ELFK 分布式日志收集系统
-
ELFK的组成:
-
- Elasticsearch: 它是一个分布式的搜索和分析引擎,它可以用来存储和索引大量的日志数据,并提供强大的搜索和分析功能。 (java语言开发,)
- logstash: 是一个用于日志收集,处理和传输的工具,它可以从各种数据源收集日志数据,对数据进行处理和过滤,将数据发送到Elasticsearch。 java
- kibana: 是一个用于数据可视化和分析的工具,它可以与Elasticsearch集成,帮助用户通过图表、仪表盘等方式直观地展示和分析日志数据。 java
- filebeat: 轻量级日志收集工具,一般安装在客户端服务器上负责收集日志,传输到ES或logstash go
-
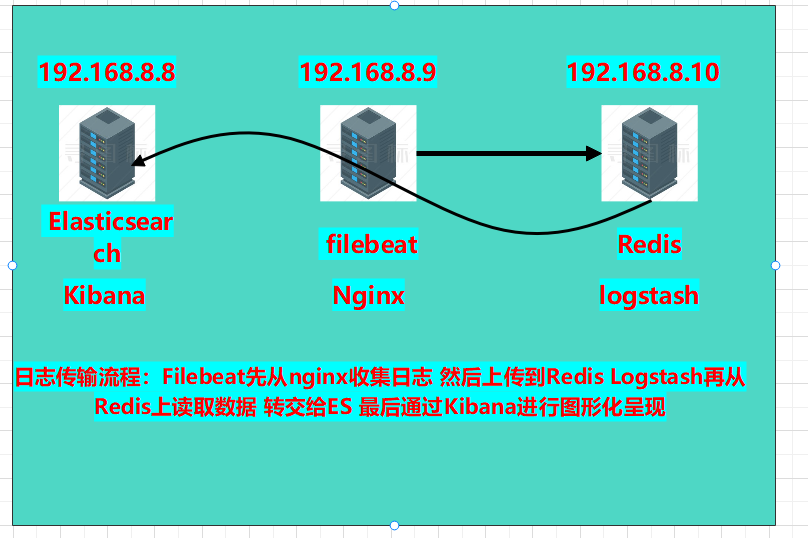
本章实验环境拓扑图:
-
- 版本介绍:
- Elasticsearch:6.6.0
- kibana:6.6.0
- filebeat:6.6.0
- nginx:1.18.0
- Redis:5.0.7
- logstash:6.6.0
- 开始部署:
- 部署8.8服务器的es和Kibna:a
- 复制软件包至服务器下安装:
- rpm -ivh elasticsearch-6.6.0.rpm
- 修改配置文件:
- vim /etc/elasticsearch/elasticsearch.yml
-
node.name: es1 path.data: /data/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 192.168.8.8,127.0.0.1 http.port: 9200
-
- vim /etc/elasticsearch/elasticsearch.yml
- 创建数据目录,并修改权限
-
mkdir -p /data/elasticsearch chown -R elasticsearch.elasticsearch /data/elasticsearch/
-
- 启动es:systemctl start elasticsearch
- 部署安装kibana:
- 安装kibana:rpm -ivh kibana-6.6.0-x86_64.rpm
- 修改配置文件:
- 修改项:
-
server.port: 5601 server.host: "192.168.8.8" server.name: "db01" #自己所在主机的主机名 elasticsearch.hosts: ["http://192.168.8.8:9200"] #es服务器的ip,便于接收日志数据 保存退出
-
- 修改项:
- 启动kibana:systemctl start kibana
- 查看两个服务的端口是否存在:
- netstat -anpt | grep 5601
- netstat -anpt | grep 9200
- 复制软件包至服务器下安装:
- 部署8.9服务器山的nginx和filebeat:
- 安装filebeat:
- rpm -ivh filebeat-6.6.0-x86_64.rpm
- 修改配置文件:
- vim /etc/filebeat/filebeat.yml (清空源内容,直接覆盖)
-
