初级爬虫实战——伯克利新闻
文章目录
- 发现宝藏
- 一、 目标
- 二、简单分析网页
- 1. 寻找所有新闻
- 2. 分析模块、版面和文章
- 三、爬取新闻
- 1. 爬取模块
- 2. 爬取版面
- 3. 爬取文章
- 四、完整代码
- 五、效果展示
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
一、 目标
爬取https://news.berkeley.edu/的字段,包含标题、内容,作者,发布时间,链接地址,文章快照 (可能需要翻墙才能访问)
二、简单分析网页
1. 寻找所有新闻

2. 分析模块、版面和文章
我们可以按照新闻模块、版面、和文章对网页信息进行拆分,分别按照步骤进行爬取
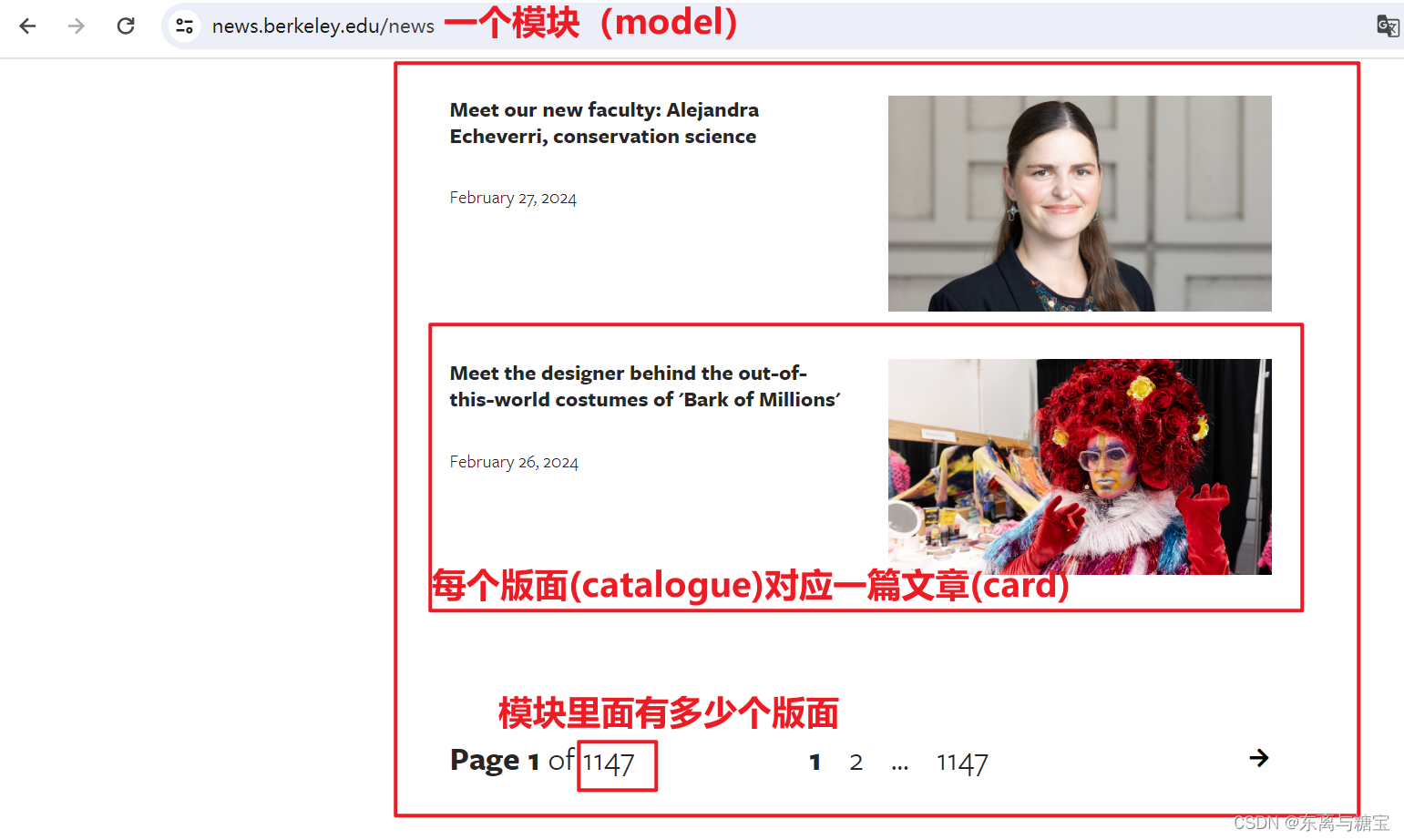
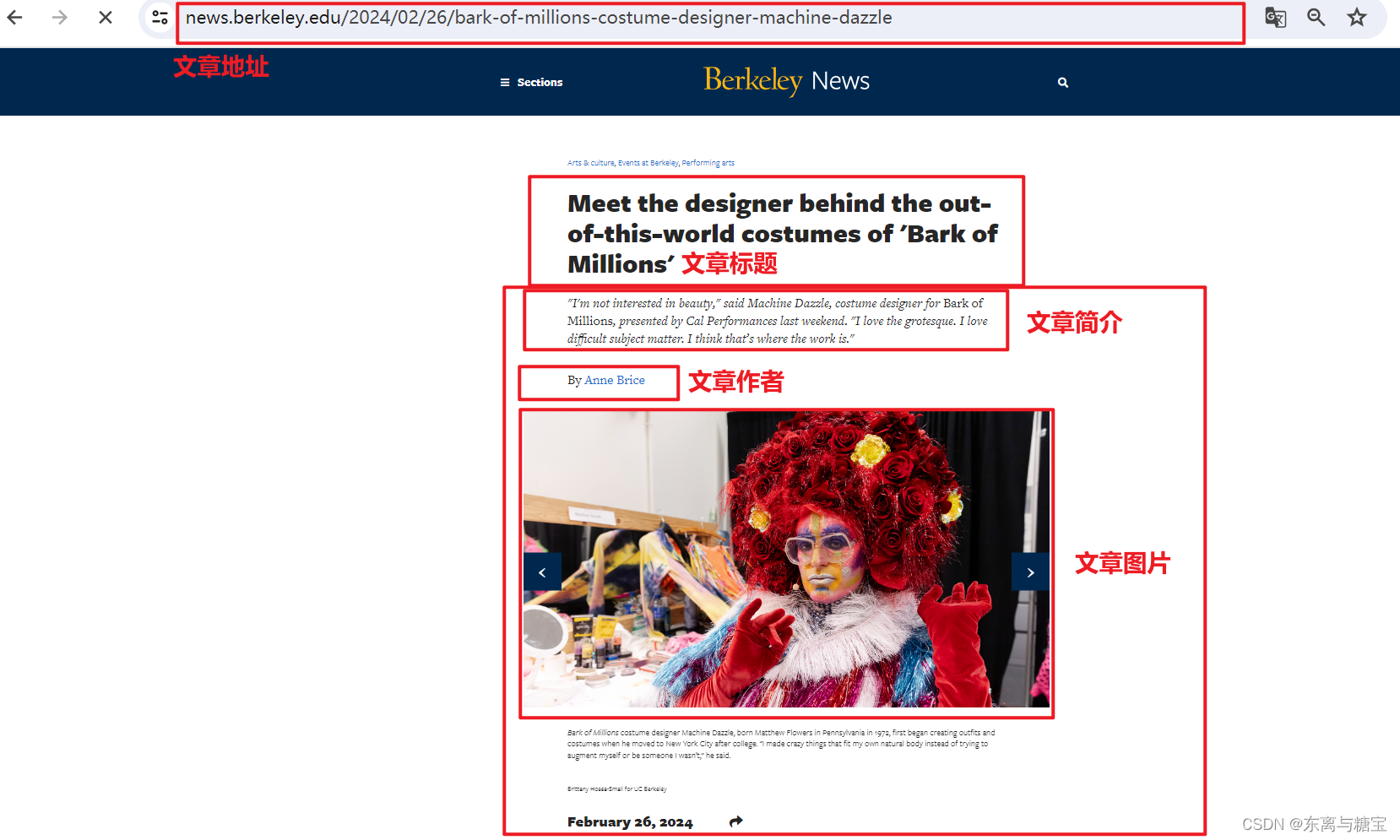
三、爬取新闻
1. 爬取模块
由于该新闻只有一个模块,所以直接请求该模块地址即可获取该模块的所有信息,但是为了兼容多模块的新闻,我们还是定义一个数组存储模块地址
class MitnewsScraper:def __init__(self, root_url, model_url, img_output_dir):self.root_url = root_urlself.model_url = model_urlself.img_output_dir = img_output_dirself.headers = {'Referer': 'https://news.berkeley.edu/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/122.0.0.0 Safari/537.36','Cookie': '替换成你自己的',}...def run():# 根路径root_url = 'https://news.berkeley.edu/'# 模块地址数组model_urls = ['https://news.berkeley.edu/news']# 文章图片保存路径output_dir = 'D://imgs//berkeley-news'for model_url in model_urls:scraper = MitnewsScraper(root_url, model_url, output_dir)scraper.catalogue_all_pages()if __name__ == "__main__":run()
多模块的新闻网站例子如下(4个模块)
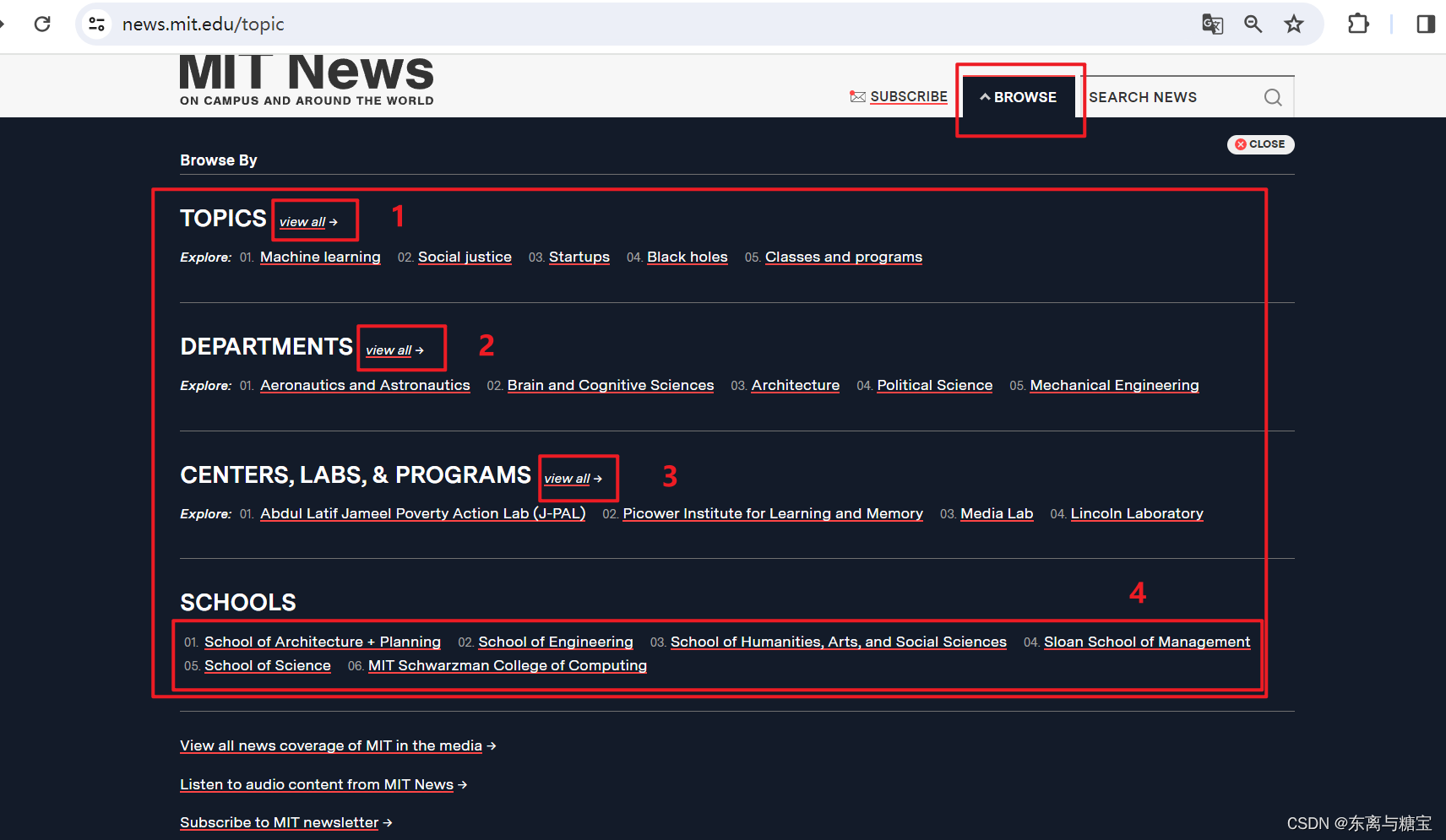
2. 爬取版面
- f12打开控制台,点击网络(network),通过切换页面观察接口的参数传递,发现只有一个page参数
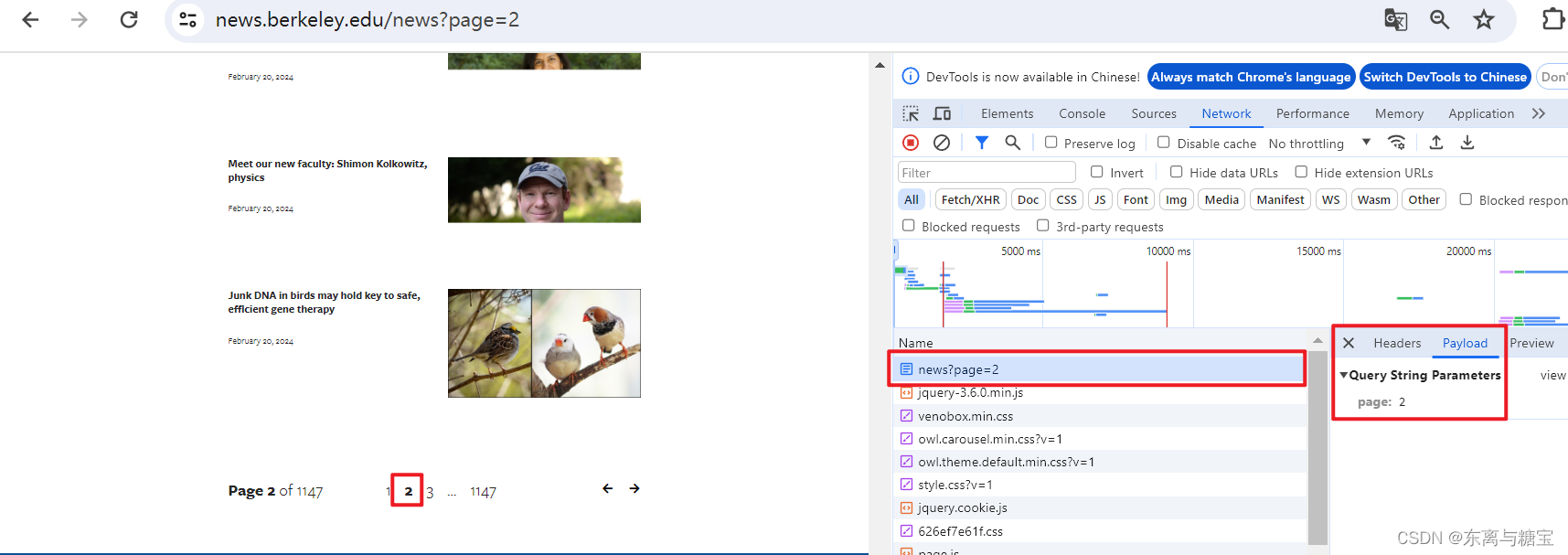
- 于是我们可以获取页面下面的页数(page x of xxxx), 然后进行遍历传参,也就遍历获取了所有版面

