Pytorch可形变卷积分类模型与可视化
E:.
│ archs.py
│ dataset.py
│ deform_conv_v2.py
│ train.py
│ utils.py
│ visual_net.py
│
├─grad_cam
│ 2.png
│ 3.png
│
├─image
│ ├─1
│ │ 154.png
│ │ 2.png
│ │
│ ├─2
│ │ 143.png
│ │ 56.png
│ │
│ └─3
│ 13.png
│
├─models
│ └─ScaledMNISTNet_wDCNv2_c3-4
│ args.pkl
│ args.txt
│ log.csv
│ model.pth
│
└─__pycache__archs.cpython-36.pycdataset.cpython-36.pycdeform_conv_v2.cpython-36.pycutils.cpython-36.pyc
主函数(train.py)
import os
import argparse
import numpy as np
from tqdm import tqdm
import pandas as pd
import joblib
from collections import OrderedDict
from datetime import datetimeimport torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasetsfrom utils import *
from dataset import train_get_loader, test_get_loader
import archs as archsarch_names = archs.__dict__.keys()def parse_args():parser = argparse.ArgumentParser()parser.add_argument('--name', default=None,help='model name: (default: arch+timestamp)')parser.add_argument('--trainData', default=r"image",help='train datasets: (default: image)')parser.add_argument('--testData', default=r"image",help='test datasets: (default: image)')parser.add_argument('--batch_size', default=1, type=int,help='batch number: (default: 4)')parser.add_argument('--arch', '-a', metavar='ARCH', default='ScaledMNISTNet',choices=arch_names,help='model architecture: ' +' | '.join(arch_names) +' (default: ScaledMNISTNet)')parser.add_argument('--deform', default=True, type=str2bool,help='use deform conv')parser.add_argument('--modulation', default=True, type=str2bool,help='use modulated deform conv')parser.add_argument('--min-deform-layer', default=3, type=int,help='minimum number of layer using deform conv')parser.add_argument('--epochs', default=100, type=int, metavar='N',help='number of total epochs to run')parser.add_argument('--optimizer', default='SGD',choices=['Adam', 'SGD'],help='loss: ' +' | '.join(['Adam', 'SGD']) +' (default: Adam)')parser.add_argument('--lr', '--learning-rate', default=1e-2, type=float,metavar='LR', help='initial learning rate')parser.add_argument('--momentum', default=0.5, type=float,help='momentum')parser.add_argument('--weight-decay', default=1e-4, type=float,help='weight decay')parser.add_argument('--nesterov', default=False, type=str2bool,help='nesterov')args = parser.parse_args()return argsdef train(args, train_loader, model, criterion, optimizer, epoch, scheduler=None):losses = AverageMeter()scores = AverageMeter()model.train()accumulation_steps = 4for i, (input, target) in tqdm(enumerate(train_loader), total=len(train_loader)):input = input.cuda()target = target.cuda()output = model(input)loss = criterion(output, target)loss = loss / accumulation_stepsloss.backward()acc = accuracy(output, target)[0]losses.update(loss.item(), input.size(0))scores.update(acc.item(), input.size(0))# compute gradient and do optimizing stepif (i+1)%accumulation_steps==0:optimizer.step()optimizer.zero_grad()log = OrderedDict([('loss', losses.avg),('acc', scores.avg),])return logdef validate(args, val_loader, model, criterion):losses = AverageMeter()scores = AverageMeter()# switch to evaluate modemodel.eval()with torch.no_grad():for i, (input, target) in tqdm(enumerate(val_loader), total=len(val_loader)):input = input.cuda()target = target.cuda()output = model(input)loss = criterion(output, target)acc = accuracy(output, target)[0]losses.update(loss.item(), input.size(0))scores.update(acc.item(), input.size(0))log = OrderedDict([('loss', losses.avg),('acc', scores.avg),])return logdef main():args = parse_args()if args.name is None:args.name = '%s' %args.archif args.deform:args.name += '_wDCN'if args.modulation:args.name += 'v2'args.name += '_c%d-4' %args.min_deform_layerif not os.path.exists('models/%s' %args.name):os.makedirs('models/%s' %args.name)print('Config -----')for arg in vars(args):print('%s: %s' %(arg, getattr(args, arg)))print('------------')with open('models/%s/args.txt' %args.name, 'w') as f:for arg in vars(args):print('%s: %s' %(arg, getattr(args, arg)), file=f)joblib.dump(args, 'models/%s/args.pkl' %args.name)criterion = nn.CrossEntropyLoss().cuda()cudnn.benchmark = Truetrain_set = train_get_loader(args.trainData, args.batch_size)test_set = test_get_loader(args.testData, args.batch_size)num_classes = 3# create modelmodel = archs.__dict__[args.arch](args.deform, args.min_deform_layer, args.modulation, num_classes)model = model.cuda()print(model)if args.optimizer == 'Adam':optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=args.lr)elif args.optimizer == 'SGD':optimizer = optim.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=args.lr,momentum=args.momentum, weight_decay=args.weight_decay, nesterov=args.nesterov)log = pd.DataFrame(index=[], columns=['epoch', 'lr', 'loss', 'acc', 'val_loss', 'val_acc'])best_acc = 0for epoch in range(args.epochs):print('Epoch [%d/%d]' %(epoch, args.epochs))# train for one epochtrain_log = train(args, train_set, model, criterion, optimizer, epoch)# evaluate on validation setval_log = validate(args, test_set, model, criterion)print('loss %.4f - acc %.4f - val_loss %.4f - val_acc %.4f'%(train_log['loss'], train_log['acc'], val_log['loss'], val_log['acc']))tmp = pd.Series([epoch,1e-1,train_log['loss'],train_log['acc'],val_log['loss'],val_log['acc'],], index=['epoch', 'lr', 'loss', 'acc', 'val_loss', 'val_acc'])log = log.append(tmp, ignore_index=True)log.to_csv('models/%s/log.csv' %args.name, index=False)if train_log['acc'] >= best_acc:torch.save(model.state_dict(), 'models/%s/model.pth' %args.name)best_acc = train_log['acc']print("=> saved best model")print("best val_acc: %f" %best_acc)if __name__ == '__main__':main()加载数据(dataset.py)
