flink重温笔记(十四): flink 高级特性和新特性(3)——数据类型及 Avro 序列化
Flink学习笔记
前言:今天是学习 flink 的第 14 天啦!学习了 flink 高级特性和新特性之数据类型及 avro 序列化,主要是解决大数据领域数据规范化写入和规范化读取的问题,avro 数据结构可以节约存储空间,本文中结合企业真实应用场景,即 kafka 的读取和写入采用自定义序列化,结合自己实验猜想和代码实践,总结了很多自己的理解和想法,希望和大家多多交流!
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!"
文章目录
- Flink学习笔记
- 四、Flink 高级特性和新特性
- 4. 数据类型及序列化
- 4.1 数据类型
- 4.2 POJO 类型细节
- 4.3 Avro优点介绍
- 4.4 定义Avro Json格式
- 4.5 使用 Java 自定义序列化到 Kfaka
- 4.5.1 准备数据
- 4.5.2 自定义Avro 序列化和反序列化
- 4.5.3 创建生产者工具类
- 4.5.4 创建消费者工具类
- 4.5.5 运行程序
- 4.6 使用 Flink 自定义序列化到 Kafka
- 4.6.1 准备数据
- 4.6.2 自定义Avro 序列化和反序列化
- 4.6.3 创建 Flink-source 类
- 4.6.4 创建 Flink-sink 类
- 4.6.5 运行程序
四、Flink 高级特性和新特性
4. 数据类型及序列化
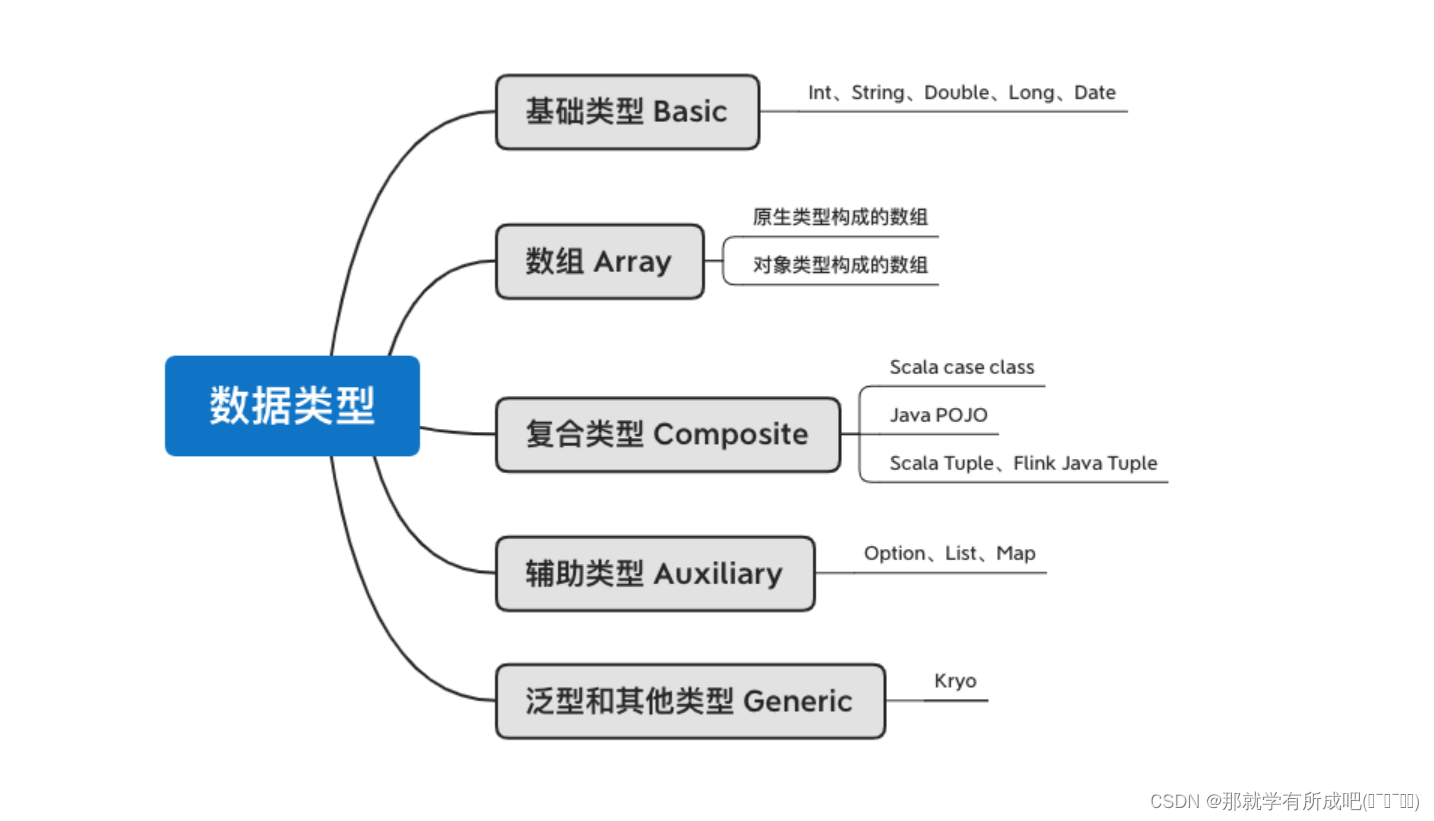
4.1 数据类型
flink 支持的数据类型:七种
4.2 POJO 类型细节
注意事项:
- 该类需要有 public 修饰
- 该类需要有 public 修饰的无参构造函数
- 该类的所有(no-static)、(no-transient)字段必须是 public,如果不是 public 则必须是有标准的 getter 和 setter
- 该类的所有字段都必须是 flink 支持的数据类型
4.3 Avro优点介绍
-
Avro 是数据序列化系统,支持大批量数据交换的应用。
-
支持二进制序列化方式,性能好 / 效率高,使用 JSON 描述。
-
动态语言友好,RPC 远程调用,支持同步和异步通信。
4.4 定义Avro Json格式
- namespace:要生成的目录
- type:类型 avro 需要指定 record
- name:会自动生成的对象
- fields:要指定的字段
注意: 创建的文件后缀名一定要叫 avsc,而不是 avro 后缀,使用 idea 生成 Order 对象
{"namespace": "cn.itcast.beans","type": "record","name": "OrderModel","fields": [{"name": "userId", "type": "string"},{"name": "timestamp", "type": "long"},{"name": "money", "type": "double"},{"name": "category", "type": "string"}]
}
注意:由于在导入 pom 依赖的时候,需要注意插件冲突,注释掉以下依赖,不然会一直爆错!
<!-- 这个会和 avro 冲突,所以先注释一下-->
<!-- <dependency>-->
<!-- <groupId>org.apache.hive</groupId>-->
<!-- <artifactId>hive-exec</artifactId>-->
<!-- <version>2.1.0</version>-->
<!-- </dependency>-->
- 快看一!导入需要的依赖到 pom 文件中:
<dependency><groupId>org.apache.avro</groupId><artifactId>avro</artifactId><version>1.8.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-avro -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-avro</artifactId><version>${flink.version}</version>
</dependency><!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.5.1</version>
</dependency>
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>2.5.1</version>
</dependency>
- 快看二!导入需要的插件到 pom 文件中:
<!-- avro编译插件 -->
<plugin><groupId>org.apache.avro</groupId><artifactId>avro-maven-plugin</artifactId><version>1.8.2</version><executions><execution><phase>generate-sources</phase><goals><goal>schema</goal></goals><configuration><sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory><outputDirectory>${project.basedir}/src/main/java/</outputDirectory></configuration></execution></executions>
</plugin>