# 获取一个模块有多少版面def catalogue_all_pages(self):response = requests.get(self.model_url, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')try:match = re.search(r'of (\d+)', soup.text)num_pages = int(match.group(1))print('模块一共有' + str(num_pages) + '页版面,')for page in range(1, num_pages + 1):self.parse_catalogues(page)print(f"========Finished modeles page {page}========")except:return False
- F12打开控制台后按照如下步骤获取版面列表对应的dom结构
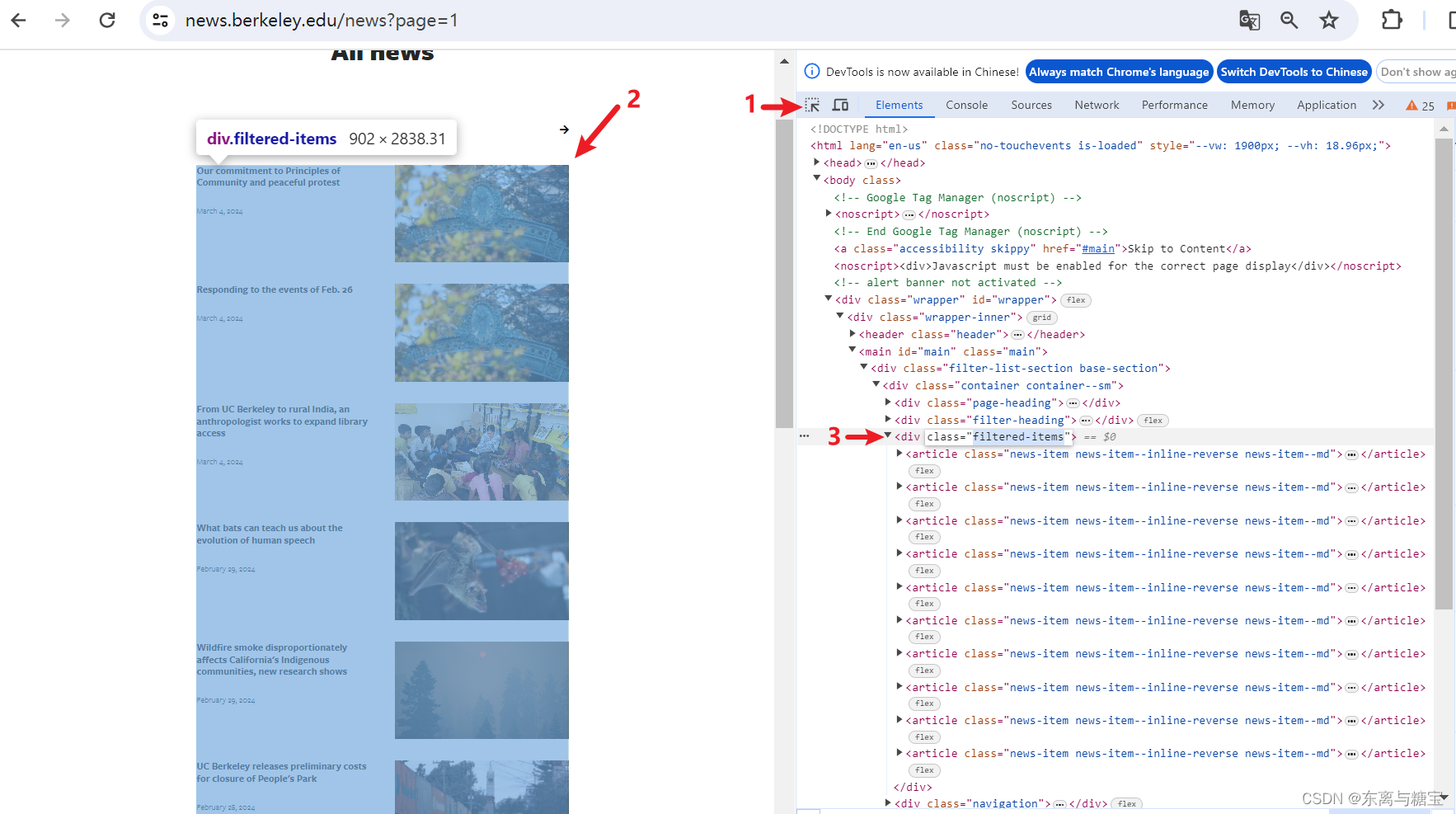
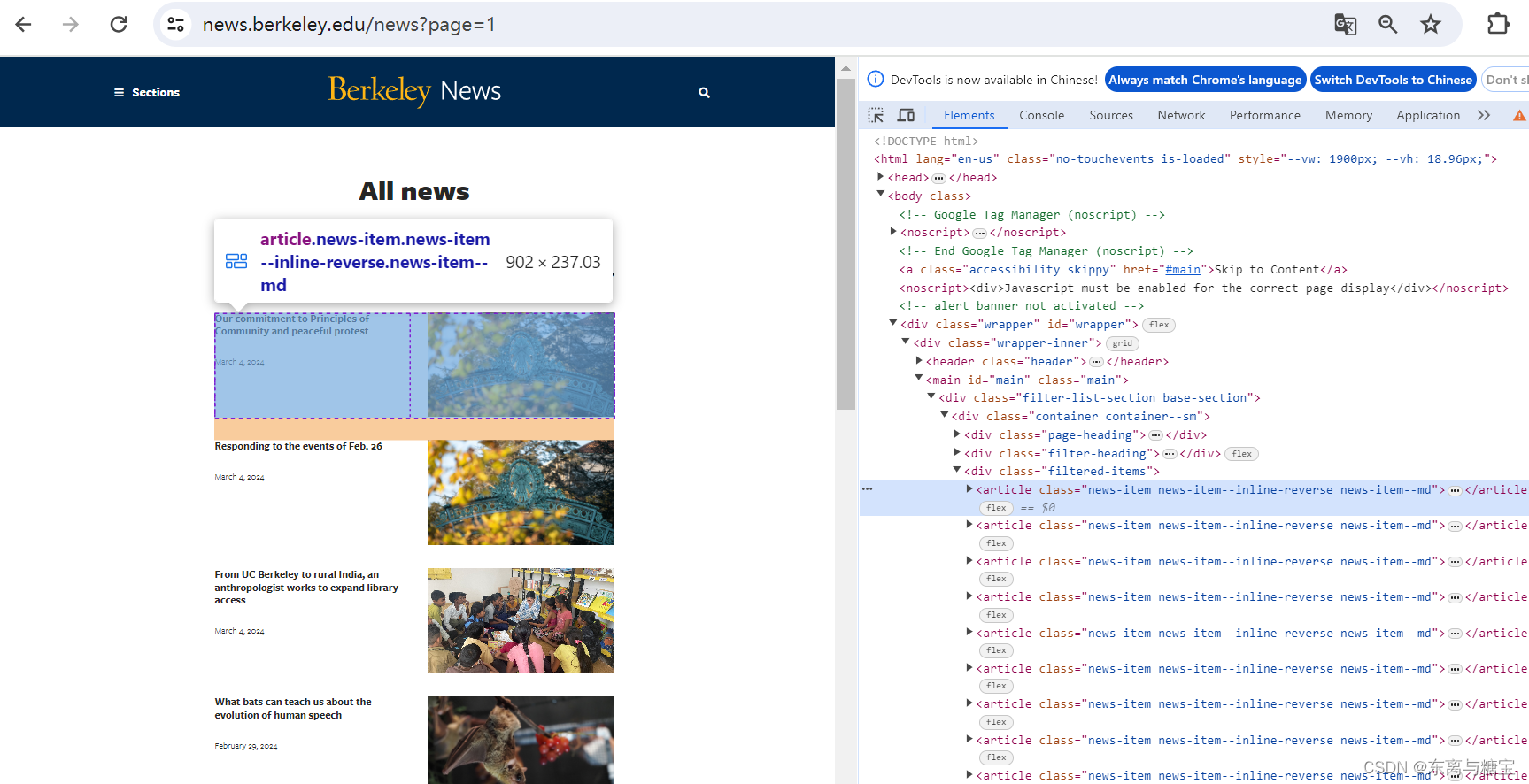
catalogue_list = soup.find('div', 'filtered-items')catalogues_list = catalogue_list.find_all('article')
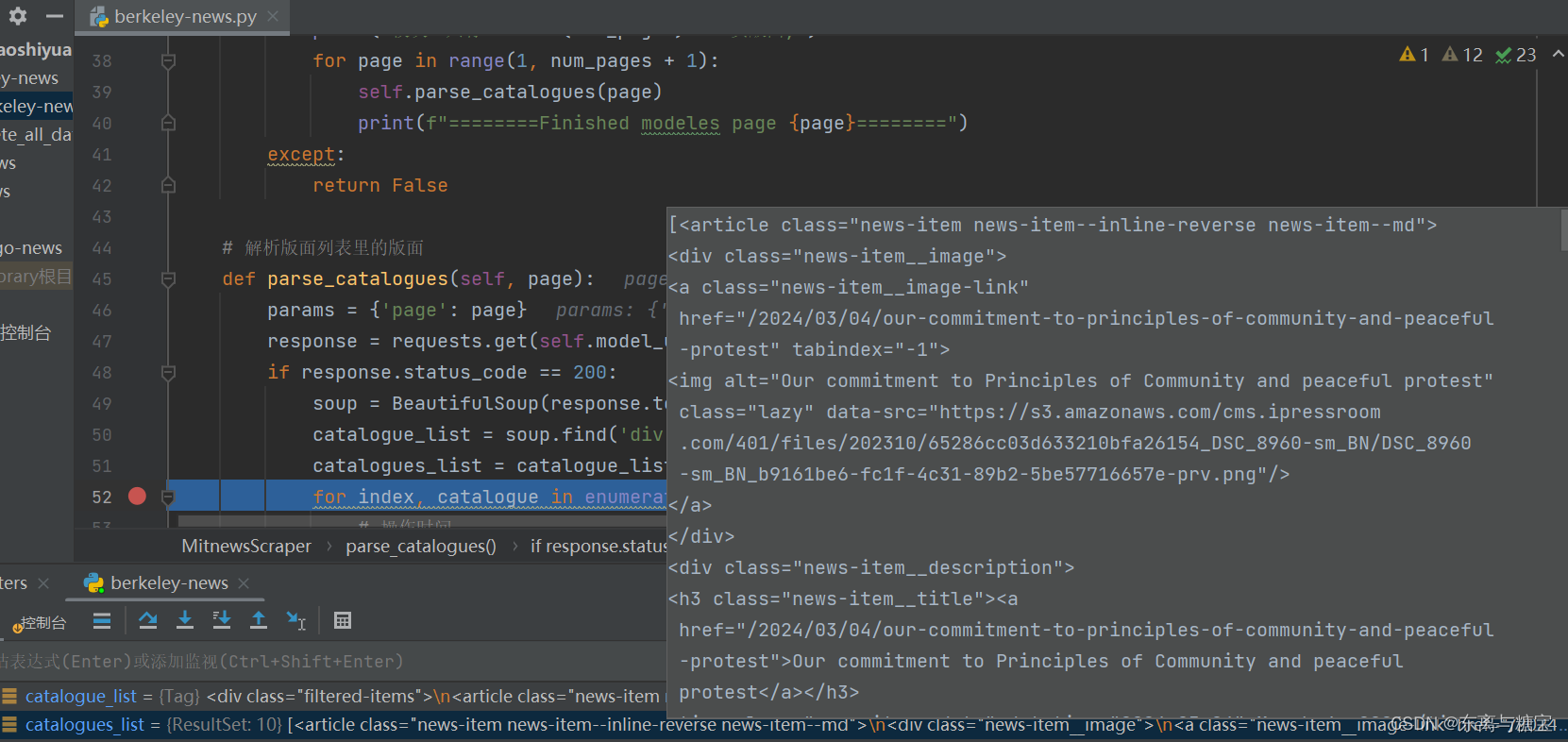
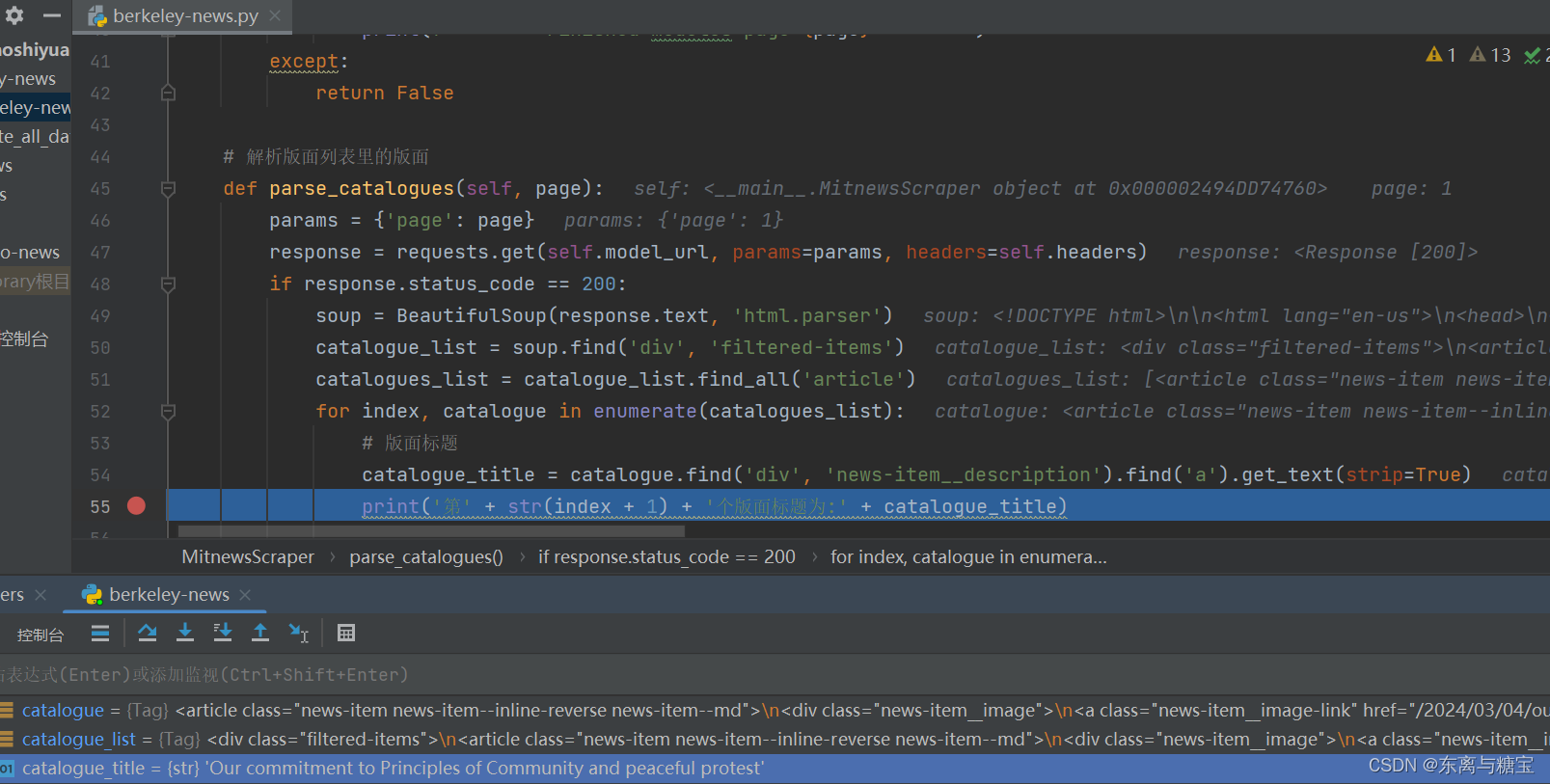
- 遍历版面列表,获取版面标题
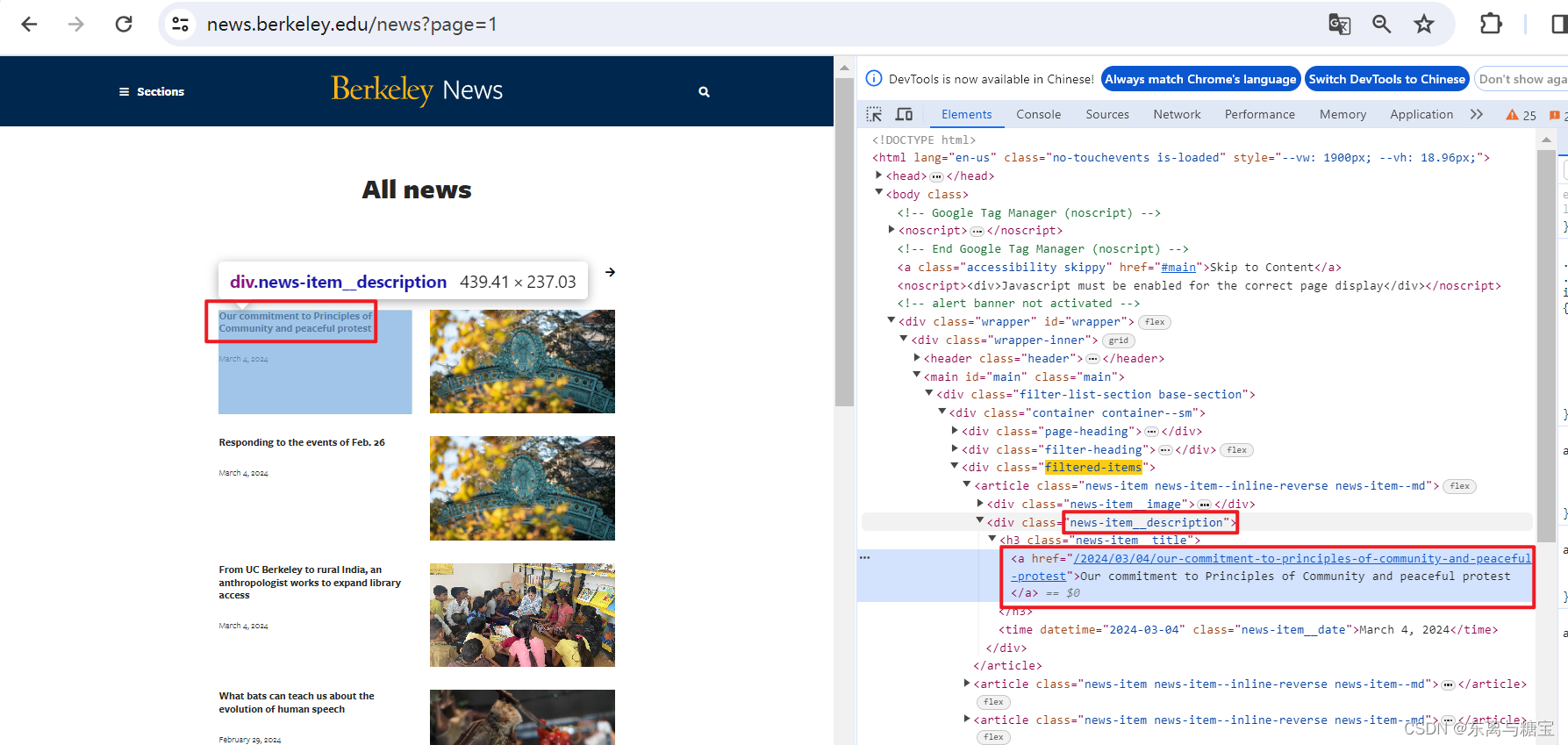
for index, catalogue in enumerate(catalogues_list):# 版面标题catalogue_title = catalogue.find('div', 'news-item__description').find('a').get_text(strip=True)print('第' + str(index + 1) + '个版面标题为:' + catalogue_title)
- 获取版面更新时间和当下的操作时间
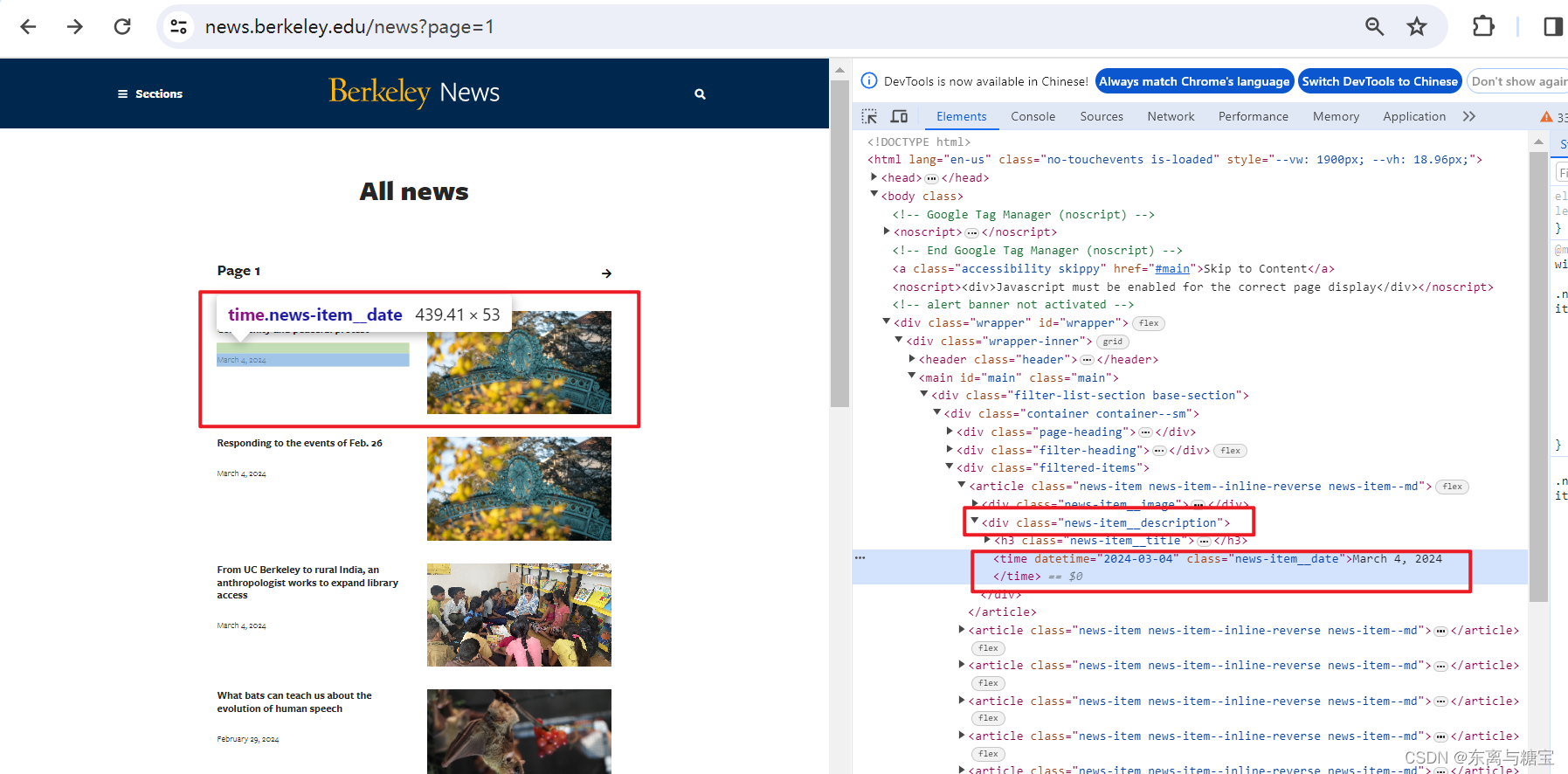
# 操作时间date = datetime.now()# 更新时间publish_time = catalogue.find('div', 'news-item__description').find('time').get('datetime')# 将日期字符串转换为datetime对象updatetime = datetime.strptime(publish_time, '%Y-%m-%d')
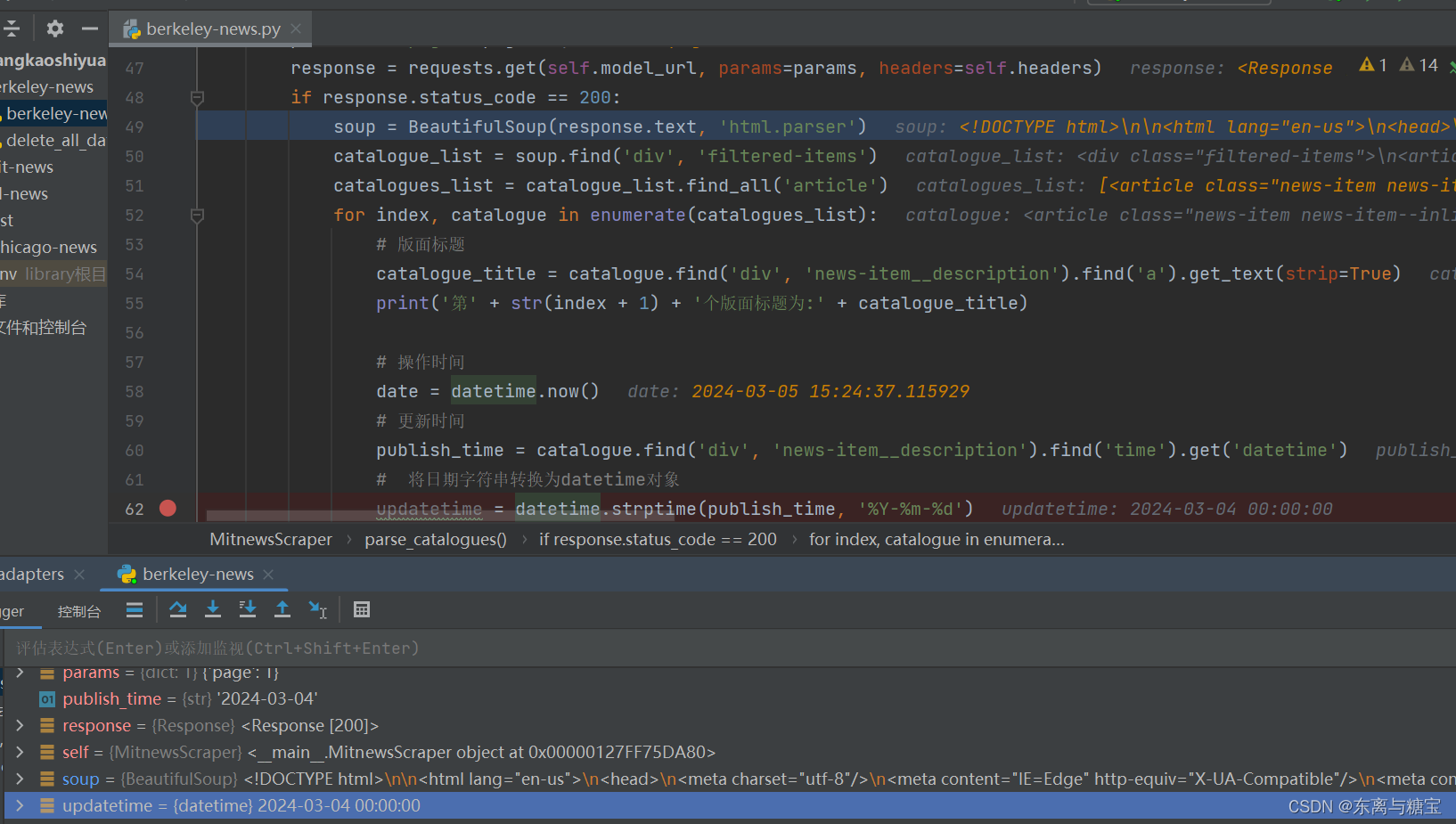
- 保存版面url和版面id, 由于该新闻是一个版面对应一篇文章,所以版面url和文章url是一样的,而且文章没有明显的标识,我们把地址后缀作为文章id,版面id则是文章id后面加上个01, 为了避免标题重复也可以把日期前缀也加上去
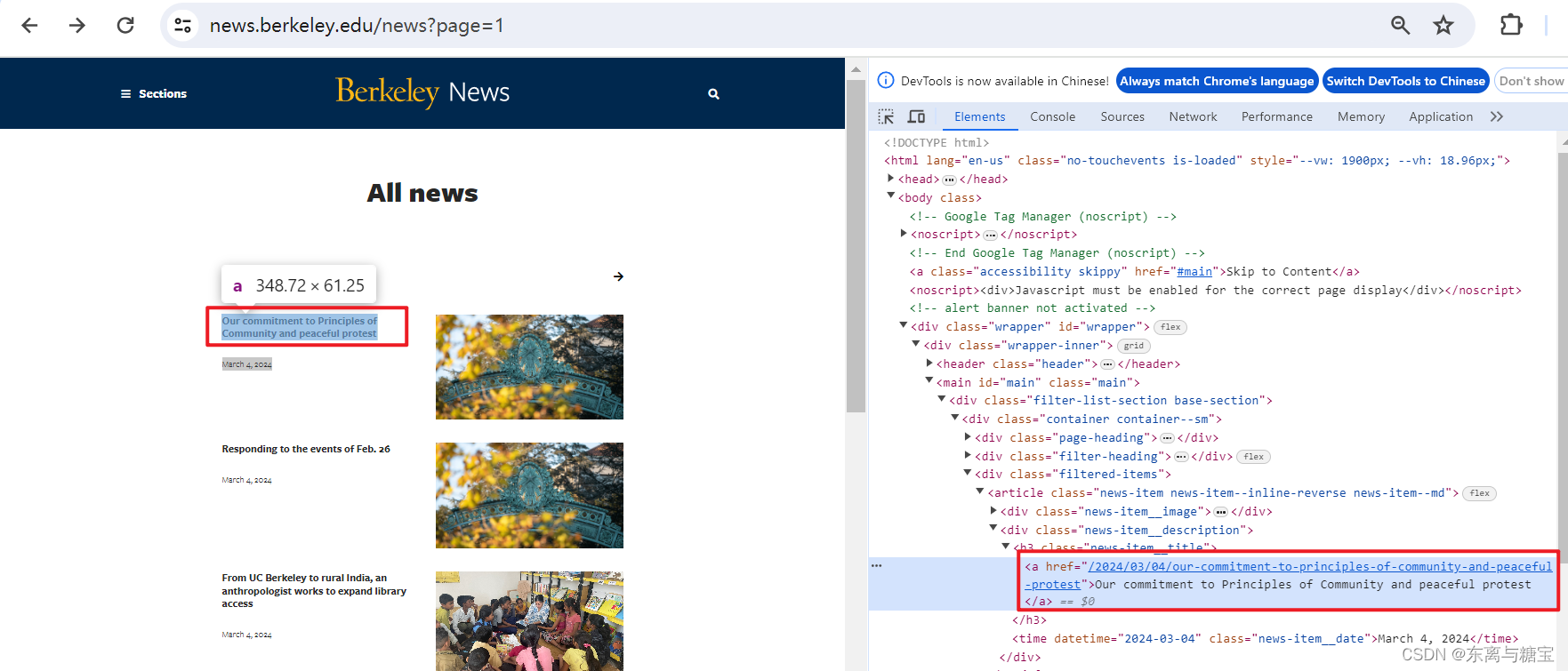
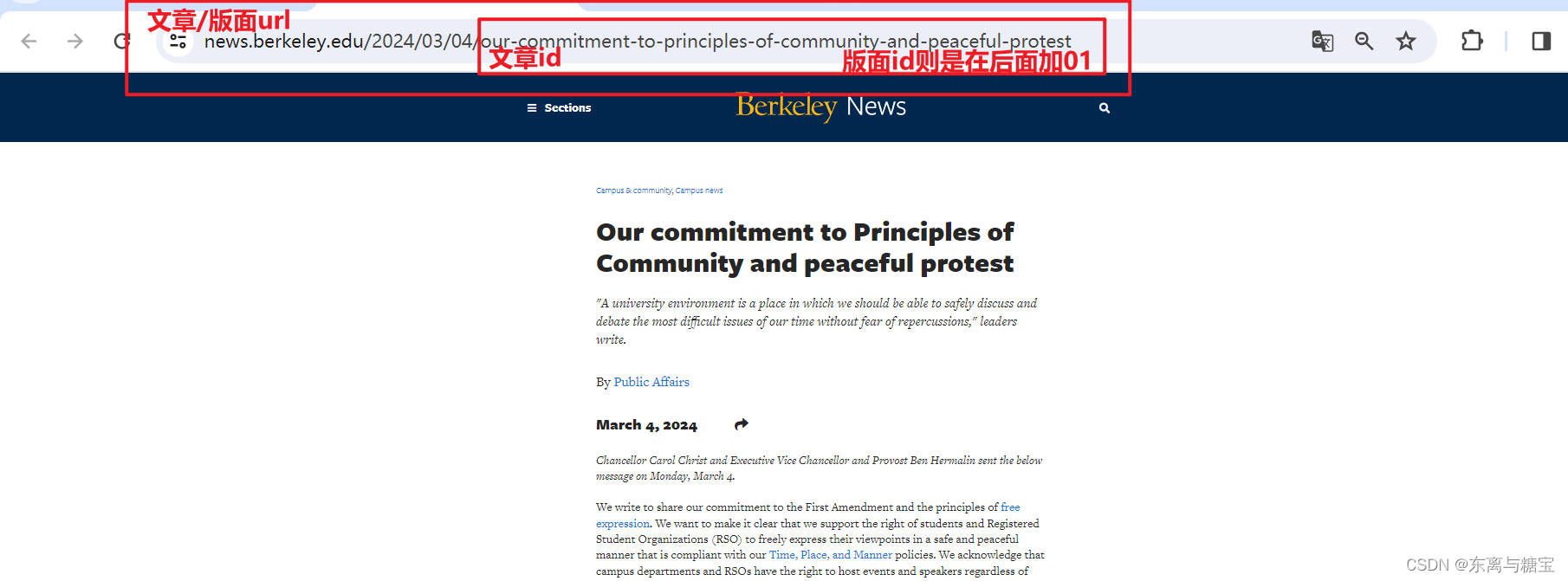
# 版面urlcatalogue_href = catalogue.find('div', 'news-item__description').find('a').get('href')catalogue_url = self.root_url + catalogue_href# 版面idcatalogue_id = catalogue_href[1:]print('第' + str(index + 1) + '个版面地址为:' + catalogue_url)
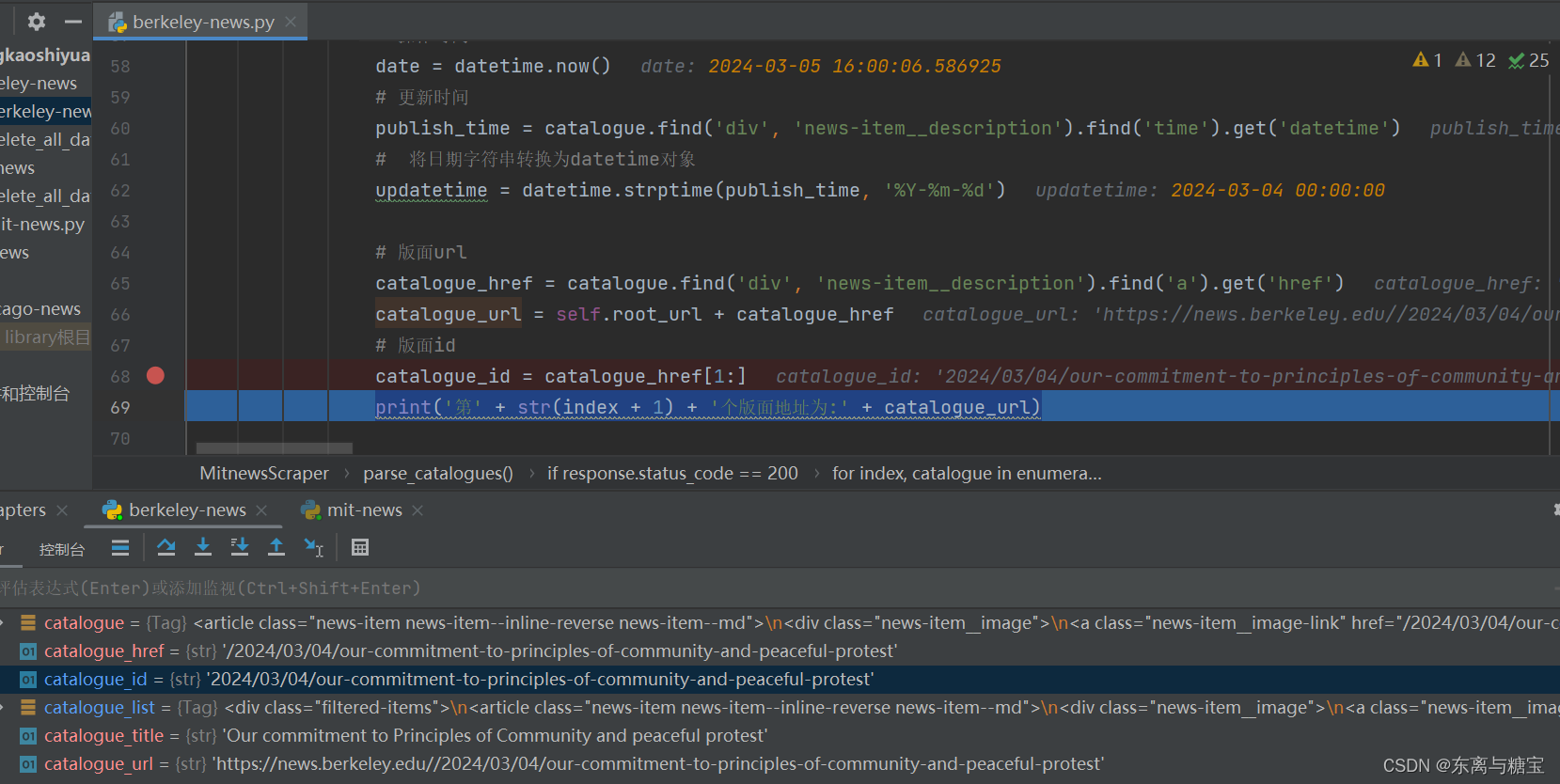
- 保存版面信息到mogodb数据库(由于每个版面只有一篇文章,所以版面文章数量cardsize的值赋为1)
# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['berkeley-news']# 创建或选择集合catalogues_collection = db['catalogues']# 插入示例数据到 catalogues 集合catalogue_data = {'id': catalogue_id + '01','date': date,'title': catalogue_title,'url': catalogue_url,'cardSize': 1,'updatetime': updatetime}
3. 爬取文章
-
由于一个版面对应一篇文章,所以版面url 、更新时间、标题和文章是一样的,并且按照设计版面id和文章id的区别只是差了个01,所以可以传递版面url、版面id、更新时间和标题四个参数到解析文章的函数里面
-
获取文章id,文章url,文章更新时间和当下操作时间
# 解析版面
def parse_catalogues(self, page):
...self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)
...# 解析文章def parse_cards_list(self, url, catalogue_id, updatetime, cardtitle):card_response = requests.get(url, headers=self.headers)soup = BeautifulSoup(card_response.text, 'html.parser')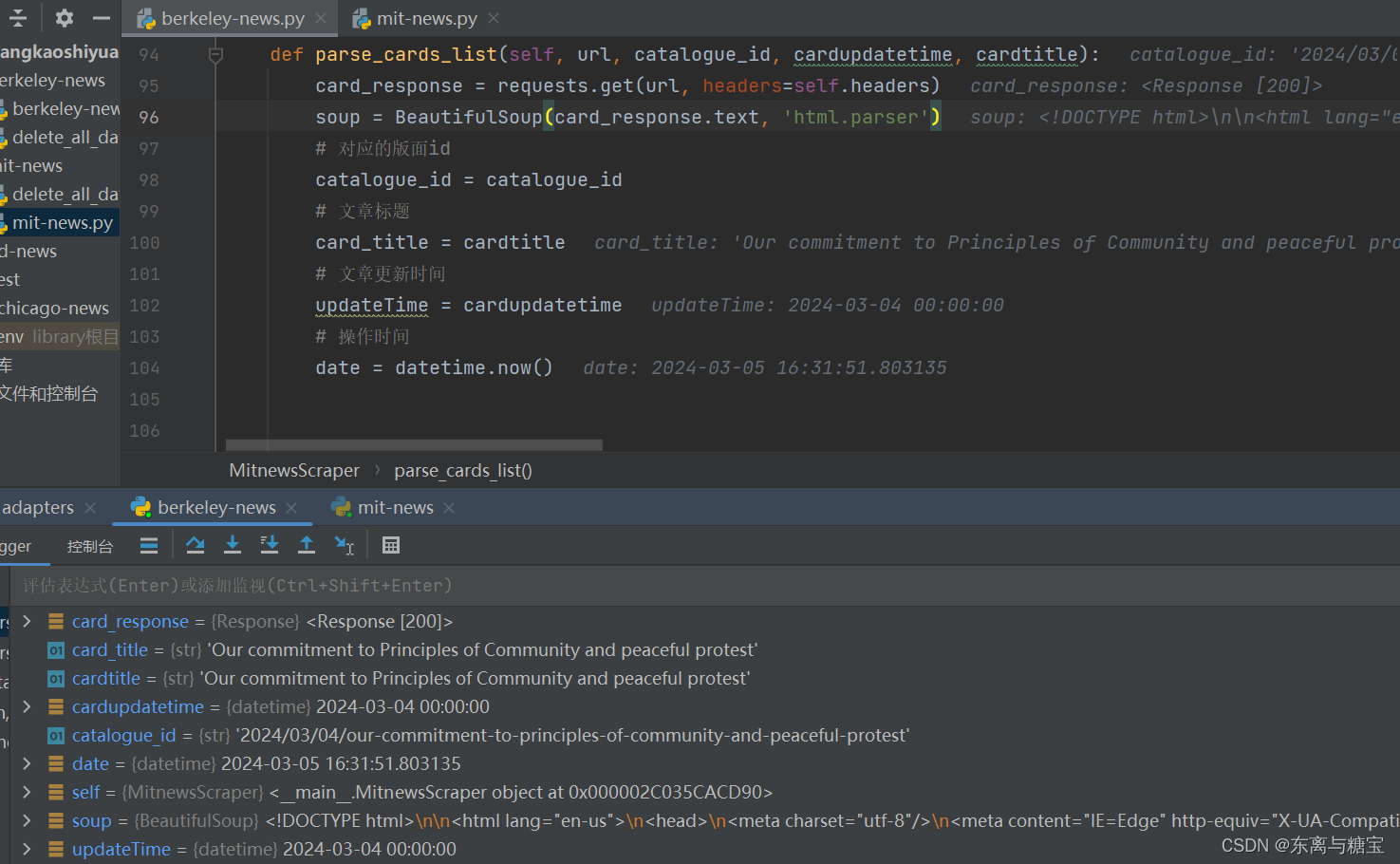
- 获取文章作者
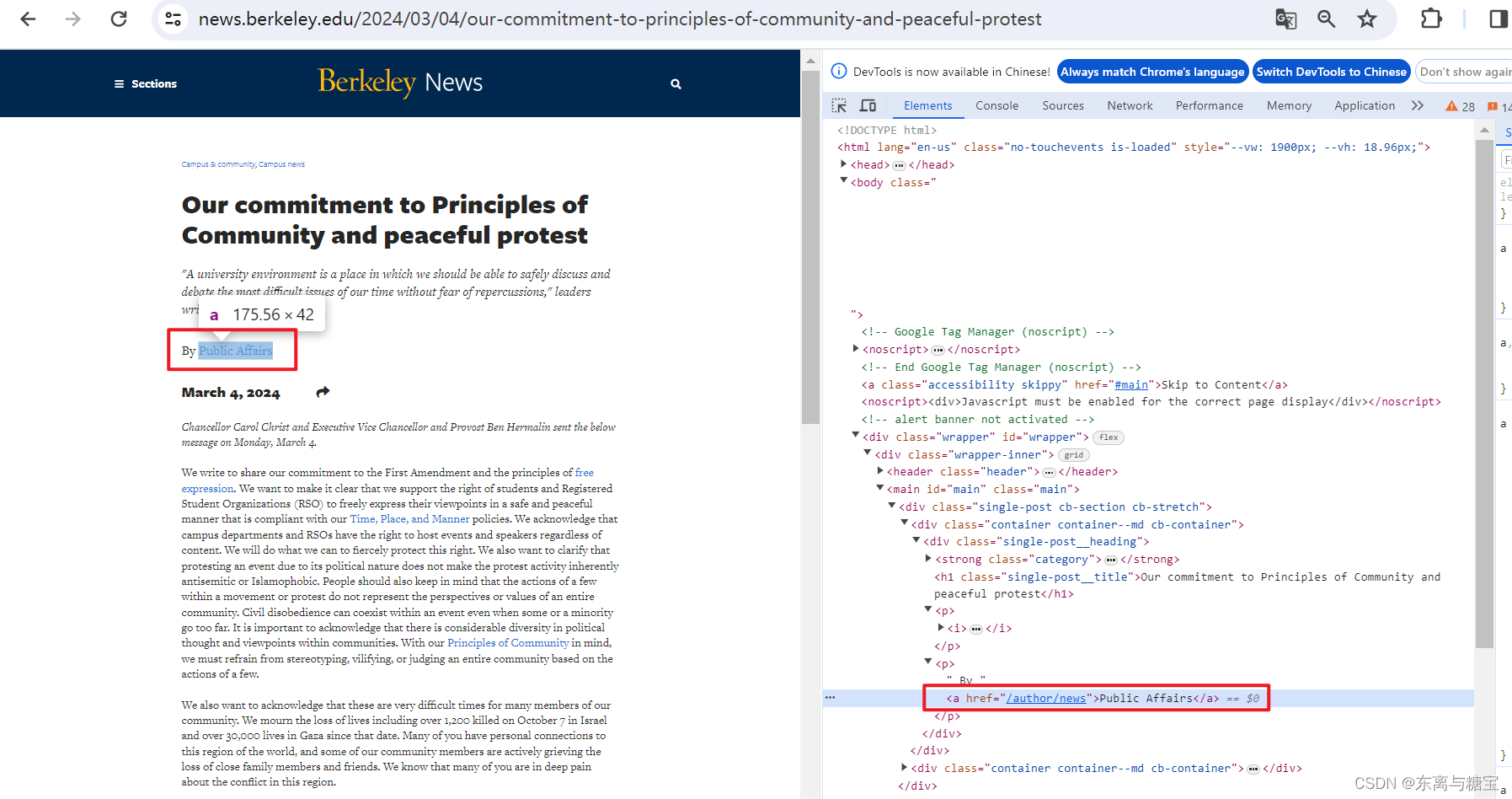
# 文章作者author = soup.find('a', href='/author/news').get_text()
- 获取文章原始htmldom结构,并删除无用的部分(以下仅是部分举例),用html_content字段保留原始dom结构
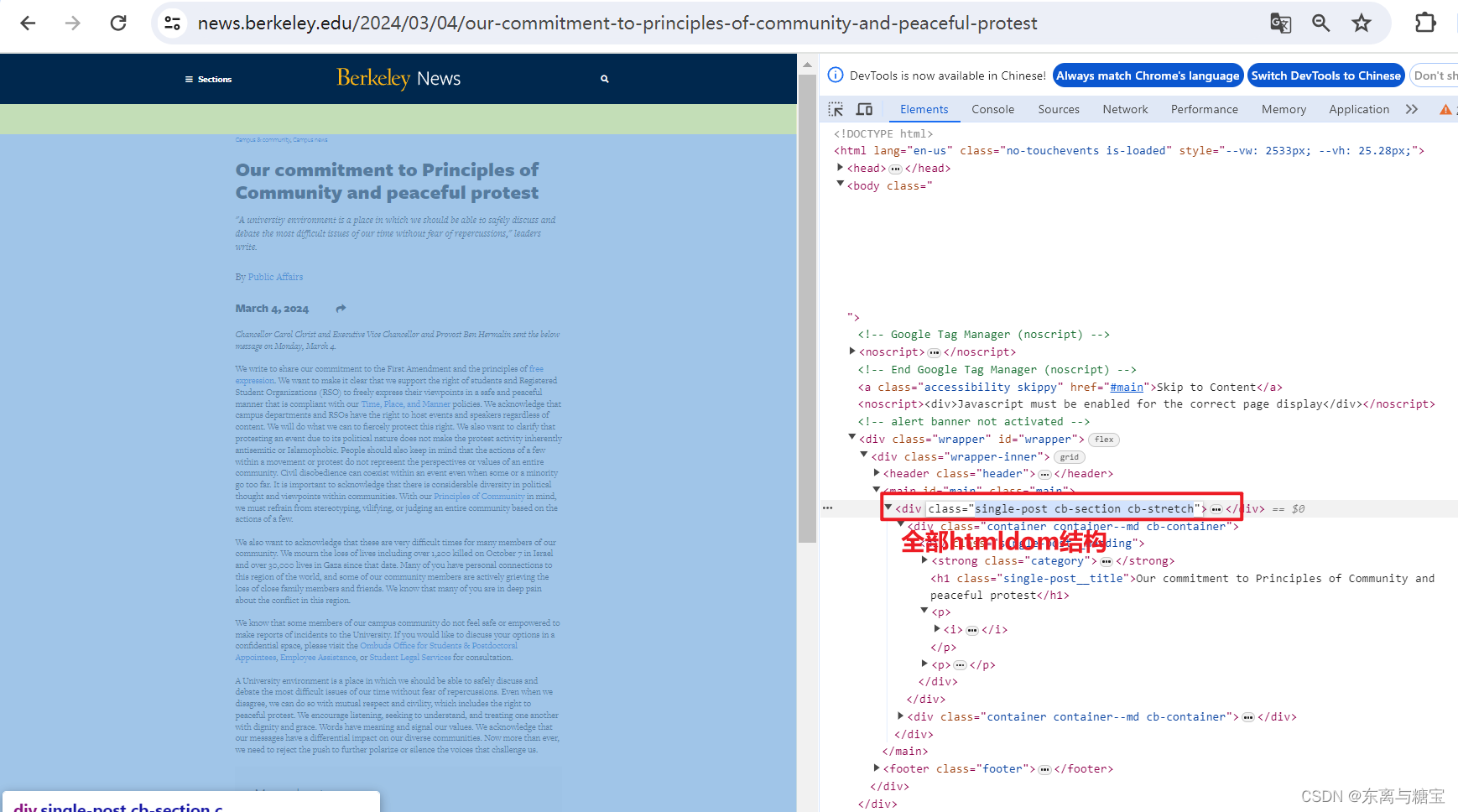
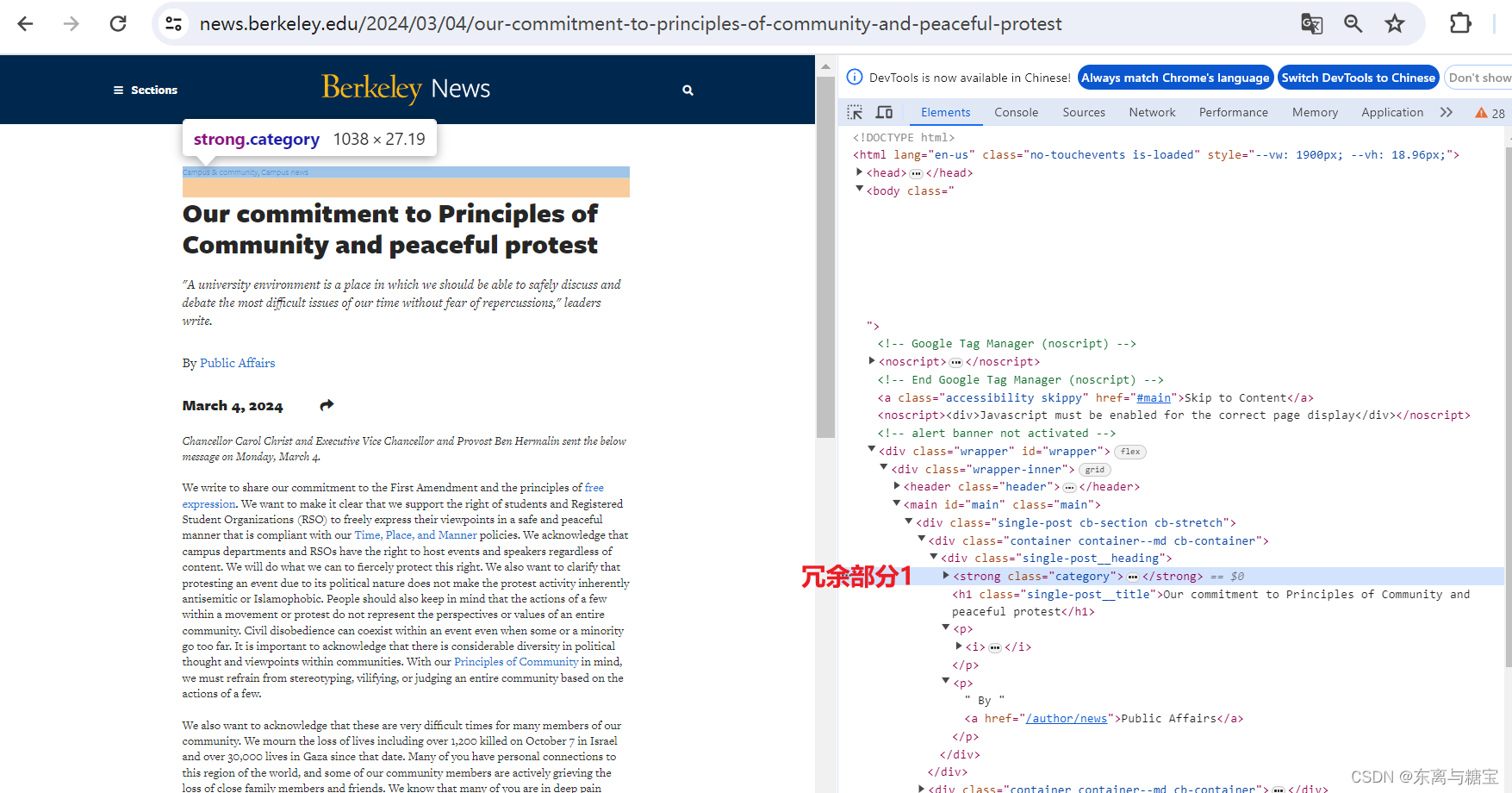
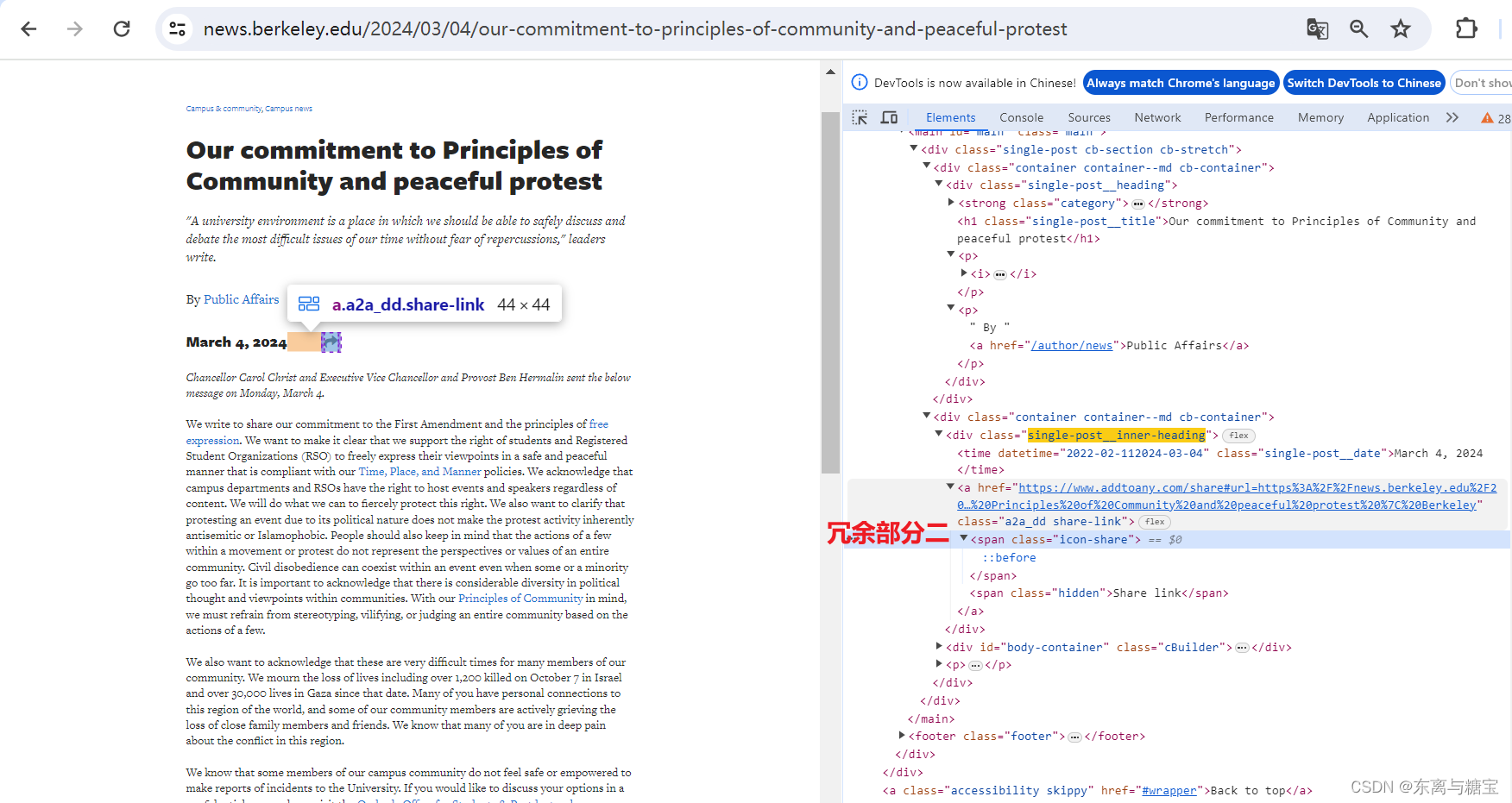
# 原始htmldom结构html_dom = soup.find('div', 'single-post cb-section cb-stretch')# 标题上方的冗余html_cut1 = html_dom.find('div', 'single-post__heading').find('strong')# 链接冗余html_cut2 = html_dom.find_all('a', 'a2a_dd share-link')# 移除元素if html_cut1:html_cut1.extract()if html_cut2:for item in html_cut2:item.extract()html_content = html_dom
- 进行文章清洗,保留文本,去除标签,用content保留清洗后的文本
