强化学习工具箱(Matlab)
1、Get Started
1.1、MDP环境下训练强化学习智能体
MDP环境如下图
- 每个圆圈代表一个状态
- 每个状态都有上或下的选择
- 智能体从状态 1 开始
- 智能体接收的奖励值为图中状态转移的值
- 训练目标是最大化累计奖励
(1)创建 MDP 环境
创建一个具有 8 个状态和 2 个动作( " up " 和 " down " )的MDP模型。
MDP = createMDP(8,["up";"down"]);
要对上图中状态转换进行建模,需修改 MDP 的状态转换矩阵和奖励矩阵。默认情况下,这些矩阵均为零。有关创建 MDP 模型和 MDP 对象属性的更多信息,请参见 createMDP 。
修改 MDP 的状态转换和奖励矩阵,例如,在以下命令中:
- 前两行指定了通过执行动作 1( " up " )从状态 1 到状态 2 的转移,以及此转移对应的奖励 +3
- 接下来的两行指定了通过执行操作2( " down " )从状态 1 到状态 3 的转移,以及此转移对应的奖励 +1
MDP.T(1,2,1) = 1;
MDP.R(1,2,1) = 3;
MDP.T(1,3,2) = 1;
MDP.R(1,3,2) = 1;
同理,指定图中其余的状态转移和对应奖励。
% State 2 transition and reward
MDP.T(2,4,1) = 1;
MDP.R(2,4,1) = 2;
MDP.T(2,5,2) = 1;
MDP.R(2,5,2) = 1;
% State 3 transition and reward
MDP.T(3,5,1) = 1;
MDP.R(3,5,1) = 2;
MDP.T(3,6,2) = 1;
MDP.R(3,6,2) = 4;
% State 4 transition and reward
MDP.T(4,7,1) = 1;
MDP.R(4,7,1) = 3;
MDP.T(4,8,2) = 1;
MDP.R(4,8,2) = 2;
% State 5 transition and reward
MDP.T(5,7,1) = 1;
MDP.R(5,7,1) = 1;
MDP.T(5,8,2) = 1;
MDP.R(5,8,2) = 9;
% State 6 transition and reward
MDP.T(6,7,1) = 1;
MDP.R(6,7,1) = 5;
MDP.T(6,8,2) = 1;
MDP.R(6,8,2) = 1;
% State 7 transition and reward
MDP.T(7,7,1) = 1;
MDP.R(7,7,1) = 0;
MDP.T(7,7,2) = 1;
MDP.R(7,7,2) = 0;
% State 8 transition and reward
MDP.T(8,8,1) = 1;
MDP.R(8,8,1) = 0;
MDP.T(8,8,2) = 1;
MDP.R(8,8,2) = 0;
指定状态 7 和状态 8 为 MDP 的终端状态。
MDP.TerminalStates = ["s7";"s8"];
创建强化学习 MDP 环境。
env = rlMDPEnv(MDP);
通过重置函数指定环境的初始状态始终为状态 1,该函数在每次训练或模拟开始时调用。创建一个匿名函数句柄,将初始状态设置为 1。
env.ResetFcn = @() 1;
设置随机数种子。
rng(0)
(2) 创建 Q-Learning 智能体
首先使用 MDP 环境中的观察和动作创建 Q table,将学习率设置为1。
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);
qTable = rlTable(obsInfo, actInfo);
qFunction = rlQValueFunction(qTable, obsInfo, actInfo);
qOptions = rlOptimizerOptions(LearnRate=1);
然后使用 Q table 创建一个 Q-learning 智能体,遵循 ϵ \epsilon ϵ-贪婪策略。有关创建 Q-learning 智能体的更多信息,请参阅 rlQAgent 和 rlQAgentOptions 。