filebeat.inputs: (日志来源) - type: log (日志格式)enabled: true (开机自启)paths: (日志路径)- /var/log/nginx/access.logoutput.elasticsearch: (日志传送到那)hosts: ["192.168.8.8:9200"]
-
-
启动filebeat服务:
-
systemctl start filebeat
-
- vim /etc/filebeat/filebeat.yml (清空源内容,直接覆盖)
-
安装nginx:
-
yum -y install nginx
-
启动nginx:nginx
-
- 安装filebeat:
-
在8.8服务器上安装网站压力测试工具:
-
yum -y install httpd-tools
-
-
2.使用ab压力测试工具测试访问
-
ab -c 1000 -n 20000 http://192.168.8.9/
-c(并发数) -n(请求数)
-
- 部署8.8服务器的es和Kibna:a
-
使用浏览器扩展程序登录es查看索引是否有访问数:
-
-
修改nginx的日志格式为json格式:
-
vim /etc/nginx/nginx.conf
-
添加在http{}内:
-
log_format log_json '{ "@timestamp": "$time_local", ' '"remote_addr": "$remote_addr", ' '"referer": "$http_referer", ' '"request": "$request", ' '"status": $status, ' '"bytes": $body_bytes_sent, ' '"agent": "$http_user_agent", ' '"x_forwarded": "$http_x_forwarded_for", ' '"up_addr": "$upstream_addr",' '"up_host": "$upstream_http_host",' '"up_resp_time": "$upstream_response_time",' '"request_time": "$request_time"' ' }';access_log /var/log/nginx/access.log log_json;
-
-
重启服务:systemctl restart nginx
-
-
修改filebeat.yml文件,区分nginx的访问日志和错误日志
-
vim /etc/filebeat/filebeat.yml
-
修改为: filebeat.inputs: - type: logenabled: truepaths:- /var/log/nginx/access.logjson.keys_under_root: truejson.overwrite_keys: truetags: ["access"]- type: logenabled: truepaths:- /var/log/nginx/error.logtags: ["error"]output.elasticsearch:hosts: ["192.168.8.8:9200"]indices:- index: "nginx-access-%{+yyyy.MM.dd}"when.contains:tags: "access"- index: "nginx-error-%{+yyyy.MM.dd}"when.contains:tags: "error"setup.template.name: "nginx" setup.template.patten: "nginx-*" setup.template.enabled: false setup.template.overwrite: true
