25.5 MySQL 聚合函数

1. 聚合函数
聚合函数(Aggregate Function): 是在数据库中进行数据处理和计算的常用函数.
它们可以对一组数据进行求和, 计数, 平均值, 最大值, 最小值等操作, 从而得到汇总结果.常见的聚合函数有以下几种:
SUM: 用于计算某一列的数值总和, 可以用于整数, 小数或者日期类型的列.
AVG: 用于计算某一列的数值平均值, 通常用于整数或者小数类型的列.
MAX: 用于找出某一列的最大值, 可以对任意数据类型的数据使用.
MIN: 用于找出某一列的最小值, 同样可以对任意数据类型的数据使用.
COUNT: 用于计算表中记录的总数或者某一列中非空值的数量.COUNT(*)会返回表中记录的总数, 适用于任意数据类型.注意事项:
* 1. 聚合函数通常都会忽略空值(COUNT比较特后续详细说明).例如, 如果一列中有5个数值和3个空值, SUM函数只会对那5个数值进行求和, 而忽略那3个空值.同样地, AVG函数也只会根据那5个数值来计算平均值.* 2. 聚合函数经常与SELECT语句的GROUP BY子句一同使用, 以便按照某个或多个列对结果进行分组.此外, 还可以使用HAVING子句对聚合结果进行过滤. 例如, 可以找出平均薪水超过某个值的部门.* 3. 聚合函数不能嵌套调用.比如不能出现类似'AVG(SUM(字段名称))'形式的调用.* 4. 聚合函数通常不能与普通字段(即非聚合字段)直接一起出现在SELECT语句的列列表中.(除非这些普通字段也包含在GROUP BY子句中, 否则数据库会报错.)聚合函数与GROUP BY子句一同使用时作用于一组数据, 并对每一组数据返回一个值.聚合函数单独使用时作用于一列数据, 并返回一个值.如果在SELECT语句中同时包含聚合函数和普通字段, 但没有使用GROUP BY子句, 数据库不知道如何将普通字段的值与聚合函数的结果对应起来.
1.1 求数值总数
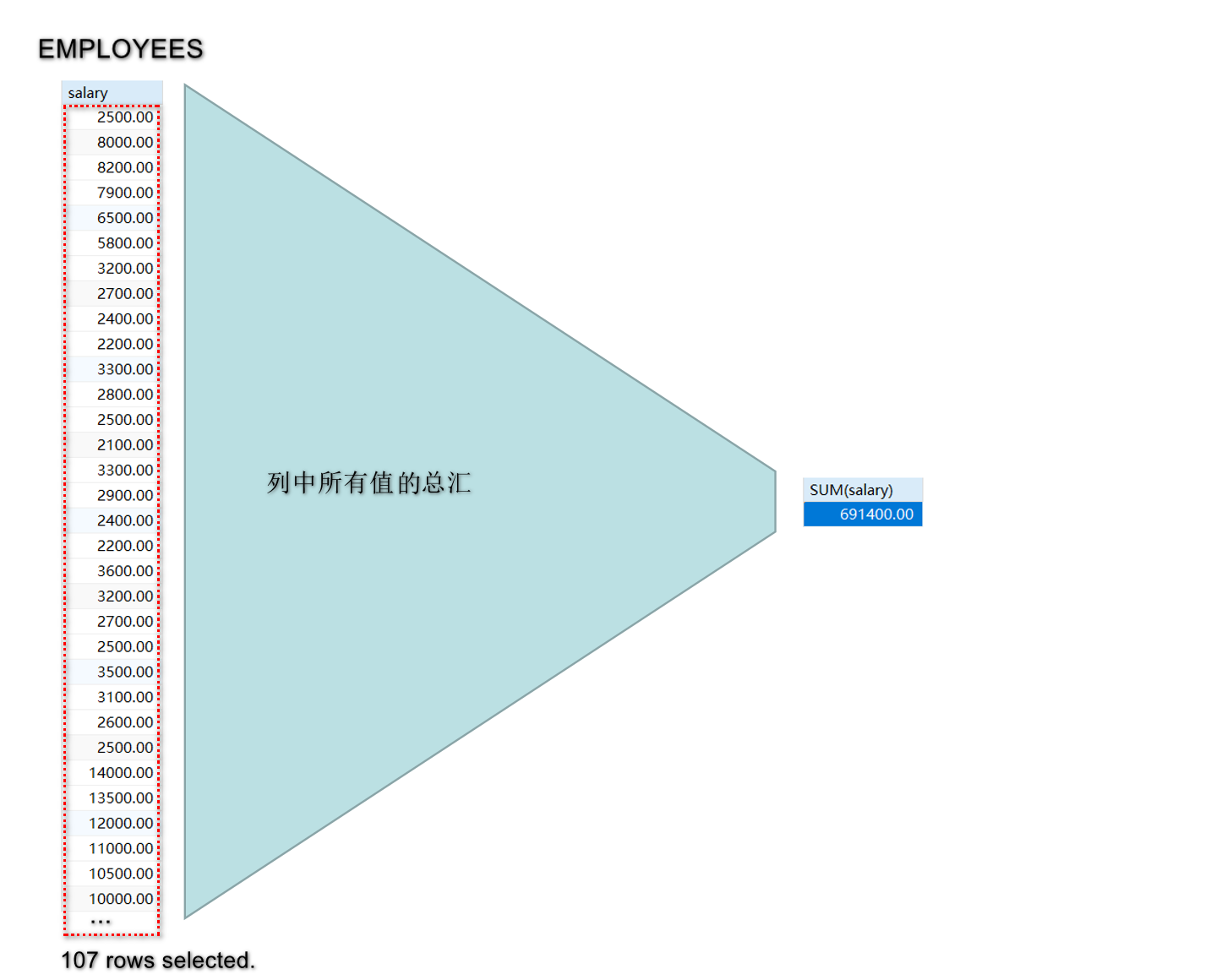
基本语法: SUM(column_name); 用于计算指定列的总和.
例: SELECT SUM(salary) AS total_salary FROM employees;
-- 查询所有员工的工资总和:
mysql> SELECT SUM(salary) FROM employees;
+-------------+
| SUM(salary) |
+-------------+
| 691400.00 | -- 整个列返回一个值, 为整列的值总和.
+-------------+
1 row in set (0.00 sec)
1.2 仅全分组模式
ONLY_FULL_GROUP_BY: 是MySQL中的一种SQL模式, 其作用是约束SQL语句的执行.
当启用这个模式时, MySQL要求SELECT语句中的GROUP BY子句中的列必须是聚合函数(如SUM、COUNT等)或在GROUP BY子句中出现的列.
换句话说, 如果在SELECT语句中存在既不在GROUP BY子句中也不作为聚合函数的列, MySQL将会抛出错误.这种限制的目的是为了确保查询结果的准确性.
因为在GROUP BY语句中, 查询结果是按照分组列进行聚合的.
如果SELECT语句中的列既包含了聚合函数又包含了其他非分组列, 那么就会出现模糊性, 无法确切地确定每个分组中的非聚合列的值.
如果想要显示员工id, 姓名等字段信息, 代码则为: SELECT employee_id, first_name, SUM(salary) FROM employees;
在MySQL 5.7.5之前的版本中代码是可以运行的, ROUP BY的行比较宽松,
允许在SELECT列表中选择未在GROUP BY子句中明确提及的列, 并且没有使用聚合函数.
然而, 从MySQL 5.7.5起, 由于默认的sql_mode包含了ONLY_FULL_GROUP_BY, MySQL对GROUP BY的执行更加严格.ONLY_FULL_GROUP_BY模式要求, 对于SELECT列表, HAVING条件或ORDER BY列表中的非聚合列,