agentOpts = rlQAgentOptions;
agentOpts.DiscountFactor = 1;
agentOpts.EpsilonGreedyExploration.Epsilon = 0.9;
agentOpts.EpsilonGreedyExploration.EpsilonDecay = 0.01;
agentOpts.CriticOptimizerOptions = qOptions;
qAgent = rlQAgent(qFunction,agentOpts); %#ok<NASGU>
(3)训练 Q-Learning 智能体
训练智能体首先需要指定训练选项。对于此示例,使用以下选项:
- 最多训练 500 回合,每回合最多持续 50 个时间步长
- 当智能体在连续 30 回合内的平均累积奖励 >10,停止训练
更多信息请参见 rlTrainingOptions 。
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 50;
trainOpts.MaxEpisodes = 500;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 13;
trainOpts.ScoreAveragingWindowLength = 30;
使用函数 Train 训练智能体,大该需要几分钟完成。为了节省时间,可以通过将 doTraining 设置为 false 来加载预训练的智能体。若要自己训练智能体,将 doTraining 设置为 true 。
doTraining = false;if doTraining% Train the agent.trainingStats = train(qAgent,env,trainOpts); %#ok<UNRCH>
else% Load pretrained agent for the example.load("genericMDPQAgent.mat","qAgent");
end
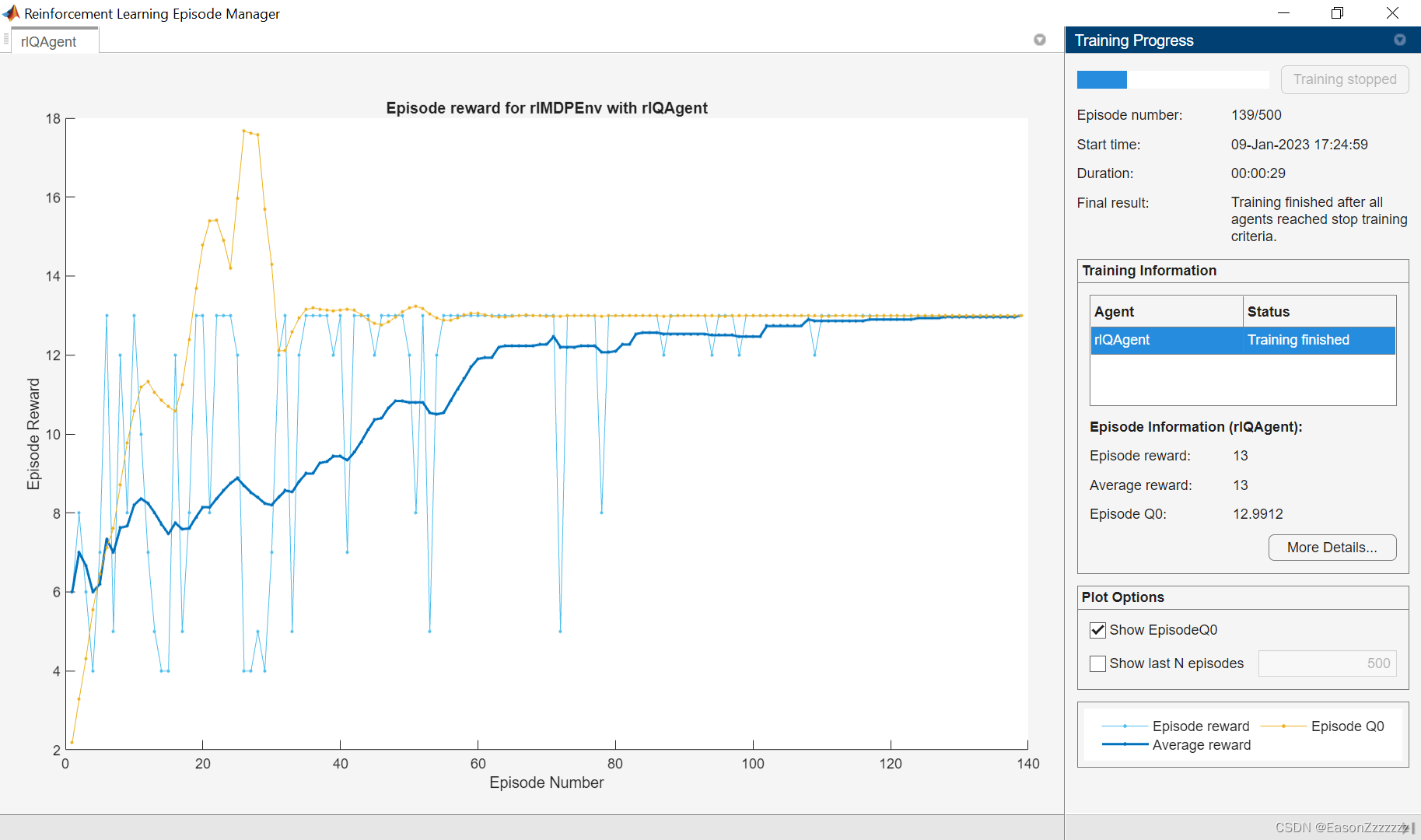
(4)验证 Q-Learning 结果
为了验证训练结果,使用函数 sim 在 MDP 环境中模拟智能体。智能体成功地找到了最佳路径,并获得了 13 的累积奖励。
Data = sim(qAgent,env);
cumulativeReward = sum(Data.Reward)==> cumulativeReward = 13
由于折扣系数设置为 1,因此经过训练的智能体的 Q table 中的值即真实的回报。
QTable = getLearnableParameters(getCritic(qAgent));
QTable{1}==> ans = 8x2 single matrix12.9912 11.66218.2141 9.995010.8645 4.04144.8017 -1.61505.1975 8.99755.8058 -0.23530 00 0
TrueTableValues = [13,12;5,10;11,9;3,2;1,9;5,1;0,0;0,0]
==> TrueTableValues = 8×213 125 1011 93 21 95 10 00 0
1.2、在网格世界中训练智能体(Q-learning 和 SARSA)
网格世界描述如下:
- 网格世界大小为 5 × 5 5\times5 5×5,有四个可能的动作(North=1,South=2,East=3,West=4)
- 智能体从网格(2,1)出发
- 如果智能体到达网格(5,5),则它将获得奖励 10
- 网格世界中包含从网格(2,4)到网格(4,4)的跳跃,奖励为 5
- 智能体会被障碍物(黑色网格区域)阻挡
- 所有其他动作将获得奖励 -1
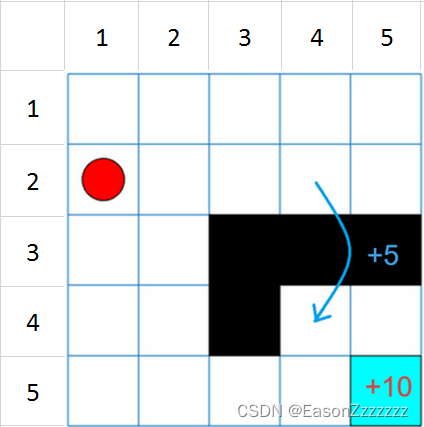
(1)创建网格世界环境
env = rlPredefinedEnv("BasicGridWorld");
通过创建一个充值函数来指定智能体的初始状态始终为 [ 2 , 1 ] [2,1] [2,1],该函数在每次训练和模拟开始调用。
从位置[1,1]开始对状态进行编号。状态编号随着您向下移动第一列,然后向下移动后续每一列而增加。因此,创建一个匿名函数句柄,将初始状态设置为2。
