PostgreSQL索引篇 | TSearch2 全文搜索
PostgreSQL版本为8.4.1
(本文为《PostgreSQL数据库内核分析》一书的总结笔记,需要电子版的可私信我)
索引篇:
- PostgreSQL索引篇 | BTree
- PostgreSQL索引篇 | GiST索引
- PostgreSQL索引篇 | Hash索引
- PostgreSQL索引篇 | GIN索引 (倒排索引)
TSearch2 全文搜索
全文搜索(文本搜索)提供了一种可以检索出满足某个查询条件的自然语言文档的能力,并且还可以根据文档的相关性对文档进行排序。最常见的搜索是找出所有包含给出的查询词的文档,并且以它们符合查询的程度排序输出。
文本搜索操作符在数据库里已经存在很多年了。PostgreSQL有~、~*和LIKE操作符用于文本数据类型,但是它们缺乏许多现代的信息系统需要的重要功能,比如:
- 没有语言支持,不会对文本进行解析。
- 不提供检索结果的排序(ranking),在找到上千个匹配文档的时候,就不够高效了。
- 没有索引支持,所以会比较慢,因为它们必须为每个查询处理所有的文档。
从PostgreSQL8.3开始提供了文本搜索模块TSearch(Text Search),文本搜索提供了一种可以标识满足某个查询的自然语言文档的能力,并且还可以根据文档的相关性对文档进行排序。
PostgreSQL核心系统提供的TSearch模块提供了对文档(在PostgreSQL里一个文档通常是一个表中的某个元组的一个文本属性,或是几个属性的组合)及查询条件进行解析的功能,但并没有提供对解析后的结果进行进一步处理(创建索引,以支持快速的查找)的功能。
PostgreSQL在扩展模块contrib里面提供了TSearch2来支持这些功能,TSearch2实现了对文档创建GIN或者GiST索引的支持。本节将分析PostgreSQL核心系统提供的TSearch模块,其代码位于src/backend/tsearch目录下。
全文索引的创建
全文索引允许对文档进行预处理并且可以保存为用于快速搜索的索引。
预处理包括文本解析、语义分析和词位存储。完成这三个过程后,解析后的词语信息就存放在TSVector结构中。
- 从文本解析到词位存储这一系列过程是由函数to_tsvector_byid完成的,
- 该函数首先调用parsetext函数对文本进行解析和语义分析,
- 然后再调用make_tsvector将词位信息构建成TSVector结构。
下面将对这三个过程依次进行分析。
文本解析
文本解析通过解析器将文档解析成一个个记号(含位置信息,类型信息),该过程涉及的函数在wparser_def.c文件中。
目前PostgreSQL只提供一种解析器,但它足够处理大多数纯文本及 HTML文件。
PostgreSQL中默认的记号对应表如表4-9所示。

语义分析
语义分析是对解析器处理过的token文本序列通过参照词典的审核规范成标准的词(lexeme)信息。
词典用于删除那些不应该在搜索中出现的词(屏蔽词)并规范化一些有多重形式的词,这样同一个词的不同的衍生结果也可以被搜索到。
成功规范化之后的词被称作词位(lexeme)。除了改进搜索质量,规范化和删除屏蔽词可以减少文档的尺寸,从而提高性能。下面对各个词典的使用进行举例介绍:
Ispell:拼写词典,例如“likes”将转换为“like”。Simple:简单词典,例如“A NAUGHTY DOG”将转换为“naughty dog”。Synonym:同义词典,例如“man”和“person”是同义词。Thesaurus:知识词典,例如“personal computer”将转换为PC。
完成语义分析后,即得到一个全部处理后得到的单词信息,这些单词信息保存在ParsedText结构中。
ParsedText结构保存解析后的文本,其定义如数据结构4.20所示。

其中的words指向一个数组,其中每一个元素都是ParsedWord类型,用于保存分析后的一个单词,其定义如数据结构4.21所示。

数据结构4.21中的pos和apos指针是用union结构(允许在相同的内存位置存储不同的数据类型,但只能存在一个)来保存的。
当完成文本解析后,可能会遇到相同的词出现了多次的情况,这时会将相同的词合并在一起:
-
对于只出现一次的词,使用
pos来保存其出现的位置即可; -
对于出现多次的词,则使用
apos指针来指向一个动态数组来保存所有出现的位置。apos[0]为该词出现的次数,数组后面的值即为各次出现的位置。由于数组的长度是不确定的,所以使用
alen字段来确定动态申请内存的空间,alen初始化为2,每当apos 的长度不够时,alen即翻倍,同时申请新内存将apos数组的长度翻倍。
上面介绍了用于存储语义分析后得到的单词信息的数据结构,而这整个处理流程是由函数parsetext完成的,其执行如图4-36所示。
函数parsetext