# 解析文章列表里的文章def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):...# 增加保留html样式的源文本origin_html = html_dom.prettify() # String# 转义网页中的图片标签str_html = self.transcoding_tags(origin_html)# 再包装成temp_soup = BeautifulSoup(str_html, 'html.parser')# 反转译文件中的插图str_html = self.translate_tags(temp_soup.text)# 绑定更新内容content = self.clean_content(str_html)# 工具 转义标签def transcoding_tags(self, htmlstr):re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义return s# 工具 转义标签def translate_tags(self, htmlstr):re_img = re.compile(r'@@##(img.*?)##@@', re.M)s = re_img.sub(r'<\1>', htmlstr) # IMG 转义return s# 清洗文章def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)content = content.replace('<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')content = content.replace(''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''','') \.replace(' <!--enpcontent', '').replace('<TABLE>', '')content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return content
- 下载保存图片
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):...imgs = []img_array = soup.find('figure', 'cb-image cb-float--none cb-float--none--md cb-float--none--lg cb-100w cb-100w--md cb-100w--lg new-figure').find_all('img')for item in img_array:img_url = item.get('src')imgs.append(img_url)if len(imgs) != 0:# 下载图片illustrations = self.download_images(imgs, card_id)# 下载图片def download_images(self, img_urls, card_id):result = re.search(r'[^/]+$', card_id)last_word = result.group(0)# 根据card_id创建一个新的子目录images_dir = os.path.join(self.img_output_dir, str(last_word))if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for index, img_url in enumerate(img_urls):try:response = requests.get(img_url, stream=True, headers=self.headers)if response.status_code == 200:# 从URL中提取图片文件名img_name_with_extension = img_url.split('/')[-1]pattern = r'^[^?]*'match = re.search(pattern, img_name_with_extension)img_name = match.group(0)# 保存图片with open(os.path.join(images_dir, img_name), 'wb') as f:f.write(response.content)downloaded_images.append([img_url, os.path.join(images_dir, img_name)])except requests.exceptions.RequestException as e:print(f'请求图片时发生错误:{e}')except Exception as e:print(f'保存图片时发生错误:{e}')return downloaded_images# 如果文件夹存在则跳过else:print(f'文章id为{card_id}的图片文件夹已经存在')return []
- 保存文章数据
# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['berkeley-news']# 创建或选择集合cards_collection = db['cards']# 插入示例数据到 catalogues 集合card_data = {'id': card_id,'catalogueId': catalogue_id,'type': 'berkeley-news','date': date,'title': card_title,'author': author,'updatetime': updateTime,'url': url,'html_content': str(html_content),'content': content,'illustrations': illustrations,}cards_collection.insert_one(card_data)四、完整代码
import os
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import re
