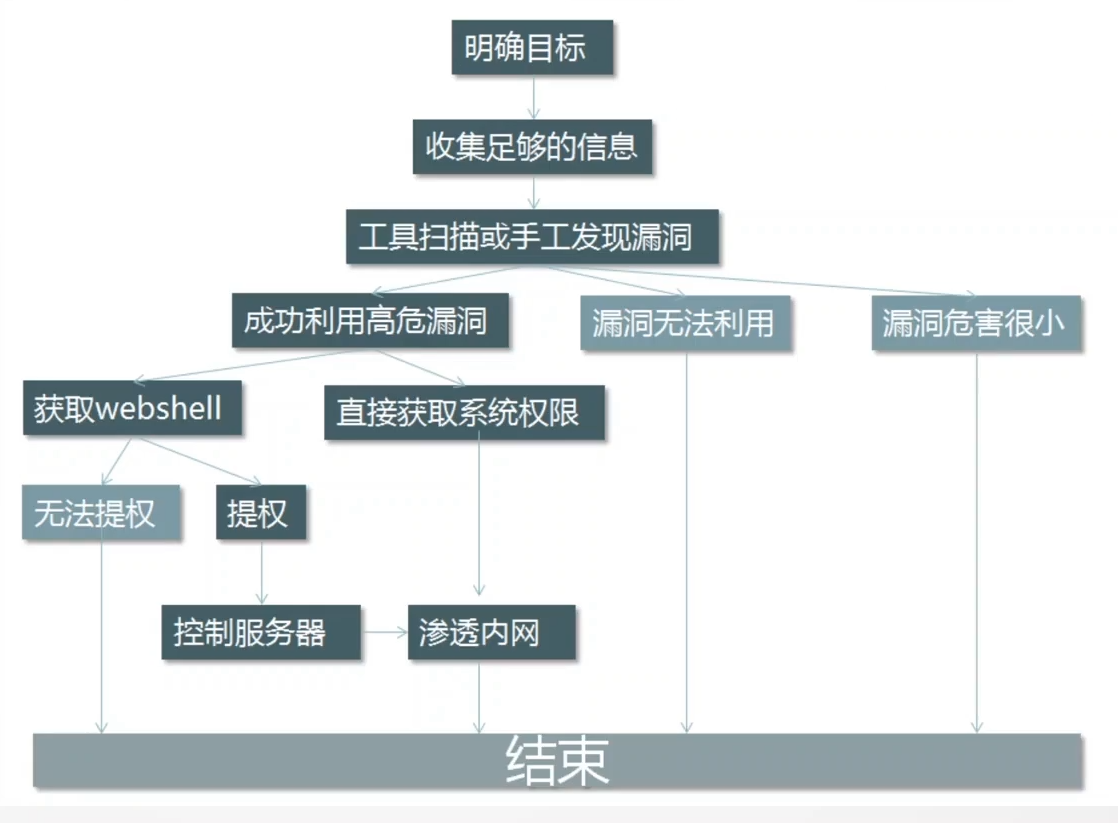
Web渗透测试流程
什么是渗透测试 渗透测试 (penetration test),是通过模拟恶意黑客的攻击方法,来评估计算机网络系统安全的一种评估方法。这个过程包括对系统的任何弱点、技术缺陷或漏洞的主动分析,这个分析是从一个攻击者可能存在的位置来进行的,并且从这个…...

