爬虫实战——scrapy框架爬取多张图片
scrapy框架的基本使用,请参考我的另一篇文章:scrapy框架的基本使用
起始爬取的网页如下:
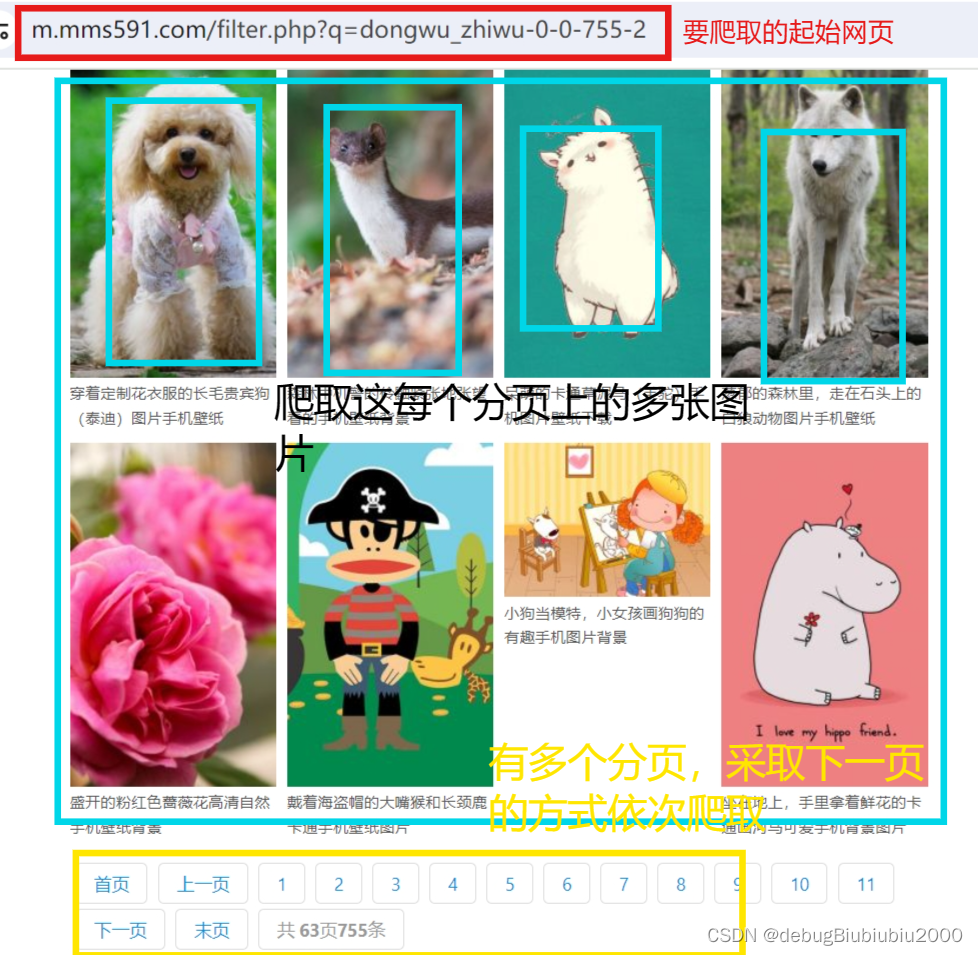
点击每张图片,可以进入图片的详情页,如下:
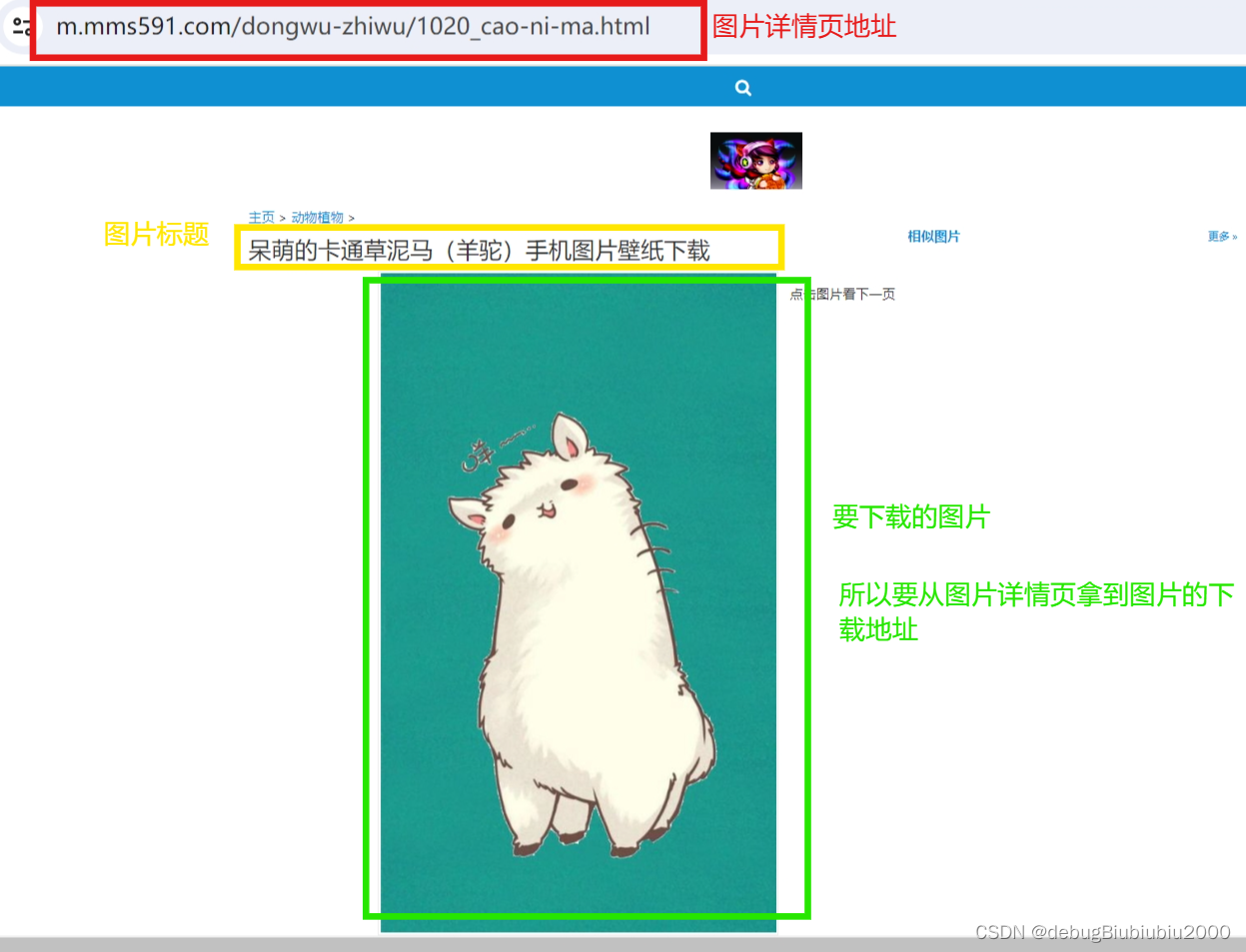
代码实现:
项目文件结构如下
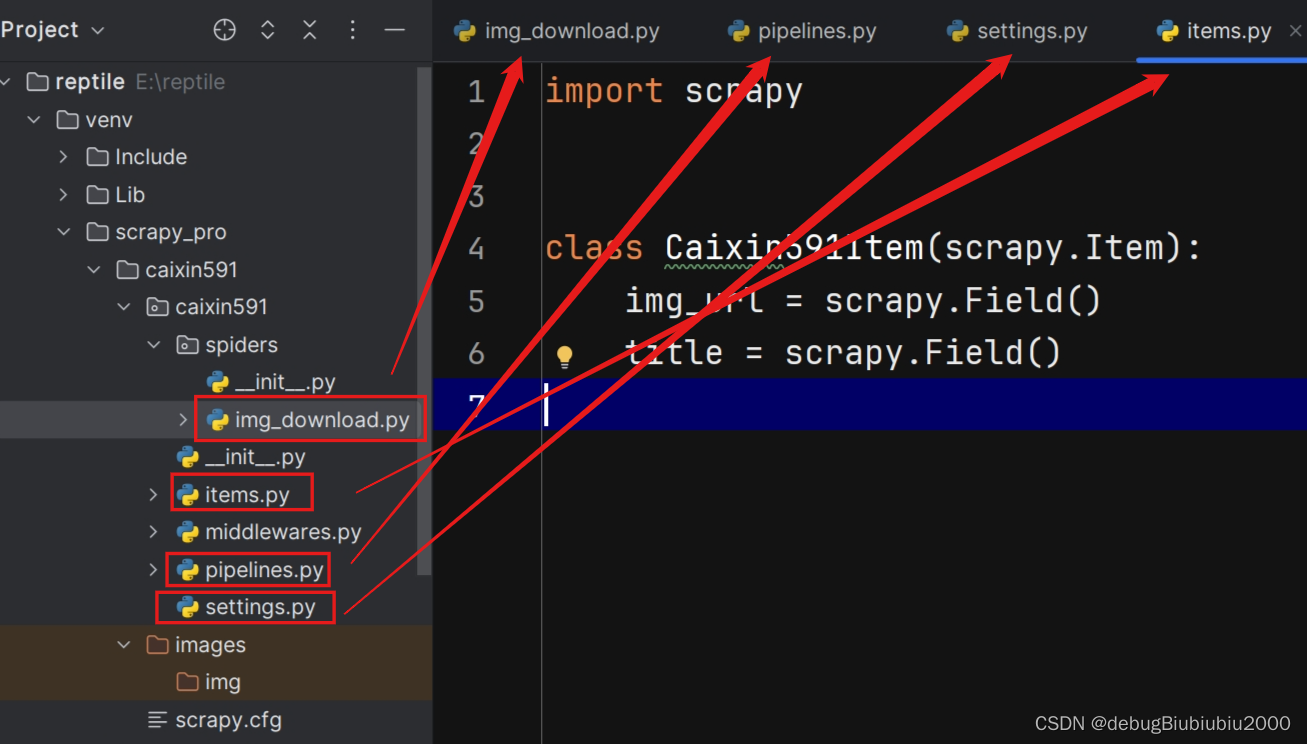
img_download.py文件代码
import scrapy
# 这里导包的时候会显示报错,但其实不影响运行,如果想去掉,可以百度一下方法
from caixin591.items import Caixin591Itemclass ImgDownloadSpider(scrapy.Spider):name = "img_download"allowed_domains = ["m.mms591.com"]# 修改默认的爬虫入口# start_urls = ["https://m.mms591.com"]start_urls = ["https://m.mms591.com/filter.php?q=dongwu_zhiwu-0-0-755-2"]def parse(self, response, **kwargs):# print(response.text) # 打印页面源代码# 从页面源代码中拿到图片详情网址# 这里有多种方法进行解析,大家可以按照自己的思路来# 我这里先拿到每个图片所在lilis = response.xpath('//div[@class="am-list-news-bd"]/ul/li')for li in lis:href = li.xpath('./div/a/@href').extract_first()# 这里拿到的地址是不完整的,需要拼接完整的URL# print(href) # '/dongwu-zhiwu/1015_he-ma.html'# 之前我们是用from urllib.parse import urljoin进行拼接# 但是scrapy中的response对象有相应的URL拼接方法detail_img = response.urljoin(href)# print(detail_img) # https://m.mms591.com/dongwu-zhiwu/1023_qi-e.html# 向图片的详情地址发送请求# 之前我们说爬虫程序要么解析出具体的数据,传递给引擎,然后通过引擎传递给通道# 要么解析出新的URL,然后传递给引擎,引擎封装成request对象,再给调度器# 所以这里我们解析出了一个新的URL,那么就封装成request对象,# 至于引擎是怎么给调度器、怎么发送这个请求得到数据的不用我们关心req = scrapy.Request(url=detail_img, # 要请求的地址method='get', # 请求的方式# 这里是自定义一个解析函数# 请求返回的内容交给谁进行数据解析callback=self.parse_detail_page)# 把请求返回给引擎yield reqbreak# 上面的过程只下载了一页图片,如果我们想下载多页图片,可以在这里进行# 可以一次性拿到所有分页的URL,然后协程或者for循环进行下载# 这里采取拿到“下一页”这个按钮的URL,然后一页一页的下载# 相当于不断地手动点击下一页这个按钮# 从页面中获取下一页按钮的URL# 这里的URL也是不完整的,需要拼接next_page_url = response.xpath(# a[contains(text(), "下一页")] 表示获取文本内容包含“下一页”的a标签'//ul[@data-am-widget="pagination"]/li/a[contains(text(), "下一页")]/@href').extract_first()print(next_page_url)if next_page_url: # 如果有下一页yield scrapy.Request(url=response.urljoin(next_page_url),method='get',# 请求返回的又是一页新的有多个图片的页面,解析逻辑桶上面,所以调用parse方法callback=self.parse)def parse_detail_page(self, response):"""在这个函数里对图片的详情页进行解析,这个方法是自定义的:param response: 请求详情页网址时返回的内容:return:"""# print(response.text)# 