【Kafka系列 08】生产者消息分区机制详解

一、前言
我们在使用 Apache Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上。
比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是对于那种大批量机器组成的集群环境,每分钟产生的日志量都能以 GB 数,因此如何将这么大的数据量均匀地分配到 Kafka 的各个 Broker 上,就成为一个非常重要的问题。
二、为什么分区?
如果你对 Kafka 分区(Partition)的概念还不熟悉,可以先返回专栏【Kafka系列 01】Kafka 是什么? 回顾一下。
Kafka 有主题(Topic)的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,也就是说 Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。官网上的这张图非常清晰地展示了 Kafka 的三级结构,如下所示:
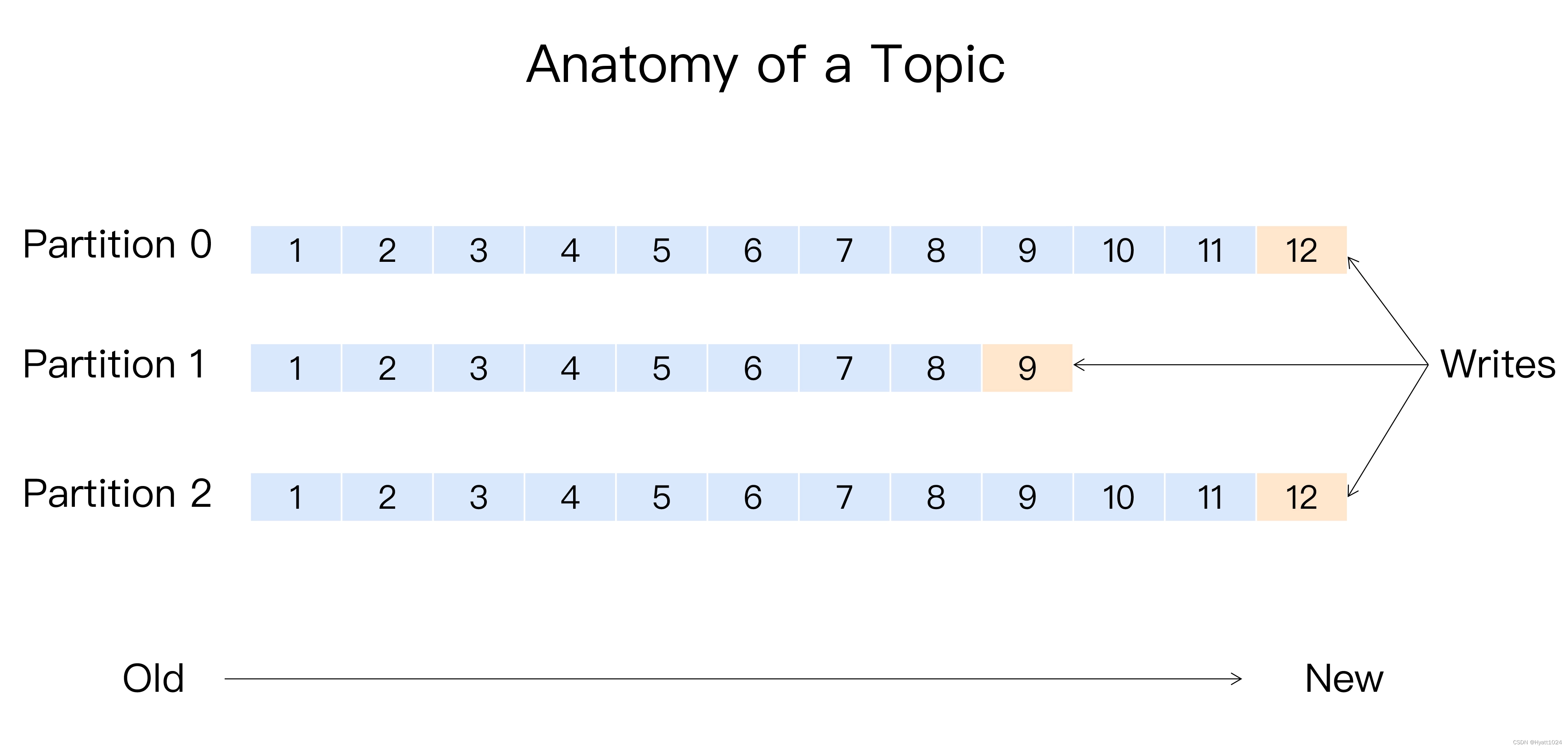
现在你可以先思考一下:你觉得为什么 Kafka 要做这样的设计?为什么使用分区的概念而不是直接使用多个主题呢?
其实分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性(Scalability)。
不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。
注:不同的分布式系统对分区的叫法也不尽相同。比如在 Kafka 中叫分区,在 MongoDB 和 Elasticsearch 中就叫分片 Shard,而在 HBase 中则叫 Region,在 Cassandra 中又被称作 vnode。从表面看起来它们实现原理可能不尽相同,但对底层分区(Partitioning)的整体思想却从未改变。
除了提供负载均衡这种最核心的功能之外,利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题。
三、分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
