生成模型与判别模型
生成模型与判别模型
一、决策函数Y=f(X)或者条件概率分布P(Y|X)
监督学习的任务就是从数据中学习一个模型(也叫分类器),应用这一模型,对给定的输入X预测相应的输出Y。这个模型的一般形式为决策函数Y=f(X)或者条件概率分布P(Y|X)。
决策函数Y=f(X):你输入一个X,它就输出一个Y,这个Y与一个阈值比较,根据比较结果判定X属于哪个类别。例如两类(w1和w2)分类问题,如果Y大于阈值,X就属于类w1,如果小于阈值就属于类w2。这样就得到了该X对应的类别了。
条件概率分布P(Y|X):你输入一个X,它通过比较它属于所有类的概率,然后输出概率最大的那个作为该X对应的类别。例如:如果P(w1|X)大于P(w2|X),那么我们就认为X是属于w1类的。
所以上面两个模型都可以实现对给定的输入X预测相应的输出Y的功能。实际上通过条件概率分布P(Y|X)进行预测也是隐含着表达成决策函数Y=f(X)的形式的。例如也是两类w1和w2,那么我们求得了P(w1|X)和P(w2|X),那么实际上判别函数就可以表示为Y= P(w1|X)/P(w2|X),如果Y大于1或者某个阈值,那么X就属于类w1,如果小于阈值就属于类w2。而同样,很神奇的一件事是,实际上决策函数Y=f(X)也是隐含着使用P(Y|X)的。因为一般决策函数Y=f(X)是通过学习算法使你的预测和训练数据之间的误差平方最小化,而贝叶斯告诉我们,虽然它没有显式的运用贝叶斯或者以某种形式计算概率,但它实际上也是在隐含的输出极大似然假设(MAP假设)。也就是说学习器的任务是在所有假设模型有相等的先验概率条件下,输出极大似然假设。
所以呢,分类器的设计就是在给定训练数据的基础上估计其概率模型P(Y|X)。如果可以估计出来,那么就可以分类了。但是一般来说,概率模型是比较难估计的。给一堆数给你,特别是数不多的时候,你一般很难找到这些数满足什么规律吧。那能否不依赖概率模型直接设计分类器呢?事实上,分类器就是一个决策函数(或决策面),如果能够从要解决的问题和训练样本出发直接求出判别函数,就不用估计概率模型了,这就是决策函数Y=f(X)的伟大使命了。例如支持向量机,我已经知道它的决策函数(分类面)是线性的了,也就是可以表示成Y=f(X)=WX+b的形式,那么我们通过训练样本来学习得到W和b的值就可以得到Y=f(X)了。还有一种更直接的分类方法,它不用事先设计分类器,而是只确定分类原则,根据已知样本(训练样本)直接对未知样本进行分类。包括近邻法,它不会在进行具体的预测之前求出概率模型P(Y|X)或者决策函数Y=f(X),而是在真正预测的时候,将X与训练数据的各类的Xi比较,和哪些比较相似,就判断它X也属于Xi对应的类。
二、生成方法和判别方法
监督学习方法又分生成方法(Generative approach)和判别方法(Discriminative approach),所学到的模型分别称为生成模型(Generative Model)和判别模型(Discriminative Model)。
判别方法:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻,感知级,决策树,支持向量机等。
生成方法:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立样本的联合概率概率密度模型P(X,Y),然后再得到后验概率P(Y|X),再利用它进行分类,就像上面说的那样。注意了哦,这里是先求出P(X,Y)才得到P(Y|X)的,然后这个过程还得先求出P(X)。P(X)就是你的训练数据的概率分布。哎,刚才说了,需要你的数据样本非常多的时候,你得到的P(X)才能很好的描述你数据真正的分布。例如你投硬币,你试了100次,得到正面的次数和你的试验次数的比可能是3/10,然后你直觉告诉你,可能不对,然后你再试了500次,哎,这次正面的次数和你的试验次数的比可能就变成4/10,这时候你半信半疑,不相信上帝还有一个手,所以你再试200000次,这时候正面的次数和你的试验次数的比(就可以当成是正面的概率了)就变成5/10了。
