并行计算CUDA DEMO
//并行计算CUDA DEMO
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
VS2019编译时返回MSB3721时没有更多错误信息
复制编译输出到命令行运行查看出错信息
nvcc.exe -gencode=arch=compute_52,code=\"sm_52,compute_52\" --use-local-env -ccbin "C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\HostX86\x64" -x cu -I"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\include" -I"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\atlmfc\include" -I"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\VS\include" -I"C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\ucrt" -I"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\VS\UnitTest\include" -I"C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\um" -I"C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\shared" -I"C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\winrt" -I"C:\Program Files (x86)\Windows Kits\10\Include\10.0.19041.0\cppwinrt" -I"C:\Program Files (x86)\Windows Kits\NETFXSDK\4.8\Include\um" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\include\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\include\include" --keep-dir x64\Release -maxrregcount=0 --machine 64 --compile -cudart static -DWIN32 -DWIN64 -DNDEBUG -D_CONSOLE -D_MBCS -Xcompiler "/EHsc /W3 /nologo /O2 /Fdx64\Release\vc142.pdb /FS /MD " -o D:\space\vsspace\TestCUDA\x64\Release\kernel.cu.obj "D:\space\vsspace\TestCUDA\TestCUDA\kernel.cu"
根据错误信息解决各种问题
输入路径改为绝对路径 $(OutDir)%(Filename)%(Extension).obj
相关文章:

并行计算CUDA DEMO
//并行计算CUDA DEMO #include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size); __global__ void addKernel(int *c, const int …...

【linux线程(一)】什么是线程?怎样操作线程?
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Linux从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学更多操作系统知识 🔝🔝 Linux线程 1. 前言2. 什么是线…...
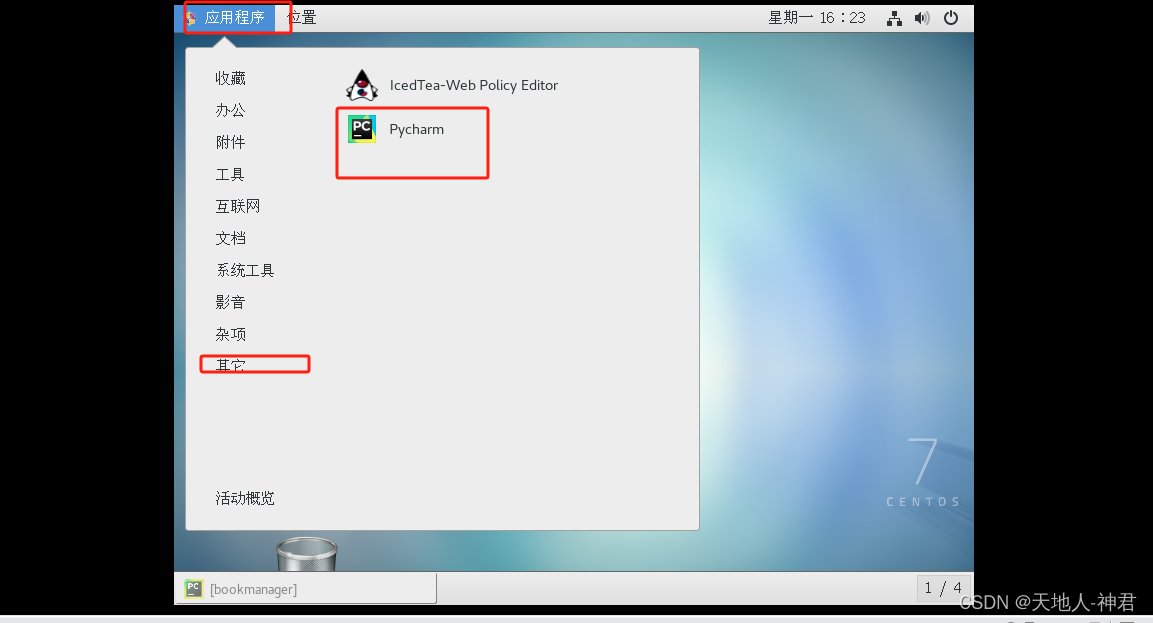
python-0002-linux安装pycharm
下载软件包 下载地址:https://download.csdn.net/download/qq_41833259/88944791 安装 # 解压 tar -zxvf 你的软件包 # 进入软件解压后的路径,如解压到了/home/soft/pycharm cd /home/soft/pycharm cd bin # 执行启动命令 sh pycharm.sh # 等待软件启…...

