一. 并行处理与GPU体系架构-并行处理简介
目录
- 前言
- 0. 简述
- 1. 串行处理与并行处理的区别
- 2. 并行执行
- 3. 容易混淆的几个概念
- 4. 常见的并行处理
- 总结
- 参考
前言
自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第一章——并行处理与GPU体系架构,一起来理解并行处理相关概念
课程大纲可以看下面的思维导图

0. 简述
本小节目标:理解并行处理的基本概念,理解 SIMD,以及编程中常见的并行处理方式
这节课我们来学习第一章的第 1 小节,理解并行处理,第一章节内容偏基础但相关知识在后面很多章节中都会涉及到。那我们为什么要讲并行处理和 GPU 体系架构呢?这是因为大家在用 tensorRT 做模型部署的时候其实不光是使用它的 API 把模型转换成推理引擎放到 GPU 上跑就行了,这个是远远不够的
我们还需要考虑很多其它的东西,比如说你的模型的推理引擎有没有充分的利用 GPU 资源,有没有把 CUDA Core、Tensor Core 都利用起来,模型的计算密度是多少,模型的可并行性是多少,有没有充分利用 GPU 资源去做并行化等等,那这些其实就是我们在做模型部署的时候需要考虑的,所以作为一个基础内容,我们会给大家展开去讲第一章节
第一章节的内容可能很多人在大学听到过一些类似的知识,那大家作为复习听一下就好了。第一章节我们分为三个部分讲解,第一部分是并行处理的简介,第二部分是 GPU 并行处理,第三部分是 GPU 体系架构
我们先来看第一部分,并行处理的简介,希望大家在学完这部分后能够去理解并行处理的一些基本概念,比如说理解什么叫 SIMD,还有在 C++ 编程中常用的并行处理方式都有哪些
1. 串行处理与并行处理的区别
OK,我们在讲并行处理之前,我们需要去想它和串行处理的区别是什么,串行处理(Sequential processing)其实就是指令或者代码块必须是依次执行的,也就是说你前面一条指令需要执行结束之后才能够执行下面一条语句
我们来看两个例子
a = b + c; // BB1
d = b + a; // BB2
我们先看第一个例子,这是两个赋值语句,第一句我们叫 BB1(Basic Block 1),第二个语句是 BB2(Basic Block 2)我们可以看到 BB2 语句中的 a 需要利用前面 BB1 语句的结果 a,这就是一个很典型的 data dependency 数据依赖的程序,像这种程序,我们必须依次执行 BB1 和 BB2,如果颠倒的话这个程序的结果就不一样了,这种情况下我们就必须要串行处理
if(a == b){ // COND3c = d; // BB4
}else{c = e; // BB5
}
我们再看第二个例子,这是一个很简单的分支程序,我们把它分成三个部分,第一个部分是 COND3 也就是条件语句,如果 a==b 条件成立则执行 BB4,如果不成立则执行 BB5,这个其实也是必须要串行执行的,为什么呢,因为我们编译器在执行的时候,我们不知道选择执行哪个语句,我们得需要知道 COND3 的结果才能够去执行 BB4 或者 BB5,所以这个也是有依赖的
所以总结来说就是当我们程序如果有一些依赖或者分支的地方,这些情况下必须让其进行串行,这里稍微给大家扩展一下,大家可能听过数据依赖其实有很多种类,我们第一个例子是 flow dependency,此外还有 Anti dependency、Output dependency、Control Dependency,大家感兴趣的可以自行查阅相关资料,这个在编译器做优化的时候其实还是很重要的东西
所以说我们串行程序它其实就是依次执行的一个程序,它的使用场景也是比较擅长去处理一些比较复杂的逻辑计算,比如大家在打开一个操作系统(Windows、Linux、Mac)的时候,它内部是有很多复杂的逻辑运算的,很多地方是需要串行执行
我们这里拿一个程序给大家去讲解一下,我们把这个程序给稍微抽象化,它有 5 个语句,statement1 到 statement5,如下图所示:

我们的 statement 语句它有可能是复制语句,也有可能是条件语句,也有可能是循环,还有可能是一个 I/O。我们给这个程序设置几个条件:
- statement2 依赖于 statement1
- statement5 依赖于 statement4
- statement3 是一个循环,跟所有的 statement 没有任何关系
- 有四个 core 可以使用
- 时钟周期
- statement1 和 statement2 需要 5 个时钟周期
- statement4 和 statement5 需要 8 个时钟周期
- statement3 需要 20 个时钟周期
那如果我们程序是按照上图串行执行,它的时钟周期就是 46 个 cycle,这个实在太慢了。我们既然有四个 core,那我们可以去想想充分利用这些 core 去把程序并行化
因此我们第一个策略如下图所示:

前面我们提到 2 和 1 是有依赖的,5 和 4 是有依赖的,3 是独立的,那这三个部分是不是可以分别分配到不同的 core 去执行呢,把 1 和 2 分配到一个 core,把 4 跟 5 分配到一个 core,把 3 分配到一个 core,这三个部分同时去执行,这样做其实对程序的运行结果没有任何影响,而它的时钟周期却只用了 20 个 cycle
我们继续优化,20 个 cycle 还是有点长,上面 20 个 cycle 中具有支配性的语句是 statement3,它是一个 for 循环,我们是不是有一些其它的策略可以给它做优化呢

我们说 statement3 这个循环可以分割成很多个子代码也就是子循环,每一个子代码块只要 5 个 cycle 就能执行完,那 statement3 就可以按照上图的分配方式,分配四个子代码块分别是 3-1、3-2、3-3、3-4,而刚好我们之前只用了三个 core,还有一个没用,我们现在就可以把空余的 core 给利用起来,把 3-3 和 3-4 放到另外一个 core 上让它去执行,那此时的执行时间就从 20 个 cycle 减少到了 16 个 cycle
那我们接着看还能不能优化呢,现在具有支配性的语句是 statement4 和 statement5,我们来看看这个能不能去优化。我们再给定一个假设条件,就是说 statement5 可以在 statement4 彻底结束之前就知道它所依赖的结果,也就是说 statement4 执行到中间环节的时候就已经把 statement5 所依赖的数据写回到寄存器或者写回到内存中,后面做的事情就跟 statement5 没有任何关系的,那也就意味着我们可以把 statement5 的执行时间往前调一点,如下图所示:

这样的话,我们 16 个 cycle 的时钟周期又能减少到 14 个
OK,我们来回顾一下,这个程序串行执行的时间一共是 46 个 cycle,我们进行了很多优化最终变成了 14 个 cycle,大概优化速度提升 3.5 倍左右,我们目前为止做的优化如下:
- 把没有数据依赖的代码分配到各个 core 各自执行(schedule,调度)
- 把一个大的 loop 循环给分割成多个小代码,分配到各个 core 执行(loop optimization)
- 在一个指令彻底执行完之前,如果已经得到了想要的数据,可以提前执行下一个指令(pipeline,流水线)
以上三个步骤其实只是并行处理中一个很简单的做法,真正做并行处理的时候其实要做的优化还有很多,我们管这一系列行为叫做 parallelization 并行化,我们管这个可以利用多核,多线程资源的程序叫做 parallelized program 并行程序
2. 并行执行
我们再回归正题,这个 parallel processing 并行执行又是指什么呢,它主要有以下几个特点:
- 指令/代码块同时执行
- 充分利用 multi-core 多核的特性,多个 core 一起去完成一个或多个任务
- 使用场景:科学计算,图像处理,深度学习等等
并行执行中多个 core 会一起去完成一个或多个任务,也就是说假设现在我们的 device 设备上有四个 core,我们可以让这四个 core 一起去执行一个 for 循环,我们把一个 for 循环分割成多个子块,让每一个 core 去完成一个部分,这个是完全 OK 的。或者我们程序很大时,我们可以让每一个 core 去分别完成这个程序的各个小任务,最终把每一个 core 的任务完成后我们再做一个同步处理,那这个也是可以的。
串行执行是针对于复杂逻辑运算的,而并行执行它非常擅长一些大规模的科学计算,比如天体预测,还有图像处理,深度学习这些东西其实也是有很多并行处理的概念在里面

上图是一个 Multi-core processor 多核处理器的架构,我们简单讲下,这个是偏计算机硬件的东西,从图中可以看到我们首先有一个 main memory 主存,主存上面有一个 L3 缓存,之后还有很多寄存器,那寄存器上面有很多 core,这些都是硬件层面的东西。在硬件之上我们会有一个自己的操作系统,然后在操作系统上有很多程序,也就是图中的 app 1、app 2 这些东西
说到并行处理,其实我们在做程序并行化的时候大部分时间处理的主要还是 loop 循环,这是因为我们发现执行时间长的程序耗时主要集中在两个方面,一个是 I/O 的内存读写,另一个就是 loop 的循环
I/O 的内存读写我们先抛开不谈,因为这里可扩展性的东西太多了,我们主要讲针对 loop 的并行处理,那 loop 的并行其实是一个很重要,也是很热门的一个课题,到目前为止已经有很多学者做了一些优化,也发表了很多论文,在图像处理还有深度学习中其实很多地方都用到了循环,比如我们在做分类任务时,我们把图片放到深度学习模型之前需要对这个图像进行预处理,包括 resize 到模型能接受的范围比如 256x256,包括通道切换比如 bgr2rgb,包括归一化比如 /255.0 等等,那这些都是需要用到循环的。还有我们在深度学习模型内部的一些卷积层或者全连接层,这里面其实也是要涉及到并行处理的

那这里我们以一个比较经典的 loop parallelization 为例给大家去讲解一下 CPU 里面是怎么对 loop 进行优化的,我们这里拿一个 4x4 的二维矩阵来进行一个讲解,默认来说它的一个遍历方式是 row major 行为主,它是先把一行的数据全遍历完之后再去遍历下一行
值得注意的是不同的编程语言它的遍历方式是不一样的,或者准确来说它的数据,二维数组在内存里面的存储方式是不一样的,比如大家经常使用的 C、C++、C# 这些语言的二维数组是以 row major 的方式进行存储的,所以我们也推荐在遍历的时候以 row major 进行遍历,但是有一些语言比如说 MatLab、R 这些语言的二维数组在内存中的存储方式其实是 column major 的

所以说针对不同语言,如果它默认存储方式是不同的话,那么也就意味着我们在进行优化的时候它对于 Reordering 的方式也是不同的,比如说对于 MatLab 语言,它存储方式默认是 column 的,但是你的编程代码里面如果遍历方式是 row major 的话,那我们可以把它修改成一个 column major 的遍历方式去完美的匹配它的一个存储方式,从而减少你的 cache miss
这个怎么理解呢,就是我们在 CPU 进行程序优化的时候,其实我们需要考虑如何尽量去减少你的一个 cache miss,比如存储数据的时候你需要考虑它的一些空间连续性或者时间连续性,比如一个元素访问到之后,它旁边的元素其实也很容易很大几率被访存,所以你把这一列的数据全都放一起访存的话,一起去放到 memory 里面去访存的话,其实它是可以减少你的 cache miss,当然再强调一遍,不同语言它的 reordering 的方式是不同的

第二个是 Vectorization 标量化,我们之前矩阵元素的遍历是一个个去遍历的,但是只要我们的指令集支持或者我们的寄存器支持的话,我们其实是可以让它四个元素一起去访问的,甚至说 16 个元素,32 个元素一起去访问,这个也是完全 OK 的,只要我们硬件支持,相比于我们原本一个个元素去访问而言,速度提升了很多

