用Python进行机器学习:Scikit-learn的入门与实践【第126篇—Scikit-learn的入门】
用Python进行机器学习:Scikit-learn的入门与实践

随着机器学习在各个领域的广泛应用,Python成为了一个备受欢迎的机器学习工具之一。在众多机器学习库中,Scikit-learn因其简单易用、功能强大而备受青睐。本文将介绍Scikit-learn的基本概念,以及如何在Python中使用它进行机器学习的实践。
1. Scikit-learn简介
Scikit-learn是一个基于NumPy、SciPy和Matplotlib的机器学习库,提供了丰富的工具和算法,涵盖了从数据预处理到模型评估的整个机器学习流程。它支持监督学习、无监督学习和降维等任务,适用于各种应用场景。
# 安装Scikit-learn
pip install scikit-learn
2. 数据准备
在机器学习任务中,数据是至关重要的一环。我们首先需要加载和准备数据,确保数据格式符合Scikit-learn的要求。下面是一个简单的数据准备例子:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
3. 选择模型
在Scikit-learn中,选择模型是一个关键步骤。我们可以根据任务类型选择适当的算法,例如分类任务可选用支持向量机(SVM)、决策树等。
from sklearn.svm import SVC# 创建支持向量机分类器
model = SVC()
4. 模型训练
模型选择好后,我们需要使用训练数据对其进行训练。
# 训练模型
model.fit(X_train, y_train)
5. 模型评估
完成模型训练后,我们需要对其性能进行评估。这通常涉及使用测试集来验证模型的泛化能力。
from sklearn.metrics import accuracy_score# 预测测试集
y_pred = model.predict(X_test)# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确度: {accuracy}")
7. 特征工程与数据预处理
在实际应用中,往往需要对原始数据进行预处理和特征工程,以提高模型的性能。Scikit-learn提供了丰富的工具,帮助我们进行数据清洗、特征缩放等操作。
from sklearn.preprocessing import StandardScaler# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
8. 超参数调优
模型的性能常常取决于超参数的选择。Scikit-learn提供了网格搜索(Grid Search)等方法,帮助我们找到最优的超参数组合。
from sklearn.model_selection import GridSearchCV# 定义超参数搜索空间
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}# 创建GridSearchCV对象
grid_search = GridSearchCV(SVC(), param_grid, cv=5)# 执行超参数搜索
grid_search.fit(X_train_scaled, y_train)# 输出最优参数
print("最优参数:", grid_search.best_params_)
9. 可视化结果
Scikit-learn结合了Matplotlib等可视化库,可以方便地对模型的性能进行可视化展示。
import matplotlib.pyplot as plt
from sklearn.metrics import plot_confusion_matrix# 可视化混淆矩阵
plot_confusion_matrix(model, X_test_scaled, y_test, cmap=plt.cm.Blues)
plt.show()
10. 持续学习与实践
机器学习是一个不断发展的领域,持续学习是提高技能的关键。Scikit-learn提供了丰富的文档和示例,帮助用户更深入地了解每个算法的原理和应用。
通过实践项目,不断尝试新的模型和技术,可以更好地理解机器学习的实际应用。同时,参与开源社区,与其他开发者分享经验,也是提升技能的有效途径。
总的来说,Scikit-learn作为一个强大而灵活的机器学习工具,为Python开发者提供了丰富的功能和便捷的操作。通过不断学习和实践,我们可以更好地利用Scikit-learn构建高效的机器学习应用,为各种挑战找到创新的解决方案。
11. 部署模型与实际应用
成功训练和优化模型后,下一步是将其部署到实际应用中。Scikit-learn模型可以通过各种方式进行部署,例如使用Flask创建API,将模型嵌入到Web应用中,或者将其集成到生产环境中。
# 通过Flask创建API
from flask import Flask, request, jsonifyapp = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.jsonfeatures = scaler.transform([data['features']])prediction = model.predict(features)return jsonify({'prediction': int(prediction[0])})if __name__ == '__main__':app.run(port=5000)
12. 异常处理与模型监控
在实际应用中,模型可能会面临各种异常情况。通过添加适当的异常处理机制,可以提高应用的稳定性。
同时,对模型性能的监控也是至关重要的。通过定期检查模型的预测准确度和其他性能指标,可以及时发现潜在的问题并采取措施进行优化。
13. 高级特性与自定义
Scikit-learn支持许多高级特性和自定义选项,以满足不同应用场景的需求。例如,可以使用Pipeline来串联多个数据处理步骤和模型,使用自定义评估指标来评估模型性能,或者通过继承BaseEstimator创建自定义的机器学习模型。
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier# 创建Pipeline
pipeline = Pipeline([('scaler', StandardScaler()),('classifier', RandomForestClassifier())