拿到图片真正的下载地址img_url = response.xpath('//img[@class="mainimg"]/@src').extract_first()# print(img_url)title = response.xpath('//h3/text()').extract_first()# print(title)item = Caixin591Item()item['img_url'] = img_urlitem['title'] = titleyield item # 把具体的数据传递给管道settings.py文件代码(删掉了没有用到的注释代码)
BOT_NAME = "caixin591"SPIDER_MODULES = ["caixin591.spiders"]
NEWSPIDER_MODULE = "caixin591.spiders"# Obey robots.txt rules
ROBOTSTXT_OBEY = TrueITEM_PIPELINES = {"caixin591.pipelines.Caixin591Pipeline": 300,"caixin591.pipelines.DownloadImgPipeline": 299
}# 配置日志界别
LOG_LEVEL = 'WARNING'# 配置保存图片的文件夹
IMAGES_STORE = './images'# 要配置这个,否则图片管道下载图片的时候会报错:
# File (code: 301): Error downloading file from <GET http:...> referred in <None>
MEDIA_ALLOW_REDIRECTS = TrueREQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"pipelines.py文件代码
import scrapy
from scrapy.pipelines.images import ImagesPipelineclass Caixin591Pipeline:def process_item(self, item, spider):return item# 下载图片
# 这里利用图片管道完成图片下载操作
# 注意要在settings文件中配置保存文件的文件夹
class DownloadImgPipeline(ImagesPipeline):# 下面三个方法都是重写ImagesPipeline类中的def get_media_requests(self, item, info):# 本方法负责发送请求进行下载# item 就是爬虫程序传递过来的数据# img_url是图片真正的下载地址,发送请求后会返回图片的字节信息# 而把图片的字节存储起来这一操作我们不需要关心# 只需要实现这三个方法就可以完成下载图片到本地这一需求req = scrapy.Request(url=item['img_url'], method='get')return req # 把请求返回给引擎# 上面是封装一个请求然后下载一次,应该也可以先封装好所有请求然后一起下载# 但是我没尝试过,感兴趣的可以试一试def file_path(self, request, response=None, info=None, *, item=None):# 本方法负责提供图片文件的存储路径# request这里对应着上面方法get_media_requests中的req# 一个图片对应一个req# 和以前一样,我们以URL的最后一部分命名图片# 请求的URL可以通过request.url获取file_name = request.url.split('/')[-1]return f'img/{file_name}' # 返回图片文件的存储路径def item_completed(self, results, item, info):# 本方法可以拿到文件的详细信息# 可以自己打印出来看看具体有什么东西# print(results)# print(item)# print(info)passitems.py文件代码
import scrapyclass Caixin591Item(scrapy.Item):img_url = scrapy.Field()title = scrapy.Field()相关文章:
爬虫实战——scrapy框架爬取多张图片
scrapy框架的基本使用,请参考我的另一篇文章:scrapy框架的基本使用 起始爬取的网页如下: 点击每张图片,可以进入图片的详情页,如下: 代码实现: 项目文件结构如下 img_download.py文件代码 im…...

