spark 实验二 RDD编程初级实践
目录
一. pyspark交互式编程示例(学生选课成绩统计)
该系总共有多少学生;
该系DataBase课程共有多少人选修;
各门课程的平均分是多少;
使用累加器计算共有多少人选了DataBase这门课。
二.编写独立应用程序实现数据去重示例
该系共开设了多少门课程?
Tom同学的总成绩平均分是多少?
求每名同学的选修的课程门数?
编写独立应用程序实现求平均值问题
一. pyspark交互式编程示例(学生选课成绩统计)
请下载chapter4-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
【参考答案】
-
该系总共有多少学生;
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).map(lambda x: x[0]) //获取每行数据的第1列 >>> distinct_res = res.distinct() //去重操作>>> distinct_res.count()//取元素总个数//265答案为:265人
-
该系DataBase课程共有多少人选修;
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")>>> res.count()//126答案为126人
-
各门课程的平均分是多少;
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1))) //为每门课程的分数后面新增一列1,表示1个学生选择了该课程。格式如('ComputerNetwork', (44, 1))>>> temp = res.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])) //按课程名聚合课程总分和选课人数。格式如('ComputerNetwork', (7370, 142))>>> avg = temp.map(lambda x:(x[0], round(x[1][0]/x[1][1],2)))//课程总分/选课人数 = 平均分,并利用round(x,2)保留两位小数>>> avg.foreach(print)答案为:
('ComputerNetwork', 51.9)('Software', 50.91)('DataBase', 50.54)('Algorithm', 48.83)('OperatingSystem', 54.94)('Python', 57.82)('DataStructure', 47.57)('CLanguage', 50.61)
使用累加器计算共有多少人选了DataBase这门课。
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")//筛选出选了DataBase课程的数据>>> accum = sc.accumulator(0) //定义一个从0开始的累加器accum>>> res.foreach(lambda x:accum.add(1))//遍历res,每扫描一条数据,累加器加1>>> accum.value //输出累加器的最终值//126答案:共有126人
二.编写独立应用程序实现数据去重示例
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
(1)假设当前目录为/usr/local/spark/mycode/remdup,在当前目录下新建一个remdup.py文件,复制下面代码;
|
(2)最后在目录/usr/local/spark/mycode/remdup下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告);
| $ python3 remdup.py |
(3)在目录/usr/local/spark/mycode/remdup/result下即可得到结果文件part-00000。
拓展
-
该系共开设了多少门课程?
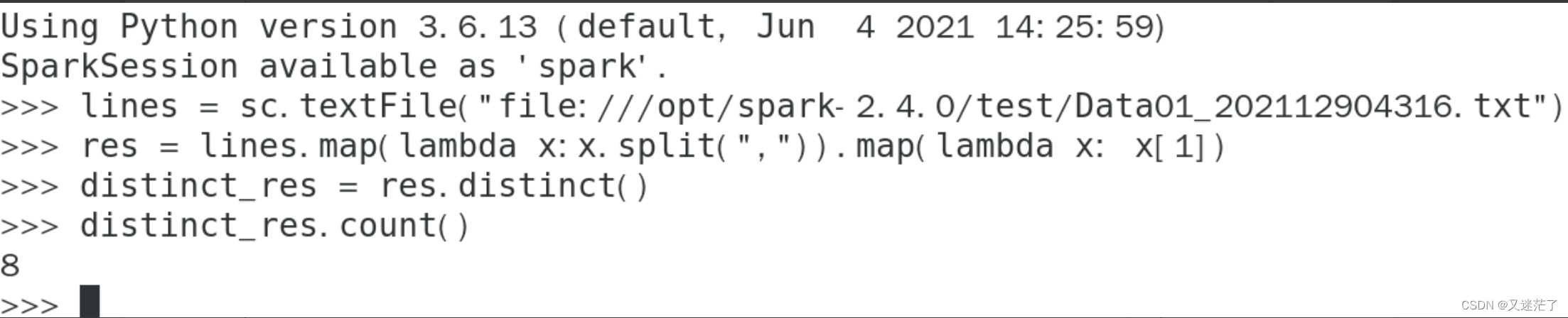
-
Tom同学的总成绩平均分是多少?