from torchvision import transforms
from torch.utils.data import Dataset
from torch.utils import data
import cv2
import numpy as np
import imgaug.augmenters as iaa
import os
from PIL import Imagesometimes = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential([iaa.Fliplr(0.5), # 对50%的图像进行上下翻转iaa.Flipud(0.5), # 对50%的图像做镜像翻转#OneOf中选一种算术运算sometimes(iaa.OneOf([iaa.Multiply(mul=(0.8,1.2),per_channel=False), # 像素相乘系数iaa.Add(value=(-20,20),per_channel=False), # 像素加减iaa.Cutout(size=0.2), # 随机裁剪区域,使用灰度填充0.05为比例iaa.Dropout(p=(0.0, 0.5), per_channel=False) # 随机移除几个区域,用黑色填充])),#OneOf中选一种形状变化sometimes(iaa.OneOf([iaa.Affine( scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},#图像缩放为80%到120%之间translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}, #平移±20rotate=(-5, 5), #旋转±45度之间shear=(-5, 5), #剪切变换±16度,(矩形变平行四边形)order=[0, 1], #使用最邻近差值或者双线性差值cval=(0, 255), #全白全黑填充mode="edge", #定义填充图像外区域的方法fit_output=False,#是否保持边缘丢失),iaa.PiecewiseAffine(scale=(0,0.04)), #局部仿射变换iaa.ElasticTransformation(alpha=(0,40),sigma=(4,8)), #使用位移场移动像素变换iaa.PerspectiveTransform(scale=(0,0.06)) #随机四点透视变换])),#OneOf中选一种模糊方法sometimes(iaa.OneOf([iaa.GaussianBlur(sigma=2.0), # 高斯模糊iaa.AverageBlur(k=(2, 7)), # 均值模糊iaa.MedianBlur(k=(3, 11)), # 种植模糊iaa.MotionBlur(k=(3, 7), angle=(0, 360)) # 运动模糊])),#OneOf中选一种边缘方法sometimes(iaa.OneOf([iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)),iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)),iaa.EdgeDetect(alpha=(0,0.75)),iaa.DirectedEdgeDetect(alpha=(0, 0.7), direction=(0.0, 1.0))# 增强特定方向上的边缘])),#OneOf中选一种对比度增强方法sometimes(iaa.OneOf([iaa.HistogramEqualization(), #直方图均衡iaa.GammaContrast(gamma=(0.7, 1.7)), #使用伽马函数改变对比度iaa.SigmoidContrast(gain=(5,6)), #使用sigmoid函数改变对比度iaa.AllChannelsCLAHE(clip_limit=(0.1,8)) #对比受限的自适应直方图])),],random_order=True # 随机的顺序把这些操作用在图像上
)"""Custom Dataset compatible with prebuilt DataLoader."""
class Dataset(Dataset):def __init__(self, ImgDir, transform):self.image_paths = []for root,dirs,files in os.walk(ImgDir):for fs in files:if fs.endswith(".png"):self.image_paths.append(os.path.join(root, fs)) self.image_paths.sort()self.transform = transformdef __getitem__(self, index):"""Reads an image from a file and preprocesses it and returns."""image_path = self.image_paths[index]image = np.array(Image.open(image_path).convert("RGB").resize((256,256)))image = seq.augment_image(image)image = image.copy()label = int(image_path.rsplit("\\",3)[1])-1if self.transform is not None:trans_image = self.transform(image)trans_label = labelelse:trans_image = imagetrans_label = labelreturn trans_image, trans_labeldef __len__(self):"""Returns the total number of image files."""return len(self.image_paths)def train_get_loader(ImgDir, batch_size):"""Builds and returns Dataloader."""transform = transforms.Compose([transforms.ToTensor()])dataset = Dataset(ImgDir, transform)data_loader = data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=0)return data_loaderdef test_get_loader(ImgDir, batch_size):"""Builds and returns Dataloader."""transform = transforms.Compose([transforms.ToTensor()])dataset = Dataset(ImgDir, transform)data_loader = data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=0)return data_loader模型结构(archs.py)
# -*- coding: utf-8 -*-
import numpy as np
from torch import nn
from torch.nn import functional as Ffrom deform_conv_v2 import *class ScaledMNISTNet(nn.Module):def __init__(self, deform, min_deform_layer, modulation, num_classes):super().__init__()self.relu = nn.ReLU(inplace=True)self.pool = nn.MaxPool2d((2, 2))self.avg_pool = nn.AdaptiveAvgPool2d(1)features = []inplanes = 3outplanes = 32for i in range(6):if deform and min_deform_layer <= i+1:features.append(DeformConv2d(inplanes, outplanes, 3, padding=1, bias=False, modulation=modulation))else:features.append(nn.Conv2d(inplanes, outplanes, 3, padding=1, bias=False))features.append(nn.BatchNorm2d(outplanes))features.append(self.relu)if i < 5:features.append(self.pool)inplanes = outplanesoutplanes *= 2self.features = nn.Sequential(*features)self.fc = nn.Linear(1024, num_classes)def forward(self, input):x = self.features(input)x = self.avg_pool(x)x = x.view(x.shape[0], -1)output = self.fc(x)return output
可形变卷积结构(deform_conv_v2.py)
import torch