那下一个 Tiling,这个技术也是很重要的,如果说我们有一个 4x4 的数组,我们把它分割成四个 2x2 的数组的话,我们是不是可以每一个元素,每一个小部分都进行遍历呢,也就是每个部分独立的遍历或者独立的计算,这个是完全 OK 的。那如果说我们可以分割成四个小部分,那也就是意味着我们四个小部分它们的计算遍历等等其实是完全可以并行化的
这里我们给大家举了几个例子其实只是 loop parallelization 中很小的一部分,但是也是现在很常用的一些方式,比如这里的 Vectorization、Tiling 这些技术其实不光光在 CPU 里面会使用,其实在 GPU 的一些设计模式里面也完美的体现出来了这几个 loop 的优化,我们后面再给大家详细去讲,现在大家理解一下就好了

(双线性插值)
那在涉及到一些 DNN 或者图像处理的时候,也有一些比较常见的并行处理的例子,比如说双线性插值,我们在 resize 的时候会用到,用周围四个点的坐标值去计算中间点 P 值时也是可以做并行化的,因为一张图像有多个像素值,resize 时很多像素值都需要像这样进行计算插值,那这些执行其实是完全可以并行化的,因为我们在做某一部分的插值计算时并不会说依赖于它相邻的那一块区域的计算,它是完全可以去并行处理的

(卷积层)
那同样的卷积也是一样的,针对 5x5 的一个 input tensort 而言,用一个 3x3 的 kernel 进行卷积,那这个卷积的过程也是可以并行化的,通过滑动窗口我们一共需要滑动 9 次,做 9 次计算,但是这 9 次的计算中我们并没有说哪一个部分一定是依赖于另外一个部分的,所以说我们这 9 个部分它其实是完全可以并行化执行的

(全连接层)
同样的全连接层也是一样的,可以看到 input tensor 有 9 个元素,你的输出的 tensor 它一共有 A、B、C、D 四个元素,我们在做计算 A 的这个过程,它其实跟计算 B 的过程是没有任何依赖性的,那就是说计算 A、计算 B、计算 C、计算 D,它们这四个计算过程也是可以完全并行化的
3. 容易混淆的几个概念
我们讲了这么多并行处理,我们先稍微停一下,我们去讲一下大家在学习的过程中容易混淆的几个概念,首先第一个就是并行和并发,这两个词还是很像的,但在英语中这两个单词是完全不一样的,一个是 parallel 并行(物理意义上同时执行),一个是 concurrent 并发(逻辑意义上同时执行)
我们先说并发,并发是什么呢,并发它是逻辑意义上的同时执行,那什么叫逻辑意义呢,我们来看下面的例子:

现在我们只有一个 CPU,我们要让它去执行两个 task,我们先让它执行 task1,当 task1 执行到一半的时候我们切换到 task2,把 task2 做完一半后我们继续回到之前做 task1,之后我们再做 task2,这样一个 CPU 来切换的去做两个 task,但是实际上这个切换 task1 和 task2 的速度是非常非常快的,我们肉眼是无法识别的,所以我们能够感觉到这个 CPU 它是在同时做两个任务,那这个就是并发,逻辑意义上的同时执行

那我们再说并行,并行它就是物理意义上的同时执行,也就是说现在我们手上的 CPU 很多,我们有两个 CPU,我们让这两个 CPU 分别处理 task1 和 task2,并且让这两个 CPU 同时去执行,这个就是物理意义上的同时执行,这个就是 parallel
我们这个课程主要还是以并行处理为主,并发其实在做编译器的时候,大家可能会用到这个概念,但是做 GPU、CUDA 的话还是用并行处理
那么还有一个容易混淆的概念就是进程和线程,线程它是进程的一个子集,一个进程它可以有很多个线程,我们以一个例子来讲解,我们打开操作系统之后,我们去打开一个小程序,那其实在打开小程序的过程中操作系统为这个程序已经分配了一个进程,但是这个小程序它其实运行的速度可能会很慢,那么我们就可以把这个小程序的这个进程再给它分配很多个小的线程,去分别完成这个程序中的各个部分,这个是并行处理的一个解决方案,也就是进程和线程的关系
那另外一个就是多核和加速比的关系,这个也是大家容易混淆的一个概念,双核它的加速不一定就是两倍,比如我们只有一个核去处理一个程序,那么这个程序它的执行时间是 2ms,那么如果说我们现在有两个核去同时处理这个程序,那是不是这个程序的时间就会由 2ms 变成 1ms 呢,其实并不是的,我们这里以 Amdahl’s Law 来进行讲解

这是一个非常经典的图,也是在做并行处理中经常会遇到的一个图,横轴是处理器的个数,纵轴是加速比,我们可以看到,核个数和加速比并不是成线性增长的,它到了一定程度之后,它这个加速比其实就饱和了,就不会再继续增长了。也就是说我们在做并行处理的时候,其实我们有很多限制因素在里面