import tracebackclass MitnewsScraper:def __init__(self, root_url, model_url, img_output_dir):self.root_url = root_urlself.model_url = model_urlself.img_output_dir = img_output_dirself.headers = {'Referer': 'https://news.berkeley.edu/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/122.0.0.0 Safari/537.36','Cookie': '替换成你自己的',}# 获取一个模块有多少版面def catalogue_all_pages(self):response = requests.get(self.model_url, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')try:match = re.search(r'of (\d+)', soup.text)num_pages = int(match.group(1))print('模块一共有' + str(num_pages) + '页版面')for page in range(1, num_pages + 1):print(f"========start catalogues page {page}" + "/" + str(num_pages) + "========")self.parse_catalogues(page)print(f"========Finished catalogues page {page}" + "/" + str(num_pages) + "========")except Exception as e:print(f'Error: {e}')traceback.print_exc()# 解析版面列表里的版面def parse_catalogues(self, page):params = {'page': page}response = requests.get(self.model_url, params=params, headers=self.headers)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')catalogue_list = soup.find('div', 'filtered-items')catalogues_list = catalogue_list.find_all('article')for index, catalogue in enumerate(catalogues_list):print(f"========start catalogue {index+1}" + "/" + "10========")# 版面标题catalogue_title = catalogue.find('div', 'news-item__description').find('a').get_text(strip=True)# 操作时间date = datetime.now()# 更新时间publish_time = catalogue.find('div', 'news-item__description').find('time').get('datetime')# 将日期字符串转换为datetime对象updatetime = datetime.strptime(publish_time, '%Y-%m-%d')# 版面urlcatalogue_href = catalogue.find('div', 'news-item__description').find('a').get('href')catalogue_url = self.root_url + catalogue_href# 版面idcatalogue_id = catalogue_href[1:]self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['berkeley-news']# 创建或选择集合catalogues_collection = db['catalogues']# 插入示例数据到 catalogues 集合catalogue_data = {'id': catalogue_id,'date': date,'title': catalogue_title,'url': catalogue_url,'cardSize': 1,'updatetime': updatetime}# 在插入前检查是否存在相同id的文档existing_document = catalogues_collection.find_one({'id': catalogue_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:catalogues_collection.insert_one(catalogue_data)print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")else:print("[爬取版面]版面 " + catalogue_url + " 已存在!")print(f"========finsh catalogue {index+1}" + "/" + "10========")return Trueelse:raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")# 解析文章列表里的文章def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):url = 'https://news.berkeley.edu/2024/03/05/meet-our-new-faculty-antoine-levy-economics'card_response = requests.get(url, headers=self.headers)soup = BeautifulSoup(card_response.text, 'html.parser')# 对应的版面idcard_id = catalogue_id# 文章标题card_title = cardtitle# 文章更新时间updateTime = cardupdatetime# 操作时间date = datetime.now()# 文章作者try:author = soup.find('a', href='/author/news').get_text()except:author = soup.find('div', 'single-post__heading').find('p').find('a').get_text()# 原始htmldom结构html_dom = soup.find('div', 'single-post cb-section cb-stretch')# 标题上方的冗余html_cut1 = html_dom.find('div', 'single-post__heading').find('strong')# 链接冗余html_cut2 = html_dom.find_all('a', 'a2a_dd share-link')# 移除元素if html_cut1:html_cut1.extract()if html_cut2:for item in html_cut2:item.extract()html_content = html_dom# 增加保留html样式的源文本origin_html = html_dom.prettify() # String# 转义网页中的图片标签str_html = self.transcoding_tags(origin_html)# 再包装成temp_soup = BeautifulSoup(str_html, 'html.parser')# 反转译文件中的插图str_html = self.translate_tags(temp_soup.text)# 绑定更新内容content = self.clean_content(str_html)# 