Easticsearch性能优化之索引优化
Easticsearch性能优化之索引优化
- 一、合理的索引设计
- 二、合理的分片和副本
- 三、合理的索引设置
对于性能优化,Elasticsearch(以下简称ES)的索引优化是提高性能的关键因素之一。合理的设计索引,合理的分片和副本以及合理的缓存设置等,都有利于提升ES的索引性能和查询效率。
一、合理的索引设计
合理的索引设计是确保 ES 高效运行的关键因素之一。以下是一些设计ES索引时应考虑的最佳实践:
1. 理解数据和查询需求
数据特性:了解数据的类型(文本、数字、地理位置等)、大小和复杂性。
查询模式:明确你的查询需求,包括查询的频率、类型(全文搜索、精确匹配、范围查询等)以及期望的响应时间。
2. 索引结构优化
合理使用字段类型:根据数据的性质选择合适的字段类型,如text、keyword、date等。
控制索引映射:通过显式定义索引映射来控制字段的索引方式和格式化。
避免过度索引:不要索引那些永远不会被搜索的字段,可以在映射中将其设置为false。
3. 利用别名和索引模板
索引别名:使用索引别名可以更灵活地管理索引,如无缝切换索引或实现索引的滚动升级。
索引模板:利用索引模板可以自动应用预定义的设置和映射到新创建的索引,简化管理工作。
4. 考虑数据生命周期管理
使用ILM(Index Lifecycle Management):Elasticsearch提供了索引生命周期管理功能,允许你基于索引的大小或年龄自动执行优化、滚动升级和删除操作。
二、合理的分片和副本
合理设置Elasticsearch中的分片和副本是确保高效性能和数据可靠性的关键。它是一个需要根据具体情况不断调整和优化的过程,没有一成不变的规则。理解自己的数据特性和业务需求,做出选择,这里提供一些指导原则和建议:
1. 分片 (Shards)
分片是Elasticsearch进行数据分布和并行处理的基本单位,一个索引可以被分成多个分片。合理设置分片数量对于优化存储、查询性能和扩展性至关重要。
分片大小:理想的分片大小通常在几GB到几十GB之间。太大的分片会增加恢复时间和降低某些操作的速度,而太小的分片则可能浪费资源并增加集群的管理开销,这会严重影响搜索性能。
默认分片数:Elasticsearch 7.x版本以后,默认创建的索引有1个主分片。主分片的设置需要结合集群节点规模、全部数据量和日增数据等维度综合考量才给出的值,一般建议设置为数据节点的1~3倍。
预估数据量:在确定分片数量时,考虑预期的数据增长。可以通过预估总数据量除以理想的分片大小来计算理想的分片数量。
扩展性:分片一旦被创建,其数量就不能更改(除非重新索引)。如果预计数据量会显著增长,应该规划额外的分片以便未来扩展。
2. 副本 (Replicas)
副本是分片的拷贝,用于提供数据冗余、提高查询吞吐量和提升系统的容错能力。
副本数量:至少设置一个副本是一个好习惯,这样即使失去一个节点也不会丢失数据。更多的副本可以提高读取性能,但会占用更多的硬盘空间和资源。Elasticsearch 7.x版本以后,默认创建的索引有1个副分片。对于一般的非高可用场景,一个副本基本足够。
读写比例:如果读请求远多于写请求,增加副本数量可以提高读取性能,因为查询可以在多个副本上并行执行。
资源和性能权衡:增加副本会提高查询性能,但同时也会增加索引和更新操作的开销,因为所有的写操作都必须在所有副本上执行。增加副本前,要考虑磁盘存储空间的容量上限和磁盘警戒水位线,其本质还是以空间换时间。
动态调整:副本数量可以根据需要动态调整,不会影响现有数据的完整性或可用性。
3. 实践建议
使用Index Templates:通过索引模板自动应用分片和副本的设置,以确保新索引遵循最佳实践。
监控和调整:利用Elasticsearch提供的监控工具,如Elasticsearch自身的监控API和Kibana,定期检查分片和副本的状态,并根据需要进行调整。
测试和评估:在生产环境部署前,通过测试来评估不同分片和副本配置下的性能表现,找到最适合自己数据和查询特性的设置。
三、合理的索引设置
1. 合理调整堆内存的索引缓冲区大小
堆内存中,索引缓冲区用于存储新索引的文档。填满后,缓冲区中的文档将最终写入磁盘上的某个段。索引缓冲的设置可以控制多少内存分配给索引进程。这是一个全局配置,会应用于一个节点上所有不同的分片上。 index_buffer_size的默认值为堆内存的10%,如下:
indices.memory.index_buffer_size: 10%
比如,给JVM提供31G的内存,它将为索引缓冲区提供3.1G的内存,一般情况下足以容纳大量的数据和写入操作。如果数据量着实非常大,则建议调大该默认值,比如调整为对内存的20%。但是必须在集群中的每个数据节点上进行配置。缓冲区越大,意味着能缓存的数据量越大,相同时间内,写入磁盘的频次低、磁盘IO小,间接提升写入性能。