扭蛋机小程序,扭蛋与互联网结合下的商机
扭蛋机作为一种娱乐消费模式,受众群体不再局限于儿童,也吸引了众多的年轻消费者。扭蛋机具有较大的随机性,玩具商品随机掉落,在购买前消费者完全不知道扭蛋中的商品是什么,这种未知性带来的惊喜感是吸引众多消费者的主…...

pytorch CV入门3-预训练模型与迁移学习
专栏链接:https://blog.csdn.net/qq_33345365/category_12578430.html 初次编辑:2024/3/7;最后编辑:2024/3/8 参考网站-微软教程:https://learn.microsoft.com/en-us/training/modules/intro-computer-vision-pytorc…...

Swift SwiftUI 学习笔记 2024
Swift SwiftUI 学习笔记 2024 一、资源 视频资源 StanfordUnivercity 公开课 2023: https://cs193p.sites.stanford.edu/2023 教程 Swift 初识:基础语法:https://docs.swift.org/swift-book/documentation/the-swift-programming-language/guidedtour/…...
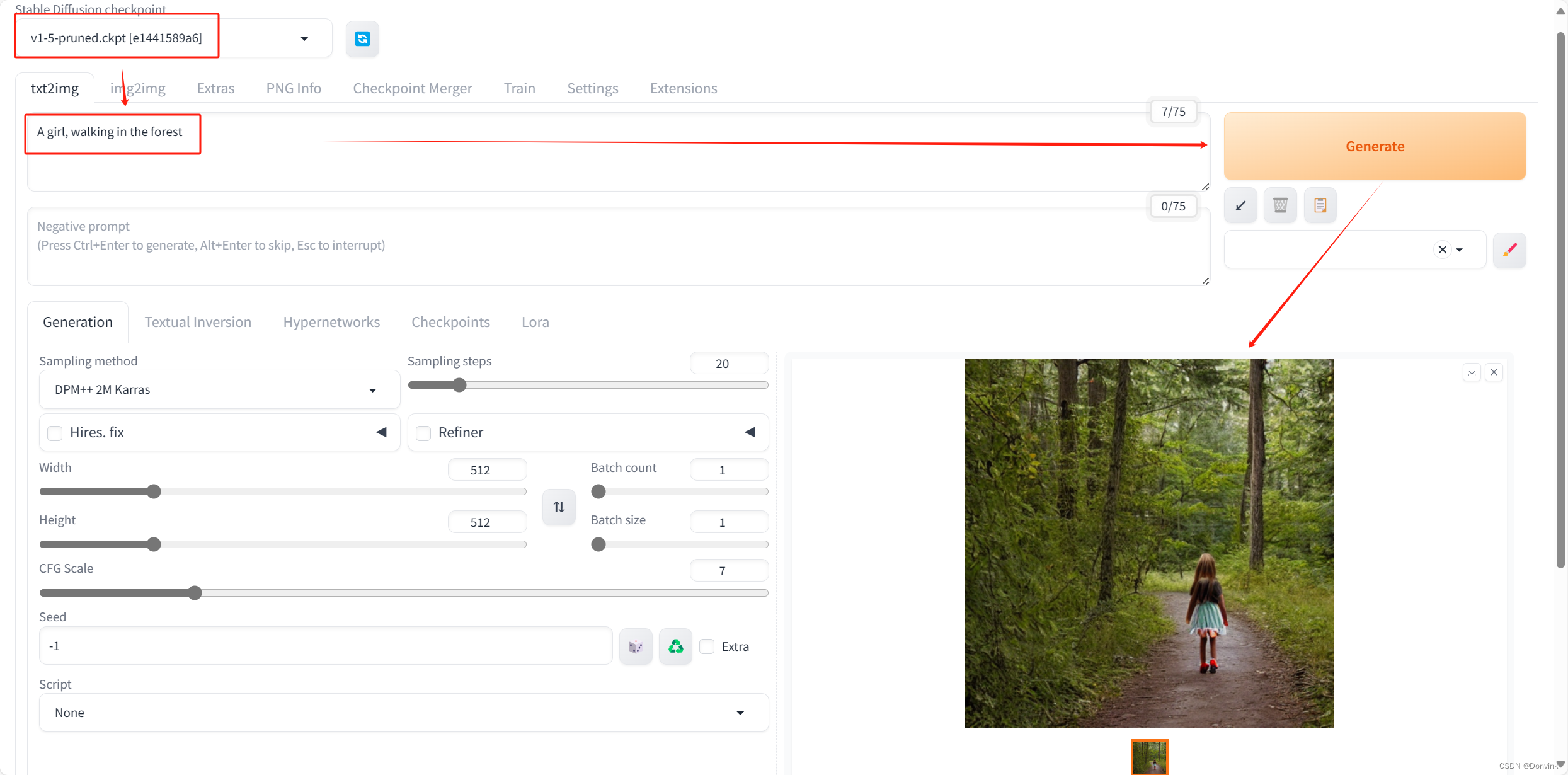
【Stable Diffusion】入门:原理简介+应用安装(Windows)+生成步骤
【Stable Diffusion】入门:原理简介应用安装(Windows)生成步骤 原理简介应用安装 原理简介 稳定扩散生成模型(Stable Diffusion)是一种潜在的文本到图像扩散模型,能够在给定任何文本输入的情况下生成照片般逼真的图像。 应用安…...
)
【栈】第十二届蓝桥杯省赛第一场C++ B组/研究生组《双向排序》(c++)
【题目描述】 给定序列 (a1,a2,⋅⋅⋅,an)(1,2,⋅⋅⋅,n),即 aii。 小蓝将对这个序列进行 m 次操作,每次可能是将 a1,a2,⋅⋅⋅,aqi 降序排列,或者将 aqi,aqi1,⋅⋅⋅,an 升序排列。 请求出操作完成后的序列。 【输入格式】 输入的第一行…...