-
-
重启服务:systemctl restart filebeat
-
-
使用ab工具压力测试一下网站:
-
测试访问数据:ab -c 1000 -n 20000 http://192.168.8.9/
-
测试错误数据:ab -c 1000 -n 20000 http://192.168.8.9/444.html
-
可以看到es收集到了两个索引:
-
-
-
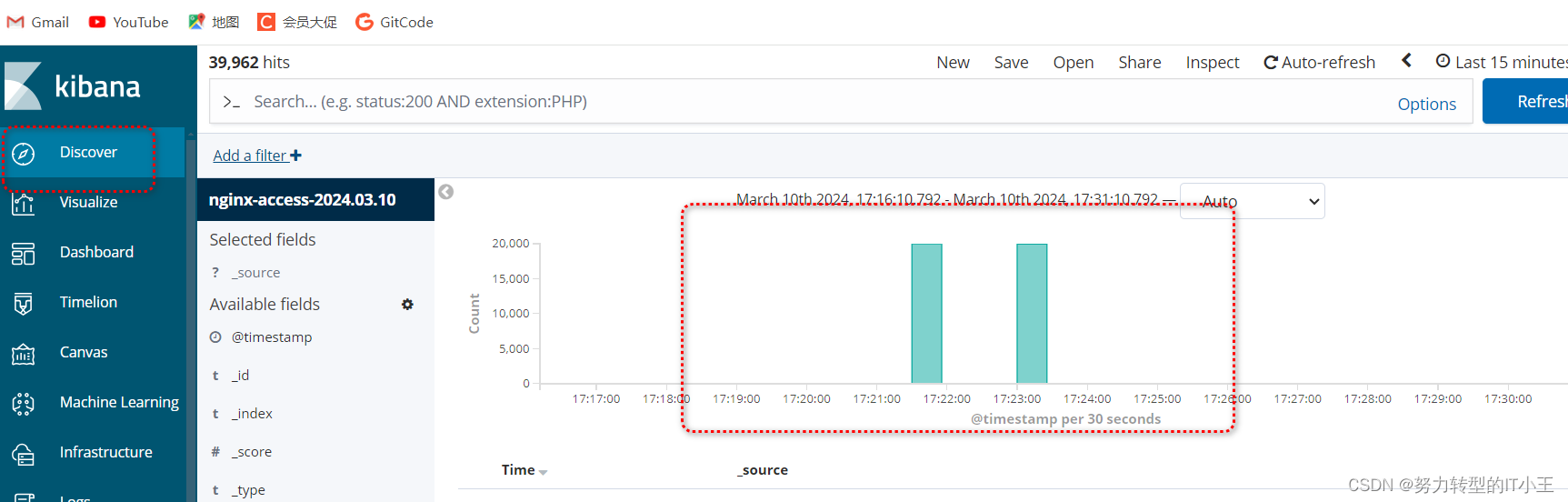
使用kibana图形化展示日志访问数据:
-
http://192.168.8.8:5601/
-
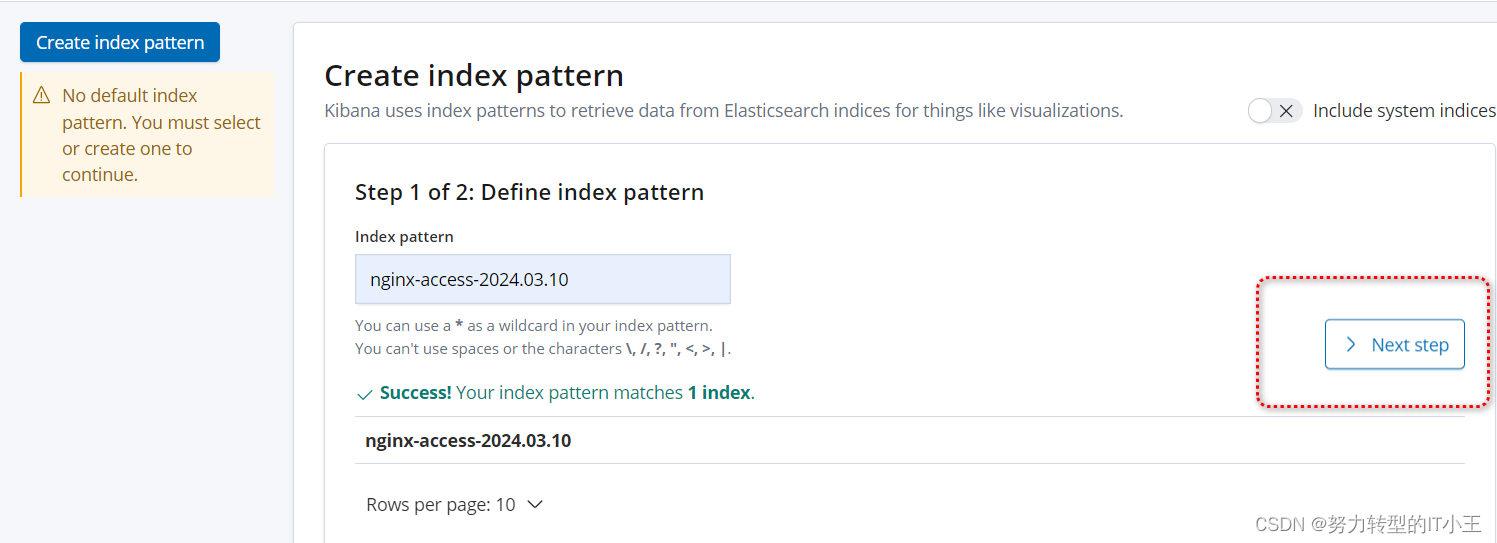
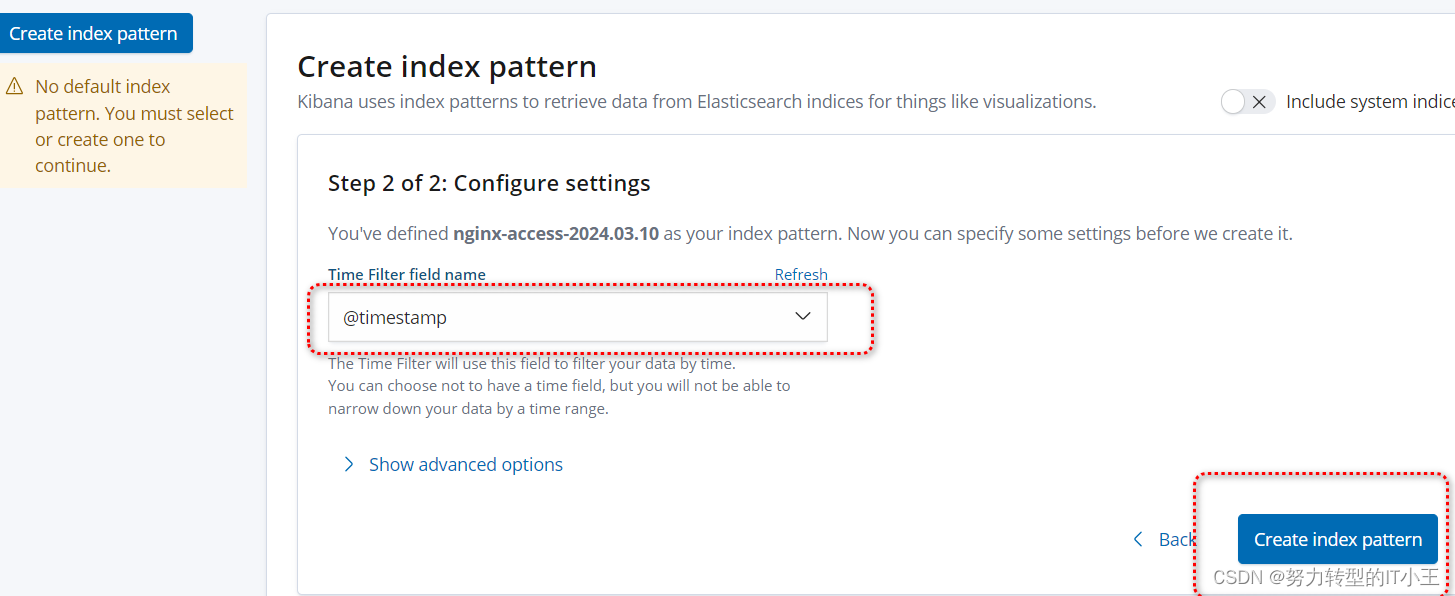
创建索引,图形化展示:
-
-
按照此步骤 将error错误索引页创建一下即可
-
-
虽然以上环境也可以进行日志收集,但只适用于中小型公司,以下再多增加一台服务器,安装redis实现消息队列,和logstash日志采集,增加吞吐量。
-
在8.10服务器上部署redis和logstash:
-
准备安装目录和数据目录:
-
mkdir -p /data/soft mkdir -p /opt/redis_cluster/redis_6379/{conf,logs,pid}
-
-
下载redis安装包:
-
cd /data/soft wget http://download.redis.io/releases/redis-5.0.7.tar.gz
-
-
将软件包解压到/opt/redis_cluster文件夹中:
-
tar xf redis-5.0.7.tar.gz -C /opt/redis_cluster/ ln -s /opt/redis_cluster/redis-5.0.7 /opt/redis_cluster/redis
-
-
切换目录编译安装redis:
-
cd /opt/redis_cluster/redis make && make install
-
-
编写redis配置文件:
-
vim /opt/redis_cluster/redis_6379/conf/6379.conf
-
bind 127.0.0.1 192.168.8.10 port 6379 daemonize yes pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log databases 16 dbfilename redis.rdb dir /opt/redis_cluster/redis_6379
-
-
启动redis服务:redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
-
-
修改8.9的filebeat文件(将filebeat收集的日志转发给redis):
