mysql的其他问题
1.MySQL数据库作发布系统的存储,一天五万条以上的增量,预计运维三年,怎么优化?
a. 设计良好的数据库结构,允许部分数据冗余,尽量避免join查询,提高效率。
b. 选择合适的表字段数据类型和存储引擎,适当的添加索引。
c. mysql库主从读写分离。
d. 找规律分表,减少单表中的数据量提高查询速度。
e。添加缓存机制,比如memcached,apc等。
f. 不经常改动的页面,生成静态页面。
g. 书写高效率的SQL。比如 SELECT * FROM TABEL 改为 SELECT field_1, field_2, field_3 FROM TABLE.
2.对于大流量的网站,您采用什么样的方法来解决各页面访问量统计问题?
a. 确认服务器是否能支撑当前访问量。
b. 优化数据库访问。
c. 禁止外部访问链接(盗链), 比如图片盗链。
d. 控制文件下载。
e. 使用不同主机分流。
f. 使用浏览统计软件,了解访问量,有针对性的进行优化。
3.为什么elasticsearch 的搜索就是比mysql要快一点呢?数据结构上的特性?
Mysql 只有 term dictionary 这一层,是以 b-tree 排序的方式存储在磁盘上的。检索一个 term 需要若干次的 random access 的磁盘操作。而 Lucene 在 term dictionary 的基础上添加了 term index 来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数。
额外值得一提的两点是:term index 在内存中是以 FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary 在磁盘上是以分 block 的方式保存的,一个 block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样 term dictionary 可以比 b-tree 更节约磁盘空间。
两者对比: 对于倒排索引,要分两种情况:
1、基于分词后的全文检索
这种情况是es的强项,而对于mysql关系型数据库而言完全是灾难
因为es分词后,每个字都可以利用FST高速找到倒排索引的位置,并迅速获取文档id列表
但是对于mysql检索中间的词只能全表扫(如果不是搜头几个字符)
2、精确检索
这种情况我想两种相差不大,有些情况下mysql的可能会更快些
如果mysql的非聚合索引用上了覆盖索引,无需回表,则速度可能更快
es还是通过FST找到倒排索引的位置并获取文档id列表,再根据文档id获取文档并根据相关度算分进行排序,但es还有个杀手锏,即天然的分布式使得在大数据量面前可以通过分片降低每个分片的检索规模,并且可以并行检索提升效率
用filter时更是可以直接跳过检索直接走缓存
4.什么是Term Index?
将分词后的term进行排序索引,类似的mysql对于"term"(即主键,或者索引键)只是做了排序, 并且是大部分是放在磁盘上的,只有B+树的上层才是放在内存中的,查询仍然需要logN的访问磁盘,而ES将term分词排序后还做了一次索引,term index,即将term的通用前缀取出,构建成Trie树 通过这个树可以快速的定位到Term dictionary的本term的offset,再经过顺序查找,便可以很快找到本term的posting list。
5.解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
池话设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。
数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。连接池还减少了用户必须等待建立与数据库的连接的时间。
6.MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?
redis 提供的数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰 allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
使用策略规则:
1、如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru
2、如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
7.如何进行大表优化?
-
限定数据的范围:务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
-
读/写分离 经典的数据库拆分方案,主库负责写,从库负责读;
-
垂直分区 根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 如下图所示,这样来说大家应该就更容易理解了。 数据库垂直分区
垂直拆分的优点: 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。 垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
-
水平分区 保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
数据库水平拆分
水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 水平拆分最好分库 。
水平拆分能够 支持非常大的数据量存储,应用端改造也少,但 分片事务难以解决 ,跨节点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度 ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
8.说说自己对于 MySQL 常见的两种存储引擎:MyISAM与InnoDB的理解?
InnoDB 引擎:InnoDB 引擎提供了对数据库 acid 事务的支持,并且还提供了行级锁和外键的约束,它的设计的目标就是处理大数据容量的数据库系统。MySQL 运行的时候,InnoDB 会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎是不支持全文搜索,同时启动也比较的慢,它是不会保存表的行数的,所以当进行 select count() from table 指令的时候,需要进行扫描全表。由于锁的粒度小,写操作是不会锁定全表的,所以在并发度较高的场景下使用会提升效率的。
MyIASM 引擎:MySQL 的默认引擎,但不提供事务的支持,也不支持行级锁和外键。因此当执行插入和更新语句时,即执行写操作的时候需要锁定这个表,所以会导致效率会降低。不过和 InnoDB 不同的是,MyIASM 引擎是保存了表的行数,于是当进行 select count() from table 语句时,可以直接的读取已经保存的值而不需要进行扫描全表。所以,如果表的读操作远远多于写操作时,并且不需要事务的支持的,可以将 MyIASM 作为数据库引擎的首选。
相关文章:

mysql的其他问题
1.MySQL数据库作发布系统的存储,一天五万条以上的增量,预计运维三年,怎么优化? a. 设计良好的数据库结构,允许部分数据冗余,尽量避免join查询,提高效率。 b. 选择合适的表字段数据类型和存储引擎…...

数据结构---复杂度(2)
1.斐波那契数列的时间复杂度问题 每一行分别是2^0---2^1---2^2-----2^3-------------------------------------------2^(n-2) 利用错位相减法,可以得到结果是,2^(n-1)-1,其实还是要减去右下角的灰色部分,我们可以拿简单的数字进行举例子&…...

【设计模式】设计原则和常见的23种经典设计模式
设计模式 1. 设计原则(记忆口诀:SOLID)【记忆口诀:单开里依接迪合(单开礼仪接地和)】 (1)单一职责原则(Single Responsibility Principle, SRP) ÿ…...
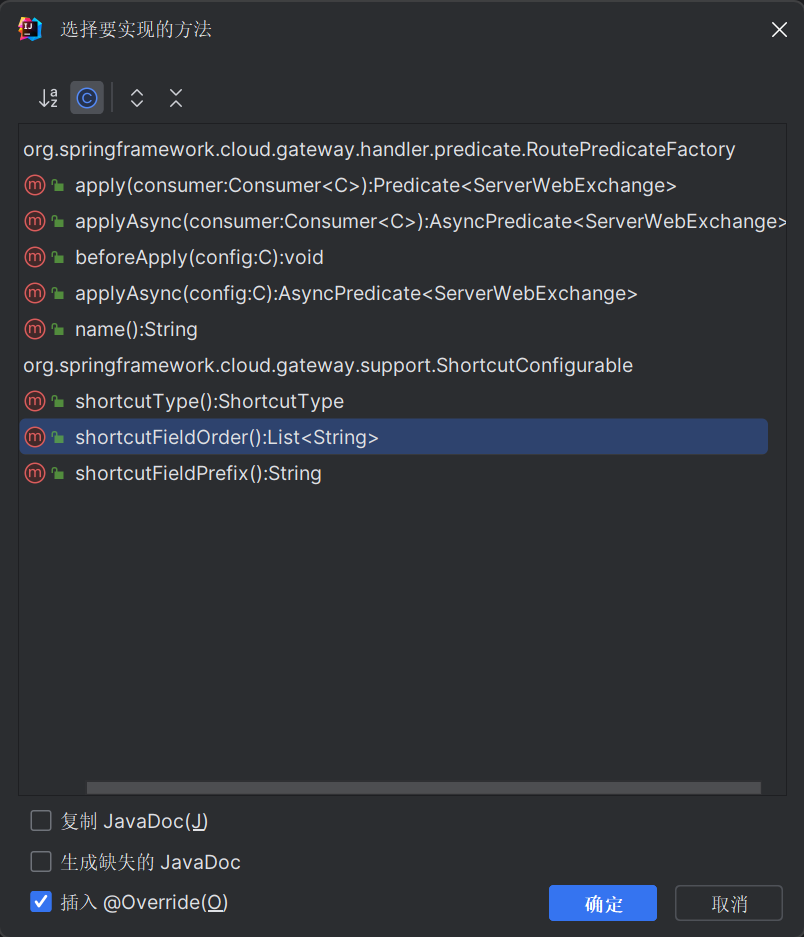
Spring Cloud Gateway自定义断言
问题:Spring Cloud Gateway自带的断言(Predicate)不满足业务怎么办?可以自定义断言! 先看Spring Cloud Gateway是如何实现断言的 Gateway中断言的整体架构如下: public abstract class AbstractRoutePred…...