它们必须明确地出现在 GROUP BY 子句中.
如果没有, MySQL 就会抛出一个错误.临时关闭ONLY_FULL_GROUP_BY模式: SET SESSION sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
-- 临时关闭ONLY_FULL_GROUP_BY模式:
mysql> SET SESSION sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
Query OK, 0 rows affected (0.00 sec)-- 临时关闭不需要重启客户端.
mysql> SELECT employee_id, first_name, SUM(salary) FROM employees;
+-------------+------------+-------------+
| employee_id | first_name | SUM(salary) |
+-------------+------------+-------------+
| 100 | Steven | 691400.00 |
+-------------+------------+-------------+
1 row in set (0.00 sec)
如果employees表中有多行数据, 且没有使用 GROUP BY子句, 那么employee_id和first_name的值是从表中随机选择的单行数据,
而SUM(salary)则是计算了表中所有行的薪水总和.
因此, employee_id和first_name的值在这种情况下确实是没有意义的, 因为它们并不代表与薪水总和相对应的具体员工.
1.3 求平均值
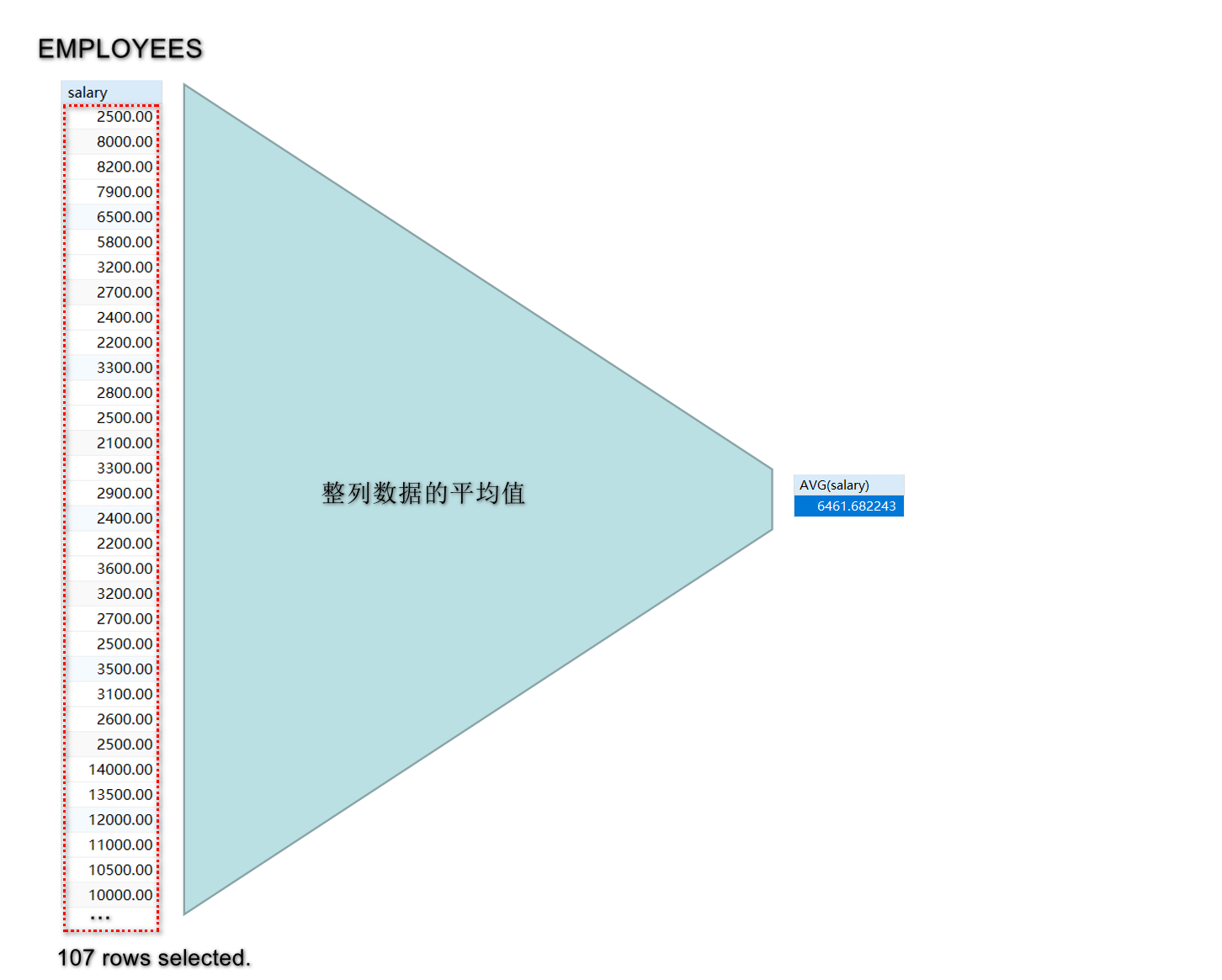
基本语法: AVG(column_name); 用于计算指定列的平均值.
例: SELECT AVG(salary) AS average_salary FROM employees;
-- 查询员工的平均工资:
mysql> SELECT AVG(salary) FROM employees;
+-------------+
| AVG(salary) |
+-------------+
| 6461.682243 | -- 整个列返回一个值, 为整列数值的平均值.
+-------------+
1 row in set (0.00 sec)-- 查询员工的平均工资:
mysql> SELECT SUM(salary) / 107 FROM employees;
+-------------------+
| SUM(salary) / 107 |
+-------------------+
| 6461.682243 |
+-------------------+
1 row in set (0.00 sec)
1.4 求最大/小值
基本语法:
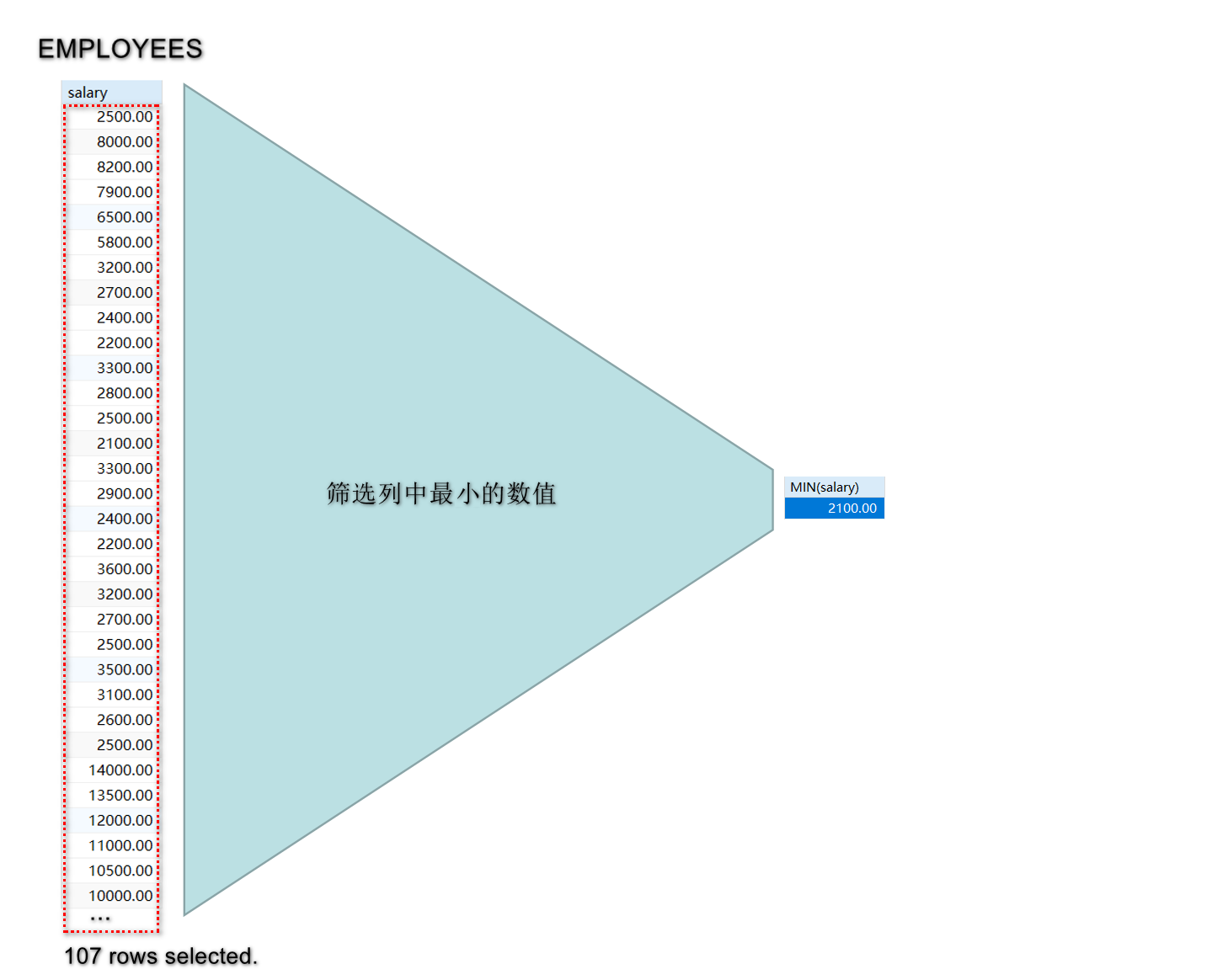
MIN(column_name); 用于找出指定列的最小值. 例: SELECT MIN(salary) AS minimum_salary FROM employees;
MAX(column_name); 用于找出指定列的最大值. 例: SELECT MAX(salary) AS maximum_salary FROM employees;
-- 查询最高工资:
mysql> SELECT MAX(salary) FROM employees;
+-------------+
| MAX(salary) |
+-------------+
| 24000.00 |
+-------------+
1 row in set (0.00 sec)

