大数据开发-Hive介绍以及安装配置
文章目录
- 数据库和数据仓库的区别
- Hive安装配置
- Hive使用方式
- Hive日志配置
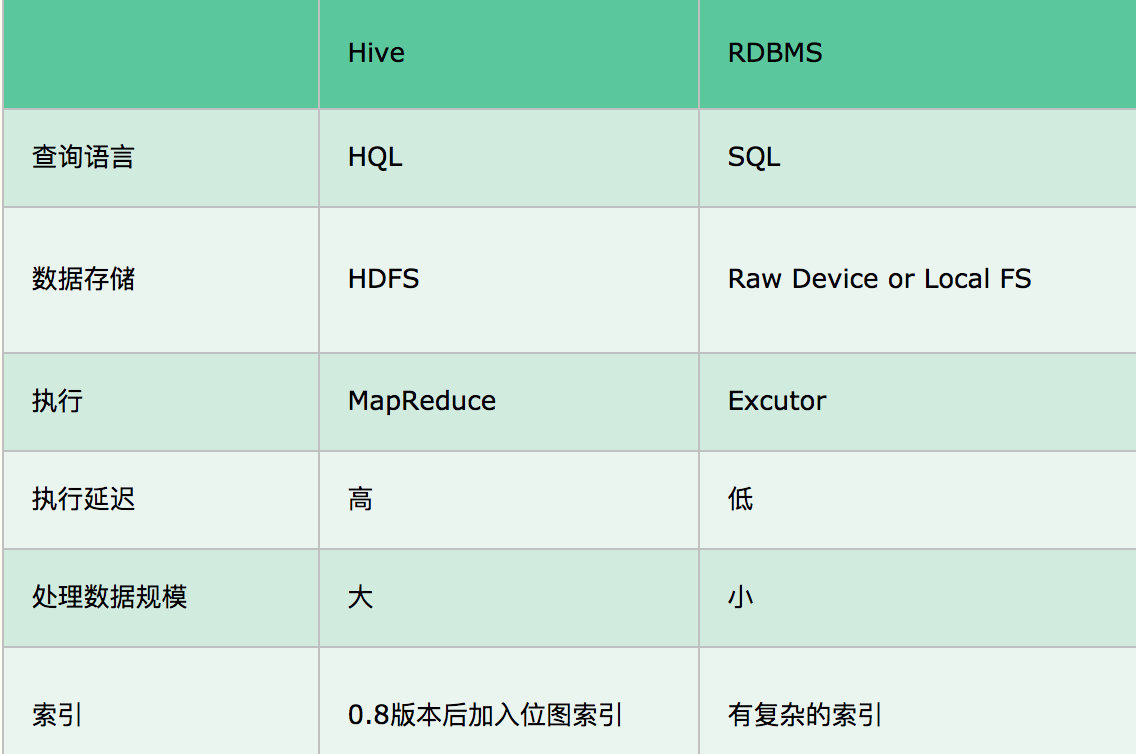
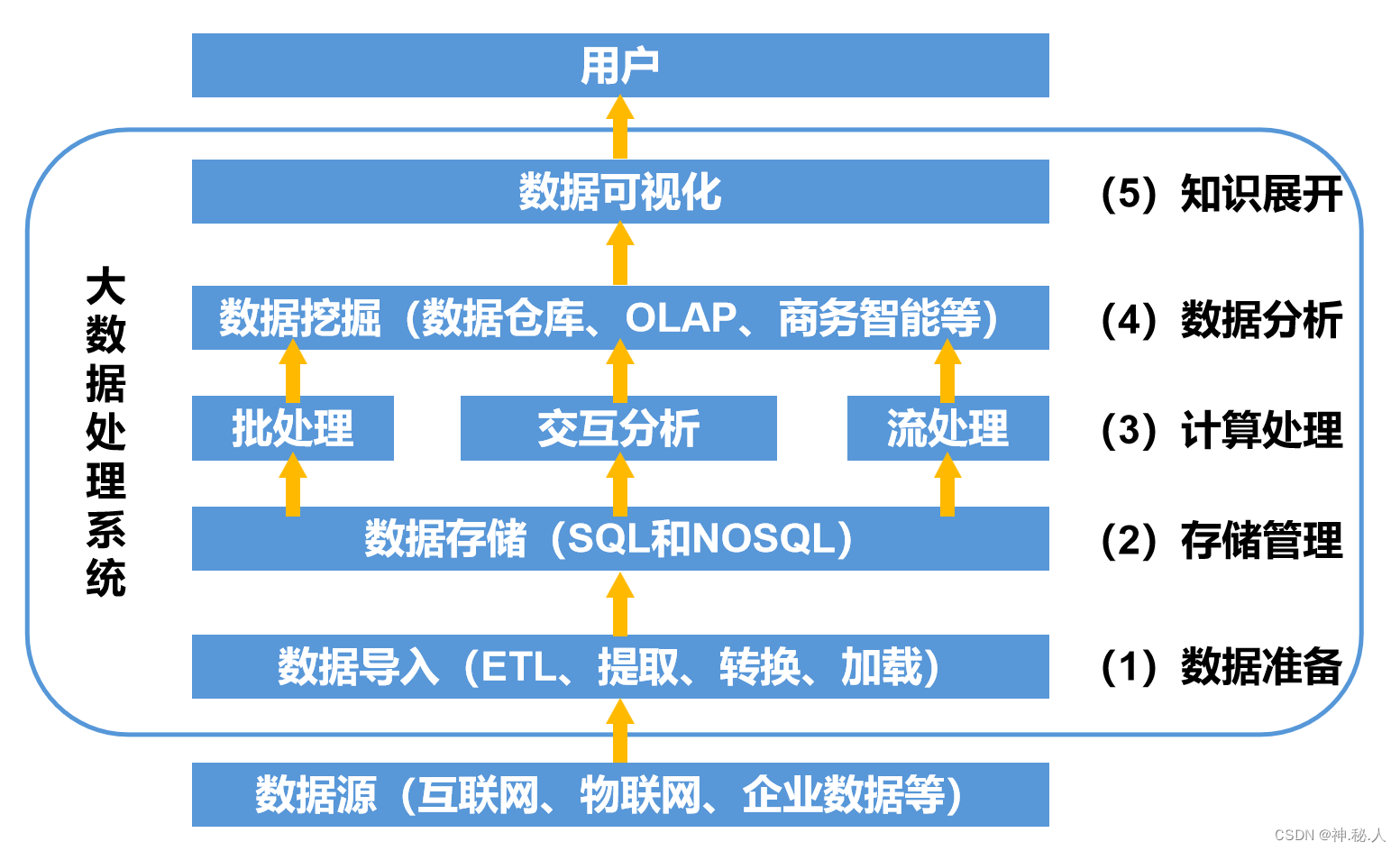
数据库和数据仓库的区别
- 数据库:传统的关系型数据库主要应用在基本的事务处理,比如交易,支持增删改查
- 数据仓库:主要做一些复杂的分析操作,侧重决策支持,相对于数据库而言,数据仓库分析的数据规模要大的多,只支持查询
- 本质区别是OLTP(On-Line-Transaction Processing)和OLAP(On-Line-Analytical Processing)的区别,OLTP称为联机事务处理,也是面向交易的处理系统,它是针对具体的业务在数据库联机的日常操作,通常对少数记录进行查询、修改,用户关心的是响应;时间,数据的安全性,完整性等问题;OLAP是分析性处理,称为联机分析处理,一般针对某些主题历史数据进行分析,支持管理决策
Hive安装配置
# 解压完之后
[root@hadoop04 conf]# mv hive-env.sh.template hive-env.sh
[root@hadoop04 conf]# mv hive-default.xml.template hive-site.xml#修改配置
[root@hadoop04 conf]# vim hive-env.sh
export JAVA_HOME=/home/soft/jdk1.8
export HIVE_HOME=/home/soft/apache-hive-3.1.2
export HADOOP_HOME=/home/soft/hadoop-3.2.0# 根据name修改对应配置
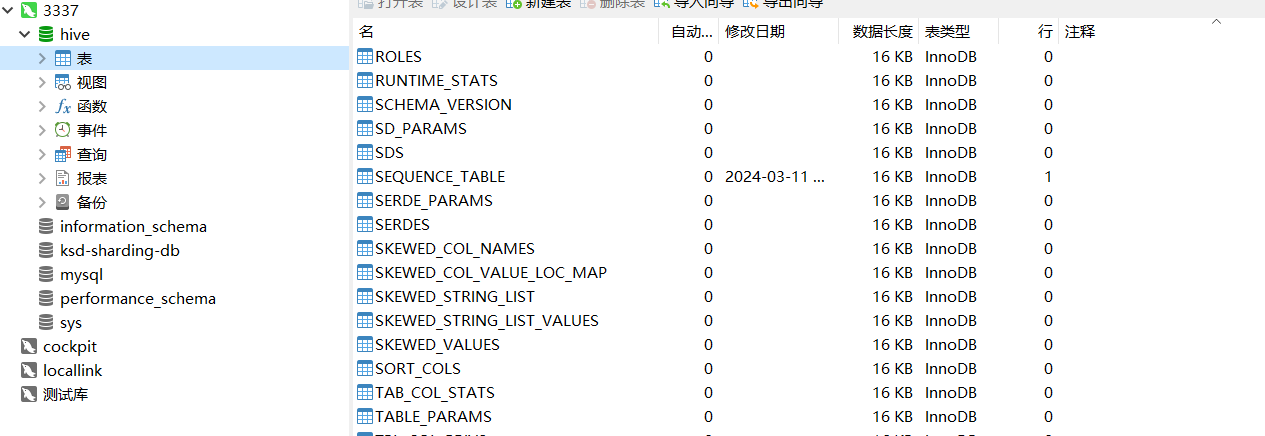
[root@hadoop04 conf]# vim hive-site.xml </property><property><name>hive.exec.local.scratchdir</name><value>/home/hive_repo/scratchdir</value><description>Local scratch space for Hive jobs</description></property><property><name>hive.downloaded.resources.dir</name><value>/home/hive_repo/resources</value><description>Temporary local directory for added resources in the remote file system.</description></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://ip:port/hive?serverTimezone=Asia/Shanghai</value><description>JDBC connect string for a JDBC metastore.To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>Username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property># 初始化数据仓库[root@hadoop04 apache-hive-3.1.2]# bin/schematool -dbType mysql -initSchema# 看到有下面那些表就算完成啦