智能测径仪在胶管行业的应用
关键字:胶管外径尺寸测量,胶管检测仪器,胶管外径检测,高温胶管外径检测,软硬胶管检测, 智能测径仪在家胶管行业中的应用主要体现在对胶管外径的精确测量和控制上。在胶管生产过程中,外径的大小直…...
vue自定义主题皮肤方案
方案一:CSS变量换肤(推荐) 利用css定义变量的方法,用var在全局定义颜色变量(需将变量提升到全局即伪类选择器 :root)然后利用js操作css变量,document.getElementsByTagName(‘body’)[0].style…...

iOS中使用schema协议调用APP和使用iframe打开APP的例子
大家好我是咕噜美乐蒂,很高兴又和大家见面了! 当调用自定义 URL scheme 或使用 iframe 打开应用程序时,可以采取以下详细步骤: 使用自定义 URL scheme 协议调用应用程序 1.首先,确认目标应用程序已经注册了自定义 U…...

2024.3.11
提示并输入一个字符串,统计该字符中大写、小写字母个数、数字个数、空格个数以及其他字符个数 #include <iostream> #include<string> using namespace std;int main() {cout << "please input a string:" << endl;string str;g…...

Web服务器需要警惕的一些安全隐患
Web服务器需要警惕的一些安全隐患有哪些,今天德迅云安全就带您来了解下。熟悉了解了就知道怎么规避风险。不过无论是什么漏洞,都体现着安全是一个整体的真理,考虑Web服务器的安全性,必须要考虑到与之相配合的操作系统。 1.物理路径…...
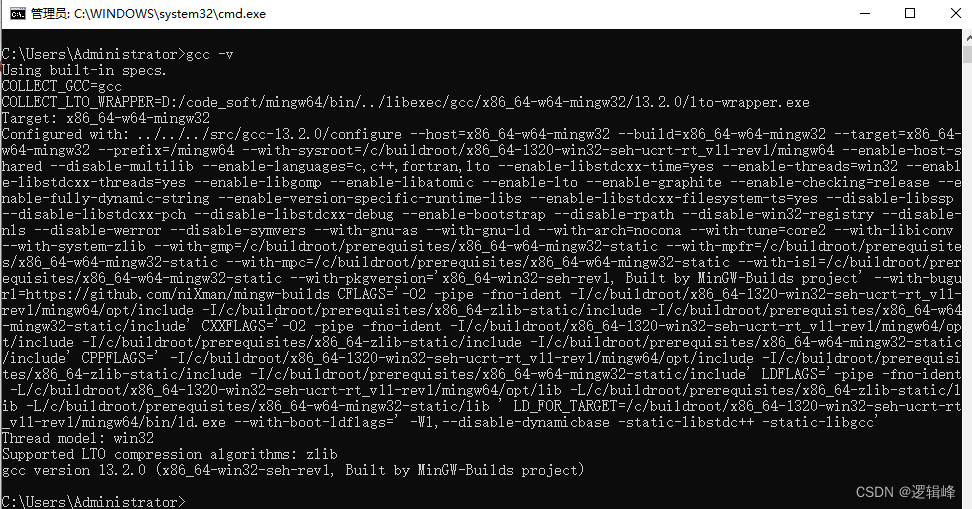
MinGW-w64的下载与安装
文章目录 1 下载2 安装3 配置环境变量4 验证 1 下载 官网地址:https://www.mingw-w64.org/github地址:https://github.com/niXman/mingw-builds-binaries/releases windows下载 跳转github下载 版本号选择:13.2.0是GCC的版本号;…...

docker使用笔记
查看本机上所有镜像 docker images打包项目(打包完成后自动载入镜像) The command docker build -t search-server . you provided is a standard way to build a Docker image. The -t flag tags the resulting image, and search-server is the tag …...

新规正式发布 | 百度深度参编《生成式人工智能服务安全基本要求》
2024年2月29日,全国网络安全标准化技术委员会( TC260 )正式发布《生成式人工智能服务安全基本要求》(以下简称《基本要求》)。《基本要求》规定了生成式人工智能服务在安全方面的基本要求,包括语料安全、模…...

2024年AI辅助研发的趋势和影响
摘要:随着人工智能技术的迅猛发展,2024年AI辅助研发正成为科技界和工业界的瞩目焦点。本文将探讨AI辅助研发在各个领域的应用和影响,并展望2024年AI辅助研发的趋势。 引言 随着人工智能技术的不断进步,AI辅助研发正逐渐渗透到各…...

