生成式 AI:使用 Pytorch 通过 GAN 生成合成数据
导 读
生成对抗网络(GAN)因其生成图像的能力而变得非常受欢迎,而语言模型(例如 ChatGPT)在各个领域的使用也越来越多。这些 GAN 模型可以说是人工智能/机器学习目前主流的原因;
因为它向每个人(尤其是该领域之外的人)展示了机器学习所具有的巨大潜力。网上已经有很多关于 GAN 模型的资源,但其中大多数都集中在图像生成上。这些图像生成和语言模型需要复杂的空间或时间复杂性,这增加了额外的复杂性,使读者更难理解 GAN 的真正本质。
为了解决这个问题并使 GAN 更容易被更广泛的受众所接受,在本文的 GAN 模型示例中,我们将采取一种不同的、更实用的方法,重点关注生成数学函数的合成数据。
除了出于学习目的的简化之外,合成数据生成本身也变得越来越重要。数据不仅在业务决策中发挥着核心作用,而且数据驱动方法的用途也越来越多,比第一原理模型更受欢迎。
比如天气预报,第一个原理模型包括通过数值求解的纳维-斯托克斯方程的简化版本。然而,深度学习研究中进行天气预报的尝试在捕捉天气模式方面非常成功,并且一旦经过训练,运行起来会更容易、更快。
有需要的朋友关注公众号【小Z的科研日常】,获取更多内容。
01、生成模型与判别模型
在机器学习中,理解判别模型和生成模型之间的区别非常重要,因为它们是 GAN 的关键组成部分:
判别模型:
判别模型侧重于将数据分类为预定义的类别,例如将狗和猫的图像分类为各自的类别。这些模型不是捕获整个分布,而是辨别不同类别的边界。它们输出 P(y|x)(类别概率,给定输入数据的 y,x),即它们回答给定数据点属于哪个类别的问题。
生成模型:
生成模型旨在理解数据的底层结构。与区分类别的判别模型不同,生成模型学习数据的整个分布。这些模型输出 p(x|y),即它们回答了给定指定类生成该特定数据点的可能性有多大的问题。
这两个模型之间的相互作用构成了 GAN 的基础。
02、GAN—结构和组件
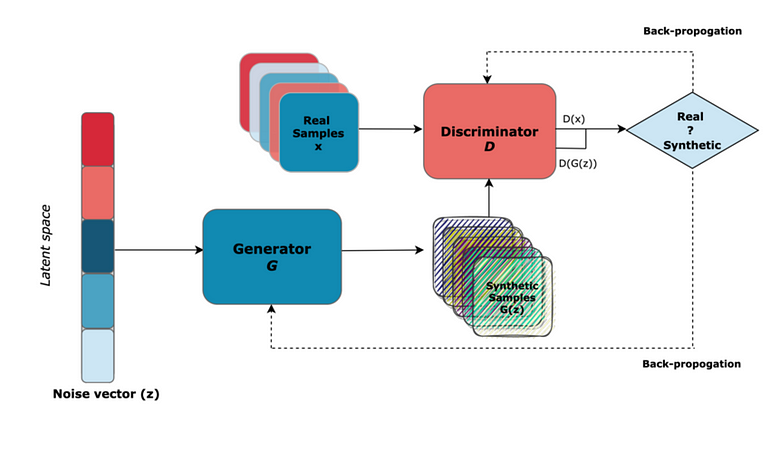
GAN 的关键组件包括噪声向量、生成器和鉴别器。
生成器:生成真实数据
为了生成合成数据,生成器使用随机噪声向量作为输入。为了欺骗鉴别器,生成器的目的是学习真实数据的分布并生成无法与真实数据区分开的合成数据。这里的一个问题是,对于相同的输入,它总是会产生相同的输出(想象一个图像生成器产生真实的图像,但总是相同的图像,这不是很有用)。随机噪声向量将随机性注入到过程中,从而提供生成的输出的多样性。
鉴别器:辨别真假
鉴别器就像一位受过训练来区分真实数据和虚假数据的艺术评论家。它的作用是仔细检查收到的数据并为工作真实性分配概率分数。如果合成数据看起来与真实数据相似,则鉴别器分配高概率,否则分配低概率分数。
对抗性训练:动态决斗
生成器努力学习生成鉴别器无法与真实数据区分开的合成数据。同时,鉴别器还学习并提高区分真实与合成的能力。这种动态的训练过程促使两个模型提高技能。这两个模型总是相互竞争(因此被称为对抗性),并且通过这种竞争,两个模型都在各自的角色中变得非常出色。
03、Pytorch实现GAN
在此示例中,我们在 pytorch 中实现了一个可以生成合成数据的模型。对于训练,我们有一个具有以下形状的 6 参数数据集(所有参数都绘制为参数 1 的函数)。每个参数都经过精心选择,具有显着不同的分布和形状,以增加数据集的复杂性并模仿真实世界的数据。