探索机器学习的无限可能性:从初学者到专家的旅程
探索机器学习的无限可能性:从初学者到专家的旅程 在当今数字时代,机器学习无疑是最引人注目的技术之一。它已经深入到我们生活的方方面面,从个性化推荐到自动驾驶汽车,再到医疗诊断和金融预测。但是,即使我们已经见证…...
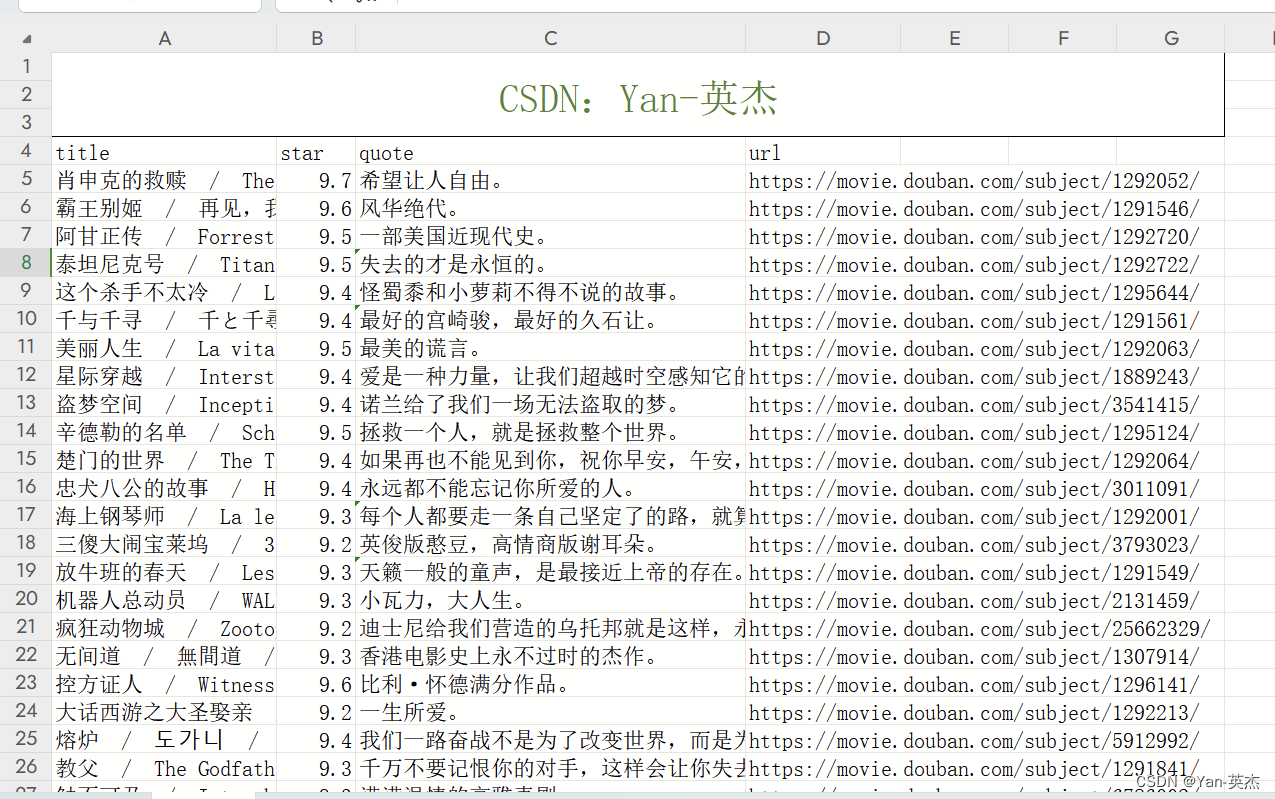
【python】六个常见爬虫案例【附源码】
大家好,我是博主英杰,整理了几个常见的爬虫案例,分享给大家,适合小白学习 一、爬取豆瓣电影排行榜Top250存储到Excel文件 近年来,Python在数据爬取和处理方面的应用越来越广泛。本文将介绍一个基于Python的爬虫程序&a…...
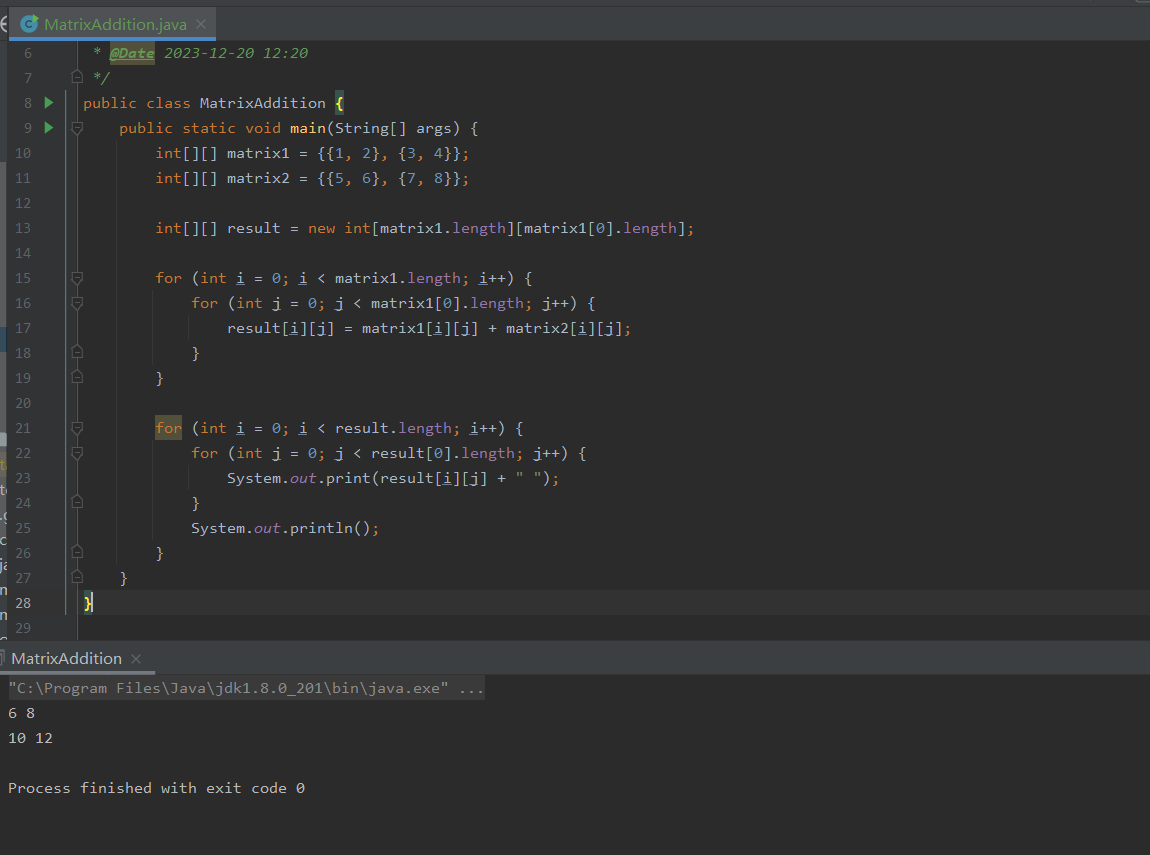
Java零基础-多维数组