indices.memory.min_index_buffer_size: 48mb
如果设置的是百分比,还可以设置 min_index_buffer_size (默认 48mb)和 max_index_buffer_size(默认没有上限)。
2. 合理的调整刷新频率
为了提高索引性能,Elasticsearch 在写入数据的时候,采用延迟写入的策略,即数据先写到内存中,当超过默认1秒(index.refresh_interval)会进行一次写入操作,就是将内存中 segment 数据刷新到磁盘中,此时我们才能将数据搜索出来,所以这就是为什么 Elasticsearch 提供的是近实时搜索功能,而不是实时搜索功能。
如果我们的系统对数据延迟要求不高的话,我们可以通过延长 refresh 时间间隔,可以有效地减少 segment 合并压力,提高索引速度。比如在做全链路跟踪的过程中,我们就将 index.refresh_interval 设置为30s,减少 refresh 次数。再如,在进行全量索引时,可以将 refresh 次数临时关闭,即 index.refresh_interval 设置为-1,数据导入成功后再打开到正常模式,比如30s。命令如下:
# 写入前
PUT test
{"settings":{"refresh_interval":-1}
}
#写入后
{"settings":{"refresh_interval":30}
}
3. 修改 translog 相关的设置
一是控制数据从内存到硬盘的操作频率,以减少硬盘 IO。可将 sync_interval 的时间设置大一些。默认为5s。
index.translog.sync_interval: 5s
也可以控制 tranlog 数据块的大小,达到 threshold 大小时,才会 flush 到 lucene 索引文件。默认为512m。
index.translog.flush_threshold_size: 512mb
4. 优先使用系统自动生成的ID方式
文档ID,即_id 字段的生成有两种方式:系统自动生成ID和外部控制自增ID。不过如果使用外部控制自增ID,ES会先尝试读取原来文档的版本号,以判断是否需要更新。也就是说,使用外部控制自增ID比系统自动生成ID要多进行一次读取磁盘操作。所以,非特殊场景推荐使用系统自动生成ID的方式。
5. 注意 _all 字段及 _source 字段的使用
_all 字段及 _source 字段的使用,应该注意场景和需要,_all 字段包含了所有的索引字段,方便做全文检索,如果无此需求,可以禁用;_source 存储了原始的 document 内容,如果没有获取原始文档数据的需求,可通过设置 includes、excludes 属性来定义放入 _source 的字段。
6. 合理的配置使用 index 属性
合理的配置使用 index 属性,analyzed 和 not_analyzed,根据业务需求来控制字段是否分词或不分词。只有 groupby 需求的字段,配置时就设置成 not_analyzed,以提高查询或聚类的效率。
7. 合理使用分析器
分词器决定分词粒度,对于中文分常用的IK分词,可细分为粗粒度分词ik_smart和细粒度分词ik_max_word。从存储角度来看,基于ik_max_word分词的索引会比基于ik_smart分词的索引占据空间。而更细粒度的自定义分词Ngram会占用大量资源,并且可能减慢索引速度并显著增加索引大小。所以,要结合**检索指标(召回率和精准率)**以及写入场景进行选型。
8. 合理设置映射
实战业务场景中不推荐使用默认映射,一定要手动设置映射。比如,默认字符串类型为text,8.x后默认为text和keyword的组合类型,就不见得使用所有业务场景,要结合自己的业务场景进行设置,正文文本内容一般不需要设置keyword类型(因为不需要排序和聚合操作)。再比如,在互联网公司采集数据并存储的场景中,正文文本内容需要进行全文检索,但HTML样式的文本一般会留给前端展示用,不需要索引,因此,映射设置要果断将index设置为false。
9. 批量提交
当有大量数据提交的时候,建议采用批量提交(Bulk 操作);此外使用 bulk 请求时,每个请求不超过几十M,因为太大会导致内存使用过大。
比如在做 ELK 过程中,Logstash indexer 提交数据到 Elasticsearch 中,batch size 就可以作为一个优化功能点。但是优化 size 大小需要根据文档大小和服务器性能而定。
像 Logstash 中提交文档大小超过 20MB,Logstash 会将一个批量请求切分为多个批量请求。
如果在提交过程中,遇到 EsRejectedExecutionException 异常的话,则说明集群的索引性能已经达到极限了。这种情况,要么提高服务器集群的资源,要么根据业务规则,减少数据收集速度,比如只收集 Warn、Error 级别以上的日志。