from torch import nnclass DeformConv2d(nn.Module):def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):"""Args:modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2)."""super(DeformConv2d, self).__init__()self.kernel_size = kernel_sizeself.padding = paddingself.stride = strideself.zero_padding = nn.ZeroPad2d(padding)self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.p_conv.weight, 0)self.p_conv.register_backward_hook(self._set_lr)self.modulation = modulationif modulation:self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.m_conv.weight, 0)self.m_conv.register_backward_hook(self._set_lr)@staticmethoddef _set_lr(module, grad_input, grad_output):grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))def forward(self, x):offset = self.p_conv(x)if self.modulation:m = torch.sigmoid(self.m_conv(x))dtype = offset.data.type()ks = self.kernel_sizeN = offset.size(1) // 2if self.padding:x = self.zero_padding(x)# (b, 2N, h, w)p = self._get_p(offset, dtype)# (b, h, w, 2N)p = p.contiguous().permute(0, 2, 3, 1)q_lt = p.detach().floor()q_rb = q_lt + 1q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)# clip pp = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)# bilinear kernel (b, h, w, N)g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))# (b, c, h, w, N)x_q_lt = self._get_x_q(x, q_lt, N)x_q_rb = self._get_x_q(x, q_rb, N)x_q_lb = self._get_x_q(x, q_lb, N)x_q_rt = self._get_x_q(x, q_rt, N)# (b, c, h, w, N)x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \g_rb.unsqueeze(dim=1) * x_q_rb + \g_lb.unsqueeze(dim=1) * x_q_lb + \g_rt.unsqueeze(dim=1) * x_q_rt# modulationif self.modulation:m = m.contiguous().permute(0, 2, 3, 1)m = m.unsqueeze(dim=1)m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)x_offset *= mx_offset = self._reshape_x_offset(x_offset, ks)out = self.conv(x_offset)return outdef _get_p_n(self, N, dtype):p_n_x, p_n_y = torch.meshgrid(torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))# (2N, 1)p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)p_n = p_n.view(1, 2*N, 1, 1).type(dtype)return p_ndef _get_p_0(self, h, w, N, dtype):p_0_x, p_0_y = torch.meshgrid(torch.arange(1, h*self.stride+1, self.stride),torch.arange(1, w*self.stride+1, self.stride))p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)return p_0def _get_p(self, offset, dtype):N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)# (1, 2N, 1, 1)p_n = self._get_p_n(N, dtype)# (1, 2N, h, w)p_0 = self._get_p_0(h, w, N, dtype)p = p_0 + p_n + offsetreturn pdef _get_x_q(self, x, q, N):b, h, w, _ = q.size()padded_w = x.size(3)c = x.size(1)# (b, c, h*w)x = x.contiguous().view(b, c, -1)# (b, h, w, N)index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y# (b, c, h*w*N)index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)return x_offset@staticmethoddef _reshape_x_offset(x_offset, ks):b, c, h, w, N = x_offset.size()x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)return x_offset计算配置函数(utils.py)
import random
import math
from PIL import Image
import numpy as npimport torchdef str2bool(v):if v.lower() in ['true', 1]:return Trueelif v.lower() in ['false', 0]:return Falseelse:assert('Boolean value expected.')def count_params(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)class AverageMeter(object):"""Computes and stores the average and current value"""def __init__(self):self.reset()def reset(self):self.val = 0self.avg = 0self.sum = 0self.count = 0def update(self, val, n=1):self.val = valself.sum += val * nself.count += nself.avg = self.sum / self.countdef accuracy(output, target, topk=(1,)):"""Computes the accuracy over the k top predictions for the specified values of k"""with torch.no_grad():maxk = max(topk)batch_size = target.size(0)_, pred = output.topk(maxk, 1, True, True)pred = pred.t()correct = pred.eq(target.view(1, -1).expand_as(pred))res = []for k in topk:correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)res.append(correct_k.mul_(100.0 / batch_size))return res可视化函数(visual_net.py)
from PIL import Image
import torch
import torchvision.transforms as transforms
import numpy as np
import cv2
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from deform_conv_v2 import *class ScaledMNISTNet(nn.Module):def __init__(self, deform, min_deform_layer, modulation, num_classes):super(ScaledMNISTNet, self).__init__()self.relu = nn.ReLU(inplace=True)self.pool = nn.MaxPool2d((2, 2))self.avg_pool = nn.AdaptiveAvgPool2d(1)features = []inplanes = 3outplanes = 32for i in range(6):if deform and min_deform_layer <= i+1:features.append(DeformConv2d(inplanes, outplanes, 3, padding=1, bias=False, modulation=modulation))else:features.append(nn.Conv2d(inplanes, outplanes, 3, padding=1, bias=False))features.append(nn.BatchNorm2d(outplanes))features.append(self.relu)if i < 5:features.append(self.pool)inplanes = outplanesoutplanes *= 2self.features = nn.Sequential(*features)self.fc = nn.Linear(1024, num_classes)def forward(self, input):x = self.features(input)x = self.avg_pool(x)x = x.view(x.shape[0], -1)output = self.fc(x)return outputdef kernel_inv_map(vis_attr, target_point, map_h, map_w):pos_shift = [vis_attr['dilation'] * 0 - vis_attr['pad'],vis_attr['dilation'] * 1 - vis_attr['pad'],vis_attr['dilation'] * 2 - vis_attr['pad']]source_point = []for idx in range(vis_attr['filter_size']**2):cur_source_point = np.array([target_point[0] + pos_shift[idx // 3],target_point[1] + pos_shift[idx % 3]])if cur_source_point[0] < 0 or cur_source_point[1] < 0 \or cur_source_point[0] > map_h - 1 or cur_source_point[1] > map_w - 1:continuesource_point.append(cur_source_point.astype('f'))return source_pointdef offset_inv_map(source_points, offset):for idx, _ in enumerate(source_points):source_points[idx][0] += offset[2*idx]source_points[idx][1] += offset[2*idx + 1]return source_pointsdef get_bottom_position(vis_attr, top_points, all_offset):map_h = all_offset[0].shape[2]map_w = all_offset[0].shape[3]for level in range(vis_attr['plot_level']):source_points = []for idx, cur_top_point in enumerate(top_points):cur_top_point = np.round(cur_top_point)if cur_top_point[0] < 0 or cur_top_point[1] < 0 \or cur_top_point[0] > map_h-1 or cur_top_point[1] > map_w-1:continuecur_source_point = kernel_inv_map(vis_attr, cur_top_point, map_h, map_w)cur_offset = np.squeeze(all_offset[level][:, :, int(cur_top_point[0]), int(cur_top_point[1])])cur_source_point = offset_inv_map(cur_source_point, cur_offset)source_points = source_points + cur_source_pointtop_points = source_pointsreturn source_pointsdef plot_according_to_point(vis_attr, im, source_points, map_h, map_w, color=[255,0,0]):plot_area = vis_attr['plot_area']for idx, cur_source_point in enumerate(source_points):y = np.round((cur_source_point[0] + 0.5) * im.shape[0] / map_h).astype('i')x = np.round((cur_source_point[1] + 0.5) * im.shape[1] / map_w).astype('i')if x < 0 or y < 0 or x > im.shape[1]-1 or y > im.shape[0]-1:continuey = min(y, im.shape[0] - vis_attr['plot_area'] - 1)x = min(x, im.shape[1] - vis_attr['plot_area'] - 1)y = max(y, vis_attr['plot_area'])x = max(x, vis_attr['plot_area'])im[y-plot_area:y+plot_area+1, x-plot_area:x+plot_area+1, :] = np.tile(np.reshape(color, (1, 1, 3)), (2*plot_area+1, 2*plot_area+1, 1))return imdef show_dconv_offset(im, all_offset, step=[2, 2], filter_size=3,dilation=2, pad=2, plot_area=2, plot_level=2):vis_attr = {'filter_size': filter_size, 'dilation': dilation, 'pad': pad,'plot_area': plot_area, 'plot_level': plot_level}map_h = all_offset[0].shape[2]map_w = all_offset[0].shape[3]step_h = step[0]step_w = step[1]start_h = np.round(step_h // 2)start_w = np.round(step_w // 2)plt.figure()for im_h in range(start_h, map_h, step_h):for im_w in range(start_w, map_w, step_w):target_point = np.array([im_h, im_w])source_y = np.round(target_point[0] * im.shape[0] / map_h)source_x = np.round(target_point[1] * im.shape[1] / map_w)if source_y < plot_area or source_x < plot_area \or source_y >= im.shape[0] - plot_area or source_x >= im.shape[1] - plot_area:continuecur_im = np.copy(im)source_points = get_bottom_position(vis_attr, [target_point], all_offset)cur_im = plot_according_to_point(vis_attr, cur_im, source_points, map_h, map_w)cur_im[int(source_y-plot_area):int(source_y+plot_area+1), int(source_x-plot_area):int(source_x+plot_area+1), :] = \np.tile(np.reshape([0, 255, 0], (1, 1, 3)), (2*plot_area+1, 2*plot_area+1, 1))plt.axis("off")plt.imshow(cur_im)plt.show(block=False)plt.pause(0.01)plt.clf()def draw_CAM(model,img_path,save_path,resize=256,isSave=True,isShow=False):# 图像加载&预处理img=Image.open(img_path).convert('RGB')loader = transforms.Compose([transforms.Resize(size=(resize,resize)),transforms.ToTensor()]) img = loader(img).unsqueeze(0) # unsqueeze(0)在第0维增加一个维度# 获取模型输出的feature/scoremodel.eval() # 测试模式,不启用BatchNormalization和Dropoutfeature=model.features(img)output=model.fc(model.avg_pool(feature).view(1, -1))# 预测得分最高的那一类对应的输出scorepred = torch.argmax(output).item()pred_class = output[:, pred]# 记录梯度值def hook_grad(grad):global feature_gradfeature_grad=gradfeature.register_hook(hook_grad)# 计算梯度pred_class.backward()grads=feature_grad # 获取梯度pooled_grads = torch.nn.functional.adaptive_avg_pool2d(grads, (1, 1)) # adaptive_avg_pool2d自适应平均池化函数,输出大小都为(1,1)# 此处batch size默认为1,所以去掉了第0维(batch size维)pooled_grads = pooled_grads[0] # shape为[batch,通道,size,size],此处batch为1,所以直接取[0]即取第一个batch的元素,就取到了每个batch内的所有元素features = feature[0] # 取【0】原因同上########################## 导数(权重)乘以相应元素for i in range(len(features)):features[i, ...] *= pooled_grads[i, ...]########################### 绘制热力图heatmap = features.detach().numpy()heatmap = np.mean(heatmap, axis=0) # axis=0,对各列求均值,返回1*nheatmap = np.maximum(heatmap, 0)heatmap /= np.max(heatmap)# 可视化原始热力图if isShow:plt.matshow(heatmap)plt.show()img = Image.open(img_path) img = np.array(img)heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0])) # 将热力图的大小调整为与原始图像相同heatmap = np.uint8(heatmap) # 将热力图转换为RGB格式heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) # 将热力图应用于原始图像superimposed_img = heatmap * 0.2 + img # 这里的0.4是热力图强度因子# 将图像保存到硬盘if isSave:superimposed_img = np.array(superimposed_img).astype(np.uint8)superimposed_img = Image.fromarray(superimposed_img)superimposed_img.save(save_path) # 展示图像if isShow:plt.imshow(superimposed_img)def draw_red(model,img_path,save_path,resize=512,isSave=True,isShow=False):# 图像加载&预处理img0=Image.open(img_path).convert('RGB')loader = transforms.Compose([transforms.Resize(size=(resize,resize)),transforms.ToTensor()]) img = loader(img0).unsqueeze(0) # unsqueeze(0)在第0维增加一个维度# 获取模型输出的feature/scoremodel.eval() # 测试模式,不启用BatchNormalization和Dropoutfeature1=model.features[:19](img)feature2=model.features[:15](img)feature3=model.features[:11](img)show_dconv_offset(np.array(img0), [feature1, feature2])model = ScaledMNISTNet(True, 3, True, 3)
print(model)
model.load_state_dict(torch.load(r'.\models\ScaledMNISTNet_wDCNv2_c3-4\model.pth'),strict=False)
draw_red(model,r'.\grad_cam\2.png',r'.\grad_cam\3.png',isSave=True,isShow=True)
draw_CAM(model,r'.\grad_cam\2.png',r'.\grad_cam\3.png',isSave=True,isShow=True)保存目录
image:数据集存放路径。
models:模型存放路径以及日志存放路径。
grad_cam:可视化图存放路径。
相关文章:

Pytorch可形变卷积分类模型与可视化
E:. │ archs.py │ dataset.py │ deform_conv_v2.py │ train.py │ utils.py │ visual_net.py │ ├─grad_cam │ 2.png │ 3.png │ ├─image │ ├─1 │ │ 154.png │ │ 2.png │ │ │ ├─2 │ │ 143.png │…...

Mysql 表逻辑分区原理和应用
MySQL的表逻辑分区是一种数据库设计技术,它允许将一个表的数据分布在多个物理分区中,但在逻辑上仍然表现为一个单一的表。这种方式可以提高查询性能、简化数据管理,并有助于高效地进行大数据量的存储和访问。逻辑分区基于特定的规则ÿ…...

架构面试题汇总:网络协议34问(七)
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 网络协议是实现各种设备和应用程序之间顺畅通信的基石。无论是构建分布式系统、开发Web应用,还是进行网络通信&#x…...

lida,一个超级厉害的 Python 库!
目录 前言 什么是 lida 库? lida 库的安装 基本功能 1. 文本分词 2. 词性标注 3. 命名实体识别 高级功能 1. 情感分析 2. 关键词提取 实际应用场景 1. 文本分类 2. 情感分析 3. 实体识别 总结 前言 大家好,今天为大家分享一个超级厉害的 Python …...

K好数 C语言 蓝桥杯算法提升ALGO3 一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字
问题描述 如果一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数。求L位K进制数中K好数的数目。例如K 4,L 2的时候,所有K好数为11、13、20、22、30、31、33 共7个。由于这个数目很大,请你输…...
2195. 深海机器人问题(网络流,费用流,上下界可行流,网格图模型)
活动 - AcWing 深海资源考察探险队的潜艇将到达深海的海底进行科学考察。 潜艇内有多个深海机器人。 潜艇到达深海海底后,深海机器人将离开潜艇向预定目标移动。 深海机器人在移动中还必须沿途采集海底生物标本。 沿途生物标本由最先遇到它的深海机器人完成采…...

