总结:Spring创建Bean循环依赖问题与@Lazy注解使用详解
总结:Spring创建Bean循环依赖问题与@Lazy注解使用详解
- 一·前提知识储备:
- 1.Spring Bean生命周期机制(IOC)
- 2.Spring依赖注入机制(DI)
- (1)@Autowired注解标注属性set方法注入
- (2)@Autowired注解标注属性注入
- (3)@Autowired注解标注构造方法注入,也可用于存在多个构造方法时,手动指明Spring框架使用哪个构造方法创建Bean
- 3.了解一定的JVM类加载原理机制
- (1)第一次使用new关键字调用类构造方法创建对象时,会触发类加载机制,然后再执行类实例化机制
- (2)每创建一个对象,就会触发类实例化机制一次,注意不是类加载机制
- (3)先产生一个对象的内存地址,再调用类的 `clinit`方法(由编译器自动生成,用于初始化静态变量和执行静态初始化块的代码),最后才执行类的构造方法。
- (4)因此一个对象的内存地址,可以在构造方法结束之前暴露出来。但Spring中所谓的提前暴露bean对象地址,都是指构造方法结束之后暴露,而不是构造方法结束之前暴露
- 4.@Lazy注解使用:
- (1)使用地方:类、方法、构造方法、方法参数、属性字段。必须标注在IOC容器管理的bean上才会生效,否则无效果
- (2)功能作用:Springboot项目启动时,懒加载Bean。即只会分配对象地址并暴露在IOC容器里面,但不会立即执行该Bean的实例化操作(构造方法)
- (3)标注在类上示例:延迟创建
- (4)标注在方法上示例:延迟注入
- (5)标注在构造方法参数上示例:延迟注入。直接标注在构造方法上面没效果,加在构造方法参数上才有效果
- (6)标注在属性字段上示例:
- 二·什么是Spring Bean循环依赖问题:
- 1.类A中存在类B属性,类B中存在类C属性,类C中存在类A属性,等类似情况:
- 2.类A中存在类A属性,等类似情况:
- 3.Spring项目启动会报异常提示:
- 三·如何解决Spring Bean循环依赖:
- 方案一:尽量避免双向依赖(根本上解决):设计时尽量避免双向依赖,因为双向依赖很容易导致循环依赖的发生。(推荐)
- 方案二:使用构造函数注入 + @Lazy注解:(推荐)
- 方案三:使用字段属性注入 + application.yml配置:
- 方案四:使用字段属性注入 + @Lazy注解:(推荐)
- 四·Spring解决循环依赖的底层原理:概述
- 1.三级缓存容器:
- 2.为什么Bean 都已经实例化了,还需要一个生产 Bean 的ObjectFactory工厂呢?
- 3.三级缓存容器工作流程示例:假设现在需要实例化两个对象:A、B
- (1)不存在循环依赖、或者存在循环依赖但不存在AOP操作:
- (2)存在循环依赖、存在AOP操作:
- 4.为什么要再包装一层ObjectFactory对象存入三级缓存呢?说是为了解决Bean对象存在AOP代理情况,那么直接生成代理对象半成品Bean放入二级缓存中,这不就可以省略三级缓存了吗?所以这使用三级缓存的意义在哪里?
- 5.使用构造器注入,造成的循环依赖,三级缓存机制无法自动解决:
- 6.为什么构造器注入,配合@Lazy注解就能解决循环依赖问题呢?
- 7·参考文献链接:
一·前提知识储备:
1.Spring Bean生命周期机制(IOC)