4.5 使用 Java 自定义序列化到 Kfaka
4.5.1 准备数据
order.csv
user_001,1621718199,10.1,电脑
user_001,1621718201,14.1,手机
user_002,1621718202,82.5,手机
user_001,1621718205,15.6,电脑
user_004,1621718207,10.2,家电
user_001,1621718208,15.8,电脑
user_005,1621718212,56.1,电脑
user_002,1621718260,40.3,家电
user_001,1621718580,11.5,家居
user_001,1621718860,61.6,家居
4.5.2 自定义Avro 序列化和反序列化
首先需要实现2个接口分别为 Serializer 和 Deserializer 分别是序列化和反序列化
package cn.itcast.day14.serialization_java;/*** @author lql* @time 2024-03-10 16:29:49* @description TODO*/import cn.itcast.day14.beans.OrderModel;
import org.apache.avro.io.BinaryDecoder;
import org.apache.avro.io.BinaryEncoder;
import org.apache.avro.io.DecoderFactory;
import org.apache.avro.io.EncoderFactory;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.Map;
import org.apache.kafka.common.serialization.*;/*** 自定义序列化和反序列化*/
public class SimpleAvroSchemaJava implements Serializer<OrderModel>, Deserializer<OrderModel> {@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {}@Overridepublic void close() {}@Overridepublic byte[] serialize(String s, OrderModel order) {// 创建序列化执行器SpecificDatumWriter<OrderModel> writer = new SpecificDatumWriter<OrderModel>(order.getSchema());// 创建一个流 用存储序列化后的二进制文件ByteArrayOutputStream out = new ByteArrayOutputStream();// 创建二进制编码器BinaryEncoder encoder = EncoderFactory.get().directBinaryEncoder(out, null);try {// 数据入都流中writer.write(order, encoder);} catch (IOException e) {e.printStackTrace();}return out.toByteArray();}@Overridepublic OrderModel deserialize(String s, byte[] bytes) {// 用来保存结果数据OrderModel order = new OrderModel();// 创建输入流用来读取二进制文件ByteArrayInputStream arrayInputStream = new ByteArrayInputStream(bytes);// 创建输入序列化执行器SpecificDatumReader<OrderModel> stockSpecificDatumReader = new SpecificDatumReader<OrderModel>(order.getSchema());//创建二进制解码器BinaryDecoder binaryDecoder = DecoderFactory.get().directBinaryDecoder(arrayInputStream, null);try {// 数据读取order= stockSpecificDatumReader.read(null, binaryDecoder);} catch (IOException e) {e.printStackTrace();}// 结果返回return order;}
}
4.5.3 创建生产者工具类
package cn.itcast.day14.serialization_java;import cn.itcast.day14.beans.OrderModel;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/*** @author lql* @time 2024-03-10 16:33:31* @description TODO*/
public class OrderProducerJava {public static void main(String[] args) {// 获取数据List<OrderModel> data = getData();System.out.println(data);try {// 创建配置文件Properties props = new Properties();props.setProperty("bootstrap.servers", "node1:9092");// 这里的健:还是 string 序列化props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 这里的值:需要指向自定义的序列化props.setProperty("value.serializer", "cn.itcast.day14.serialization_java.SimpleAvroSchemaJava");// 创建kafka的生产者KafkaProducer<String, OrderModel> userBehaviorProducer = new KafkaProducer<String, OrderModel>(props);// 循环遍历数据for (OrderModel orderModel : data) {ProducerRecord<String, OrderModel> producerRecord = new ProducerRecord<String, OrderModel>("order", orderModel);userBehaviorProducer.send(producerRecord);System.out.println("数据写入成功"+data);Thread.sleep(1000);}} catch (InterruptedException e) {e.printStackTrace();}}public static List<OrderModel> getData() {ArrayList<OrderModel> orderModels = new ArrayList<OrderModel>();try {BufferedReader br = new BufferedReader(new FileReader(new File("D:\\IDEA_Project\\BigData_Java\\flinkbase_pro\\data\\input\\order.csv")));String line = "";while ((line = br.readLine()) != null) {String[] fields = line.split(",");orderModels.add(new OrderModel(fields[0], Long.parseLong(fields[1]), Double.parseDouble(fields[2]), fields[3]));}} catch (Exception e) {e.printStackTrace();}return orderModels;}
}
4.5.4 创建消费者工具类
package cn.itcast.day14.serialization_java;import cn.itcast.day14.beans.OrderModel;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.Arrays;
import java.util.Properties;
/*** @author lql* @time 2024-03-10 16:38:29* @description TODO*/