Hive使用方式
命令行方式
# 连接hive
[root@hadoop04 apache-hive-3.1.2]# bin/hive
which: no hbase in (/home/soft/jdk1.8/bin:/home/soft/hadoop-3.2.0/bin:/home/soft/hadoop-3.2.0/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/soft/apache-hive-3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/soft/hadoop-3.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 505baa88-4bd1-4f00-9345-448ae17ab151Logging initialized using configuration in jar:file:/home/soft/apache-hive-3.1.2/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Hive Session ID = dfffb77e-23d3-4c56-9457-32f30b5f4e3c# 查询
hive> show tables;
OK
Time taken: 1.019 seconds
# 建表
hive> create table t1(id int,name string);
OK
Time taken: 1.875 seconds
hive> show tables;
OK
t1
Time taken: 0.388 seconds, Fetched: 1 row(s)
# 插入数据 会进行mapreduce
hive> insert into t1(id,name)values(1,"test");
Query ID = root_20240311140339_1e1450d1-2227-4b3d-bb10-e21f0016903b
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:set mapreduce.job.reduces=<number>
Starting Job = job_1710135432246_0001, Tracking URL = http://hadoop01:8088/proxy/application_1710135432246_0001/
Kill Command = /home/soft/hadoop-3.2.0/bin/mapred job -kill job_1710135432246_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2024-03-11 14:04:00,036 Stage-1 map = 0%, reduce = 0%
2024-03-11 14:04:08,605 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.66 sec
2024-03-11 14:04:16,949 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.69 sec
MapReduce Total cumulative CPU time: 4 seconds 690 msec
Ended Job = job_1710135432246_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop01:9000/user/hive/warehouse/t1/.hive-staging_hive_2024-03-11_14-03-39_724_266361142260875320-1/-ext-10000