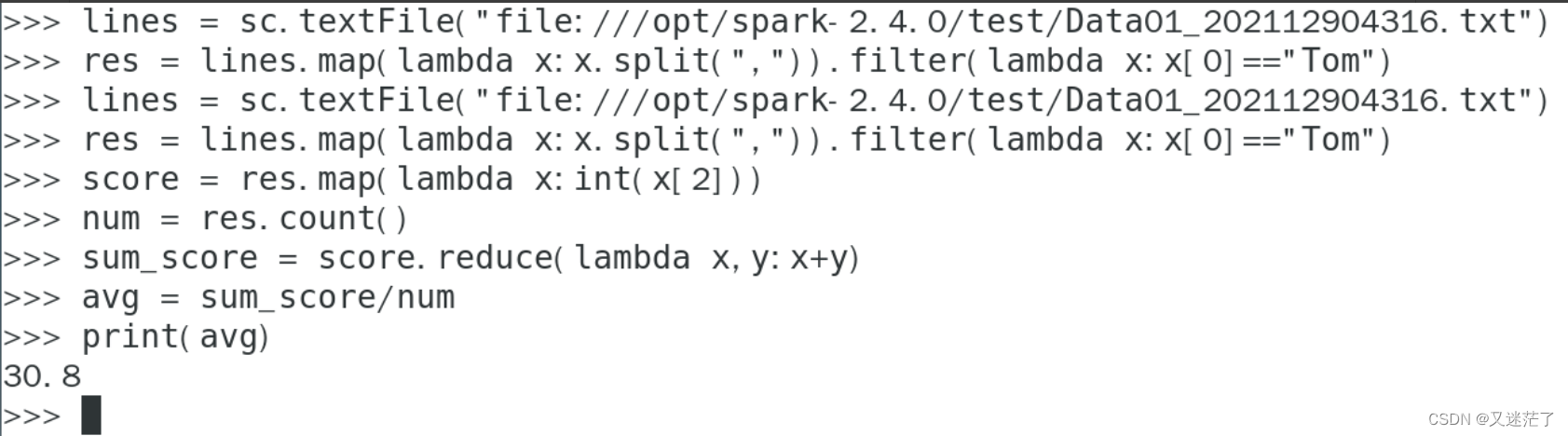
-
求每名同学的选修的课程门数?
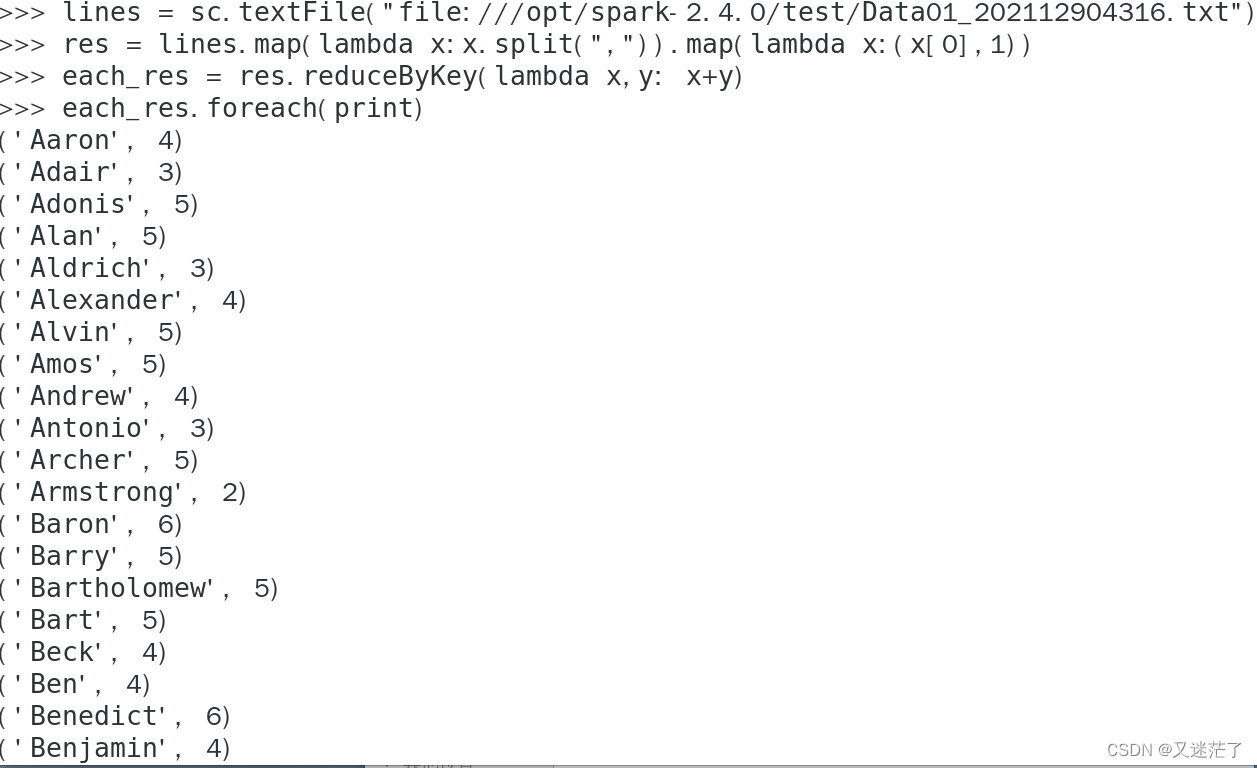
-
编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,
Algorithm成绩(文件名 Algorithm_.txt):
小明 92
小红 87
小新 82
小丽 90
Database成绩(文件名 Database_.txt):
小明 95
小红 81
小新 89
小丽 85
Python成绩(文件名 Python_.txt):
小明 82
小红 83
小新 94
小丽 91
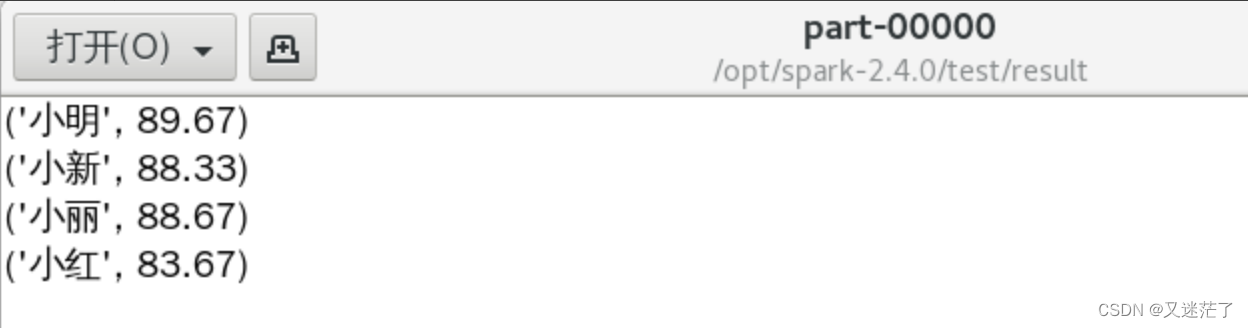
平均成绩格式如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
相关文章:
spark 实验二 RDD编程初级实践
目录 一. pyspark交互式编程示例(学生选课成绩统计) 该系总共有多少学生; 该系DataBase课程共有多少人选修; 各门课程的平均分是多少; 使用累加器计算共有多少人选了DataBase这门课。 二.编写独立应用程序实现数…...
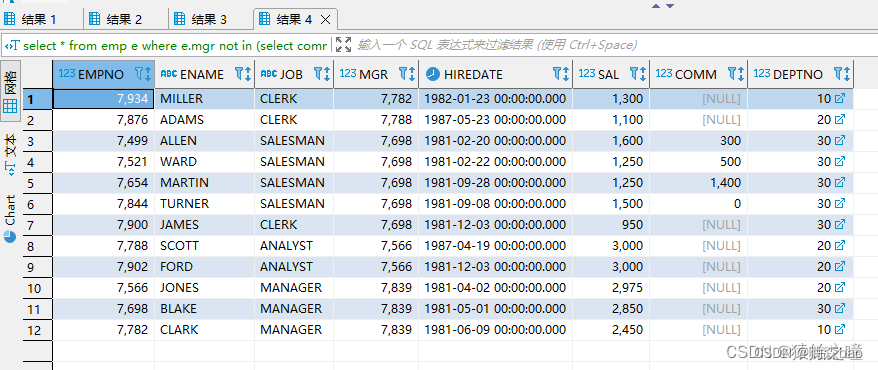
【MySQL】not in遇上null的坑
今天遇到一个问题: 1、当 in 内的字段包含 null 的时候,正常过滤; 2、当 not in 内的字段包含 null 的时候,不能正常过滤,即使满足条件,最终结果也为 空。 测试如下: select * from emp e;当…...

鸿蒙4.0-DevEco Studio界面工程
DevEco Studio界面工程 DevEco Studio 下载与第一个工程新建的第一个工程界面回到Project工程结构来看 DevEco Studio 下载与第一个工程 DevEco Studio 下载地址:点击跳转 https://developer.harmonyos.com/cn/develop/deveco-studio#download 学习课堂以及文档地址…...
前端将html导出pdf文件解决分页问题
这是借鉴了qq_251025116大佬的解决方案并优化升级完成的,原文链接 1.安装依赖 npm install jspdf html2canvas2.使用方法 import htmlToPdffrom ./index.jsconst suc () > {message.success(success);};//记得在需要打印的div上面添加 idlet dom document.que…...