public class OrderConsumerJava {public static void main(String[] args) {Properties prop = new Properties();prop.put("bootstrap.servers", "node1:9092");prop.put("group.id", "order");prop.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 设置反序列化类为自定义的avro反序列化类prop.put("value.deserializer", "cn.itcast.day14.serialization_java.SimpleAvroSchemaJava");KafkaConsumer<String, OrderModel> consumer = new KafkaConsumer<String, OrderModel>(prop);consumer.subscribe(Arrays.asList("order"));while (true) {// poll 方法用于从 kafka 中拉取数据ConsumerRecords<String, OrderModel> poll = consumer.poll(1000);for (ConsumerRecord<String, OrderModel> stringStockConsumerRecord : poll) {System.out.println(stringStockConsumerRecord.value());}}}
}
4.5.5 运行程序
# 首先启动zookeeper# 启动 kafka,记得后台启动
后台:cd /export/servers/kafka_2.11-0.10.0.0nohup bin/kafka-server-start.sh config/server.properties 2>&1 &停止:cd /export/servers/kafka_2.11-0.10.0.0bin/kafka-server-stop.sh# 创建topic
bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 1 --topic order
# 模拟消费者
bin/kafka-console-consumer.sh --zookeeper node1:2181 --from-beginning --topic order
结果:
- 生产者打印:
[{"userId": "user_001", "timestamp": 1621718199, "money": 10.1, "category": "电脑"}, {"userId": "user_001", "timestamp": 1621718201, "money": 14.1, "category": "手机"}, {"userId": "user_002", "timestamp": 1621718202, "money": 82.5, "category": "手机"}, {"userId": "user_001", "timestamp": 1621718205, "money": 15.6, "category": "电脑"}, {"userId": "user_004", "timestamp": 1621718207, "money": 10.2, "category": "家电"}, {"userId": "user_001", "timestamp": 1621718208, "money": 15.8, "category": "电脑"}, {"userId": "user_005", "timestamp": 1621718212, "money": 56.1, "category": "电脑"}, {"userId": "user_002", "timestamp": 1621718260, "money": 40.3, "category": "家电"}, {"userId": "user_001", "timestamp": 1621718580, "money": 11.5, "category": "家居"}, {"userId": "user_001", "timestamp": 1621718860, "money": 61.6, "category": "家居"}]
数据写入成功
- 消费者打印:
{"userId": "user_001", "timestamp": 1621718199, "money": 10.1, "category": "电脑"}
{"userId": "user_001", "timestamp": 1621718201, "money": 14.1, "category": "手机"}
{"userId": "user_002", "timestamp": 1621718202, "money": 82.5, "category": "手机"}
{"userId": "user_001", "timestamp": 1621718205, "money": 15.6, "category": "电脑"}
{"userId": "user_004", "timestamp": 1621718207, "money": 10.2, "category": "家电"}
{"userId": "user_001", "timestamp": 1621718208, "money": 15.8, "category": "电脑"}
{"userId": "user_005", "timestamp": 1621718212, "money": 56.1, "category": "电脑"}
{"userId": "user_002", "timestamp": 1621718260, "money": 40.3, "category": "家电"}
{"userId": "user_001", "timestamp": 1621718580, "money": 11.5, "category": "家居"}
{"userId": "user_001", "timestamp": 1621718860, "money": 61.6, "category": "家居"}
总结:值的序列化需要指定自己定义的序列化。
4.6 使用 Flink 自定义序列化到 Kafka
4.6.1 准备数据
order.csv
user_001,1621718199,10.1,电脑
user_001,1621718201,14.1,手机
user_002,1621718202,82.5,手机
user_001,1621718205,15.6,电脑
user_004,1621718207,10.2,家电
user_001,1621718208,15.8,电脑
user_005,1621718212,56.1,电脑
user_002,1621718260,40.3,家电
user_001,1621718580,11.5,家居
user_001,1621718860,61.6,家居
4.6.2 自定义Avro 序列化和反序列化
首先需要实现2个接口分别为 SerializationSchema 和 DeserializationSchema 分别是序列化和反序列化
package cn.itcast.day14.serialization_flink;/*** @author lql* @time 2024-03-10 17:35:09* @description TODO*/
import cn.itcast.day14.beans.OrderModel;
import org.apache.avro.io.BinaryDecoder;
import org.apache.avro.io.BinaryEncoder;
import org.apache.avro.io.DecoderFactory;
import org.apache.avro.io.EncoderFactory;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;/*** 自定义序列化和反序列化*/