固定随机数种子
rng(0)
(2)创建 Q-Learning 智能体
首先创建 Q table,然后将学习率设置为1。
qTable = rlTable(getObservationInfo(env),getActionInfo(env));
qRepresentation = rlQValueRepresentation(qTable,getObservationInfo(env),getActionInfo(env));
qRepresentation.Options.LearnRate = 1;
接下来,使用 Q-table 创建 Q-learning 智能体,并设定 ϵ \epsilon ϵ-贪婪策略。更多信息请参见 rlQAgent 和 rlQAgentOptions。
agentOpts = rlQAgentOptions;
agentOpts.EpsilonGreedyExploration.Epsilon = .04;
qAgent = rlQAgent(qRepresentation,agentOpts);
(3)训练 Q-Learning 智能体
指定以下训练选项:
- 最多训练 200 回合,每个回合最多持续 50 个时间步长
- 当智能体连续 20 回合平均累计奖励 >10 时,停止训练
更多的信息请参见 rlTrainingOptions
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 50;
trainOpts.MaxEpisodes= 200;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 11;
trainOpts.ScoreAveragingWindowLength = 30;
使用函数 Train 来训练 Q-learning 智能体,训练可能需要几分钟才能完成。
为了在运行此示例时节省时间,可以将 doTraining 设置为 false 来加载预训练的智能体。若要自己训练智能体,可以将 doTraining 设置为 true 。
doTraining = false;if doTraining% Train the agent.trainingStats = train(qAgent,env,trainOpts);
else% Load the pretrained agent for the example.load('basicGWQAgent.mat','qAgent')
end
回合管理器窗口打开并显示训练进度。
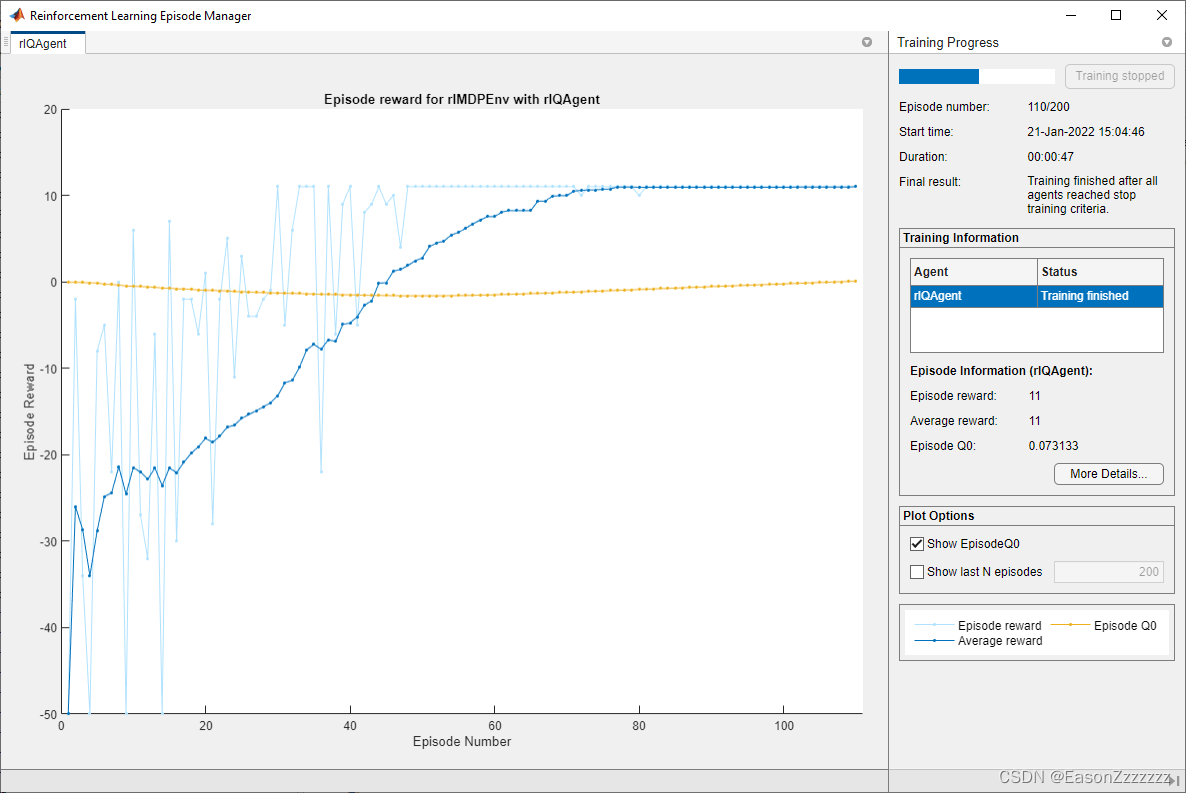
(4)验证 Q-Learning 结果
plot(env)
env.Model.Viewer.ShowTrace = true;
env.Model.Viewer.clearTrace;
使用函数 sim 模拟环境中的智能体。
sim(qAgent,env)
(5)创建和训练 SARSA 智能体
使用与 Q-learning 智能体相同的 Q table 和 ϵ \epsilon ϵ-贪婪策略。更多信息请参见 rlSARSAAgent 和 rlSARSAAgentOptions
agentOpts = rlSARSAAgentOptions;
agentOpts.EpsilonGreedyExploration.Epsilon = 0.04;
sarsaAgent = rlSARSAAgent(qRepresentation,agentOpts);
使用函数 Train 训练 SARSA 智能体,训练可能需要几分钟才能完成。
为了在运行此示例时节省时间,可以将 doTraining 设置为 false 来加载预训练的智能体。若要自己训练智能体,可以将 doTraining 设置为 true 。
doTraining = false;if doTraining% Train the agent.trainingStats = train(sarsaAgent,env,trainOpts);
else% Load the pretrained agent for the example.load('basicGWSarsaAgent.mat','sarsaAgent')