-- 查询最低工资:
mysql> SELECT MIN(salary) FROM employees;
+-------------+
| MIN(salary) |
+-------------+
| 2100.00 |
+-------------+
1 row in set (0.00 sec)
-- 最早入职的员工的入职时间与最迟入职的员工的入职时间:
mysql> SELECT MIN(hire_date), MAX(hire_date) FROM employees;
+----------------+----------------+
| MIN(hire_date) | MAX(hire_date) |
+----------------+----------------+
| 1987-06-17 | 2000-04-21 |
+----------------+----------------+
1 row in set (0.00 sec)
1.5 统计
基本语法:
COUNT(*): 计算表中所有记录的数量. 例: SELECT COUNT(*) AS total_employees FROM employees;
COUNT(常数): 计算表中所有记录的数量. 例: SELECT COUNT(1) AS total_employees FROM employees;
COUNT(字段): 计算指定列中非NULL值的数量. 例: SELECT COUNT(salary) AS salary_count FROM employees; COUNT函数在处理NULL值时的行为取决于其使用的具体形式.
使用COUNT(1)或COUNT(2)或COUNT(*)时, 它们的功能实际上是相同的.
(这里的常数仅仅是一个占位符, 用于表示对每一行进行计数, 可以被任何非NULL的常量表达式替换.)
它们都会计算表中的行数, 不论列中的值是否为NULL.
count(*)是SQL92定义的标准统计行数的语法, 跟数据库无关, 跟NULL和非NULL无关.当使用COUNT(字段)时, 它会统计该字段在表中出现的次数, 但会忽略字段值为NULL的情况.
也就是说, 它不会将null值计入总数.
-- 计算表中数据有多少行:
mysql> SELECT COUNT(*), COUNT(1), COUNT(2) FROM employees;
+----------+----------+----------+
| COUNT(*) | COUNT(1) | COUNT(2) |
+----------+----------+----------+
| 107 | 107 | 107 | -- 员工表中有107条数据.
+----------+----------+----------+
1 row in set (0.00 sec)-- COUNT(字段)时会忽略字段值为NULL的情况:
mysql> SELECT COUNT(employee_id), COUNT(commission_pct) FROM employees;
+--------------------+-----------------------+
| COUNT(employee_id) | COUNT(commission_pct) |
+--------------------+-----------------------+
| 107 | 35 |
+--------------------+-----------------------+
1 row in set (0.00 sec)

-- 查询员工的平均工资:
mysql> SELECT SUM(salary) / COUNT(*) FROM employees;
+------------------------+
| SUM(salary) / COUNT(*) |
+------------------------+
| 6461.682243 |
+------------------------+
1 row in set (0.00 sec)-- 计算有佣金的员工的佣金平均值(忽略值为NULL的情况):
mysql> SELECT AVG(commission_pct), SUM(commission_pct) / COUNT(commission_pct) FROM employees;
+---------------------+---------------------------------------------+
| AVG(commission_pct) | SUM(commission_pct) / COUNT(commission_pct) |
+---------------------+---------------------------------------------+
| 0.222857 | 0.222857 |
+---------------------+---------------------------------------------+
1 row in set (0.00 sec)-- 计算员工的佣金平均值:
mysql> SELECT AVG(IFNULL(commission_pct, 0)),
SUM(commission_pct) / COUNT(IFNULL(commission_pct, 0))
FROM employees;
+--------------------------------+--------------------------------------------------------+
| AVG(IFNULL(commission_pct, 0)) | SUM(commission_pct) / COUNT(IFNULL(commission_pct, 0)) |
+--------------------------------+--------------------------------------------------------+
| 0.072897 | 0.072897 |
+--------------------------------+--------------------------------------------------------+
1 row in set (0.00 sec)
问题: 统计表中的记录数, 使用COUNT(*), COUNT(1), COUNT(具体字段)哪个效率更高呢?
答: 如果使用的是MyISAM存储引擎, 则三者效率相同, 都是O(1).如果使用的是InnoDB 存储引擎, 则三者效率:COUNT(*) = COUNT(1) > COUNT(字段).
2. GROUP BY 分组
2.1 基本语法
GROUP BY是SQL中的一个子句, 用于对查询结果进行分组.
在SELECT语句中使用GROUP BY子句时, 数据库会根据指定的列或表达式的值对查询结果进行分组.
所有具有相同值的行会被放到同一个分组中, 如果分组列中具有NULL值, 则NULL将作为一个分组返回.
然后, 你可以使用聚合函数(如SUM, AVG, COUNT等)对每个分组进行计算, 得到每个分组的摘要信息.基本语法如下:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
其中, column_name是你要根据其进行分组的列的名称, aggregate_function是你要应用的聚合函数.
GROUP BY声明在FROM后面, WHERE后面, ORDER BY前面, LIMIT前面.注意事项:
* 1. 除聚集计算语句外, SELECT语句中的每个列都必须在GROUP BY子句中给出, 否则报错.
* 2. GROUP BY子句可以包含任意数目的列, 这使得能对分组进行嵌套, 为数据分组提供更细致的控制.例如, 你可以同时按部门和职位对员工进行分组, 以获取更详细的数据.
* 3. GROUP_CONCAT()函数是MySQL中的一个特殊函数, 它主要用于将同一个分组中的值连接起来, 并返回一个字符串结果.这个函数在配合GROUP BY子句使用时非常有用, 因为它可以在分组后, 将指定字段的所有值连接成一个单独的字符串.
* 4. 使用GROUP BY子句对多个列进行分组时, 列的顺序并不会影响分组的结果或聚合函数的结果.这是因为GROUP BY子句是基于所有列的组合来定义分组的, 而不是单独基于每个列.
2.2 基本使用
-- 将员工按部门分组(所有具有相同值的行会被放到同一个分组中, 每个分组返回一个值):
mysql> SELECT department_id FROM employees GROUP BY department_id;
+---------------+
| department_id |
+---------------+
| NULL |
| 10 |
| 20 |
| 30 |
| 40 |
| 50 |
| 60 |
| 70 |
| 80 |
| 90 |
| 100 |
| 110 |
+---------------+
12 rows in set (0.00 sec)-- 使用GROUP_CONCAT()函数可以在分组后, 将指定字段的所有值连接成一个单独的字符串.
-- 按部门分组后, 将每个组的成员薪资连接成一个字符串:
SELECT department_id, GROUP_CONCAT(salary) FROM employees GROUP BY department_id;
+---------------+----------------------------------------------------------------+
| department_id | GROUP_CONCAT(salary) | | NULL | 7000.00 |
| 10 | 4400.00 | | 20 | 13000.00,6000.00 |
| 30 | 11000.00,3100.00,2900.00,2800.00,2600.00,2500.00 |
| 40 | 6500.00 |
| ... | ... | -- 省略
| 100 | 12000.00,9000.00,8200.00,7700.00,7800.00,6900.00 |
| 110 | 12000.00,8300.00 | +---------------+----------------------------------------------------------------+
-- 除聚集计算语句外, SELECT语句中的每个列都必须在GROUP BY子句中给出, 否则报错.
-- salary没有在集合函数中, 也没有在GROUP BY分组中, 就不能出现在SELECT中.
mysql> SELECT department_id, salary FROM employees GROUP BY department_id;
ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'atguigudb.employees.salary' which is not functionally dependent on columns in GROUP BY clause;
this is incompatible with sql_mode=only_full_group_by-- 错误1055(42000): SELECT 列表中的表达式#2不在GROUP BY子句中,
-- 并且包含非聚合列'atguigudb.employees.salary', 该列不是GROUP BY子句中列的函数依赖项;
-- 这与sql_mode=only_full_group_by 不兼容.
-- 如果sql_mode没有设置only_full_group_by运行得到的结果也没有任何意义, 一个分组中有多个人取一个名字来对应, 取谁都不合适.
2.3 搭配聚合函数
使用GROUP BY子句与聚合函数搭配是非常常见的做法,
主要用于将多行数据按照一个或多个列进行分组, 并对每个分组应用聚合函数来计算汇总值.以下是一些常用的聚合函数及其与GROUP BY子句搭配使用的示例:
* 1. 计算每个分组的某列的总和: SELECT department_id, SUM(salary) AS total_salary FROM employees GROUP BY department_id;
* 2. 计算每个分组的某列的平均值: SELECT job_id, AVG(salary) AS average_salary FROM employees GROUP BY job_id;
* 3. 找出每个分组的某列的最大值: SELECT department_id, MAX(salary) AS max_salary FROM employees GROUP BY department_id;
* 4. 找出每个分组的某列的最小值: SELECT job_id, MIN(hire_date) AS earliest_hire_date FROM employees GROUP BY job_id;
* 5. 计算每个分组的行数: SELECT department_id, COUNT(*) AS num_employees FROM employees GROUP BY department_id;
-- 计算每个部门的平均工资(1.先按部门id分组. 2.使用聚合函数对分组后的字段进行计算):
mysql> SELECT department_id, AVG(salary) FROM employees GROUP BY department_id;
+---------------+--------------+
| department_id | AVG(salary) |
+---------------+--------------+
| NULL | 7000.000000 |
| 10 | 4400.000000 |
| 20 | 9500.000000 |
| 30 | 4150.000000 |
| 40 | 6500.000000 |
| 50 | 3475.555556 |
| 60 | 5760.000000 |
| 70 | 10000.000000 |
| 80 | 8955.882353 |
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
+---------------+--------------+
12 rows in set (0.00 sec)

