【NLP经典论文阅读】Efficient Estimation of Word Representations in Vector Space(附代码)

【NLP经典论文阅读】Efficient Estimation of Word Representations in Vector Space(附代码)
1. 论文简介
Efficient Estimation of Word Representations in Vector Space(以下简称Word2vec)是一篇由Google的Tomas Mikolov等人于2013年发表的论文,该论文提出了一种基于神经网络的词向量训练方法,能够高效地学习到单词在向量空间中的分布式表示。
出处:https://arxiv.org/abs/1301.3781
作者:Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
单位:Google
发表年份:2013年
论文大意:
论文提出了两种新的模型架构,用于从非常大的数据集中计算单词的连续向量表示。这些表示的质量通过单词相似性任务进行衡量,并将结果与基于不同类型的神经网络的先前表现最佳的技术进行比较。我们观察到准确率有大幅提升,而计算成本则更低,即从一个16亿个单词的数据集中学习高质量单词向量只需不到一天的时间。此外,我们展示了这些向量在测量句法和语义单词相似性的测试集上提供了最先进的性能。
2. 论文详解
Word2vec的主要思想是通过预测上下文或目标单词的方法学习单词的向量表示。具体来说,Word2vec通过一个简单的神经网络来学习单词的向量表示,该神经网络包括一个输入层、一个隐藏层和一个输出层。输入层接收到一个单词,将其转换为一个向量表示,然后将该向量传递到隐藏层中。隐藏层对输入向量进行一些变换,然后将结果传递到输出层。输出层则根据上下文或目标单词的不同,采用不同的损失函数来计算损失,然后通过反向传播算法来更新模型参数。
Word2vec有两种模型,分别是CBOW模型和Skip-gram模型。CBOW模型根据上下文单词来预测中心单词,而Skip-gram模型则根据中心单词来预测上下文单词。在训练时,Word2vec通过梯度下降算法来最小化损失函数,并将单词的向量表示作为最终的输出。