public class SimpleAvroSchemaFlink implements DeserializationSchema<OrderModel>, SerializationSchema<OrderModel> {@Overridepublic byte[] serialize(OrderModel order) {// 创建序列化执行器SpecificDatumWriter<OrderModel> writer = new SpecificDatumWriter<OrderModel>(order.getSchema());// 创建一个流 用存储序列化后的二进制文件ByteArrayOutputStream out = new ByteArrayOutputStream();// 创建二进制编码器BinaryEncoder encoder = EncoderFactory.get().directBinaryEncoder(out, null);try {// 数据入都流中writer.write(order, encoder);} catch (IOException e) {e.printStackTrace();}return out.toByteArray();}@Overridepublic TypeInformation<OrderModel> getProducedType() {return TypeInformation.of(OrderModel.class);}@Overridepublic OrderModel deserialize(byte[] bytes) throws IOException {// 用来保存结果数据OrderModel userBehavior = new OrderModel();// 创建输入流用来读取二进制文件ByteArrayInputStream arrayInputStream = new ByteArrayInputStream(bytes);// 创建输入序列化执行器SpecificDatumReader<OrderModel> stockSpecificDatumReader = new SpecificDatumReader<OrderModel>(userBehavior.getSchema());//创建二进制解码器BinaryDecoder binaryDecoder = DecoderFactory.get().directBinaryDecoder(arrayInputStream, null);try {// 数据读取userBehavior=stockSpecificDatumReader.read(null, binaryDecoder);} catch (IOException e) {e.printStackTrace();}// 结果返回return userBehavior;}@Overridepublic boolean isEndOfStream(OrderModel userBehavior) {return false;}
}4.6.3 创建 Flink-source 类
package cn.itcast.day14.serialization_flink;/*** @author lql* @time 2024-03-10 17:37:15* @description TODO*/
import cn.itcast.day14.beans.OrderModel;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;import java.util.Properties;public class OrderProducerFlink {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> value = env.readTextFile("D:\\IDEA_Project\\BigData_Java\\flinkbase_pro\\data\\input\\order.csv");DataStream<OrderModel> orderModelDataStream = value.map(row -> {String[] fields = row.split(",");return new OrderModel(fields[0], Long.parseLong(fields[1]), Double.parseDouble(fields[2]), fields[3]);});Properties prop = new Properties();prop.setProperty("bootstrap.servers", "node1:9092");//4.连接KafkaFlinkKafkaProducer<OrderModel> producer = new FlinkKafkaProducer<>("order",new SimpleAvroSchemaFlink(),prop);//5.将数据打入kafkaorderModelDataStream.addSink(producer);//6.执行任务env.execute();}
}
4.6.4 创建 Flink-sink 类
package cn.itcast.day14.serialization_flink;/*** @author lql* @time 2024-03-10 17:40:04* @description TODO*/
import cn.itcast.day14.beans.OrderModel;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class OrderConsumerFlink {public static void main(String[] args) throws Exception {//1.构建流处理运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1); // 设置并行度1 方便后面测试// 2.设置kafka 配置信息Properties prop = new Properties();prop.put("bootstrap.servers", "node1:9092");prop.put("group.id", "UserBehavior");prop.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 下面有提及:SimpleAvroSchemaFlink,上面就不需要指定了!// 3.构建Kafka 连接器FlinkKafkaConsumer kafka = new FlinkKafkaConsumer<OrderModel>("order", new SimpleAvroSchemaFlink(), prop);//4.设置Flink层最新的数据开始消费kafka.setStartFromLatest();//5.基于kafka构建数据源DataStream<OrderModel> data = env.addSource(kafka);//6.结果打印data.print();env.execute();}
}
4.6.5 运行程序
这里运用 Kafka-Tool 2.0.7 可视化工具,工具包放在资源处啦,大家感兴趣可以观看我上传的资源哟!
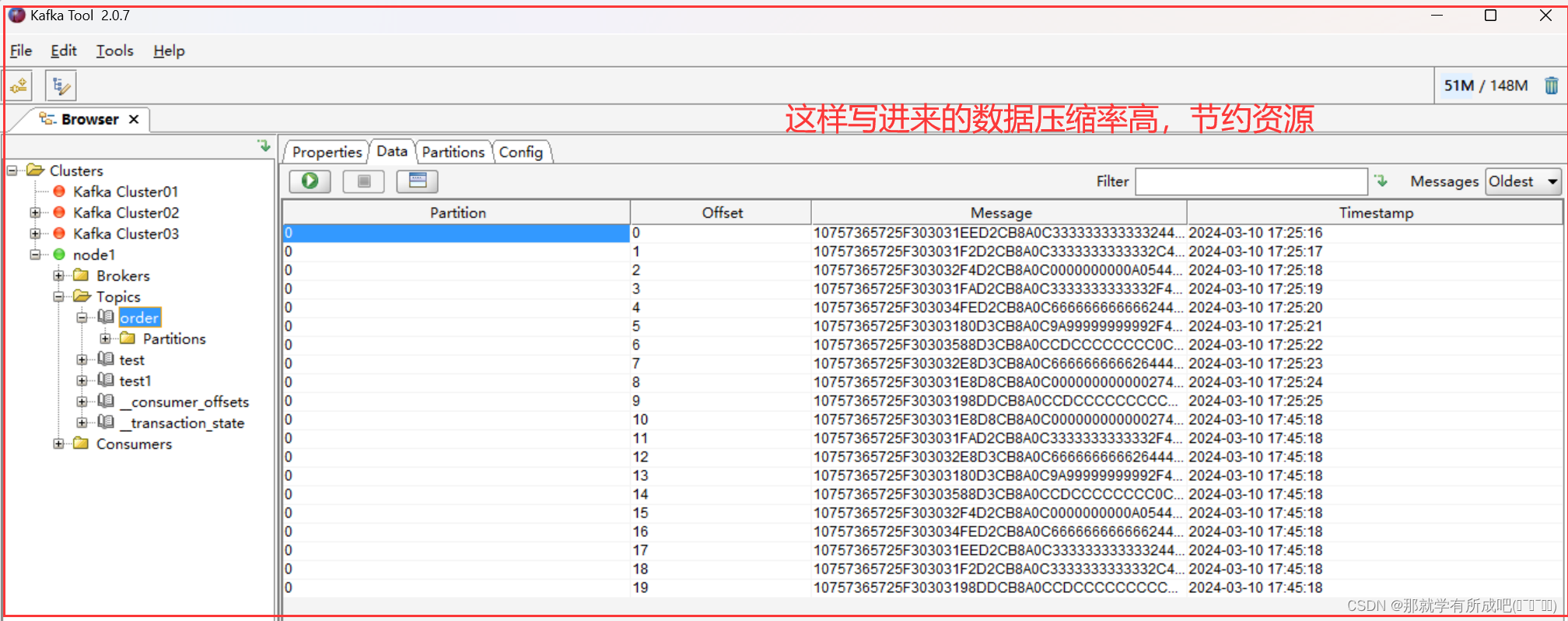
总结:📚 刚开始学习这个知识点时,我真是感觉有些吃力,觉得它太抽象、太难以理解了。但想到这是企业工作环境中必须掌握的技术,能够为企业节省资源、提高数据存储效率,我就鼓起勇气,决定迎难而上。💪
于是,我根据例子,一个字母一个字母地敲下代码,反复调试、尝试。终于,当程序运行成功的那一刻,我感到了前所未有的成就感!
🎉原来,成功真的就是坚持的结果。只有当你坚持不懈地努力,才能有机会看到胜利的曙光。
🌈明天,我也要继续努力学习,不断挑战自己,迎接更多的成功!🚀 加油!💪
相关文章:
flink重温笔记(十四): flink 高级特性和新特性(3)——数据类型及 Avro 序列化
Flink学习笔记 前言:今天是学习 flink 的第 14 天啦!学习了 flink 高级特性和新特性之数据类型及 avro 序列化,主要是解决大数据领域数据规范化写入和规范化读取的问题,avro 数据结构可以节约存储空间,本文中结合企业真…...
python75-Python的函数参数,关键字(keyword)参数
在定义Python函数时可定义形参(形式参数的意思)这些形参的值要等到调用时才能确定下来,由函数的调用者负责为形参传入参数值。简单来说,就是谁调用函数,谁负责传入参数值。 关键字(keyword)参数 Python函数的参数名不是无意义的,…...
Java宝典-抽象类和接口
目录 1. 抽象类1.1 抽象类的概念1.2 抽象类的语法1.3 抽象类的特点 2. 接口2.1 接口的概念2.2 接口的语法2.3 接口的特点2.4 实现多个接口2.5 接口的继承 3. 接口使用案例 铁汁们好,今天我们学习抽象类和接口~ 1. 抽象类 1.1 抽象类的概念 什么是抽象类?在面向对象中,如果一…...
6. Gin集成redis
文章目录 一:连接Redis二:基本使用三:字符串四:列表五:哈希六:Set七:管道八、事务九:示例 代码地址:https://gitee.com/lymgoforIT/golang-trick/tree/master/14-go-redi…...