Gitea 安装和配置
Gitea 安装和配置: http://coffeelatte.vip.cpolar.top/post/software/applications/gitea/gitea_安装和配置/ 文章目录 Gitea 安装和配置: <http://coffeelatte.vip.cpolar.top/post/software/applications/gitea/gitea_%E5%AE%89%E8%A3%85%E5%92%8C%E9%85%8D%E7%BD%AE/>…...

CEF JS与c++能够交互的原理 以及 JS 调用C++的流程分析
相关章节:CEF 之 Render进程 与 Browser进程通信 目录 一、JS与c++能够交互的原理 二、JS调用C++ 流程梳理...

关于比特币的AI对话
【ChatGPT】 比特币源码开源吗? 是的,比特币的源码是开源的。比特币项目是在MIT许可证下发布的,这意味着任何人都可以查看、修改、贡献和分发代码。比特币的源码托管在GitHub上,可以通过下面的链接进行访问: https://g…...
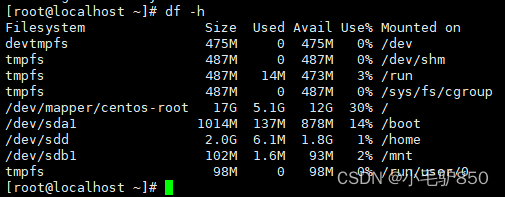
Linux查看磁盘命令df-h详解
df -h 是一个常用的 Linux 命令,用于查看文件系统的磁盘使用情况并以易于阅读的方式显示。以下是 df -h 命令的详细解释: -h:以人类可读的格式显示磁盘空间大小。例如,使用 GB、MB、KB 等单位代替字节。 执行 df -h 命令后&…...
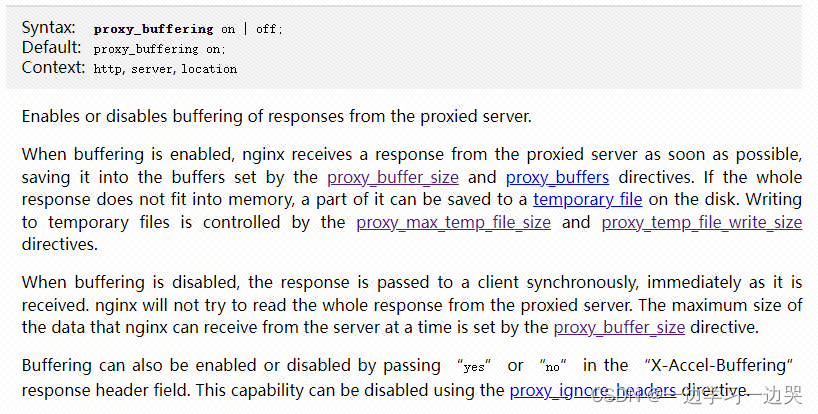
nginx-排查一次大文件无法正常下载问题
目录 问题现象&报错信息 问题现象以及分析 nginx报错信息 问题解决 方法1:配置proxy_max_temp_file_size 方法2:关闭proxy_buffering 参考文档 问题现象&报错信息 问题现象以及分析 文件正常从后端服务器直接下载时,一切正常…...