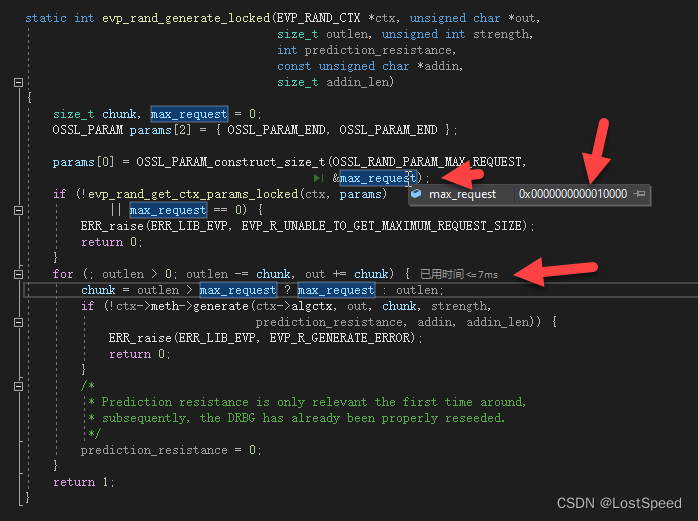
openssl3.2 - exp - 产生随机数
文章目录 openssl3.2 - exp - 产生随机数概述笔记END openssl3.2 - exp - 产生随机数 概述 要用到openssl产生的随机数, 查了资料. 如果用命令行产生随机数, 如下: openssl rand -hex -num 6 48bfd3a64f54单步跟进去, 看到主要就是调用了一个RAND_bytes(), 没其他了. 官方说…...
[]有何不同?)
【三两波折】char *foo[]和char(*foo)[]有何不同?
1、先谈优先级 最高级别 —— 有四个,他们并不像运算符: []数组下标左到右结合()用于(表达式) or 函数名(形参表)左到右结合.读取结构体成员左到右结合->读取结构体成员(通过指针)左到右结合 第二级别…...
怎么查看pod服务对应哪些docker容器)
k8s(kubernetes)怎么查看pod服务对应哪些docker容器
Kubernetes(k8s)中的Pod是一组共享网络和存储资源的容器集合。每个Pod都包含一个或多个Docker容器,这些容器共享网络命名空间和存储卷,并在同一主机上运行。因此,可以将Pod视为一组紧密相关的Docker容器的逻辑主机&…...
)
[2023年]-hadoop面试真题(二)
[2023年]-hadoop面试真题(一) (北京) Maptask的个数由什么决定?(北京) 如何判定一个job的map和reduce的数量 ?(北京) MR中Shuffle过程 ?(北京) MR中处理数据流程 ?(…...
蓝桥杯备战刷题-滑动窗口
今天给大家带来的是滑动窗口的类型题,都是十分经典的。 1,无重复字符的最长子串 看例三,我们顺便来说一下子串和子序列的含义 子串是从字符串里面抽出来的一部分,不可以有间隔,顺序也不能打乱。 子序列也是从字符串里…...
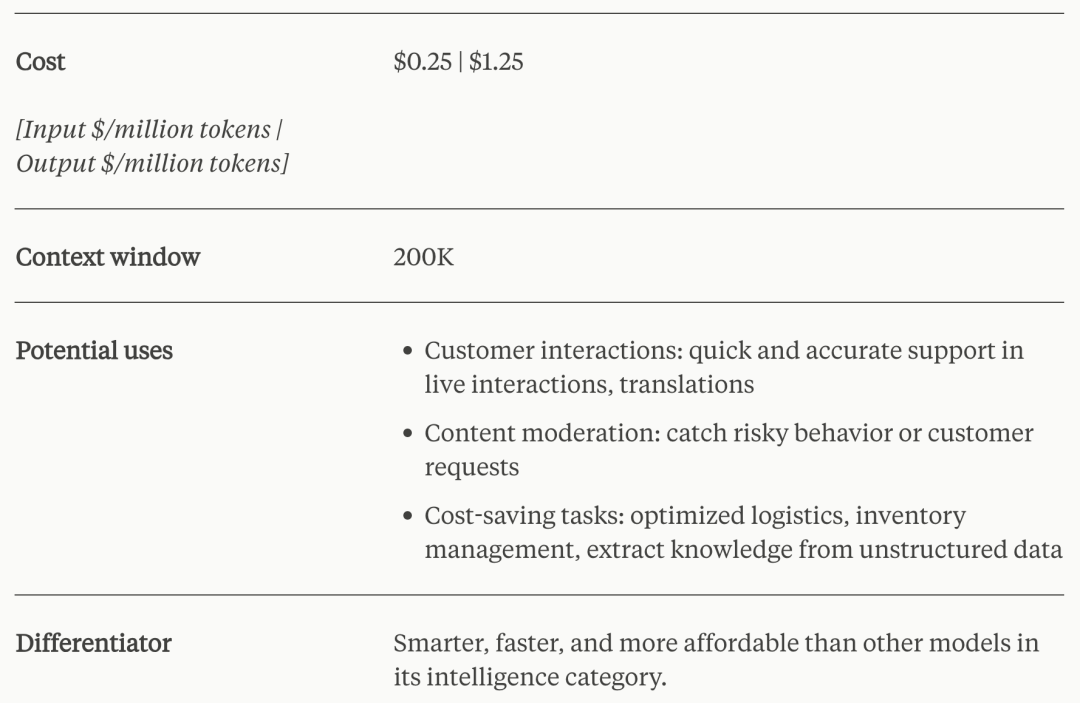
LLM(十一)| Claude 3:Anthropic发布最新超越GPT-4大模型
2024年3月4日,Anthropic发布最新多模态大模型:Claude 3系列,共有Haiku、Sonnet和Opus三个版本。 Opus在研究生水平专家推理、基础数学、本科水平专家知识、代码等10个维度,超过OpenAI的GPT-4。 Haiku模型更注重效率,能…...
