【Python从入门到进阶】50、当当网Scrapy项目实战(三)
接上篇《49、当当网Scrapy项目实战(二)》
上一篇我们讲解了的Spider与item之间的关系,以及如何使用item,以及使用pipelines管道进行数据下载的操作,本篇我们来讲解Scrapy的多页面下载如何实现。
一、多页面下载原理分析
1、多页面数据下载主要思路
我们之前编写的爬虫,主要是针对当当网书籍详情首页的列表数据进行下载,也只能下载第一页已经加载好的列表数据:
如果我们想要下载该种书籍的多页数据(例如1到100页)的数据,这就涉及到爬虫的多页面下载逻辑了。
我们现在可以思考一下,我们下载从第1页到第100页的书籍详情列表数据,数据结构和取数逻辑是否是一样的?答案是一样的。
所以我们在爬虫文件中编写的数据列表数据获取逻辑是核心程序,是不需要修改的,我们只需要把每一页的新内容传输给它,它进行数据转换清洗,变成数据结构对象,最后存储到文件中去即可。如同下图: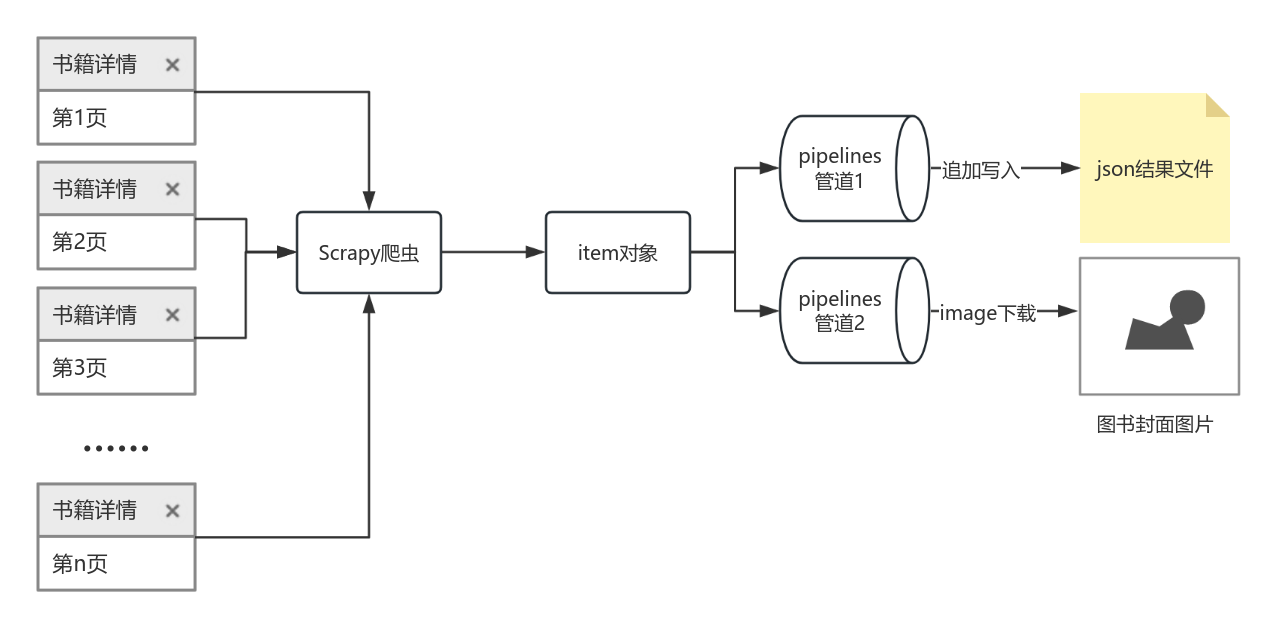
我们要做的事情,就是在爬虫中parse函数执行第1页请求完毕后,再使用parse函数执行第2页、第3页等等的请求即可。
2、如何获取多个页面的数据
我们如何来获取第2页及之后的数据呢?首先我们进入图书列表页,分别点击后面的第2页、第3页,并记录一下浏览器上面的地址:
我们分别看一下第1页、第2页、第3页的网址: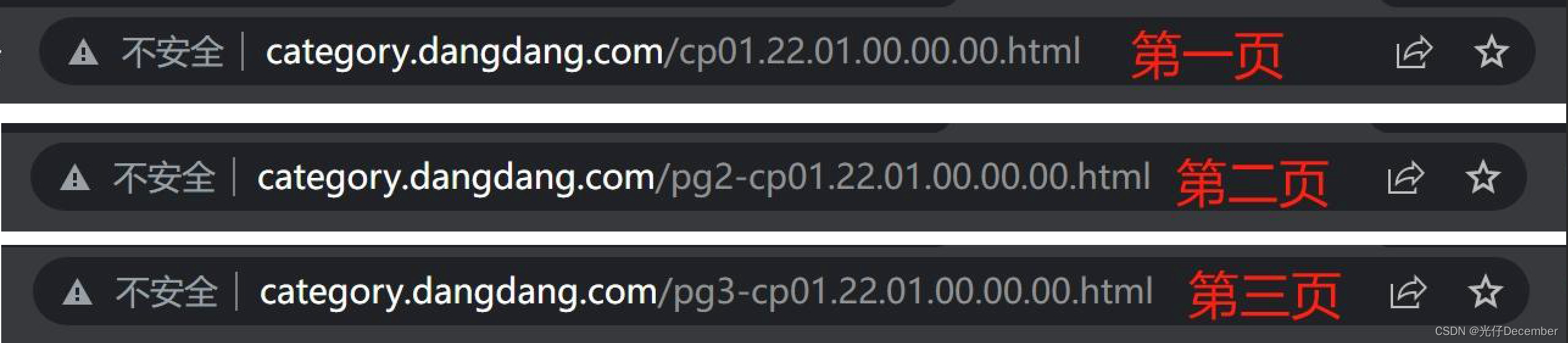
聪明的童鞋应该可以看出区别了吧,没错,从第1页之后,每页页面在“cp01”前会有一个“pgx-”,而其中的“x”就是当前的页码数。所以我们要获取某一页的数据,就只需要修改“pg”后面的数字为几,即可拿到相关页面的数据了。
二、多页面下载程序编写
1、指定相关路径
此时我们在爬虫文件中,就需要指定起始页面是什么,然后后续的迭代页面是什么,代码如下:
class DangSpider(scrapy.Spider):name = "dang"# 如果为多页下载,必须将allowed_domains的范围调整为主域名allowed_domains = ["category.dangdang.com"]start_urls = ["http://category.dangdang.com/cp01.22.01.00.00.00.html"]base_url = 'http://category.dangdang.com/pg'end_url = '-cp01.22.01.00.00.00.html'page = 1#......下面代码省略......其中的base_url是迭代页面的主地址信息,end_url是页码获取后拼接的静态页面固定地址,page是下一次要抓取的页面的页码数。
2、编写多页面下载判定与执行逻辑
然后我们在之前parse函数结束中的for循环结束后,编写一个页面判断的逻辑(注意是在for循环的外面,parse函数的里面):
if self.page < 100: # 判断当前页面是否在100页以内self.page = self.page + 1 # 获取下一个页码# 根据获取的页码,拼接下一个需要爬取的页面url地址url = self.base_url + str(self.page) + self.end_url# 回调爬虫的parse函数,用新的url继续进行数据爬取# scrapy.Request就是scrapy的get请求# 其中的url是请求地址,callback是需要执行的爬虫的函数,注意不需要加圆括号yield scrapy.Request(url=url,callback=self.parse)3、测试效果
这是我们删除原来抓取的book.json中的所有数据,清理下载的书籍图片,然后通过“scrapy crawl dang”命令执行我们的dang.py爬虫: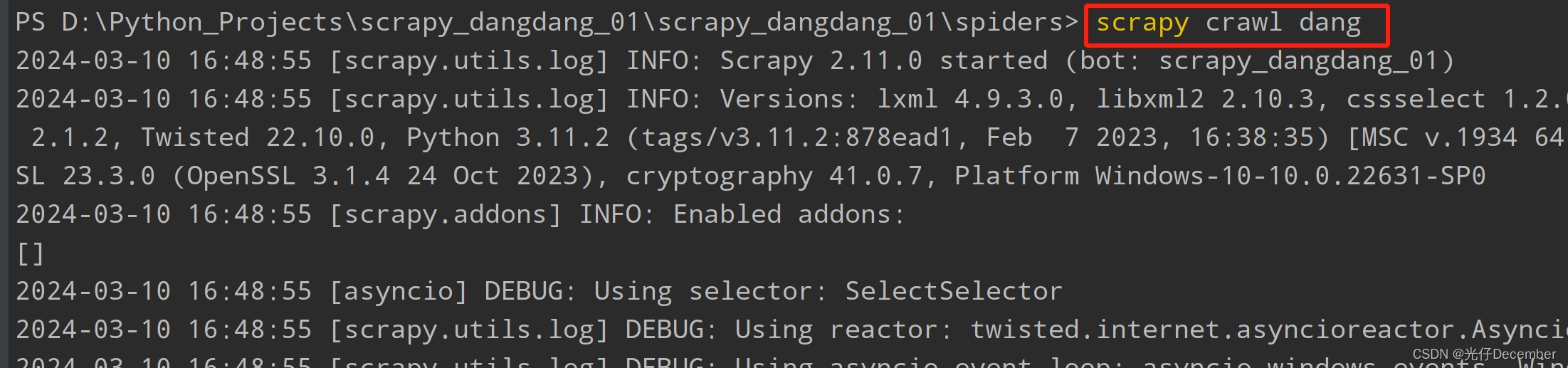