Vue/cli项目全局css使用
第一步:创建css文件 在合适的位置创建好css文件,文件可以是sass/less/stylus...第二步:响预处理器loader传递选项 //摘自官网,引入样式 // vue.config.js module.exports {css: {loaderOptions: {// 给 sass-loader 传递选项sa…...
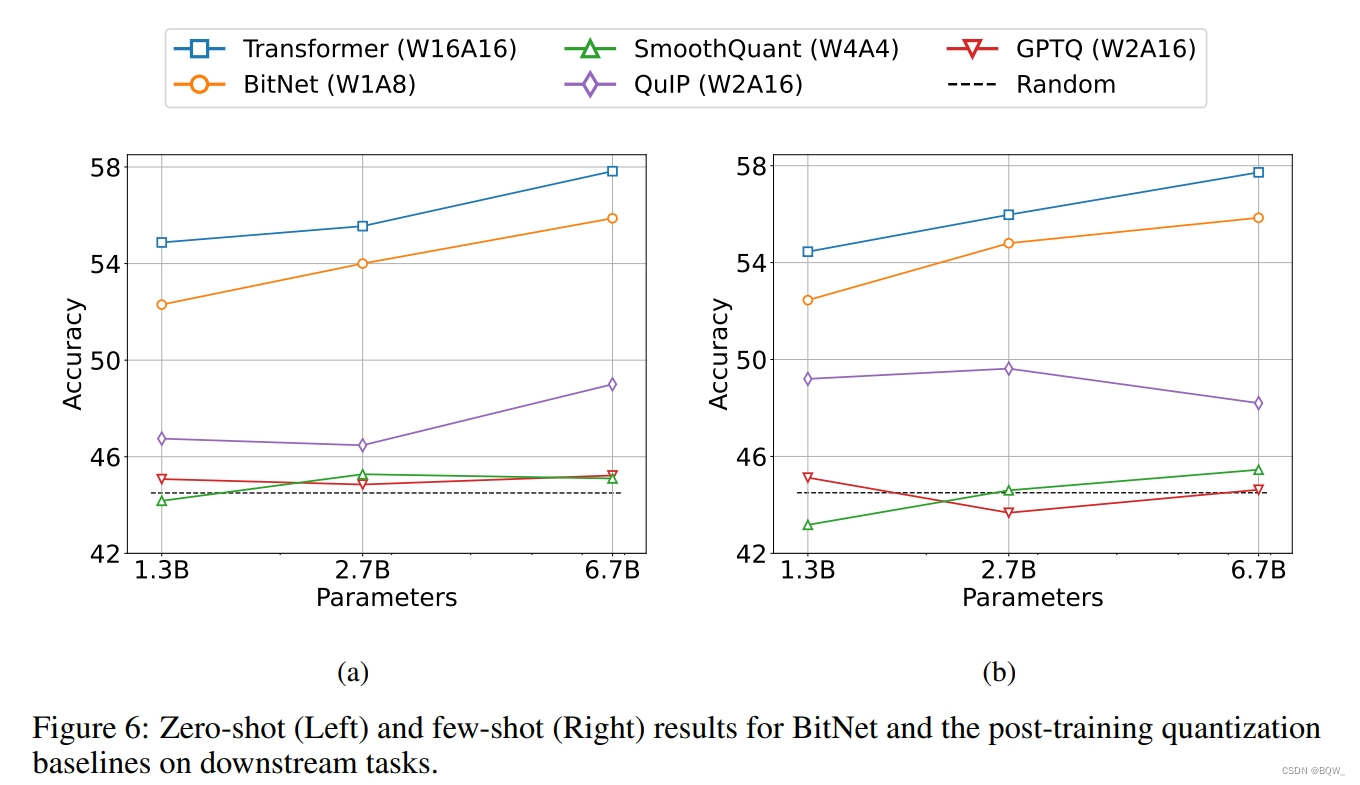
【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM
BitNet:用1-bit Transformer训练LLM 《BitNet: Scaling 1-bit Transformers for Large Language Models》 论文地址:https://arxiv.org/pdf/2310.11453.pdf 相关博客 【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM 【自然语言…...
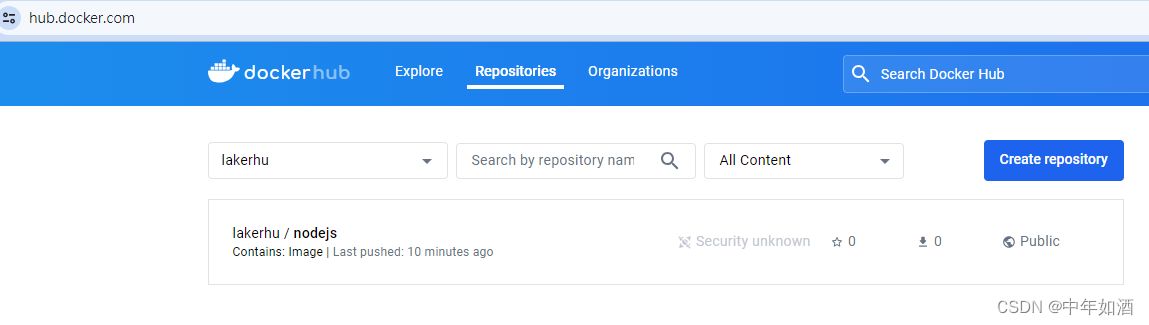
安装及管理docker
文章目录 1.Docker介绍2.Docker安装3.免sudo设置4. 使用docker命令5.Images6.运行docker容器7. 管理docker容器8.创建image9.Push Image 1.Docker介绍 Docker 是一个简化在容器中管理应用程序进程的应用程序。容器让你在资源隔离的进程中运行你的应用程序。类似于虚拟机&#…...
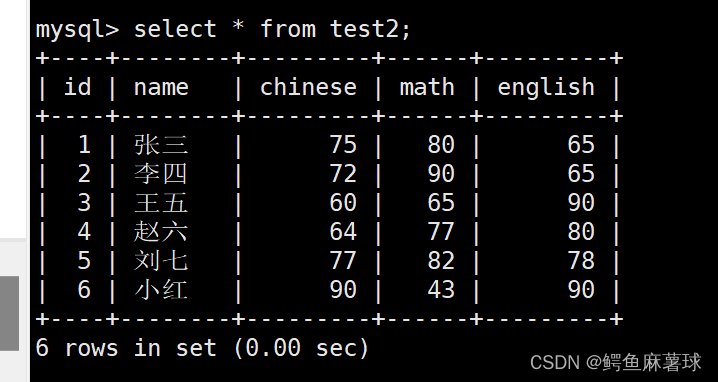
【MySQL】表的增删改查——MySQL基本查询、数据库表的创建、表的读取、表的更新、表的删除
文章目录 MySQL表的增删查改1. Create(创建)1.1 单行插入1.2 多行插入1.3 替换 2. Retrieve(读取)2.1 select查看2.2 where条件2.3 结果排序2.4 筛选分页结果 3. Update(更新)3.1 更新单个数据3.2 更新多个…...