下载图片imgs = []try:img_array = soup.find('figure', 'cb-image cb-float--none cb-float--none--md cb-float--none--lg cb-100w cb-100w--md cb-100w--lg new-figure').find_all('img')except:img_array = soup.find('div', 'container container--lg cb-container').find_all('img')if len(img_array) is not None:for item in img_array:img_url = item.get('src')if img_url is None:img_url = item.get('data-src')imgs.append(img_url)if len(imgs) != 0:# 下载图片illustrations = self.download_images(imgs, card_id)# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['berkeley-news']# 创建或选择集合cards_collection = db['cards']# 插入示例数据到 cards 集合card_data = {'id': card_id,'catalogueId': catalogue_id,'type': 'berkeley-news','date': date,'title': card_title,'author': author,'updatetime': updateTime,'url': url,'html_content': str(html_content),'content': content,'illustrations': illustrations,}# 在插入前检查是否存在相同id的文档existing_document = cards_collection.find_one({'id': card_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:cards_collection.insert_one(card_data)print("[爬取文章]文章 " + url + " 已成功插入!")else:print("[爬取文章]文章 " + url + " 已存在!")# 下载图片def download_images(self, img_urls, card_id):result = re.search(r'[^/]+$', card_id)last_word = result.group(0)# 根据card_id创建一个新的子目录images_dir = os.path.join(self.img_output_dir, str(last_word))if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for index, img_url in enumerate(img_urls):try:response = requests.get(img_url, stream=True, headers=self.headers)if response.status_code == 200:# 从URL中提取图片文件名img_name_with_extension = img_url.split('/')[-1]pattern = r'^[^?]*'match = re.search(pattern, img_name_with_extension)img_name = match.group(0)# 保存图片with open(os.path.join(images_dir, img_name), 'wb') as f:f.write(response.content)downloaded_images.append([img_url, os.path.join(images_dir, img_name)])print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')except requests.exceptions.RequestException as e:print(f'请求图片时发生错误:{e}')except Exception as e:print(f'保存图片时发生错误:{e}')return downloaded_images# 如果文件夹存在则跳过else:print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')return []# 工具 转义标签def transcoding_tags(self, htmlstr):re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义return s# 工具 转义标签def translate_tags(self, htmlstr):re_img = re.compile(r'@@##(img.*?)##@@', re.M)s = re_img.sub(r'<\1>', htmlstr) # IMG 转义return s# 清洗文章def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)content = content.replace('<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')content = content.replace(''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''','') \.replace(' <!--enpcontent', '').replace('<TABLE>', '')content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return contentdef run():# 根路径root_url = 'https://news.berkeley.edu/'# 模块地址数组model_urls = ['https://news.berkeley.edu/news']# 文章图片保存路径output_dir = 'D://imgs//berkeley-news'for model_url in model_urls:scraper = MitnewsScraper(root_url, model_url, output_dir)scraper.catalogue_all_pages()if __name__ == "__main__":run()五、效果展示
相关文章:
初级爬虫实战——伯克利新闻
文章目录 发现宝藏一、 目标二、简单分析网页1. 寻找所有新闻2. 分析模块、版面和文章 三、爬取新闻1. 爬取模块2. 爬取版面3. 爬取文章 四、完整代码五、效果展示 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不…...