LLVM TableGen 系统学习笔记
Basic TableGen 系统可以帮助记录领域特定的信息。它也可以认为是一种小型的编译系统。 TableGen 责负分析文件, 分析结果交给领域特定的后端进行处理。 重要的概念 records 一个 record 有一个独立的名称,一系列值和一系列父类。 它保存了特定领域…...

基于stm32的流水灯设计
1基于stm32的流水灯设计[proteus仿真] 速度检测系统这个题目算是课程设计和毕业设计中常见的题目了,本期是一个基于51单片机的自行车测速系统设计 需要的源文件和程序的小伙伴可以关注公众号【阿目分享嵌入式】,赞赏任意文章 2¥,…...

kotlin图片合成和压缩
kotlin图片合成和压缩 之前的方法是继承AsyncTask 在doInBackground 里面去做压缩的操作,然后用 publishProgress 切到主线程里面更新 新方法是在协程里的去做 class ImageService {private fun getSumWidths(bitmaps: ArrayList<Bitmap>): Int {var sumWid…...

Java学习笔记004——接口概念理解及意义
一个类中有抽象方法,则必须声明为abstract(做为抽象类),抽象类不能实例化。子类继承抽象类,必须对所有的抽象方法重写,否则依然有抽象方法,还是抽象的,无法实例化。故抽象类常做为基…...

MT笔试题
前言 某团硬件工程师的笔试题,个人感觉题目的价值还是很高的,分为选择题和编程题,选择题考的是嵌入式基础知识,编程题是两道算法题,一道为简单难度,一道为中等难度 目录 前言选择题编程题 选择题 C语言中变…...

50道SQL面试题
50道SQL面试题 有需要互关的小伙伴,关注一下,有关必回关,争取今年认证早日拿到博客专家 环境 -- ---------------------------- -- Table structure for teacher -- ---------------------------- DROP TABLE IF EXISTS teacher; CREATE TABLE teacher (t_id varchar(20) …...
2024蓝桥杯每日一题(双指针)
一、第一题:牛的学术圈 解题思路:双指针贪心 仔细思考可以知道,写一篇综述最多在原来的H指数的基础上1,所以基本方法可以是先求出原始的H指数,然后分类讨论怎么样提升H指数。 【Python程序代码】 n,l map(int,…...

Android 开发过程中常见的内存泄漏场景分析
场景1 Static变量存储上下文环境Context public class ClassName {// 定义1个静态变量private static Context mContext;//... // 引用的是Activity的contextmContext context; // 当Activity需销毁时,由于mContext 静态 & 生命周期 应用程序的生命周期&…...
)
Codeforces-1935E:Distance Learning Courses in MAC(思维)
E. Distance Learning Courses in MAC time limit per test 2 seconds memory limit per test 256 megabytes input standard input output standard output The New Year has arrived in the Master’s Assistance Center, which means it’s time to introduce a new feature…...

ZooKeeper和Diamond有什么不同
本文主要是讨论下两个类似产品:ZooKeeper和Diamond在配置管理这个应用场景上的异同点。 Diamond,顾名思义,寄寓了开发人员对产品稳定性的厚望,希望它像钻石一样,提供稳定的配置访问。Diamond是淘宝网Java中间件团队的核…...
三、N元语法(N-gram)
为了弥补 One-Hot 独热编码的维度灾难和语义鸿沟以及 BOW 词袋模型丢失词序信息和稀疏性这些缺陷,将词表示成一个低维的实数向量,且相似的词的向量表示是相近的,可以用向量之间的距离来衡量相似度。 N-gram 统计语言模型是用来计算句子概率的…...

QML 3D入门知识路线
目前使用的版本 v5.14.0 模块导入 使用QML 3D时需要 import Qt3D.Core 2.14 核心模块类 V6以上的版本已经发布,所以有很多module会发生变化,主要有核心module、输入、逻辑、渲染、动画和扩展module,以及2D/3D场景模块 类名 能…...
)
蓝牙系列五:开源蓝牙协议BTStack框架代码阅读(1)
蓝牙学习系列,借鉴卫东上老师的蓝牙视频教程。 BTStack协议栈学习。首先来看一下,对于硬件操作,它是如何来进行处理的。在上篇文章中曾说过,在main函数里面它会调用硬件相关的代码,调用操作系统相关的代码。在BTStack中,可以搜索一下main.c,将会发现有很多main.c,都是…...