相比传统的词向量方法,Word2vec的优点在于它能够高效地处理大量的语料库,从而学习到更加准确的单词向量表示。此外,Word2vec的向量表示能够自动捕捉到单词之间的语义和语法关系,因此在自然语言处理任务中表现出了良好的性能。
除了论文之外,Word2vec的相关代码也已经在GitHub上开源,可以在https://github.com/tmikolov/word2vec上找到。在该项目中,提供了C++和Python两种版本的实现代码,包括CBOW和Skip-gram两种模型以及负采样和层次softmax两种训练方法。
2.1 Skip-gram
在Skip-gram模型中,我们的目标是通过中心单词来预测上下文单词。对于给定的一对(中心单词,上下文单词),我们希望最大化它们的共现概率。
假设我们有一个长度为TTT的文本序列w1,w2,...,wTw_1,w_2,...,w_Tw1,w2,...,wT,我们的目标是最大化以下条件概率的对数似然函数:
L(θ)=1T∑t=1T∑−c≤j≤c,j≠0logp(wt+j∣wt;θ)L(\theta)=\frac{1}{T}\sum_{t=1}^T\sum_{-c\le j\le c,j\ne 0}\log p(w_{t+j}|w_t;\theta)L(θ)=T1t=1∑T−c≤j≤c,j=0∑logp(wt+j∣wt;θ)
其中,ccc是上下文单词的窗口大小,θ\thetaθ是模型的参数。
我们使用Softmax函数来估计每个上下文单词的概率:
p(wt+j∣wt;θ)=exp(vwt+j′⋅vwt)∑i=1Wexp(vi′⋅vwt)p(w_{t+j}|w_t;\theta)=\frac{\exp(v_{w_{t+j}}'\cdot v_{w_t})}{\sum_{i=1}^W\exp(v_i'\cdot v_{w_t})}p(wt+j∣wt;θ)=∑i=1Wexp(vi′⋅vwt)exp(vwt+j′⋅vwt)
其中,vwv_wvw和vw′v'_wvw′分别表示单词www在输入和输出层中的向量表示,WWW是词汇表大小。
2.2 CBOW模型
CBOW模型与Skip-gram模型类似,但是反过来。在CBOW模型中,我们的目标是通过上下文单词来预测中心单词。具体来说,我们希望最大化中心单词和其上下下文单词的共现概率,公式如下:
L(θ)=1T∑t=1Tlogp(wt∣wt−c,…,wt−1,wt+1,…,wt+c;θ)L(\theta)=\frac{1}{T}\sum_{t=1}^T\log p(w_t|w_{t-c},\ldots,w_{t-1},w_{t+1},\ldots,w_{t+c};\theta)L(θ)=T1t=1∑Tlogp(wt∣wt−c,…,wt−1,wt+1,…,wt+c;θ)
其中,ccc是上下文单词的窗口大小,θ\thetaθ是模型的参数。
我们使用Softmax函数来估计中心单词的概率:
p(wt∣wt−c,…,wt−1,wt+1,…,wt+c;θ)=exp(∑j=−c,j≠0cvwt+j)∑i=1Wexp(∑j=−c,j≠0cvwt+j)p(w_t|w_{t-c},\ldots,w_{t-1},w_{t+1},\ldots,w_{t+c};\theta)=\frac{\exp(\sum_{j=-c,j\ne 0}^cv_{w_{t+j}})}{\sum_{i=1}^W\exp(\sum_{j=-c,j\ne 0}^cv_{w_{t+j}})}p(wt∣wt−c,…,wt−1,wt+1,…,wt+c;θ)=∑i=1Wexp(∑j=−c,j=0cvwt+j)exp(∑j=−c,j=0cvwt+j)
其中,vwv_wvw和vw′v'_wvw′分别表示单词www在输入和输出层中的向量表示,CCC是上下文单词的数量,WWW是词汇表大小。
2.3 模型优化
在训练Word2Vec模型时,我们需要最大化对数似然函数。由于词汇表很大,如果使用标准的梯度下降法来优化模型,计算量将非常大。为了解决这个问题,作者提出了两种方法:Hierarchical Softmax和Negative Sampling。
2.3 Hierarchical Softmax
在Hierarchical Softmax中,我们将输出层的单词表示为一个二叉树,其中每个叶子节点都表示一个单词。每个非叶子节点都表示两个子节点的内积,每个叶子节点都表示该单词的条件概率。由于二叉树的形状,我们可以使用log2W\log_2 Wlog2W个节点来表示词汇表大小为WWW的模型,这将大大降低计算量。
在使用Hierarchical Softmax进行训练时,我们需要通过二叉树来计算每个上下文单词的概率,如下所示:
p(wt+j∣wt)=exp(vwt+jT⋅vwt)∑i=1Wexp(viT⋅vwt)=exp(score(wt+j,wt))∑i=1Wexp(score(wi,wt))p(w_{t+j}|w_t)=\frac{\exp(v_{w_{t+j}}^T\cdot v_{w_t})}{\sum_{i=1}^W\exp(v_i^T\cdot v_{w_t})}=\frac{\exp(\text{score}(w_{t+j},w_t))}{\sum_{i=1}^W\exp(\text{score}(w_i,w_t))}p(wt+j∣wt)=∑i=1Wexp(viT⋅vwt)exp(vwt+jT⋅vwt)=∑i=1Wexp(score(wi,wt))exp(score(wt+j,wt))
其中,l(wO)l(w_O)l(wO)是单词wOw_OwO在二叉树中的深度,n(wO,j)n(w_O,j)n(wO,j)表示在单词wOw_OwO的路径上第jjj个节点,σ(x)=11+exp(−x)\sigma(x)=\frac{1}{1+\exp(-x)}σ(x)=1+exp(−x)1是Sigmoid函数。
2.4 Negative Sampling
在Negative Sampling中,我们将每个训练样本拆分成多个二元组(wI,wO)(w_I,w_O)(wI,wO),其中wIw_IwI是中心单词,wOw_OwO是上下文单词。
对于每个二元组,我们随机采样KKK个噪声单词,用它们来计算负样本。具体地,我们将每个单词的概率提高到3/43/43/4次方,并进行归一化,得到单词www的采样概率:
Psample(w)=f(w)3/4∑i=1Wf(wi)3/4P_{\text{sample}}(w)=\frac{f(w)^{3/4}}{\sum_{i=1}^{W}f(w_i)^{3/4}}Psample(w)=∑i=1Wf(wi)3/4f(w)3/4
其中,f(w)f(w)f(w)是单词www在训练语料中出现的频次。
在使用Negative Sampling进行训练时,我们的目标是最小化负样本的概率和中心单词的概率的负对数似然:
−logσ(vwO′⋅vwI)−∑k=1Klogσ(−vwk′⋅vwI)-\log\sigma(v'_{w_O}\cdot v_{w_I})-\sum_{k=1}^{K}\log\sigma(-v'_{w_k}\cdot v_{w_I})−logσ(vwO′⋅vwI)−k=1∑Klogσ(−vwk′⋅vwI)
其中,wkw_kwk是噪声单词,σ(x)=11+exp(−x)\sigma(x)=\frac{1}{1+\exp(-x)}σ(x)=1+exp(−x)1是Sigmoid函数。
使用Negative Sampling的优点在于计算速度较快,但是它有可能丢失一些信息,因为它只考虑了一部分的负样本。
3. 代码实现
下面,我们通过一个简单的案例来演示如何使用Word2vec训练词向量。首先,我们需要下载并解压缩一个语料库,例如维基百科的语料库。然后,我们可以使用Python中的gensim库来训练词向量。具体代码如下:
import gensim
from gensim.models import Word2Vec# 加载语料库
sentences = gensim.models.word2vec.Text8Corpus('path/to/corpus')# 训练模型
model = Word2Vec(sentences, size=100, window=5, min_count=5, workers=4)# 保存模型
model.save('path/to/model')# 加载模型
model = Word2Vec.load('path/to/model')# 获取单词向量
vector = model['word']
在上面的代码中,我们首先使用Text8Corpus类加载语料库,然后使用Word2Vec类来训练模型。其中,size参数指定了向量的维度,window参数指定了上下文单词的窗口大小,min_count参数指定了单词出现的最小次数,workers参数指定了使用的线程数。训练完成后,我们可以使用save和load方法来保存和加载模型,使用model[‘word’]来获取单词的向量表示。
通过Word2vec训练出的词向量可以用于许多自然语言处理任务,例如词义相似度计算、命名实体识别和情感分析等。例如,在情感分析任务中,我们可以通过将一句话中的单词向量取平均来获取该句话的向量表示,然后使用分类器来对其进行情感分类。该方法在许多情感分析任务中表现出了良好的性能。
相关文章:
【NLP经典论文阅读】Efficient Estimation of Word Representations in Vector Space(附代码)
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