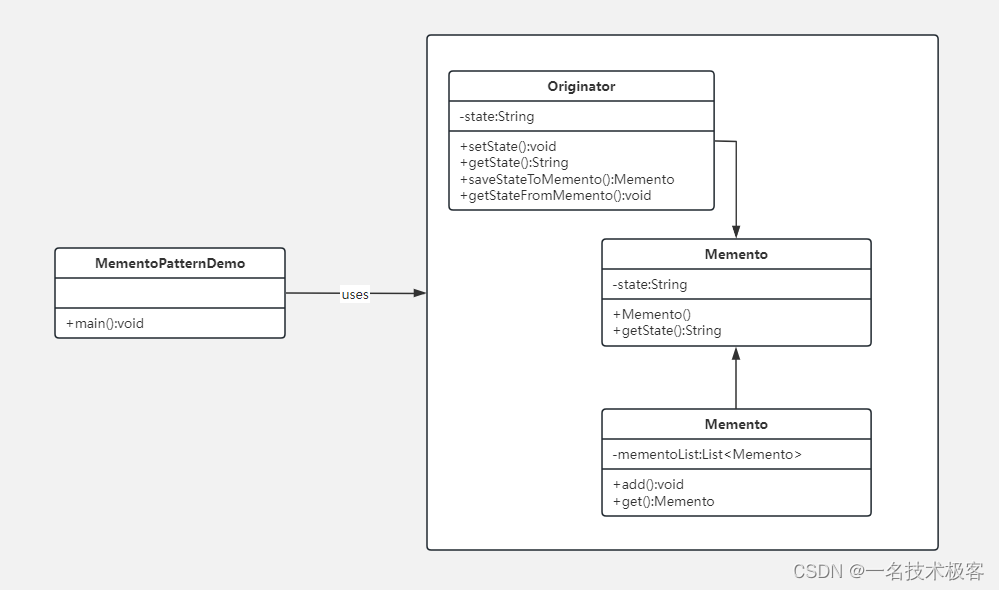
20-Java备忘录模式 ( Memento Pattern )
Java备忘录模式 摘要实现范例 备忘录模式(Memento Pattern)保存一个对象的某个状态,以便在适当的时候恢复对象 备忘录模式属于行为型模式 摘要 1. 意图 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对…...

整合生成型AI战略:从宏观思维到小步实践
“整合生成型AI战略:从宏观思维到小步实践” 在这篇文章中,我们探讨了将生成型AI和大型语言模型融入企业核心业务的战略开发方法。我们的方法基于敏捷开发原则,技术专家和数据科学家需要采纳商业思维,而执行官则需理解生成型AI和…...
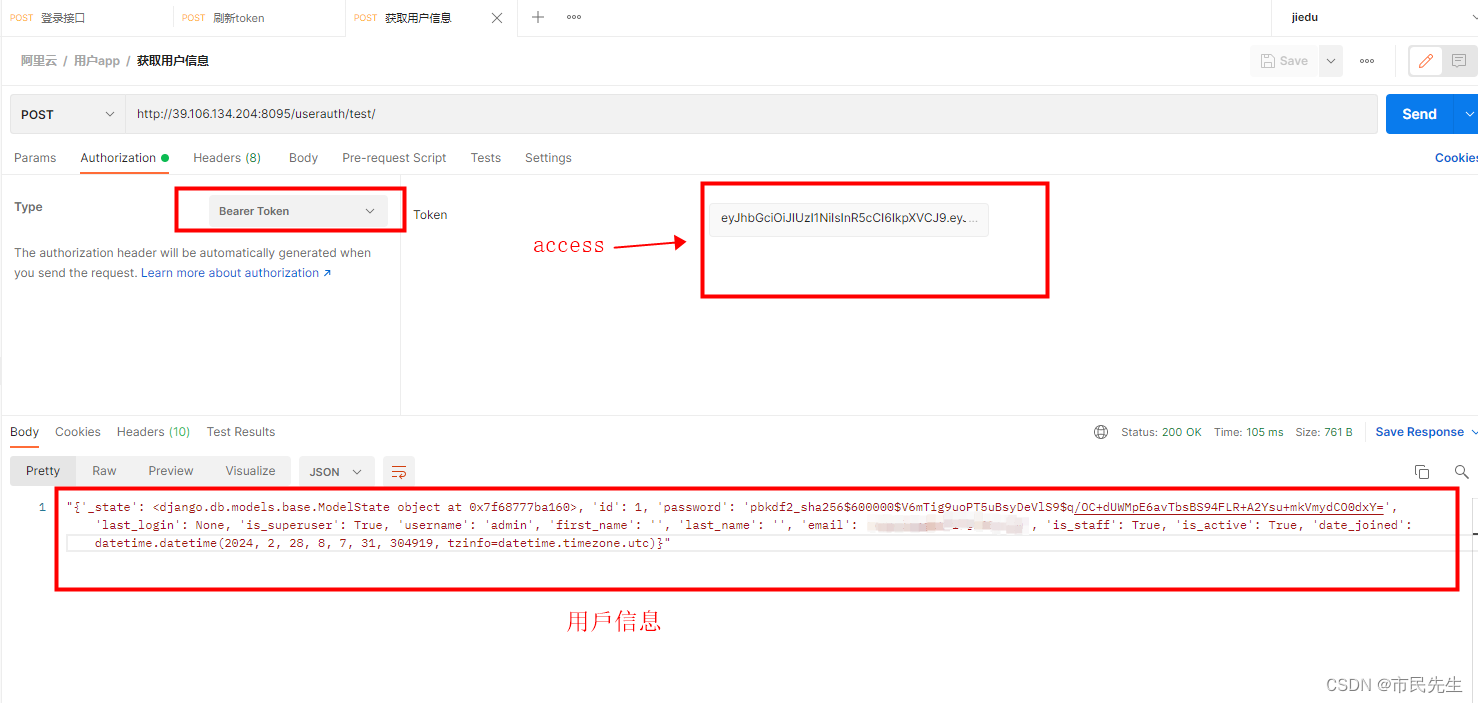
个人博客系列-后端项目-用户验证(5)
介绍 创建系统管理app,用于管理系统的用户,角色,权限,登录等功能,项目中将使用django-rest_framework进行用户认证和权限解析。这里将完成用户认证 用户验证 rest_framework.authentication模块中的认证类ÿ…...
css3中nth-child属性作用及用法剖析