WPF资源的继承
假设这里有一个全局的资源 <Style TargetType"TextBlock"><Setter Property"FontSize" Value"40"/> </Style> 这是时候有些控件可能需要一个样式在这个基础上加一点内容的 <Style x:Key"textBlockStyle" Targ…...

linux网络通信(TCP)
TCP通信 1.socket----->第一个socket 失败-1,错误码 参数类型很多,man查看 2.connect 由于s_addr需要一个32位的数,使用下面函数将点分十进制字符串ip地址以网络字节序转换成32字节数值 同理端口号也有一个转换函数 我们的端口号位两个字…...
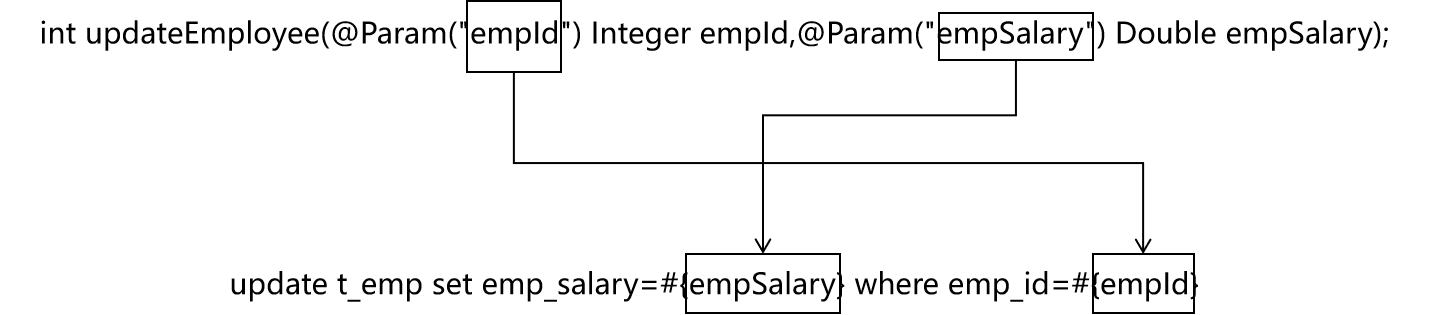
Mybatis 多个简单类型参数传入sql语句
如果只有一个简单类型的参数传入sql语句,我们可以在在#{}中可以随意命名,都可以获取到数据。但通常与接口方法中的参数同名。 但是如果有多个简单类型参数,如果没有特殊处理,那么Mybatis无法根据参数名获取数据。 正确获取方式如…...

