RNN实战
本主要是利用RNN做多分类任务,在熟悉RNN训练的过程中,我们可以理解
1)超参数 batch_size和pad_size对训练过程的影响。
2)文本处理过程中是如何将文本的文字表示转化为向量表示
3)RNN梯度消失和序列长度的关系
4)利用pytorch如何训练一个网络模型以及保存和加载
5)理解多分类任务中的混淆矩阵
数据集HUCNews中抽取了20万条新闻标题,文本长度在20到30之间。一共10个类别,每类2万条。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集划分
| 数据集 | 数据量 |
|---|---|
| 训练集 | 18万 |
| 验证集 | 1万 |
| 测试集 | 1万 |
重要参数如下
self.dropout = 0.3 # 随机失活
self.num_epochs = 7 # epoch数
self.batch_size = 256 # batch size
self.pad_size = 7 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.hidden_size = 128 # rnn隐藏层
self.num_layers = 2 # rnn层数,注意RNN中的层数必须大于1,dropout才会生效
RNN.py 模型文件,主要是配置文件和RNN网络模型定义。
# coding: UTF-8
import torch
import torch.nn as nn
import numpy as npclass Config(object):"""配置参数"""def __init__(self, dataset, embedding):self.model_name = 'RNN'self.train_path = dataset + '/data/train.txt' # 训练集self.dev_path = dataset + '/data/dev.txt' # 验证集self.test_path = dataset + '/data/test.txt' # 测试集self.class_list = [x.strip() for x in open(dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单self.vocab_path = dataset + '/data/vocab.pkl' # 词表self.save_path = dataset + '/saved_dict/' + self.model_name + 'ckpt' # 模型训练结果self.log_path = dataset + '/log/' + self.model_nameself.embedding_pretrained = torch.tensor(np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32')) \if embedding != 'random' else None # 预训练词向量self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备self.dropout = 0.3 # 随机失活self.require_improvement = 10000 # 若超过10000batch效果还没提升,则提前结束训练self.num_classes = len(self.class_list) # 类别数self.n_vocab = 0 # 词表大小,在运行时赋值self.num_epochs = 7 # epoch数self.batch_size = 256 # batch sizeself.pad_size = 7 # 每句话处理成的长度(短填长切)self.learning_rate = 1e-3 # 学习率self.embed = self.embedding_pretrained.size(1) \if self.embedding_pretrained is not None else 300 # 字向量维度, 若使用了预训练词向量,则维度统一self.hidden_size = 128 # rnn隐藏层self.num_layers = 2 # rnn层数,注意RNN中的层数必须大于1,dropout才会生效class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()if config.embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)self.rnn = nn.RNN(config.embed, config.hidden_size, config.num_layers,batch_first=True, dropout=config.dropout)self.fc = nn.Linear(config.hidden_size, config.num_classes)def forward(self, x):# 将原始数据转化成密集向量表示 [batch_size, seq_len, embedding]out = self.embedding(x[0])out, hidden_ = self.rnn(out)# out[:, -1, :] seq_len最后时刻的输出等价 hidden_out = self.fc(out[:, -1, :])return out
run_rnn.py文件,主程序入口,指定运行参数以及文本加载过程,最后调用train_eval.py的train函数进行模型训练。
import time
import torch
import numpy as np
from train_eval import train, init_network
from importlib import import_module
import argparse
from utils import build_dataset, build_iterator, get_time_difparser = argparse.ArgumentParser(description='Chinese Text Classification')
parser.add_argument('--model', default='RNN', type=str, required=True)
parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained')
parser.add_argument('--word', default=False, type=bool, help='True for word, False for char')
args = parser.parse_args()if __name__ == '__main__':dataset = 'THUCNews' # 数据集# 搜狗新闻:embedding_SougouNews.npz, 腾讯:embedding_Tencent.npz, 随机初始化:randomembedding = 'embedding_SougouNews.npz'if args.embedding == 'random':embedding = 'random'model_name = args.modelx = import_module('models.' + model_name)config = x.Config(dataset, embedding)np.random.seed(1)torch.manual_seed(1)torch.cuda.manual_seed_all(1)torch.backends.cudnn.deterministic = Truestart_time = time.time()print("Loading data...")# args.word 分词方式, True是词级别,默认是Falsevocab, train_data, dev_data, test_data = build_dataset(config, args.word)# build_iterator返回格式 [([词/字在词典中的位置] ,label, len(word)), ...]train_iter = build_iterator(train_data, config)dev_iter = build_iterator(dev_data, config)test_iter = build_iterator(test_data, config)time_dif = get_time_dif(start_time)print("Time usage:", time_dif)# len(vocab)="<PAD>", len(vocab) -1 ="<UNK>"config.n_vocab = len(vocab)model = x.Model(config).to(config.device)init_network(model)print(model.parameters)train(config, model, train_iter, dev_iter, test_iter)
train_eval.py 文件,主要对模型参数进行初始化,函数train主要是从自定义迭代器中加载数据进行训练。test函数是在模型训练完后对测试数据集进行测试。evaluate函数主要是在训练过程中对验证集数据进行验证。