DxO PureRAW:赋予RAW图像生命,打造非凡视觉体验 mac/win版
DxO PureRAW 是一款专为RAW图像处理而设计的软件,旨在帮助摄影师充分利用RAW格式的优势,实现更加纯净、细腻的图像效果。该软件凭借其强大的功能和易于使用的界面,成为了RAW图像处理领域的佼佼者。 DxO PureRAW 软件获取 首先,Dx…...

【MySQL | 第四篇】区分SQL语句的书写和执行顺序
文章目录 4.区分SQL语句的书写和执行顺序4.1书写顺序4.2执行顺序4.3总结4.4扩充:辨别having与where的异同?4.5聚合查询 4.区分SQL语句的书写和执行顺序 注意:SQL 语句的书写顺序与执行顺序不是一致的 4.1书写顺序 SELECT <字段名> …...
服务器又被挖矿记录
写在前面 23年11月的时候我写过一篇记录服务器被挖矿的情况,点我查看。当时是在桌面看到了bash进程CPU占用异常发现了服务器被挖矿。 而过了几个月没想到又被攻击,这次比上次攻击手段要更高明点,在这记录下吧。 发现过程 服务器用的是4090…...

嵌入式学习day34 网络
TCP包头: 1.序号:发送端发送数据包的编号 2.确认号:已经确认接收到的数据的编号(只有当ACK为1时,确认号才有用) TCP为什么安全可靠: 1.在通信前建立三次握手连接 SYN SYNACK ACK 2.在通信过程中通过序列号和确认号保障数据传输的完整性 本次发送序列号:上次…...

欧科云链:角力Web3.0,香港如何为合规设线?
在香港拥抱Web3.0的过程中,以欧科云链为代表的合规科技企业将凸显更大重要性。 ——据香港商报网报道 据香港明报、商报等媒体报道,港区全国政协兼香港选委界立法会议员吴杰庄在日前召开的全国两会上提出在大湾区建设国际中小企业创新Web3融资平台等提案࿰…...
Android SDK2 (实操三个小目标)
书接上回:Android SDK 1(概览)-CSDN博客 今天讲讲三个实际练手内容,用的是瑞星微的sdk。 1 实操编译Android.bp 首先还是感叹下,现在的系统真的越搞越复杂,最早只有gcc,后面多了make…...

数字编码与字符编码:解锁编程世界的基石
在计算机的世界里,一切信息都是以数字的形式存在。但是,你有没有想过,我们是如何在这个由0和1构成的数字世界中表示复杂的信息,如文本、图像和声音的呢?本篇文章将带你深入探索数字编码与字符编码的奥秘,它…...

C语言-写一个简单的Web服务器(一)
基于TCP的web服务器 概述 C语言可以干大事,我们基于C语言可以完成一个简易的Web服务器。当你能够自行完成web服务器,你会对C语言有更深入的理解。对于网络编程,字符串的使用,文件使用等等都会有很大的提高。 关于网络的TCP协议在…...