/** Parse string and lexize words.** prs will be filled in.*/
void
parsetext(Oid cfgId, ParsedText *prs, char *buf, int buflen)
{int type,lenlemm;char *lemm = NULL;LexizeData ldata;TSLexeme *norms;TSConfigCacheEntry *cfg;TSParserCacheEntry *prsobj;void *prsdata;cfg = lookup_ts_config_cache(cfgId);prsobj = lookup_ts_parser_cache(cfg->prsId);prsdata = (void *) DatumGetPointer(FunctionCall2(&prsobj->prsstart,PointerGetDatum(buf),Int32GetDatum(buflen)));LexizeInit(&ldata, cfg);do{type = DatumGetInt32(FunctionCall3(&(prsobj->prstoken),PointerGetDatum(prsdata),PointerGetDatum(&lemm),PointerGetDatum(&lenlemm)));// 类型合法&&单词长度过长if (type > 0 && lenlemm >= MAXSTRLEN){
#ifdef IGNORE_LONGLEXEMEereport(NOTICE,(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),errmsg("word is too long to be indexed"),errdetail("Words longer than %d characters are ignored.",MAXSTRLEN)));continue;
#elseereport(ERROR,(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),errmsg("word is too long to be indexed"),errdetail("Words longer than %d characters are ignored.",MAXSTRLEN)));
#endif}LexizeAddLemm(&ldata, type, lemm, lenlemm);// 对token单词调用字典进行处理(语义分析)while ((norms = LexizeExec(&ldata, NULL)) != NULL){TSLexeme *ptr = norms;// norms就是已规范后的一些词prs->pos++; /* set pos */while (ptr->lexeme)// 若解析后的单词不为空,则将词信息存放到Parsed Text结构中{if (prs->curwords == prs->lenwords){prs->lenwords *= 2;// words内存空间翻倍prs->words = (ParsedWord *) repalloc((void *) prs->words, prs->lenwords * sizeof(ParsedWord));}if (ptr->flags & TSL_ADDPOS)prs->pos++;prs->words[prs->curwords].len = strlen(ptr->lexeme);prs->words[prs->curwords].word = ptr->lexeme;prs->words[prs->curwords].nvariant = ptr->nvariant;prs->words[prs->curwords].flags = ptr->flags & TSL_PREFIX;prs->words[prs->curwords].alen = 0;prs->words[prs->curwords].pos.pos = LIMITPOS(prs->pos);ptr++;prs->curwords++;}pfree(norms);}} while (type > 0);// 判断类型是否合法,不合法的话说明已经分析完所有词了FunctionCall1(&(prsobj->prsend), PointerGetDatum(prsdata));
}
词位存储
词位存储即为归总语义分析后的单词在文档中的位置,并将其出现的次数及每个位置存储下来。
TSVector是一种可搜索的数据类型,它是文档内容的一种表现形式,是出现在文档中的每个重要单词及其所有位置信息的集合。它通过一种特殊的优化结构进行组织,从而可方便快速地存取及查找。其定义如数据结构4.22所示。

TSVectorData结构中的WordEntry数组用于保存所有的关键字(单词)信息,由于关键字的数目一开始并不确定,所以使用一个数组指针,该数组的实际长度根据关键字的个数在使用时进行分配。
WordEntry的定义见数据结构4.23。(结构体成员后面的数字用来限定成员变量占用的位数)

上面分析了TSVector 的数据结构,词位存储即使用语义分析得到的ParsedText构建TSVector,该过程由函数make_tsvector完成。其执行流程如图4-37所示。