比如说我们回到之前的例子,我们看这里面 statement3 这个 for 循环我们可以分割,这个是完全 OK 的,但是 1 和 2,4 和 5 它们之间存在依赖关系,那如果有依赖关系的话,我们再怎么做并行,我们也不能够让 4 和 5 一起去执行,也不能让 1 和 2 并行执行,其实这个就是一个强制性的约束力,就是程序再怎么并行还是有个上限的
同时我们从图中还能看到 8 核的加速比有的时候也会差于 4 核,也就是说我们有的时候核越多其实并不是效率会越高,为什么呢,因为我们在做加速的时候,其实还是需要考虑它的数据传输,一些偏内存的读写,数据传输这个方面所消耗的时间也是需要去考虑的
4. 常见的并行处理
我们讲现在常用的并行处理方式都有哪些呢,刚才给大家稍微提了一下,并行处理自古以来都是一个非常非常热门的话题,有很多种方式,这里我们简单举几个例子:
- 编译器自动化并行优化
- GCC,LLVM,TVM,…
- 针对 for 循环的并行优化
- tile,fuse,split,vectorization,…
- 计算图优化
- CFG,HTG,MTG,…
- 数据流
- Dataflow compiler
- Dataflow architecture
- Polyhedral
- Polyhedral compiler
- HPC
- High performance computing
- …
首先编译器它就有很多自动化并行优化的一些方式,大家比较常见的 GCC、G++,它里面有很多自动并行优化的一些策略,还有做编译器的人可能经常听到的 LLVM,它们也有很多这种优化策略,还是大家做深度学习的编译器的时候,模型部署的时候,可能会经常听到 TVM 这个东西,它是针对深度学习模型 DNN 模型的一个编译器,这个里面也有很多自动化并行优化策略在里面
那我们还有很多针对 for 循环的并行优化,这个是一个很热门的话题,比如说 tile,fuse,split,vectorization 等等,到目前为止已经是很成熟的技术了,有很多地方都在用。
还有计算图优化,这个跟大家经常听到的 pytorch 或者是 tensorflow 里面的计算图是不一样的,我们可以把它理解为像是一个程序的流程图一样,就是 CFG、HTG、MTG 等等,这些都是 graph,我们针对这个程序的这个 graph 来进行优化,这个也是并行处理的一个方式
我们还有数据流,这个也是一个很老的概念了,我们有针对 Dataflow 的一个编译器,也有人在做 Dataflow 的硬件研发,这个还是挺常见的,现在很多 DNN 的模型,有很多硬件厂商会去把它制作成一个 Dataflow 的数据流的硬件,那大家感兴趣的可以查阅一下相关资料。
还有 Polyhedral,可以有针对 Polyhedral 这个编译器的开发,还有包括 HPC 超大规模计算的一些并行优化
总的来讲并行处理其实是一个很大的课题,很多人都在做,那我们这门课程的 TensorRT 我们可以把它理解为一个编译器,把一个模型输入到 TensorRT 里面给它做各种优化,优化成一个推理引擎,能够放到硬件上最优化你程序的执行时间
我们这门课程要讲 TensorRT,要讲 CUDA 编程的话,我们不得不提 SIMD 这个东西,因为太重要的,SIMD 全称 Single Instruction Multiple Data 也就是说我们同一条指令去执行多个数据,这个怎么理解,那我们先看一个简单的例子

我们现在要做一个乘法运算,A1 乘以 B1 赋值给 C1,同样我们还有 A2、B2、C2;A3、B3、C3;A4、B4、C4,那么我们这个过程其实在编译的时候,计算机需要处理的事情还挺多的,我们得需要先取指令,我们读取数据,还得做计算,再写回数据,这是针对一个,针对其它几个也是同样的操作,也就是这些同样的操作我们需要重复四次,那这是不是非常麻烦呢
OK,那针对这个我们其实有一个优化策略,如下图所示:

我们把 A1、A2、A3、A4 放在一起,B1、B2、B3、B4 也放在一起,C1、C2、C3、C4 也是一样的,那么这是不是也就意味着我们只需要读取一次数据,计算一次乘法,写回一次数据就行了,这个其实是可以的,我们管这种操作方式叫做 SIMD operation,它前面一个个取数据的操作方式我们叫 Scale operation,这个在编译器中也是比较常见的概念
在 CUDA 编程与 TensorRT 中以及 NVIDIA 在做 tensor core 的设计理念中都存在着 SIMD

我们从 NVIDIA 的官网中看 Tensor Core 的介绍,它很擅长去做 4x4 矩阵的乘加法运算,也就是图中的 D=AxB+C,如果我们依次去执行的话要执行 16 次,非常麻烦,Tensor Core 的设计理念就是允许多个数据放在一起去执行,快速计算 AxB+C,接下来的课程去针对 GPU 的体系架构我们会稍微扩展去讲一下,这个是很重要也是很核心的一个东西
值得注意的是准确来说在 CUDA 编程中它其实使用的并不是 SIMD 而是 SIMT(Single Instruction Multiple Thread),不再是多数据而是多线程,CUDA 编程中线程是一个很重要的概念,也就是说它会去充分利用它的多核资源去进行多线程化,用多线程化去把一个卷积操作,矩阵乘法操作这些东西进行优化处理,SIMT 和 SIMD 很像,它是 SIMD 的一个高级版,这个接下来我们也会再结合 CUDA 编程去讲
那最后我们去给大家稍微介绍一下比较常见的并行处理方式
CPU 上的并行处理
- OpenMP
- pthread
- MPI
- Halide
- 应用场景:图像预处理/后处理,Multi-task 模型
GPU 上的并行处理
- CUDA programming
- 应用场景:DNN 优化
我们这里主要针对模型部署的一些常见的并行处理方式,首先我们得先看我们并行处理的计算是要放到哪里去执行,我们是直接放在 GPU 上呢,还是放在 CPU 上,如果是 GPU 上的化,其实我们就用 CUDA 或者 TensorRT 是 OK 的,它的应用场景也是针对 DNN 进行的优化策略,那如果是放在 CPU 上的话,其实我们有很多种选项,我们可以选 OpenMP,可以使用 pthread、MPI、Halide 等等
那大家大学期间如果上过 C++ 并行处理课程的话,可能经常听到过 OpenMP,这个还是比较老的概念了,MPI 也是,其实它这些东西就是你在程序中如果声明了一个代码块,由 OpenMP 声明了代码块之后,那么你的这个程序就是这一部分可以进行并行化,它可以是指令级别的并行化,也可以是代码块的并行化,这个不是我们这门课程的重点就不展开讲了,感兴趣的可以查阅下相关资料
那么在 CPU 上的并行处理,它其实应用的场景主要是在图像的预处理和后处理上,就是说需要我们把数据放在 GPU 上之前,我们需要把这个图像给进行加工,让它加工成模型可以识别的一个格式,这个是在 CPU 上做的,其实现在有很多为了让预处理和后处理进行加速,也把它放在 GPU 上做,这个也是有的
还有就是做 Multi Task 的一个模型,也就是多任务模型,如果说我们的模型它既有分割又有检测,或者说我们有很多个分割,我们让它并行处理的话,其实也是可以用到这个 CPU 并行处理的概念,直接 OpenMP 或者 pthread 做并行处理,这个也是完全可以的