注意:bean实例化就是指调用构造方法创建bean的过程
参考详情文献:
https://blog.csdn.net/riemann_/article/details/118500805
2.Spring依赖注入机制(DI)
参考详情文献:
https://juejin.cn/post/6857406008877121550#heading-17
(1)@Autowired注解标注属性set方法注入
@Component
public class Dog {// 私有成员变量private Cat cat;// 使用@Autowired注解标注setter方法@Autowiredpublic void setCat(Cat cat) {this.cat = cat;}// 其他业务逻辑...
}
(2)@Autowired注解标注属性注入
@Component
public class Dog {@Autowiredprivate Cat cat;
}
(3)@Autowired注解标注构造方法注入,也可用于存在多个构造方法时,手动指明Spring框架使用哪个构造方法创建Bean
@Component
public class Dog {private Cat cat;@Autowiredpublic Dog(Cat cat) {this.cat = cat;}
}
3.了解一定的JVM类加载原理机制
参考详情文献:
https://blog.csdn.net/weixin_48033662/article/details/135246047
(1)第一次使用new关键字调用类构造方法创建对象时,会触发类加载机制,然后再执行类实例化机制
(2)每创建一个对象,就会触发类实例化机制一次,注意不是类加载机制
(3)先产生一个对象的内存地址,再调用类的 clinit方法(由编译器自动生成,用于初始化静态变量和执行静态初始化块的代码),最后才执行类的构造方法。
(4)因此一个对象的内存地址,可以在构造方法结束之前暴露出来。但Spring中所谓的提前暴露bean对象地址,都是指构造方法结束之后暴露,而不是构造方法结束之前暴露
示例代码如下:
public class Example {private String value;private Example next;public Example(String value) {// 开启新线程并让其尝试访问this.valuenew Thread(() -> {//将当前对象内存地址,赋给next属性,提前暴露当前对象地址System.out.println("异步线程next:" + next);System.out.println("新线程:" + this.value);}).start();//将当前对象内存地址,赋给next属性,提前暴露当前对象地址next = this;System.out.println("主线程next:" + next);// 睡眠一段时间模拟初始化耗时操作try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}this.value = value;System.out.println("构造方法内部:value已初始化为 " + this.value);}public static void main(String[] args) {Example example = new Example("Hello, World!");// 此时example引用已经可以获取,但value字段还未初始化System.out.println("example:" + example);}
}
4.@Lazy注解使用:
(1)使用地方:类、方法、构造方法、方法参数、属性字段。必须标注在IOC容器管理的bean上才会生效,否则无效果
@Target({ElementType.TYPE, ElementType.METHOD, ElementType.CONSTRUCTOR, ElementType.PARAMETER, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Lazy {/*** Whether lazy initialization should occur.*/boolean value() default true;}
(2)功能作用:Springboot项目启动时,懒加载Bean。即只会分配对象地址并暴露在IOC容器里面,但不会立即执行该Bean的实例化操作(构造方法)
注意:
(1)简述:虽然会创建该类的一个对象,但是不会执行该对象的构造方法
(2)没有标注该注解或者进行特定配置时,Springboot项目启动时,会默认将扫描范围内的所有Bean进行实例化操作(既创建该类对象,又执行该对象的构造方法)
(3)标注在类上示例:延迟创建
@Lazy
@Component
public class Cat {private String name;private int age;public Cat() {System.out.println("Cat无参构造方法执行");}
}
(4)标注在方法上示例:延迟注入
注意:@Lazy注解 + @Configuration注解同时标注在类上,会作用所有@Bean注册的类实例
@Configuration
public class IocConfig {@Lazy@Beanpublic Dog dog(){return new Dog();}
}
(5)标注在构造方法参数上示例:延迟注入。直接标注在构造方法上面没效果,加在构造方法参数上才有效果
@Component
public class Cat {private Dog dog;@Autowiredpublic Cat(@Lazy Dog dog) {this.dog = dog;}
}
(6)标注在属性字段上示例:
@Component
public class Cat {@Lazy@Autowiredprivate Dog dog;
}
二·什么是Spring Bean循环依赖问题:
1.类A中存在类B属性,类B中存在类C属性,类C中存在类A属性,等类似情况:

示例代码:
类A
@Component
public class A {@Autowiredprivate B b;
}
类B:
@Component
public class B {@Autowiredprivate C c;
}
类C:
@Component
public class C {@Autowiredprivate A a;
}
2.类A中存在类A属性,等类似情况:

示例代码:
@Component
public class A {@Autowiredprivate A a;
}
3.Spring项目启动会报异常提示:
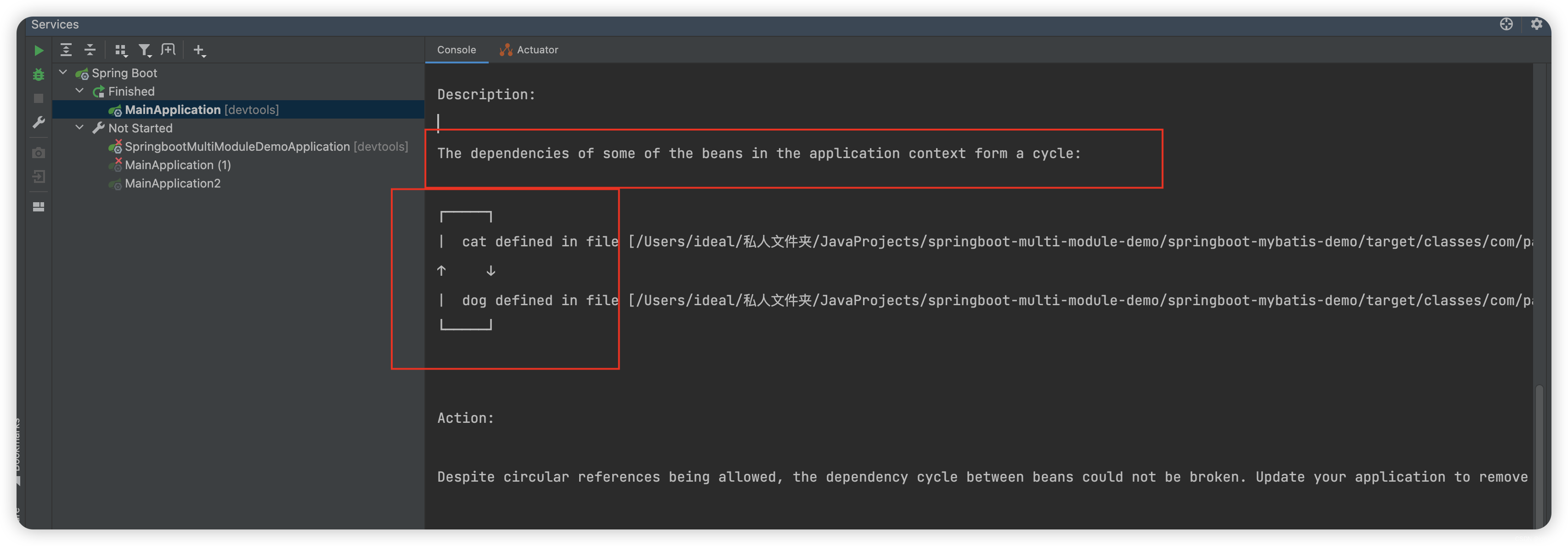
三·如何解决Spring Bean循环依赖:
方案一:尽量避免双向依赖(根本上解决):设计时尽量避免双向依赖,因为双向依赖很容易导致循环依赖的发生。(推荐)
方案二:使用构造函数注入 + @Lazy注解:(推荐)
(1)当有两个类互相依赖时,只要在任意一个类的构造方法上,将另一方参数标注@Lazy注解即可打破循环引用;当然两个类构造方法互相都加也行
(2)若很多个类才构成循环依赖,则建议直接将每个类的构造方法上对方参数都标注@Lazy注解;否则你就一个个去分析循环依赖,然后再单个加@Lazy注解吧
注意:构造函数注入是解决循环依赖问题的最佳方式之一,因为它能够保证Bean在实例化时所有依赖已经注入。
示例代码:
@Component
public class Cat {private Dog dog;/*** 构造方法注入属性对象时,被标注@Lazy注解的参数对象,并不会直接触发Dog类的实例化操作,* 而是会先放入一个dog的代理对象在这里,当后面该dog的代理对象被第一次调用时,才会触发Dog的实例化操作,* 但是生成的实例化对象并不会替换原本的代理对象,只会将实例化对象注入代理对象里面。* (代理对象在其内部维护对实际实例的引用,在后续每次调用时,代理对象都会将请求转发给已经实例化的原生对象,并返回原生对象的方法执行结果)* @param dog*/@Autowiredpublic Cat(@Lazy Dog dog) {//注意这里不能在构造方法里面调用dog对象,一旦调用就会立即触发Dog的实例化操作this.dog = dog;}
}
@Component
public class Dog {private Cat cat;//只要保证一方加了@Lazy注解就行@Autowiredpublic Dog(@Lazy Cat cat) {this.cat = cat;}
}
方案三:使用字段属性注入 + application.yml配置:
application.yml配置如下:
#允许Spring循环引用配置,默认是关闭的
spring:main:allow-circular-references: true
(1)开启后Springboot会主动尝试利用三级缓存机制来打破循环引用。如果实在打破不了,就会抛循环引用异常让用户自己解决(可以配合@Lazy注解解决)
(2)一般使用@Autowired注入属性的循环依赖,都可以被Springboot主动打破
(3)Spring无法解决单纯由构造器注入导致的循环依赖,因为Java语言本身的特性决定了构造器调用必须在一个实例化阶段完成,无法通过延后注入的方式打破循环(可以配合@Lazy注解解决)
(4)非单例bean造成的循环引用,Spring也无法自动解决
代码示例:
@Component
public class Cat {@Autowiredprivate Dog dog;//手动指明使用哪个构造方法创建bean@Autowiredpublic Cat() {System.out.println("Cat无参构造方法执行");}
}
@Component
public class Dog {@Autowiredprivate Cat cat;@Autowiredpublic Dog() {System.out.println("Dog无参构造方法执行");}
}
方案四:使用字段属性注入 + @Lazy注解:(推荐)
(1)当有两个类互相依赖时,只要在任意一个类中另一方的属性字段上标注@Lazy注解,即可打破循环引用;当然两个类相都加也行
(2)若很多个类才构成循环依赖,则建议直接将每个类的另一方属性字段都标注@Lazy注解;否则你就一个个去分析循环依赖,然后再单个加@Lazy注解吧
代码示例:
@Component
public class Cat {@Lazy@Autowiredprivate Dog dog;@Autowiredpublic Cat() {System.out.println("Cat无参构造方法执行");}
}
@Component