如果要自定义分区策略,你需要显式地配置生产者端的参数 partitioner.class。这个参数该怎么设定呢?方法很简单,在编写生产者程序时,你可以编写一个具体的类实现org.apache.kafka.clients.producer.Partitioner 接口。这个接口也很简单,只定义了两个方法:partition() 和 close(),通常你只需要实现最重要的 partition 方法。我们来看看这个方法的方法签名:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);这里的 topic、key、keyBytes、value 和 valueBytes 都属于消息数据,cluster 则是集群信息(比如当前 Kafka 集群共有多少主题、多少 Broker 等)。Kafka 给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。只要你自己的实现类定义好了 partition 方法,同时设置 partitioner.class 参数为你自己实现类的 Full Qualified Name,那么生产者程序就会按照你的代码逻辑对消息进行分区。虽说可以有无数种分区的可能,但比较常见的分区策略也就那么几种,下面我来详细介绍一下。
3.1 轮询策略
也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
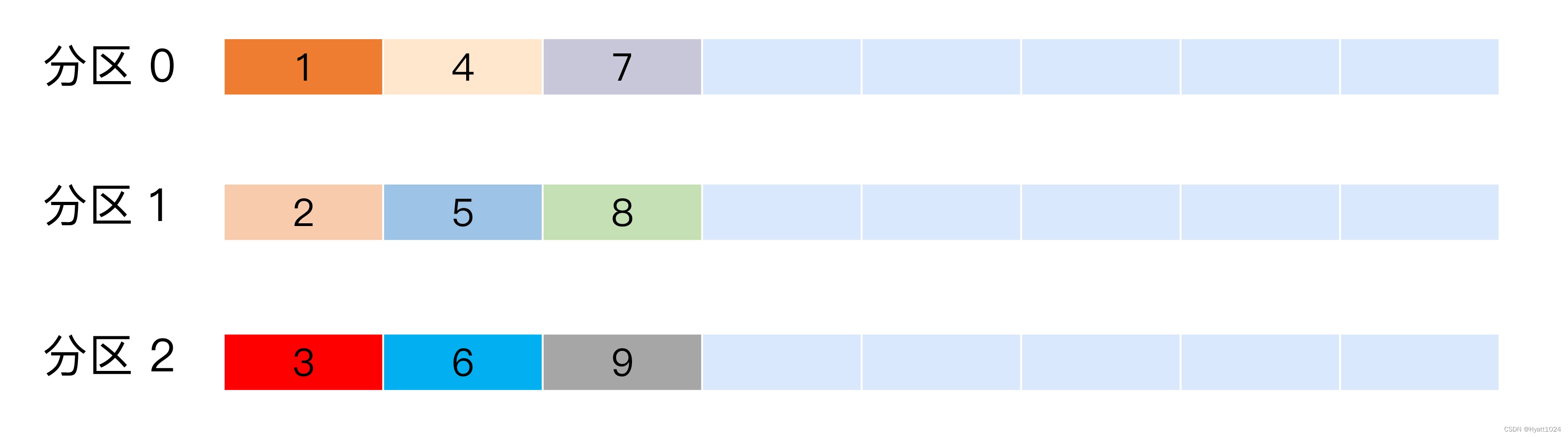
这就是所谓的轮询策略。轮询策略是 Kafka Java 生产者 API 默认提供的分区策略。如果你未指定partitioner.class 参数,那么你的生产者程序会按照轮询的方式在主题的所有分区间均匀地“码放”消息。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
3.2 随机策略
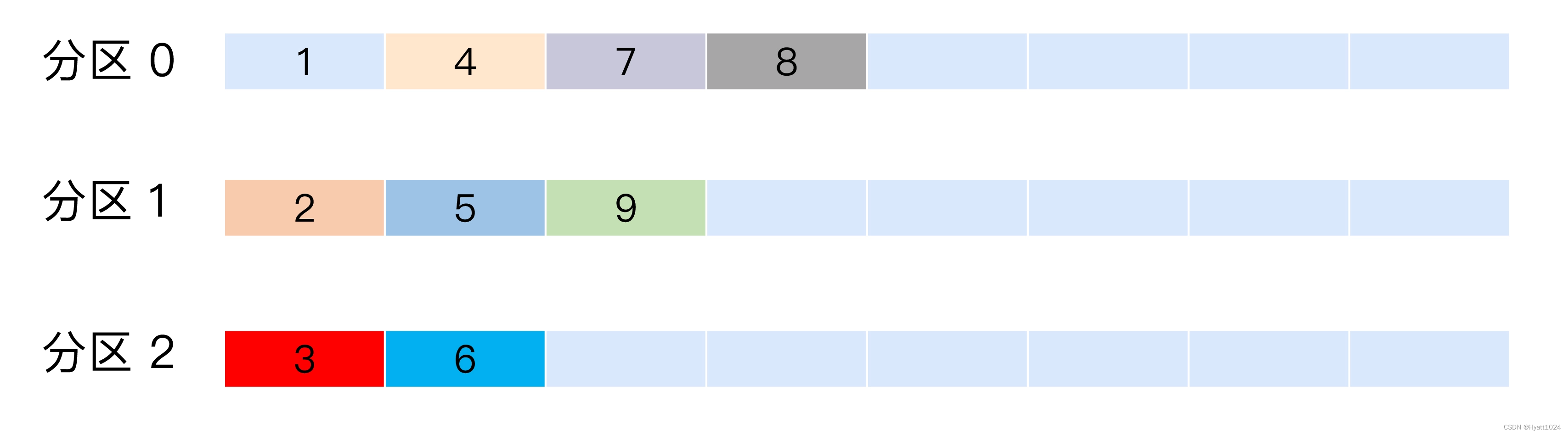
也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示。