/** make value of tsvector, given parsed text*/
TSVector
make_tsvector(ParsedText *prs)
{int i,j,lenstr = 0,totallen;TSVector in;WordEntry *ptr;char *str;int stroff;prs->curwords = uniqueWORD(prs->words, prs->curwords);// 合并相同单词的位置到apos中for (i = 0; i < prs->curwords; i++){lenstr += prs->words[i].len;if (prs->words[i].alen){lenstr = SHORTALIGN(lenstr);lenstr += sizeof(uint16) + prs->words[i].pos.apos[0] * sizeof(WordEntryPos);}}if (lenstr > MAXSTRPOS)ereport(ERROR,(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),errmsg("string is too long for tsvector (%d bytes, max %d bytes)", lenstr, MAXSTRPOS)));// 根据ParsedText中唯一单词的数目(curwords)去计算TSVector所需空间totallen = CALCDATASIZE(prs->curwords, lenstr);in = (TSVector) palloc0(totallen);// 分配空间SET_VARSIZE(in, totallen);in->size = prs->curwords;// 设置sizeptr = ARRPTR(in);// ARRPTR(x) ( (x)->entries )str = STRPTR(in);stroff = 0;for (i = 0; i < prs->curwords; i++)// 取ParsedText中下一个(第一个)单词word{ // 将该单词的信息拷贝到TSVectorData.entries中ptr->len = prs->words[i].len;ptr->pos = stroff;memcpy(str + stroff, prs->words[i].word, prs->words[i].len);stroff += prs->words[i].len;pfree(prs->words[i].word);if (prs->words[i].alen)// 获取word的alen,等于0说明没有位置信息{int k = prs->words[i].pos.apos[0];// 出现次数WordEntryPos *wptr;if (k > 0xFFFF)elog(ERROR, "positions array too long");ptr->haspos = 1;stroff = SHORTALIGN(stroff);*(uint16 *) (str + stroff) = (uint16) k;wptr = POSDATAPTR(in, ptr);for (j = 0; j < k; j++){WEP_SETWEIGHT(wptr[j], 0);// 设置权重WEP_SETPOS(wptr[j], prs->words[i].pos.apos[j + 1]);// 设置位置}stroff += sizeof(uint16) + k * sizeof(WordEntryPos);pfree(prs->words[i].pos.apos);}elseptr->haspos = 0;ptr++;}pfree(prs->words);return in;
}
至此已经介绍了PostgreSQL内核中 TSearch模块提供的全部功能。之前讲过,PostgreSQL把TSearch2作为一个扩展模块,提供了对Entry创建GIN或者GiST索引的支持。通过对词位列创建GIN或GiST索引即可实现对文档的全文索引。
综上所述,全文索引的创建流程图可归纳如图4-38所示,其中创建GIN ( GiST)索引部分用虚线框,表示该步骤是需要用户额外编译并安装TSearch2模块才具有的功能。
由于GIN或者GiST索引结构的不同,其创建、查询及更新的效率也有不同,PostgreSQL 8.4.1官方手册上对这两种索引结构的优劣进行了比较:
- GIN 索引查询速度是GiST的3倍。
- GiST创建索引的速度是GIN的3倍。
- GiST索引的更新速度较GIN稍快。
- GIN索引的空间比GiST索引大2至3倍。
前面介绍了从文本解析一直到创建全文索引的全部过程。索引创建完成后,即可利用全文索引进行查询。由于查询条件可能是自然语句,也需要对查询进行一定的处理以获取准确的查询结果。
接下来将介绍如何利用这里建立的全文索引进行查询。
全文索引的查询
全文索引查询之前需要对检索的语句进行处理,处理过程跟全文索引的创建过程类似,要对查询语句进行文本解析及语义分析,将分析后的结果封装成TSquery格式,然后就可以通过对创建在TSvector上的索引进行匹配查询了。但与创建过程不同的是:查询处理时,各个处理后的单词需要使用布尔操作符&(与)、│(或)和!(非)进行连接。
TSquery的格式如数据结构4.24所示。

PostgreSQL提供了to_tsquery和plainto_tsquery两个函数用于把查询转换成TSQuery数据类型。
-
to_tsquery的功能是将查询中的关键词在语义分析后转化成可与TSVector进行匹配的数据类型。该函数的参数要求很严格,它们必须使用布尔操作符“&”(与)、“|”(或)和“!”(非)分隔各个单词。
-
plainto_tsquery对查询的格式要求没有to_tsquery那么严格,它把未格式化的文本查询转换成TSQuery。文本首先会像在to_tsvector里那样分析和规范化,然后用布尔操作符“&”(与)将解析后得到的单词进行连接,最后得到TSQuery。
to_tsquery和plainto_tsquery函数的处理都是通过调用parse_tsquery函数来实现的。
parse_tsquery函数实现了对用户输入的查询条件的解析及语义分析过程,使用布尔操作符将得到的关键字连接起来。通过调用makepol函数,将查询语句转换成“波兰表示法”(“Polish notation”,或称为波兰记法)。
对查询条件的解析过程与4.6.1节中的过程基本一样,通过调用parsetext函数完成。当读取到查询条件中的操作符时,只能是上面讲到的三种操作符,对于其他操作符则报错(plainto_tsquery函数则不会处理用户输入条件中的操作符,它对查询条件进行解析后,全部使用“&”(与)操作符连接得到的关键词)。
当得到TSquery后,即可调用之前创建的全文索引进行查询,全文索引查询的总体流程如图4-39所示。