-- 查询各个部门的最高工资:
mysql> SELECT department_id, MAX(salary) FROM employees GROUP BY department_id;
+---------------+-------------+
| department_id | MAX(salary) |
+---------------+-------------+
| NULL | 7000.00 |
| 10 | 4400.00 |
| 20 | 13000.00 |
| 30 | 11000.00 |
| 40 | 6500.00 |
| 50 | 8200.00 |
| 60 | 9000.00 |
| 70 | 10000.00 |
| 80 | 14000.00 |
| 90 | 24000.00 |
| 100 | 12000.00 |
| 110 | 12000.00 |
+---------------+-------------+
12 rows in set (0.00 sec)-- 查询每个岗位的平均工资:
mysql> SELECT job_id, AVG(salary) FROM employees GROUP BY job_id;
+------------+--------------+
| job_id | AVG(salary) |
+------------+--------------+
| AC_ACCOUNT | 8300.000000 |
| AC_MGR | 12000.000000 |
| AD_ASST | 4400.000000 |
| ... | ... | -- 省略
| SA_REP | 8350.000000 |
| SH_CLERK | 3215.000000 |
| ST_CLERK | 2785.000000 |
| ST_MAN | 7280.000000 |
+------------+--------------+
19 rows in set (0.00 sec)
2.4 多列分组
GROUP BY子句对多个列进行分组时, 列的顺序不会影响分组的结果.
但SELECT子句中列的顺序可能会影响结果的显示顺序.
-- 查询每个部门与岗位的平均工资.
-- 方式1:
mysql> SELECT department_id, job_id, AVG(salary) FROM employees GROUP BY department_id, job_id;
+---------------+------------+--------------+
| department_id | job_id | AVG(salary) |
+---------------+------------+--------------+
| 90 | AD_PRES | 24000.000000 | -- 先按部门id分组, 在这个基础上再按岗位id分组.
| 90 | AD_VP | 17000.000000 | -- 对二次分组后的薪资信息求平均值.
| 60 | IT_PROG | 5760.000000 |
| ... | ... | ... | -- 省略
| 110 | AC_MGR | 12000.000000 |
| 110 | AC_ACCOUNT | 8300.000000 |
+---------------+------------+--------------+
20 rows in set (0.00 sec)-- 方式2:
mysql> SELECT job_id, department_id, AVG(salary) FROM employees GROUP BY job_id, department_id;
+------------+---------------+--------------+
| job_id | department_id | AVG(salary) |
+------------+---------------+--------------+
| AD_PRES | 90 | 24000.000000 | -- GROUP BY子句对多个列进行分组时, 列的顺序不会影响分组的结果...
| AD_VP | 90 | 17000.000000 | -- SELECT子句中列的顺序可能会影响结果的显示顺序.
| ... | ... | ... | -- 省略
| AC_MGR | 110 | 12000.000000 |
| AC_ACCOUNT | 110 | 8300.000000 |
+------------+---------------+--------------+
20 rows in set (0.00 sec)