如果要实现随机策略版的 partition 方法,很简单,只需要两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。
本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
3.3 按消息键保序策略
也称 Key-ordering 策略。有点尴尬的是,这个名词是我自己编的,Kafka 官网上并无这样的提法。
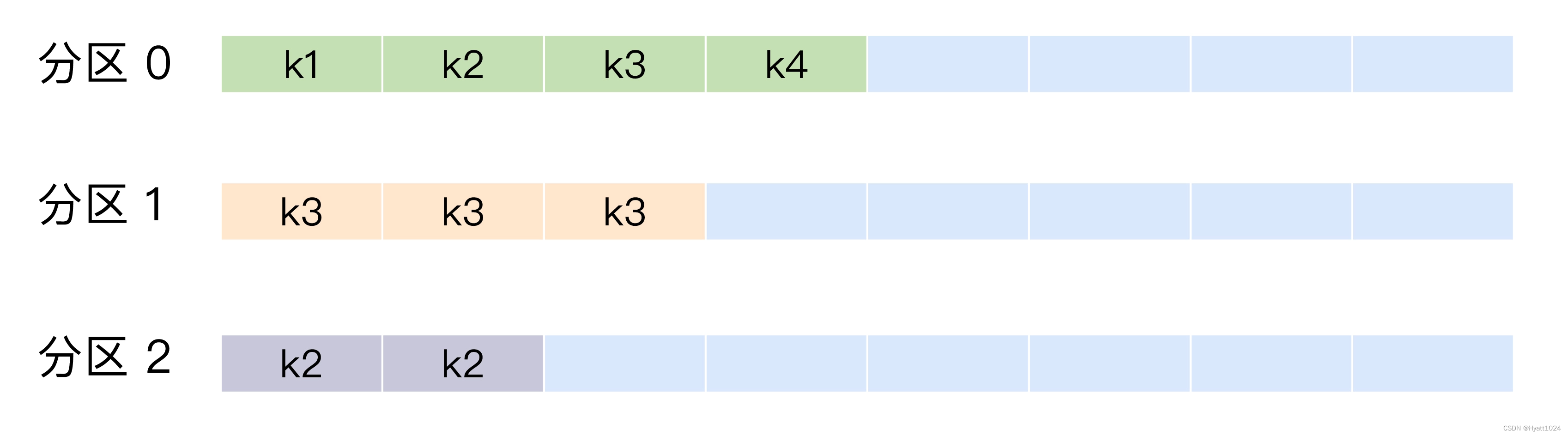
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。特别是在 Kafka 不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,如下图所示。
实现这个策略的 partition 方法同样简单,只需要下面两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();前面提到的 Kafka 默认分区策略实际上同时实现了两种策略:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。
3.4 其他分区策略
上面这几种分区策略都是比较基础的策略,除此之外你还能想到哪些有实际用途的分区策略?其实还有一种比较常见的,即所谓的基于地理位置的分区策略。当然这种策略一般只针对那些大规模的 Kafka 集群,特别是跨城市、跨国家甚至是跨大洲的集群。
四、小结
今天我们讨论了 Kafka 生产者消息分区的机制以及常见的几种分区策略。切记分区是实现负载均衡以及高吞吐量的关键,故在生产者这一端就要仔细盘算合适的分区策略,避免造成消息数据的“倾斜”,使得某些分区成为性能瓶颈,这样极易引发下游数据消费的性能下降。
相关文章:
【Kafka系列 08】生产者消息分区机制详解
一、前言 我们在使用 Apache Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上。 比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是对于那种大批量机器组成的集群环境,每分…...