定义 GAN 模型组件(生成器和判别器)
import torch
from torch import nn
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.nn.init as init
import pandas as pd
import numpy as np
from torch.utils.data import Dataset# 定义单块功能
def FC_Layer_blockGen(input_dim, output_dim):single_block = nn.Sequential(nn.Linear(input_dim, output_dim),nn.ReLU())return single_block# 定义 GENERATOR
class Generator(nn.Module):def __init__(self, latent_dim, output_dim):super(Generator, self).__init__()self.model = nn.Sequential(nn.Linear(latent_dim, 256),nn.ReLU(),nn.Linear(256, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, output_dim),nn.Tanh() )def forward(self, x):return self.model(x)#定义单个判别块
def FC_Layer_BlockDisc(input_dim, output_dim):return nn.Sequential(nn.Linear(input_dim, output_dim),nn.ReLU(),nn.Dropout(0.4))# 定义判别器class Discriminator(nn.Module):def __init__(self, input_dim):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, 512),nn.ReLU(),nn.Dropout(0.4),nn.Linear(512, 512),nn.ReLU(),nn.Dropout(0.4),nn.Linear(512, 256),nn.ReLU(),nn.Dropout(0.4),nn.Linear(256, 1),nn.Sigmoid())def forward(self, x):return self.model(x)#定义训练参数
batch_size = 128
num_epochs = 500
lr = 0.0002
num_features = 6
latent_dim = 20# 模型初始化
generator = Generator(noise_dim, num_features)
discriminator = Discriminator(num_features)# 损失函数和优化器
criterion = nn.BCELoss()
gen_optimizer = torch.optim.Adam(generator.parameters(), lr=lr)
disc_optimizer = torch.optim.Adam(discriminator.parameters(), lr=lr)模型初始化和数据处理
file_path = 'SamplingData7.xlsx'
data = pd.read_excel(file_path)
X = data.values
X_normalized = torch.FloatTensor((X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) * 2 - 1)
real_data = X_normalizedclass MyDataset(Dataset):def __init__(self, dataframe):self.data = dataframe.values.astype(float)self.labels = dataframe.values.astype(float)def __len__(self):return len(self.data)def __getitem__(self, idx):sample = {'input': torch.tensor(self.data[idx]),'label': torch.tensor(self.labels[idx])}return sample# 创建数据集实例
dataset = MyDataset(data)# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)def weights_init(m):if isinstance(m, nn.Linear):init.xavier_uniform_(m.weight)if m.bias is not None:init.constant_(m.bias, 0)pretrained = False
if pretrained:pre_dict = torch.load('pretrained_model.pth')generator.load_state_dict(pre_dict['generator'])discriminator.load_state_dict(pre_dict['discriminator'])
else:# 应用权重初始化generator = generator.apply(weights_init)discriminator = discriminator.apply(weights_init)模型训练
model_save_freq = 100latent_dim =20
for epoch in range(num_epochs):for batch in dataloader:real_data_batch = batch['input']real_labels = torch.FloatTensor(np.random.uniform(0.9, 1.0, (batch_size, 1)))disc_optimizer.zero_grad()output_real = discriminator(real_data_batch)loss_real = criterion(output_real, real_labels)loss_real.backward()fake_labels = torch.FloatTensor(np.random.uniform(0, 0.1, (batch_size, 1)))noise = torch.FloatTensor(np.random.normal(0, 1, (batch_size, latent_dim)))generated_data = generator(noise)output_fake = discriminator(generated_data.detach())loss_fake = criterion(output_fake, fake_labels)loss_fake.backward()disc_optimizer.step()valid_labels = torch.FloatTensor(np.random.uniform(0.9, 1.0, (batch_size, 1)))gen_optimizer.zero_grad()output_g = discriminator(generated_data)loss_g = criterion(output_g, valid_labels)loss_g.backward()gen_optimizer.step()print(f"Epoch {epoch}, D Loss Real: {loss_real.item()}, D Loss Fake: {loss_fake.item()}, G Loss: {loss_g.item()}")模型评估和可视化结果
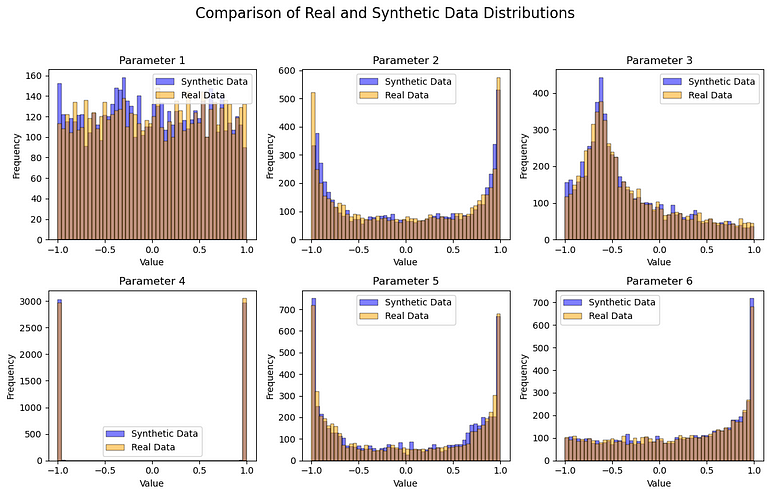
import seaborn as snssynthetic_data = generator(torch.FloatTensor(np.random.normal(0, 1, (real_data.shape[0], noise_dim))))# 绘制结果
fig, axs = plt.subplots(2, 3, figsize=(12, 8))
fig.suptitle('Real and Synthetic Data Distributions', fontsize=16)for i in range(2):for j in range(3):sns.histplot(synthetic_data[:, i * 3 + j].detach().numpy(), bins=50, alpha=0.5, label='Synthetic Data', ax=axs[i, j], color='blue')sns.histplot(real_data[:, i * 3 + j].numpy(), bins=50, alpha=0.5, label='Real Data', ax=axs[i, j], color='orange')axs[i, j].set_title(f'Parameter {i * 3 + j + 1}', fontsize=12)axs[i, j].set_xlabel('Value')axs[i, j].set_ylabel('Frequency')axs[i, j].legend()plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()#创建 2x3 网格的子绘图
fig, axs = plt.subplots(2, 3, figsize=(15, 10))
fig.suptitle('Comparison of Real and Synthetic Data', fontsize=16)# Define parameter names
param_names = ['Parameter 1', 'Parameter 2', 'Parameter 3', 'Parameter 4', 'Parameter 5', 'Parameter 6']# 各参数的散点图
for i in range(2):for j in range(3):param_index = i * 3 + jsns.scatterplot(real_data[:, 0].numpy(), real_data[:, param_index].numpy(), label='Real Data', alpha=0.5, ax=axs[i, j])sns.scatterplot(synthetic_data[:, 0].detach().numpy(), synthetic_data[:, param_index].detach().numpy(), label='Generated Data', alpha=0.5, ax=axs[i, j])axs[i, j].set_title(param_names[param_index], fontsize=12)axs[i, j].set_xlabel(f'Real Data - {param_names[param_index]}')axs[i, j].set_ylabel(f'Real Data - {param_names[param_index]}')axs[i, j].legend()plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()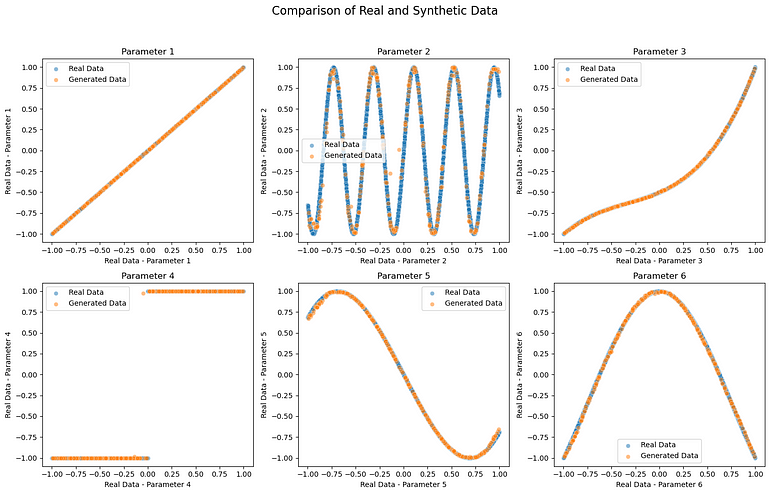
相关文章:
生成式 AI:使用 Pytorch 通过 GAN 生成合成数据
导 读 生成对抗网络(GAN)因其生成图像的能力而变得非常受欢迎,而语言模型(例如 ChatGPT)在各个领域的使用也越来越多。这些 GAN 模型可以说是人工智能/机器学习目前主流的原因; 因为它向每个人࿰…...
C#/WPF 清理任务栏托盘图标缓存
在我们开发Windows客户端程序时,往往会出现程序退出后,任务还保留之前程序的缓存图标。每打开关闭一次程序,图标会一直增加,导致托盘存放大量缓存图标。为了解决这个问题,我们可以通过下面的程序清理任务栏托盘图标缓存…...
java SSM科研管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM科研管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…...
C# OpenCvSharp 图片批量改名
目录 效果 项目 代码 下载 C# OpenCvSharp 图片批量改名 效果 项目 代码 using NLog; using OpenCvSharp; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Windows.Forms; namespace OpenCvSharp_Demo { publi…...
大数据开发-Hive介绍以及安装配置
文章目录 数据库和数据仓库的区别Hive安装配置Hive使用方式Hive日志配置 数据库和数据仓库的区别 数据库:传统的关系型数据库主要应用在基本的事务处理,比如交易,支持增删改查数据仓库:主要做一些复杂的分析操作,侧重…...
指针篇章-(4)+qsort函数的模拟
学习目录 ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————…...