-
vim /etc/filebeat/filebeat.yml
-
filebeat.inputs: - type: logenabled: truepaths:- /var/log/nginx/access.logjson.keys_under_root: truejson.overwrite_keys: truetags: ["access"]- type: logenabled: truepaths:- /var/log/nginx/error.logtags: ["error"]setup.template.settings:index.number_of_shards: 3setup.kibana:output.redis:hosts: ["192.168.8.10"]key: "filebeat"db: 0timeout: 5
-
- 重启服务:systemctl restart filebeat
- 再次在8.8上使用压力测试工具访问网站:ab -c 1000 -n 20000 http://192.168.8.9/
- 登录redis数据库:redis-cli
- 查看是否有以filebeat命名的键:
- filebeat与redis关联成功!
- 查看是否有以filebeat命名的键:
-
-
- 继续在8.10服务器上部署logstash:
- rpm -ivh logstash-6.6.0.rpm
- 修改logstash配置文件,实现access和error日志分离
- vim /etc/logstash/conf.d/redis.conf
-
input {redis {host => "192.168.8.10"port => "6379"db => "0"key => "filebeat"data_type => "list"} }filter {mutate {convert => ["upstream_time","float"]convert => ["request_time","float"]} }output {stdout {}if "access" in [tags] {elasticsearch {hosts => ["http://192.168.8.8:9200"]index => "nginx_access-%{+YYYY.MM.dd}"manage_template => false}}if "error" in [tags] {elasticsearch {hosts => ["http://192.168.8.8:9200"]index => "nginx_error-%{+YYYY.MM.dd}"manage_template => false}} }
-
- 最后重启logstash:
-
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis.conf
-
-
过程需等待,启动较慢(大约2-3分钟)
- vim /etc/logstash/conf.d/redis.conf
-
最后通过kibana图形化界面,可以看到nginx的access日志和error错误日志即可,最终效果和仅部署elk效果一致,只不过添加了redis数据库和filebeat日志收集工具,有了redis可以实现了消息队列为es服务器减轻了压力。
-