【PyTorch】进阶学习:BCEWithLogitsLoss在多标签分类任务中的正确使用---logits与标签形状指南
【PyTorch】进阶学习:BCEWithLogitsLoss在多标签分类任务中的正确使用—logits与标签形状指南 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTo…...

ocr关键信心提取数据集
doc/doc_ch/dataset/kie_datasets.md PaddlePaddle/PaddleOCR - Gitee.com https://huggingface.co/datasets/howard-hou/OCR-VQA OCR-VQA Dataset | Papers With Code...
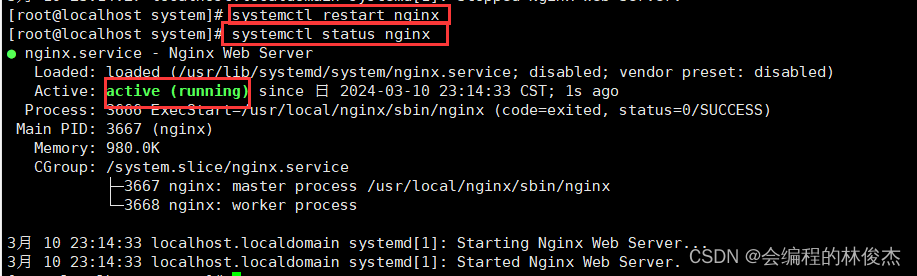
Linux中,配置systemctl操作Nginx
最近在通过Linux系统学一些技术,但是在启动Nginx时,总是需要执行其安装路径下的脚本文件,要么我们需要先进入其安装路径,要么我们每次执行命令直接拼上Nginx的完整目录,如启动时命令为/usr/local/nginx/sbin/nginx。 可…...
Sleuth(Micrometer)+ZipKin分布式链路追踪
Sleuth(Micrometer)ZipKin分布式链路追踪 Micrometer springboot3之前还可以用sleuth,springboot3之后就被Micrometer所替代 官网https://github.com/spring-cloud/spring-cloud-sleuth 为什么会出现这个技术? 在微服务框架中,一个由客户…...

fanout模式
生产者: public class Provider {public static void main(String[] args) throws IOException {Connection connection RabbitMQUtils.getConnection();Channel channel connection.createChannel();//通道声明指定的交换机 参数1:交换机名称 参数2&…...