2.5 分组后排序
在SQL中, 分组后排序通常涉及两个关键步骤:
* 1. 首先使用GROUP BY子句对数据进行分组.
* 2. 然后使用ORDER BY子句对分组后的结果进行排序.基本语法:
SELECT column1, column2, aggregate_function(column3)
FROM your_table
GROUP BY column1, column2
ORDER BY column1, column2;
-- 查询每个部门的平均工资, 按照平均工资升序排列:
mysql> SELECT department_id, AVG(salary) AS `avg_sal` FROM employees GROUP BY department_id ORDER BY avg_sal;
+---------------+--------------+
| department_id | avg_sal |
+---------------+--------------+
| 50 | 3475.555556 |
| 30 | 4150.000000 |
| 10 | 4400.000000 |
| 60 | 5760.000000 |
| 40 | 6500.000000 |
| NULL | 7000.000000 |
| 100 | 8600.000000 |
| 80 | 8955.882353 |
| 20 | 9500.000000 |
| 70 | 10000.000000 |
| 110 | 10150.000000 |
| 90 | 19333.333333 |
+---------------+--------------+
12 rows in set (0.00 sec)
2.6 WITH ROLLUP 子句
WITH ROLLUP是SQL中的一个子句, 主要用于与GROUP BY子句结合使用, 以在查询结果中生成小计和总计.
当在查询中使用GROUP BY对数据进行分组后, WITH ROLLUP会在结果集的末尾添加额外的行, 这些行显示了基于当前分组层次结构的汇总信息.语法: SELECT department_id, AVG(salary) FROM employees GROUP BY department_id WITH ROLLUP;注意事项:
* 1. 汇总值通常是基于所选的聚合函数来计算的(如汇总AVG()函数的平均值, 那么汇总的结果也就是平均值).
* 2. 当使用WITH ROLLUP进行分组时, 如果在汇总时列的某个值为NULL, 那么该列在汇总行中的值也会被设置为NULL.
* 3. 使用多列进行分组时, WITH ROLLUP会按照你指定的列的顺序生成不同级别的汇总.例如, 如果按照列A和列B进行分组, 那么WITH ROLLUP会首先为每一组(A, B)生成汇总行,然后为每一个唯一的A值生成汇总行(此时B列的值为NULL), 最后在结果集的末尾生成一个包含所有行汇总的单一行(此时A和B列的值都为NULL).
* 4. 老版本MySQL使用WITH ROLLUP后不能使用ORDER BY排序.
-- 查询每个部门与岗位的平均工资, 将每列的结尾生产一个汇总:
mysql> SELECT department_id, AVG(salary) FROM employees GROUP BY department_id WITH ROLLUP;
+---------------+--------------+
| department_id | AVG(salary) |
+---------------+--------------+
| NULL | 7000.000000 |
| 10 | 4400.000000 |
| 20 | 9500.000000 |
| 30 | 4150.000000 |
| 40 | 6500.000000 |
| 50 | 3475.555556 |
| 60 | 5760.000000 |
| 70 | 10000.000000 |
| 80 | 8955.882353 |
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
| NULL | 6461.682243 | -- 汇总为: 所有部门的平均工资.
+---------------+--------------+
13 rows in set (0.00 sec)-- 查询每个部门的最工资总和:
mysql> SELECT department_id, SUM(salary) FROM employees GROUP BY department_id WITH ROLLUP;
+---------------+-------------+
| department_id | SUM(salary) |
+---------------+-------------+
| NULL | 7000.00 |
| 10 | 4400.00 |
| 20 | 19000.00 |
| 30 | 24900.00 |
| 40 | 6500.00 |
| 50 | 156400.00 |
| 60 | 28800.00 |
| 70 | 10000.00 |
| 80 | 304500.00 |
| 90 | 58000.00 |
| 100 | 51600.00 |
| 110 | 20300.00 |
| NULL | 691400.00 | -- 总汇为: 所有部门的工资总和.
+---------------+-------------+
13 rows in set (0.00 sec)
-- 多列分组使用WITH ROLLUP:
mysql> SELECT department_id, job_id, AVG(salary) FROM employees GROUP BY department_id, job_id WITH ROLLUP;
+---------------+------------+--------------+
| department_id | job_id | AVG(salary) |
+---------------+------------+--------------+
| NULL | SA_REP | 7000.000000 |
| NULL | NULL | 7000.000000 | -- 计算department_id和job_id的所有组合平均值.
| 10 | AD_ASST | 4400.000000 |
| 10 | NULL | 4400.000000 | -- 计算department_id和job_id的所有组合平均值.
| 20 | MK_MAN | 13000.000000 |
| 20 | MK_REP | 6000.000000 |
| 20 | NULL | 9500.000000 | -- 计算department_id和job_id的所有组合平均值.
| 30 | PU_CLERK | 2780.000000 |
| 30 | PU_MAN | 11000.000000 |
| 30 | NULL | 4150.000000 | -- 计算department_id和job_id的所有组合平均值.
| ... | ... | ... |
| NULL | NULL | 6461.682243 | -- 总汇为所有department_id和job_id组合的平均值.
+---------------+------------+--------------+
33 rows in set (0.00 sec)
-- 查询每个部门的平均工资并按工资升序:
mysql> SELECT department_id, AVG(salary) AS `avg_sal` FROM employees
GROUP BY department_id WITH ROLLUP ORDER BY avg_sal ASC;
+---------------+--------------+
| department_id | avg_sal |
+---------------+--------------+
| 50 | 3475.555556 |
| 30 | 4150.000000 |
| 10 | 4400.000000 |
| 60 | 5760.000000 |
| NULL | 6461.682243 |
| 40 | 6500.000000 |
| NULL | 7000.000000 |
| 100 | 8600.000000 |
| 80 | 8955.882353 |
| 20 | 9500.000000 |
| 70 | 10000.000000 |
| 110 | 10150.000000 |
| 90 | 19333.333333 |
+---------------+--------------+
13 rows in set (0.00 sec)-- 5.7版本:
mysql> SELECT department_id, AVG(salary) AS `avg_sal` FROM employees
GROUP BY department_id WITH ROLLUP ORDER BY avg_sal ASC;
ERROR 1221 (HY000): Incorrect usage of CUBE/ROLLUP and ORDER BY
3. HAVING过滤
3.1 基本语法
在MySQL中, HAVING关键字主要用于对分组后的数据进行过滤.HAVING子句的基本语法如下:
HAVING <查询条件>
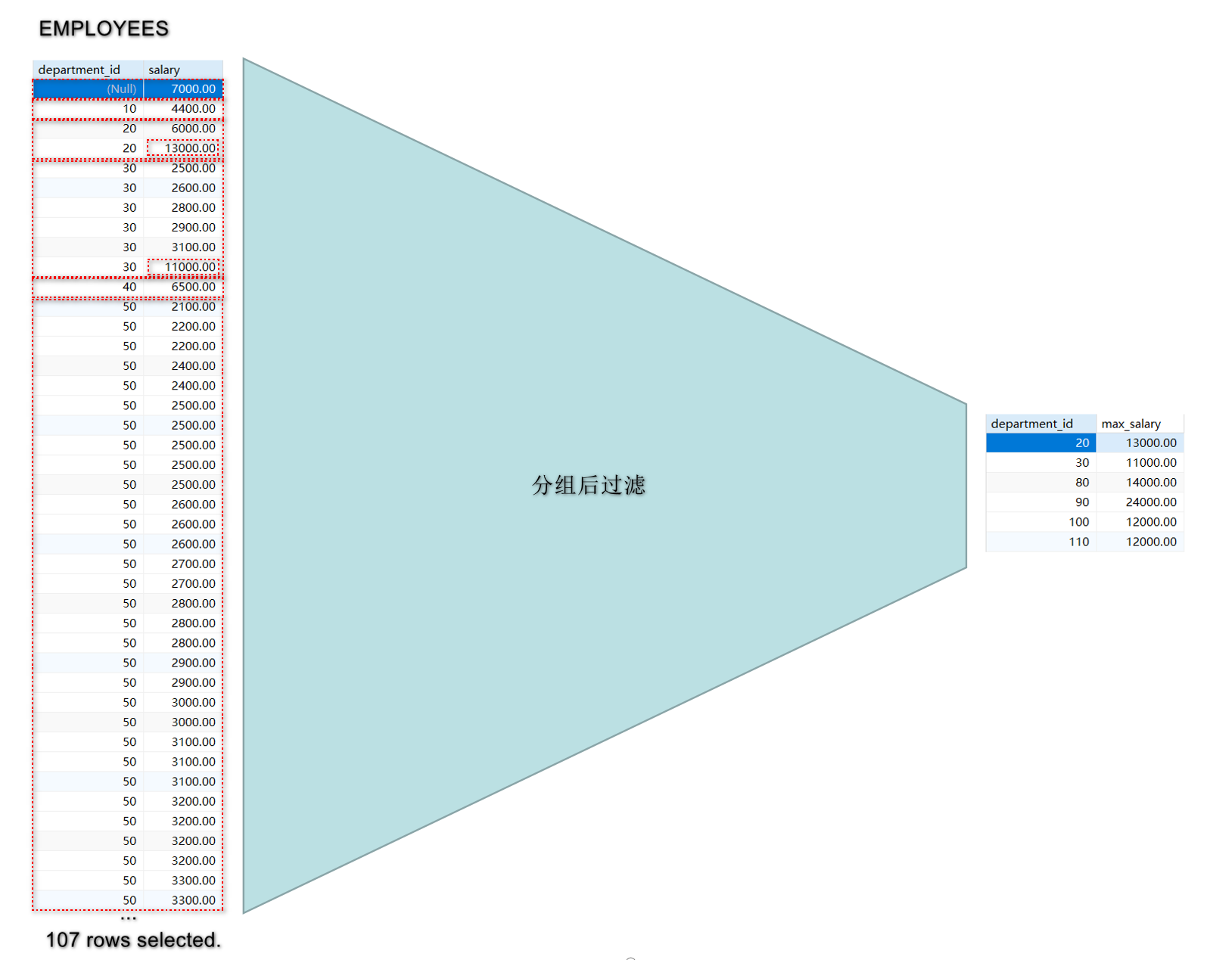
其中, <查询条件>指的是指定的过滤条件, 可以包含聚合函数.例如, 如果你想要查询各部门最高工资大于10000的部门信息, 可以使用以下查询:
SELECT department, MAX(salary) as max_salary
FROM employees
GROUP BY department
HAVING max_salary > 10000;
在这个查询中, 首先使用GROUP BY子句按部门对员工进行分组, 然后使用MAX(salary)聚合函数计算每个部门的最高工资.
最后, 使用HAVING子句过滤出最高工资大于10000的部门.注意事项:
* 1. 当过滤条件中使用了聚合函数时, 必须使用HAVING而不是WHERE.这是因为WHERE子句在数据分组前进行过滤, 并且不支持聚合函数, 而HAVING子句是在数据分组后进行过滤, 并支持使用聚合函数.
* 2. HAVING子句通常与GROUP BY子句一起使用, 且声明在GROUP BY子句的后面.另外, 虽然HAVING可以单独使用, 但当过滤条件中没有聚合函数时, 推荐使用WHERE子句, 因为它的执行效率更高.
-- 查询各部门最高工资大于10000的部门信息:
mysql> SELECT department_id, MAX(salary) AS `max_salary` FROM employees
GROUP BY department_id HAVING max_salary > 10000;
+---------------+------------+
| department_id | max_salary |
+---------------+------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
| 80 | 14000.00 |
| 90 | 24000.00 |
| 100 | 12000.00 |
| 110 | 12000.00 |