MySQL底层原理
1. 请解释MySQL的逻辑架构和物理架构。 MySQL的逻辑架构和物理架构涉及到多个层面,包括网络连接、服务处理、存储引擎以及数据存储等部分。具体如下: 逻辑架构: 连接层(Connection Layer):客户端通过TCP…...
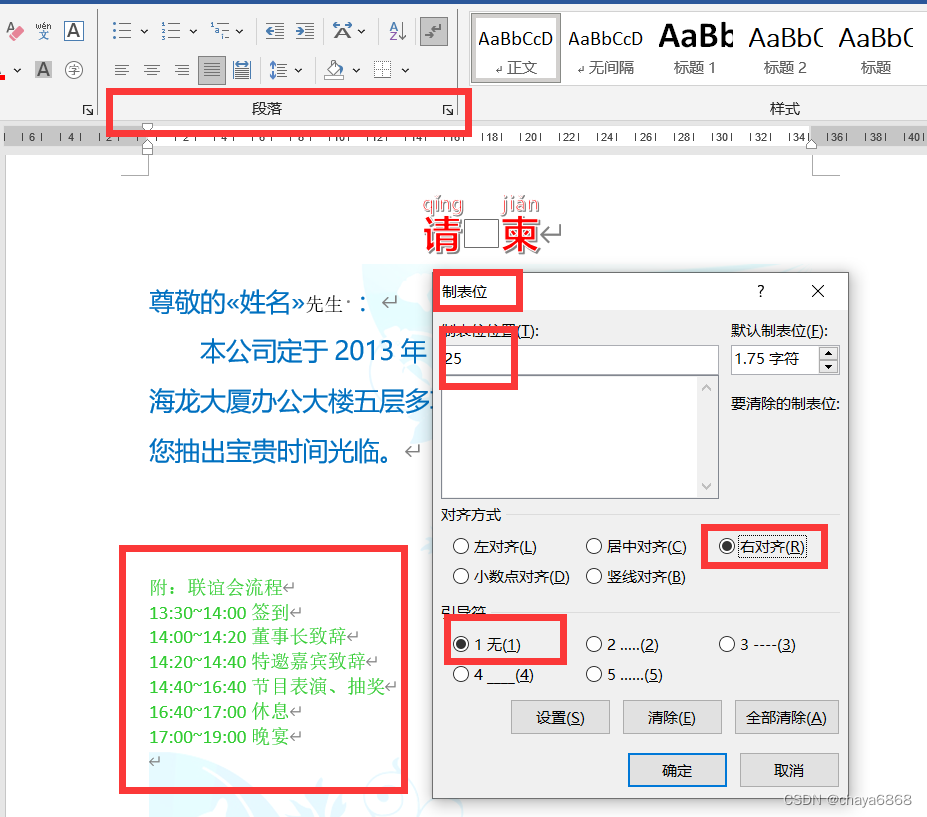
复盘-word
word-大学生网络创业交流会 设置段落,段后行距才有分 word-选中左边几行字进行操作 按住alt键进行选中 word复制excel随excel改变(选择性粘贴) 页边距为普通页边距定义 ##### word 在内容控件里面填文字(调属性)…...