Docker基础—CentOS中卸载Docker
要卸载已经安装好的 Docker,可以按照以下步骤进行: 1 停止正在运行的 Docker 服务 sudo systemctl stop docker 2 卸载 Docker 软件包 sudo yum remove docker-ce 3 删除 Docker 数据和配置文件(可选) sudo rm -rf /var/lib…...

深入解读 Elasticsearch 磁盘水位设置
本文将带你通过查看 Elasticsearch 源码来了解磁盘使用阈值在达到每个阶段的处理情况。 跳转文章末尾获取答案 环境 本文使用 Macos 系统测试,512M 的磁盘,目前剩余空间还有 60G 左右,所以按照 Elasticsearch 的设定,ES 中分片应…...
M1电脑 Xcode15升级遇到的问题
遇到四个问题 一、模拟器下载经常报错。 二、Xcode15报错: SDK does not contain libarclite 三、报错coreAudioTypes not found 四、xcode模拟器运行一次下次必定死机 一、模拟器下载经常报错。 可以https://developer.apple.com/download/all/?qios 下载最新的模拟器&…...
)
软考 系统架构设计师之回归及知识点回顾(3)
接前一篇文章:软考 系统架构设计师之回归及知识点回顾(2) 继续回顾一下之前已经介绍和讲解过的系统架构设计师中的知识点: 7. 净室软件工程 净室(Cleaning Room)软件工程是一种应用数学与统计学理论&…...

探索stable diffusion的奇妙世界--01
目录 1. 理解prompt提示词: 2. Prompt中的技术参数: 3. Prompt中的Negative提示词: 4. Prompt中的特殊元素: 5. Prompt在stable diffusion中的应用: 6. 作品展示: 在AI艺术领域,stable di…...