SpringCloud OpenFeign 服务接口调用
一、前言 接下来是开展一系列的 SpringCloud 的学习之旅,从传统的模块之间调用,一步步的升级为 SpringCloud 模块之间的调用,此篇文章为第四篇,即介绍 Feign 和 OpenFeign 服务接口调用。 二、概述 2.1 Feign 是什么 Feign 是一…...

WAP网站商业计划书(附下载)
这份文件“WAP网站商业计划书.zip”详细阐述了一个由富有创造力和远见的大学生团队构思的创业项目。这个计划旨在开发并运营一个专注于无线应用协议(WAP)技术的网站,以服务于移动设备用户群体,提供一个易于访问、功能丰富且用户体…...

【存储】ZYNQ+NVMe小型化全国产存储解决方案
文章目录 1、背景2、基础理论3、设计方案3.1、FPGA设计方案3.1.1、NVMe控制器实现3.1.2、NVMe控制器实现 3.2 驱动软件设计方案3.2.1 读写NVMe磁盘软件驱动3.2.2 NVMe磁盘驱动设计3.2.3 标准EXT4文件系统设计 3.3 上位机控制软件设计方案 4、测试结果4.1 硬件测试平台说明4.2 测…...

数据结构之栈详解(C语言手撕)
🎉个人名片: 🐼作者简介:一名乐于分享在学习道路上收获的大二在校生 🙈个人主页🎉:GOTXX 🐼个人WeChat:ILXOXVJE 🐼本文由GOTXX原创,首发CSDN&…...
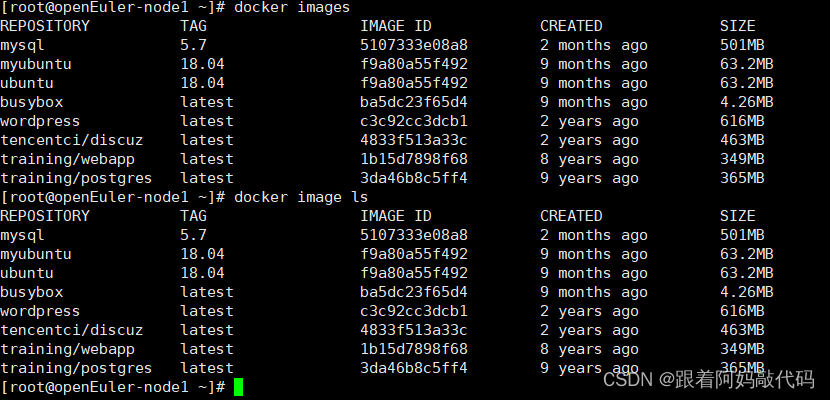
Docker学习——Dock镜像
什么是Docker镜像 Docker 镜像类似于虚拟机镜像,可以将它理解为一个只读的模板。 一个镜像可以包含一个基本的操作系统环境,里面仅安装了 Apache 应用程序(或 用户需要的其他软件) 可以把它称为一个 Apache 镜像。镜像是创建 Do…...