+---------------+------------+
6 rows in set (0.00 sec)
3.2 基本使用
-- 查询部门id为10, 20, 30, 40这4个部门中最高工资大于10000高的部门信息:
mysql> SELECT department_id, MAX(salary) AS `max_salary` FROM employees
WHERE department_id IN (10, 20, 30, 40)
GROUP BY department_id HAVING max_salary > 10000;
+---------------+------------+
| department_id | max_salary |
+---------------+------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
+---------------+------------+
2 rows in set (0.00 sec)-- 低效的方式:
-- 当过滤条件中没有聚合函数时, 则此过滤条件声明在WHERE中或HAVING中都可以. 但是声明在WHERE中效率更高.
-- 先分组后过滤: 如果分组的数据量特别大, 那么首先进行分组可能会消耗较多的计算资源.
-- 先过滤后分组: 滤掉不需要的数据, 然后再进行分组, 这可以减少分组操作的数据量, 从而提高查询效率.
mysql> SELECT department_id, MAX(salary) AS `max_salary` FROM employees
GROUP BY department_id HAVING max_salary > 10000 AND department_id IN (10, 20, 30, 40);
+---------------+------------+
| department_id | max_salary |
+---------------+------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
+---------------+------------+
2 rows in set (0.00 sec)
3.3 WHERE和HAVING的对比
WHERE和HAVING的对比:
* 1. WHERE可以直接使用表中的字段作为筛选条件, 但不能使用分组中的计算函数作为筛选条件;HAVING必须要与GROUP BY配合使用, 可以把分组计算的函数和分组字段作为筛选条件.这决定了, 在需要对数据进行分组统计的时候, HAVING可以完成WHERE不能完成的任务.这是因为, 在查询语法结构中, WHERE在GROUP BY之前, 所以无法对分组结果进行筛选.HAVING 在 GROUP BY 之后, 可以使用分组字段和分组中的计算函数, 对分组的结果集进行筛选, 这个功能是 WHERE 无法完成的.另外, WHERE排除的记录不再包括在分组中.* 2. 如果需要通过连接从关联表中获取需要的数据, WHERE是先筛选后连接, 而HAVING是先连接后筛选.这一点, 就决定了在关联查询中, WHERE比HAVING更高效.因为WHERE可以先筛选, 用一个筛选后的较小数据集和关联表进行连接, 这样占用的资源比较少, 执行效率也比较高.HAVING则需要先把结果集准备好, 也就是用未被筛选的数据集进行关联, 然后对这个大的数据集进行筛选, 这样占用的资源就比较多, 执行效率也较低.
关键字 | 优点 | 缺点 |
|---|---|---|
WHERE | 先筛选数据再关联, 执行效率高. | 不能使用分组中的计算函数进行筛选. |
HAVING | 可以使用分组中的计算函数. | 在最后的结果集中进行筛选, 执行效率较低. |
开发中的选择:
WHERE和HAVING不是互相排斥的, 可以在一个查询里面同时使用WHERE和HAVING.
包含分组统计函数的条件用HAVING, 普通条件用WHERE.
这样, 既利用了WHERE条件的高效快速,又发挥了HAVING可以使用包含分组统计函数的查询条件的优点.
当数据量特别大的时候, 运行效率会有很大的差别.
4. SQL底层执行原理
4.1 查询的结构
关键字顺序: SELECT ... FROM ... JOIN ... ON ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
-- sql92语法:
SELECT DISTINCT -- 组合去重column1, -- 分组字段column2, aggregate_function(column3) AS alias_name -- 集合函数
FROM table1
JOIN -- 表连接table2
ON table1.id = table2.table1_id -- 表连接条件
WHERE -- 过滤条件table1.column4 = 'some_value' AND table2.column5 > 100
GROUP BY -- 按字段分组column1, column2
HAVING -- 聚合函数过滤aggregate_function(column3) > some_value
ORDER BY -- 排序column1 ASC, aggregate_function(column3) DESC
LIMIT -- 分页offset, number_of_rows;
-- sql99语法
SELECT DISTINCT -- 组合去重column1, -- 分组字段column2, aggregate_function(column3) AS alias_name -- 集合函数
FROM table1
(LEFT / RIGHT) JOIN -- 表连接table2
ON table1.id = table2.table1_id -- 表连接条件
WHERE -- 过滤条件table1.column4 = 'some_value' AND table2.column5 > 100
GROUP BY -- 按字段分组column1, column2
HAVING -- 聚合函数过滤aggregate_function(column3) > some_value
ORDER BY -- 排序column1 ASC, alias_name DESC
LIMIT -- 分页offset, number_of_rows;
4.2 SELECT执行顺序
SQL语句的各个部分会按照以下顺序进行处理:
* 1. FROM ... JOIN ... ON首先, 数据库会根据FROM子句确定要查询的表.然后, 如果存在JOIN操作(如INNER JOIN, LEFT JOIN, RIGHT JOIN等), 数据库会根据ON子句中指定的条件将这些表连接起来.* 2. WHERE在连接了所有必要的表之后, WHERE子句会过滤出满足条件的记录. 这一步会大大减少需要处理的记录数.* 3. GROUP BY接下来, GROUP BY子句会将结果集按照指定的列进行分组.这通常与聚合函数(如SUM(), COUNT(), AVG()等)一起使用, 以便对每个组进行计算.* 4. HAVINGHAVING子句用于过滤分组后的结果.它类似于WHERE子句, 但作用于分组后的数据, 而不是原始的记录.* 5. SELECT在此阶段, 数据库会选择要显示的列. 这包括直接选择的列和通过聚合函数计算得到的列.* 6. DISTINCT如果在SELECT子句中使用了DISTINCT关键字, 数据库会去除结果集中的重复行.* 7. ORDER BYORDER BY子句会对结果集进行排序.可以按照一列或多列进行排序, 并指定升序(ASC)或降序(DESC).* 8. LIMIT最后, LIMIT子句用于限制返回的记录数. 这对于分页查询特别有用, 因为它允许你只获取结果集的一个子集.需要注意的是, 虽然上述顺序是SQL语句的逻辑执行顺序, 但实际的物理执行计划可能会因数据库优化器的决策而有所不同.
优化器会根据表的大小, 索引的存在与否, 统计信息等因素来决定如何最有效地执行查询.
执行顺序: FROM ... JOIN ... ON -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
在SELECT语句执行这些步骤的时候, 每个步骤都会产生一个虚拟表, 然后将这个虚拟表传入下一个步骤中作为输入.
需要注意的是, 这些步骤隐含在SQL的执行过程中, 对于我们来说是不可见的.
4.3 SQL 的执行原理
SELECT是先执行FROM这一步的.
在这个阶段, 如果是多张表联查, 还会经历下面的几个步骤:
* 1. 首先先通过CROSS JOIN求笛卡尔积, 相当于得到虚拟表 vt (virtual table) 1-1;
* 2. 通过ON进行筛选, 在虚拟表vt1-1的基础上进行筛选, 得到虚拟表 vt1-2;
* 3. 添加外部行. 如果我们使用的是左连接, 右链接或者全连接, 就会涉及到外部行, 也就是在虚拟表 vt1-2 的基础上增加外部行, 得到虚拟表 vt1-3.当然如果我们操作的是两张以上的表, 还会重复上面的步骤, 直到所有表都被处理完为止.
这个过程得到是我们的原始数据.当我们拿到了查询数据表的原始数据, 也就是最终的虚拟表vt1, 就可以在此基础上再进行WHERE阶段.
在这个阶段中, 会根据vt1表的结果进行筛选过滤, 得到虚拟表 vt2.然后进入第三步和第四步, 也就是GROUP BY和HAVING阶段.
在这个阶段中, 实际上是在虚拟表vt2的基础上进行分组和分组过滤, 得到中间的虚拟表vt3和vt4.当我们完成了条件筛选部分之后, 就可以筛选表中提取的字段, 也就是进入到SELECT和DISTINCT阶段.
首先在SELECT阶段会提取想要的字段, 然后在DISTINCT阶段过滤掉重复的行, 分别得到中间的虚拟表vt5-1和vt5-2.当我们提取了想要的字段数据之后, 就可以按照指定的字段进行排序, 也就是ORDER BY阶段, 得到虚拟表vt6.最后在vt6的基础上, 取出指定行的记录, 也就是LIMIT阶段, 得到最终的结果, 对应的是虚拟表vt7.当然我们在写SELECT语句的时候, 不一定存在所有的关键字, 相应的阶段就会省略.
4.4 别名问题
在SQL中, 字段别名主要在SELECT子句中使用, 以便为查询结果的列提供更具描述性或更简洁的名称.
然而, 别名在查询的其他部分(如WHERE和GROUP BY子句)中的使用是有限制的, 这主要是出于查询逻辑和语法解析的考虑.为什么WHERE和GROUP BY不能使用别名?
逻辑顺序: SQL查询的执行顺序并不是按照你写的顺序来的.
虽然书写顺序是: FROM -> WHERE -> GROUP BY -> HAVING -> SELECT, 但实际执行时, WHERE和GROUP BY会在SELECT之前被处理.
因此, 在WHERE或GROUP BY中使用别名时, 该别名可能尚未被定义或识别.解析顺序: SQL查询解析器在处理查询时, 需要按照特定的顺序来解析各个子句.
如果允许在WHERE或GROUP BY中使用别名, 那么解析器就需要进行更复杂的处理, 以确保别名在正确的上下文中被解析.为什么HAVING可以使用别名?
标准的SQL标准是不允许在having中使用select子句中的别名, 但是MySQL对这个地方进行了扩展.
官网中明确表示: 可以在group by, having子句中使用别名, 不可以在where中使用别名。地址: https://dev.mysql.com/doc/refman/8.0/en/problems-with-alias.html .