end
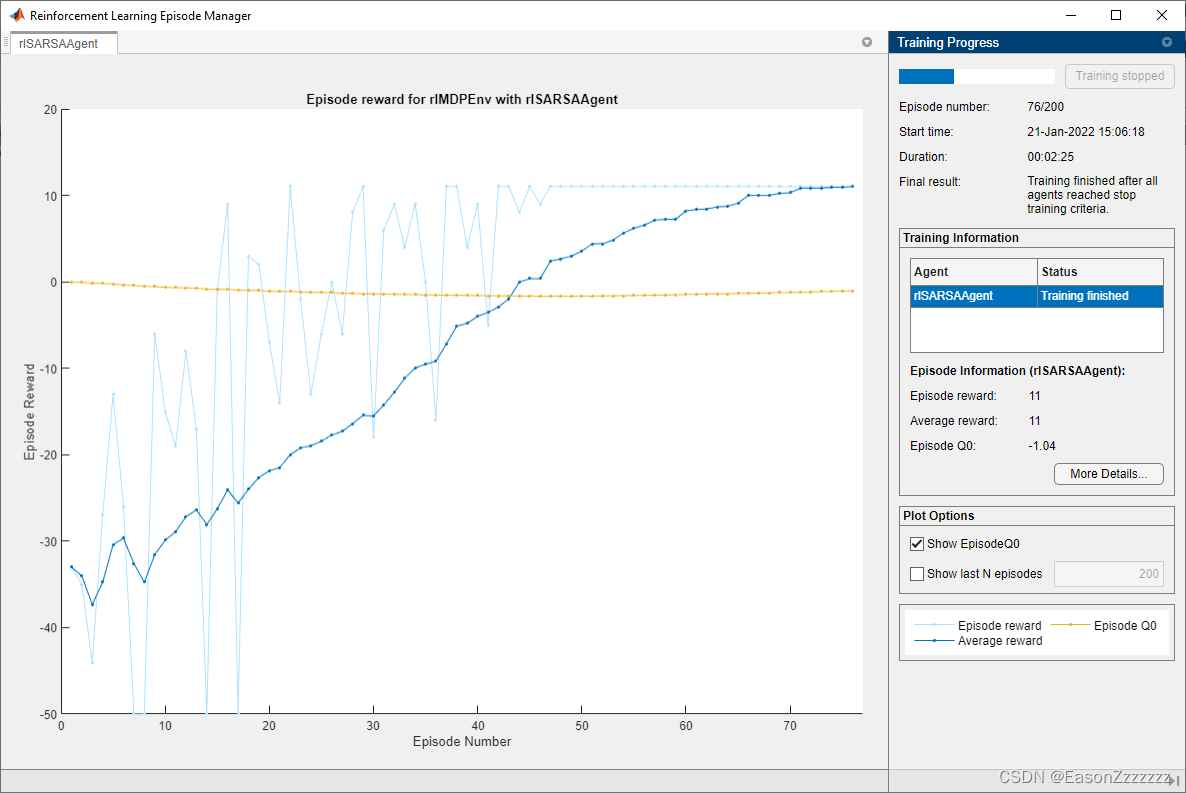
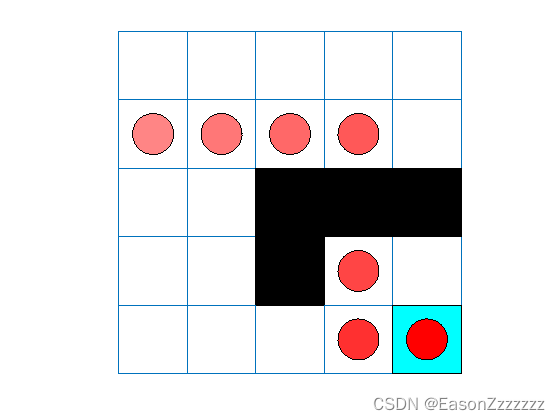
(6)验证 SARSA 结果
plot(env)
env.Model.Viewer.ShowTrace = true;
env.Model.Viewer.clearTrace;
在环境中对智能体进行仿真。
sim(sarsaAgent,env)
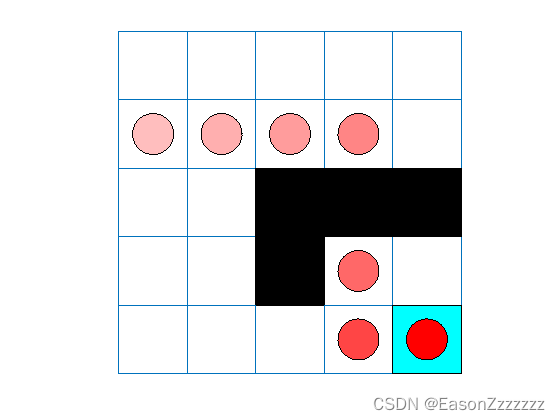
SARSA 智能体找到与 Q-learning 智能体相同的解决方案。
1.3、创建 Simulink 环境并训练智能体
这个例子展示了如何将水箱 Simulink 模型中的 PI 控制器转换为强化学习深度确定性策略梯度(DDPG)智能体。有关在 MATLAB 中训练 DDPG 智能体的示例,请参阅 Compare DDPG Agent to LQR Controller 。
(1)水箱模型
该模型的目标是控制水箱中的水位。有关水箱模型的更多信息,请参阅 watertank Simulink Model 。
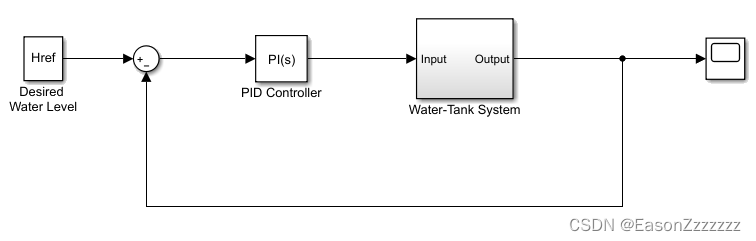
修改原始模型:
- 删除PID控制器
- 插入强化学习智能体模块
- 计算状态观测矢量 [ ∫ e d t e h ] T \left[\int\ e\ \mathrm{dt}\quad e\quad h\right]^T [∫ e dteh]T,其中 h h h 是水箱中的水位, e = r − h e=r−h e=r−h, r r r 是参考水位
- 设置奖励: r e w a r d = 10 ( ∣ e ∣ < 0.1 ) − 1 ( ∣ e ∣ ≥ 0.1 ) − 100 ( h ≤ 0 ∣ ∣ h ≥ 20 ) \mathrm{reward}=10\ (\ \mid e \mid<\ 0.1)\ -1\ (\ \mid e \mid\ \geq\ 0.1\ )\ -100\ (\ h\leq0\ ||\ h\geq20) reward=10 ( ∣e∣< 0.1) −1 ( ∣e∣ ≥ 0.1 ) −100 ( h≤0 ∣∣ h≥20)
- 设置终端信号,例如仿真在 h ≤ 0 h≤0 h≤0 或 h ≥ 20 h≥20 h≥20 时停止。
生成的模型是 r l w a t e r t a n k . s l x \mathrm{rlwatertank.slx} rlwatertank.slx。有关此模型和更改的详细信息,请参见创建自定义 Simulink 环境 。
open_system("rlwatertank")
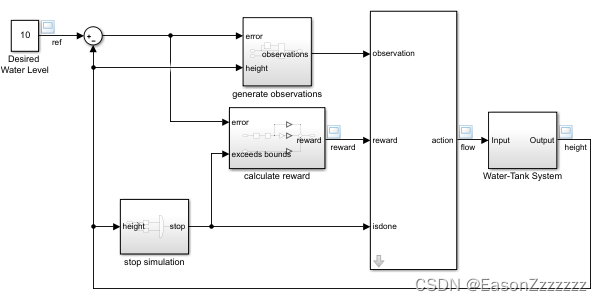
(2)创建环境
环境模型的创建包括以下内容:
- 智能体与环境交互的动作信号和状态观测信号。有关详细信息,请参见环境接口
- 智能体用来衡量其结果好坏的奖励信号。有关详细信息,请参见 在自定义环境中定义奖励和状态观测信号
定义状态观测明细 o b s I n f o \mathrm{obsInfo} obsInfo 和动作明细 a c t I n f o \mathrm{actInfo} actInfo。
% Observation info
obsInfo = rlNumericSpec([3 1],...LowerLimit=[-inf -inf 0 ]',...UpperLimit=[ inf inf inf]');% Name and description are optional and not used by the software
obsInfo.Name = "observations";
obsInfo.Description = "integrated error, error, and measured height";% Action info
actInfo = rlNumericSpec([1 1]);
actInfo.Name = "flow";
创建环境对象。
env = rlSimulinkEnv("rlwatertank","rlwatertank/RL Agent",...obsInfo,actInfo);