程序执行后,可以看到爬虫在逐页爬取相关数据: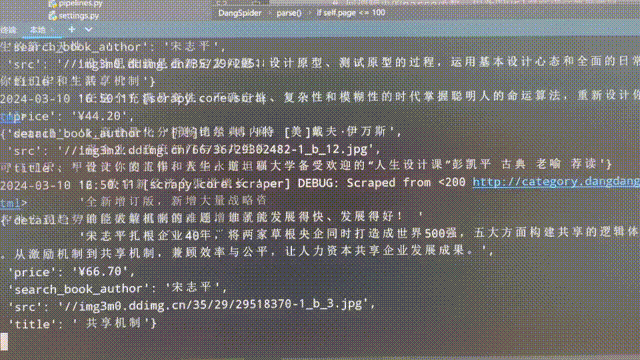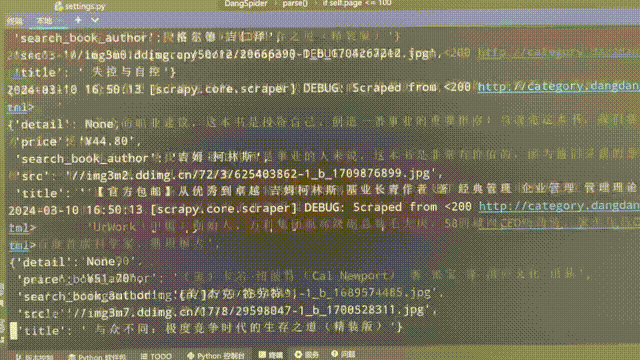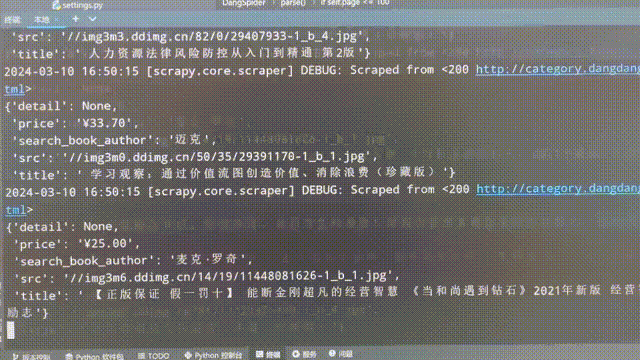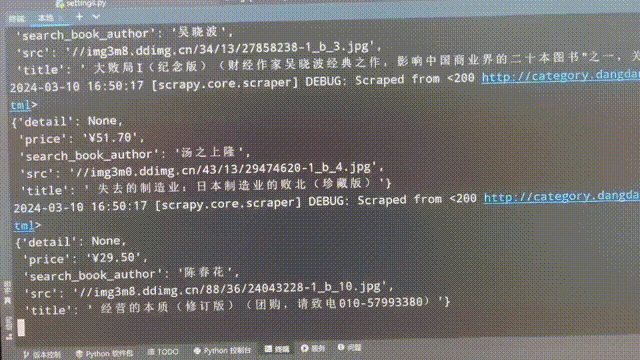
等待爬虫执行完毕(这里我爬了101页,是因为上面小于100写成小于等于了):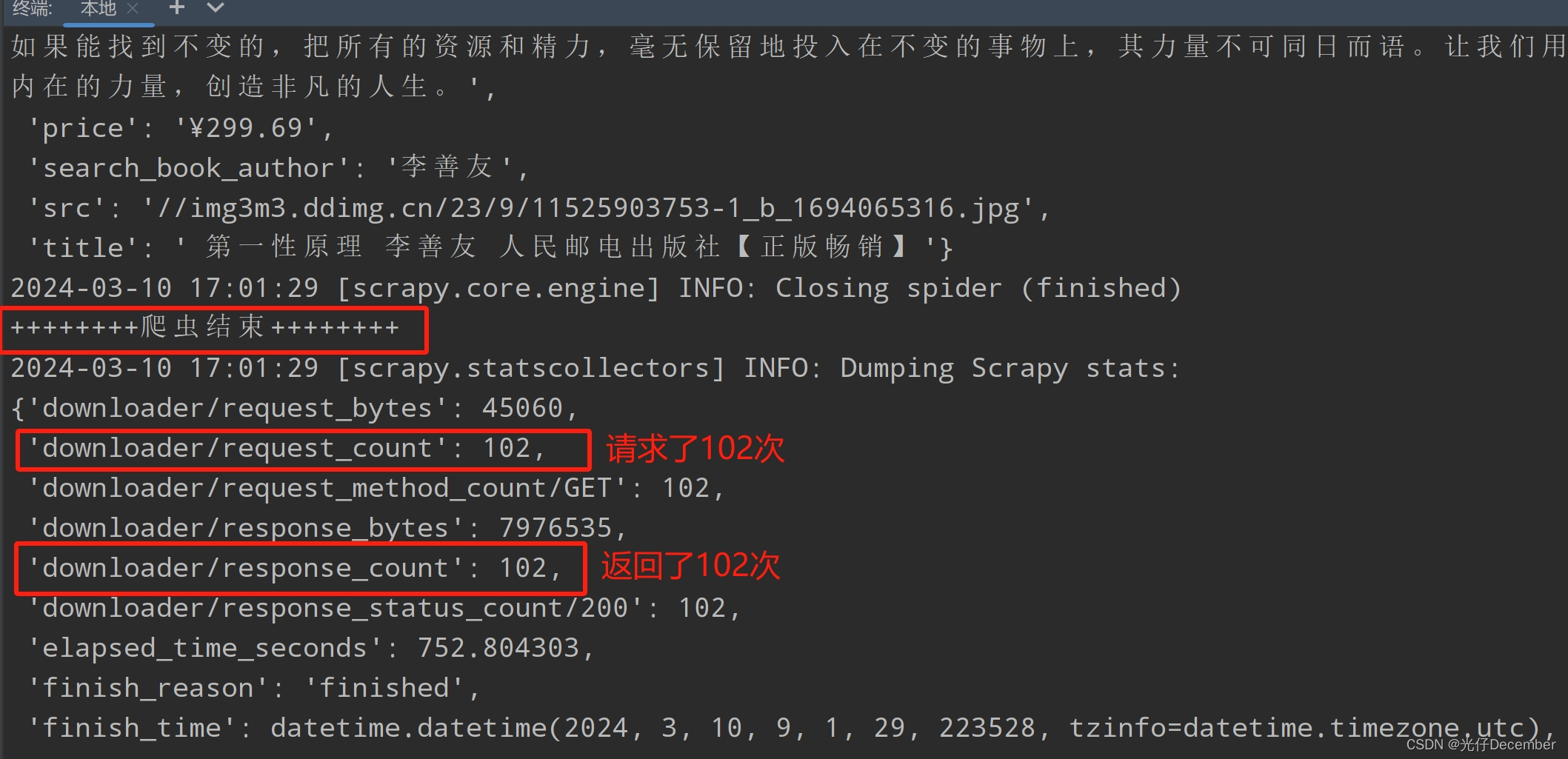
我们可以看到json文件又被写满了: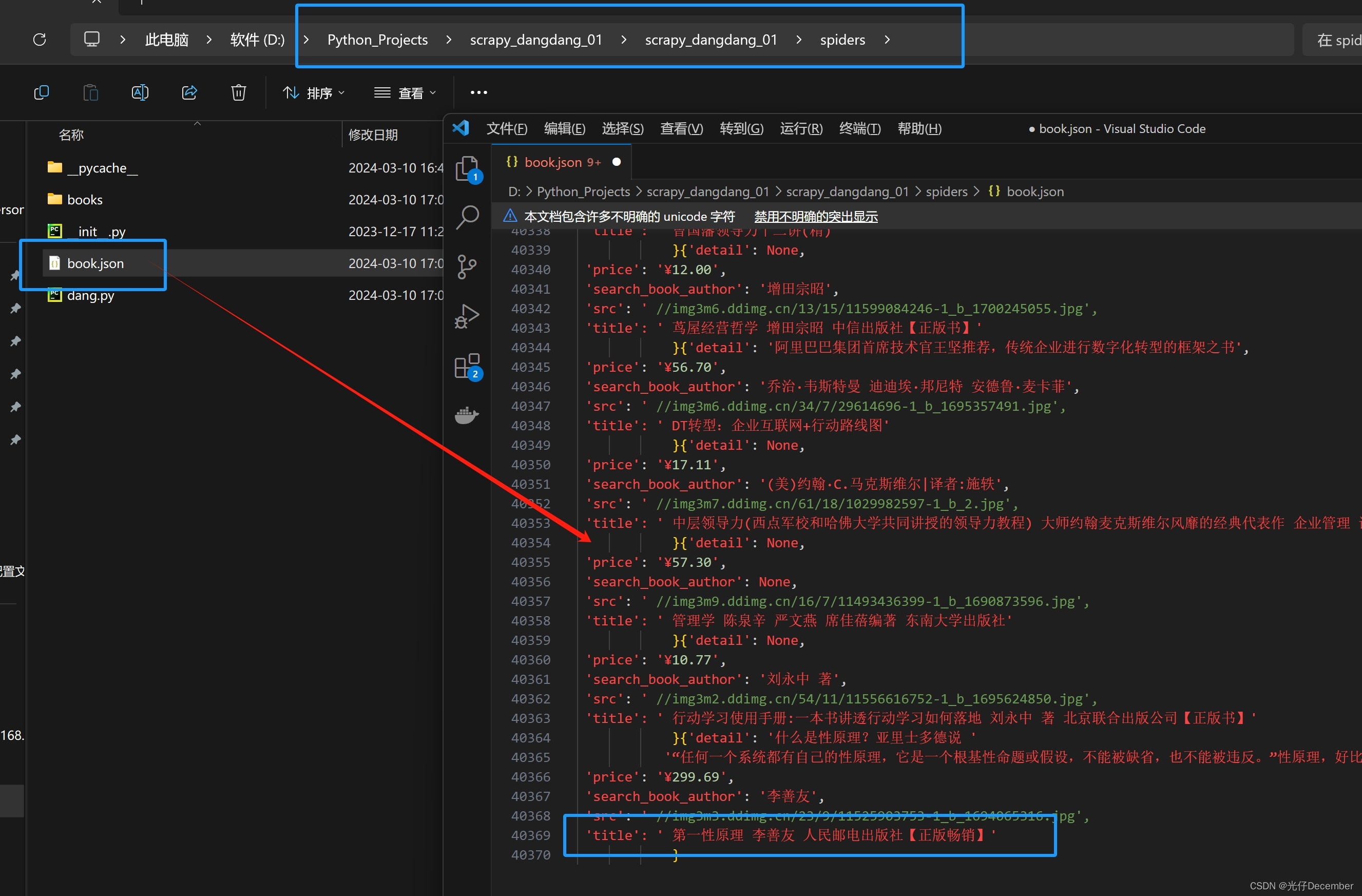
其中最后一个数据,和当前网站的第100页的数据基本吻合: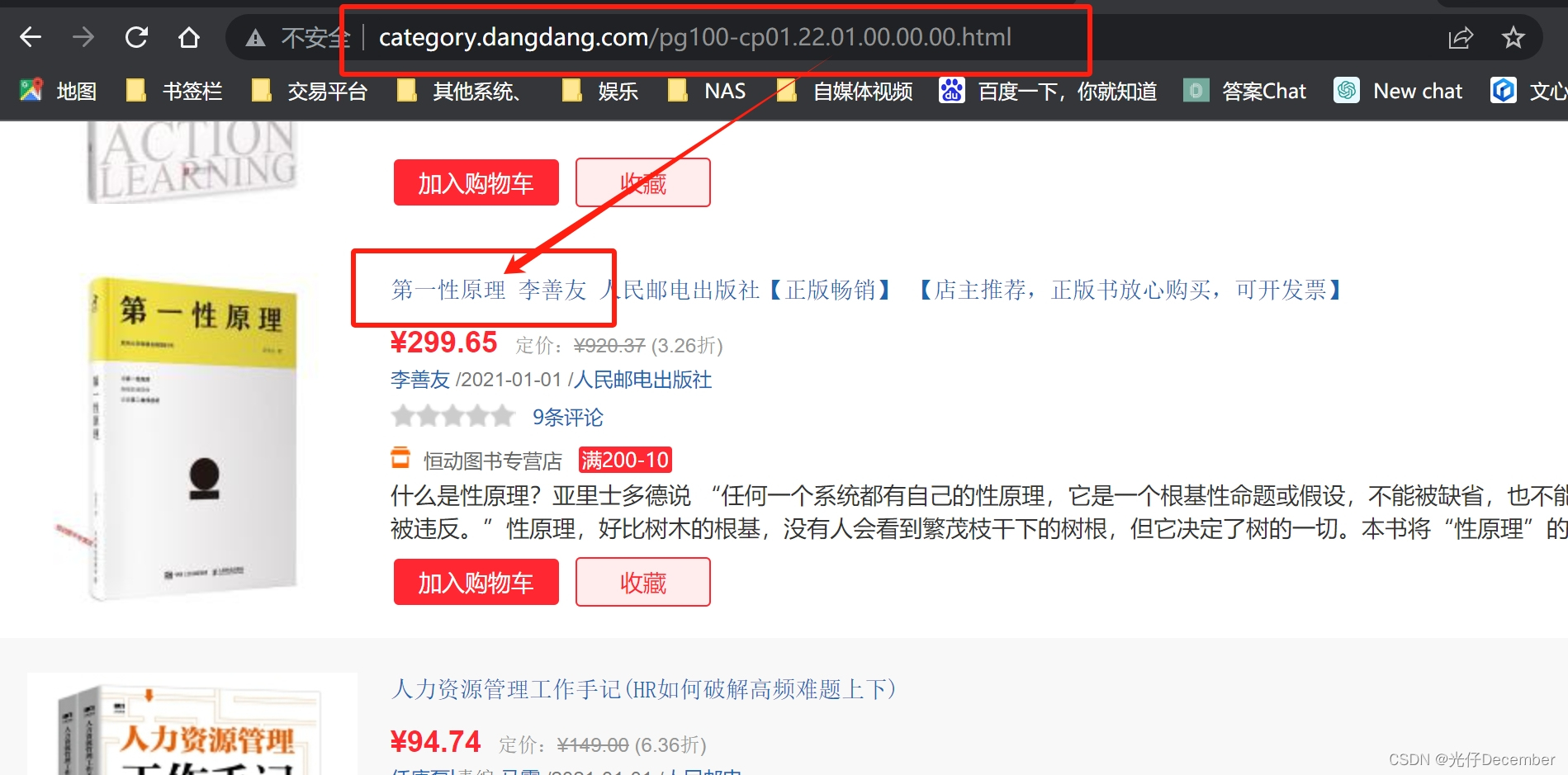
查看一下图片,发现也是全部下载下来了(1页60条数据,100页共6000张封面,我们下载了5700多张),说明1到100页的数据已经基本全部抓取过来了:
4、完整代码
下面是刚刚上面优化完毕后的Scrapy爬虫逻辑的完整代码:
import scrapyfrom scrapy_dangdang_01.items import ScrapyDangdang01Itemclass DangSpider(scrapy.Spider):name = "dang"# 如果为多页下载,必须将allowed_domains的范围调整为主域名allowed_domains = ["category.dangdang.com"]start_urls = ["http://category.dangdang.com/cp01.22.01.00.00.00.html"]base_url = 'http://category.dangdang.com/pg'end_url = '-cp01.22.01.00.00.00.html'page = 1def parse(self, response):# 获取所有的图书列表对象li_list = response.xpath('//ul[@id="component_59"]/li')# 遍历li列表,获取每一个li元素的几个值for li in li_list:# 书籍图片src = li.xpath('.//img/@data-original').extract_first()# 第一张图片没有@data-original属性,所以会获取到控制,此时需要获取src属性值if src:src = srcelse:src = li.xpath('.//img/@src').extract_first()# 书籍名称title = li.xpath('.//img/@alt').extract_first()# 书籍作者search_book_author = li.xpath('./p[@class="search_book_author"]//span[1]//a[1]/@title').extract_first()# 书籍价格price = li.xpath('./p[@class="price"]//span[@class="search_now_price"]/text()').extract_first()# 书籍简介detail = li.xpath('./p[@class="detail"]/text()').extract_first()# print("======================")# print("【图片地址】", src)# print("【书籍标题】", title)# print("【书籍作者】", search_book_author)# print("【书籍价格】", price)# print("【书籍简介】", detail)# 将数据封装到item对象中book = ScrapyDangdang01Item(src=src, title=title, search_book_author=search_book_author, price=price, detail=detail)# 获取一个book对象,就将该对象交给pipelinesyield bookif self.page < 100: # 判断当前页面是否在100页以内self.page = self.page + 1 # 获取下一个页码# 根据获取的页码,拼接下一个需要爬取的页面url地址url = self.base_url + str(self.page) + self.end_url# 回调爬虫的parse函数,用新的url继续进行数据爬取# scrapy.Request就是scrapy的get请求# 其中的url是请求地址,callback是需要执行的爬虫的函数,注意不需要加圆括号yield scrapy.Request(url=url,callback=self.parse)至此,关于Scrapy实战项目的多页数据下载的内容就全部介绍完毕。下一篇我们来讲解电影天堂网站的多页面下载,继续巩固一下多页面下载技术。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/136605061
相关文章:
【Python从入门到进阶】50、当当网Scrapy项目实战(三)
接上篇《49、当当网Scrapy项目实战(二)》 上一篇我们讲解了的Spider与item之间的关系,以及如何使用item,以及使用pipelines管道进行数据下载的操作,本篇我们来讲解Scrapy的多页面下载如何实现。 一、多页面下载原理分…...