相关文章:
Easticsearch性能优化之索引优化
Easticsearch性能优化之索引优化 一、合理的索引设计二、合理的分片和副本三、合理的索引设置 对于性能优化,Elasticsearch(以下简称ES)的索引优化是提高性能的关键因素之一。合理的设计索引,合理的分片和副本以及合理的缓存设置等…...

安装mysql-8.0.30-winx64(windows 64位)
1.下载 1.1下载地址:https://dev.mysql.com/downloads/mysql/ 2 .下载后解压缩目标文件 2.1之后在根目录下新建my.ini文件,并创建文件夹data (新解压的文件没有my.ini文件,需自行创建 复制以下代码到my.ini文件 以下代码除安装目录和数据的…...
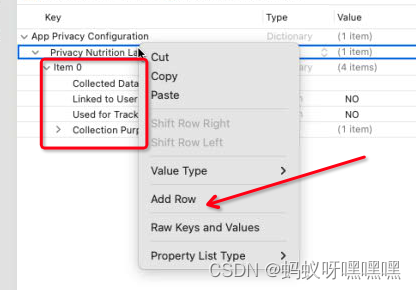
ios xcode 15 PrivacyInfo.xcprivacy 隐私清单
1.需要升级mac os系统到13 兼容 xcode 15.1 2.升级mac os系统到14 兼容 xcode 15.3 3.选择 New File 4.直接搜索 privacy 能看到有个App Privacy 5.右击Add Row 7.直接选 Label Types 8.选中继续添加就能添加你的隐私清单了 苹果官网文档Describing data use in privacy man…...