Vue中的组件:构建现代Web应用的基石
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
【从部署服务器到安装autodock vina】
注意:服务器 linux系统选用ubuntu 登录系统,如果没有图形化见面可以先安装图形化界面 可以参考该视频 --> linux安装图形化界面 非阿里云ubuntu 依次执行以下命令 sudo apt-get update sudo apt-get install gnome sudo reboot阿里云ubuntu 需多执…...
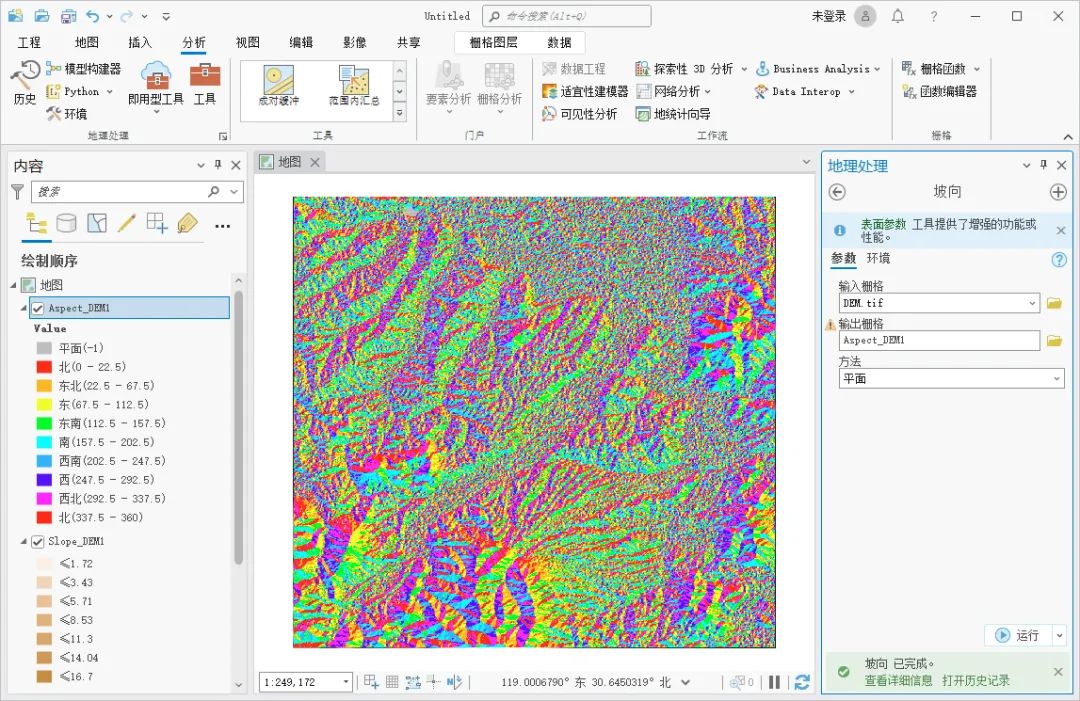
如何使用ArcGIS Pro进行坡度分析
坡度分析是地理信息系统中一种常见的空间分析方法,用于计算地表或地形的坡度,这里为大家介绍一下如何使用ArcGIS Pro进行坡度分析,希望能对你有所帮助。 数据来源 教程所使用的数据是从水经微图中下载的DEM数据,除了DEM数据&…...
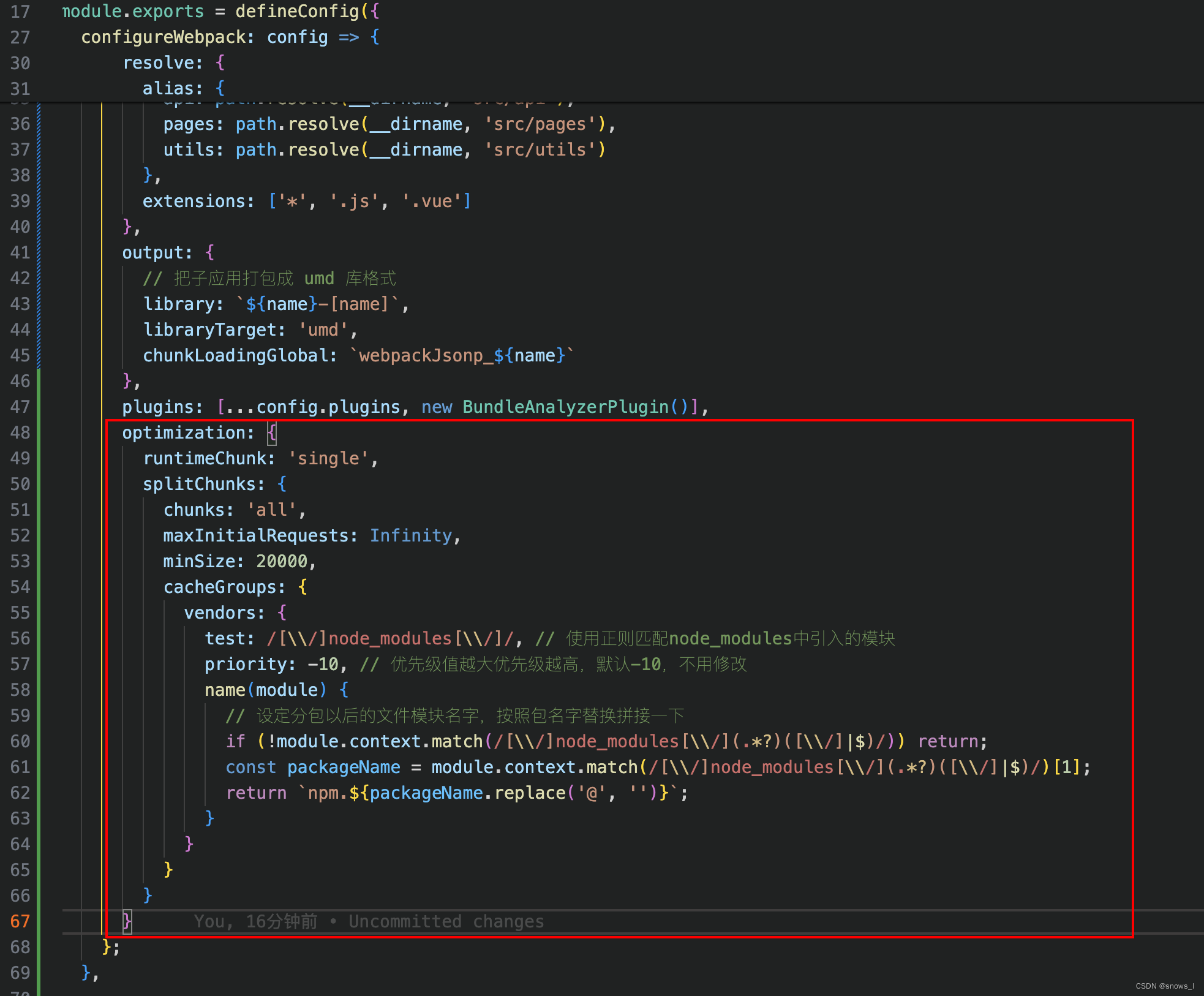
Vue3.2 + vue/cli-service 打包 chunk-vendors.js 文件过大导致页面加载缓慢解决方案
chunk-vendors.js 是/node_modules 目录下的所有模块打包成的包, 但是这包太大导致页面加载很慢(我的都要3-4秒了), 这个时候就会出现白屏的情况 解决方案 1、compression-webpack-plugin 插件解决方案 1)、安装 npm …...
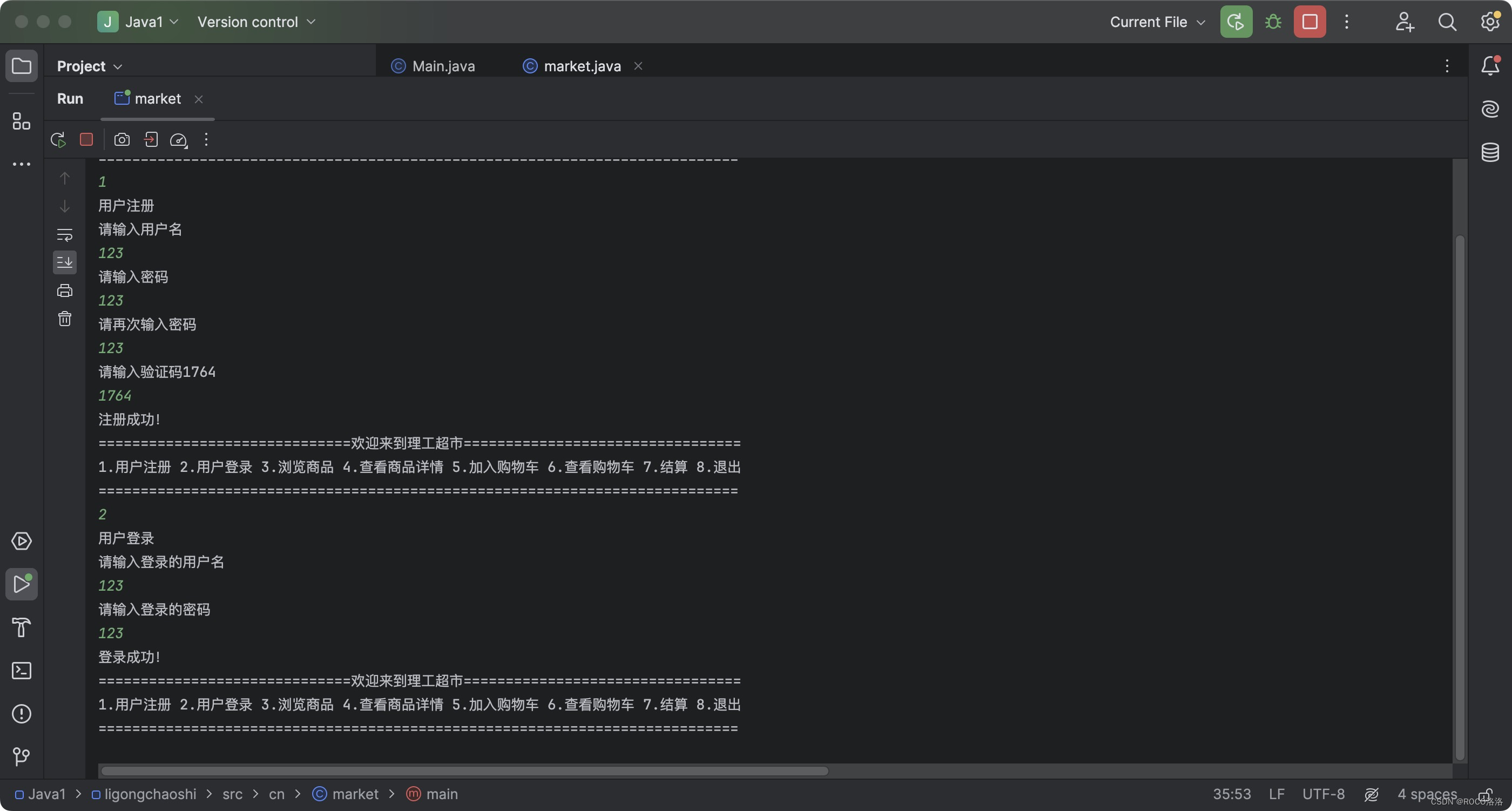
Java学习笔记NO.18
T1.理工超市 (1)题目描述 编写一个程序,设计理工超市功能菜单并完成注册和登录功能的实现。显示完菜单后,提示用户输入菜单项序号。当用户输入<注册>和<登录>菜单序号时模拟完成注册和登录功能,最后提示…...
【JVM】聊聊垃圾回收之三色标记算法
在垃圾收集器 CMS中存在四个阶段,初始标记、并发标记、重新标记、并发清理。 那么在并发标记中由于没有STW,业务程序和GC程序是并发执行的,那么是如何实现对象的并发标记的。 并发垃圾回收 并发标记其实是一个宏观的过程,仍然需…...