【调试记录】vscode远程连接问题汇总
1. kex_exchange_identification kex_exchange_identification: read: Connection reset by xxx.xx.xx.x 一直连不上实验室的服务器,用PUTTY和Mobaxterm也不行(报错:Remote side unexpectedly closed network connection)。已知…...

基于springboot的疾病防控综合系统
采用技术 基于springboot的疾病防控综合系统的设计与实现~ 开发语言:Java 数据库:MySQL 技术:SpringBootMyBatis 工具:IDEA/Ecilpse、Navicat、Maven 系统效果展示 用户功能效果 打卡管理 接种记录查看 公告信息查看 社区…...

js实现文本内容过长中间显示...两端正常展示
实现效果 实现思路 获取标题盒子的真实宽度, 我这里用的是clientWidth;获取文本内容所占的实际宽度;根据文字的大小计算出每个文字所占的宽度;判断文本内容的实际宽度是否超出了标题盒子的宽度;通过文字所占的宽度累加之和与标题…...

Buran勒索病毒通过Microsoft Excel Web查询文件进行传播
Buran勒索病毒首次出现在2019年5月,是一款新型的基于RaaS模式进行传播的新型勒索病毒,在一个著名的俄罗斯论坛中进行销售,与其他基于RaaS勒索病毒(如GandCrab)获得30%-40%的收入不同,Buran勒索病毒的作者仅占感染产生的25%的收入,…...
中间件 | Redis - [基本信息]
INDEX 1 常规用法2 QPS3 pipeline 1 常规用法 分布式锁 最常见用法,需要注意分布式锁的redis需要单点 分布式事务 分布式事务中,核心的技术难点其实是分布式事务这个事本身作为数据的持久化 2PC,比如 seata 的 AT 模式下,将 un…...

