XGB-20:XGBoost中不同参数的预测函数
有许多在XGBoost中具有不同参数的预测函数。
预测选项
xgboost.Booster.predict() 方法有许多不同的预测选项,从 pred_contribs 到 pred_leaf 不等。输出形状取决于预测的类型。对于多类分类问题,XGBoost为每个类构建一棵树,每个类的树称为树的“组”,因此输出维度可能会因所使用的模型而改变。
在1.4版本后,添加了 strict_shape 的新参数。可以将其设置为 True,以指示希望获得更受限制的输出。假设正在使用 xgboost.Booster,以下是可能的返回列表:
-
使用
strict_shape设置为True进行正常预测时:- 输出是一个2维数组,第一维是行数,第二维是组数。对于回归/生存/排序/二分类,这相当于一个形状为
shape[1] == 1的列向量。但对于多类别问题,使用multi:softprob时,列数等于类别数。如果strict_shape设置为False,输出1维或2维数组
- 输出是一个2维数组,第一维是行数,第二维是组数。对于回归/生存/排序/二分类,这相当于一个形状为
-
使用
output_margin避免转换且strict_shape设置为True时:- 输出是一个2维数组,除了
multi:softmax由于去掉了转换而具有与multi:softprob相等的输出形状。如果strict_shape设置为False,则输出可以具有1维或2维,具体取决于所使用的模型
- 输出是一个2维数组,除了
-
使用
pred_contribs且strict_shape设置为True时:- 输出是一个3维数组,形状为(
行数,组数,列数+1)。是否使用approx_contribs不会改变输出形状。如果未设置strict_shape参数,则它可以是2维或3维数组,具体取决于是否使用多类别模型
- 输出是一个3维数组,形状为(
-
使用
pred_interactions且strict_shape设置为True时:- 输出是一个4维数组,形状为(
行数,组数,列数+1,列数+1)。是否使用approx_contribs不会改变输出形状。如果strict_shape设置为False,则它可以具有3维或4维,具体取决于底层模型
- 输出是一个4维数组,形状为(
-
使用
pred_leaf且strict_shape设置为True时:- 输出是一个4维数组,形状为(
n_samples, n_iterations, n_classes, n_trees_in_forest)。n_trees_in_forest在训练过程中由num_parallel_tree指定。当strict_shape设置为False时,输出是一个2维数组,最后3维连接成1维。如果最后一维等于1,则会删除最后一维。
- 输出是一个4维数组,形状为(
对于 R 包,当指定 strict_shape 时,将返回一个数组,其值与 Python 相同, R 数组是列主序的,而 Python 的 numpy 数组是行主序的,因此所有维度都被颠倒。例如,对于在 strict_shape=True 的情况下通过 Python predict_leaf 获得的输出有4个维度:(n_samples, n_iterations, n_classes, n_trees_in_forest),而在 R 中 strict_shape=TRUE 的输出是 (n_trees_in_forest, n_classes, n_iterations, n_samples)。
除了这些预测类型之外,还有一个称为 iteration_range 的参数,类似于模型切片。但与实际将模型拆分为多个堆栈不同,它只是返回由范围内的树形成的预测。每次迭代创建的树的数量等于num_parallel_tree。因此,如果正在训练大小为4的增强随机森林,对于3类别分类数据集,并且想要使用前2次迭代的树进行预测,需要提供 iteration_range=(0, 2)。然后将在此预测中使用前
棵树。
提前停止Early Stopping
在使用提前停止进行训练时,原生 Python 接口和 sklearn/R 接口之间存在一种不一致的行为。默认情况下,在 R 和 sklearn 接口上,会自动使用 best_iteration,因此预测将来自最佳模型。但是在原生 Python 接口中,xgboost.Booster.predict() 和 xgboost.Booster.inplace_predict() 默认使用完整模型。用户可以使用 iteration_range 参数和 best_iteration 属性来实现相同的行为。此外,xgboost.callback.EarlyStopping 的 save_best 参数可能会很有用。
基准分数Base Margin
XGBoost 中有一个名为 base_score 的训练参数,以及一个 DMatrix 的元数据称为 base_margin。它们指定了增强模型的全局偏差。如果提供了后者,则会忽略前者。base_margin 可用于基于其他模型训练 XGBoost 模型。
阶段性预测