public class Dog {@Lazy@Autowiredprivate Cat cat;@Autowiredpublic Dog() {System.out.println("Dog无参构造方法执行");}
}
四·Spring解决循环依赖的底层原理:概述
1.三级缓存容器:
public class DefaultSingletonBeanRegistry ... {//1、最终单例Bean容器,里面bean都已经完成了实例化、属性注入、初始化,称之为"一级缓存"Map<String, Object> singletonObjects = new ConcurrentHashMap(256);//2、早期Bean单例池,缓存半成品对象(完成了实例化,但未完成属性注入、未执行初始化 init 方法),且当前对象已经被其他对象引用了,称之为"二级缓存"Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16);//3、单例Bean的工厂池,缓存半成品对象(完成了实例化,但未完成属性注入、未执行初始化 init 方法),对象未被引用,使用时在通过工厂创建Bean,称之为"三级缓存"Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
}
2.为什么Bean 都已经实例化了,还需要一个生产 Bean 的ObjectFactory工厂呢?
这跟循环依赖期间存在AOP操作有关:
(1)若不存在循环依赖、或者存在循环依赖但没有AOP操作时,ObjectFactory的getObject()方法返回的是,原本bean实例对象
(2)若存在循环依赖且存在AOP操作时,ObjectFactory的getObject()方法返回的是,原本bean实例的代理对象(提前创建代理对象,原本Spring的设计模式是bean实例化、属性注入、初始化之后,再创建代理对象的,但这种特殊情况为了解决循环依赖,只能提前创建。因此Spring框架在极端情况下,可能出现bean后置处理器方法在属性注入、初始化方法前执行,但问题也能解决)
3.三级缓存容器工作流程示例:假设现在需要实例化两个对象:A、B
(1)不存在循环依赖、或者存在循环依赖但不存在AOP操作:
1.先从一级、二级、三级缓存容器找对象A,发现没有
2.执行A的构造方法进行实例化,但未执行属性注入、初始化操作(@PostConstruct),A 只是一个半成品。
3.将早期的A暴露出去,放到三级缓存容器singletonFactories中,bean对象会被ObjectFactory包装起来
4.A进行属性注入,发现没有依赖其他未创建的对象
5.A进行初始化操作(@PostConstruct),完成bean创建工作
6.然后会调用addSingleton方法,将自己丢到一级缓存中,并将自己从二级、三级缓存中移除(实际只有三级缓存容器有对象)
7.再按照上述步骤创建B对象,从步骤1开始
......
(2)存在循环依赖、存在AOP操作:
1.先从一级、二级、三级缓存容器找对象A,发现没有
2.实例化A,此时 A 还未完成属性填充和初始化方法(@PostConstruct)的执行,A 只是一个半成品。
3.提前暴露A引用,为 A 创建一个 Bean 工厂,并放入到 singletonFactories 中。
4.属性注入A,发现 A 需要注入 B 对象,但是一级、二级、三级缓存均为发现对象 B。
5.实例化B,此时 B 还未完成属性填充和初始化方法(@PostConstruct)的执行,B 只是一个半成品。
6.提前暴露B引用,为 B 创建一个 Bean 工厂,并放入到 singletonFactories 中。
7.属性注入B,发现 B 需要注入 A 对象,此时在一级、二级未发现对象 A,但是在三级缓存中发现了对象 A,从三级缓存中得到对象 A,
并将对象 A 放入二级缓存中,同时删除三级缓存中的对象 A。(注意,此时的 A 还是一个半成品,并没有完成属性填充和执行初始化方法),
然后将对象 A 注入到对象 B 中,对象 B 完成属性填充
8.执行B初始化方法,B对象彻底创建完成。
9.将B对象放入到一级缓存中,同时删除三级缓存中的对象 B。(此时对象 B 已经是一个成品)
10.对象 A 得到对象 B,将对象 B 注入到对象 A 中,对象 A 完成属性填充。(对象 A 得到的是一个完整的对象 B)
11.执行A初始化方法,A对象彻底创建完成
12.将A对象放入到一级缓存中,同时删除二级缓存中的对象 A。(此时对象 A 已经是一个成品)