哈喽,各位小伙伴们,你们好呀,我是喵手。 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。 我是一名后…...
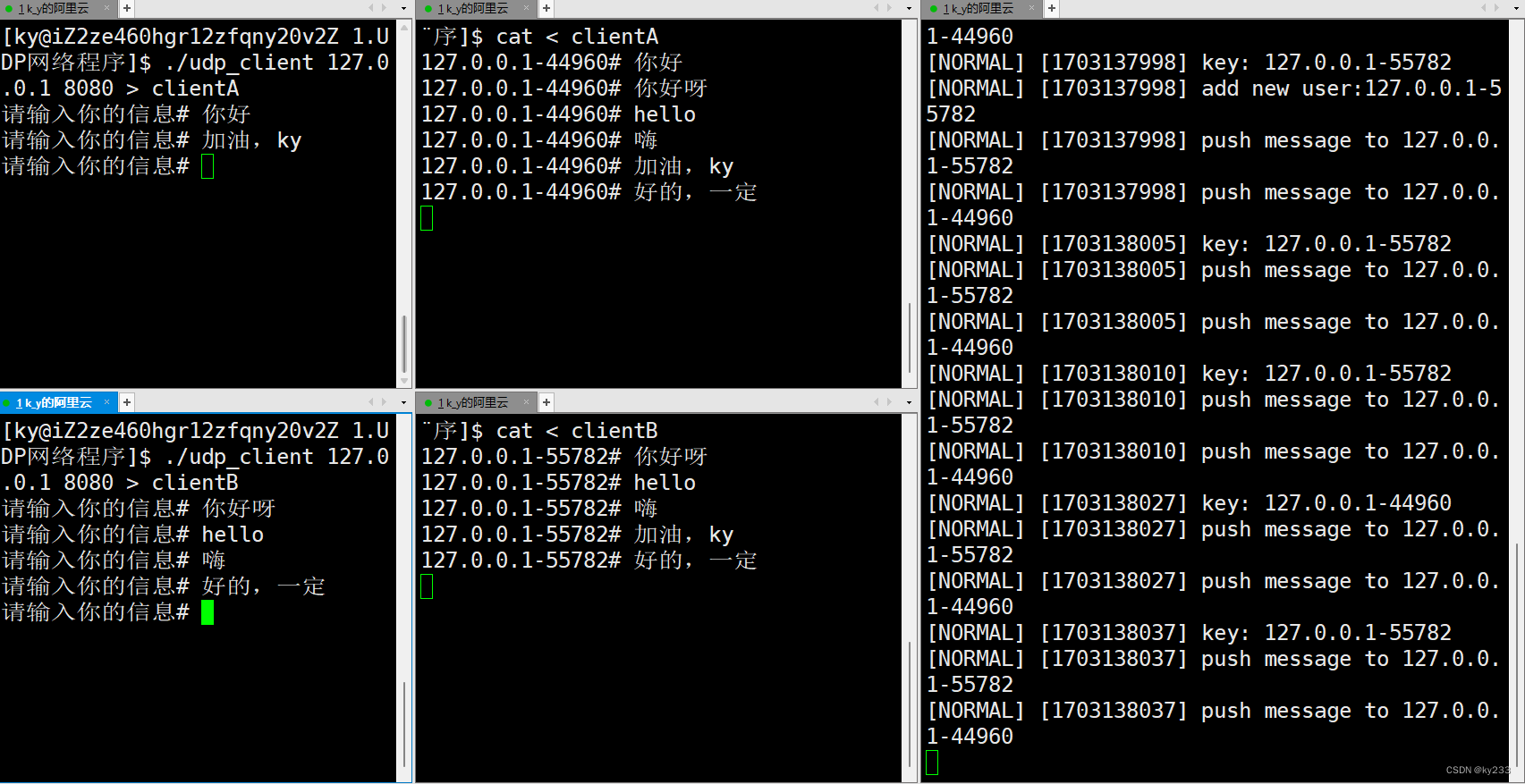
Linux网络套接字之UDP网络程序
(。・∀・)ノ゙嗨!你好这里是ky233的主页:这里是ky233的主页,欢迎光临~https://blog.csdn.net/ky233?typeblog 点个关注不迷路⌯▾⌯ 实现一个简单的对话发消息的功能! 目录…...
Apache POI 解析和处理Excel
摘要:由于开发需要批量导入Excel中的数据,使用了Apache POI库,记录下使用过程 1. 背景 Java 中操作 Excel 文件的库常用的有Apache POI 和阿里巴巴的 EasyExcel 。Apache POI 是一个功能比较全面的 Java 库,适合处理复杂的 Offi…...