C语言数组的维数该如何理解?
一、问题 什么叫做维,维是不是数组中数的个数呢? 二、解答 维数是数组元素的下标个数。使⽤数组的时候,如果只有⼀个下标,则称为⼀维数组,⼀维数组⼀般表示⼀种线性数据的组合。⼆维数组则是有两个下标,可…...
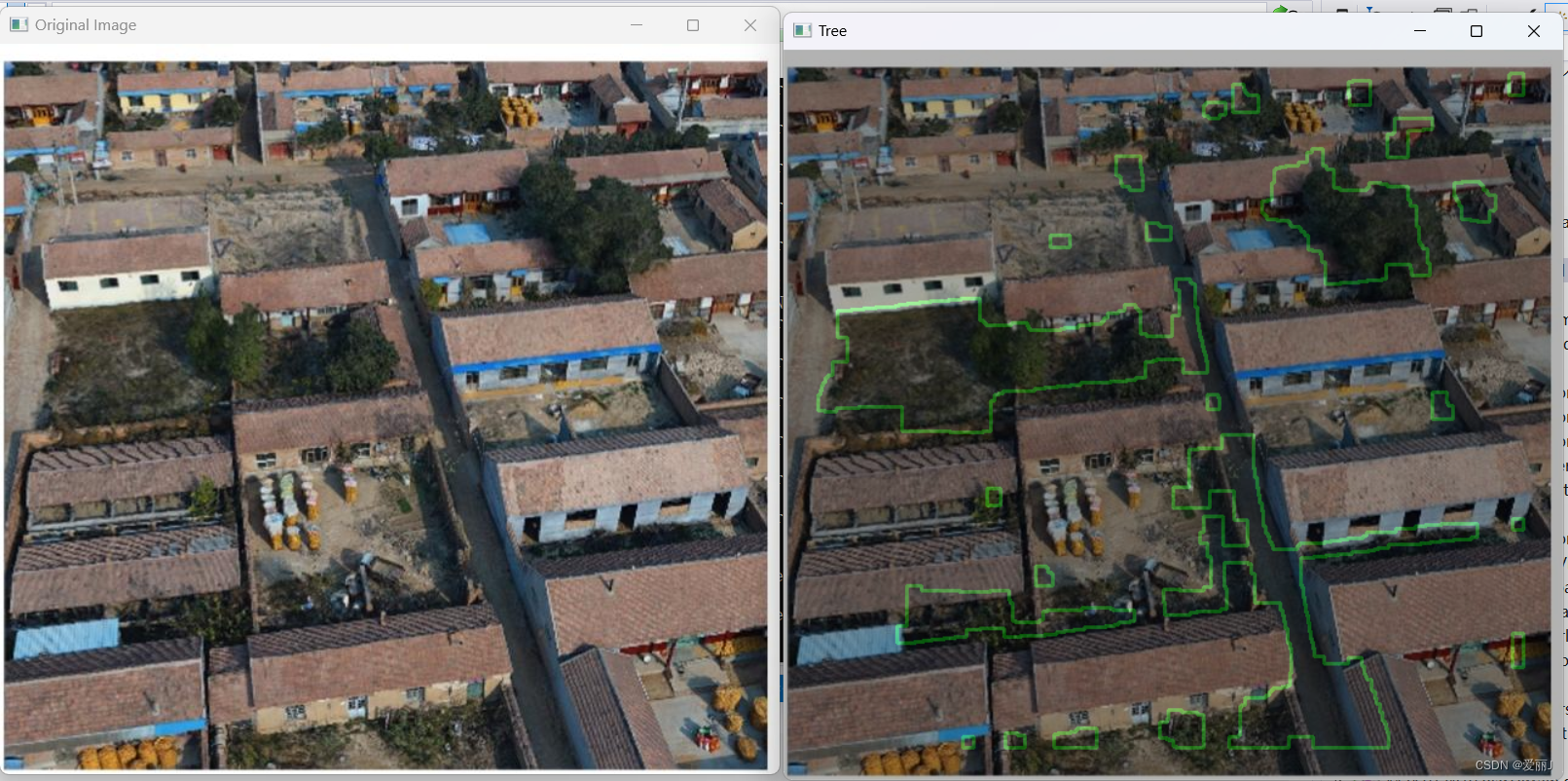
opencv解析系列 - 基于DOM提取大面积植被(如森林)
Note:简单提取,不考虑后处理(填充空洞、平滑边界等) #include <iostream> #include "opencv2/imgproc.hpp" #include "opencv2/highgui.hpp" #include <opencv2/opencv.hpp> using namespace cv…...

【Leetcode】299. 猜数字游戏
文章目录 题目思路代码结果 题目 题目链接 你在和朋友一起玩 猜数字(Bulls and Cows)游戏,该游戏规则如下: 写出一个秘密数字,并请朋友猜这个数字是多少。朋友每猜测一次,你就会给他一个包含下述信息的提…...

JWT身份验证
在实际项目中一般会使用jwt鉴权方式。 JWT知识点 jwt,全称json web token ,JSON Web令牌是一种开放的行业标准RFC 7519方法,用于在两方安全地表示声明。具体网上有许多文章介绍,这里做简单的使用。 1.数据结构 JSON Web Token…...

IOS面试题object-c 71-80
71. 简单介绍下NSURLConnection类及 sendSynchronousRequest:returningResponse:error:与– initWithRequest:delegate:两个方法的区别?NSURLConnection 主要用于网络访问,其中 sendSynchronousRequest:returningResponse:error:是同步访问数据,即当前…...