接口测试实战--使用docker方案去部署jenkins并搭建接口自动化项目
一、搭建环境 1.几个概念 CI:持续集成 CD:持续交付 DevOps(development and operations):是一个框架,是一种方法论,并不是一套工具,包括一系列基本原则和实践,核心价值在于更快速的交付和响应市场变化。 jenkins:一个开源框架,需要操作什么流程,就下载什么插件 2…...

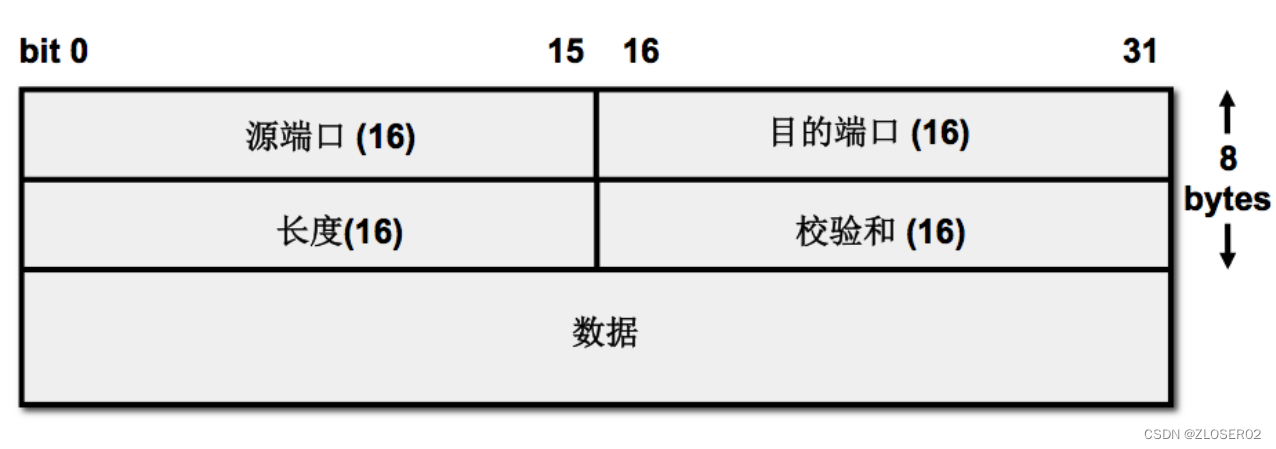
Day 8.TCP包头和HTTP
TCP包头 1.序号:发送端发送数据包的编号 2.确认号:已经确认接收到的数据的编号(只有当ACK为1时、确认号才有用); TCP为什么安全可靠 1.在通信前建立三次握手 SYP SYPACK ACK 2.在通信过程中通过序列号和确认号和…...