还有一个问题就是,在机器学习领域有个约定俗成的说法是:不要去学那些对这个任务没用的东西。例如,对于一个分类任务:对一个给定的输入x,将它划分到一个类y中。那么,如果我们用生成模型:p(x,y)=p(y|x)·p(x)
那么,我们就需要去对p(x)建模,但这增加了我们的工作量,这让我们很不爽(除了上面说的那个估计得到P(X)可能不太准确外)。实际上,因为数据的稀疏性,导致我们都是被强迫地使用弱独立性假设去对p(x)建模的,所以就产生了局限性。所以我们更趋向于直观的使用判别模型去分类。
这样的方法之所以称为生成方法,是因为模型表示了给定输入X产生输出Y的生成关系。用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。典型的生成模型有:朴素贝叶斯和隐马尔科夫模型等。
三、生成模型和判别模型的优缺点
在监督学习中,两种方法各有优缺点,适合于不同条件的学习问题。
生成方法的特点:上面说到,生成方法学习联合概率密度分布P(X,Y),所以就可以从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度。但它不关心到底划分各类的那个分类边界在哪。生成方法可以还原出联合概率分布P(Y|X),而判别方法不能。生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快的收敛于真实模型,当存在隐变量时,仍可以用生成方法学习。此时判别方法就不能用。
判别方法的特点:判别方法直接学习的是决策函数Y=f(X)或者条件概率分布P(Y|X)。不能反映训练数据本身的特性。但它寻找不同类别之间的最优分类面,反映的是异类数据之间的差异。直接面对预测,往往学习的准确率更高。由于直接学习P(Y|X)或P(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
四、生成模型和判别模型的联系
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
五、再形象点可以吗
例如我们有一个输入数据x,然后我们想将它分类为标签y。(迎面走过来一个人,你告诉我这个是男的还是女的)
生成模型学习联合概率分布p(x,y),而判别模型学习条件概率分布p(y|x)。
下面是个简单的例子:
例如我们有以下(x,y)形式的数据:(1,0), (1,0), (2,0), (2, 1)
那么p(x,y)是:
y=0 y=1-----------x=1 | 1/2 0x=2 | 1/4 1/4
而p(y|x) 是:
y=0 y=1-----------x=1 | 1 0x=2 | 1/2 1/2
我们为了将一个样本x分类到一个类y,最自然的做法就是条件概率分布p(y|x),这就是为什么我们对其直接求p(y|x)方法叫做判别算法。而生成算法求p(x,y),而p(x,y)可以通过贝叶斯方法转化为p(y|x),然后再用其分类。但是p(x,y)还有其他作用,例如,你可以用它去生成(x,y)对。
再假如你的任务是识别一个语音属于哪种语言。例如对面一个人走过来,和你说了一句话,你需要识别出她说的到底是汉语、英语还是法语等。那么你可以有两种方法达到这个目的:
1、学习每一种语言,你花了大量精力把汉语、英语和法语等都学会了,我指的学会是你知道什么样的语音对应什么样的语言。
2、不去学习每一种语言,你只学习这些语言模型之间的差别,然后再分类。意思是指我学会了汉语和英语等语言的发音是有差别的,我学会这种差别就好了。
那么第一种方法就是生成方法,第二种方法是判别方法。
生成算法尝试去找到底这个数据是怎么生成的(产生的),然后再对一个信号进行分类。基于你的生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。
相关文章:

生成模型与判别模型
生成模型与判别模型 一、决策函数Yf(X)或者条件概率分布P(Y|X) 监督学习的任务就是从数据中学习一个模型(也叫分类器),应用这一模型,对给定的输入X预测相应的输出Y。这个模型的一般形式为决策函数Yf(X)或者条件概率分布P(Y|X)。 …...

Kotlin lateinit 和 lazy 之间的区别 (翻译)
Kotlin 中的属性是使用var或val关键字声明的。Late init 和 lazy 都是用来初始化以后要用到的属性。 由于这两个关键字都用于声明稍后将要使用的属性,因此让我们看一下它们以及它们的区别。 Late Init 在下面的示例中,我们有一个变量 myClass࿰…...

Golang alpine Dockerfile 最小打包
最近在ubantu 上进行了 iris项目的alpine 版本打包,过程遇到了一些问题,记录一下。 golang版本 :1.18 系统:ubantu 代码结构 Dockfile内容 FROM alpine:latest MAINTAINER Si Wei<3320376695qq.com> ENV VERSION 1.1 ENV G…...
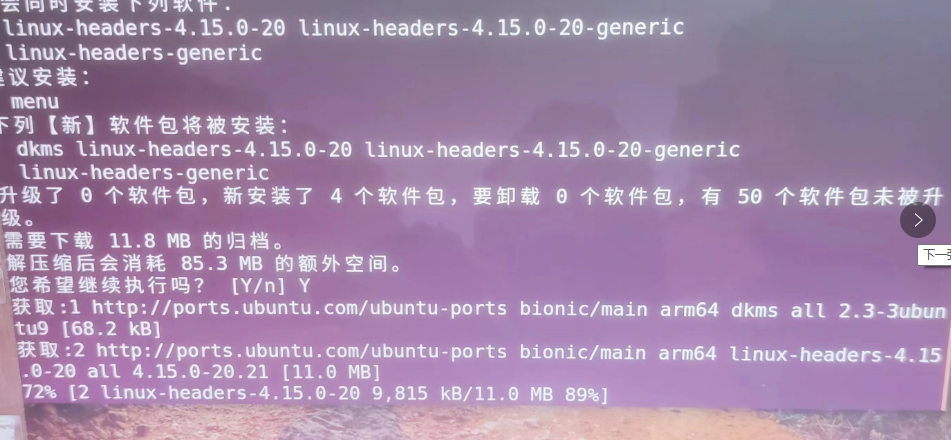
在NVIDIA JetBot Nano小车上更新WIFI驱动
前言:树莓派上的WIFI驱动类型比较多,经常有更好驱动的需求本文给出RealTek的无线WIFI模组,8821CU的驱动更新办法步骤第一 通过其他方式连接网络小车通过网线或者老的WIFI连接到网络上第二 构建驱动模块并下载驱动首先,我们需要打开一个ubuntu…...

2023年网络安全最应该看的书籍,弯道超车,拒绝看烂书
学习的方法有很多种,看书就是一种不错的方法,但为什么总有人说:“看书是学不会技术的”。 其实就是书籍没选对,看的书不好,你学不下去是很正常的。 一本好书其实不亚于一套好的视频教程,尤其是经典的好书…...

VSYNC研究
Vsync信号是SurfaceFlinger进程中核心的一块逻辑,我们主要从以下几个方面着手讲解。软件Vsync是怎么实现的,它是如何保持有效性的?systrace中看到的VSYNC信号如何解读,这些脉冲信号是在哪里打印的?为什么VSYNC-sf / VS…...

python gRPC:根据.protobuf文件生成py代码、grpc转换为http协议对外提供服务
文章目录python GRPC:根据.protobuf文件生成py代码grpcio-tools安装和使用python GRPC的官网示例grpc转换为http协议对外提供服务工作问题总结grpc-ecosystem/grpc-gateway/third_party/googleapis: warning: directory does not exist.python GRPC:根据…...
Allegro如何输出ODB文件操作指导
Allegro如何输出ODB文件操作指导 在PCB设计完成之后,需要输出生产文件用于生产加工,除了gerber文件可以用生产制造,ODB文件同样也可以用于生产,如下图 用Allegro如何输出ODB文件,具体操作如下 首先确保电脑上已经安装了ODB这个插件,版本不受限制点击File...
koa-vue的分页实现
1.引言 最近确实体会到了前端找工作的难处,不过大家还是要稳住心态,毕竟有一些前端大神说的有道理,前端发展了近20年,诞生了很多leader级别的大神,这些大神可能都没有合适的坑位,我们新手入坑自然难一些&am…...