SQL 注入攻击 - insert注入
环境准备:构建完善的安全渗透测试环境:推荐工具、资源和下载链接_渗透测试靶机下载-CSDN博客 一、注入原理 描述:insert注入是指通过前端注册的信息被后台通过insert操作插入到数据库中。如果后台没有做相应的处理,就可能导致insert注入漏洞。原因:后台未对用户输入进行充…...

第一个 Angular 项目 - 添加路由
第一个 Angular 项目 - 添加路由 前置项目是 第一个 Angular 项目 - 添加服务,之前的切换页面使用的是 ngIf 对渲染的组件进行判断,从而完成渲染。这一步的打算是添加路由,同时添加 edit recipe 的功能(同样通过路由实现) 用到的内容为&…...

如何简洁高效的搭建一个SpringCloud2023的maven工程
前言 依赖管理有gradle和maven,在这里选择比较常用和方便的Maven作为工程项目和依赖管理工具来搭建SpringCloud实战工程。主要用到的maven管理方式是多模块和bom依赖管理。 什么是maven的多模块依赖管理 Maven 多模块项目相对于单模块项目而言,依赖是…...

uniapp直接连接wifi(含有ios和安卓的注意事项)
前言 小程序中直接连接wifi-----微信小程序 代码 启动 //启动wifistartWifi() {return new Promise((resolve, reject) > {uni.startWifi({success: (res) > {console.log(启动wifi 成功, res)resolve(true)},fail: (err) > {console.error(启动wifi 失败, err)uni.s…...

一. Ubuntu入门
目录 一. Ubuntu系统安装 1. 安装虚拟机软件VMware 2. 安装Ubuntu操作系统 二. Ubuntu系统入门 1. Shell操作 1.1 Shell 简介 1.2 Shell基本操作 1.3 常用Shell命令 (1) 目录信息查看命令ls (2) 目录切换命令cd (3) 当前路径显示命令pwd (4) 系统信息查看命令uname…...

rk3568 Android12 增加支持 ntfs 格式
rk3568 Android12 增加支持 ntfs 格式 Windows平台上可移动硬盘支持 NTFS,FAT32,exFAT三种格式。Fat32文件格式是一种通用格式,任何USB存储设备都会预装该文件系统,可以在任何操作系统平台上使用。最主要的缺陷是只支持最大单文件大小容量为4GB,因此日常使用没有问题,只有…...

【MapReduce】02.Hadoop序列化
实现bean对象序列化步骤 自定义bean对象实现序列化接口。 1)必须实现Writable接口 2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造 public FlowBean(){super(); } 3)重写序列化方法 Override public …...