计算机mfc140.dll文件缺失的修复方法分析,一键修复mfc140.dll
电脑显示mfc140.dll文件缺失信息时,不必担心,这通常是个容易解决的小问题。接下来让我们详细探究并解决mfc140.dll文件缺失的状况。以下将详述相应的解决方案,从而帮助您轻松克服这一技术难题。通过几个简单步骤,即可恢复正常使用…...

web前端框架
目前比较火热的几门框架: React React是由Facebook(脸书)开发和创建的开源框架。React 用于开发丰富的用户界面,特别是当您需要构建单页应用程序时。它是最强大的前端框架。 弊端: 您不具备 JavaScript 的实践知识,则建议不要使用 React。同样&#x…...
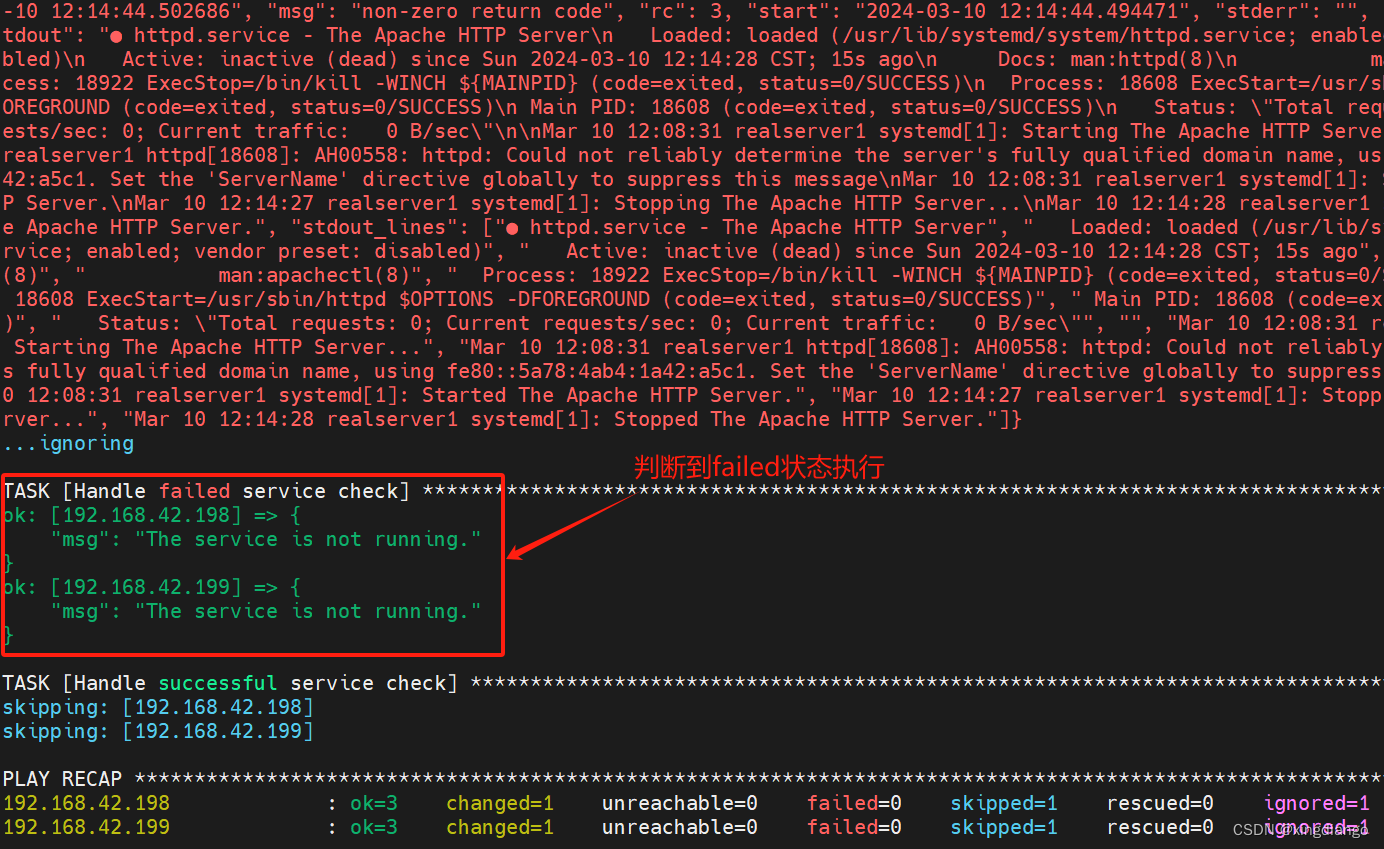
关于playbook中when条件过滤报The conditional check ‘result|failed‘ failed的问题
问题现象 在使用plabook中的when做过滤脚本如下: --- - hosts: realserversremote_user: roottasks:- name: Check if httpd service is runningcommand: systemctl status httpdregister: resultignore_errors: True- name: Handle failed service checkdebug:ms…...