c++ 类内可以定义引用数据成员吗?
在C中,类内是可以定义引用数据成员的,但是在初始化对象时,必须在构造函数的成员初始化列表中对引用进行初始化,因为引用必须在创建时被初始化,并且不能在其生存期内引用不同的对象。下面是一个简单的示例: …...
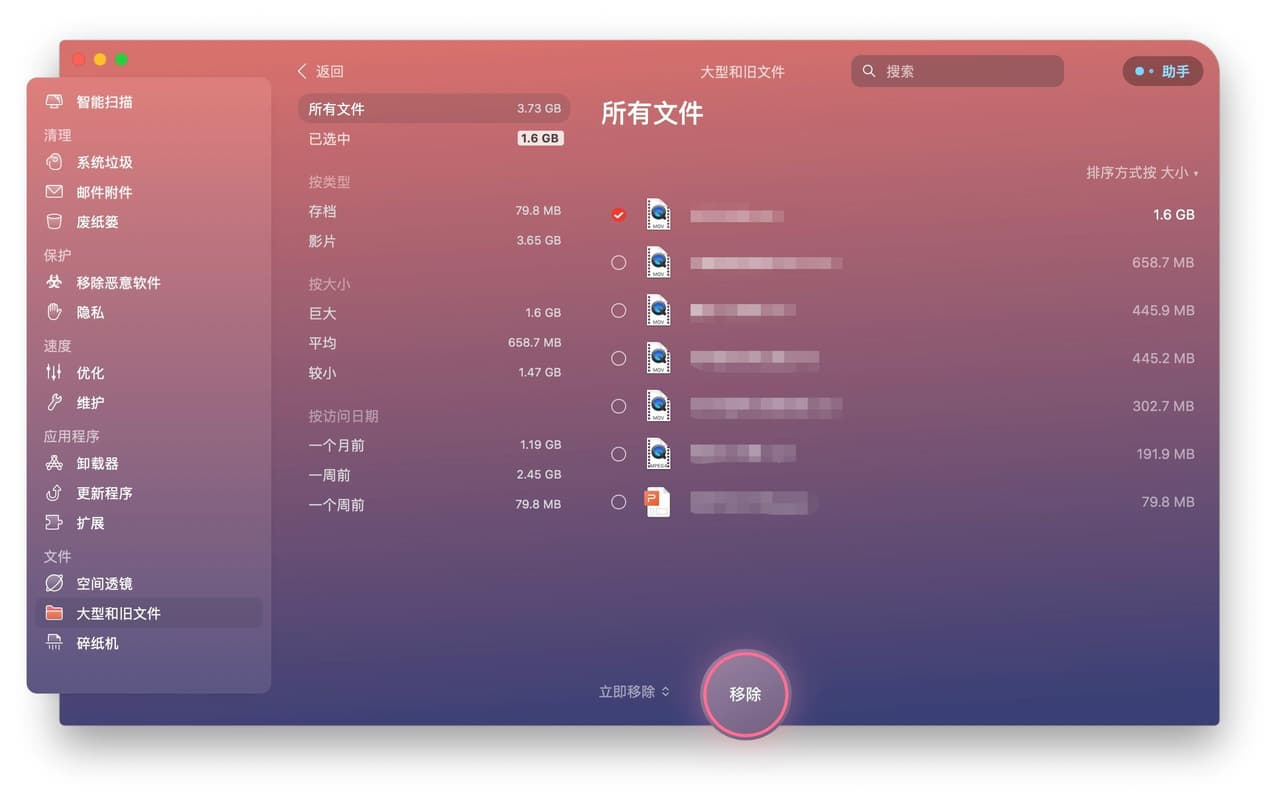
MacBook2024苹果免费mac电脑清理垃圾软件CleanMyMac X
CleanMyMac X是一款专业的Mac清理软件,具备多种强大功能。首先,它能够智能清理Mac磁盘上的垃圾文件和多余语言安装包,从而快速释放电脑内存。其次,CleanMyMac X可以轻松管理和升级Mac上的应用,同时强力卸载恶意软件并修…...