# coding: UTF-8
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from tensorboardX import SummaryWriter
import matplotlib.pyplot as plt# 权重初始化,默认xavier
def init_network(model, method='xavier', exclude='embedding', seed=123):for name, w in model.named_parameters():if exclude not in name:if 'weight' in name:if method == 'xavier':nn.init.xavier_normal_(w)elif method == 'kaiming':nn.init.kaiming_normal_(w)else:nn.init.normal_(w)elif 'bias' in name:nn.init.constant_(w, 0)else:passdef train(config, model, train_iter, dev_iter, test_iter):loss_list = []start_time = time.time()model.train()optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)total_batch = 0 # 记录进行到多少batchdev_best_loss = float('inf')last_improve = 0 # 记录上次验证集loss下降的batch数flag = False # 记录是否很久没有效果提升writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))# dev_acc_list = []# dev_loss_list = []for epoch in range(config.num_epochs):print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))for i, (trains, labels) in enumerate(train_iter):outputs = model(trains)# 打印tensor的所有数据# torch.set_printoptions(threshold=float('inf'))model.zero_grad()loss = F.cross_entropy(outputs, labels)loss_list.append(loss.detach().numpy())loss.backward()optimizer.step()if total_batch % 100 == 0:true = labels.data.cpu()# 取出每一行最大的那个概率的索引值predic = torch.max(outputs.data, 1)[1].cpu()train_acc = metrics.accuracy_score(true, predic)dev_acc, dev_loss = evaluate(config, model, dev_iter)# dev_acc_list.append(dev_acc)# dev_loss_list.append(dev_loss)if dev_loss < dev_best_loss:dev_best_loss = dev_losstorch.save(model.state_dict(), config.save_path)improve = '*'last_improve = total_batchelse:improve = ''time_dif = get_time_dif(start_time)msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))writer.add_scalar("loss/train", loss.item(), total_batch)writer.add_scalar("loss/dev", dev_loss, total_batch)writer.add_scalar("acc/train", train_acc, total_batch)writer.add_scalar("acc/dev", dev_acc, total_batch)model.train()total_batch += 1if total_batch - last_improve > config.require_improvement:# 验证集loss超过10000batch没下降,结束训练print("No optimization for a long time, auto-stopping...")flag = Truebreakif flag:breakwriter.close()size = len(loss_list)x_axis = [i for i in range(0, size)]plt.plot(x_axis, loss_list, color='red')plt.show()test(config, model, test_iter)def test(config, model, test_iter):model.load_state_dict(torch.load(config.save_path))model.eval()start_time = time.time()test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'print(msg.format(test_loss, test_acc))print("Precision, Recall and F1-Score...")print(test_report)print("Confusion Matrix...")print(test_confusion)time_dif = get_time_dif(start_time)print("Time usage:", time_dif)def evaluate(config, model, data_iter, test=False):model.eval()loss_total = 0predict_all = np.array([], dtype=int)labels_all = np.array([], dtype=int)# 模型评估的时候无梯度模式with torch.no_grad():for texts, labels in data_iter:outputs = model(texts)loss = F.cross_entropy(outputs, labels)loss_total += losslabels = labels.data.cpu().numpy()predict = torch.max(outputs.data, 1)[1].cpu().numpy()labels_all = np.append(labels_all, labels)predict_all = np.append(predict_all, predict)acc = metrics.accuracy_score(labels_all, predict_all)if test:report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)confusion = metrics.confusion_matrix(labels_all, predict_all)return acc, loss_total / len(data_iter), report, confusion# 用于训练过程中的验证return acc, loss_total / len(data_iter)model_test.py 是单个文本的推理文件。
utils.py定义了加载数据集函数load_dataset,自定义迭代器将数据转化为tensor格式便于输入到模型。
完整代码github地址
项目结构清晰以后我们主要要记录一下,RNN训练过程中遇到的一些问题,尽管现在已经不怎么使用RNN网络模型了,不过这不影响RNN在时序网络中的地位(LSTM 长短时记忆网络、GRU门控循环单元都是RNN的优化)我们还是有必要好好认识一下RNN的训练过程,以及超参数对损失值的影响。
我们主要参数设置如下,我们只对batch_size和pad_size进行修改看一下模型的损失下降曲线。
self.dropout = 0.3 # 随机失活
self.require_improvement = 10000 # 若超过10000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 7 # epoch数
self.batch_size = 64 # batch size
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1) \
if self.embedding_pretrained is not None else 300 # 字向量维度
self.hidden_size = 128 # rnn隐藏层
self.num_layers = 2 # rnn层数,注意RNN中的层数必须大于1,dropout才会生效
batch_size = 64 pad_size = 32 learning_rate = 1e-3
训练过程