那我们这里再稍微扩展一下,就是我们刚才看到的图,multicore processor 在多核处理器,一般来说我们常见的就是同构架构,就是一个处理器里面它们有很多 core,它们的 core 其实都是一样的,我们有一个 CPU Core1、CPU Core2、CPU Core3、CPU Core4。但是我们在异构架构里面它不光是只有一个种类的核,如上图所示,我们可以有 CPU Core,也可以有 GPU Core,还可以有 DSP Core,也可以 Fast core,就是这些 core 是相互结合,相互联合起来去组成一个计算机硬件的
所以我们在做模型部署的时候,其实我们要想的东西很多,不光要去想这个东西是怎么能够在 GPU 上变快,我们还得去想它的 CPU 和 GPU 之间的通信是什么样子的,我们哪些地方可以放在 CPU 上去执行更快一点,我们哪些地方可以放在 DSP 上去执行,我们在做异步执行的时候怎么做等等,这些也是在异构架构中经常需要涉及到的理念
OK,以上就是第一部分的内容
总结
本次课程我们学习了并行处理的相关知识,首先我们讲解了串行处理和并行处理的区别,串行处理就是指令或代码必须依次执行,常用于一些比较复杂的逻辑运算;并行处理就是指令或代码块同时执行,常用于科学计算,图像处理等。之后我们讲解了 loop 循环优化的一些方案,比如 Vectorization、Tiling 等等,同时我们区分了几个容易混淆的概念,包括并行/并发、进程/线程等。最好我们简单介绍了一些常见的并行处理方式,重点是 SIMD 以及 CUDA 编程中非常重要的 SIMT。
OK,以上就是第 1 小节有关并行处理的全部内容了,下节我们来学习 GPU 并行处理的相关知识,敬请期待😄
参考
- Bilinear interpolation
- A guide to convolution arithmetic for deep learning
- Fully Connected Layer vs. Convolutional Layer: Explained
- Multicore Processing
相关文章:
一. 并行处理与GPU体系架构-并行处理简介
目录 前言0. 简述1. 串行处理与并行处理的区别2. 并行执行3. 容易混淆的几个概念4. 常见的并行处理总结参考 前言 自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考 本次课程我们来学习下课程第一章——并行处…...

vb机试考试成绩分析与统计,设计与实现(高数概率统计)-141-(代码+程序说明)
转载地址http://www.3q2008.com/soft/search.asp?keyword141 前言: 为何口出狂言,作任何VB和ASP的系统, 这个就是很好的一个证明 :) 又有些狂了... 数据库操作谁都会,接触的多了也没什么难的,VB编程难在哪?算法上,这个是一个算法题的毕业设计,里面涉及到对试卷的 平均分,最…...
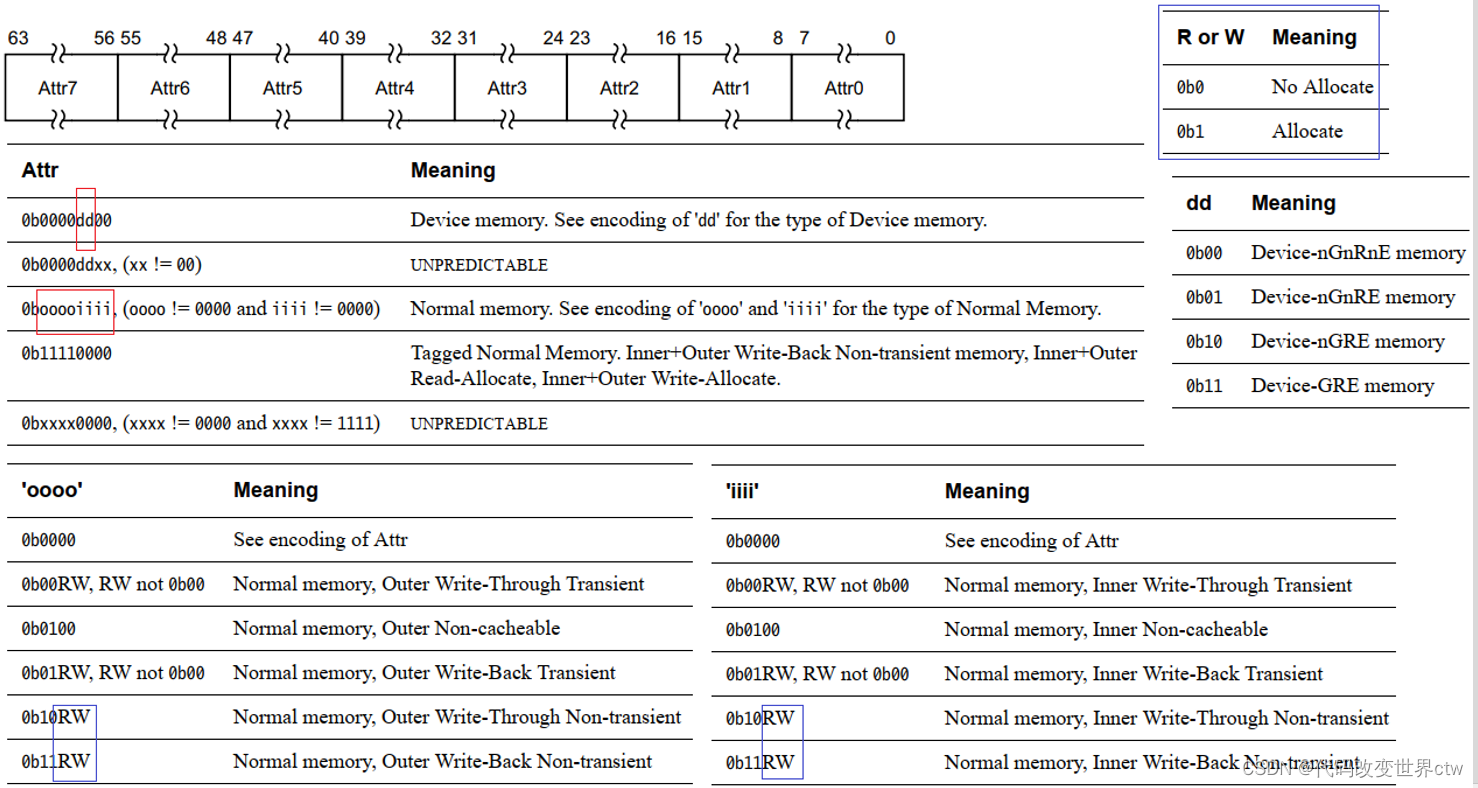
Arm MMU深度解读
文章目录 一、MMU概念介绍二、虚拟地址空间和物理地址空间2.1、(虚拟/物理)地址空间的范围2.2、物理地址空间有效位(范围) 三、Translation regimes四、地址翻译/几级页表?4.1、思考:页表到底有几级?4.2、以4KB granule为例,页表的…...