Vue.js计算属性:实现数据驱动的利器
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
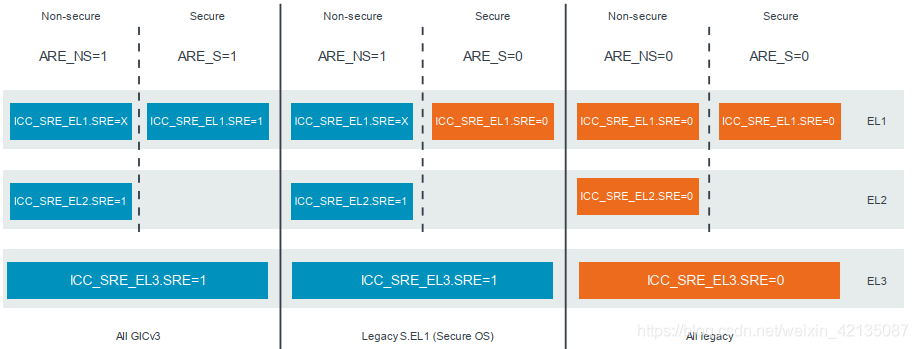
10-ARM gicv3/gicv4的总结-基础篇
目录 1、gic的版本2、GICv3/gicv4的模型图3、gic中断号的划分4、GIC连接方式5、gic的状态6、gic框架7、gic Configuring推荐 本文转自 周贺贺,baron,代码改变世界ctw,Arm精选, armv8/armv9,trustzone/tee,s…...

数据库系统概论(超详解!!!) 第三节 关系数据库
1.基本概念 1. 域(Domain) 域是一组具有相同数据类型的值的集合。 2. 笛卡尔积(Cartesian Product) 给定一组域D1,D2,…,Dn,允许其中某些域是相同的。 D1,D2…...
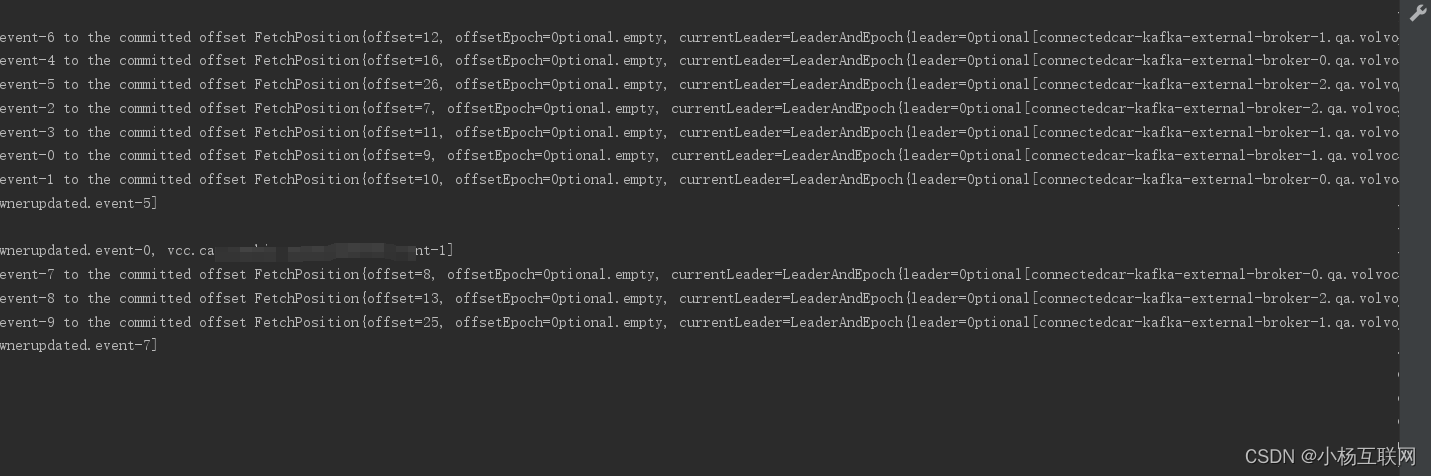
Springboot 集成kafka 消费者实现ssl方式连接监听消息实现消费
证书准备:springboot集成kafka 消费者实现 如何配置是ssl方式连接的时候需要进行证书的转换。原始的证书是pem, 或者csr方式 和key方式的时候需要转换,因为kafka里面是jks 需要通过openssl进行转换。 证书处理: KeyStore 用于存储客户端的证…...