4.为什么要再包装一层ObjectFactory对象存入三级缓存呢?说是为了解决Bean对象存在AOP代理情况,那么直接生成代理对象半成品Bean放入二级缓存中,这不就可以省略三级缓存了吗?所以这使用三级缓存的意义在哪里?
-
(1)正常情况下(没有循环依赖):
-
(1-1)Spring都是在完全创建好Bean之后,才创建对应的代理对象
-
(2)为了处理循环依赖,Spring有三种选择:
-
(2-1)不管有没有循环依赖,直接将半成品bean对象放入二级缓存,用于解决循环依赖问题。(会导致无法注入AOP代理对象,只能是原生bean实例对象)
-
(2-2)不管有没有循环依赖,都提前创建好代理对象,并将代理对象放入二级缓存,出现循环依赖时,其他对象直接就可以取到代理对象并注入。(会导致无法注入原生bean实例对象,只能是AOP代理对象)
-
(2-3)加一个中间层,只有出现循环依赖且存在AOP操作时,才会提前生成代理对象,其他情况下都是返回原生bean实例对象。(这样就极大可能保证Spring按照原本AOP代理设计模式进行创建bean,且又能解决循环依赖问题)
注意:虽然加一个中间层,看似极大的兼顾了两种情况。但Spring框架在极端情况下,还是可能出现bean后置处理器方法在属性注入、初始化方法前执行,但该问题也能通过合理手段解决
5.使用构造器注入,造成的循环依赖,三级缓存机制无法自动解决:
因为构造器循环依赖是发生在bean实例化阶段,此时连bean的构造方法都没执行完,早期对象都无法创建出来。因此也无法放到三级缓存。三级缓存只能是在bean实例化之后,才能起到作用
6.为什么构造器注入,配合@Lazy注解就能解决循环依赖问题呢?
(1)示例代码:
@Component
public class Cat {private Dog dog;/*** 构造方法注入属性对象时,被标注@Lazy注解的参数对象,并不会直接触发Dog类的实例化操作,* 而是会先放入一个dog的代理对象在这里,当后面该dog的代理对象被第一次调用时,才会触发Dog的实例化操作,* 但是生成的实例化对象并不会替换原本的代理对象,只会将实例化对象注入代理对象里面。* (代理对象在其内部维护对实际实例的引用,在后续每次调用时,代理对象都会将请求转发给已经实例化的原生对象,并返回原生对象的方法执行结果)* @param dog*/@Autowiredpublic Cat(@Lazy Dog dog) {//注意这里不能在构造方法里面调用dog对象,一旦调用就会立即触发Dog的实例化操作this.dog = dog;}
}
(2)使用构造器注入 + @Lazy注解,解决循环依赖的工作流程示例:一句话,@Lazy 注解是通过建立一个中间代理层,来破解循环依赖的
1.从一、二、三级缓存总找不到cat对象,开始实例化cat对象
2.由于Cat构造器参数dog上标注了@Lazy注解,因此Spring执行构造方法时,会创建一个代理对象赋给dog属性
3.cat对象成功创建实例对象,放入三级缓存里面
4.cat对象再执行属性注入、初始化操作,完成最终bean创建
5.cat对象最后放入单例池里面(一级缓存),删除二、三级缓存里面的cat对象
6.当cat对象的dog属性被第一次调用时(dog此时是代理对象),会触发Dog类的实例化操作,生成实例化对象dog2
7.dog2对象再执行属性注入、初始化方法,完成最终bean创建,放入单例池(一级缓存)
8.Spring最后再将dog2对象注入到cat对象的dog属性的代理对象里面
(生成的实例化对象并不会替换原本的代理对象,只会将实例化对象注入代理对象里面。代理对象在其内部维护对实际实例的引用,
在后续每次调用时,代理对象都会将请求转发给已经实例化的原生对象,并返回原生对象的方法执行结果)
7·参考文献链接:
Spring 解决循环依赖必须要三级缓存吗?
Spring循环依赖解决方案
Spring使用三级缓存解决循环依赖?
spring中怎么解决循环依赖的问题
Spring系列第28篇:Bean循环依赖详解
相关文章:
总结:Spring创建Bean循环依赖问题与@Lazy注解使用详解
总结:Spring创建Bean循环依赖问题与Lazy注解使用详解 一前提知识储备:1.Spring Bean生命周期机制(IOC)2.Spring依赖注入机制(DI)(1)Autowired注解标注属性set方法注入(2&…...