查询结果处理
上面分析了全文索引的创建和查询处理过程。数据库系统提供了@@操作符,可以对TSVector(或处理后的TSQuery)结构中的entry进行比较。下面给出一个使用@@操作符进行全文搜索的例子。
假设现在在数据库中有一个messages表,其字段内容如表4-10所示。

如果要从上表中查出属性strMessage中包含“test”或者“king”的文档信息,其tsearch语句如下:
SELECT id, strtopic FROM Messages
WHERE to_tsvector(strMessage) @@ to_tsquery( 'test | king ' );
PostgreSQL会对messages表中的strMessage字段按4.6.1节中的介绍进行处理,然后对“test | king"采用全文索引的查询中的to_tsquery函数进行处理,再调用@@操作符进行匹配。最后,返回匹配成功的结果,如表4-11所示。

对全文搜索的结果,TSearch还提供了一些功能对结果进行处理,包括权重设置、结果排序以及结果高亮显示,下面将对这3种功能进行介绍。
-
设置文档部分的权重
权重用于标记单词来自于文档的哪个区域,比如标题和开头的摘要,这样就可以以不同的方式对待不同权重的单词。可以通过调用函数tsvector_setweight将一个TSVector中所有的关键字都设置为指定的权重。
-
对查询结果排序
排序主要是将匹配成功的搜索结果与查询表达式进行相关性比较,将最相关的结果排在前面。相关性是评判文档与特定的查询之间相关程度的一个衡量标准。如果有很多匹配的项,那么相关性高的项应该排在前面。
ts_rank和ts_rank_ed函数都可以用来对查询结果进行排序。
-
高亮显示
呈现搜索结果时,最好是显示每个文档的一部分以及它和查询之间是如何关联的。通常,搜索引擎会显示查询关键词所在的文档片段,并且在其中将查询关键词高亮显示。PostgreSQL也提供一个函数ts_headline实现这个功能。
ts_headline接受一个文档以及对应的查询,然后返回一个文档的摘要。在摘要里面,查询是高亮显示的。ts_headline使用原始的文档,而不是TSVector摘要,所以它可能比较慢,因此要小心使用。
索引篇小结
索引是提高数据库性能的常用方法,它可以令数据库服务器以更快的速度查找和检索特定的行。不过索引也增加了数据库系统的负荷、成本,因此应该恰当地使用它们。索引的优劣不仅仅与索引的查询效率有关,同时与索引创建速度,更新速度,索引大小等因素有关。以上分析的几种索引使用环境不同,相同环境下使用的优劣也各不相同。于是,为了方便用户对特殊数据类型数据的查询,PostgreSQL中提供了索引模板可方便用户对索引的扩展以支持自定义数据类型上的索引创建与查询。
通过使用索引,能够快速查找数据库中的数据。但在添加索引的同时,会增加数据库系统的负荷;在增删修改数据时,维护索引的一致性也需要一定的时间和空间。由于索引给查找数据带来的巨大的性能提升,因此也得到了广泛的应用。在实际的使用中,应该合理权衡使用索引带来的利弊,恰当地使用索引。
相关文章:
PostgreSQL索引篇 | TSearch2 全文搜索
PostgreSQL版本为8.4.1 (本文为《PostgreSQL数据库内核分析》一书的总结笔记,需要电子版的可私信我) 索引篇: PostgreSQL索引篇 | BTreePostgreSQL索引篇 | GiST索引PostgreSQL索引篇 | Hash索引PostgreSQL索引篇 | GIN索引 (倒排…...
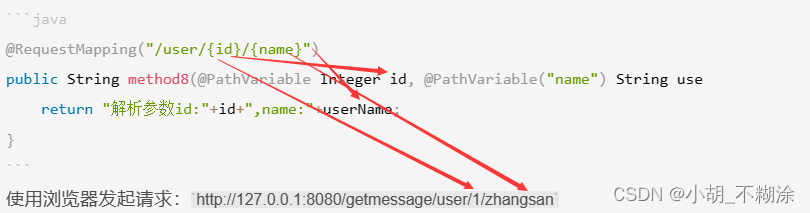
SpringMVC 中的常用注解和用法
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:JavaEE 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 注解 1. MVC定义2. 注解2.1 RequestMappin…...