2k_Day1:今天是设计模式的大白话1
大白话: 原则有一点很难做到,就是定义好的类,只能加不能改(开放-关闭原则) 1.工厂模式就是,比如你定了一个汽车接口,然后小车、中车、大车都继承这个接口,这时,定一个汽…...
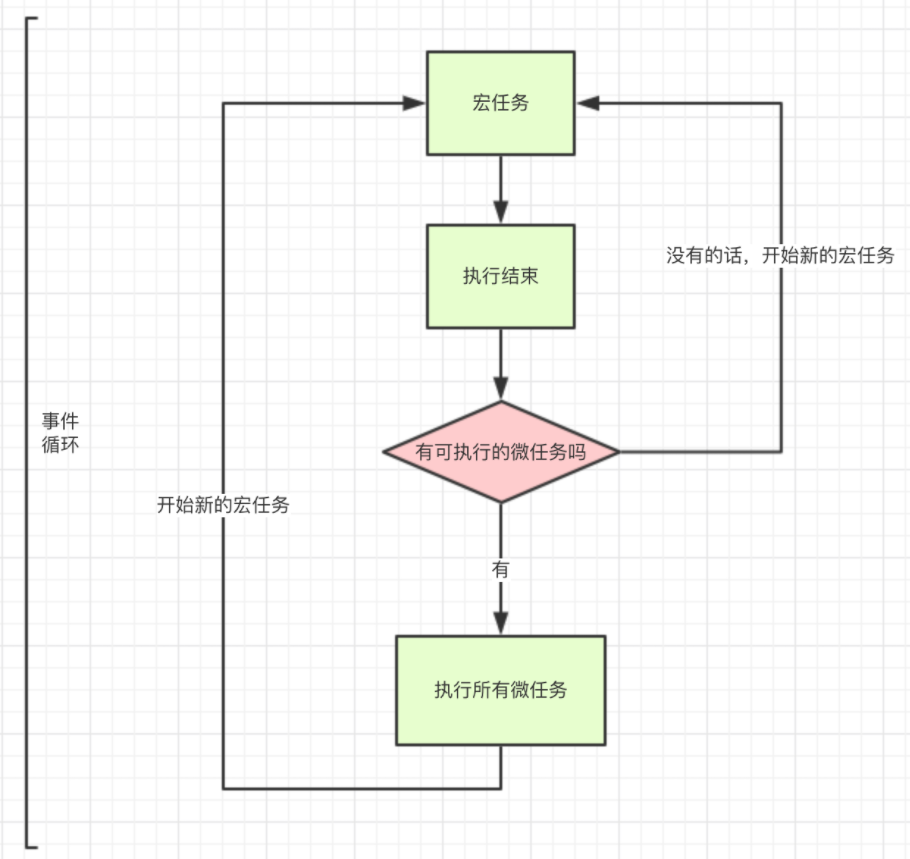
面试官:说说你对事件循环的理解
一、事件循环是什么 首先,JavaScript是一门单线程的语言,意味着同一时间内只能做一件事,但是这并不意味着单线程就是阻塞,而实现单线程非阻塞的方法就是事件循环 在JavaScript中,所有的任务都可以分为 同步任务&#…...

【SpringCloud微服务实战03】Nacos 注册中心
一、Nacos安装 官方文档安装Nacos教程:Nacos 快速开始 这里安装的是1.4.7版本,安装之后访问http://127.0.0.1:8848/nacos 管理界面如下:(用户名:nacos,密码:nacos) 二、Nacos服务注册和发现 1、在父工程中配置文件pom.xml 中添加spring-cloud-alilbaba的管理依赖:…...

FLatten Transformer_ Vision Transformer using Focused Linear Attention
paper: https://arxiv.org/abs/2308.00442 code: https://github.com/LeapLabTHU/FLatten-Transformer 摘要 当将transformer模型应用于视觉任务时,自注意的二次计算复杂度( n 2 n^2 n2)一直是一个持续存在的挑战。另一方面,线性注意通过精心设计的映射…...

STM32CubeMX学习笔记17--- FSMC
1.1 TFTLCD简介 TFT-LCD(thin film transistor-liquid crystal display)即薄膜晶体管液晶显示器。液晶显示屏的每一个像素上都设置有一个薄膜晶体管(TFT),每个像素都可以通过点脉冲直接控制,因而每个节点都…...
)
【MogDB】实战MogDB数据库适配Halo博客系统1.6版本(基于springframework+hibernate+HikariPool)
前言 前一篇文章说了MogDB适配Halo,【MogDB】将流行的博客系统Halo后端的数据库设置为MogDB,但是适配的是2.x版本,由于2.x版本已经引入了对postgresql的支持,而MogDB对于postgresql有很好的兼容性,因此适配起来很简单。但是由于halo2.x的版本…...