Mac下java环境搭建
JDK 教程:MAC安装JDK及环境变量配置-CSDN博客 建议JDK7和JDK8都装上,因为一些老项目是用JDK7开发,使用JDK8编译时报错。(若没有老项目,直接安装jdk8) 若配置环境变量时找不到JDK的安装路径,有两种方式: 方式一、mac默认位置为:/Library/Java/JavaVirtualMachines/…...

mac设置java环境变量
在 macOS 系统上,设置 JAVA_HOME 环境变量可以通过以下步骤进行: 打开终端应用程序。 输入以下命令来查找 Java 的安装路径:/usr/libexec/java_home 终端会返回 Java 的安装路径,类似 /Library/Java/JavaVirtualMachines/jdk1.…...

【笔记】Android 漫游定制SPN定制有关字段
一、SPN模块简介 【笔记】SPN和PLMN 运营商网络名称显示 Android U 配置 WiFiCalling 场景下PLMN/SPN 显示的代码逻辑介绍 【笔记】Android Telephony 漫游SPN显示定制(Roaming Alpha Tag) 二、相关配置字段 non_roaming_operator_string_array 是否…...
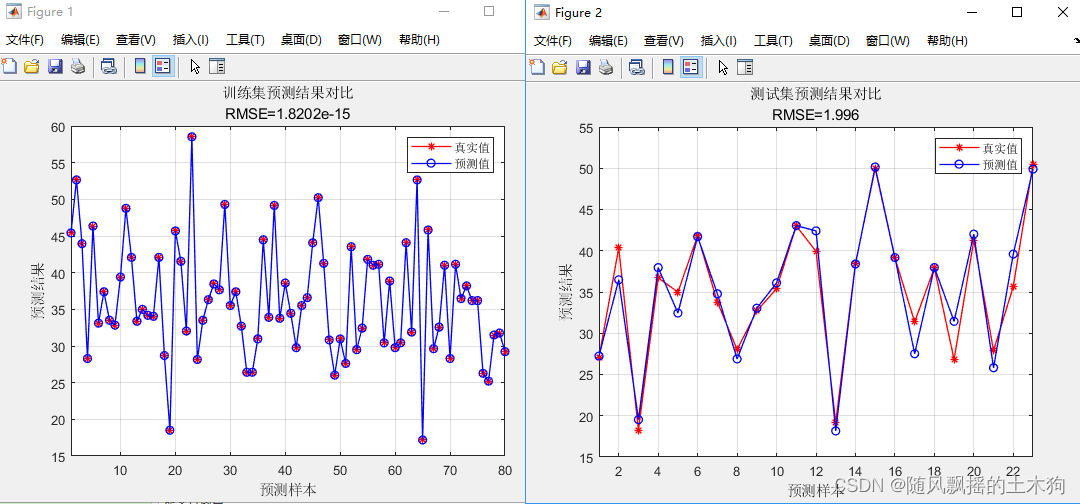
【MATLAB第99期】#源码分享 | 基于MATLAB的SHEPard模型多输入单输出回归预测模型
【MATLAB第99期】#源码分享 | 基于MATLAB的SHEPard模型多输入单输出回归预测模型 Shepard模型(简称SP模型)就是一种直观的、可操作的相似预测法,常用于插值。相似预测法基本原理按照相似原因产生相似结果的原则,从历史样本中集中找出与现在的最相似的一…...
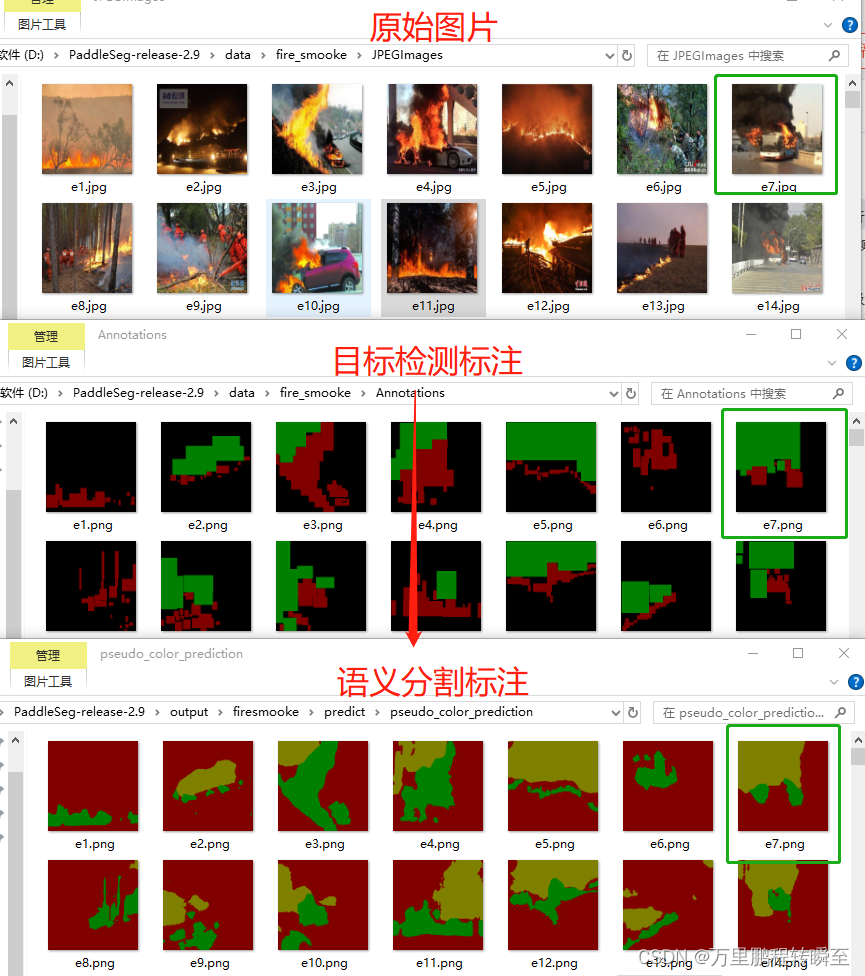
python工具方法 47 基于paddleseg将目标检测数据升级为语义分割数据
在进行项目研究时,通常需要搜集开源数据集。但是所能搜集到的数据集通常会存在形式上的差异,比如我想要的是语义分割数据,而搜集到的数据集却是目标检测数据;在这种情况下所搜集的数据就完成没有利用价值了么?不,其还存在价值,我们可以通过模型训练对数据标签的标注粒度…...