Spring bean生命周期分为几个阶段?
bean 的生命周期从调用 beanFactory 的 getBean 开始,到这个 bean 被销毁,可以总结为以下七个阶段:处理名称,检查缓存→处理父子容器→处理 dependsOn→选择 scope 策略→创建 bean→类型转换处理→销毁 bean划分的阶段和名称并不…...

【基础算法】单链表的OJ练习(4) # 分割链表 # 回文链表 #
文章目录前言分割链表回文链表写在最后前言 本章的OJ练习相对前面的难度加大了,但是换汤不换药,还是围绕单链表的性质来出题的。我相信,能够过了前面的OJ练习,本章的OJ也是轻轻松松。 对于OJ练习(3):-> 传送门 <…...
SpringBoot整合定时任务和邮件发送(邮箱 信息轰炸 整蛊)
SpringBoot整合定时任务和邮件发送(邮箱 信息轰炸 整蛊) 目录SpringBoot整合定时任务和邮件发送(邮箱 信息轰炸 整蛊)1.概述2.最佳实践2.1创建项目引入依赖(mail)2.2 修改yml配置文件2.3 启动类添加EnableScheduling注解2.4 执行的…...
Arduino添加ESP32开发板
【2023年3月4日】 最近要在新电脑上安装Arduino,需要进行一些配置,正好记录一下! Arduino2.0.1 下的开发板添加操作。 ESP32开发板GitHub链接: GitHub - espressif/arduino-esp32: Arduino core for the ESP32Arduino core for…...