安全开发基础 -- DAST,SAST,IAST简单介绍
安全开发基础-- DAST,SAST,IAST 简介 DAST 动态应用程序安全测试(Dynamic Application Security Testing)技术在测试或运行阶段分析应用程序的动态运行状态。它模拟黑客行为对应用程序进行动态攻击,分析应用程序的反…...
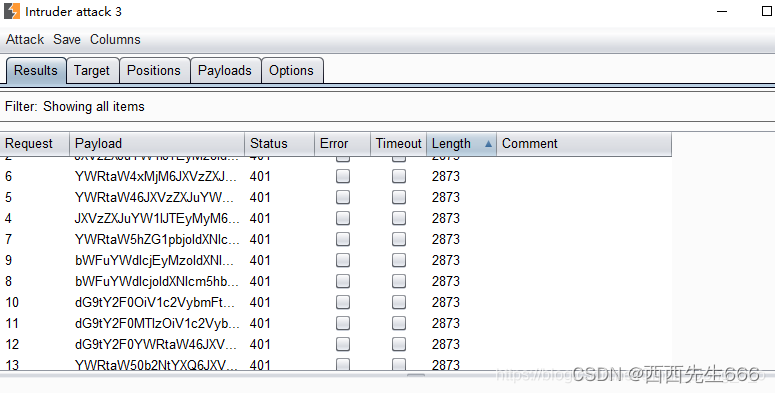
网络安全之暴力破解介绍及暴力破解Tomcat
网络安全之暴力破解介绍及应用场景一、暴力破解介绍1.1 暴力破解介绍1.2 暴力破解应用场景一、暴力破解Tomcat一、暴力破解介绍 1.1 暴力破解介绍 暴力破解字典:https://github.com/k8gege/PasswordDic 1.2 暴力破解应用场景 一、暴力破解Tomcat 登录Tomcat后台&a…...
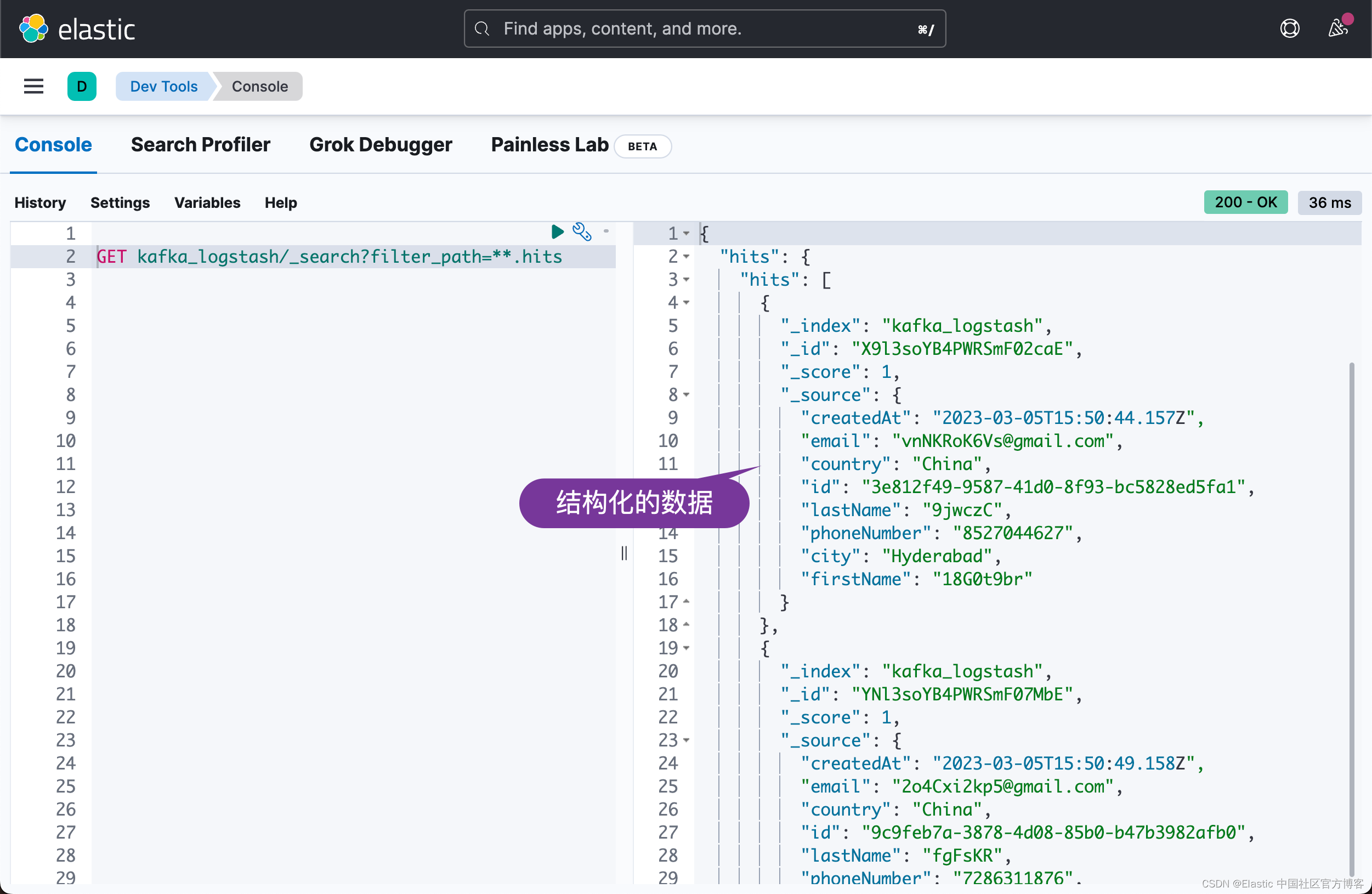
Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我构建了从 Beats > Kafka > Logstash > Elasticsearch 的管道。在今天的文章中,我将描述从 Nodejs > Kafka > Logstash > Elasticsearch 这样的一个数据流。在…...