])# 在Pipeline中进行训练
pipeline.fit(X_train, y_train)
14. 持续改进与反馈循环
最后,机器学习是一个不断改进的过程。通过收集用户反馈、监控模型性能和持续学习新的技术,可以建立一个反馈循环,不断改进和优化机器学习系统,确保其在不同环境和数据分布下都能表现良好。
通过这篇博客,我们深入了解了使用Python中的Scikit-learn库进行机器学习的基本流程,并介绍了一些高级特性和实践经验。希望读者能够通过实践进一步掌握Scikit-learn的强大功能,将机器学习技术应用到实际项目中,取得更好的成果。祝愿大家在机器学习的旅程中越走越远!
15. 面向未来的发展方向
随着机器学习领域的快速发展,我们不仅要关注Scikit-learn当前的功能和用法,还应关注未来的发展方向。以下是一些可能的趋势和建议:
15.1 深度学习整合
虽然Scikit-learn在传统机器学习领域表现出色,但深度学习近年来崭露头角。未来版本的Scikit-learn可能会更好地整合深度学习模型,以满足更复杂任务的需求。
# 示例:使用深度学习库整合
from sklearn.neural_network import MLPClassifier# 创建多层感知机分类器
mlp_model = MLPClassifier()
mlp_model.fit(X_train_scaled, y_train)
15.2 自动化工具集成
自动化机器学习(AutoML)工具的兴起为模型选择、超参数调优等任务提供了便利。Scikit-learn可能会在未来版本中集成更多自动化工具,简化用户在模型开发中的工作。
# 示例:使用AutoML工具
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV# 创建RandomizedSearchCV对象
param_dist = {'n_estimators': [50, 100, 200], 'max_depth': [None, 10, 20]}
random_search = RandomizedSearchCV(RandomForestClassifier(), param_distributions=param_dist, n_iter=3, cv=5)# 执行随机搜索
random_search.fit(X_train_scaled, y_train)
15.3 更强大的可解释性
在实际应用中,模型的可解释性变得越来越重要。未来版本的Scikit-learn可能会加强模型解释性的功能,帮助用户理解模型的决策过程。
# 示例:使用SHAP(SHapley Additive exPlanations)库进行解释
import shap# 创建解释器
explainer = shap.Explainer(model)
shap_values = explainer.shap_values(X_test_scaled)# 可视化特征重要性
shap.summary_plot(shap_values, X_test_scaled, feature_names=iris.feature_names)
15.4 社区贡献和开源生态
Scikit-learn是一个开源项目,不断受益于全球开发者社区的贡献。未来的发展可能涉及更多算法的添加、性能优化和生态系统的扩展。
# 示例:使用其他社区贡献的算法
from sklearn.ensemble import GradientBoostingClassifier# 创建梯度提升分类器
gb_model = GradientBoostingClassifier()
gb_model.fit(X_train_scaled, y_train)
通过关注这些趋势和发展方向,我们可以更好地准备迎接未来机器学习的挑战,并更灵活地应对不断变化的需求。希望Scikit-learn在未来的版本中能够为机器学习社区提供更多创新和实用的功能。
总结
在这篇博客文章中,我们深入探讨了使用Python中的Scikit-learn库进行机器学习的全面流程。以下是本文的主要总结:
-
Scikit-learn简介: 我们首先介绍了Scikit-learn作为一个基于NumPy、SciPy和Matplotlib的机器学习库,具有简单易用和功能强大的特点。
-
数据准备: 演示了如何加载和准备数据,以确保其符合Scikit-learn的要求,并使用鸢尾花数据集作为例子。
-
选择模型: 引导读者选择适用于任务的模型,例如支持向量机(SVM)用于分类任务。
-
模型训练: 展示了如何使用训练数据对模型进行训练,使其能够理解和学习数据的模式。
-
模型评估: 通过测试集评估模型性能,使用准确度等指标来度量模型的泛化能力。
-
特征工程与数据预处理: 介绍了特征缩放等预处理技术,以提高模型性能。
-
超参数调优: 使用网格搜索等方法找到最优的超参数组合,优化模型性能。
-
可视化结果: 利用Matplotlib等库可视化混淆矩阵等结果,提高对模型性能的理解。
-
部署模型与实际应用: 展示了如何将训练好的模型部署到实际应用中,例如使用Flask创建API。
-
异常处理与模型监控: 强调在实际应用中添加异常处理机制和定期监控模型性能的重要性。
-
高级特性与自定义: 提示读者Scikit-learn支持Pipeline、自定义评估指标等高级特性。
-
持续改进与反馈循环: 强调机器学习是一个不断改进的过程,建议建立反馈循环,保持持续学习。
-
面向未来的发展方向: 探讨了未来Scikit-learn可能的发展方向,包括深度学习整合、自动化工具集成、更强大的可解释性和社区贡献。
通过本文,读者将获得关于使用Scikit-learn进行机器学习的全面指南,包括基本流程、实践经验以及未来发展的趋势。这将有助于读者更好地应用机器学习技术解决实际问题,并为未来的学习和实践提供坚实的基础。
相关文章:
用Python进行机器学习:Scikit-learn的入门与实践【第126篇—Scikit-learn的入门】
用Python进行机器学习:Scikit-learn的入门与实践 随着机器学习在各个领域的广泛应用,Python成为了一个备受欢迎的机器学习工具之一。在众多机器学习库中,Scikit-learn因其简单易用、功能强大而备受青睐。本文将介绍Scikit-learn的基本概念&am…...