Loading data to table default.t1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.69 sec HDFS Read: 15158 HDFS Write: 236 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 690 msec
OK
Time taken: 42.328 seconds
hive> select * from t1;
OK
1 test
Time taken: 0.726 seconds, Fetched: 1 row(s)
hive> drop table t1;
OK
Time taken: 1.368 seconds
# 退出
hive> quit;Hive日志配置
运行时日志
[root@hadoop04 conf]# mv hive-log4j2.properties.template hive-log4j2.properties
[root@hadoop04 conf]# vim hive-log4j2.properties
# list of properties
property.hive.log.level = INFO
property.hive.root.logger = DRFA
property.hive.log.dir = /home/hive_repo/log
property.hive.log.file = hive.log
property.hive.perflogger.log.level = INFO任务执行日志
[root@hadoop04 conf]# mv hive-exec-log4j2.properties.template hive-exec-log4j2.properties
[root@hadoop04 conf]# vim hive-exec-log4j2.properties status = INFO
name = HiveExecLog4j2
packages = org.apache.hadoop.hive.ql.log# list of properties
property.hive.log.level = INFO
property.hive.root.logger = FA
property.hive.query.id = hadoop
property.hive.log.dir = /home/hive_repo/log
property.hive.log.file = ${sys:hive.query.id}.loglevel = INFO
property.hive.root.logger = FA
property.hive.query.id = hadoop
property.hive.log.dir = /home/hive_repo/log
property.hive.log.file = ${sys:hive.query.id}.log
相关文章:
大数据开发-Hive介绍以及安装配置
文章目录 数据库和数据仓库的区别Hive安装配置Hive使用方式Hive日志配置 数据库和数据仓库的区别 数据库:传统的关系型数据库主要应用在基本的事务处理,比如交易,支持增删改查数据仓库:主要做一些复杂的分析操作,侧重…...
指针篇章-(4)+qsort函数的模拟
学习目录 ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————…...