2024 年 AI 辅助研发趋势
在2024年,AI辅助研发的应用趋势将非常广泛。举个例子,比如在医疗健康领域,AI将深度参与新药研发、早期癌症研究以及辅助诊断等,助力医疗技术的突破。同时,在农业领域,AI也将通过无人机、智能装备等方式&…...

聊聊pytho中的函数
Python中的函数 一、Python中函数的作用与使用步骤 1、为什么需要函数 在Python实际开发中,我们使用函数的目的只有一个“让我们的代码可以被重复使用” 函数的作用有两个: ① 代码重用(代码重复使用) ② 模块化编程&#x…...

Python中starmap有什么用的?
目录 前言 starmap函数的作用 starmap函数的用法 starmap函数的示例 1. 对每个元组元素进行求和 2. 对每个元组元素进行乘积 实际应用场景 1. 批量处理函数参数 2. 并行处理任务 3. 批量更新数据库 总结 前言 在Python中, starmap 是一个非常有用的函数&…...
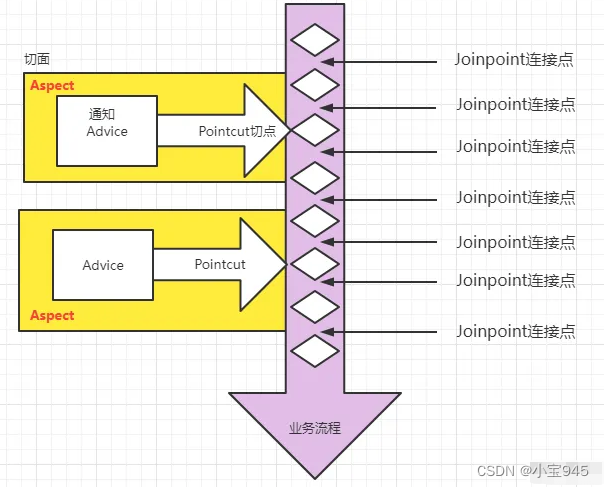
面向切面编程 AOP
提示:主要内容参考动力节点老杜的Spring6讲义。 面向切面编程 AOP 一、AOP介绍二、AOP的七大术语三、切点表达式 IoC使软件组件松耦合。AOP让你能够捕捉系统中经常使用的功能,把它转化成组件。AOP(Aspect Oriented Programming)&a…...

POS 之 奖励机制
为什么需要有奖惩机制 如果没有奖励,就不会有节点参与POS,运营节点有成本,而奖励正是让运营者获利的方式 如果没有惩罚,网络上会充斥着很多无效节点,会扰乱甚至破坏网络 所有奖励和惩罚在每个 Epoch 实施一次 奖励 什…...

Unity类银河恶魔城学习记录9-7 p88 Crystal instead of Clone源代码
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili Blackhole_Skill_Controller.cs using System.Collections; using System…...

导出RWKV模型为onnx
测试模型: https://huggingface.co/RWKV/rwkv-5-world-3b 导出前对modeling_rwkv5.py进行一个修改: # out out.reshape(B * T, H * S) out out.reshape(B * T, H * S, 1) # <<--- modified out F.group_norm(out, nu…...
)
【LeetCode】整数转罗马数字 C语言 | 此刻,已成艺术(bushi)
Problem: 12. 整数转罗马数字 文章目录 思路解题方法复杂度Code 思路 暴力破解 转换 解题方法 由思路可知 复杂度 时间复杂度: O ( n ) O(n) O(n) 空间复杂度: O ( 1 ) O(1) O(1) Code char* intToRoman(int num) {char *s (char*)malloc(sizeof(char)*4000), *p s;while(…...

移动App开发常见的三种模式:原生应用、H5移动应用、混合模式应用
引言 在移动应用市场的迅猛发展中,移动App开发正日益成为技术创新和用户体验提升的焦点。对于开发者而言,选择适合自己项目的开发模式成为至关重要的决策。本文将探究移动App开发的三种常见模式:原生应用、H5移动应用和混合模式应用。这三种…...