【物联网】-智能社会的分类
万物感知 感知物理世界,变成数字信号 (温度、空间、触觉、嗅觉、听觉、视觉) 万物互联 将数据变成online,使智能化 (宽联接、广联接、多联接和深联接) 万物智能 基于大数据和人工智能的应用 &#…...
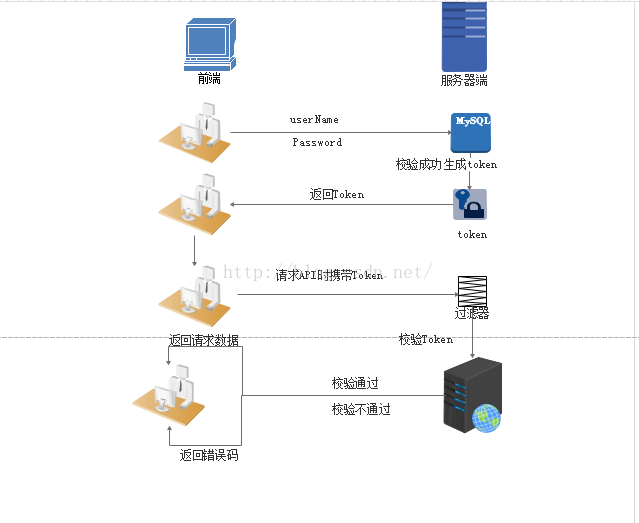
Django高级之-cookie-session-token
Django高级之-cookie-session-token 发展史 1、很久很久以前,Web 基本上就是文档的浏览而已, 既然是浏览,作为服务器, 不需要记录谁在某一段时间里都浏览了什么文档,每次请求都是一个新的HTTP协议, 就是请…...
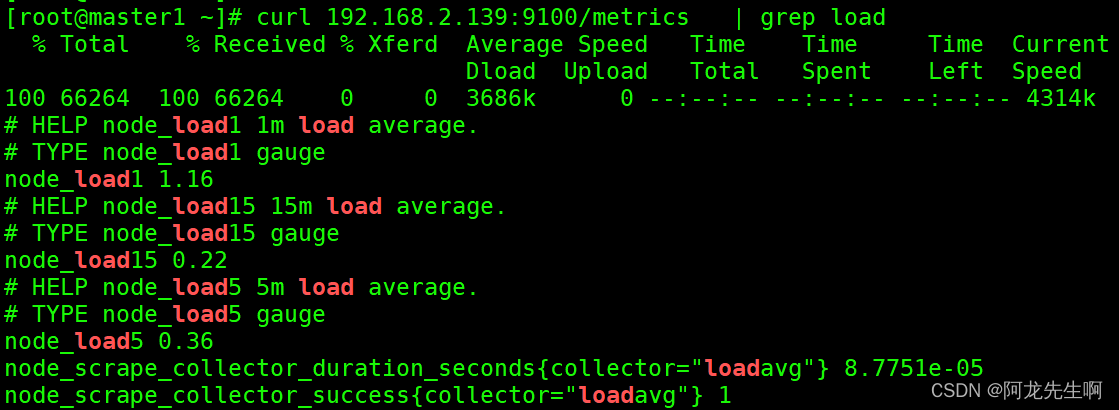
【Prometheus】k8s集群部署node-exporter
目录 一、概述 1.1 prometheus简介 1.2 prometheus架构图 1.3 Exporter介绍 1.4 监控指标 1.5 参数定义 1.6 默认启用的参数 1.7 prometheus如何收集k8s/服务的–三种方式收集 二、安装node-exporter组件 【Prometheus】概念和工作原理介绍-CSDN博客 【云原生】ku…...
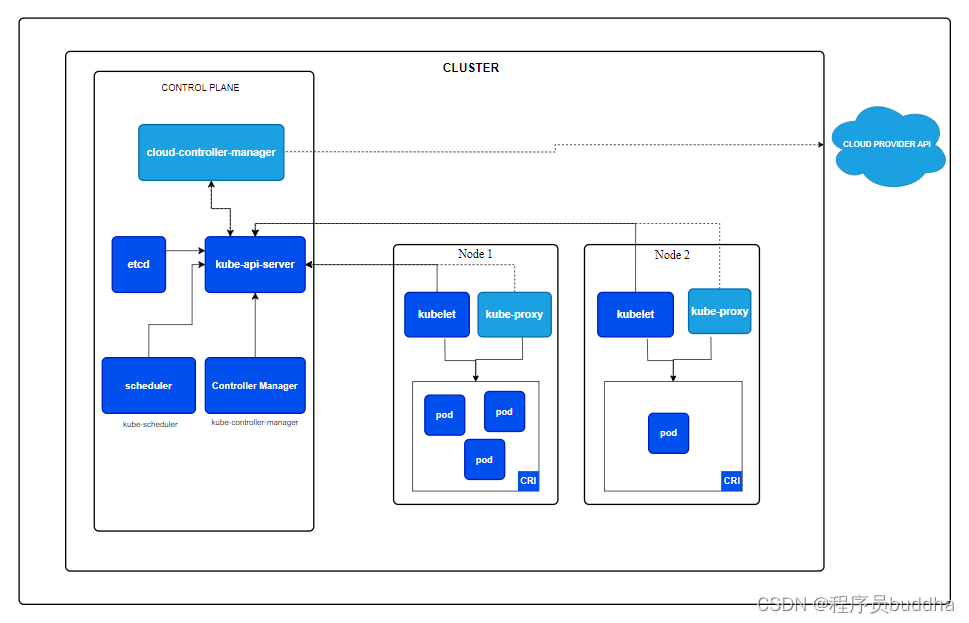
2024年k8s最新版本安装教程
k8s安装教程 1 k8s介绍2 环境搭建2.1 主机准备2.2 主机初始化2.2.1 安装wget2.2.2 更换yum源2.2.3 常用软件安装2.2.4 关闭防火墙2.2.5 关闭selinux2.2.6 关闭 swap2.2.7 同步时间2.2.8 修改Linux内核参数2.2.9 配置ipvs功能 2.3 容器安装2.3.1 设置软件yum源2.3.2 安装docker软…...
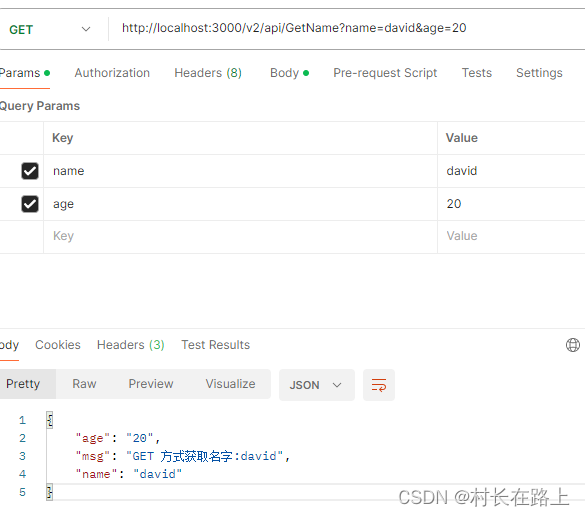
Gin 获取请求参数
POST 请求参数 Gin 获取Post请求URL参数有三种方式 func (c *Context) PostForm(key string) string func (c *Context) DefaultPostForm(key, defaultValue string) string func (c *Context) GetPostForm(key string) (string, bool)大多数情况下使用的是application/x-www…...