【机器学习】支持向量机 | 支持向量机理论全梳理 对偶问题转换,核方法,软间隔与过拟合
支持向量机走的路和之前介绍的模型不同 之前介绍的模型更趋向于进行函数的拟合,而支持向量机属于直接分割得到我们最后要求的内容 1 支持向量机SVM基本原理 当我们要用一条线(或平面、超平面)将不同类别的点分开时,我们希望这条…...

【JS】APIs:事件流、事件委托、其他事件、页面尺寸、日期对象与节点操作
1 事件流 捕获阶段:从父到子 冒泡阶段:从子到父 1.1 事件捕获 <body> <div class"fa"><div class"son"></div> </div> <script>const fadocument.querySelector(.fa);const sondocument.qu…...

定制红酒:如何根据客户需求调整红酒口感与风格
在云仓酒庄洒派,云仓酒庄洒派深知不同消费者对于红酒的口感与风格有着不同的喜好和需求。因此,云仓酒庄洒派根据消费者的具体要求,灵活调整红酒的口感与风格,以满足他们的期望。 首先,云仓酒庄洒派会与消费者进行深入的…...

利用excel批量修改图片文件名
今天同事提出需求要实现利用excel批量修改某文件夹下的图片重命名,衡量到各种条件,最后还是选择了vbs来实现。代码如下 代码 创建Excel对象 Set objExcel CreateObject("Excel.Application") objExcel.Visible False 隐藏Excel窗口 打开Ex…...
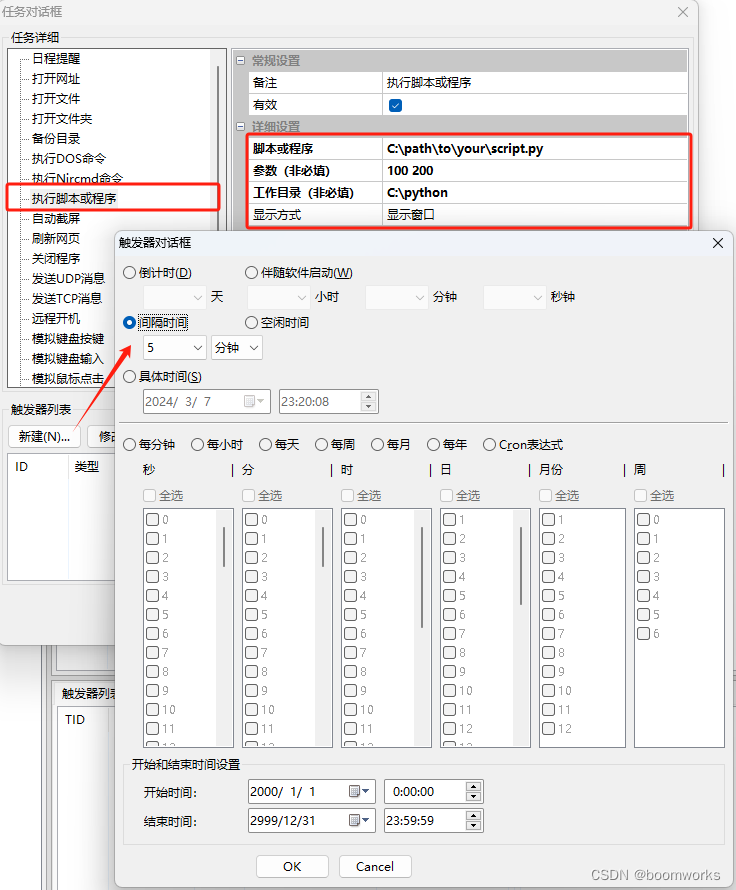
间隔5分钟执行1次Python脚本设置步骤 —— 定时执行专家
《定时执行专家》是一款制作精良、功能强大、毫秒精度、专业级的定时任务执行软件,用于在 Windows 系统上定时执行各种任务,包括执行脚本或程序。 下面是使用 "定时执行专家" 软件设置定时执行 Python 脚本的步骤: 步骤 1: 设置 P…...
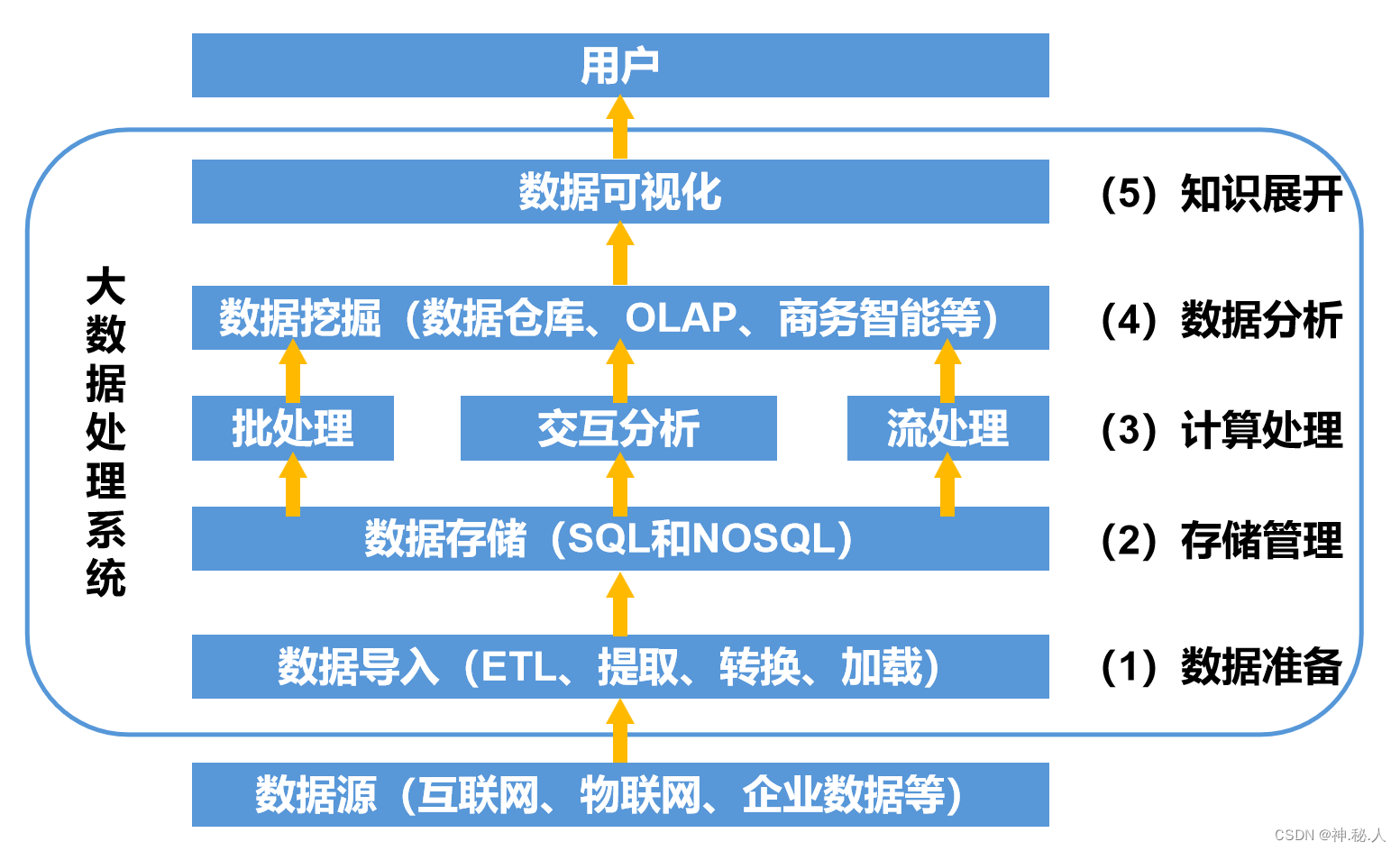
计算机网络基础【信息系统监理师】
计算机网络基础【信息系统监理师】 1、OSI七层参考模型2、TCP/IP协议3、网络拓扑结构分类4、网络传输介质分类5、网络交换技术6、网络存储技术7、网络规划技术8、综合布线系统8.1、综合布线工程内容8.1、隐蔽工程-金属线槽安装8.2、隐蔽工程-管道安装槽道与各种管线间的最小净距…...