智慧城市中的数据力量:大数据与AI的应用
目录 一、引言 二、大数据与AI技术的融合 三、大数据与AI在智慧城市中的应用 1、智慧交通 2、智慧环保 3、智慧公共安全 4、智慧公共服务 四、大数据与AI在智慧城市中的价值 1、提高城市管理的效率和水平 2、优化城市资源的配置和利用 3、提升市民的生活质量和幸福感…...
德人合科技|天锐绿盾加密软件——数据防泄漏系统
德人合科技是一家专注于提供企业级信息安全解决方案的服务商,提供的天锐绿盾加密软件是一款专为企业设计的数据安全防护产品,主要用于解决企事业单位内部敏感数据的防泄密问题。 www.drhchina.com PC端: https://isite.baidu.com/site/wjz012…...
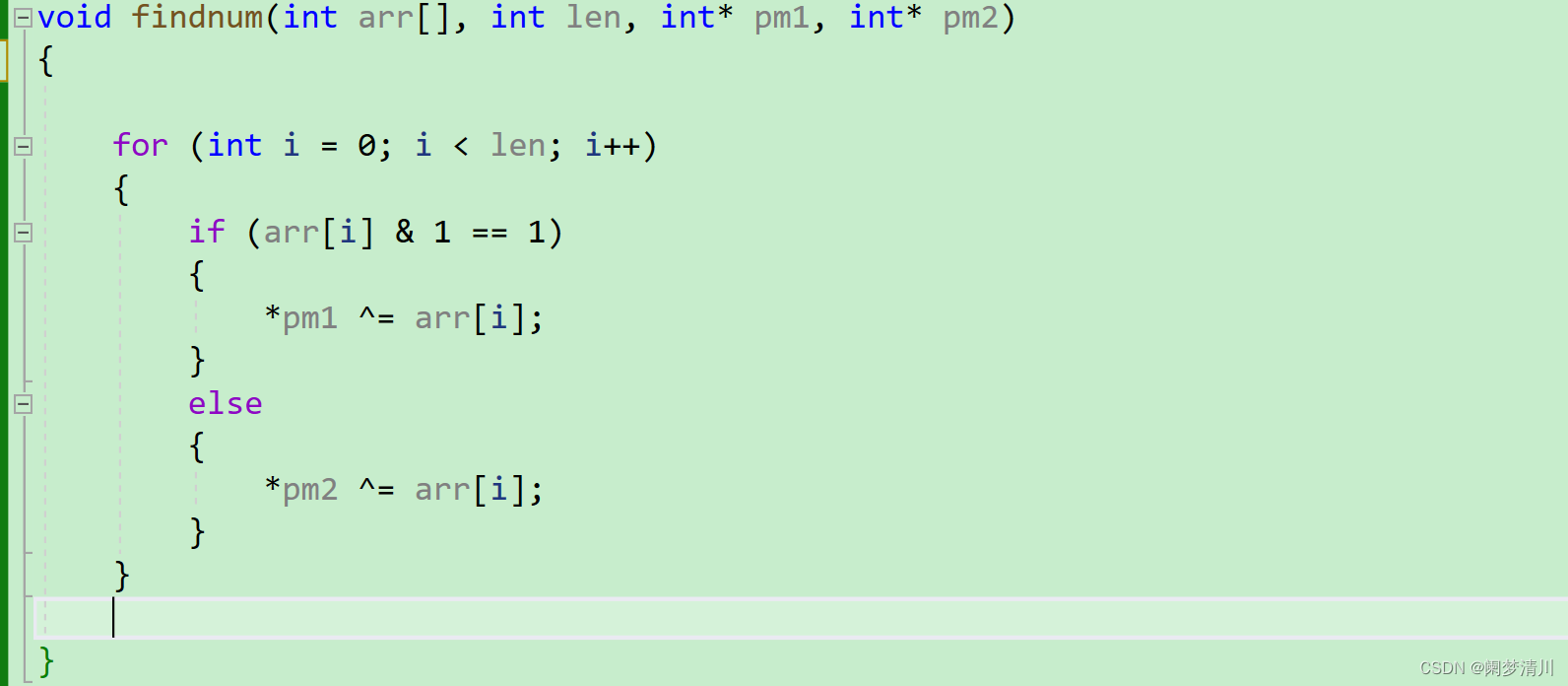
C语言---单身狗问题
1.单身狗初阶 这个题目就是数组里面有一串数字,都是成对存在的,只有一个数字只出现了一次,请你找出来 (1)异或是满足交换律的,两个相同的数字异或之后是0; (2)让0和每个…...