hello宝子们...我们是艾斯视觉擅长ui设计和前端开发10年经验!希望我的分享能帮助到您!如需帮助可以评论关注私信我们一起探讨!致敬感谢感恩! 标题:CSS3中nth-child属性作用及用法剖析 摘要:CSS3中的nth-child选择器允许我们根据元素位置来定位特定的元素…...

okHttp MediaType MIME格式详解
一、介绍 我们在做数据上传时,经常会用到Okhttp的开源库,okhttp开源库也遵循html提交的MIME数据格式。 所以我们经常会看到applicaiton/json这样的格式在传。 但是如果涉及到其他文件等就需要详细的数据格式,否则服务端无法解析 二、okHt…...

跨境电商三大趋势
跨境电商有着不断发展的三大趋势: 个性化定制:随着消费者需求的不断变化和个性化定制的潮流,跨境电商平台开始提供更多的定制化服务。消费者可以根据自己的需求选择产品的款式、材料和设计,从而获得更加个性化的产品体验。 无界销…...
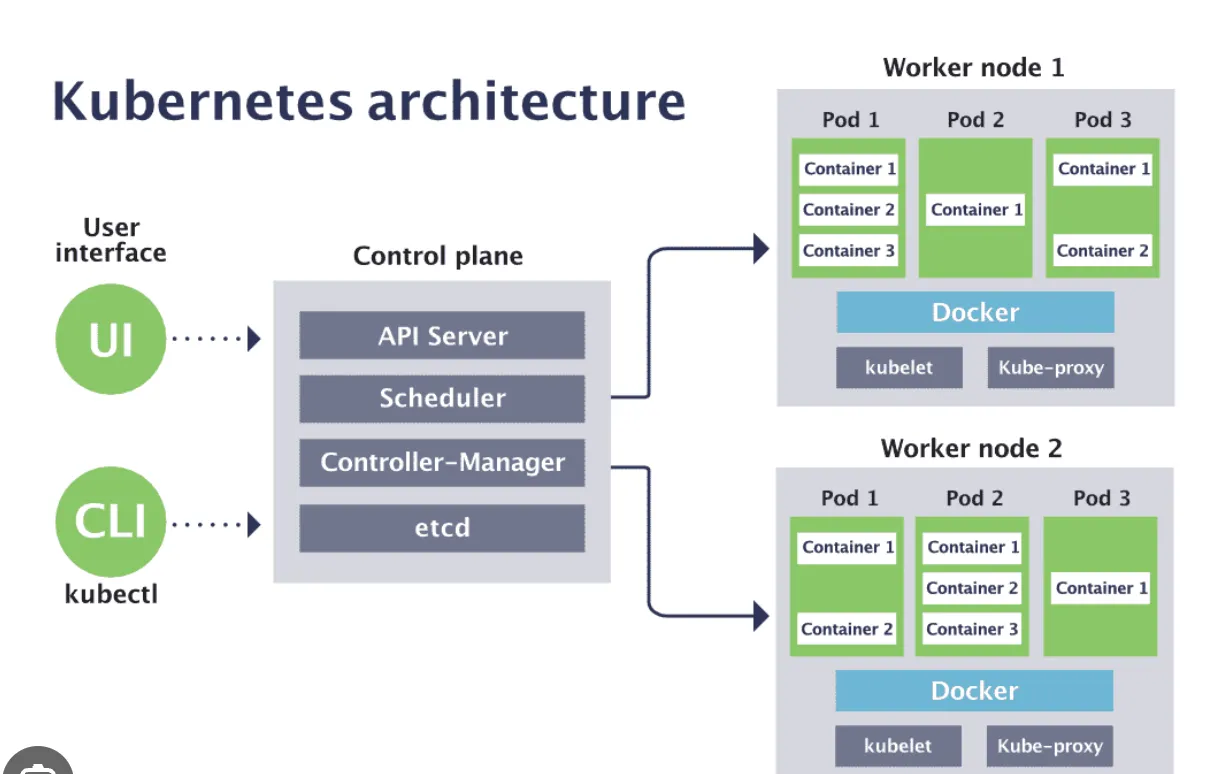
【DevOps基础篇之k8s】如何通过Kubernetes CKA认证考试
【DevOps基础篇之k8s】如何通过Kubernetes CKA认证考试 目录 【DevOps基础篇之k8s】如何通过Kubernetes CKA认证考试核心概念资源监控生命周期管理Cluster维护安全认证问题排查其他推荐超级课程: Docker快速入门到精通Kubernetes入门到大师通关课这些是我在准备CK...