Python与FPGA——局部二值化
文章目录 前言一、局部二值化二、Python局部二值化三、FPGA局部二值化总结 前言 局部二值化较全局二值化难,我们将在此实现Python与FPGA的局部二值化处理。 一、局部二值化 局部二值化就是使用一个窗口,在图像上进行扫描,每扫出9个像素求平均…...

如何用LangGraph构建智能AI代理:从零开始掌握状态驱动的工作流
如何用LangGraph构建智能AI代理:从零开始掌握状态驱动的工作流 【免费下载链接】langgraph Build resilient language agents as graphs. 项目地址: https://gitcode.com/GitHub_Trending/la/langgraph 想要构建能够记住对话历史、处理复杂任务、并且可以随时…...

Wan2.2-I2V-A14B镜像免配置方案:单卡24G显存+120GB内存开箱即用部署指南
Wan2.2-I2V-A14B镜像免配置方案:单卡24G显存120GB内存开箱即用部署指南 1. 镜像概述与核心优势 Wan2.2-I2V-A14B是一款专为文生视频任务优化的私有部署镜像,针对RTX 4090D 24GB显存显卡进行了深度优化。这个镜像最大的特点就是"开箱即用"——…...

TP4552B低功耗 5V 常开的锂电池充放电解决方案
概述 TP4552B 是一款集成线性充电管理、同步升压转换、电池电量指示和多种保护功能的单芯片电源管理 SOC,为锂电池的充放电提供完整的单芯片电源解决方案。 TP4552B 内部集成了线性充电管理模块、同步升压放电管理模块、电量检测与 LED 指示模块、保护模块。TP4552B…...

750亿元!生命科学软件市场规模披露,技术创新驱动赛道加速成长
据恒州诚思调研统计,2025年全球生命科学软件市场规模约达750亿元。鉴于生命科学领域对数字化、智能化解决方案的需求日益增长,以及软件技术在数据处理、模型构建等方面的持续创新,预计未来该市场将持续保持平稳增长态势,到2032年市…...

LLM API延迟突增300ms?模型token吞吐骤降?——AI原生可观测性四象限诊断法,15分钟定位GPU显存泄漏+KV Cache膨胀根源
第一章:AI原生软件研发的可观测性实践 2026奇点智能技术大会(https://ml-summit.org) AI原生软件的研发范式正从根本上重塑可观测性需求——模型推理延迟、数据漂移、提示工程异常、向量嵌入分布偏移等新型信号,无法被传统APM或日志监控体系有效捕获。可…...

Phi-3-vision-128k-instruct实战:构建基于卷积神经网络的图像增强预处理流水线
Phi-3-vision-128k-instruct实战:构建基于卷积神经网络的图像增强预处理流水线 1. 引言:当AI视觉遇上图像质量问题 你有没有遇到过这样的情况?好不容易拍了一张照片,结果因为光线不足、镜头抖动或者设备限制,图像质量…...

接地电阻柜的多种款式!
接地电阻柜作为电力系统的关键保护设备,其多样化主要体现在分类维度丰富、适配场景广泛,可根据电压等级、保护对象、电阻阻值等灵活划分,满足不同工况需求。按电压等级可分为低压(0.22kV~0.66kV)、中压(6kV…...

Vue3 响应式系统是如何实现依赖收集的?通俗易懂的 Proxy 机制解析
Vue3响应式核心用Proxy替代Object.defineProperty,通过get/set拦截实现按需依赖收集与触发;读取时track记录effect,修改时trigger通知更新。Vue3 的响应式核心靠 Proxy 实现依赖收集,它不像 Vue2 那样遍历所有属性去 defineProper…...

hybrid实验
拓扑分接口SW1SW2SW3配置IP地址池配置DHCP自动获取IPPC1PC2PC3PC4PC5PC6END...

别再死记硬背!用Multisim仿真带你直观理解TTL反相器的工作原理
用Multisim仿真拆解TTL反相器:从波形透视晶体管开关艺术 当你第一次在教科书上看到TTL反相器的原理图时,那些密密麻麻的三极管、电阻和二极管是否让你望而生畏?传统学习方式要求我们死记硬背各个工作区间的电压阈值和电流路径,但这…...