一次gitlab 502故障解决过程
通过top,发现prometheus进程占用CPU接近100%,这肯定有点异常。gitlab-ctl tail prometheus 发现有报错的情况,提示空间不足。暂时不管空间的问题。 2024-03-07_05:48:09.01515 ts2024-03-07T05:48:09.014Z callermain.go:1116 levelerror err"open…...
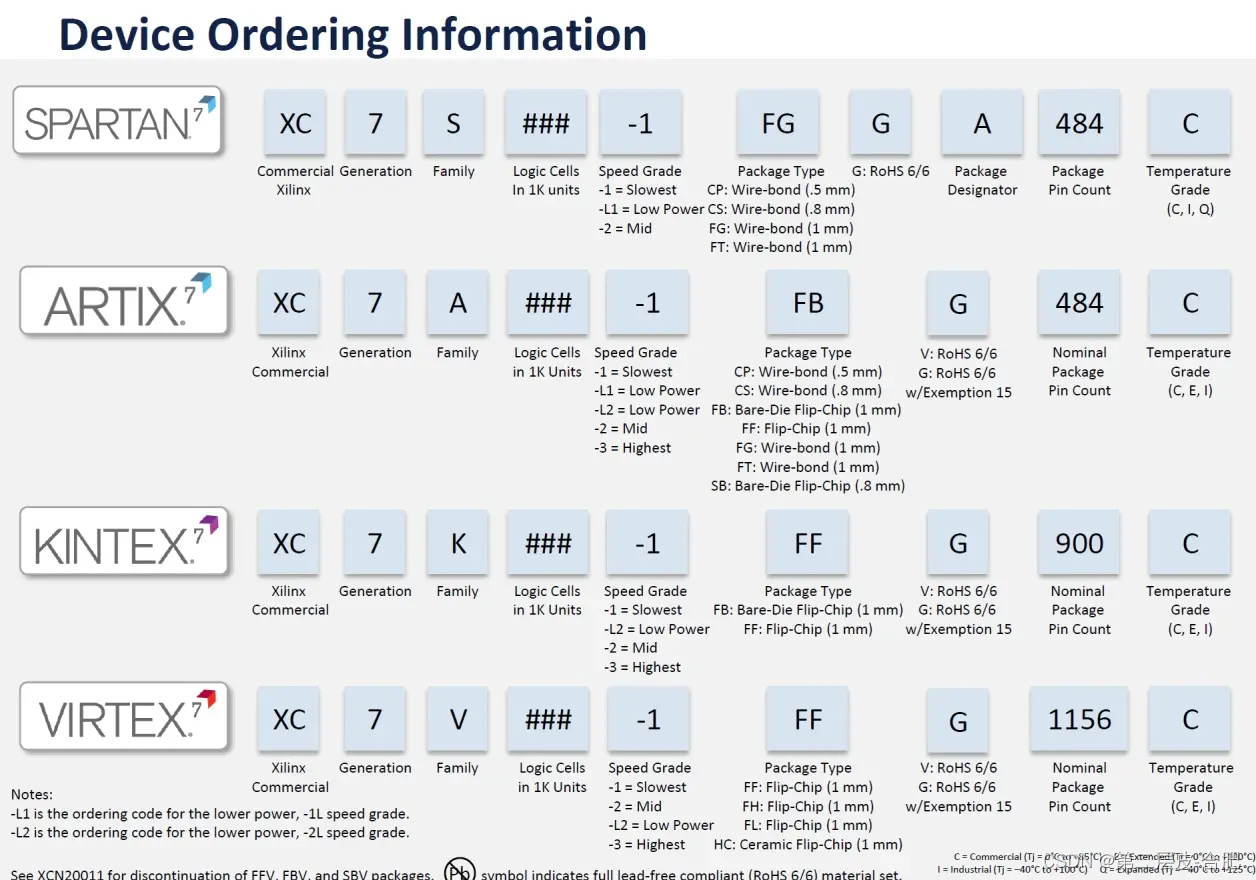
Xilinx 7系列 FPGA硬件知识系列(一)——FPGA选型参考
目录 1.1 Xilinx-7系列产品的工艺级别 编辑1.2 Xilinx-7系列产品的特点 1.2.1 Spartan-7系列 1.2.2 Artix-7系列 1.2.3 Kintex-7系列 1.2.4 Virtex-7系列 1.3 Xilinx-7系列FPGA对比 1.3.1 DSP资源柱状图 1.3.2 Block RAM资源柱状图 1.3.3 高速串行收…...