相关文章:

ELFK 分布式日志收集系统
ELFK的组成: Elasticsearch: 它是一个分布式的搜索和分析引擎,它可以用来存储和索引大量的日志数据,并提供强大的搜索和分析功能。 (java语言开发,)logstash: 是一个用于日志收集,处理和传输的…...

excel批量数据导入时用poi将数据转化成指定实体工具类
1.实现目标 excel进行批量数据导入时,将批量数据转化成指定的实体集合用于数据操作,实现思路:使用注解将属性与表格中的标题进行同名绑定来赋值。 2.代码实现 2.1 目录截图如下 2.2 代码实现 package poi.constants;/*** description: 用…...
【软件工程导论】——软工学绪论及传统软件工程(学习笔记)
📖 前言:随着软件产业的发展,计算机应用逐步渗透到社会生活的各个角落,使各行各业都发生了很大的变化。这同时也促使人们对软件的品种、数量、功能和质量等提出了越来越高的要求。然而,软件的规模越大、越复杂…...
C语言编译成库文件的要求
keil编译成库文件 在Keil中,将C语言源文件编译成库文件通常需要进行以下步骤: 创建一个新的Keil项目,并将所需的C语言源文件添加到该项目中。 在项目设置中配置编译选项,确保生成的目标文件符合库文件的标准格式。 编译项目&…...