Mysql通配符的使用
LIKE操作符 通配符:用来匹配值的一部分的特殊字符。 搜索模式:由字面值,通配符或两者组合构成的搜索条件。 百分号(%)通配符 搜索模式使用例如下 SELECT prod_id, prod_name FROM products WHERE prod_name Like jet%; 这条子句表示&…...
RocketMQ-02
1. 案例介绍 1.1 业务分析 模拟电商网站购物场景中的【下单】和【支付】业务 ###1)下单 用户请求订单系统下单订单系统通过RPC调用订单服务下单订单服务调用优惠券服务,扣减优惠券订单服务调用调用库存服务,校验并扣减库存订单服务调用用户…...
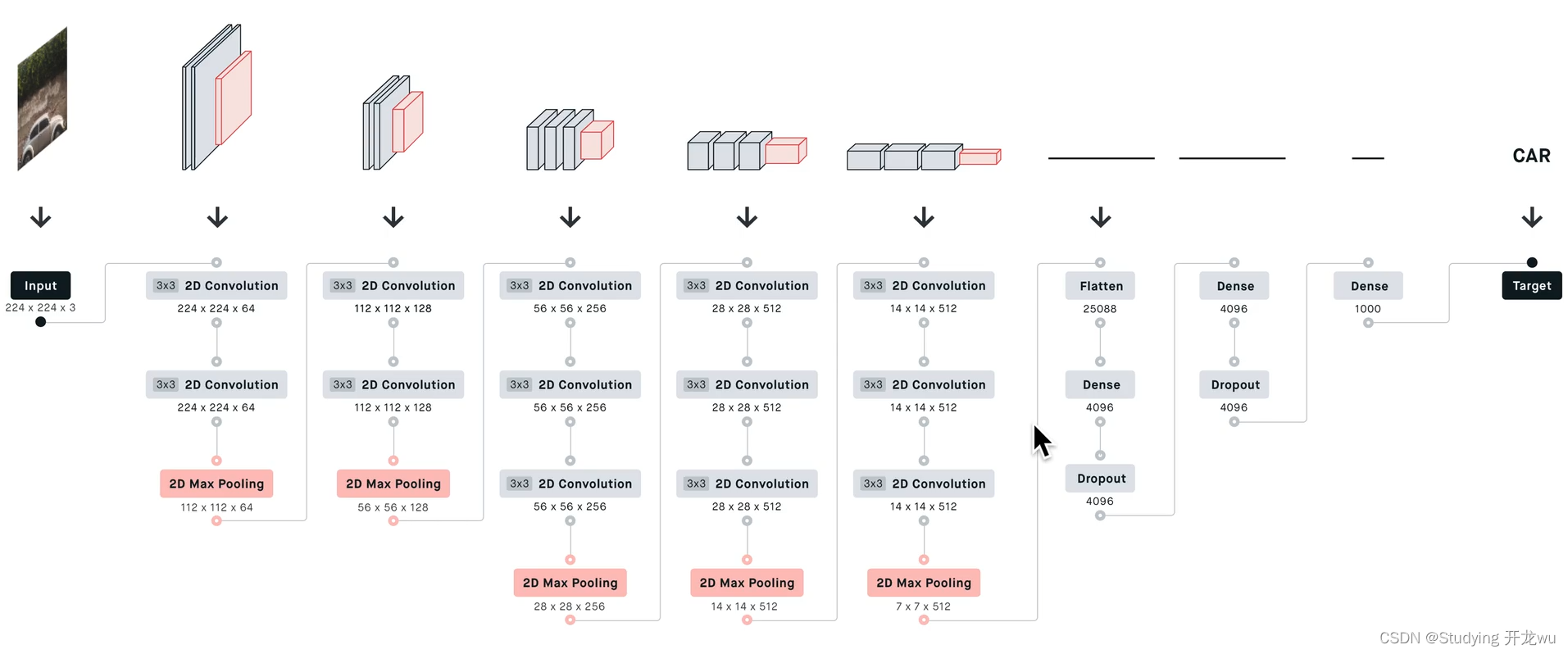
深度学习卷积神经网络CNN之 VGGNet模型主vgg16和vgg19网络模型详解说明(理论篇)
1.VGG背景 2. VGGNet模型结构 3. 特点(创新、优缺点及新知识点) 一、VGG背景 VGGNet是2014年ILSVRC(ImageNet Large Scale Visual Recognition Challenge大规模视觉识别挑战赛)竞赛的第二名,解决ImageNet中的1000类图…...
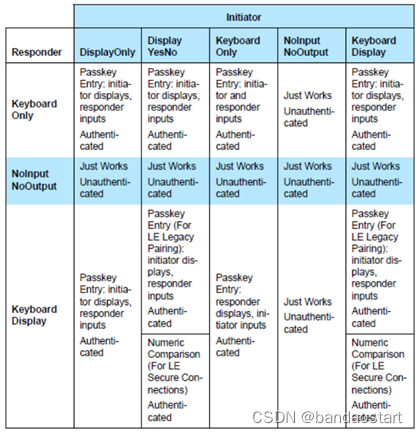
三:BLE协议架构简介
低功耗蓝牙体系整体架构说明1. PHY(物理层)2. LL(链路层)3. HCI(主机与控制器通信接口)4. L2CAP(逻辑链路控制及适配协议)5. ATT(属性协议)6. GATT(通用属性规范)7. GAP(通用访问规范)8. SM(安全管理)整体架构说明 架构层说明PHY1. 物理层2. 控制射频的发送和接收LL1. 链路层2.…...
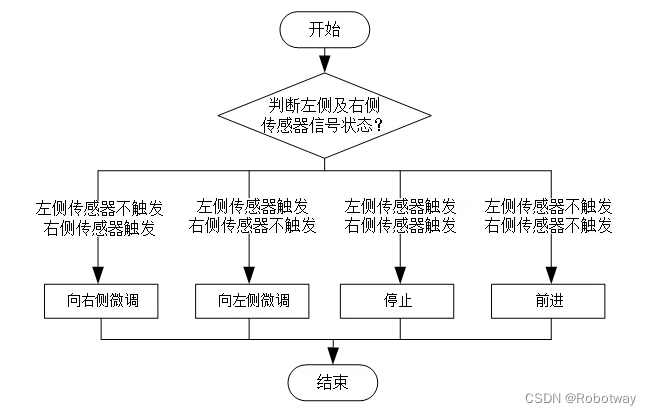
小型双轮差速底盘双灰度循迹功能的实现
1. 功能说明 在机器人车体上安装2个 灰度传感器 ,实现机器人按照下图所指定的路线进行导航运动,来模拟仓库物流机器人按指定路线行进的工作过程。 2. 使用样机 本实验使用的样机为R023e样机。 3. 功能实现 3.1 电子硬件 在这个示例中,我们采…...