【Docker】Neo4j 容器化部署
Neo4j环境标准软件基于Bitnami neo4j 构建。当前版本为5.17.0 你可以通过轻云UC部署工具直接安装部署,也可以手动按如下文档操作,该项目已经全面开源,可以从如下环境获取 配置文件地址: https://gitee.com/qingplus/qingcloud-platform Qin…...

Visual studio编译器报1个无法解析的外部命令
解决思路:(以下思路需对照代码进行逐点分析) ①:代码里函数有声明,但是没有定义 (初学者错这个比较多) ②:类中有静态变量成员,没有对它进行初始化(是变量&…...

微信小程序(五十三)修改用户头像与昵称
注释很详细,直接上代码 上一篇 新增内容: 1.外界面个人资料基本模块 2.资料修改界面同步问题实现(细节挺多,考虑了后期转服务器端的方便之处) 源码: app.json {"window": {},"usingCompone…...
VUE3 显示Echarts百度地图
本次实现最终效果 技术基础以及环境要求 vue3 echarts 百度地图API 要求1: VUE3 环境搭建:https://blog.csdn.net/LQ_001/article/details/136293795 要求2: VUE3 echatrs 环境搭建:https://blog.csdn.net/LQ_001/article/details/1363…...

FFmpeg将视频包AVPacket通过视频流方式写入本地文件
1.写视频头 void writeVideoHeader(const char* videoFileName){int r avformat_alloc_output_context2(&pFormatCtx, nullptr, nullptr,videoFileName);if(r < 0){qDebug()<<"Error: avformat_alloc_output_context2: "<<av_err2str(r);return;…...

C语言连接【MySQL】
稍等更新图片。。。。 文章目录 安装 MySQL 库连接 MySQLMYSQL 类创建 MySQL 对象连接数据库关闭数据库连接示例 发送命令设置编码格式插入、删除或修改记录查询记录示例 参考资料 安装 MySQL 库 在 CentOS7 下,使用命令安装 MySQL: yum install mysq…...

_note_09
1.说一说类加载的过程 加载(Loading) -> 验证(Verification) -> 准备(Preparation) -> 解析(Resolution) -> 初始化(Initialization)类的加载是…...

是否可以在HTTP中缓存POST方法
如果您想知道是否可以缓存post请求,并尝试研究该问题的答案,那么您很可能不会成功。当搜索“缓存post请求”时,第一个结果是这个StackOverflow问题。 答案是令人困惑的,包括缓存应该如何工作,缓存如何根据RFC工作&…...

Xilinx 7系列FPGA配置(ug470)
Xilinx 7系列FPGA配置(ug470) 配置模式串行配置模式接口从-连接方式主-连接方式串行菊花链(非同时配置)串行配置(同时配置)时序 主SPI配置模式SPIx1/x2 连接图SPIx1模式时序SPIx4 连接图SPI操作指令操作fla…...

3分钟开通GPT-4
AI从前年12月份到现在已经伴随我们一年多了,还有很多小伙伴不会开通,其实开通很简单,环境需要自己搞定,升级的话就需要一张visa卡,办理visa卡就可以直接升级chatgptPLSU 一、虚拟卡支付 这种方式的优点是操作简单&…...

Easticsearch性能优化之索引优化
Easticsearch性能优化之索引优化 一、合理的索引设计二、合理的分片和副本三、合理的索引设置 对于性能优化,Elasticsearch(以下简称ES)的索引优化是提高性能的关键因素之一。合理的设计索引,合理的分片和副本以及合理的缓存设置等…...