基于yolov5的草莓成熟度检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】
功能演示: 基于yolov5的草莓成熟度检测系统,系统既能够实现图像检测,也可以进行视屏和摄像实时检测_哔哩哔哩_bilibili (一)简介 基于yolov5的草莓成熟度系统是在pytorch框架下实现的,这是一个完整的项目…...
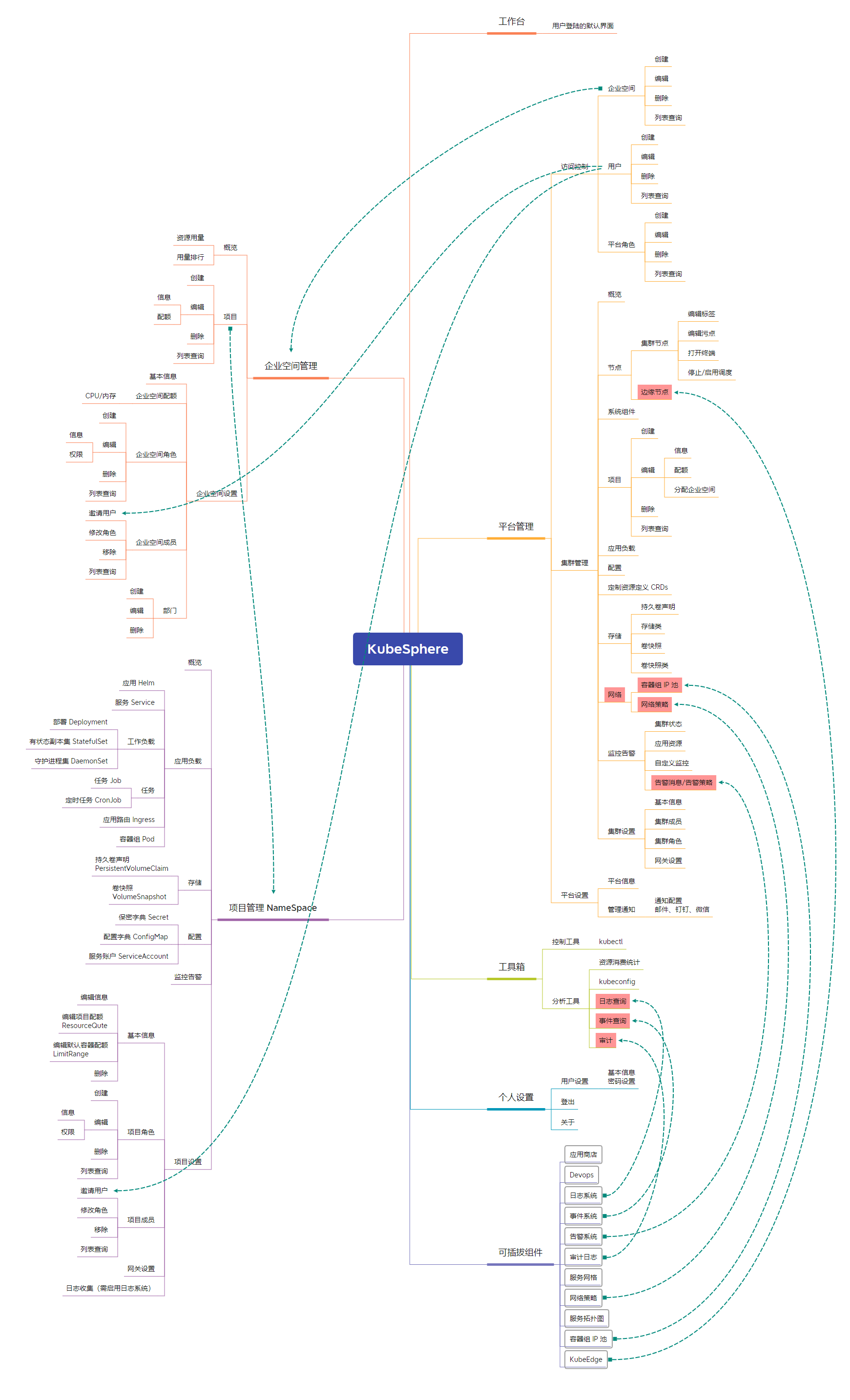
Kubesphere 保姆级分析
应用场景 KubeSphere 适用于多种场景,为企业提供容器化的环境,借助完善的管理和运维功能,让企业在数字化转型过程中从容应对各种挑战和各类业务场景,如多云多集群管理、敏捷软件开发、自动化运维、微服务治理、流量管理以及 DevO…...