电子签名?玩具罢了!
需要的前置知识:简单的canvas绘制线路过程 let canvas document.getElementById(id); //id为canvas标签元素的id,或通过其它方法获取标签 let ctx canvas.getContext(2d); //规定为2d绘制图片,即确定为2d画笔 ctx.strokeStyle "whit…...

【Spring Boot读取配置文件的方式】
Spring Boot 支持多种读取配置文件的方式,常用的方式有以下三种: application.properties: Spring Boot 默认会读取该文件作为应用的配置文件。可以在 src/main/resources 目录下创建该文件,并在其中配置应用的属性。 applicat…...

java学习路线规划
java学习路线规划 一、写在前面 兄弟,我整理了一下关于自己之前学习java的一些方向,给你归纳在这里,有空就来看看,希望对你有帮助。 二、java基础篇 1、认识java 了解java历史,大概看看发展史,安装…...
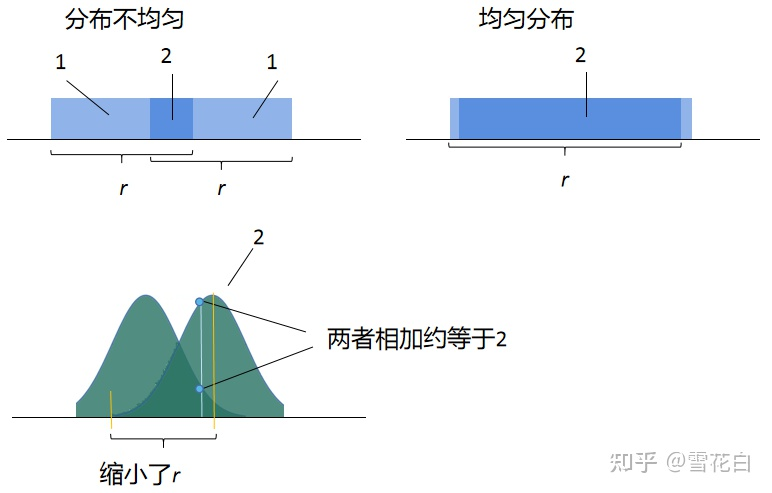
格密码学习笔记(二):连续极小、覆盖半径和平滑参数
文章目录最短距离和连续极小值距离函数和覆盖半径格的平滑参数致谢最短距离和连续极小值 除了行列式,格的另一个基本量是格上最短非零向量的长度,即格中最短距离,其定义为 λ1minx,y∈L,x≠y∥x−y∥minz∈L,z≠0∥z∥.\begin{aligned} …...

ios 通过搜索设备MAC地址绑定
最近做了一个物联网项目,涉及到了设备绑定配网这块,需要了解一下iOS BLE与设备绑定的相关知识点,第一次接触蓝牙相关的项目,所以开始熟悉蓝牙的相关信息。没有去深入研究BabyTooth库,只是感觉CoreBluetooth已经让我更好的理解整个流程这个物联网项目的设备绑定流程是…...

Python实现人脸识别,进行视频跟踪打码,羞羞的画面统统打上马赛克
哈喽兄弟们,我是轻松~ 今天我们来实现用Python自动对视频打马赛克前言准备工作代码实战效果展示最后前言 事情是这样的,昨天去表弟家,用了下他的电脑,不小心点到了他硬盘里隐藏的秘密,本来我只需要用几分钟电脑的&…...

vcf bed起始位置是0还是1
VCF 起始位置为1, POS - position: The reference position, with the 1st base having position 1. Positions are sorted numerically, in increasing order, within each reference sequence CHROM. It is permitted to have multiple records with the same POS. Telome…...
Hexo+live2d | 如何把live2d老婆放进自己的博客
参考:Hexo添加Live2D看板娘最新教程live2d-widgetlive2d-widget-models网页/博客Hexo添加live2d游戏角色看板娘,简易添加,碧蓝航线等live2d新型游戏角色模型(moc3)live2d-moc3jsdelivr方法1可以直接去看参考文章的第一部分的第一篇…...

【微信小程序】-- 页面导航 -- 导航传参(二十四)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

Pytorch学习笔记#2: 搭建神经网络训练MNIST手写数字数据集
学习自https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html 导入并预处理数据集 pytorch中数据导入和预处理主要用torch.utils.data.DataLoader 和 torch.utils.data.Dataset Dataset 存储样本及其相应的标签,DataLoader在数据上生成一个可迭…...