使用 DMatrix 的原生接口,可以对预测进行阶段性(或缓存)。例如,可以首先对前4棵树进行预测,然后在8棵树上运行预测。在运行第一个预测后,前4棵树的结果被缓存,因此当您在8棵树上运行预测时,XGBoost 可以重复使用先前预测的结果。缓存会在下一次预测、训练或评估时自动过期,如果缓存的 DMatrix 对象已过期(例如,超出作用域并被语言环境中的垃圾回收器收集)。
阶段性预测
使用原生接口和 DMatrix,可以对预测进行阶段性(或缓存)。例如,可以首先对前4棵树进行预测,然后在8棵树上运行预测。在运行第一个预测后,前4棵树的结果被缓存,因此当在8棵树上运行预测时,XGBoost 可以重复使用先前预测的结果。如果缓存的 DMatrix 对象已过期(例如,超出作用域并被语言环境中的垃圾回收器收集),则缓存会在下一次预测、训练或评估时自动过期。
In-place预测
传统上,XGBoost 只接受 DMatrix 进行预测,使用诸如 scikit-learn 接口之类的包装器时,构建过程会在内部发生。添加了对就地预测的支持,以绕过 DMatrix 的构建,这种构建方式速度较慢且占用内存。新的预测函数具有有限的功能,但通常对于简单的推断任务已经足够。它接受 Python 中一些常见的数据类型,如 numpy.ndarray、scipy.sparse.csr_matrix 和 cudf.DataFrame,而不是 xgboost.DMatrix。可以调用 xgboost.Booster.inplace_predict() 来使用它。请注意,就地预测的输出取决于输入数据类型,当输入在 GPU 数据上时,输出为 cupy.ndarray,否则返回 numpy.ndarray。
线程安全
在 1.4 版本之后,所有的预测函数,包括具有各种参数的正常预测(如 shap 值计算和 inplace_predict),在底层 booster 为 gbtree 或 dart 时是线程安全的,这意味着只要使用树模型,预测本身就应该是线程安全的。但是安全性仅在预测方面得到保证。如果尝试在一个线程中训练模型,并在另一个线程中使用相同的模型进行预测,则行为是未定义的。这比人们可能期望的更容易发生,例如可能会在预测函数内部意外地调用 clf.set_params():
def predict_fn(clf: xgb.XGBClassifier, X):X = preprocess(X)clf.set_params(n_jobs=1) # NOT safe!return clf.predict_proba(X, iteration_range=(0, 10))with ThreadPoolExecutor(max_workers=10) as e:e.submit(predict_fn, ...)
隐私保护预测
Concrete ML 是由 Zama 开发的第三方开源库,提供了类似于梯度提升类,但直接在加密数据上进行预测的功能,这得益于全同态加密。一个简单的例子如下:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from concrete.ml.sklearn import XGBClassifierx, y = make_classification(n_samples=100, class_sep=2, n_features=30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=10, random_state=42
)# Train in the clear and quantize the weights
model = XGBClassifier()
model.fit(X_train, y_train)# Simulate the predictions in the clear
y_pred_clear = model.predict(X_test)# Compile in FHE
model.compile(X_train)# Generate keys
model.fhe_circuit.keygen()# Run the inference on encrypted inputs!
y_pred_fhe = model.predict(X_test, fhe="execute")print("In clear:", y_pred_clear)
print("In FHE:", y_pred_fhe)
print(f"Similarity: {int((y_pred_fhe == y_pred_clear).mean()*100)}%")
参考
- https://xgboost.readthedocs.io/en/latest/prediction.html
相关文章:

XGB-20:XGBoost中不同参数的预测函数
有许多在XGBoost中具有不同参数的预测函数。 预测选项 xgboost.Booster.predict() 方法有许多不同的预测选项,从 pred_contribs 到 pred_leaf 不等。输出形状取决于预测的类型。对于多类分类问题,XGBoost为每个类构建一棵树,每个类的树称为…...