损失函数结果图,可以看出根本就不收敛,pad_size值过大,可能出现出现梯度消失,导致模型参数根本就不更新。

batch_size = 64 pad_size = 16 learning_rate = 1e-3
训练过程

从这里足以感性的理解为什么很多人说RNN携带的时序信息走不远,当我们将时序长度pad_size设置16时(其他参数不变)可以看到验证数据集的准确度和损失都还不错的,比pad_size=32要好很多,至少可以知道模型的参数是在更新,且损失值也有下降的趋势。

混淆矩阵也还可以。 混淆矩阵参考

以上是文本序列长度pad_size对RNN训练的影响。现在我们来看下batch_size大小对RNN训练的影响。为了让模型收敛pad_szie统一取16
batch_size = 128 pad_size = 16 learning_rate = 1e-3
训练过程

batch_size变大为128更新次数少,每一次迭代考虑的样本更多。每次迭代考虑的样本大了以后,梯度优化的波动变小,下降更平滑。相比batch_size=64,损失图像下下降确实更平滑。混淆矩阵无太大差异。

batch_size = 256 pad_size = 16 learning_rate = 1e-3
训练过程

batch_size=256损失值下降更平滑,收敛速度更快,batch_size=64时训练时长在18min左右,而此参数下训练时长仅要5min左右。

batch_size = 1024 pad_size = 16 learning_rate = 1e-3
训练过程

batch_size=1024时收敛速度更快,而此参数下训练时长仅要2min左右。

混淆矩阵,可以看出在显存足够大的情况下适当增大batch_size可以达到两点效果1)加快训练的收敛的速度 2)梯度优化的波动减小,收敛过程更加平滑。

至此我们已经完成了RNN训练中两个比较重要的超参数batch_size和pad_size对训练过程的影响。还有很多其他的超参数这里就不实验了。
pad_size由32变成16时候,显然只用到了一半的数据信息,无论怎么进行超参数的优化都不可能达到最好的结果。如果使用32又会出现梯度消失,从而模型不收敛。LSTM模型就有效的改进了这个缺陷。下一篇文章我们使用同样的超参数和数据集构造一个LSTM模型实验这个改进有多大。
参考
https://github.com/649453932/Chinese-Text-Classification-Pytorch
相关文章:
RNN实战
本主要是利用RNN做多分类任务,在熟悉RNN训练的过程中,我们可以理解 1)超参数 batch_size和pad_size对训练过程的影响。 2)文本处理过程中是如何将文本的文字表示转化为向量表示 3)RNN梯度消失和序列长度的关系 4&#…...
从GPT入门,到R语言基础与作图、回归模型分析、混合效应模型、多元统计分析及结构方程模型、Meta分析、随机森林模型及贝叶斯回归分析综合应用等专题及实战案例
目录 专题一 GPT及大语言模型简介及使用入门 专题二 GPT与R语言基础与作图(ggplot2) 专题三 GPT与R语言回归模型(lm&glm) 专题四 GPT与混合效应模型(lmm&glmm) 专题五 GPT与多元统计分析&…...

【Android】数据安全(一) —— Sqlite加密
目录 SQLCipherSQLiteCrypt其它 SQLCipher SQLCipher 是 SQLite 数据库的的开源扩展,使用了 256 位 AES 加密,支持跨平台、零配置、数据100%加密、加密开销低至 5 -15%、占用空间小、性能出色等优点,因此非常适合保护嵌入式应用程序数据库&a…...