设置一个自定义重置函数,使模型的参考值随机化。
env.ResetFcn = @(in)localResetFcn(in);
指定仿真时间 T f T_f Tf和智能体采样时间 T s T_s Ts(单位为秒)。
Ts = 1.0;
Tf = 200;
设置随机数种子。
rng(0)
(3)创建 Critic
DDPG 智能体使用参数化动作价值函数来评估策略,它以当前状态观测和动作作为输入,输出单个标量(估计的未来折扣累积奖励)。
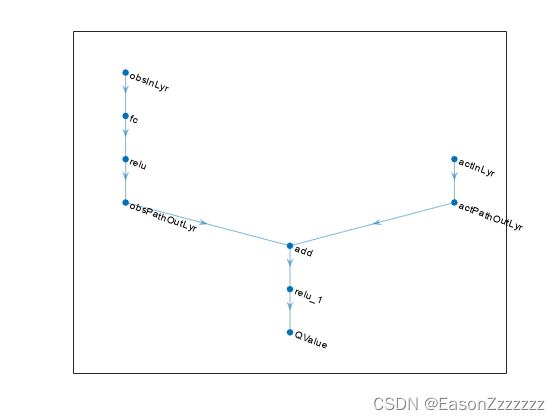
要在 critic 中对参数化动作价值函数进行建模,使用具有两个输入层(一个用于 o b s I n f o \mathrm{obsInfo} obsInfo 指定的状态观测通道,另一个用于 a c t I n f o \mathrm{actInfo} actInfo 指定的动作通道)和一个输出层( 返回标量值 )的神经网络。
将每条网络路径定义为层对象数组。为每个路径的输入和输出层指定名称。通过这些名称,可以连接各路径,然后将网络输入层和输出层与相应的环境通道明确关联。从 o b s I n f o \mathrm{obsInfo} obsInfo 和 a c t I n f o \mathrm{actInfo} actInfo 明细中获取状态观测空间和动作空间的维度。
% Observation path
obsPath = [featureInputLayer(obsInfo.Dimension(1),Name="obsInLyr")fullyConnectedLayer(50)reluLayerfullyConnectedLayer(25,Name="obsPathOutLyr")];% Action path
actPath = [featureInputLayer(actInfo.Dimension(1),Name="actInLyr")fullyConnectedLayer(25,Name="actPathOutLyr")];% Common path
commonPath = [additionLayer(2,Name="add")reluLayerfullyConnectedLayer(1,Name="QValue")];criticNetwork = layerGraph();
criticNetwork = addLayers(criticNetwork,obsPath);
criticNetwork = addLayers(criticNetwork,actPath);
criticNetwork = addLayers(criticNetwork,commonPath);criticNetwork = connectLayers(criticNetwork, ..."obsPathOutLyr","add/in1");
criticNetwork = connectLayers(criticNetwork, ..."actPathOutLyr","add/in2");
查看 Critic 网络配置。
figure
plot(criticNetwork)
将网络转换为 dlnetwork 对象并汇总其属性。
criticNetwork = dlnetwork(criticNetwork);
summary(criticNetwork)==> Initialized: trueNumber of learnables: 1.5kInputs:1 'obsInLyr' 3 features2 'actInLyr' 1 features
指定的深度神经网络、环境明细对象、网络输入与状态观测和动作通道相关联的名称,创建 Critic 对象。
critic = rlQValueFunction(criticNetwork, ...obsInfo,actInfo, ...ObservationInputNames="obsInLyr", ...ActionInputNames="actInLyr");
有关 Q-value 函数的更多信息,请参阅 rlQValueFunction 。
用随机输入的状态观测和动作来检查 Critic。