Python的模块应用和文件I/O
Python 解释 Python是一种高级编程语言,以其简洁、易读和易用而闻名。它是一种通用的、解释型的编程语言,适用于广泛的应用领域,包括软件开发、数据分析、人工智能等。python是一种解释型,面向对象、动态数据类型的高级程序设计…...

设计模式之依赖倒转原则
目录 1、 基本介绍 2、 应用实例 3、 依赖关系传递的三种方式 (1) 接口传递 (2) 构造方法传递 (3) setter方式传递 4、 注意事项和细节 1、 基本介绍 依赖倒转原则(Dependence Inversion Principle)是指: 高层模块不应该依赖低层模块,二者都应该依…...

Springboot启动后想要做某些事可以通过什么方法实现?
在Spring Boot应用中,如果你想在应用启动完成后执行一些特定的操作(例如缓存预热),可以实现CommandLineRunner或ApplicationRunner接口。这两个接口都提供了一个run方法,在Spring Boot应用上下文初始化完成后会被自动调…...

网络原理初识(2)
目录 一、协议分层 1、分层的作用 2、OSI七层模型 3、TCP / IP五层(或四层)模型 4、网络设备所在分层 5、网络分层对应 二、封装和分用 发送过程(封装) 1、应用层(应用程序) QQ 2、传输层 3、网络层 4、数据链路层 5、物理…...

【C++】每日一题 92 反转链表
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 class ListNode { public:int val;ListNode* next;ListNode(int _val) {val _val;next nullptr;} };…...

算法D39 | 动态规划2 | 62.不同路径 63. 不同路径 II
今天开始逐渐有 dp的感觉了,题目不多,就两个 不同路径,可以好好研究一下 62.不同路径 本题大家掌握动态规划的方法就可以。 数论方法 有点非主流,很难想到。 代码随想录 视频讲解:动态规划中如何初始化很重要&#x…...

面试官:如何在 Spring Boot 启动的时候提前运行一些特定的代码
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:如何在 Spring Boot 启动的时候提前运行一些特定的代码 在Spring Boot启动的时候提前运行一些特定的代码可以通过实现ApplicationRunner接口、Com…...
力扣最热100题——56.合并区间
吾日三省吾身 还记得梦想吗 正在努力实现它吗 可以坚持下去吗 目录 吾日三省吾身 力扣题号:56. 合并区间 - 力扣(LeetCode) 题目描述 Java解法一:排序然后原地操作 具体代码如下 Java解法二:new一个list…...

docker学习(十四)docker搭建私服
docker私服搭建,配置域名访问,设置访问密码 启动registry docker run -d \-p 5000:5000 \-v /opt/data/registry:/var/lib/registry \registrydocker pull hello-world docker tag hello-world 127.0.0.1:5000/hello-world docker push 127.0.0.1:5000…...

基于BERTopic模型的英文20新闻数据集主题聚类及可视化
文章目录 bertopic介绍20 newsgroups dataset20 newsgroups数据集下载数据导入nltk数据处理bertopic模型构建模型训练运行模型可视化目前主题的一致性得分语料库建模bertopic介绍 BERTopic 是基于深度学习的一种主题建模方法。BERT 是一种用于 NLP 的预训练策略,它成功地利用…...