C/C++蓝桥杯之日期问题
问题描述:小明正在整理一批文献,这些文献中出现了很多日期,小明知道这些日期都在1960年1月1日至2059年12月31日之间,令小明头疼的是,这些日期采用的格式非常不统一,有采用年/月/日的,有采用月/日…...

【理解指针(二)】
文章目录 一、指针的运算(1)指针加整数(2)指针减指针(指针关系运算) 二、野指针(1)野指针的成因(1.1)指针未初始化(1.2)指针的越界访问…...

使用AI纠正文章
我写了一段关于哲学自学的读书笔记,处于好奇的目的,让AI帮我纠正语法和逻辑。我的原文如下: 泰勒斯第一次提出了水是万物本源的说法,对于泰勒斯为什么提出这样的观点,或者是这样的观点是怎么来的,我们无从所…...

拼多多API批量获取商品详情信息
随着电子商务的蓬勃发展,淘宝作为中国最大的在线购物平台之一,每天需要处理海量的商品上架和交易。为了提高工作效率,自动化上架商品和批量获取商品详情信息成为了许多商家和开发者的迫切需求。本文将详细介绍淘宝的API接口及其相关技术&…...
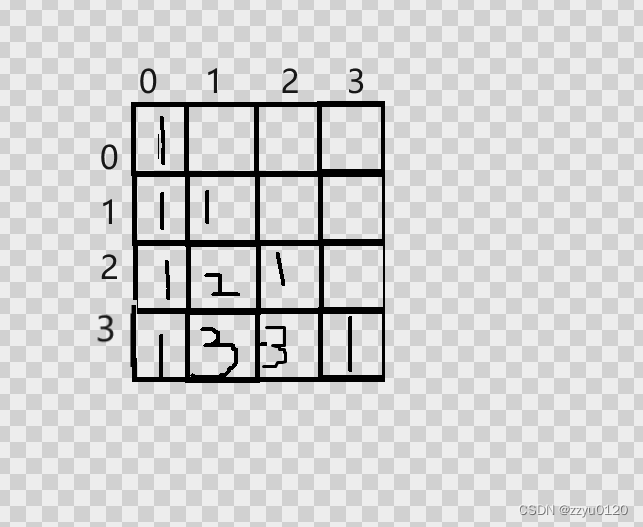
杨辉三角(C语言)
杨辉三角 一.什么是杨辉三角 一.什么是杨辉三角 每个数等于它上方两数之和。 每行数字左右对称,由1开始逐渐变大。 第n行的数字有n项。 前n行共[(1n)n]/2 个数。 … 当前行的数上一行的数上一行的前一列的数 void yanghuisanjian(int arr[][20], int n) {for (int i…...