getValue(critic, ...{rand(obsInfo.Dimension)}, ...{rand(actInfo.Dimension)})==> ans = single-0.1631
有关创建 Critics 的详细信息,请参见 Create Policies and Value Functions 。
(4)创建 Actor
DDPG 智能体在连续动作空间上使用参数化的确定性策略,该策略由连续的确定性 Actor 学习。
Actor 将当前状态观测作为输入,返回动作作为输出。
对 Actor 进行建模,需使用具有一个输入层(如 o b s I n f o \mathrm{obsInfo} obsInfo 所指定,接收环境状态观测通道的内容)和一个输出层(如 a c t I n f o \mathrm{actInfo} actInfo 所指定,将动作返回到环境动作通道)的神经网络。
将网络定义为层对象数组。
actorNetwork = [featureInputLayer(obsInfo.Dimension(1))fullyConnectedLayer(3)tanhLayerfullyConnectedLayer(actInfo.Dimension(1))];
将网络转换为 dlnetwork 对象并汇总其属性。
actorNetwork = dlnetwork(actorNetwork);
summary(actorNetwork)==> Initialized: trueNumber of learnables: 16Inputs:1 'input' 3 features
使用指定的深度神经网络、环境明细对象以及与状态观测通道相关联的网络输入名称,创建 Actor 对象。
actor = rlContinuousDeterministicActor(actorNetwork,obsInfo,actInfo);
更多信息,请参阅 rlContinuousDeterministicActor 。
用随机输入状态观测数据检查 Actor。
getAction(actor,{rand(obsInfo.Dimension)})==> ans = 1x1 cell array{[-0.3408]}
(5)创建 DDPG 智能体
使用指定的 Actor 和 Critic 对象创建 DDPG 智能体。
agent = rlDDPGAgent(actor,critic);
更多信息,请参阅 rlDDPGAgent 。
指定智能体、Actor 和 Critic 。
agent.SampleTime = Ts;agent.AgentOptions.TargetSmoothFactor = 1e-3;
agent.AgentOptions.DiscountFactor = 1.0;
agent.AgentOptions.MiniBatchSize = 64;
agent.AgentOptions.ExperienceBufferLength = 1e6; agent.AgentOptions.NoiseOptions.Variance = 0.3;
agent.AgentOptions.NoiseOptions.VarianceDecayRate = 1e-5;agent.AgentOptions.CriticOptimizerOptions.LearnRate = 1e-03;
agent.AgentOptions.CriticOptimizerOptions.GradientThreshold = 1;
agent.AgentOptions.ActorOptimizerOptions.LearnRate = 1e-04;
agent.AgentOptions.ActorOptimizerOptions.GradientThreshold = 1;
或者,也可以使用 rlDDPGAgentOptions 对象指定智能体选项。
用随机输入状态观测结果检查智能体。
getAction(agent,{rand(obsInfo.Dimension)})==> ans = 1x1 cell array{[-0.7926]}
(6)训练智能体
首先要指定训练选项。本例中使用以下选项:
- 每次训练最多运行 5000 回合。指定每回合最多持续 ceil ( T f / T s T_f/T_s Tf/Ts) ( 即 200 )个时间步