接口测试实战--使用docker方案去部署jenkins并搭建接口自动化项目
一、搭建环境 1.几个概念 CI:持续集成 CD:持续交付 DevOps(development and operations):是一个框架,是一种方法论,并不是一套工具,包括一系列基本原则和实践,核心价值在于更快速的交付和响应市场变化。 jenkins:一个开源框架,需要操作什么流程,就下载什么插件 2…...

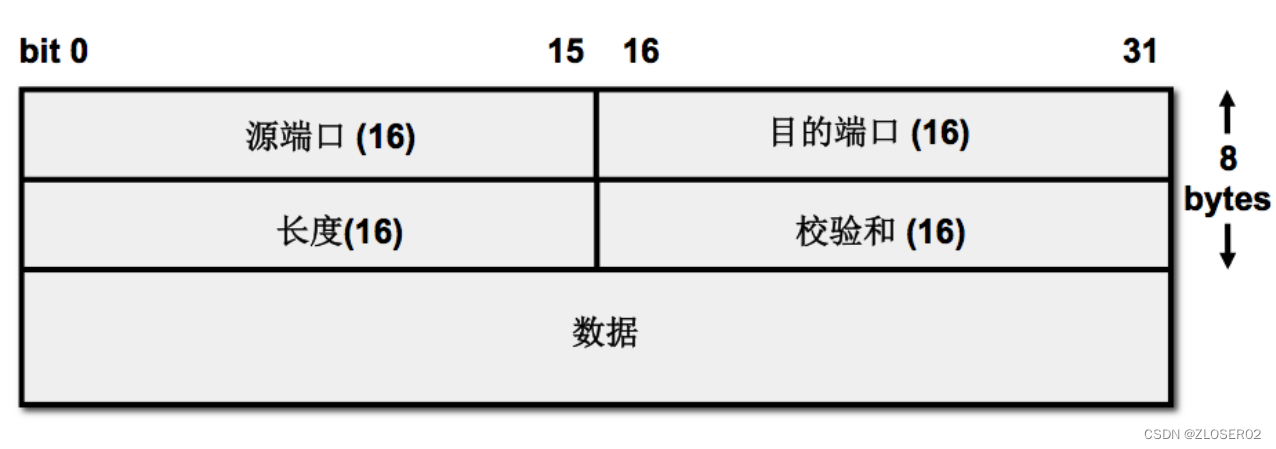
Day 8.TCP包头和HTTP
TCP包头 1.序号:发送端发送数据包的编号 2.确认号:已经确认接收到的数据的编号(只有当ACK为1时、确认号才有用); TCP为什么安全可靠 1.在通信前建立三次握手 SYP SYPACK ACK 2.在通信过程中通过序列号和确认号和…...