CorelDRAW Graphics Suite2024专业图形设计软件Windows/Mac最新25.0.0.230版
CorelDRAW Graphics Suite 2024是一款专业的图形设计软件,它集成了CorelDRAW Standard 2024和其他高级图形处理工具,为用户提供了全面的图形设计和编辑解决方案。 该软件拥有强大的矢量编辑功能,用户可以轻松创建和编辑矢量图形,…...

el-form表单中,对非表单内字段增加校验的方法
1、问题说明: 在开发表单的时候,可能会遇到el-form-item中绑定的值不在表单绑定的数据对象中。 此时用prop绑定该字段名是无效的,需要单独对这个字段进行校验。 在el-form-item中有一个属性 error 。用于表单域验证错误信息,设…...
【VTKExamples::Points】第四期 ExtractEnclosedPoints
很高兴在雪易的CSDN遇见你 VTK技术爱好者 QQ:870202403 公众号:VTK忠粉 前言 本文分享VTK样例ExtractEnclosedPoints,并解析接口vtkExtractEnclosedPoints,希望对各位小伙伴有所帮助! 感谢各位小伙伴的点赞+关注,小易会继续努力分享,一起进步! 你的点赞就是我…...
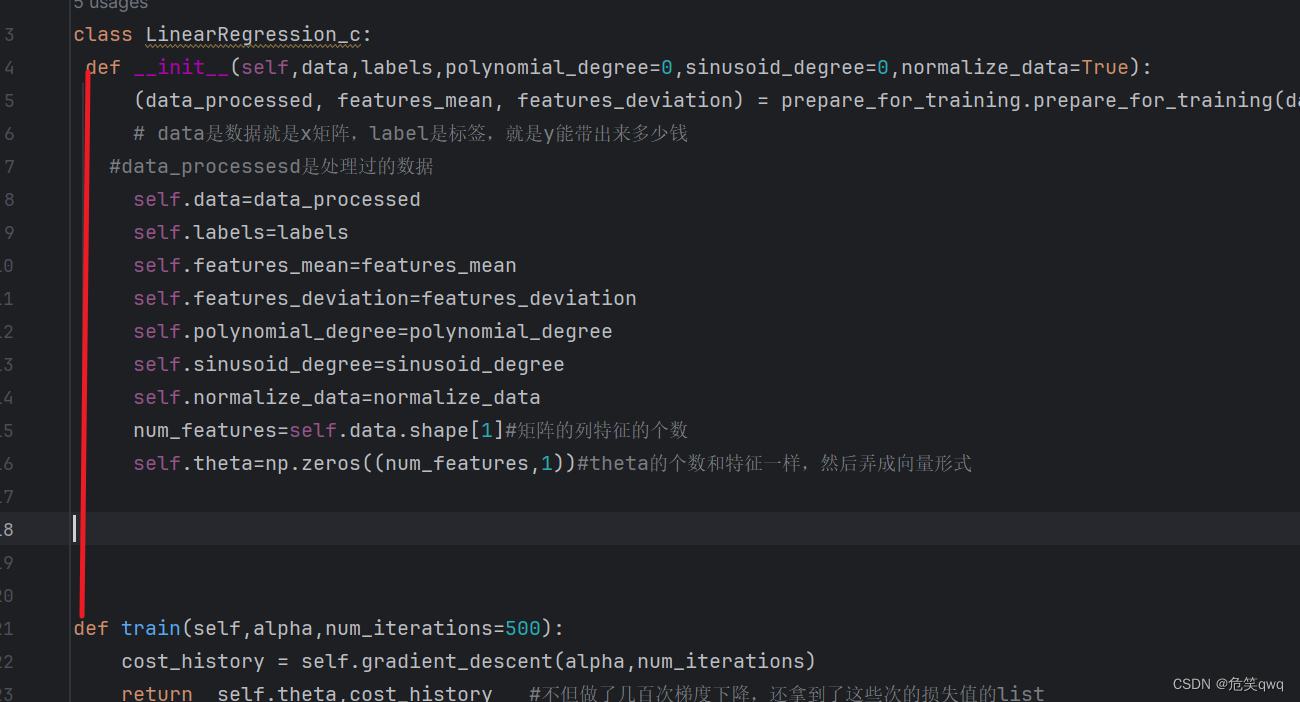
bug--xxoobject has no attribute xxx
Python 创建类的实例后却不能调用写的方法,检查了半天原来是缩进的问题,def函数不应该和class并列 只能说这个英文空格太小了,看不出来。。。。...

7 BUILD.gn文件怎么写,Gn + Ninja编译一个Hello world程序的例子Demo
BUILD.gn文件怎么写,Gn Ninja编译一个Hello world程序的例子Demo 作者将狼才鲸创建日期2024-03-11 Ninja安装流程见:一个能直接运行的Ninja例子,build.ninja文件怎么写?Gn安装流程见:Ubuntu18.04下安装Gn软件 这是一…...
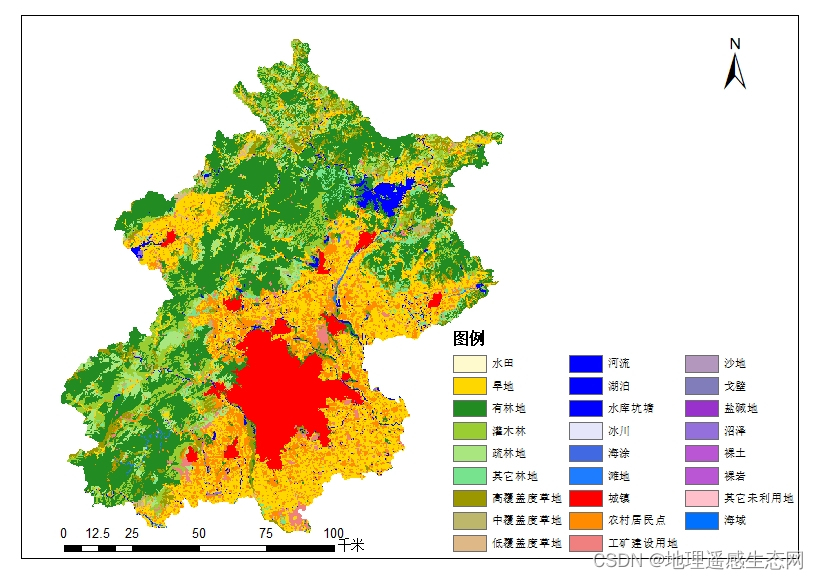
北京市行政村边界shp数据/北京市乡镇边界/北京市土地利用分类数据
北京是一座有着三千多年历史的古都,在不同的朝代有着不同的称谓,大致算起来有二十多个别称。北京地势西北高、东南低。西部、北部和东北部三面环山,东南部是一片缓缓向渤海倾斜的平原。境内流经的主要河流有:永定河、潮白河、北运…...

力扣--动态规划/深度优先算法/回溯算法93.复原IP地址
这题主要用了动态规划和回溯算法。 动态规划数组初始化(DP数组): 首先,创建一个二维数组dp,用于记录字符串中哪些部分是合法的IP地址。对字符串进行遍历,同时考虑每个可能的IP地址部分(每部分由1到3个字符组…...

第一次Python小练习题目
1.打印某学校的校训,具体内容如下所示: ****************************** 勤奋 严谨 求实 创新 ****************************** 注意: 第一行和最后一行各有 30 个*号。 答案: school_strs "勤奋 严谨 求实 创新&q…...
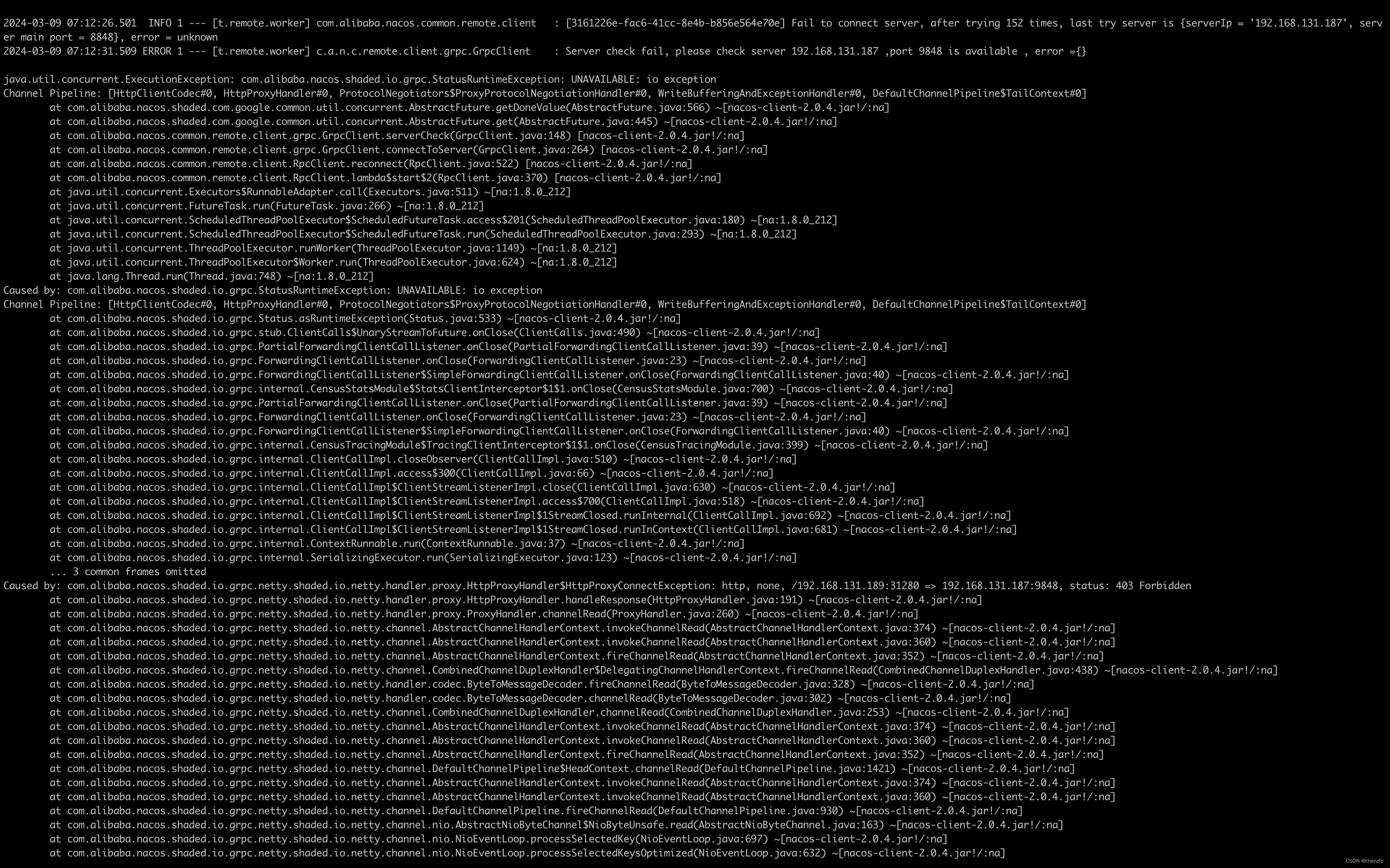
[BUG] docker运行Java程序时配置代理-Dhttp.proxyHost后启动报错
[BUG] docker运行Java程序时配置代理-Dhttp.proxyHost后启动报错 bug现象描述 版本:2.0.4(客户端和服务端都是) 环境:私有云环境,只有少量跳板机器可以访问公网,其他机器均通过配置代理方式访问公网 bug现…...

Python网站的搭建和html基础
1.Python网站代码及讲解 一般我们搭建小型的网站就用flask库就行了。 (1)安装flask库 安装完python后,按住windows徽标键和r,弹出“运行”,在里面输入cmd。 回车打开,输入“pip install flask”。 (2&am…...
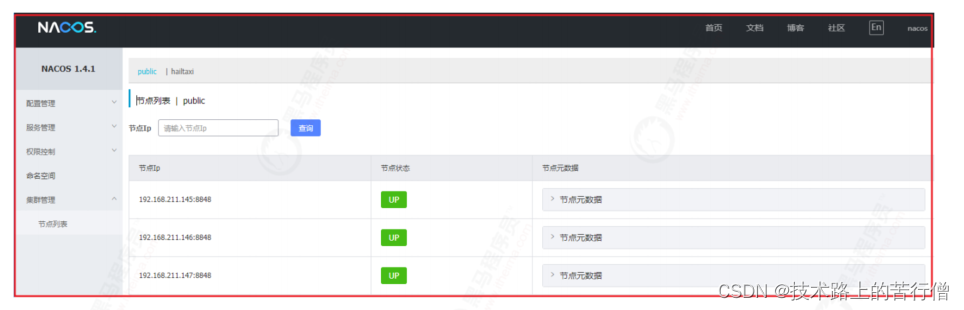
SpringCloud(21)之SpringCloud Alibaba Nacos实战应用
一、Nacos安装 1.1 Nacos概述 Nacos是Alibaba微服务生态组件中的重要组件之一,主要用它实现应用的动态服务发现、配置管理、 服务管理。Nacos discovery alibaba/spring-cloud-alibaba Wiki GitHub Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

taotoken用量看板如何帮助团队精细化管理api调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken用量看板如何帮助团队精细化管理api调用成本 对于团队管理者而言,将大模型能力集成到产品开发或业务流程中&am…...

智能烹饪助手:基于传感器融合与AI的厨房自动化实践
1. 项目概述:一个让厨房小白也能自信下厨的智能伙伴每次站在灶台前,你是不是也经历过这样的场景:一边手忙脚乱地翻着菜谱,一边担心锅里的菜是不是快糊了,还要分心去计算各种调料该放多少?对于很多刚接触烹饪…...

SpringBoot WebClient 介绍
目录一、什么是 WebClient?二、 WebClient 能解决什么问题?三、WebClient 和 RestTemplate 的区别四、WebClient 的核心优势1. 非阻塞(Non-Blocking)2. 支持异步3. 链式 API 更现代五、WebClient 的核心对象六、Mono 和 Flux 是什…...