- 在 "回合管理器 "对话框中显示训练进度(设置 Plots 选项),并禁用命令行显示( 将 Verbose 选项设为 false )
- 当智能体在连续 20 个回合中获得的平均累积奖励 > 800 时,停止训练。此时,智能体可以控制水箱中的水位
更多信息,请参阅 rlTrainingOptions 。
trainOpts = rlTrainingOptions(...MaxEpisodes=5000, ...MaxStepsPerEpisode=ceil(Tf/Ts), ...ScoreAveragingWindowLength=20, ...Verbose=false, ...Plots="training-progress",...StopTrainingCriteria="AverageReward",...StopTrainingValue=800);
使用函数 train 训练智能体。训练是一个计算密集型过程,需要几分钟才能完成。为节省运行此示例的时间,请将 doTraining 设为 false,以加载预训练过的智能体。要自己训练代理,可将 doTraining 设为 true。
doTraining = false;if doTraining% Train the agent.trainingStats = train(agent,env,trainOpts);
else% Load the pretrained agent for the example.load("WaterTankDDPG.mat","agent")
end

(7)验证 DDPG 智能体
根据模型仿真验证 DDPG 智能体。由于重置函数会随机化参考值,因此要固定随机数种子,以确保可重复性。
rng(1)
在环境中仿真,并将输出返回。
simOpts = rlSimulationOptions(MaxSteps=ceil(Tf/Ts),StopOnError="on");
experiences = sim(env,agent,simOpts);
(8)本地重置函数
function in = localResetFcn(in)% Randomize reference signal
blk = sprintf("rlwatertank/Desired \nWater Level");
h = 3*randn + 10;
while h <= 0 || h >= 20h = 3*randn + 10;
end
in = setBlockParameter(in,blk,Value=num2str(h));% Randomize initial height
h = 3*randn + 10;
while h <= 0 || h >= 20h = 3*randn + 10;
end
blk = "rlwatertank/Water-Tank System/H";
in = setBlockParameter(in,blk,InitialCondition=num2str(h));end
相关文章:
强化学习工具箱(Matlab)
1、Get Started 1.1、MDP环境下训练强化学习智能体 MDP环境如下图 每个圆圈代表一个状态每个状态都有上或下的选择智能体从状态 1 开始智能体接收的奖励值为图中状态转移的值训练目标是最大化累计奖励 (1)创建 MDP 环境 创建一个具有 8 个状态和 2 …...
程序人生 - 爬虫者,教育也!
作为一个站长,你是不是对爬虫不胜其烦?爬虫天天来爬,速度又快,频率又高,服务器的大量资源被白白浪费。 看这篇文章的你有福了,我们今天一起来报复一下爬虫,直接把爬虫的服务器给干死机。 本文有…...
OKLink2月安全月报| 2起典型漏洞攻击案例分析
在本月初我们发布的2024年2月安全月报中提到,2月全网累计造成损失约1.03亿美元。其中钓鱼诈骗事件损失占比11.76%。 OKLink提醒大家,在参与Web3项目时,应当仔细调研项目的真实性、可靠性,提升对钓鱼网站和风险项目的甄别能力&…...

可视化表单流程编辑器为啥好用?
想要提升办公率、提高数据资源的利用率,可以采用可视化表单流程编辑器的优势特点,实现心中愿望。伴随着社会的进步和发展,提质增效的办公效果一直都是很多职场办公团队的发展需求,作为低代码技术平台服务商,流辰信息团…...