云原生周刊:Helm Charts 深入探究 | 2024.3.11
开源项目推荐 Glasskube Glasskube 提供了一个用于 Kubernetes 的缺失的包管理器。它具有图形用户界面(GUI)和命令行界面(CLI)。Glasskube 包是具备依赖感知、GitOps 准备和可以通过中央公共包仓库自动更新的特性。 imgpkg imgpkg(发音为:"imag…...
【C++初阶】第六站 : 模板初阶
前言: 本章知识点:泛型编程、函数模板、类模板 专栏: C初阶 目录 泛型编程 函数模板 1.函数模板概念 2.函数模板格式 3.函数模板的原理 4.函数模板的实例化 5.模板参数的匹配原则 类模板 类模板的定义格式 类模板的实例化 泛型编程 如何实现一…...

训练保存模型checkpoint时报错SyntaxError: invalid syntax
在使用pytorch训练保存checkpoint时,出现如下报错: rootautodl-container-745411b452-c5cebfed:~/kvasir-seg-main# python train_transunet.py --loss_function"IoULoss" --training_augmentation0File "train_transunet.py", lin…...
虚拟机中安装Win98
文章目录 一、下载Win98二、制作可启动光盘三、VMware中安装Win98四、Qemu中安装Win981. Qemu的安装2. 安装Win98 Win98是微软于1998年发布的16位与32位混合的操作系统,也是一代经典的操作系统,期间出现了不少经典的软件与游戏,还是值得怀念的…...

《C++游戏编程入门》第4章 标准模板库: Hangman
《C游戏编程入门》第4章 标准模板库: Hangman 4.1 标准模板库4.2 vector04.heros_inventory2.cpp 4.3 使用迭代器04.heros_inventory3.cpp 4.4 使用算法04.high_scores.cpp 4.5 理解向量性能4.6 其他STL容器4.7 Hangman简介04.hangman.cpp 4.1 标准模板库 Standard Template L…...
Linux最小系统安装无法查看IP地址
1,出现原因 服务器重启完成之后,我们可以通过linux的指令 ip addr 来查询Linux系统的IP地址,具体信息如下: 从图中我们可以看到,并没有获取到linux系统的IP地址,这是为什么呢?这是由于启动服务器时未加载网…...

分享个好用的GPT网站
目录 一、背景 二、功能描述 1、写代码 2、联网查询 3、AI绘图 一、背景 我现在的开发工作都依靠ChatGPT,效率提升了好几倍。这样一来,我有更多时间来摸鱼,真是嘎嘎香~ ⭐⭐⭐点击直达 ⭐⭐⭐ 二、功能描述 1、写代码 import java.ut…...
hyperf 二十六 数据迁移 二
教程:Hyperf 参考文章hyperf 二十五 数据迁移 一-CSDN博客 根据之前写的数据迁移的文章,已经说明Hyperf\Database\Schema\Schema::create()实际运行Hyperf\Database\Schema\Grammars\MySqlGrammar::compileCreate()生成的sql字符串。 文档所谓"在…...

linux下如何hook第三方播放器的视频数据?
背景 作为显卡生产商,当用户使用我们的显卡硬解码播放视频时,如果出现比如花屏等问题,为了快速确定问题原因,我们需要一个工具来帮助判断出问题是出在原始视频端,亦或者是应用程序端,亦或者是显卡端。因此我们需要一种方法,来对目标播放器程序进行监控,并捕获到视频源的…...