OpenJudge - 38:计算多项式的导函数
总时间限制: 1000ms 内存限制: 65536kB 描述 计算多项式的导函数是一件非常容易的任务。给定一个函数f(x),我们用f(x)来表示其导函数。我们用x^n来表示x的n次幂。为了计算多项式的导函数,你必须知道三条规则: (1)、(C) 0 如果C是常量 (2)、…...
)
数据结构:顺序表(C++实现)
1 头文件 SeqList.h //SeqList.h #pragma once #define _CRT_SECURE_NO_WARNINGS #include<iostream> #include<cassert> using namespace std; class SeqList { public://初始化SeqList();//销毁~SeqList();//头插void PushFront(int data);//头删void PopFront(…...
C++ 篇:解析 ONNX)
从零开始 TensorRT(7)C++ 篇:解析 ONNX
前言 学习资料: B站视频配套代码 cookbook 示例 参考源码:cookbook → 04-BuildEngineByONNXParser → pyTorch-ONNX-TensorRT 源码 C 代码量较多,已上传 GitHub OpenCV 安装: apt install libopencv-dev(1&…...

k8s集群的CA证书过期处理
文章目录 制作延期的CA证书获取CA全名准备签发申请配置生成新CA验证并替换CA 更新master组件的CA配置kube-apiserverkube-controller-managerkube-schedulerkube-admin检查证书过期时间 更新ServiceAccount secret更新node组件配置的CA更新kubelet连接配置签发kubelet自动申请的…...
linuxOPS基础_linux系统注意事项
Linux严格区分大小写 Linux 和Windows不同,Linux严格区分大小写的,包括文件名和目录名、命令、命令选项、配置文件设置选项等。 例如,Win7 系统桌面上有文件夹叫做Test,当我们在桌面上再新建一个名为 test 的文件夹时,…...

《探索虚拟与现实的边界:VR与AR谁更能引领未来?》
引言 在当今数字时代,虚拟现实(VR)和增强现实(AR)技术正以惊人的速度发展,并逐渐渗透到我们的日常生活中。它们正在重新定义人与技术、人与环境之间的关系,同时也为各行各业带来了全新的可能性。然而,究竟是VR还是AR更有潜力改变未来?本文将围绕这一问题展开深入探讨。…...

C++ 获取上一级文件夹路径
我们可能会经常遇到文件所在文件夹路径的问题,虽然各大平台也有提供方便快捷的API来实现,但是如果脱离平台本身,或者想实现跨平台的话,可以考虑用纯C的代码来实现这一需求 示例代码 #include <string> #include <ios…...

Apache Pulsar的分布式集群模式构建
1. 准备环境 6台带jdk8的Linux服务器(CentOS7为例) ip分别为: 主机名IP地址zookeeper1192.168.8.101zookeeper2192.168.8.102zookeeper3192.168.8.103pulsar1192.168.8.108pulsar2192.168.8.109pulsar3192.168.8.110 2. 下载Pulsar最新安…...

第三百八十六回
文章目录 概念介绍使用方法示例代码 我们在上一章回中介绍了Snackbar Widget相关的内容,本章回中将介绍TimePickerDialog Widget.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在这里说的TimePickerDialog是一种弹出窗口,只不过窗口的内容固定显示…...

Java中介者模式剖析及使用场景
中介者模式 一、介绍二、智能家居系统项目实现三、总结1.优点2.缺点3.使用经验4.Spring框架类似使用思想 一、介绍 介者模式是一种行为型设计模式,它允许对象之间通过一个中介者对象进行通信,而不是直接相互引用。将多对多的关系转化为一对多的关系&…...

ElevenLabs用AI为Sora文生视频模型配音 ,景联文科技提供高质量真人音频数据集助力生成逼真音效
随着Open AI公司推出的Sora文生视频模型惊艳亮相互联网,AI语音克隆创企ElevenLabs又为Sora的演示视频生成了配音,所有的音效均由AI创造,与视频内容完美融合。 ElevenLabs的语音克隆技术能够从一分钟的音频样本中创建逼真的声音。为了实现这一…...