【机器学习】支持向量机 | 支持向量机理论全梳理 对偶问题转换,核方法,软间隔与过拟合
支持向量机走的路和之前介绍的模型不同 之前介绍的模型更趋向于进行函数的拟合,而支持向量机属于直接分割得到我们最后要求的内容 1 支持向量机SVM基本原理 当我们要用一条线(或平面、超平面)将不同类别的点分开时,我们希望这条…...

【JS】APIs:事件流、事件委托、其他事件、页面尺寸、日期对象与节点操作
1 事件流 捕获阶段:从父到子 冒泡阶段:从子到父 1.1 事件捕获 <body> <div class"fa"><div class"son"></div> </div> <script>const fadocument.querySelector(.fa);const sondocument.qu…...

定制红酒:如何根据客户需求调整红酒口感与风格
在云仓酒庄洒派,云仓酒庄洒派深知不同消费者对于红酒的口感与风格有着不同的喜好和需求。因此,云仓酒庄洒派根据消费者的具体要求,灵活调整红酒的口感与风格,以满足他们的期望。 首先,云仓酒庄洒派会与消费者进行深入的…...

利用excel批量修改图片文件名
今天同事提出需求要实现利用excel批量修改某文件夹下的图片重命名,衡量到各种条件,最后还是选择了vbs来实现。代码如下 代码 创建Excel对象 Set objExcel CreateObject("Excel.Application") objExcel.Visible False 隐藏Excel窗口 打开Ex…...
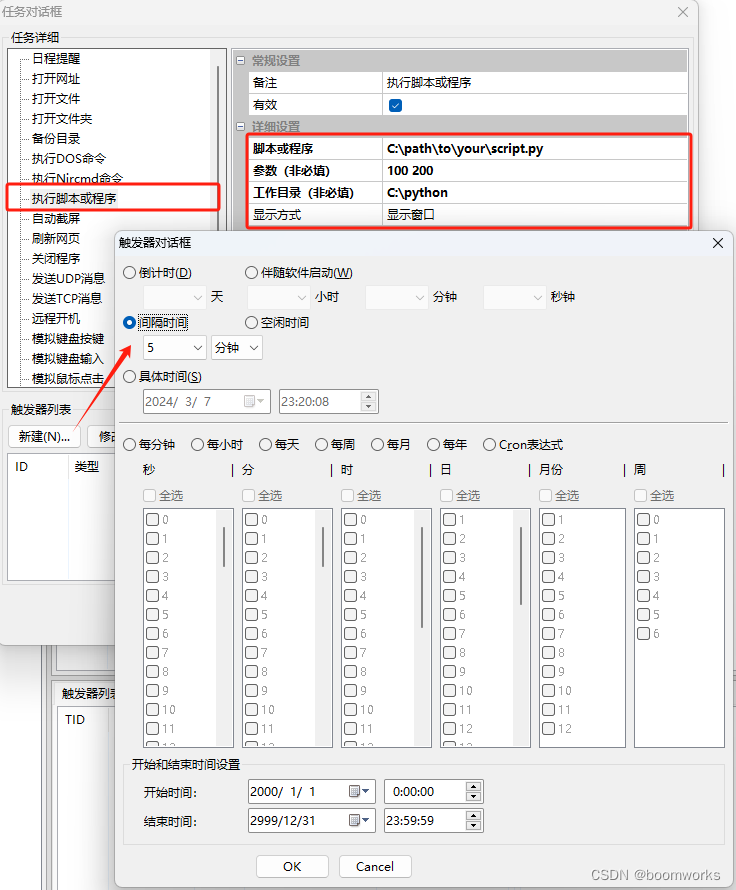
间隔5分钟执行1次Python脚本设置步骤 —— 定时执行专家
《定时执行专家》是一款制作精良、功能强大、毫秒精度、专业级的定时任务执行软件,用于在 Windows 系统上定时执行各种任务,包括执行脚本或程序。 下面是使用 "定时执行专家" 软件设置定时执行 Python 脚本的步骤: 步骤 1: 设置 P…...
计算机网络基础【信息系统监理师】
计算机网络基础【信息系统监理师】 1、OSI七层参考模型2、TCP/IP协议3、网络拓扑结构分类4、网络传输介质分类5、网络交换技术6、网络存储技术7、网络规划技术8、综合布线系统8.1、综合布线工程内容8.1、隐蔽工程-金属线槽安装8.2、隐蔽工程-管道安装槽道与各种管线间的最小净距…...