网络安全风险评估:详尽百项清单要点
网络安全风险评估是识别、分析和评估组织信息系统、网络和资产中潜在风险和漏洞的系统过程。主要目标是评估各种网络威胁和漏洞的可能性和潜在影响,使组织能够确定优先顺序并实施有效的安全措施来减轻这些风险。该过程包括识别资产、评估威胁和漏洞、分析潜在影响以…...
不会用虚拟机装win10?超详细教程解决你安装中的所有问题!
前言:安装中有任何疑问,可以在评论区提问,博主身经百战会快速解答小伙伴们的疑问 BT、迅雷下载win10镜像(首先要下载win10的镜像):ed2k://|file|cn_windows_10_business_editions_version_1903_updated_sep…...

洛谷 素数环 Prime Ring Problem
题目描述 PDF 输入格式 输出格式 题意翻译 输入正整数 nn,把整数 1,2,\dots ,n1,2,…,n 组成一个环,使得相邻两个整数之和均为素数。输出时,从整数 11 开始逆时针排列。同一个环恰好输出一次。n\leq 16n≤16,保证一定有解。 多…...
【DPDK】基于dpdk实现用户态UDP网络协议栈
文章目录 一.背景及导言二.协议栈架构设计1. 数据包接收和发送引擎2. 协议解析3. 数据包处理逻辑 三.网络函数编写1.socket2.bind3.recvfrom4.sendto5.close 四.总结 一.背景及导言 在当今数字化的世界中,网络通信的高性能和低延迟对于许多应用至关重要。而用户态网…...