Mysql数据库-基本表操作
1.表操作 创建表:CREATE TABLE table_name ( field1 datatype, field2 datatype, field3 datatype ) character set 字符集 collate 校验规则 engine 存储引擎; field 表示列名 datatype 表示列的类型 character set 字符集,如果没有指定字符集ÿ…...
)
OceanBase社区版单节点安装搭建(Docker)
OceanBase社区版单节点安装搭建(Docker) 文章目录 OceanBase社区版单节点安装搭建(Docker)一、环境检查及Docker配置1.1 安装docker1.2 配置docker镜像源 二、OB镜像下载三、obd部署单节点数据库四、创建业务租户、数据库、表4.1 …...
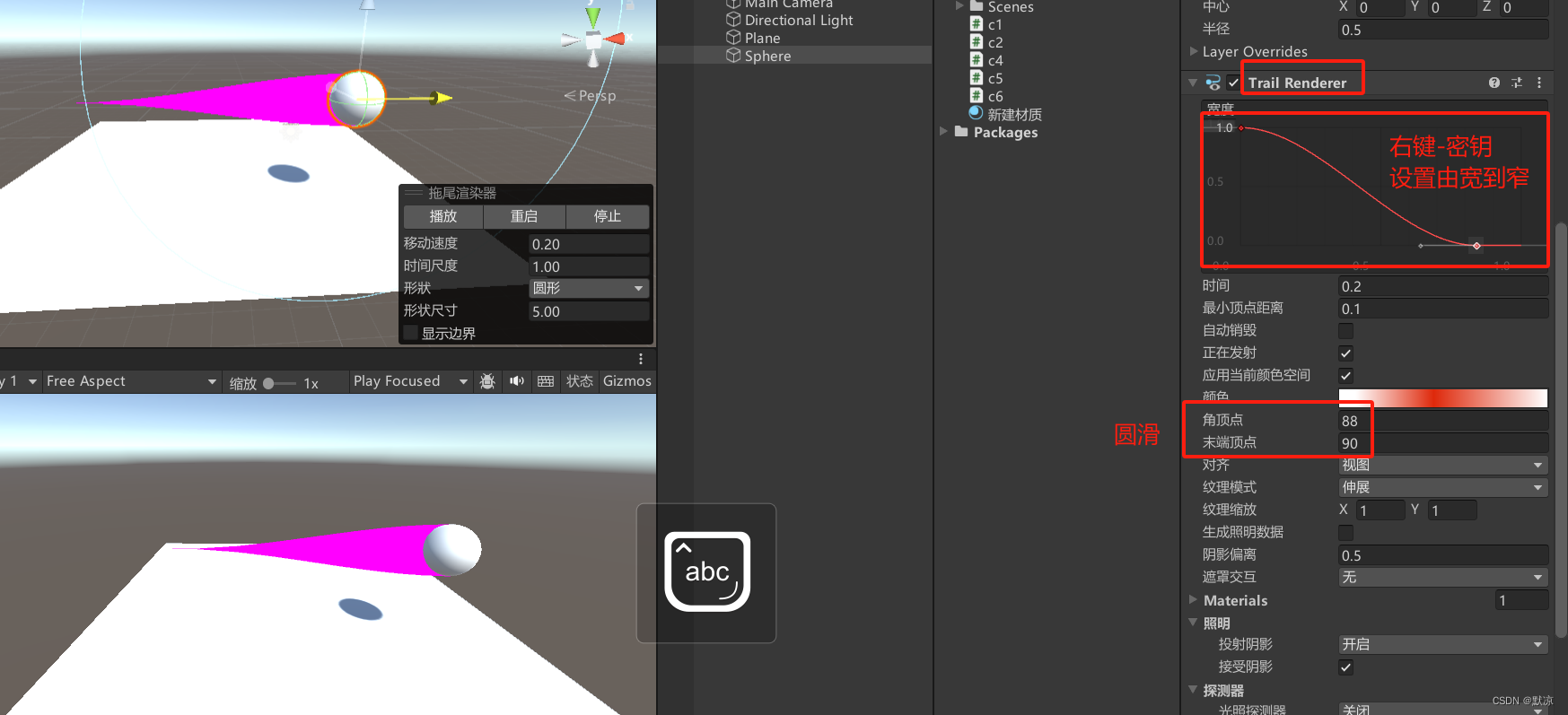
Unity 关节:铰链、弹簧、固定、物理材质:摩檫力、 特效:拖尾、
组件-物理-关节:铰链(类似门轴) 自动动作、多少力可以将其断开、 弹簧可以连接另一个刚体(拖动即可) 固定一般是等待一个断裂力,造成四分五裂的效果。 物理材质 设置摩檫力,则可以创造冰面的…...