记录一次es的性能调优
文章目录es性能调优启用g1垃圾回收器es性能调优 成都的es集群经常出现告警,查看日志发现 [gc][11534155] overhead, spent [38.3s] collecting in the last [38.6s]这是 JVM 垃圾回收过程中的一条日志,表示在最近 38.6 秒内,JVM 进行了一次…...
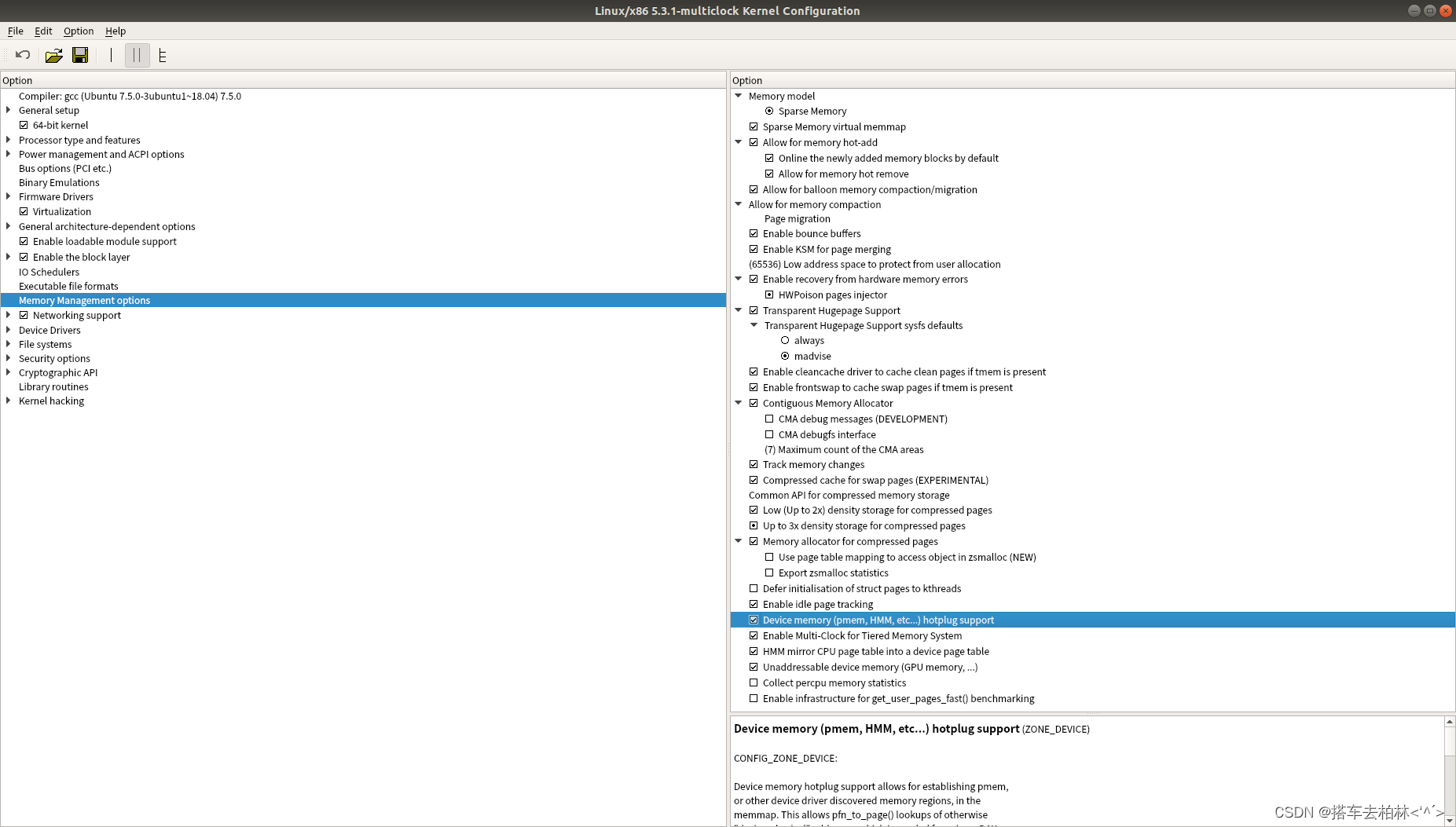
内核性能评估测试及具体修改操作步骤记录
步骤记录前言一、查看环境配置二、LRU缓存空间调整三、进程扫描时间间隔四、与其他内核对比的工作负载测试(另一个内核的编译)总结前言 记录的相关操作有:查看服务器硬件环境、LRU缓存大小修改、内核命名、内核编译以及进程执行周期的设置。…...