【代码】Android|获取存储权限并创建、存储文件
版本:Android 11及以上,gradle 7.0以上,Android SDK > 29 获取存储权限 获取存储权限参考:Android 11 外部存储权限适配指南及方案,这篇文章直接翻到最下面,用XXPermissions框架。它漏了这个框架的使用方…...

每日一练 | 华为认证真题练习Day196
1、在如图所示的网络中,三台交换机运行RSTP,配置情况如图所示 根据图中配置情况判断根交换机为 A. SWA B. SWB C. SWC D. 无法确定 2、如图所示,在RT1路由器上配置OSPF多进程,其中RT1的进程100通过骨干区域和RT2建立OSPF邻居&…...
如何在Linux本地搭建Tale网站并实现无公网ip远程访问
文章目录 前言1. Tale网站搭建1.1 检查本地环境1.2 部署Tale个人博客系统1.3 启动Tale服务1.4 访问博客地址 2. Linux安装Cpolar内网穿透3. 创建Tale博客公网地址4. 使用公网地址访问Tale 前言 今天给大家带来一款基于 Java 语言的轻量级博客开源项目——Tale,Tale…...

论哪个行业官网颜值普遍较高,装修设计第二,无人敢称第一。
装饰设计公司官网普遍颜值较高的原因主要包括以下几点: 1. 美学要求: 装饰设计公司本身就是从事美学和艺术的行业,他们对于视觉效果和美感有着较高的要求,因此他们的官网在设计上往往会更加注重颜值。 2. 品牌形象:…...

Elastic Stack--08--SpringData框架
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 SpringData[官网: https://spring.io/projects/spring-data](https://spring.io/projects/spring-data) Spring Data Elasticsearch 介绍 1.SpringData-…...

华为OD机试 - 模拟数据序列化传输(Java JS Python C C++)
题目描述 模拟一套简化的序列化传输方式,请实现下面的数据编码与解码过程 编码前数据格式为 [位置,类型,值],多个数据的时候用逗号分隔,位置仅支持数字,不考虑重复等场景;类型仅支持:Integer / String / Compose(Compose的数据类型表示该存储的数据也需要编码)编码后数…...

使用Tokeniser估算GPT和LLM服务的查询成本
将LLM集成到项目所花费的成本主要是我们通过API获取LLM返回结果的成本,而这些成本通常是根据处理的令牌数量计算的。我们如何预估我们的令牌数量呢?Tokeniser包可以有效地计算文本输入中的令牌来估算这些成本。本文将介绍如何使用Tokeniser有效地预测和管…...
)
2-Docker-应用-多容器部署Django+Vue项目(nginx+uwsgi+mysql)
摘要: 本文详细介绍了如何使用Docker部署一个多容器DjangoVue项目,包括nginx、uwsgi和mysql。文章内容涵盖了基础知识回顾、需求分析、设计方案、实现步骤、技巧与实践、性能优化与测试、常见问题与解答以及结论与展望。 阅读时长:约60分钟…...

Vue 中的 key:列表渲染的秘诀
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

Linux系统架构----nginx的服务基础
一.Nginx的概述 Nginx是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx稳定性高,而且系统资源消耗少Nginx相对于Apache主要处理静态请求,而apache主要处理动态请求Nginx是一款轻量级的Web 服务器/反向代理服务…...
项目管理工具及模板(甘特图、OKR周报、任务管理、头脑风暴等)
项目管理常用模板大全: 1. 项目组OKR周报 2. 项目组传统周报工作法 3. 项目甘特图 4. 团队名单 5. 招聘跟进表 6. 出勤统计 7. 年度工作日历 8. 项目工作年计划 9. 版本排期 10. 项目组任务管理 11. 项目规划模板 12. 产品分析报告 13. 头脑风暴 信息化项目建设全套…...

MySQL--索引底层数据结构详解
索引是什么? 索引是帮助MySQL高效获取数据的排好序的数据结构,因此可知索引是数据结构。 概念很抽象,但是类比生活中的例子就很容易理解,比如一本厚厚的书,我们想取找某一小节,我们可以根据目录去快速找到…...

如何解决爬虫程序访问速度受限问题
目录 前言 一、代理IP的获取 1. 自建代理IP池 2. 购买付费代理IP 3. 使用免费代理IP网站 二、代理IP的验证 三、使用代理IP进行爬取 四、常见问题和解决方法 1. 代理IP不可用 2. 代理IP速度慢 3. 代理IP被封禁 总结 前言 解决爬虫程序访问速度受限问题的一种常用方…...

如何考上东南大学计算机学院?
东南大学招生学院是计算机科学与工程学院、苏州联合研究生院,复试公平,不歧视双非考生,985院校中性价比较高,但近年热度在逐年上涨,需要警惕。 建议报考计算机科学与工程学院081200计算机科学与技术专业目标分数为380…...

双指针算法练习
27. 移除元素 题目 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑…...
桌面终端管理(实用+收藏篇)
桌面终端管理软件是管理和保护企业电脑数据安全的工具。 它能够帮助管理员更有效地控制和监督员工电脑的日常使用,软件的功能包括软件管理、硬件监控、远程管理、数据加密和防泄密、行为审计以及安全防护等。 桌面终端管理的核心要义 桌面终端管理不仅仅是对硬件设…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...