安装mysql-8.0.30-winx64(windows 64位)
1.下载 1.1下载地址:https://dev.mysql.com/downloads/mysql/ 2 .下载后解压缩目标文件 2.1之后在根目录下新建my.ini文件,并创建文件夹data (新解压的文件没有my.ini文件,需自行创建 复制以下代码到my.ini文件 以下代码除安装目录和数据的…...
ios xcode 15 PrivacyInfo.xcprivacy 隐私清单
1.需要升级mac os系统到13 兼容 xcode 15.1 2.升级mac os系统到14 兼容 xcode 15.3 3.选择 New File 4.直接搜索 privacy 能看到有个App Privacy 5.右击Add Row 7.直接选 Label Types 8.选中继续添加就能添加你的隐私清单了 苹果官网文档Describing data use in privacy man…...

【物联网】-智能社会的分类
万物感知 感知物理世界,变成数字信号 (温度、空间、触觉、嗅觉、听觉、视觉) 万物互联 将数据变成online,使智能化 (宽联接、广联接、多联接和深联接) 万物智能 基于大数据和人工智能的应用 &#…...

.NET 新特性概览与相关文章索引蜕
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...

PAJ7620手势传感器Arduino驱动库详解
1. 项目概述RevEng PAJ7620 是一个面向嵌入式平台的 Arduino 兼容 C 驱动库,专为 PixArt 公司推出的 PAJ7620 系列集成手势识别传感器设计。该库完整支持 PAJ7620、PAJ7620U2 和 PAJ7620F2 三种硬件变体,其核心目标是将底层寄存器操作、IC 协议时序、模式…...

ESP32/ESP8266轻量级OTA固件升级库详解
1. 项目概述ESP32FwUploader 是一款专为 ESP32 和 ESP8266 系列微控制器设计的轻量级、高可靠性固件空中升级(Over-The-Air, OTA)库。它并非简单封装 ESP-IDF 或 Arduino Core 的原生 OTA 接口,而是以“开箱即用”和“工程鲁棒性”为核心目标…...

【JavaScript高级编程】拆解函数流水线 上衫
一、什么是setuptools? setuptools 是一个用于创建、分发和安装 Python 包的核心库。 它可以帮助你: 定义 Python 包的元数据(如名称、版本、作者等)。 声明包的依赖项,确保你的包能够正确运行。 构建源代码分发包&…...
的实战应用与数据处理指南)
GNSS差分码偏差(DCB)的实战应用与数据处理指南
1. GNSS差分码偏差(DCB)的核心概念解析 第一次接触DCB这个概念时,我也被各种专业术语绕得头晕。简单来说,你可以把DCB想象成GNSS信号在传输过程中产生的"指纹识别误差"。就像不同品牌的手机充电线给同一台设备充电时&am…...

Comsol 微穿孔板吸声性能优化:基于多算法求解器的参数调优实践
1. 微穿孔板吸声体的技术魅力与优化挑战 第一次接触微穿孔板吸声体时,我就被它的设计理念深深吸引。这种由亚毫米级穿孔薄板和背后空腔组成的结构,不需要传统吸声材料就能实现优异的声学性能。在实际工程项目中,从录音棚到高铁车厢࿰…...

SEATA分布式事务——AT模式挠
简介 AI Agent 不仅仅是一个能聊天的机器人(如普通的 ChatGPT),而是一个能够感知环境、进行推理、自主决策并调用工具来完成特定任务的智能系统,更够完成更为复杂的AI场景需求。 AI Agent 功能 根据查阅的资料,agent的…...

运算放大器电流流向的3个常见误区,硬件工程师必看避坑指南
运算放大器电流流向的3个常见误区,硬件工程师必看避坑指南 在硬件电路设计中,运算放大器(Op-Amp)作为模拟电路的核心器件,其电流流向的理解直接影响电路性能与稳定性。然而,即使是经验丰富的工程师…...

UniApp分包避坑指南:pages.json配置常见错误与各平台大小限制详解
UniApp分包实战手册:从配置陷阱到多平台适配策略 第一次在UniApp项目里尝试分包时,我盯着微信开发者工具里那个刺眼的"主包超限"警告整整十分钟。这就像玩俄罗斯方块——明明每个模块都精心设计,却在最后关头因为几KB的差距功亏一篑…...

React/Vue项目部署后,刷新页面就404?一个Nginx配置帮你搞定
React/Vue项目部署后刷新页面404?Nginx配置终极解决方案 刚部署完React/Vue项目时,很多开发者都会遇到一个诡异现象:首页访问正常,但点击内部路由后再刷新页面,浏览器突然弹出404错误。这就像魔术师的手帕突然消失一样…...