5分钟掌握Diablo Edit2:暗黑破坏神II角色编辑器的终极指南
5分钟掌握Diablo Edit2:暗黑破坏神II角色编辑器的终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神II的刷装备烦恼吗?想要快速体验不同build的乐趣…...

XSS-Game 实战解析:从Level1到Level18的攻防思维演进
1. XSS-Game入门:理解基础注入逻辑 第一次接触XSS-Game时,很多人会疑惑这到底是个什么游戏。简单来说,这是一个专门设计用来练习XSS(跨站脚本攻击)技术的在线靶场,包含18个难度递增的关卡。每个关卡都模拟了…...

PyWxDump:微信数据管理的终极本地解决方案指南
PyWxDump:微信数据管理的终极本地解决方案指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 在数字时代,微信聊天记录承载着我们珍贵的回忆和重要信息,但你是否曾担心数据安全、备份困…...

智能卡通信调优实战:手把手教你用逻辑分析仪抓取并解析ISO7816 PPS协商过程
智能卡通信调优实战:手把手教你用逻辑分析仪抓取并解析ISO7816 PPS协商过程 在嵌入式系统和智能卡应用开发中,通信稳定性往往是项目成败的关键。当你的智能卡设备频繁出现通信中断、数据丢失或速率不达标时,问题很可能隐藏在协议协商阶段。IS…...
SVPWM算法MATLAB仿真进阶:从模型搭建到代码生成)
stm32 FOC从学习开发(七)SVPWM算法MATLAB仿真进阶:从模型搭建到代码生成
1. SVPWM算法仿真与代码生成全流程 搞电机控制的朋友都知道,SVPWM(空间矢量脉宽调制)是FOC(磁场定向控制)的核心算法之一。前几期我们聊过Clark变换、Park变换,也讲过SVPWM的基本原理,今天咱们就…...
GalTransl代码架构分析:理解多进程插件系统的设计原理
GalTransl代码架构分析:理解多进程插件系统的设计原理 【免费下载链接】GalTransl 支持GPT-4/Claude/Deepseek/Sakura等大语言模型的Galgame自动化翻译解决方案 Automated translation solution for visual novels supporting GPT-4/Claude/Deepseek/Sakura 项目地…...

MATLAB bandpass函数实战:用音乐合成和滤波案例,5分钟搞懂信号处理核心参数
MATLAB bandpass函数实战:从音乐合成到精准滤波的完整指南 1. 用MATLAB合成你的第一段数字音乐 在开始滤波之前,让我们先创造一段属于自己的数字音乐。这个过程中,你会理解声音信号在数字世界中的本质——它不过是一串随时间变化的数字序列。…...

僧伽罗文语音本地化迫在眉睫!斯里兰卡新《数字服务法》2024年10月生效前,你必须掌握的7项ElevenLabs合规配置
更多请点击: https://intelliparadigm.com 第一章:僧伽罗文语音本地化的法律动因与技术紧迫性 斯里兰卡《官方语言法》(No. 33 of 1956)及2023年修订的《国家数字包容战略》明确要求:所有面向公众的政府数字服务必须支…...

Go语言设计模式:行为型模式
Go语言设计模式:行为型模式 一、行为型模式概述 行为型模式关注对象之间的通信和职责分配,描述对象如何协作以及如何分配职责。 Go语言中的行为型模式特点 接口驱动:通过接口定义行为契约并发安全:考虑并发场景下的协作组合实现&a…...
Code Coverage:从覆盖率收集到报告生成的全流程实战)
【VCS】(6)Code Coverage:从覆盖率收集到报告生成的全流程实战
1. 代码覆盖率基础概念 第一次接触代码覆盖率这个概念时,我也是一头雾水。记得当时领导问我:"这个模块的验证覆盖率多少了?"我只能支支吾吾说还在跑仿真。后来才明白,代码覆盖率是衡量验证完整性的重要指标,…...