如何通过Python代码连接OceanBase Oracle租户
背景 目前,连接数据库的Oracle租户,只能通过Java和C的驱动程序,无法通过其他语言的驱动程序。为了满足社区中用户希望在Python代码中连接Oracle租户的需求,这里提供一种替代方案。通过结合使用JayDeBeApi和JDBC,我们可…...
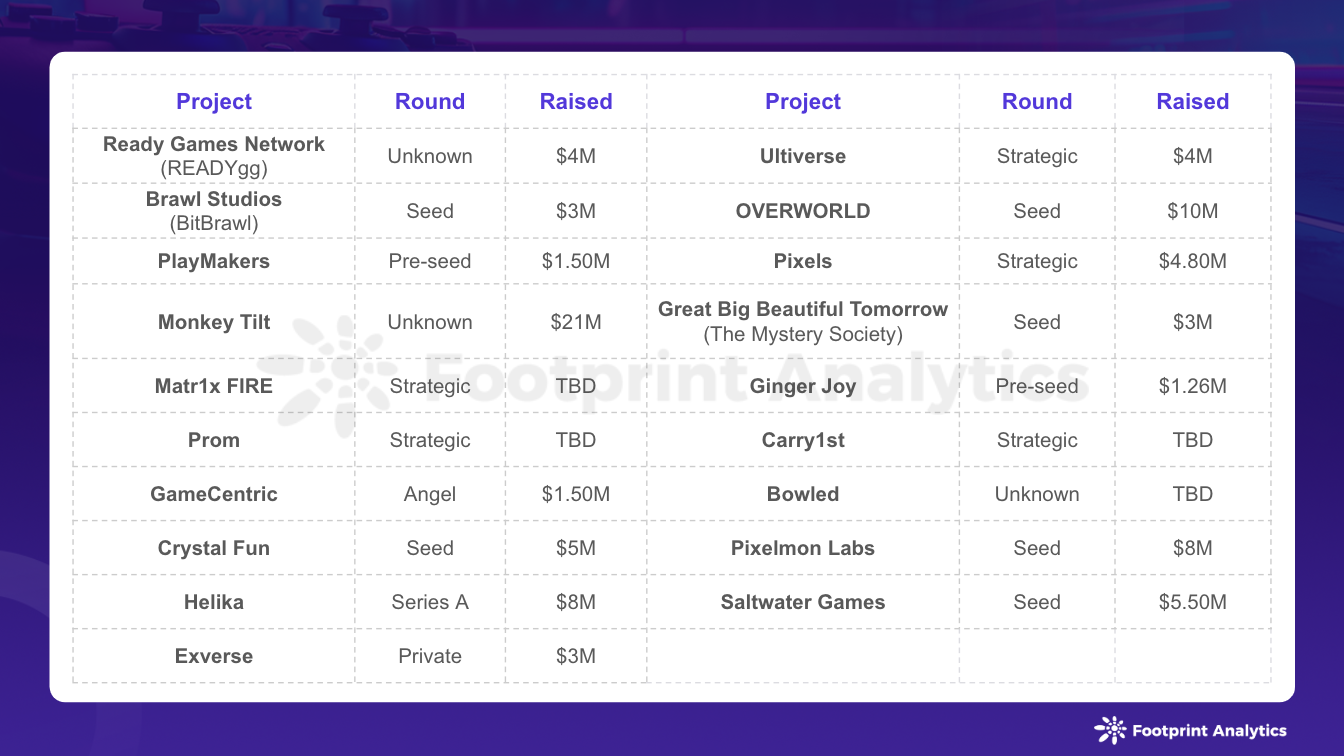
2 月 Web3 游戏行业动态
作者:stellafootprint.network 数据来源:区块链游戏研究页面 - Footprint Analytics 2024 年 2 月,区块链游戏领域在加密货币价格上涨和活跃用户激增的推动下,实现了显著增长。然而,行业在维持用户参与度和留存率方面…...

普发Pfeiffer Prisma QMS200四极质谱计内部电路图装配3D图电路板接口详细注解
普发Pfeiffer Prisma QMS200四极质谱计内部电路图装配3D图电路板接口详细注解...
)
2024.03.04——2024.03.10 力扣练习总结及专项巩固(二)
1. (22. 括号生成)这里只讨论第二种做法回溯法。在回溯法的函数void backtrack(vector<string>& ans, string& current, int open, int close, int n); 中,可分为三个if条件判断,分别判断当current.size() 2*n,ope…...

前端NodeJs笔记之包结构到进程和线程到命令行到Node模块化讲解
包结构 包实际上是一个压缩文件,解压以后还原为目录,符合规范的目录应该包含如下文件: -package.json 描述文件 -bin 可执行二进制文件 -lib js代码 -doc …...

【Java】获取手机文件名称补充
本地的 ADB 工具路径指的是你电脑上安装的 Android Debug Bridge(ADB)工具的路径。ADB 是 Android SDK 中的一个工具,用于与连接到计算机上的 Android 设备进行通信。你需要确保 ADB 已正确安装,并知道其在你计算机上的位置。 通…...
YoloV8改进策略:BackBone改进|TransNeXt:ViT的鲁棒Foveal视觉感知
文章目录 摘要论文:《TransNeXt:ViT的鲁棒Foveal视觉感知》1、引言2、相关工作3、方法3.1、聚合像素焦点注意力3.1.1、像素焦点注意力3.1.2、在单个混合器中聚合不同的注意力3.1.3、克服多尺度图像输入3.1.4、特征分析3.2、卷积门控单元(Convolutional GLU)3.2.1、动机3.2.…...