CTF全解析:五大核心模块+零基础学习+参赛指南
CTF全解析:五大核心模块零基础学习参赛指南 摘要:CTF(Capture The Flag,夺旗赛)作为网络安全领域最具实战性的竞赛形式,是零基础入门网络安全、锤炼技术、积累求职竞争力的最佳路径。但很多新手刚接触时&a…...
与ISO 26262实践:那些年我们踩过的安全机制坑)
# 020、AutoSAR CP功能安全(FuSa)与ISO 26262实践:那些年我们踩过的安全机制坑
一、从一次诡异的ECU复位说起 上周在联调阶段,某个控制器在连续运行48小时后突然复位。抓到的错误日志里只有一句含糊的“EcuM_Shutdown”。硬件同事查了电源纹波,软件同事翻了任务栈溢出,都没定位到根因。最后在MemIf模块里发现端倪:某个非安全相关的任务写穿了安全内存分…...

Scrcpy不止于投屏:解锁电脑键鼠反向控制Android、多开、录屏等隐藏玩法
Scrcpy不止于投屏:解锁电脑键鼠反向控制Android、多开、录屏等隐藏玩法 在移动办公和跨设备协作成为主流的今天,如何高效地在电脑上操作手机内容成为许多专业人士的痛点。Scrcpy作为一款开源工具,早已超越了基础投屏的范畴,正在重…...

告别混乱!用嘉立创EDA个人/团队库,高效管理你的STM32项目原理图符号
告别混乱!用嘉立创EDA个人/团队库,高效管理你的STM32项目原理图符号 在硬件开发领域,一个精心设计的原理图符号库就像建筑师的标准化图纸——它不仅能显著提升设计效率,还能从根本上避免因符号混乱导致的沟通成本和设计错误。对于…...
)
Gilisoft Total Repair(全能修复大师)
链接:https://pan.quark.cn/s/a8e8b547d1f9Gilisoft Total Repair是一款功能强大的文件修复软件,中文又被成为“全能修复大师”,具有一键式智能修复引擎,可以自动解决500多个常见问题,如系统延迟、游戏崩溃和文件损坏。…...

现在不看就晚了:2026奇点大会刚公布的多模态对话系统“实时语义蒸馏”专利技术,6个月内将成行业准入门槛
第一章:2026奇点智能技术大会:多模态对话系统 2026奇点智能技术大会(https://ml-summit.org) 多模态对话系统正从实验室走向高保真工业部署,2026奇点智能技术大会首次将语音、视觉、文本与触觉信号的联合对齐建模设为技术主线。本届大会展示…...
)
Java SPI实战:从零实现一个可插拔的日志框架(附完整代码)
Java SPI实战:构建可插拔日志框架的深度探索 在当今快速迭代的软件开发领域,模块化和可扩展性已成为架构设计的核心诉求。想象一下这样的场景:你的应用需要同时支持控制台日志、文件日志和网络日志,但又不希望将具体实现硬编码在…...
在汽车电子生命周期中的4种角色)
从ECU复位到产线下线:深度拆解ControlDTCSetting(0x85)在汽车电子生命周期中的4种角色
ECU生命周期中的ControlDTCSetting(0x85)服务:从研发到售后的四维实践指南 当ECU完成最后一次产线测试即将装车时,产线工程师老张习惯性地在EOL终端上输入了一组UDS指令。其中那条ControlDTCSetting(0x85)服务的执行结果让他确认了这个控制单元已经准备好…...

从“失调”到“增益不准”:用Arduino和MCP3008带你直观理解ADC两大静态误差
从“失调”到“增益不准”:用Arduino和MCP3008带你直观理解ADC两大静态误差 在电子测量和数据采集领域,模数转换器(ADC)的性能直接影响整个系统的精度。但对于初学者而言,数据手册上那些抽象的误差参数往往令人望而生畏…...

3种场景解析:如何在不登录微软账户的情况下管理Windows Insider预览版
3种场景解析:如何在不登录微软账户的情况下管理Windows Insider预览版 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: h…...