宏任务与微任务:JavaScript异步编程的秘密
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
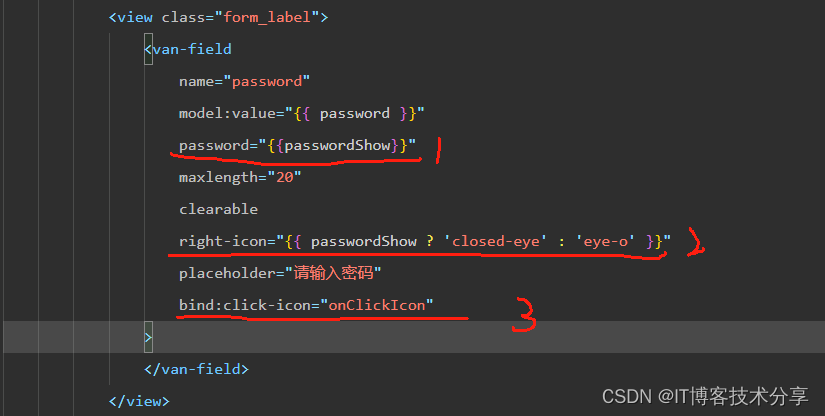
vant van-field 密码输入框小程序里隐藏、显示密码bug总结
老规矩先上效果图: vant 输入框组件 密码的隐藏与显示功能: 注: 用password属性控制密码的显示与隐藏 不要用type属性,type属性在真机上有时会没有效果 1、当然如果只用typepassword 不需要切换显示、隐藏也可以使用。 2、如果用到了密码的显示与…...

代理ip应用场景
代理IP是一种网络技术,它允许用户通过中间来访问互联网资源,隐藏真实的IP地址代理IP的应用场景非常泛,以下是一些常见的应用场景: 1 隐私保护:使用代理IP可以隐藏用户的真实IP地址,保护个人隐私。在浏览网…...

C/C++指针详解
接下来我们来介绍一下什么是指针? 指针其实就是元素存放地址,更加形象的比喻:在酒店中如果你想要去注必须去付费不然不能住,在计算机也同样如此(但是不需要付费哦)每当我们使用一个变量或其他需要申请空间…...

实验一:华为VRP系统的基本操作
1.1实验介绍 1.1.1关于本实验 本实验通过配置华为设备,了解并熟悉华为VRP系统的基本操作 1.1.2实验目的 理解命令行视图的含义以及进入离开命令行视图的方法 掌握一些常见的命令 掌握命令行在线帮助的方法 掌握如何撤销命令 掌握如何使用命令快捷键 1.1.3实验组网 …...

rosenbridge项目工具集完整使用教程:探索x86 CPU硬件后门研究利器
rosenbridge项目工具集完整使用教程:探索x86 CPU硬件后门研究利器 【免费下载链接】rosenbridge Hardware backdoors in some x86 CPUs 项目地址: https://gitcode.com/gh_mirrors/ro/rosenbridge rosenbridge项目是一个专注于x86 CPU硬件后门研究的工具集&a…...

终极Zotero格式化插件:3分钟让你的文献库焕然一新
终极Zotero格式化插件:3分钟让你的文献库焕然一新 【免费下载链接】zotero-format-metadata Linter for Zotero. A plugin for Zotero to format item metadata. Shortcut to set title rich text; set journal abbreviations, university places, and item languag…...

如何彻底解决Mac多窗口遮挡问题?Topit窗口置顶工具深度解析
如何彻底解决Mac多窗口遮挡问题?Topit窗口置顶工具深度解析 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否曾为Mac上频繁切换窗口而烦恼&…...

从JACS到Nature子刊:这些顶级化学期刊的缩写,你写论文时用对了吗?
顶级化学期刊缩写规范指南:从JACS到Nature子刊的精准表达 在学术写作中,期刊名称的缩写错误看似微不足道,实则可能影响稿件的专业形象甚至引发审稿质疑。化学领域尤其特殊——其期刊缩写体系既遵循通用规则,又存在大量历史形成的特…...

奥贝胆酸Obeticholic引起严重瘙痒,对症治疗与剂量调整方案
奥贝胆酸作为法尼醇X受体(FXR)激动剂,在治疗原发性胆汁性胆管炎(PBC)等肝脏疾病方面发挥着重要作用。然而,其引起的严重瘙痒问题给患者带来了极大困扰,严重影响患者的生活质量,甚至可…...

Elasticsearch:快速近似 ES|QL - 第一部分
作者:来自 Elastic Jan Kuipers 及 Thomas Veasey 通过 Elasticsearch 实操:深入了解我们在 Elasticsearch Labs 仓库中的示例 notebooks,开始免费云试用,或者现在就在你的本地机器上试用 Elastic。 分析工作负载通常涉及将大量数…...

终极冒险岛游戏编辑器:5分钟快速上手完整指南
终极冒险岛游戏编辑器:5分钟快速上手完整指南 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected Harepacker-resurrected是一款专为…...

动态规划解题框架
动态规划解题框架:高效解决复杂问题的利器 动态规划(Dynamic Programming,DP)是一种高效解决复杂问题的算法思想,广泛应用于计算机科学、数学和经济学等领域。其核心思想是将大问题分解为子问题,通过存储子…...

Stable Yogi Leather-Dress-Collection步骤详解:从下载镜像到生成首张皮衣图
Stable Yogi Leather-Dress-Collection步骤详解:从下载镜像到生成首张皮衣图 1. 工具简介 Stable Yogi Leather-Dress-Collection是一款基于Stable Diffusion v1.5和Anything V5动漫底座模型开发的2.5D皮衣穿搭生成工具。它能让你轻松创建各种风格的动漫皮衣穿搭图…...

深度解析roop-unleashed:开源AI视频换脸工具的技术架构与实战应用
深度解析roop-unleashed:开源AI视频换脸工具的技术架构与实战应用 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed roop-unleashed是一个基于深度…...