力扣hot100:240.搜索二维矩阵II(脑子)
吉大21级算法分析与设计的一道大题,由于每一行都是排好序的直接逐行二分 可以达到:O(mlogn)。但是这里追求更广的思路可以使用其他方法。 矩阵四分: 在矩阵中用中心点比较,如果target大于中心点的值,则由于升序排列&am…...
)
Apache Hive(三)
一、Apache Hive 1、ETL数据清洗 数据问题 问题1:当前数据中,有一些数据的字段为空,不是合法数据 解决:where 过滤 问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段…...
的概念,并说明在Python中如何使用)
ORM(对象关系映射)的概念,并说明在Python中如何使用
ORM(对象关系映射)的概念,并说明在Python中如何使用 ORM(对象关系映射)是一种编程技术,它实现了将关系型数据库中的数据映射到程序中的对象模型,使得开发者能够使用面向对象的方式来操作数据…...

Br 算法
基于google的brotli开源,实现Br算法。 #include <brotli/encode.h> #include <brotli/decode.h>namespace br {/*compress unsigned char* content,if ok return non empty unsigned char * */std::string compress_string(const std::string& c…...

GPT实战系列-一种构建LangChain自定义Tool工具的简单方法
GPT实战系列-一种构建LangChain自定义Tool工具的简单方法 LLM大模型: GPT实战系列-探究GPT等大模型的文本生成 GPT实战系列-Baichuan2等大模型的计算精度与量化 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF …...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

2026上海GEO生成式引擎优化服务商综合实力测评:谁在真正帮品牌进入AI答案
当企业在讨论“上海生成式引擎优化公司哪家好”时,这个问题本身就反映了市场一个关键的转折。两三年前,企业营销的主战场还是搜索引擎排名和官网访问量。现在,决策者开始频繁向DeepSeek、豆包、通义千问等AI工具提问,而这些生成式…...
)
【独家首发】国内23家AI语音服务商最新报价数据库(含教育/医疗/金融行业专属折扣码及最小起订量红线)
更多请点击: https://kaifayun.com 第一章:AI语音合成价格与性价比分析 AI语音合成(TTS)服务的定价模式日益多样化,从按字符/音频时长计费到订阅制、API调用包、企业定制方案并存。理解不同服务商的成本结构与实际输出…...

通过Taotoken用量看板清晰追踪各模型的Token消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰追踪各模型的Token消耗情况 对于依赖大模型API进行开发的个人或团队而言,成本控制与预算规划…...

MUUFL Gulfport高光谱与LiDAR数据集:遥感研究者的终极实战指南
MUUFL Gulfport高光谱与LiDAR数据集:遥感研究者的终极实战指南 【免费下载链接】MUUFLGulfport MUUFL Gulfport Hyperspectral and LIDAR Data: This data set includes HSI and LIDAR data, Scoring Code, Photographs of Scene, Description of Data 项目地址: …...