【Oracle之DataGuard的初步学习】
** 以下所有均是基于11G版本的 ** 一、DataGuard的部署方式 DG的部署最常用的方式就是直接在备库端部署一个空库然后再设置参数,但是这样做在初始同步时如果数据量过大会耗费较长的时间;相对来说这中方式比较简单不易出错。 还有一种方式就是通过rman的备…...
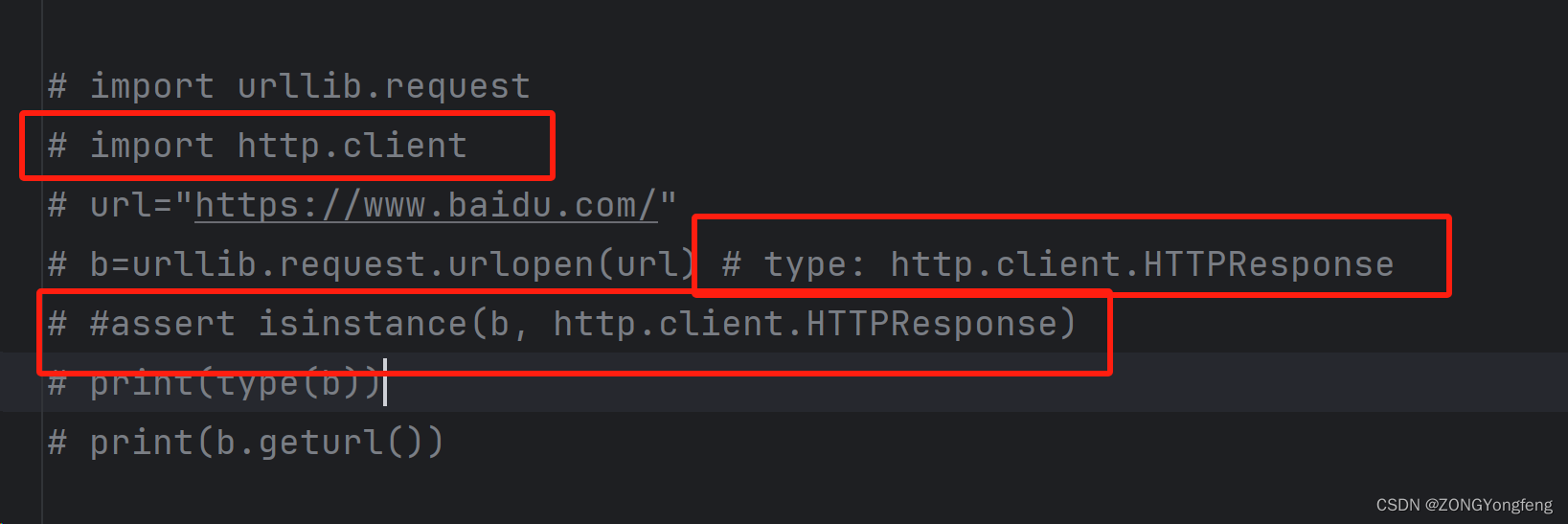
PyCharm无代码提示解决
PyCharm无代码提示解决方法 在使用PyCharm工具时,调用方法却无法进行提示,针对PyCharm无代码提示整理下解决方案 1、Python内置语法无智能提示 复现:我这里以urllib库读取网页内容为例,在通过urlopen()之后调用getur…...
记一次 .NET某设备监控自动化系统 CPU爆高分析
一:背景 1. 讲故事 先说一下题外话,一个监控别人系统运行状态的程序,结果自己出问题了,有时候想一想还是挺讽刺的,哈哈,开个玩笑,我们回到正题,前些天有位朋友找到我,说…...

大数据与云计算
目录 一、大数据时代二、云计算——大数据的计算三、云计算发展现状四、云计算实现机制五、云计算压倒性的成本优势 一、大数据时代 我们先来看看百度关于 “大数据”(Big Data)的搜索指数。 可以看出,“大数据” 这个词是从2012年才引起关注…...

一. 并行处理与GPU体系架构-并行处理简介
目录 前言0. 简述1. 串行处理与并行处理的区别2. 并行执行3. 容易混淆的几个概念4. 常见的并行处理总结参考 前言 自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考 本次课程我们来学习下课程第一章——并行处…...

vb机试考试成绩分析与统计,设计与实现(高数概率统计)-141-(代码+程序说明)
转载地址http://www.3q2008.com/soft/search.asp?keyword141 前言: 为何口出狂言,作任何VB和ASP的系统, 这个就是很好的一个证明 :) 又有些狂了... 数据库操作谁都会,接触的多了也没什么难的,VB编程难在哪?算法上,这个是一个算法题的毕业设计,里面涉及到对试卷的 平均分,最…...