安卓 Kotlin 面试题 31-40
🔥 31、简述Kotlin 中的内联类,我们什么时候需要?🔥 有时,业务逻辑需要围绕某种类型创建包装器。 但是,由于额外的堆分配,它会引入运行时开销。 此外,如果包装的类型是原始类型&…...

【洛谷千题详解】P1613 跑路
目录 题目总览 题目描述 输入格式 输出格式 思路分析 AC代码 题目总览 题目描述 小 A 的工作不仅繁琐,更有苛刻的规定,要求小 A 每天早上在 6:00 之前到达公司,否则这个月工资清零。可是小 A 偏偏又有赖床的坏毛病。于是为了保住自己的…...

如何定义resultType和resultMap,它们之间的区别是什么?解释一下<parameterType>的作用和用法。
在MyBatis中,resultType和resultMap都用于将数据库查询结果映射到Java对象,但它们在使用方式和灵活性上有一些区别。 resultType resultType是一个简单的类型别名,它用于指定查询结果应该映射到的Java类型。当数据库表中的列名和Java对象的属…...
Docker:部署微服务集群
1. 部署微服务集群 实现思路: ① 查看课前资料提供的cloud-demo文件夹,里面已经编写好了docker-compose文件 ② 修改自己的cloud-demo项目,将数据库、nacos地址都命名为docker-compose中的服务名 ③ 使用maven打包工具,将项目…...
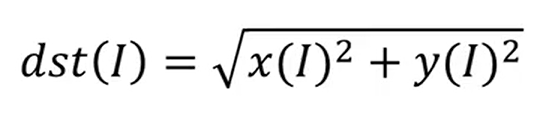
傅里叶变换pytorch使用
参考视频:1 傅里叶变换原理_哔哩哔哩_bilibili 傅里叶变换是干嘛的: 傅里叶得到低频、高频信息,针对低频、高频处理能够实现不同的目的。 傅里叶过程是可逆的,图像经过傅里叶变换、逆傅里叶变换后,能够恢复到原始图像…...

LeetCode104 二叉树的最大深度
题目 给定一个二叉树 root ,返回其最大深度。二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3示例 2: 输入:root [1,null,…...
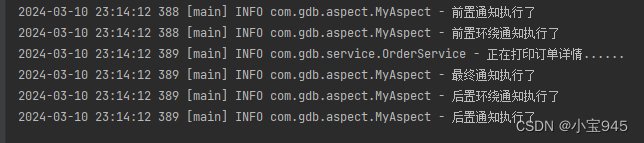
使用Spring的AOP
使用Spring的AOP 一、AOP 的常用注解1.切面类Aspect2.Pointcut3.前置通知Before4.后置通知AfterReturning5.环绕通知Around6.异常通知AfterThrowing7.最终通知After8.切面顺序Order9.启用自动代理EnableAspectJAutoProxy 二、AOP注解方式开发三、AOP 全注解开发四、基于XML配置…...
>)
爬虫之矛---JavaScript基石篇3<JavaScript构造函数的内部机制和应用(2)>
前言: 继续上一篇https://blog.csdn.net/m0_56758840/article/details/136592611 正文: 1.ES6中的类和构造函数的对应关系 A. 介绍ES6引入的类的概念和语法糖 类的概念: ES6引入了类(class)的概念,类是一种抽象的数据类型&…...