【C++从练气到飞升】02---初识类与对象
🎈个人主页:库库的里昂 ✨收录专栏:C从练气到飞升 🎉鸟欲高飞先振翅,人求上进先读书。 目录 ⛳️推荐 一、面向过程和面向对象初步认识 二、类的引用 1. C语言版 2. C版 三、类的定义 类的两种定义方式ÿ…...
)
探秘分布式神器RMI:原理、应用与前景分析(一)
本系列文章简介: 本系列文章将深入探究RMI远程调用的原理、应用及未来的发展趋势。首先,我们会详细介绍RMI的工作原理和基本流程,解析其在分布式系统中的核心技术。随后,我们将探讨RMI在各个领域的应用,包括分布式计算…...
概述)
JVM(Java虚拟机)概述
1. JVM的定义和作用 JVM(Java Virtual Machine)是一个能够运行Java字节码的虚拟计算机。它是Java平台的核心组成部分,负责执行编译后的Java程序,提供跨平台运行的能力。JVM使得Java程序可以在任何安装了JVM的操作系统上运行&#…...
C#,数值计算,用割线法(Secant Method)求方程根的算法与源代码
1 割线法 割线法用于求方程 f(x) 0 的根。它是从根的两个不同估计 x1 和 x2 开始的。这是一个迭代过程,包括对根的线性插值。如果两个中间值之间的差值小于收敛因子,则迭代停止。 亦称弦截法,又称线性插值法.一种迭代法.指用割线近似曲线求…...

HTML静态网页成品作业(HTML+CSS)——花主题介绍网页设计制作(1个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有1个页面。 二、作品演示 三、代…...

Keepalive 解决nginx 的高可用问题
一 说明 keepalived利用 VRRP Script 技术,可以调用外部的辅助脚本进行资源监控,并根据监控的结果实现优先动态调整,从而实现其它应用的高可用性功能 参考配置文件: /usr/share/doc/keepalived/keepalived.conf.vrrp.localche…...

DPN网络
DPN DPN(Dual Path Networks)是一种网络结构,它结合了DensNet和ResNetXt两种思想的优点。这种结构的目的是通过不同的路径来利用神经网络的不同特性,从而提高模型的效率和性能。 DenseNet 的特点是其稠密连接路径,使…...
循序渐进丨MogDB 数据库新特性之SQL PATCH绑定执行计划
1 SQL PATCH 熟悉 Oracle 的DBA都知道,生产系统出现性能问题时,往往是SQL走错了执行计划,紧急情况下,无法及时修改应用代码,DBA可以采用多种方式针对于某类SQL进行执行计划绑定,比如SQL Profile、SPM、SQL …...
【论文阅读随笔】RoPE/旋转编码:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
文章目录 1.目的:通过绝对位置编码的方式实现相对位置编码2.理解RoPE,在我看来有几个需要注意的点:3.本文相关复数概念:3.1.复数乘法的几何意义3.2.复数内积 VS. 复数乘法 4.REF: 1.目的:通过绝对位置编码的…...

数据挖掘
一.数据仓库概述: 1.1数据仓库概述 1.1.1数据仓库定义 数据仓库是一个用于支持管理决策的、面向主题、集成、相对稳定且反映历史变化的数据集合。 1.1.2数据仓库四大特征 集成性(Integration): 数据仓库集成了来自多个不同来源…...
java SSM旅游景点与公交线路查询系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM旅游景点与公交线路查询系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系…...