S7-200smart远程无线模拟量信号采集案例
本参考方案使用西门子PLCS7-200SMART 结合无线通讯终端DTD434MC和DTD433F实现 PLC对远端设备模拟量的远程无线输入输出查询控制。所使用到的设备:西门子S7-200smartPLC无线数据终端DTD434MC无线模拟量信号测控终端DTD433F所使用的协议:ModbusRTU协议方案…...

Blender Python材质处理入门
本文介绍在 Blender 中如何使用 Python API 获取材质及其属性。 推荐:用 NSDT场景设计器 快速搭建3D场景。 1、如何获取材质 方法1、 获取当前激活的材质 激活材质是当前在材质槽中选择的材料。 如果你选择一个面,则活动材料将更改为分配给选定面的材质…...
ChatGPT后劲很大,问题也是
ChatGPT亮相即封神,最初的访客是程序员、工程师、AI从业者、投资人,最后是无数懵懂又好奇的普通人:ChatGPT是什么?自己会被ChatGPT取代吗?看待ChatGPT的立场也是两个极端: 快乐,是因为ChatGPT太…...

世界那么大,你哪都别去了,来我带你了解CSS3 (二)
文章目录❤️🔥CSS文档流❤️🔥CSS浮动❤️🔥CSS定位❤️🔥CSS媒体查询❤️🔥CSS文档流 文档流是文档中可显示对象在排列时所占用的位置/空间。 例如:块元素自上而下摆放,内…...