Kook Zimage真实幻想Turbo效果炸裂!高清梦幻人像作品集首发
Kook Zimage真实幻想Turbo效果炸裂!高清梦幻人像作品集首发 1. 梦幻人像生成新标杆 当第一次看到Kook Zimage真实幻想Turbo生成的作品时,我作为一个从业多年的数字艺术创作者,也不禁为它的表现力所震撼。这款基于Z-Image-Turbo底座的幻想风…...

Secure boot入门-2fip包加载image流程
本小节从代码的角度去看下,代码环境准备还是参考之前的文章:ATF入门-1qmeu搭建ARM全套源码学习环境,不用开发板免费学习ARM。 secure boot在arm上需要用到fip包,这里以bl1加载bl2为例,bl2.bin是在fip.bin里面进行打包…...

华硕无畏Pro14 K6400ZC 原厂Win11 21H2系统分享下载
华硕无畏Pro14 K6400ZC配备了一键恢复功能,方便用户在系统异常或更换硬盘后轻松恢复出厂设置。该功能支持Windows 11 21H2家庭版系统,并通过原厂工厂文件和隐藏恢复分区实现。用户只需准备一个20G以上的U盘,按照提供的安装教程操作即可完成系…...

通义千问2.5-7B-Instruct部署优化:量化模型仅4GB显存占用
通义千问2.5-7B-Instruct部署优化:量化模型仅4GB显存占用 1. 引言 在本地部署大语言模型时,显存占用一直是开发者面临的主要挑战之一。传统70亿参数模型通常需要12GB以上显存,而通义千问2.5-7B-Instruct通过量化技术实现了突破性优化&#…...

2026最权威的六大AI科研方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 作为具有先进性的大语言模型的DeepSeek,在论文写作里能够发挥出有着多种不同情况…...

FUTURE POLICE在会议场景的落地:实时语音转写与多说话人区分
FUTURE POLICE在会议场景的落地:实时语音转写与多说话人区分 每次开完会,你是不是都有这样的感觉:讨论得热火朝天,但会后整理纪要却成了大难题。谁说了什么?关键结论是什么?光靠回忆和手写记录,…...

Wan2.2-I2V-A14B新手必看:WebUI界面各模块功能图解与操作动线
Wan2.2-I2V-A14B新手必看:WebUI界面各模块功能图解与操作动线 1. 开篇导览:认识你的视频创作助手 当你第一次打开Wan2.2-I2V-A14B的WebUI界面时,可能会被各种选项和参数搞得有点懵。别担心,这个界面其实设计得非常直观ÿ…...

Laravel 8 中实现错误日志与调试日志分离的完整配置指南
本文详解如何在 Laravel 8 中精准分离错误日志(laravel.log)与调试日志(debug.log),通过自定义日志通道、调整默认通道及显式调用策略,彻底避免错误消息误写入调试日志文件。 本文详解如何在 laravel …...
发布Android 开发库到Maven私服)
【我的Android进阶之旅】快速创建和根据不同的版本类型(Dev、Beta、Release)发布Android 开发库到Maven私服
文章目录 前言 一、准备好要上传的Android 开发库 二、编写上传Maven私服的脚本 2.1 maven_upload.gradle文件 2.2 maven_user.properties配置文件 2.3 maven_pom.properties配置文件 三、执行上传maven的gradle脚本文件 3.1 上传成功 3.2 上传失败 四、使用maven私服中的库文件…...

中科院与京东联手突破AI训练难题:让机器像老师一样自我反思学习
这项由中国科学院信息工程研究所联合中科院网络空间安全学院和京东公司共同完成的研究于2026年发表,论文编号arXiv:2604.03128v1,为人工智能领域的自我学习训练方法带来了重要突破。在人工智能快速发展的今天,如何让机器更聪明地学习始终是科…...