【设计模式专题之抽象工厂模式】3. 家具工厂
题目描述 小明家新开了两个工厂用来生产家具,一个生产现代风格的沙发和椅子,一个生产古典风格的沙发和椅子,现在工厂收到了一笔订单,请你帮他设计一个系统,描述订单需要生产家具的信息。 输入描述 输入的第一行是一…...

安卓加固被破解怎么办?揭秘性能下降与源码泄露风险的真实原因
在选择安卓加固服务时,企业决策者最担心的几个问题往往是:花了钱,方案会不会很快被绕过?加固后,APP会不会变得又卡又慢甚至崩溃?把源码上传到云端加固,数据安全如何保障?这些并非杞人…...

猫抓浏览器扩展:如何快速提取网页视频和音频资源
猫抓浏览器扩展:如何快速提取网页视频和音频资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch࿰…...

Java解析大疆无人机照片元数据:从EXIF到XMP的实战指南
1. 为什么需要解析大疆无人机照片元数据 当你用大疆无人机拍摄照片时,相机不仅记录了画面本身,还悄悄存储了大量"幕后花絮"。这些隐藏在照片里的元数据(Metadata)就像飞行黑匣子,包含了GPS坐标、飞行高度、相…...

Drift-AR:一个熵信号,同时加速AR与视觉解码两大瓶颈,实现5.5倍加速+单步生成!
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上…...

从QT到VTK:为什么三维可视化开发要选基于GPU的绘图API?
从QT到VTK:为什么三维可视化开发要选基于GPU的绘图API? 在三维可视化开发领域,技术选型往往决定了项目的成败。当开发者面临QT和VTK两种截然不同的技术路线时,如何做出明智选择?这不仅仅是一个简单的API偏好问题&#…...

MGeo中文地址解析模型参数详解:多模态预训练底座实战解析
MGeo中文地址解析模型参数详解:多模态预训练底座实战解析 地址信息,就像我们日常生活中的“数字门牌”,是连接线上信息与线下物理世界的关键桥梁。无论是点外卖时精准送达,还是导航时快速定位,背后都离不开对地址文本…...
的保姆级技巧)
告别眼瞎!FullEventLogView实战:高效分析海量Windows安全日志(evtx文件)的保姆级技巧
告别眼瞎!FullEventLogView实战:高效分析海量Windows安全日志(evtx文件)的保姆级技巧 在网络安全事件响应和系统运维中,Windows事件日志(evtx文件)分析是每个技术人员都绕不开的必修课。但当你面…...
)
Conda报错‘Malformed version string’别慌,三步搞定.condarc配置(附清华/阿里云源)
Conda报错‘Malformed version string’深度解析与实战修复指南 遇到Conda报错"Malformed version string"时,很多开发者第一反应是重装环境或切换Python版本。实际上,90%的此类问题源于.condarc配置文件中的版本号格式或镜像源配置错误。本文…...

Qwen3互联网应用架构:构建可扩展的字幕处理微服务
Qwen3互联网应用架构:构建可扩展的字幕处理微服务 想象一下,你负责一个在线教育平台,每天有成千上万的用户上传课程视频。用户希望视频能立刻配上字幕,方便学习和搜索。高峰期时,每分钟可能有上百个视频同时涌入。如果…...

Nunchaku FLUX.1-dev 在网络安全演练中的应用:生成模拟网络攻击场景示意图
Nunchaku FLUX.1-dev 在网络安全演练中的应用:生成模拟网络攻击场景示意图 1. 引言 想象一下,你正在组织一场网络安全演练。你需要向团队成员,尤其是那些非技术背景的同事,清晰地解释一个复杂的网络攻击链:攻击者如何…...