【Claude 3】一文谈谈Anthropic(Claude) 亚马逊云科技(Bedrock)的因缘际会
文章目录 前言1. Anthropic的诞生2. Anthropic的“代表作”——Claude 3的“三驾马车”3. 亚马逊云科技介绍4. 强大的全托管服务平台——Amazon Bedrock5. 亚马逊云科技(AWS)和Anthropic的联系6. Claude 3模型与Bedrock托管平台的关系7. Clude 3限时体验入口分享【⚠️截止3月1…...

c#开发100问?
什么是C#?C#是由谁开发的?C#与Java之间有哪些相似之处?C#与C有哪些不同之处?C#的主要特性是什么?请解释C#中的类和对象。C#中的命名空间是什么?什么是C#中的属性和字段?请解释C#中的继承和多态性…...

回归预测 | Matlab实现BiTCN-BiGRU-Attention双向时间卷积双向门控循环单元融合注意力机制多变量回归预测
回归预测 | Matlab实现BiTCN-BiGRU-Attention双向时间卷积双向门控循环单元融合注意力机制多变量回归预测 目录 回归预测 | Matlab实现BiTCN-BiGRU-Attention双向时间卷积双向门控循环单元融合注意力机制多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.M…...
)
野火STM32H743XIH6+TouchGFX实战:七寸屏从零点亮到GUI设计全流程(附SDRAM避坑指南)
野火STM32H743XIH6TouchGFX实战:从硬件搭建到GUI设计的全流程解析 在嵌入式系统开发中,图形用户界面(GUI)的实现往往是最具挑战性的环节之一。野火STM32H743XIH6开发板搭配TouchGFX框架,为开发者提供了一套高性能的GUI解决方案。本文将带你从…...

STC32G144K246做多协议网关?用FreeRTOS管理CAN-FD和USART的实战思路
STC32G144K246多协议网关实战:FreeRTOS下的CAN-FD与USART协同设计 工业现场的数据孤岛问题一直是自动化系统的痛点。不同厂商的设备可能采用Modbus、CANopen等异构协议,而STC32G144K246凭借其双CAN-FD接口和八组USART的硬件配置,配合FreeRTOS…...

终极指南:如何用ChemCrow AI助手在5分钟内完成复杂化学分析
终极指南:如何用ChemCrow AI助手在5分钟内完成复杂化学分析 【免费下载链接】chemcrow-public Chemcrow 项目地址: https://gitcode.com/gh_mirrors/ch/chemcrow-public ChemCrow是一个基于大语言模型的化学智能助手,通过整合12种专业化学工具&am…...

技术深度评测:PPTist如何重塑Web端演示文稿创作体验
技术深度评测:PPTist如何重塑Web端演示文稿创作体验 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for …...
)
从入门到精通:CST中WCS坐标系与Pick功能的完整指南(含参数化建模实例)
从入门到精通:CST中WCS坐标系与Pick功能的完整指南(含参数化建模实例) 在电磁仿真领域,CST Studio Suite作为行业标杆工具,其建模效率直接决定了整个设计流程的顺畅程度。而WCS(工作坐标系)和Pi…...

大模型学习-python基础Day6
一.文件操作文件是存储在磁盘上的数据集合。文件可以包含各种类型的数据,如文本、图像、音频等等。文件系统通过文件名和文件路径来定位和管理文件。文件名通常包含文件的名称和和扩展名。文件路径可以是绝对路径也可以是相对路径。1.文件的分类纯文本文件ÿ…...

老旧Mac焕发新生:OpenCore Legacy Patcher完整使用指南
老旧Mac焕发新生:OpenCore Legacy Patcher完整使用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹果官方抛弃的老旧Mac&…...

LinkSwift:2025年最实用的网盘直链下载助手完整指南
LinkSwift:2025年最实用的网盘直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

从光学特性到算法实现:深度解析Shading校正技术
1. 什么是Shading现象? 当你用手机拍摄一张纯色背景的照片时,有没有发现画面四角总是比中心暗一些?这就是典型的Luma Shading现象。专业相机镜头拍出来的照片边缘经常会出现暗角,而手机摄像头则更容易出现边缘偏色问题,…...

Chord视频理解工具实战:一键部署,轻松实现视频目标定位与追踪
Chord视频理解工具实战:一键部署,轻松实现视频目标定位与追踪 1. 工具概览与核心能力 Chord视频时空理解工具是一款基于Qwen2.5-VL架构开发的本地智能视频分析解决方案。它突破了传统图像处理的局限,能够理解视频中的时空关系,实…...