像素时装锻造坊实战:VMware环境配置与Anything-v5模型快速上手指南
像素时装锻造坊实战:VMware环境配置与Anything-v5模型快速上手指南 1. 为什么选择VMware部署像素时装锻造坊 当你第一次看到像素时装锻造坊的界面时,可能会被它独特的日系RPG风格吸引。这款基于Stable Diffusion和Anything-v5模型的图像生成工具&#…...

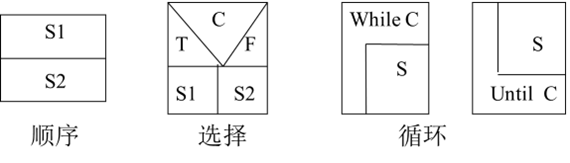
过程表示法:如何用步骤与操作表示知识
在知识表示中,有一类知识并不主要回答“对象是什么”或“对象之间有什么关系”,而是回答“事情应该怎样一步步完成”。例如,如何求解一个问题、如何执行一项操作、如何完成一个任务流程。这类知识强调步骤、顺序、控制和执行方式,…...
)
2026奇点智能技术大会核心议程泄露(仅限前500名技术负责人获取的微调参数黄金组合)
第一章:2026奇点智能技术大会:大模型个性化微调 2026奇点智能技术大会(https://ml-summit.org) 微调范式的根本性演进 在2026奇点智能技术大会上,主流大模型微调已从全参数微调全面转向高效参数微调(PEFT)与上下文感…...

WLAN部署实战:从AP上线到CAPWAP隧道建立的完整解析
1. WLAN组网基础:为什么需要AP与AC协作? 想象一下你走进一家咖啡馆,手机自动连上了WiFi。这个看似简单的动作背后,其实是一套复杂的无线局域网(WLAN)系统在运作。现代企业级WLAN通常采用AC(无线…...

从ISO 17987协议到代码:一文搞懂LIN唤醒信号的CANoe自动化测试怎么写
从ISO 17987协议到代码:LIN唤醒信号的CANoe自动化测试实战指南 在汽车电子系统开发中,LIN总线作为CAN总线的补充,广泛应用于车门模块、座椅控制、空调系统等对实时性要求不高的场景。网络管理是LIN总线开发中的关键环节,其中唤醒机…...

Qwen3-4B-Instruct-2507保姆级教程:tokenizer模板严格对齐官方
Qwen3-4B-Instruct-2507保姆级教程:tokenizer模板严格对齐官方 想快速体验一个响应快、对话流畅、还能写代码的纯文本AI助手吗?今天要介绍的这个项目,就是基于阿里通义千问最新发布的Qwen3-4B-Instruct-2507模型打造的。它去掉了所有跟图像处…...

如何快速掌握猫抓浏览器扩展:专业用户的终极资源嗅探方案
如何快速掌握猫抓浏览器扩展:专业用户的终极资源嗅探方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页视频无法下载而烦恼…...

Ubuntu启动失败:No bootable devices found的排查与修复指南
1. 问题现象与初步判断 当你按下电源键期待Ubuntu系统正常启动时,屏幕上突然跳出"No bootable devices found"的提示,这种场景就像你拿着钥匙却打不开自家房门一样令人焦虑。这个错误通常意味着计算机的固件(BIOS/UEFI)…...

网盘直链下载助手:告别限速困扰的完整解决方案
网盘直链下载助手:告别限速困扰的完整解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...

零基础极速上手:用AI建站工具10分钟生成你的第一个网站
痛点与目标看着别人轻松拥有自己的品牌官网,你是不是也心动了,却因为不懂代码、不会设计、预算有限而迟迟没动手?别担心,搭建专业网站的门槛已经被新一代的AI生成网站工具彻底打破了。即使你完全不懂技术,也能在10分钟…...