Go语言基础
Go的数据类型定义 //运行第一个程序package main func main(){print("Hello World") }在GO语言中,一个程序只能有一个main包,对应只能有一个main方法,若无法满足这个条件,编译时将会报错。注释方式与PHP相同 import的使…...

IOS覆盖率报告info文件解读
一,IOS覆盖率报告的生成 在做前端精准测试的时候,对于iOS端,通常会做如下操作: (1)合并覆盖率数据 如下操作: xcrun llvm-profdata merge coverage_file1657885040728.profraw coverage_fil…...
爬虫实战——scrapy框架爬取多张图片
scrapy框架的基本使用,请参考我的另一篇文章:scrapy框架的基本使用 起始爬取的网页如下: 点击每张图片,可以进入图片的详情页,如下: 代码实现: 项目文件结构如下 img_download.py文件代码 im…...
内部调剂与跨项目共享策略)
LS-DYNA过量采购的许可证(核心数)内部调剂与跨项目共享策略
用闲置许可证做项目“缓冲池”,才是真正省下的钱我啊这边又赶上个烦心事,甲方项目组死活要使用LS-DYNA,说句实在的,IT部门说许可证全被占用了问题是,那帮人并尚未真的在用,只是担心自己用不到,搞…...
)
微信小程序跳转外部链接,除了web-view,这3种场景你考虑到了吗?(含代码示例)
微信小程序外部链接跳转的进阶实践:突破web-view的3种高阶场景 在微信小程序开发中,web-view组件是连接外部网页最直接的桥梁,但实际业务场景往往比基础实现复杂得多。当你的小程序需要处理带登录态的跳转、TabBar集成或性能敏感型页面时&…...

如何使用C#调用Oracle存储过程_OracleCommand配置CommandType.StoredProcedure
OracleCommand.CommandType CommandType.StoredProcedure 生效的前提是:存储过程名与CommandText完全一致(含大小写、包名),参数名、方向、类型须与PL/SQL端严格匹配,且连接字符串必须包含UnicodeTrue以确保字符串正确…...
及其在智能诊断中的应用)
深入解析UDS中的DID(Data Identification)及其在智能诊断中的应用
1. DID是什么?为什么它在车辆诊断中如此重要? 想象一下你是一名汽车医生,面对一辆"生病"的车辆,你需要快速准确地找到问题所在。这时候,DID就像是车辆的"体检报告编号",通过这个编号&a…...

实战EuroSAT遥感分类:3步构建高精度土地利用识别系统 [特殊字符]
实战EuroSAT遥感分类:3步构建高精度土地利用识别系统 🚀 【免费下载链接】EuroSAT EuroSAT: Land Use and Land Cover Classification with Sentinel-2 项目地址: https://gitcode.com/gh_mirrors/eu/EuroSAT EuroSAT数据集为遥感图像分类提供了标…...

EXTI中断回调函数详解:从HAL库源码分析到按键LED实战优化
EXTI中断回调函数深度解析:从HAL库源码到多按键优先级优化实战 当我们需要在嵌入式系统中实现实时响应外部事件时,外部中断(EXTI)机制往往是最高效的选择。不同于轮询方式需要持续消耗CPU资源检查GPIO状态,EXTI可以在引脚电平变化时立即中断当…...

STM32G474外部中断避坑指南:从CubeMX配置到中断服务函数编写,新手常犯的5个错误
STM32G474外部中断避坑指南:从CubeMX配置到中断服务函数编写 第一次接触STM32G474的外部中断功能时,很多开发者都会遇到各种奇怪的问题——中断不触发、响应异常甚至系统卡死。这些问题往往源于几个容易被忽视的细节配置。本文将深入剖析新手最容易踩的5…...

生成式AI内容安全不是加个过滤器就行!揭秘行业TOP3企业正在部署的“提示-生成-分发-追溯”闭环治理体系
第一章:生成式AI内容安全不是加个过滤器就行! 2026奇点智能技术大会(https://ml-summit.org) 在大模型应用爆发式落地的今天,许多团队仍误将“部署关键词黑名单”或“调用现成内容审核API”等同于构建了内容安全防线。这种认知偏差正导致大…...
)
从HAL库到LL库:STM32CubeMX工程配置详解与切换指南(附性能对比)
从HAL库到LL库:STM32CubeMX工程配置详解与切换指南(附性能对比) 在嵌入式开发领域,效率与性能始终是开发者追求的核心目标。对于使用STM32系列MCU的工程师而言,STM32CubeMX作为官方提供的图形化配置工具,已…...

SeuratWrappers终极指南:3步解锁单细胞分析扩展工具集
SeuratWrappers终极指南:3步解锁单细胞分析扩展工具集 【免费下载链接】seurat-wrappers Community-provided extensions to Seurat 项目地址: https://gitcode.com/gh_mirrors/se/seurat-wrappers 你是否曾在使用Seurat进行单细胞数据分析时,渴望…...