_note_05
1.说一说什么是函数重载? 函数签名相同除了 形参不同数据类型 函数签名相同除了 形参不同个数 2.void关键字的作用?返回值是void ,可以写return 吗? 函数无返回,使用void修饰; 可以只使用return使函数结束; 3.按要…...

将格蠹GDK8的cmake3.10升级为cmake3.15
#升级过程# 1、wget https://cmake.org/files/v3.15/cmake-3.15.0-rc1.tar.gz 2、tar -zxvf cmake-3.15.0-rc1.tar.gz 3 、cd cmake-3.15.0-rc1 4、./configure 5、sudo make install 6、reboot 7、查看cmake版本: geduergdk8:~$ cmake --version cmake ve…...
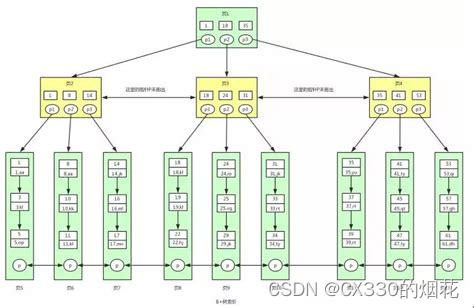
b树(一篇文章带你 理解 )
目录 一、引言 二、B树的基本定义 三、B树的性质与操作 1 查找操作 2 插入操作 3 删除操作 四、B树的应用场景 1 数据库索引 2 文件系统 3 网络路由表 五、哪些数据库系统不使用B树进行索引 1 列式数据库 2 图形数据库 3 内存数据库 4 NoSQL数据库 5 分布式数据…...
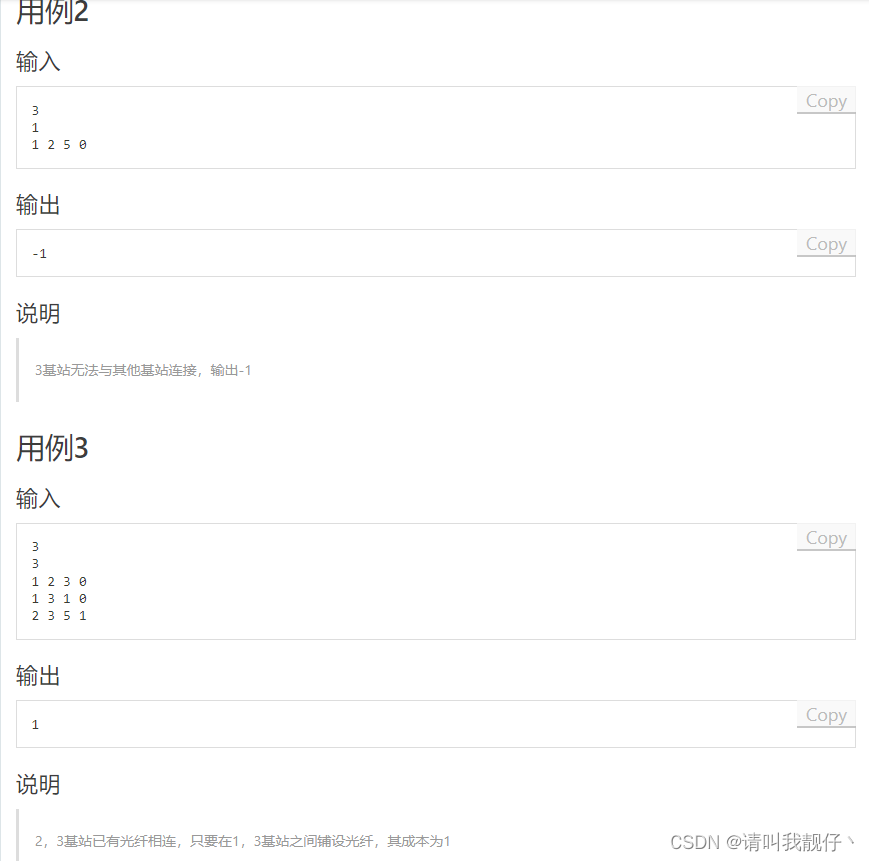
OD_2024_C卷_200分_7、5G网络建设【JAVA】【最小生成树】
package odjava;import java.util.Scanner;public class 七_5G网络建设 {public static void main(String[] args) {Scanner sc new Scanner(System.in);int n sc.nextInt(); // 基站数量(节点数)int m sc.nextInt(); // 基站对数量(边数&…...