开源好用的所见即所得(WYSIWYG)编辑器:Editor.js
文章目录 特点基于区块干净的数据 界面与交互插件标题和文本图片列表Todo表格 使用安装创建编辑器实例配置工具本地化自定义样式 今天介绍一个开源好用的Web所见即所得(WYSIWYG)编辑器: Editor.js Editor.js 是一个基于 Web 的所见即所得富文本编辑器,它…...

sqlite 损坏 修复
步骤1 SQLite Download Page下载sqlite3 对应的系统版本 2.参考怎么恢复sqlite 数据库文件✅ - 有乐数据恢复网 sqlite3 dbname > .mode insert > .output dbdump.sql > .dump > .exit 恢复方法1 1.创建一个新的数据库 例如名字叫 test.db 2sqlite3 test.…...
_kaic)
weixin291基于微信小程序的家政服务预约系统的设计与实现+php(文档+源码)_kaic
第4章 系统详细实现 4.1登录功能模块的界面实现 在系统调试运行后,可以进入本界面&am…...

5步快速上手AntiDupl:彻底告别重复图片困扰的智能解决方案
5步快速上手AntiDupl:彻底告别重复图片困扰的智能解决方案 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾经花费数小时在数千张照片中寻找重复文件…...

NSE-每日交易数据全量分析报告-包含股票债券期权等多类型金融工具-2022年交易记录-支持市场分析与算法训练
NSE每日交易数据全量分析报告 引言与背景 NSE(印度国家证券交易所)作为印度最大的证券交易所之一,其每日交易数据(Bhavcopy)包含了市场上所有交易品种的详细信息,对于金融分析、算法训练和投资决策具有极高…...

fre:ac音频转换器:你的数字音乐整理终极方案
fre:ac音频转换器:你的数字音乐整理终极方案 【免费下载链接】freac The fre:ac audio converter project 项目地址: https://gitcode.com/gh_mirrors/fr/freac 你是否曾为杂乱无章的音乐文件而烦恼?或是面对不同设备间的格式兼容问题束手无策&am…...

Bilibili API评论接口实战指南:高效获取与处理用户互动数据
Bilibili API评论接口实战指南:高效获取与处理用户互动数据 【免费下载链接】bilibili-api 哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api 项目地址: https://gitcode.com/gh…...

【Python学习】递归算法
目录 一、递归的核心概念 1.1 什么是递归? 1.2 递归的两个核心要素(必记) 二、Python递归函数的基本语法 2.1 语法结构 2.2 最简单的递归示例:求1到n的和 三、Python递归的经典实例(必练) 实例1&…...
)
SGLang实战:如何用Python DSL编写带分支的LLM生成任务(附完整代码)
SGLang实战:如何用Python DSL编写带分支的LLM生成任务(附完整代码) 在构建复杂AI应用时,开发者常面临一个核心矛盾:既希望利用大语言模型(LLM)的生成能力,又需要精确控制生成流程。传…...
,收藏这一篇就够了!)
Anthropic Harness工程入门基础教程(非常详细),收藏这一篇就够了!
用 ChatGPT 和用 Claude Code,是两种完全不同的体感。 前者就是聊天,后者是在聊天的基础上给用户干活。 像 Claude Code 这样的 Coding Agent 打开终端,需求丢进去,它开始读文件、搜索代码、执行命令、跑测试、提 PR,…...

快速解密Wii U NUS文件:CDecrypt工具的终极解决方案
快速解密Wii U NUS文件:CDecrypt工具的终极解决方案 【免费下载链接】cdecrypt Decrypt Wii U NUS content — Forked from: https://code.google.com/archive/p/cdecrypt/ 项目地址: https://gitcode.com/gh_mirrors/cd/cdecrypt 对于Wii U游戏开发者和模组…...

哔哩下载姬DownKyi:三步掌握B站视频下载的终极免费工具
哔哩下载姬DownKyi:三步掌握B站视频下载的终极免费工具 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...