2024年G3锅炉水处理证模拟考试题库及G3锅炉水处理理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年G3锅炉水处理证模拟考试题库及G3锅炉水处理理论考试试题是由安全生产模拟考试一点通提供,G3锅炉水处理证模拟考试题库是根据G3锅炉水处理最新版教材,G3锅炉水处理大纲整理而成࿰…...

常用的gpt网站
ChatGPT是一款基于人工智能技术的对话型AI助手,能够进行自然语言交互并提供个性化的对话服务。通过先进的深度学习模型,ChatGPT能够理解用户输入的文本,并生成有逻辑、连贯性的回复。它可以回答各种问题、提供建议、分享知识,还能…...

java中string类型常用的37个函数
java中string类型常用的37个函数—无极低码 int indexOf(int ch, int fromIndex) 、int indexOf(int ch) 、int indexOf(String str, int fromIndex) 、int indexOf(String str) 、int lastIndexOf(int ch, int fromIndex) 、int lastIndexOf(int ch) 、int lastIndexOf(Strin…...

【JVM】字节码指令 getstatic
在Java虚拟机(JVM)中,getstatic 是一个字节码指令,用于从类的静态字段(Static Field)获取值,并将这个值压入当前方法的操作数栈顶。这个操作仅适用于类级别的静态变量,而非实例变量。…...

P1179 [NOIP2010 普及组] 数字统计
#include <bits/stdc.h> using namespace std;int main(){int l;int r;cin>>l>>r;int sum 0;for (int i l;i < r;i){int temp 0;int j i;while(j){if(j % 10 2){temp;}j j/10;}sum sum temp;}cout << sum;return 0; }[NOIP2010 普及组] 数字…...

使用Java的等待/通知机制实现一个简单的阻塞队列
Java的等待/通知机制 Java的等待通知机制是多线程间进行通信的一种方式。 有三个重要的方法:wait(),notify() 和以及notifyAll() wait():该方法用于让当前线程(即调用该方法的线程)进入等待状态并且释放掉该对象上的…...
)
linux kernel物理内存概述(七)
目录 一、内核中小内存、频繁分配和释放场景 二、slab是内存池化技术 三、内核中使用slab对象池的地方 四、slab内核设计 使用比页小的内存,内核的处理方式使用slab 一、内核中小内存、频繁分配和释放场景 slab首先会向伙伴系统一次性申请一个或者多个物理内存…...
【C#】.net core 6.0 使用第三方日志插件Log4net,日志输出到控制台或者文本文档
欢迎来到《小5讲堂》 大家好,我是全栈小5。 这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。…...