2023年再不会Redis,就要被淘汰了
目录专栏导读一、同样是缓存,用map不行吗?二、Redis为什么是单线程的?三、Redis真的是单线程的吗?四、Redis优缺点1、优点2、缺点五、Redis常见业务场景六、Redis常见数据类型1、String2、List3、Hash4、Set5、Zset6、BitMap7、Bi…...

Java SPI机制了解与应用
1. 了解SPI机制 我们在平时学习和工作中总是会听到Java SPI机制,特别是使用第三方框架的时候,那么什么是SP机制呢?SPI 全称 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的接口,它可以用来…...

前端入门必学:CSS盒子模型与图片样式全解析前言
在学习前端开发的过程中,掌握 CSS 的基础知识是至关重要的一步。本文将详细介绍 CSS 盒子模型、标签宽高、边框、边距 以及 图片与背景图片 的使用方法,适合刚入门的同学系统学习和复习。一、CSS 盒子模型——页面布局的基石1. 什么是盒子模型࿱…...

嵌入式Linux系统固化:从启动卡制作到eMMC克隆的工程实践
1. 项目概述:从“启动卡”到“系统固化”的工程实践在嵌入式开发、工业控制、边缘计算乃至一些特定的服务器运维场景里,我们经常会遇到一个看似基础却至关重要的需求:如何将一个完整的Linux操作系统,从一张临时的启动介质…...
)
钱学森物理大一统:宇宙速度阶梯尺 全套公版正式文档(带可计算代码)
宇宙速度阶梯尺 全套公版正式文档 (无版权全开源全民通用可直接印刷发布/平台投稿/社区分发) 开篇总纲 定名:本源速度阶梯尺 核心主旨:大道至简,以地球天然标准音速为万物速度本源基底,以宇宙真空光速为速度…...

纺织行业智能化升级进入深水区:AI验布机从“可选项”变为“必选项”
过去三年,走访过数十家纺织服装企业的行业观察者会发现一个明显的变化:2023年时,AI验布机还是展会上引人驻足的新奇设备;到了2025年,它已经成为越来越多工厂标准配置的一部分。这一转变背后,折射出整个纺织…...

Claude Code出质量事故了?Anthropic发了一篇有诚意的复盘|AI新岗位FDE爆火
每天更新,带你读懂科技圈。 今日看点: Anthropic 正式回应 Claude Code 质量下降的社区讨论,披露三条幕后原因;FDE(Forward Deployed Engineer)正在成为 AI 公司争抢的新岗位;Figma 自研 Redis …...

深入解析Safe智能合约钱包:架构、安全与开发实践
1. 项目概述:一个面向未来的智能合约钱包架构如果你在Web3领域待过一段时间,尤其是深度参与过以太坊生态的DApp开发或资产管理,那么你一定对“钱包”这个入口工具有着复杂的感情。一方面,它是我们通往链上世界的钥匙;另…...

电商客服机器人如何通过 Taotoken 动态选择性价比最优的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 电商客服机器人如何通过 Taotoken 动态选择性价比最优的模型 在电商客服场景中,用户咨询的问题复杂度差异巨大。从简单…...

AI Native Web 开发实战:从零构建智能应用
AI Native Web 产品实战指南:从概念到落地的完整路线做了大半年 AI 应用开发之后,我发现一个现象:很多人知道 “AI Native” 这个词,但真要动手做一个 AI Native 的 Web 产品,脑子里是一团浆糊的。这篇文章就是想把这块…...

智能定时任务管理:用自然语言替代Crontab,TickGPTick项目实践
1. 项目概述:一个能“听懂”你需求的定时任务管理器最近在折腾一个自动化脚本项目时,我又一次陷入了“定时任务”的泥潭。相信很多开发者都有同感:写个脚本容易,但想让它定时、可靠、有状态地跑起来,总得和 crontab、s…...

MAA明日方舟自动辅助工具终极指南:一键解放双手的智能解决方案
MAA明日方舟自动辅助工具终极指南:一键解放双手的智能解决方案 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: htt…...