三维的旋转平移矩阵形式
在三维空间中,一个物体或坐标系的旋转和平移可以通过一个4x4的变换矩阵来表示。这个矩阵通常被称为仿射变换矩阵或齐次变换矩阵。它结合了旋转矩阵和平移向量的功能,能够同时表示旋转和平移操作。 一个4x4的旋转平移矩阵通常具有以下形式: 复…...

Linux系统下scrcpy最新版安装与配置全攻略
1. 为什么你需要scrcpy? 作为一个长期在Linux环境下折腾各种工具的老用户,我不得不说scrcpy绝对是手机投屏工具中的"瑞士军刀"。它最大的优势在于完全免费开源,而且延迟极低,实测在局域网环境下几乎感觉不到画面延迟。我…...

告别内存访问瓶颈:深入STM32H7的AXI总线矩阵,优化DMA与多核数据流
突破STM32H7性能极限:AXI总线矩阵与DMA调优实战指南 当你在开发基于STM32H7的高性能应用时,是否遇到过这样的困境:理论上400MHz的主频和双精度浮点单元应该轻松应对4K图像处理,但实际运行时却频频遭遇卡顿?摄像头采集的…...
美)
高精度计算插件 decimal.js 处理 JS 浮点数精度问题(. + . !== .)美
1. 智能软件工程的范式转移:从库集成到原生框架演进 在生成式人工智能(Generative AI)从单纯的文本生成向具备自主规划与执行能力的“代理化(Agentic)”系统跨越的过程中,.NET 生态系统正在经历一场自该平台…...

PDFtoPrinter深度解析:.NET平台下的PDF自动化打印最佳实践
PDFtoPrinter深度解析:.NET平台下的PDF自动化打印最佳实践 【免费下载链接】PDFtoPrinter .Net Wrapper over PDFtoPrinter util allows to print PDF files. 项目地址: https://gitcode.com/gh_mirrors/pd/PDFtoPrinter PDFtoPrinter是一个专为.NET开发者设…...

OBS Studio实战:SRT推流配置与性能优化全解析
1. SRT协议与OBS推流基础认知 第一次接触SRT推流时,我被它复杂的参数配置搞得晕头转向。直到有次直播电竞比赛,RTMP推流出现严重卡顿,才真正体会到SRT的价值——当时切换SRT协议后,延迟直接从3秒降到0.8秒,观众弹幕瞬间…...

华中科技大学本科毕业论文LaTeX模板完整使用指南:快速上手终极教程
华中科技大学本科毕业论文LaTeX模板完整使用指南:快速上手终极教程 【免费下载链接】HUSTPaperTemp 华中科技大学本科毕业论文LaTeX模板 2017 项目地址: https://gitcode.com/gh_mirrors/hu/HUSTPaperTemp 对于华中科技大学的本科生来说,毕业论文…...

Claude Code 行为指南
Claude Code 行为指南 背景与问题 Andrej Karpathy(前 OpenAI 创始成员、前 Tesla AI 总监)在社交媒体上分享了他对 LLM 编码行为的观察:“模型会替你做出错误的假设并直接执行,而不去验证。它们不管理自己的困惑,不寻…...

Midscene.js:用自然语言重新定义UI自动化,告别繁琐代码时代
Midscene.js:用自然语言重新定义UI自动化,告别繁琐代码时代 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 还在为编写复杂的UI自动化脚本…...

HarvestText实体发现:无监督方法识别领域特定实体的终极指南 [特殊字符]
HarvestText实体发现:无监督方法识别领域特定实体的终极指南 🚀 【免费下载链接】HarvestText 文本挖掘和预处理工具(文本清洗、新词发现、情感分析、实体识别链接、关键词抽取、知识抽取、句法分析等),无监督或弱监督…...

MOSFET栅极电路设计全解析:从驱动优化到系统保护
1. MOSFET栅极电路设计基础 MOSFET作为现代电子系统的核心开关器件,其栅极电路设计直接决定了整体性能表现。记得我第一次调试电机驱动板时,就因为栅极电阻选型不当导致MOSFET过热烧毁,这个教训让我深刻认识到栅极设计的重要性。 栅极电路本质…...