地址: https://dev.mysql.com/doc/refman/8.0/en/group-by-handling.html .
5. 练习
* 1. where子句可否使用组函数进行过滤?
答: where不支持组函数过滤, 组函数过滤需要使用having子句.
-- 2. 查询公司员工工资的最大值, 最小值, 平均值, 总和:
mysql> SELECT MAX(salary), MIN(salary), AVG(salary), SUM(salary) FROM employees;
+-------------+-------------+-------------+-------------+
| MAX(salary) | MIN(salary) | AVG(salary) | SUM(salary) |
+-------------+-------------+-------------+-------------+
| 24000.00 | 2100.00 | 6461.682243 | 691400.00 |
+-------------+-------------+-------------+-------------+
1 row in set (0.00 sec)
-- 3. 查询员工最高工资和最低工资的差距(别名difference):
mysql> SELECT MAX(salary), MIN(salary), MAX(salary) - MIN(salary) AS `difference` FROM employees;
+-------------+-------------+------------+
| MAX(salary) | MIN(salary) | difference |
+-------------+-------------+------------+
| 24000.00 | 2100.00 | 21900.00 | -- 人与人之间的差别超越了物种之间的差别, 加油吧!!!
+-------------+-------------+------------+
1 row in set (0.00 sec)
-- 4. 查询各岗位(job_id)的员工工资的最大值, 最小值, 平均值, 总和:
mysql> SELECT job_id, MAX(salary), MIN(salary), AVG(salary), SUM(salary) FROM employees GROUP BY job_id;
+------------+-------------+-------------+--------------+-------------+
| job_id | MAX(salary) | MIN(salary) | AVG(salary) | SUM(salary) |
+------------+-------------+-------------+--------------+-------------+
| AC_ACCOUNT | 8300.00 | 8300.00 | 8300.000000 | 8300.00 |
| AC_MGR | 12000.00 | 12000.00 | 12000.000000 | 12000.00 |
| AD_ASST | 4400.00 | 4400.00 | 4400.000000 | 4400.00 |
| AD_PRES | 24000.00 | 24000.00 | 24000.000000 | 24000.00 |
| AD_VP | 17000.00 | 17000.00 | 17000.000000 | 34000.00 |
| FI_ACCOUNT | 9000.00 | 6900.00 | 7920.000000 | 39600.00 |
| FI_MGR | 12000.00 | 12000.00 | 12000.000000 | 12000.00 |
| HR_REP | 6500.00 | 6500.00 | 6500.000000 | 6500.00 |
| IT_PROG | 9000.00 | 4200.00 | 5760.000000 | 28800.00 |
| MK_MAN | 13000.00 | 13000.00 | 13000.000000 | 13000.00 |
| MK_REP | 6000.00 | 6000.00 | 6000.000000 | 6000.00 |
| PR_REP | 10000.00 | 10000.00 | 10000.000000 | 10000.00 |
| PU_CLERK | 3100.00 | 2500.00 | 2780.000000 | 13900.00 |
| PU_MAN | 11000.00 | 11000.00 | 11000.000000 | 11000.00 |
| SA_MAN | 14000.00 | 10500.00 | 12200.000000 | 61000.00 |
| SA_REP | 11500.00 | 6100.00 | 8350.000000 | 250500.00 |
| SH_CLERK | 4200.00 | 2500.00 | 3215.000000 | 64300.00 |
| ST_CLERK | 3600.00 | 2100.00 | 2785.000000 | 55700.00 |
| ST_MAN | 8200.00 | 5800.00 | 7280.000000 | 36400.00 |
+------------+-------------+-------------+--------------+-------------+
19 rows in set (0.00 sec)
-- 5. 统计各个岗位(job_id)的员工人数:
mysql> SELECT job_id, COUNT(*) FROM employees GROUP BY job_id;
+------------+----------+
| job_id | COUNT(*) |
+------------+----------+
| AC_ACCOUNT | 1 |
| AC_MGR | 1 |
| AD_ASST | 1 |
| AD_PRES | 1 |
| AD_VP | 2 |
| FI_ACCOUNT | 5 |
| FI_MGR | 1 |
| HR_REP | 1 |
| IT_PROG | 5 |
| MK_MAN | 1 |
| MK_REP | 1 |
| PR_REP | 1 |
| PU_CLERK | 5 |
| PU_MAN | 1 |
| SA_MAN | 5 |
| SA_REP | 30 |
| SH_CLERK | 20 |
| ST_CLERK | 20 |
| ST_MAN | 5 |
+------------+----------+
19 rows in set (0.00 sec)
-- 6.查询各个管理者手下员工的最低工资, 其中最低工资不能低于6000, 没有管理者的员工不计算在内:
mysql> SELECT manager_id, MIN(salary) AS `min_salary`
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING min_salary > 6000;
+------------+------------+
| manager_id | min_salary |
+------------+------------+
| 102 | 9000.00 |
| 108 | 6900.00 |
| 145 | 7000.00 |
| 146 | 7000.00 |
| 147 | 6200.00 |
| 148 | 6100.00 |
| 149 | 6200.00 |
| 205 | 8300.00 |
+------------+------------+
8 rows in set (0.00 sec)
-- 7.查询所有部门的名字, 地址id(location_id), 员工数量和平均工资, 并按平均工资降序:
-- 两个表拼接需要查询所有部门的名字, 地址id(location_id), 这两个字段在第二张表, 那肯定是右连接(左表中可能存在NULL).
SELECT department_name, location_id, COUNT(*), AVG(salary) AS `avg_salary`
FROM employees AS `emp`
RIGHT JOIN departments AS `dep`
ON emp.department_id = dep.department_id
GROUP BY department_name, location_id
ORDER BY avg_salary DESC;
+----------------------+-------------+----------+--------------+
| department_name | location_id | COUNT(*) | avg_salary |
+----------------------+-------------+----------+--------------+
| Executive | 1700 | 3 | 19333.333333 |
| Accounting | 1700 | 2 | 10150.000000 |
| Public Relations | 2700 | 1 | 10000.000000 |
| Marketing | 1800 | 2 | 9500.000000 |
| Sales | 2500 | 34 | 8955.882353 |
| Finance | 1700 | 6 | 8600.000000 |
| Human Resources | 2400 | 1 | 6500.000000 |
| IT | 1400 | 5 | 5760.000000 |
| Administration | 1700 | 1 | 4400.000000 |
| Purchasing | 1700 | 6 | 4150.000000 |
| Shipping | 1500 | 45 | 3475.555556 |
| ... | ... | ... | ... | -- 省略
| Retail Sales | 1700 | 1 | NULL |
| Recruiting | 1700 | 1 | NULL |
| Payroll | 1700 | 1 | NULL |
+----------------------+-------------+----------+--------------+
27 rows in set (0.00 sec)
-- 8. 查询每个部名称呼, 岗位名称和最低工资:
-- 查询每个部名称呼先就使用右连接(左表中可能存在NULL).
SELECT department_name, job_id, MIN(salary) AS `min_salary`
FROM employees AS `emp`
RIGHT JOIN departments AS `dep`
ON emp.department_id = dep.department_id
GROUP BY department_name, job_id;
+----------------------+------------+------------+
| department_name | job_id | min_salary |
+----------------------+------------+------------+
| Administration | AD_ASST | 4400.00 |
| Marketing | MK_MAN | 13000.00 |
| Marketing | MK_REP | 6000.00 |
| Purchasing | PU_MAN | 11000.00 |
| Purchasing | PU_CLERK | 2500.00 |
| Human Resources | HR_REP | 6500.00 |
| Shipping | ST_MAN | 5800.00 |
| ... | ... | ... | -- 省略
| IT Support | NULL | NULL |
| NOC | NULL | NULL |
| IT Helpdesk | NULL | NULL |
| Government Sales | NULL | NULL |
| Retail Sales | NULL | NULL |
| Recruiting | NULL | NULL |
| Payroll | NULL | NULL |
+----------------------+------------+------------+
35 rows in set (0.00 sec)
相关文章:
25.5 MySQL 聚合函数
1. 聚合函数 聚合函数(Aggregate Function): 是在数据库中进行数据处理和计算的常用函数. 它们可以对一组数据进行求和, 计数, 平均值, 最大值, 最小值等操作, 从而得到汇总结果.常见的聚合函数有以下几种: SUM: 用于计算某一列的数值总和, 可以用于整数, 小数或者日期类型的列…...