k8s Secret配置资源,ConfigMap 存储配置信资源管理详解
目录 一、Secret 概念 三种Secret类型 pod三种使用secret的方式 应用场景:凭据: 二、 示例 2.1、用kubectl create secret命令创建 Secret 创建Secret: 查看Secret列表: 描述Secret: 2.2、用 base64 编码&…...
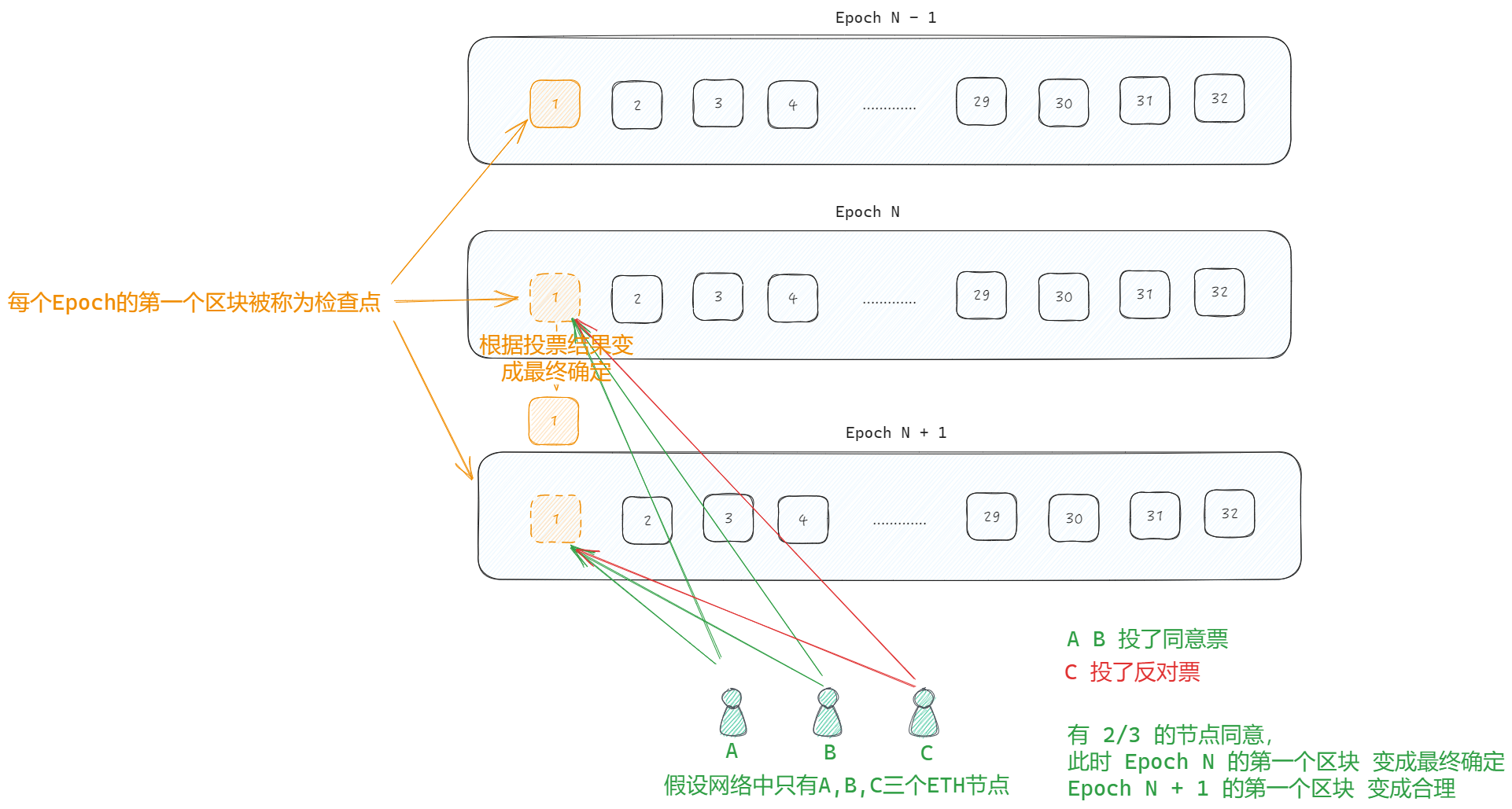
POS 之 最终确定性
Gasper Casper 是一种能将特定区块更新为 最终确定 状态的机制,使网络的新加入者确信他们正在同步规范链。当区块链出现多个分叉时,分叉选择算法使用累计投票来确保节点可以轻松选择正确的分叉。 最终确定性 最终确定性是某些区块的属性,意味…...
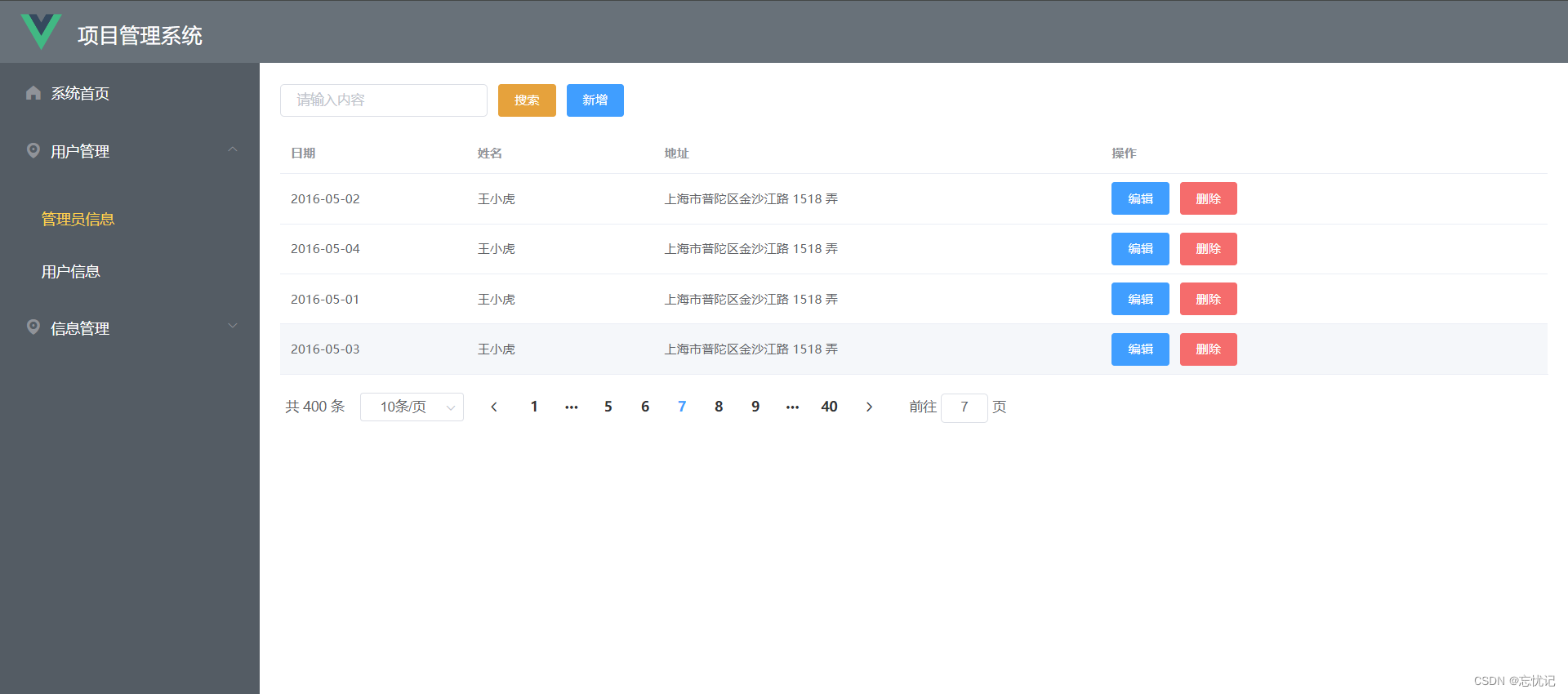
Vue快速开发一个主页
前言 这里讲述我们如何快速利用Vue脚手架快速搭建一个主页。 页面布局 el-container / el-header / el-aside / el-main:https://element.eleme.cn/#/zh-CN/component/container <el-container><el-header style"background-color: #4c535a"…...
)
Java SE入门及基础(33)
final 修饰符 1. 应用范围 final 修饰符应该使用在类、变量以及方法上 2. final 修饰类 Note that you can also declare an entire class final. A class that is declared final cannot be subclassed. This is particularly useful, for example, when creating an imm…...