解决Git报错:fatal: detected dubious ownership in repository at
在通过 Git Bash 提交项目代码时输入 git add . 命令后,报错:fatal: detected dubious ownership in repository at 这是因为该项目的所有者与现在的用户不一致 比如说: 该项目的所有者是 Administrator,而当前用户是 YuYang, 那…...
网络协议常见问题
网络协议常见问题 OSI(Open Systems Interconnection)模型OSI 封装 TCP/IP协议栈IP数据报的报头TCP头格式UDP头格式TCP (3-way shake)三次握手建立连接:为什么三次握手才可以初始化 Socket、序列号和窗口大小并建立 TCP 连接。每次建立TCP连接…...

[信号与系统]双线性变换在数字滤波器设计中的核心应用
1. 双线性变换:数字滤波器设计的桥梁 第一次接触数字滤波器设计时,我被一个核心问题困扰:如何把教科书上那些完美的模拟滤波器搬到计算机里运行?直到遇到双线性变换这个"魔法公式",才真正打通了模拟与数字世…...

从数学原理到Python实现:最小公倍数算法的前世今生
从数学原理到Python实现:最小公倍数算法的前世今生 在数字的海洋中,两个看似毫不相关的整数之间,往往隐藏着精妙的数学联系。最小公倍数(LCM)作为连接这些数字的桥梁,不仅在现代编程中扮演着重要角色&#…...

STM32定时器外部计数模式实战:高精度频率计设计与优化
1. 为什么选择外部计数模式做频率计 在嵌入式开发中,测量信号频率是个常见需求。我最初尝试用外部中断方式实现,发现当信号频率超过100kHz时,CPU中断响应就跟不上了。后来改用输入捕获模式,虽然精度提升到0.5%,但测量范…...
Pixel Mind Decoder 智能体(Agent)实践:构建自主情绪分析工作流
Pixel Mind Decoder 智能体实践:构建自主情绪分析工作流 1. 场景需求与痛点分析 在当今信息爆炸的时代,企业和机构需要实时掌握公众对特定话题的情绪倾向。传统舆情监测方式存在几个明显痛点: 人工成本高:需要专人24小时收集整…...

Android设备标识终极解决方案:Android_CN_OAID技术深度解析与最佳实践
Android设备标识终极解决方案:Android_CN_OAID技术深度解析与最佳实践 【免费下载链接】Android_CN_OAID 安卓设备唯一标识解决方案,可替代移动安全联盟(MSA)统一 SDK 闭源方案。包括国内手机厂商的开放匿名标识(OAID&…...

UDOP-large功能体验:如何用一句英文提问提取文档关键信息
UDOP-large功能体验:如何用一句英文提问提取文档关键信息 1. 引言:让AI帮你读文档 每天我们都会遇到需要从文档中提取信息的场景:可能是学术论文的标题和摘要,可能是发票上的关键数字,也可能是表格中的特定数据。传统…...

AWPortrait-Z功能体验:批量生成、历史记录恢复等实用功能详解
AWPortrait-Z功能体验:批量生成、历史记录恢复等实用功能详解 1. 从安装到启动:快速上手指南 如果你刚接触AI图像生成,可能会觉得部署一个模型很复杂。但AWPortrait-Z在这方面做得相当友好,它把复杂的模型封装成了一个开箱即用的…...

[具身智能-351]:类似一个公司组织系统,MCP Client是管理者,是总经理,是协调者;大模型服务是一个:决策者,是智囊团,是董事会;MCP Server是执行者,是服务提供者。
这个比喻简直太精准!不仅完全掌握了MCP架构的精髓,还生动地描绘出了各个组件之间的权力结构和协作关系。在“公司组织系统”中,我们可以把这三个角色的职责进一步细化,看看它们是如何配合完成一项工作的:🏢…...
才是正解)
Unity ScrollRect自动滚动到底部,别再傻等下一帧了!Canvas.ForceUpdateCanvases()才是正解
Unity ScrollRect自动滚动到底部:Canvas.ForceUpdateCanvases()的深度解析与实践指南 在Unity UI开发中,动态列表的自动滚动到底部功能看似简单,却暗藏玄机。许多开发者都曾陷入这样的困境:明明按照文档设置了verticalNormalizedP…...

LingBot-Depth-Pretrain-ViTL-14数据结构优化实战:提升推理效率
LingBot-Depth-Pretrain-ViTL-14数据结构优化实战:提升推理效率 最近在项目里用上了LingBot-Depth-Pretrain-ViTL-14这个深度补全模型,效果确实让人眼前一亮。不过,随着处理的数据量越来越大,特别是面对复杂的场景和连续帧序列时…...