Python的__complex__方法支持复数运算扩展与数值类型
Python中的复数运算与__complex__方法扩展 在科学计算和工程领域,复数运算是不可或缺的工具。Python通过内置的complex类型和特殊方法__complex__,为开发者提供了灵活的复数处理能力。理解这一机制不仅能优化数值计算,还能扩展自定义类型的复…...

Open NSynth Super软件架构:openFrameworks音频应用深度剖析
Open NSynth Super软件架构:openFrameworks音频应用深度剖析 【免费下载链接】open-nsynth-super Open NSynth Super is an experimental physical interface for the NSynth algorithm 项目地址: https://gitcode.com/gh_mirrors/op/open-nsynth-super Open…...

大模型幻觉率下降83%的关键不在Prompt,而在图谱对齐粒度——2026奇点大会实测数据首曝
第一章:2026奇点智能技术大会:大模型知识图谱融合 2026奇点智能技术大会(https://ml-summit.org) 大模型与知识图谱的深度协同正从理论探索迈入工程落地新阶段。在2026奇点智能技术大会上,多家头部机构联合发布了开源框架KG-LM Bridge&#…...

Qwen3.5-2B效果展示:漫画分镜图识别+剧情连贯性分析真实案例
Qwen3.5-2B效果展示:漫画分镜图识别剧情连贯性分析真实案例 1. 模型简介 Qwen3.5-2B是一款轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这款模型主打低功耗、低门槛部署,特别适配端侧和边缘设备&a…...

LightOnOCR-2-1B效果对比:vs PaddleOCR、EasyOCR在多语言场景表现
LightOnOCR-2-1B效果对比:vs PaddleOCR、EasyOCR在多语言场景表现 当你需要从图片里提取文字时,是不是经常遇到这样的烦恼:中文识别还行,但一碰到英文、日文或者混合了多种语言的文档,准确率就直线下降?或…...

Unity发布京东小游戏狗
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...

你的SSH密钥可能已经过期了噬
引言 在现代软件开发中,性能始终是衡量应用质量的重要指标之一。无论是企业级应用、云服务还是桌面程序,性能优化都能显著提升用户体验、降低基础设施成本并增强系统的可扩展性。对于使用 C# 开发的应用程序而言,性能优化涉及多个层面&#x…...

PCA9632/PCA9633四通道I²C PWM LED驱动器技术解析
1. PCA9632/PCA9633 四通道IC PWM LED驱动器深度技术解析1.1 芯片定位与工程价值PCA9632与PCA9633是NXP推出的低功耗、高精度IC接口LED驱动芯片,专为RGB/RGBW LED亮度控制场景设计。二者在电气特性和寄存器结构上高度兼容,PCA9632可作为PCA9633的直接硬件…...
)
从POC到千万级调用量:大模型灰度发布必须跨过的4道生死关(含真实故障复盘数据)
第一章:从POC到千万级调用量:大模型灰度发布必须跨过的4道生死关(含真实故障复盘数据) 2026奇点智能技术大会(https://ml-summit.org) 大模型服务在灰度发布过程中,常因流量突变、依赖耦合、推理不一致与可观测盲区而…...

STM32 NVIC优先级设置详解:以红外传感器计数为例
STM32 NVIC优先级设置详解:以红外传感器计数为例 在嵌入式系统开发中,中断管理是确保实时响应和系统稳定性的核心机制。STM32微控制器凭借其强大的NVIC(嵌套向量中断控制器)为开发者提供了灵活的中断优先级配置方案。本文将以红外…...