网络安全风险评估:详尽百项清单要点
网络安全风险评估是识别、分析和评估组织信息系统、网络和资产中潜在风险和漏洞的系统过程。主要目标是评估各种网络威胁和漏洞的可能性和潜在影响,使组织能够确定优先顺序并实施有效的安全措施来减轻这些风险。该过程包括识别资产、评估威胁和漏洞、分析潜在影响以…...
不会用虚拟机装win10?超详细教程解决你安装中的所有问题!
前言:安装中有任何疑问,可以在评论区提问,博主身经百战会快速解答小伙伴们的疑问 BT、迅雷下载win10镜像(首先要下载win10的镜像):ed2k://|file|cn_windows_10_business_editions_version_1903_updated_sep…...

洛谷 素数环 Prime Ring Problem
题目描述 PDF 输入格式 输出格式 题意翻译 输入正整数 nn,把整数 1,2,\dots ,n1,2,…,n 组成一个环,使得相邻两个整数之和均为素数。输出时,从整数 11 开始逆时针排列。同一个环恰好输出一次。n\leq 16n≤16,保证一定有解。 多…...
【DPDK】基于dpdk实现用户态UDP网络协议栈
文章目录 一.背景及导言二.协议栈架构设计1. 数据包接收和发送引擎2. 协议解析3. 数据包处理逻辑 三.网络函数编写1.socket2.bind3.recvfrom4.sendto5.close 四.总结 一.背景及导言 在当今数字化的世界中,网络通信的高性能和低延迟对于许多应用至关重要。而用户态网…...

开源好用的所见即所得(WYSIWYG)编辑器:Editor.js
文章目录 特点基于区块干净的数据 界面与交互插件标题和文本图片列表Todo表格 使用安装创建编辑器实例配置工具本地化自定义样式 今天介绍一个开源好用的Web所见即所得(WYSIWYG)编辑器: Editor.js Editor.js 是一个基于 Web 的所见即所得富文本编辑器,它…...

sqlite 损坏 修复
步骤1 SQLite Download Page下载sqlite3 对应的系统版本 2.参考怎么恢复sqlite 数据库文件✅ - 有乐数据恢复网 sqlite3 dbname > .mode insert > .output dbdump.sql > .dump > .exit 恢复方法1 1.创建一个新的数据库 例如名字叫 test.db 2sqlite3 test.…...
初学Vue——Vue路由
0 什么是Vue路由 类似于Html中的超链接(<a>)一样,可以跳转页面的一种方式。 前端路由:URL中hash(#号之后的内容)与组件之间的对应关系,如下图: 当我们点击左侧导航栏时,浏览器的地址栏会发生变化,路…...
如何使用宝塔面板搭建Discuz并结合cpolar实现远程访问本地论坛
文章目录 前言1.安装基础环境2.一键部署Discuz3.安装cpolar工具4.配置域名访问Discuz5.固定域名公网地址6.配置Discuz论坛 前言 Crossday Discuz! Board(以下简称 Discuz!)是一套通用的社区论坛软件系统,用户可以在不需要任何编程的基础上&a…...

llc的基波分析法
对于我们之前分析的 LLC等效谐振电路的分析,其实我们发现分析的并不是完整的方波输入,而是用正弦波来分的 那么为何用基波来分析呢,因为对于方波而言,根据傅里叶级数它是可以分解成基波、 1次、3次、5次.......等各种奇次谐波的入…...
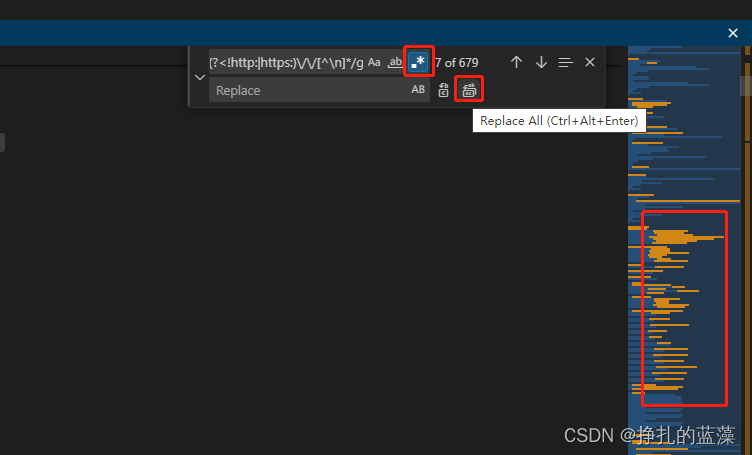
一键清除JavaScript代码中的注释:使用正则表达式实现
这个正则表达式可以有效地匹配 JavaScript 代码中的各种注释,并且跳过了以 http: 或 https: 开头的链接。 /\/\*[\s\S]*?\*\/|\/\/[^\n]*|<!--[\s\S]*?-->|(?<!http:|https:)\/\/[^\n]*/gvscode 实战,ctrlF 调出查找替换工具,点…...
)
实验室安全必备:5种危险有机试剂的淬灭操作指南(含实操视频)
实验室安全必修课:5种高危有机试剂的精准淬灭实战手册 推开有机化学实验室的门,扑面而来的除了试剂特有的气味,还有潜藏在每个操作步骤中的安全挑战。氢化锂铝遇水瞬间释放的氢气、硼氢化钠与酸接触时产生的自燃性硼烷、三光气分解时可能生成…...