TSINGSEE青犀煤矿矿井视频监控与汇聚融合管理视频监管平台建设方案
一、背景需求 随着我国经济的飞速发展,煤炭作为我国的主要能源之一,其开采和利用的重要性不言而喻。然而,煤矿事故频发,不仅造成了巨大的人员伤亡和财产损失,也对社会产生了深远的负面影响。视频监控系统作为实现煤矿智…...
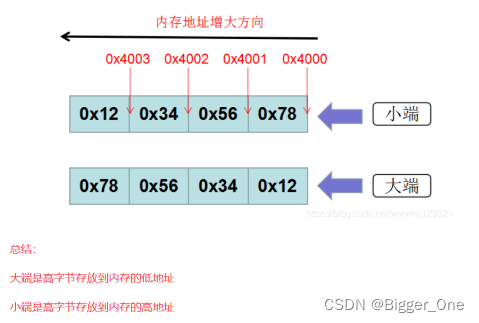
C语言 - 各种自定义数据类型
1.结构体 把不同类型的数据组合成一个整体 所占内存长度是各成员所占内存的总和 typedef struct XXX { int a; char b; }txxx; txxx data; typedef struct XXX { int a:1; int b:1; …...

第四弹:Flutter图形渲染性能
目标: 1)Flutter图形渲染性能能够媲美原生? 2)Flutter性能优于React Native? 一、Flutter图形渲染原理 1.1 Flutter图形渲染原理 Flutter直接调用Skia 1)Flutter将一帧录制成SkPicture(skpÿ…...
#蓝桥杯)
基础算法(三)#蓝桥杯
文章目录 11、构造11.1、小浩的ABC11.2、小新的质数序列挑战11.3、小蓝找答案11.4、小蓝的无限集 12、高精度12.1、阶乘数码(高精度*单精度) 11、构造 11.1、小浩的ABC #include<bits/stdc.h> using namespace std; #define IOS ios::sync_with_stdio(false);cin.tie(n…...

人工智能在增强数据安全方面的作用
近年来,人工智能(AI)的力量已被证明是无与伦比的。它不再是我们想象的主题。人工智能已经成为现实,并且越来越清楚地表明它可以让世界变得更美好。但人工智能能帮助我们增强数据安全吗? 由于技术的日益普及࿰…...

python】jupyter notebook导出pdf和pdf不显示中文问题
安装nbconvert 首先安装nbconvert才能将.ipynb文件转化为pdf、latex、html等。 conda install nbconvert安装Pandoc Pandoc官网下载地址: https://pandoc.org/installing.html 下载安装包github地址:https://github.com/jgm/pandoc/releases/tag/3.1.6.2 安装MiKTex 下载…...

通过SDKMAN安装各种版本JDK
文章目录 1. 安装SDKMAN管理器2. 通过SDK管理器安装JDK3. 参考链接 1. 安装SDKMAN管理器 安装SDKMAN的脚本为: # 1.1 安装: 如果没有权限可以考虑sudo用户执行; curl -s "https://get.sdkman.io" | bash# 1.2 安装完成后查看版本号 sdk version# 1.3 查看帮助信息 …...

软考高级:软件架构风格概念和例题
作者:明明如月学长, CSDN 博客专家,大厂高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《Effective Java》独家解析》专栏作者。 热门文章推荐&am…...