Cursor界面深度定制:从Settings汉化到个性化语言包制作
1. 为什么需要深度定制Cursor界面? 作为一名长期使用Cursor的开发者,我深刻理解官方英文界面带来的不便。每次打开设置菜单都要在脑海中自动翻译,特别是团队协作时,非技术背景成员面对满屏英文设置项时的茫然表情让我印象深刻。Cu…...

HoRain云--ASP 变量
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...

四川厨房设备平台的赋能逻辑与核心优势
四川作为餐饮产业大省,川味餐饮(火锅、川菜、特色小吃等)的规模化发展,推动商用厨房设备市场持续扩容。据行业数据统计,四川商用厨房设备市场年增速稳定在12%,但行业长期存在的产业链割裂、供需匹配低效、服…...

2025届必备的六大AI写作网站推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 作为大语言模型的DeepSeek,在学术论文写作里能够发挥多重辅助功能,在…...

Chrome文本替换插件终极指南:如何智能编辑任何网页内容
Chrome文本替换插件终极指南:如何智能编辑任何网页内容 【免费下载链接】chrome-extensions-searchReplace 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-extensions-searchReplace 在浏览网页时,你是否曾遇到过需要修改页面内容却无能为…...

跨境电商降本增效利器:HY-MT1.5-1.8B翻译模型部署与优化
跨境电商降本增效利器:HY-MT1.5-1.8B翻译模型部署与优化 1. 引言:跨境电商的翻译痛点与解决方案 在跨境电商运营中,语言障碍是影响业务扩展的关键因素。从商品详情页的多语言适配到客服沟通的实时翻译,传统解决方案往往面临三大…...

亚洲美女-造相Z-Turbo效果可视化:同一提示词下不同采样步数与CFG Scale影响分析
亚洲美女-造相Z-Turbo效果可视化:同一提示词下不同采样步数与CFG Scale影响分析 想用AI生成一张好看的亚洲美女图片,是不是经常遇到这样的困惑:明明提示词写得挺详细,但出来的图要么模糊不清,要么表情僵硬,…...
,而是专注于“感知-决策-动作”端到端学习的 AI 框架。他们共同成为具身智能时代最重要的开源基础设施之一)
[具身智能-364]:LeRobot 不是通用机器人控制系统(如 ROS2 导航/规划栈),而是专注于“感知-决策-动作”端到端学习的 AI 框架。他们共同成为具身智能时代最重要的开源基础设施之一
LeRobot 与 ROS2 并非替代关系,而是“智能生成”与“可靠执行”的双轨架构。二者共同构成了下一代机器人从“实验室原型”走向“物理世界部署”的基石。以下从定位差异、架构协同、融合挑战、演进趋势四个维度进行系统阐述。🔍 一、核心定位与设计哲学&a…...

Mitogen上下文管理实战:从本地到SSH的完整部署清单
Mitogen上下文管理实战:从本地到SSH的完整部署清单 【免费下载链接】mitogen Distributed self-replicating programs in Python 项目地址: https://gitcode.com/gh_mirrors/mi/mitogen Mitogen是一个基于Python的分布式自复制程序框架,通过高效的…...

Android-Mediasession-播放状态监控
Android 监控 MediaSession 播放状态并打印包名的 Java 实现 下面是一个完整的 Java 示例,展示如何系统级监控所有应用的 MediaSession 播放状态,并打印当前正在播放的应用包名。 📦 一、核心原理 通过 MediaSessionManager 获取所有活跃的 M…...