x64dbg实战指南:从零开始掌握程序调试与分析技巧
1. x64dbg调试器入门:为什么选择它? 第一次接触逆向工程的朋友,往往会被各种调试工具搞得眼花缭乱。我刚开始学习时也试过OllyDbg、WinDbg这些老牌工具,但最终发现x64dbg才是最适合新手的"瑞士军刀"。它最大的优势就是同…...

燃料电池热管理控制,接受定制,单循环,双循环定制,效率
代码逻辑分析 数据构建:由于没有原始数据,代码中通过分段函数模拟了图中的趋势: 0-600s:保持为 0。 600-700s:出现一个向下的尖峰(约 -0.4),随后迅速反弹至 0.2。 700-1100s…...
)
从Prompt Engineering到Agent Engineering:2026奇点大会定义的AI原生研发能力图谱(含6级评估矩阵)
第一章:AI原生软件研发:2026奇点智能技术大会核心议题 2026奇点智能技术大会(https://ml-summit.org) AI原生软件研发已从概念验证迈入工程化落地深水区。2026奇点智能技术大会将AI原生软件定义为“以大模型为运行时、以提示与工具调用为基本指令单元、…...

CLIP-GmP-ViT-L-14部署教程:Airflow调度定时批量图文匹配任务流
CLIP-GmP-ViT-L-14部署教程:Airflow调度定时批量图文匹配任务流 1. 项目概述 CLIP-GmP-ViT-L-14是一个经过几何参数化(GmP)微调的CLIP模型,在ImageNet和ObjectNet数据集上能达到约90%的准确率。这个强大的视觉语言模型可以帮助我们实现图片和文本之间的…...
)
华为ENSP模拟器实战:手把手教你从零搭建一个可用的企业级无线网络(AC+AP+交换机)
华为ENSP模拟器实战:从零构建企业级无线网络的完整指南 1. 环境准备与基础概念 在开始构建企业级无线网络之前,我们需要先理解几个核心组件的作用。华为的无线控制器(AC)负责集中管理所有接入点(AP),而交换机则负责连接这些设备并提供必要的V…...

Qwen3-TTS-12Hz-1.7B-CustomVoice部署教程:NVIDIA Triton推理服务器集成方案
Qwen3-TTS-12Hz-1.7B-CustomVoice部署教程:NVIDIA Triton推理服务器集成方案 1. 为什么选择Qwen3-TTS-12Hz-1.7B-CustomVoice 你是否遇到过这样的问题:语音合成服务在多语言场景下表现不稳定,切换语种时音色突变、情感生硬;流式响…...

2025届毕业生推荐的五大降重复率工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,人工智能内容生成技术被广泛应用,此时,AIGC检测系统…...
伪)
《数论探微:进阶版》(Arithmetic Tales: Advanced Edition)伪
一、核心问题及解决方案(按踩坑频率排序) 问题 1:误删他人持有锁——最基础也最易犯的漏洞 成因:释放锁时未做身份校验,直接执行 DEL 命令删除键。典型场景:服务 A 持有锁后,业务逻辑耗时超过…...

DRM框架深度解析:从fbdev到atomic commit的显存绑定全流程
DRM框架深度解析:从fbdev到atomic commit的显存绑定全流程 在Linux图形驱动开发领域,DRM(Direct Rendering Manager)框架作为现代显示子系统的核心,其显存管理机制直接影响图形性能与稳定性。本文将系统剖析DRM框架中显…...