Vue3响应式编程
Vue 3 的响应式系统是其核心特性之一,它允许开发者创建响应式的数据绑定和组件状态管理。在 Vue 3 中,响应式系统得到了显著的改进,提供了更好的性能和更灵活的使用方式。 1. 响应式原理 Vue 3 使用了 Proxy 对象来实现响应式系统ÿ…...
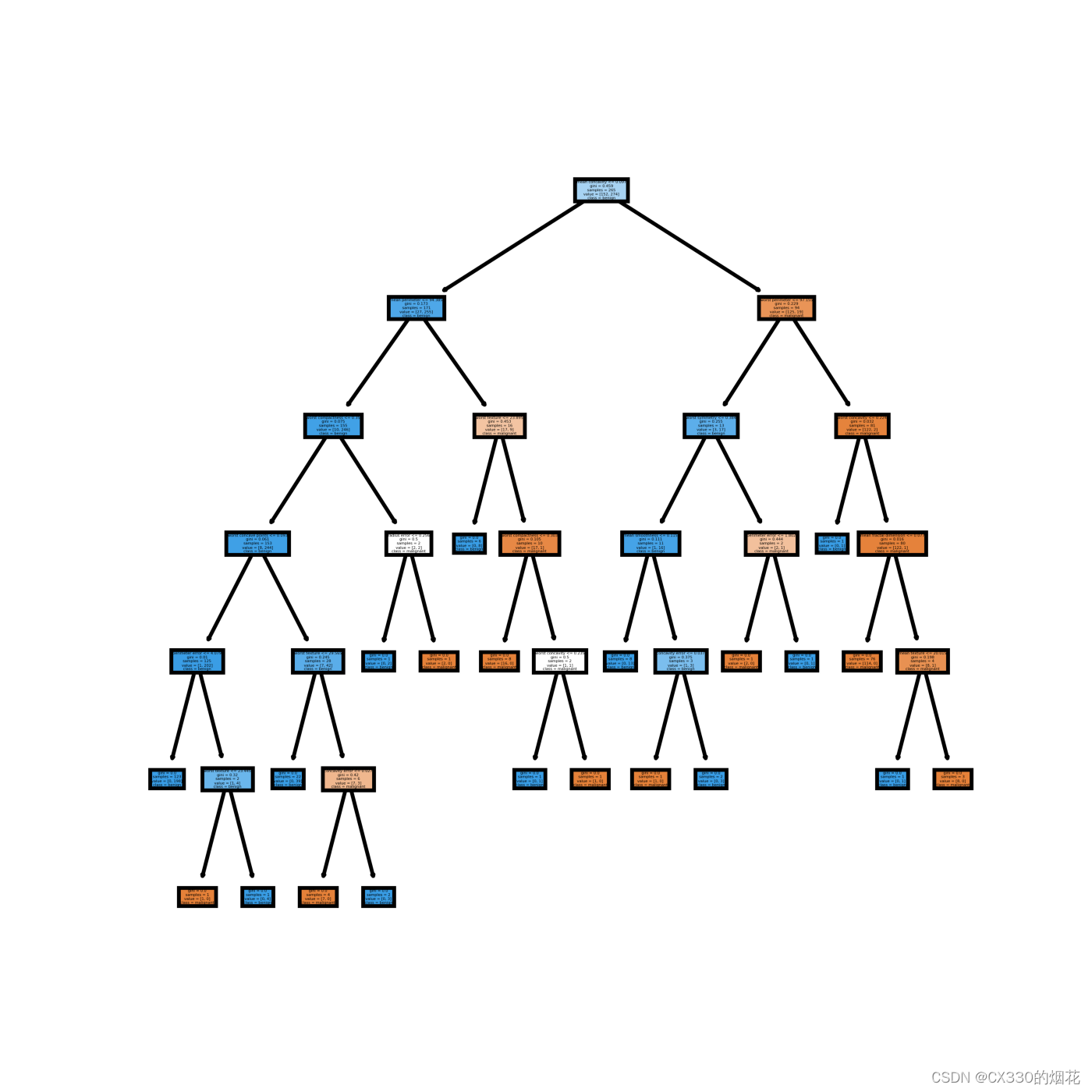
决策树算法优化(一篇文章 理解)
目录 引言 一、决策树的基本概念 二、决策树的构建过程 1 特征选择 2 决策树生成 3 决策树剪枝 三、决策树算法的缺点 1 过拟合问题 2 对噪声敏感 3 缺乏连续变量的处理 4 倾向于选择具有较多类别的特征 四、优化策略 1 集成学习 2 连续变量处理 3 特征选择优化 …...

【C语言步行梯】自定义函数、函数递归详谈
🎯每日努力一点点,技术进步看得见 🏠专栏介绍:【C语言步行梯】专栏用于介绍C语言相关内容,每篇文章将通过图片代码片段网络相关题目的方式编写,欢迎订阅~~ 文章目录 什么是函数库函数自定义函数函数执行示例…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

利用 Taotoken 多模型能力为智能客服场景提供备份路由
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型能力为智能客服场景提供备份路由 智能客服系统是许多企业与用户交互的关键入口,其响应能力和服务…...