多维时序 | Matlab实现VMD-CNN-LSTM变分模态分解结合卷积神经网络结合长短期记忆神经网络多变量时间序列预测
多维时序 | Matlab实现VMD-CNN-LSTM变分模态分解结合卷积神经网络结合长短期记忆神经网络多变量时间序列预测 目录 多维时序 | Matlab实现VMD-CNN-LSTM变分模态分解结合卷积神经网络结合长短期记忆神经网络多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介…...

用Python进行机器学习:Scikit-learn的入门与实践【第126篇—Scikit-learn的入门】
用Python进行机器学习:Scikit-learn的入门与实践 随着机器学习在各个领域的广泛应用,Python成为了一个备受欢迎的机器学习工具之一。在众多机器学习库中,Scikit-learn因其简单易用、功能强大而备受青睐。本文将介绍Scikit-learn的基本概念&am…...

2024年G3锅炉水处理证模拟考试题库及G3锅炉水处理理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年G3锅炉水处理证模拟考试题库及G3锅炉水处理理论考试试题是由安全生产模拟考试一点通提供,G3锅炉水处理证模拟考试题库是根据G3锅炉水处理最新版教材,G3锅炉水处理大纲整理而成࿰…...

常用的gpt网站
ChatGPT是一款基于人工智能技术的对话型AI助手,能够进行自然语言交互并提供个性化的对话服务。通过先进的深度学习模型,ChatGPT能够理解用户输入的文本,并生成有逻辑、连贯性的回复。它可以回答各种问题、提供建议、分享知识,还能…...

java中string类型常用的37个函数
java中string类型常用的37个函数—无极低码 int indexOf(int ch, int fromIndex) 、int indexOf(int ch) 、int indexOf(String str, int fromIndex) 、int indexOf(String str) 、int lastIndexOf(int ch, int fromIndex) 、int lastIndexOf(int ch) 、int lastIndexOf(Strin…...

【JVM】字节码指令 getstatic
在Java虚拟机(JVM)中,getstatic 是一个字节码指令,用于从类的静态字段(Static Field)获取值,并将这个值压入当前方法的操作数栈顶。这个操作仅适用于类级别的静态变量,而非实例变量。…...

P1179 [NOIP2010 普及组] 数字统计
#include <bits/stdc.h> using namespace std;int main(){int l;int r;cin>>l>>r;int sum 0;for (int i l;i < r;i){int temp 0;int j i;while(j){if(j % 10 2){temp;}j j/10;}sum sum temp;}cout << sum;return 0; }[NOIP2010 普及组] 数字…...

使用Java的等待/通知机制实现一个简单的阻塞队列
Java的等待/通知机制 Java的等待通知机制是多线程间进行通信的一种方式。 有三个重要的方法:wait(),notify() 和以及notifyAll() wait():该方法用于让当前线程(即调用该方法的线程)进入等待状态并且释放掉该对象上的…...
)
linux kernel物理内存概述(七)
目录 一、内核中小内存、频繁分配和释放场景 二、slab是内存池化技术 三、内核中使用slab对象池的地方 四、slab内核设计 使用比页小的内存,内核的处理方式使用slab 一、内核中小内存、频繁分配和释放场景 slab首先会向伙伴系统一次性申请一个或者多个物理内存…...
【C#】.net core 6.0 使用第三方日志插件Log4net,日志输出到控制台或者文本文档
欢迎来到《小5讲堂》 大家好,我是全栈小5。 这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。…...

TSINGSEE青犀煤矿矿井视频监控与汇聚融合管理视频监管平台建设方案
一、背景需求 随着我国经济的飞速发展,煤炭作为我国的主要能源之一,其开采和利用的重要性不言而喻。然而,煤矿事故频发,不仅造成了巨大的人员伤亡和财产损失,也对社会产生了深远的负面影响。视频监控系统作为实现煤矿智…...
C语言 - 各种自定义数据类型
1.结构体 把不同类型的数据组合成一个整体 所占内存长度是各成员所占内存的总和 typedef struct XXX { int a; char b; }txxx; txxx data; typedef struct XXX { int a:1; int b:1; …...

第四弹:Flutter图形渲染性能
目标: 1)Flutter图形渲染性能能够媲美原生? 2)Flutter性能优于React Native? 一、Flutter图形渲染原理 1.1 Flutter图形渲染原理 Flutter直接调用Skia 1)Flutter将一帧录制成SkPicture(skpÿ…...
#蓝桥杯)
基础算法(三)#蓝桥杯
文章目录 11、构造11.1、小浩的ABC11.2、小新的质数序列挑战11.3、小蓝找答案11.4、小蓝的无限集 12、高精度12.1、阶乘数码(高精度*单精度) 11、构造 11.1、小浩的ABC #include<bits/stdc.h> using namespace std; #define IOS ios::sync_with_stdio(false);cin.tie(n…...

人工智能在增强数据安全方面的作用
近年来,人工智能(AI)的力量已被证明是无与伦比的。它不再是我们想象的主题。人工智能已经成为现实,并且越来越清楚地表明它可以让世界变得更美好。但人工智能能帮助我们增强数据安全吗? 由于技术的日益普及࿰…...

python】jupyter notebook导出pdf和pdf不显示中文问题
安装nbconvert 首先安装nbconvert才能将.ipynb文件转化为pdf、latex、html等。 conda install nbconvert安装Pandoc Pandoc官网下载地址: https://pandoc.org/installing.html 下载安装包github地址:https://github.com/jgm/pandoc/releases/tag/3.1.6.2 安装MiKTex 下载…...

通过SDKMAN安装各种版本JDK
文章目录 1. 安装SDKMAN管理器2. 通过SDK管理器安装JDK3. 参考链接 1. 安装SDKMAN管理器 安装SDKMAN的脚本为: # 1.1 安装: 如果没有权限可以考虑sudo用户执行; curl -s "https://get.sdkman.io" | bash# 1.2 安装完成后查看版本号 sdk version# 1.3 查看帮助信息 …...

软考高级:软件架构风格概念和例题
作者:明明如月学长, CSDN 博客专家,大厂高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《Effective Java》独家解析》专栏作者。 热门文章推荐&am…...

Vue3响应式编程
Vue 3 的响应式系统是其核心特性之一,它允许开发者创建响应式的数据绑定和组件状态管理。在 Vue 3 中,响应式系统得到了显著的改进,提供了更好的性能和更灵活的使用方式。 1. 响应式原理 Vue 3 使用了 Proxy 对象来实现响应式系统ÿ…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

别让依赖毁了你的实验:记一次Vision Mamba复现中causal_conv1d与mamba-ssm的版本“打架”事件
Vision Mamba复现实战:破解依赖冲突的工程化解决方案在深度学习项目的复现过程中,依赖管理往往是最容易被忽视却又最常导致问题的环节。最近在复现Vision Mamba模型时,我遭遇了一场典型的Python依赖"战争"——causal_conv1d与mamba…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...

AI 如何改变软件工程:Martin Fowler 视角 + 实战洞见
AI 如何改变软件工程:Martin Fowler 视角 实战洞见 AI(尤其是 LLM)是软件工程自高级语言(从汇编到 C/Fortran)以来最大的转变。它引入了非确定性(Non-deterministic)编程,改变了从编…...

Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南
Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在数字化教育快速发展的今天&…...

密码学入门:区块链中的密码学原理
密码学入门:区块链中的密码学原理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊密码学这个重要话题。作为一个Web3探索者,密码学是区块链的基础。今天就来分享一下区块链中常用的密码学原理。 为什么密码学很重要&a…...