ChatGPT逐步进入留学圈但并不能解决留学规划的问题
2022 年底,一个能像人类一样对话的AI软件ChatGPT,在5天内突破一百万用户,风靡全球,如今用户已达1.8亿。 四个月后,ChatGPT进化为GPT4版本。该版本逻辑、数学推理能力卓越。拿留美标准化考试举例,GPT4能够在…...

WebGL之灯光使用解析
在使用灯光之前,首先我们需要了解,与定义更广泛的 OpenGL 不同,WebGL 并没有继承 OpenGL 中灯光的支持。所以你只能由自己完全得控制灯光。幸运得是,这也并不是很难,本文接下来就会介绍完成灯光的基础。 在 3D 空间中…...
【Spring云原生系列】SpringBoot+Spring Cloud Stream:消息驱动架构(MDA)解析,实现异步处理与解耦合
🎉🎉欢迎光临,终于等到你啦🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟持续更新的专栏《Spring 狂野之旅:从入门到入魔》 &a…...

PostgreSQL索引篇 | TSearch2 全文搜索
PostgreSQL版本为8.4.1 (本文为《PostgreSQL数据库内核分析》一书的总结笔记,需要电子版的可私信我) 索引篇: PostgreSQL索引篇 | BTreePostgreSQL索引篇 | GiST索引PostgreSQL索引篇 | Hash索引PostgreSQL索引篇 | GIN索引 (倒排…...

5分钟搞定Docker+MySQL数据持久化:挂载本地目录与字符集配置全流程
DockerMySQL数据持久化实战:目录挂载与字符集配置终极指南 刚接触Docker的开发者经常会遇到这样的困扰:MySQL容器重启后数据全部丢失,或者存储的emoji表情变成了一堆问号。这些问题看似简单,却直接影响着开发效率和数据安全。本文…...

【车辆】simulink自动驾驶赛车基于快速探索随机树的路径规划【含Matlab源码 15318期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

5分钟解决NVIDIA显卡色彩过饱和:novideo_srgb显示器色彩校准终极指南
5分钟解决NVIDIA显卡色彩过饱和:novideo_srgb显示器色彩校准终极指南 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirrors/no/novid…...

如何快速掌握OCAuxiliaryTools:黑苹果配置的终极图形化指南
如何快速掌握OCAuxiliaryTools:黑苹果配置的终极图形化指南 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 你是否在为黑…...

C# 解析 PowerPoint 文件:从基础读取到高级内容提取实战
1. 为什么需要解析PowerPoint文件? 在日常工作中,我们经常会遇到需要批量处理PowerPoint文件的需求。比如市场部门需要从上百份产品演示PPT中提取关键卖点,培训部门要整理历年课件中的知识点,或者数据分析师需要收集各部门汇报中的…...

Nano-Banana实战教程:生成可直接嵌入技术文档的矢量化风格图
Nano-Banana实战教程:生成可直接嵌入技术文档的矢量化风格图 你是不是也遇到过这样的烦恼?写技术文档、产品说明书或者设计提案时,想配一张清晰、专业的产品结构图,结果要么是手绘的草图不够看,要么是找的素材风格不搭…...

AI Agent 跑完任务怎么通知你?我写了个微信推送服务渍
1、普通的insert into 如果(主键/唯一建)存在,则会报错 新需求:就算冲突也不报错,用其他处理逻辑 回到顶部 2、基本语法(INSERT INTO ... ON CONFLICT (...) DO (UPDATE SET ...)/(NOTHING)) 语…...

从Bellman-Ford到SPFA:图解最短路径算法的优化之路
从Bellman-Ford到SPFA:图解最短路径算法的优化之路 在解决单源最短路径问题时,算法选择往往需要在效率与通用性之间寻找平衡。Bellman-Ford算法以其处理负权边的能力著称,但其固定时间复杂度的特性使其在某些场景下显得效率不足。而SPFA&…...

OpCore-Simplify:告别手动配置,15分钟搞定专业级黑苹果EFI
OpCore-Simplify:告别手动配置,15分钟搞定专业级黑苹果EFI 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的OpenCo…...

Jenkins 学习总结几
先唠两句:参数就像餐厅点单 把API想象成一家餐厅的“后厨系统”。 ? 路径参数/dishes/{dish_id} -> 好比你要点“宫保鸡丁”这道具体的菜,它是菜单(资源路径)的一部分。查询参数/dishes?spicytrue&typeSichuan -> 好比…...