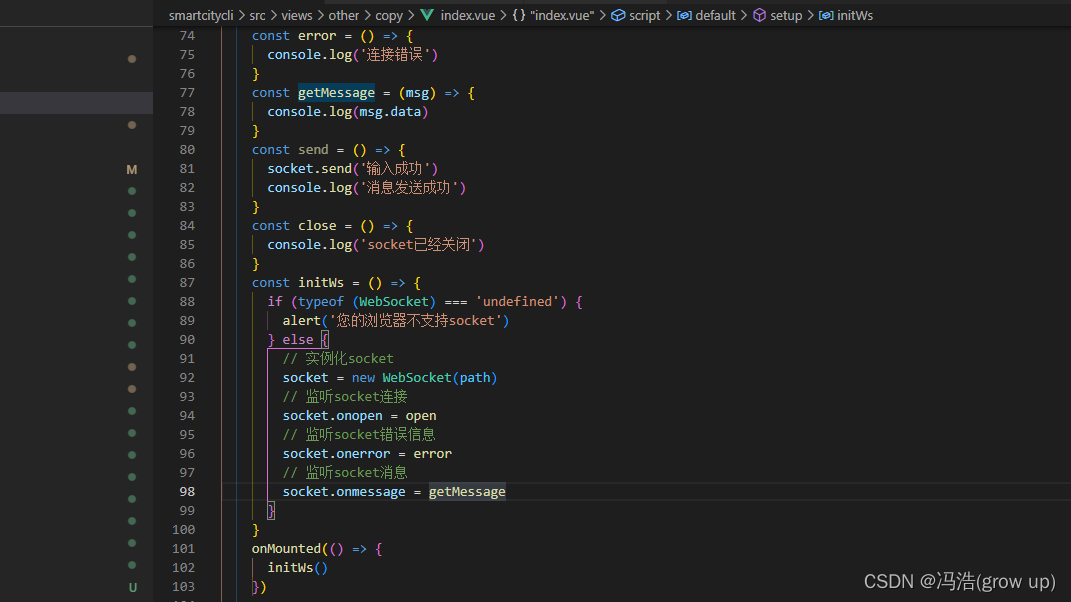
websocket 使用示例
websocket 使用示例 前言html中使用vue3中使用1、安装websocket依赖2、代码 vue2中使用1、安装websocket依赖2、代码 前言 即时通讯webSocket 的使用 html中使用 以下是一个简单的 HTML 页面示例,它连接到 WebSocket 服务器并包含一个文本框、一个发送按钮以及 …...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的水下目标检测系统(深度学习模型+UI界面+训练数据集)
摘要:本研究详述了一种采用深度学习技术的水下目标检测系统,该系统集成了最新的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等早期算法进行了性能评估对比。该系统能够在各种媒介——包括图像、视频文件、实时视频流及批量文件中——准确地识别水…...

中间件 Redis 服务集群的部署方案
前言 在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。 正是在这…...
)
生成哈夫曼树C卷(JavaPythonC++Node.jsC语言)
给定长度为n的无序的数字数组,每个数字代表二叉树的叶子节点的权值,数字数组的值均大于等于1。请完成一个函数,根据输入的数字数组,生成哈夫曼树,并将哈夫曼树按照中序遍历输出。 为了保证输出的二又树中序遍历结果统一,增加以下限制:二叉树节点中,左节点权值小于等于右…...
Java代码审计安全篇-SSRF(服务端请求伪造)漏洞
前言: 堕落了三个月,现在因为被找实习而困扰,着实自己能力不足,从今天开始 每天沉淀一点点 ,准备秋招 加油 注意: 本文章参考qax的网络安全java代码审计,记录自己的学习过程,还希望各…...
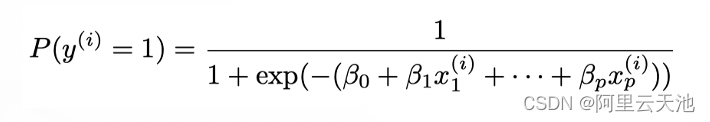
入门可解释机器学习和可解释性【内容分享和实战分析】
本篇文章为天池三月场读书会《可解释机器学习》的内容概述和项目实战分享,旨在为推广机器学习可解释性的应用提供一定帮助。 本次直播分享视频和实践代码以及PP获取地址:https://tianchi.aliyun.com/specials/promotion/activity/bookclub 目录 内容分…...
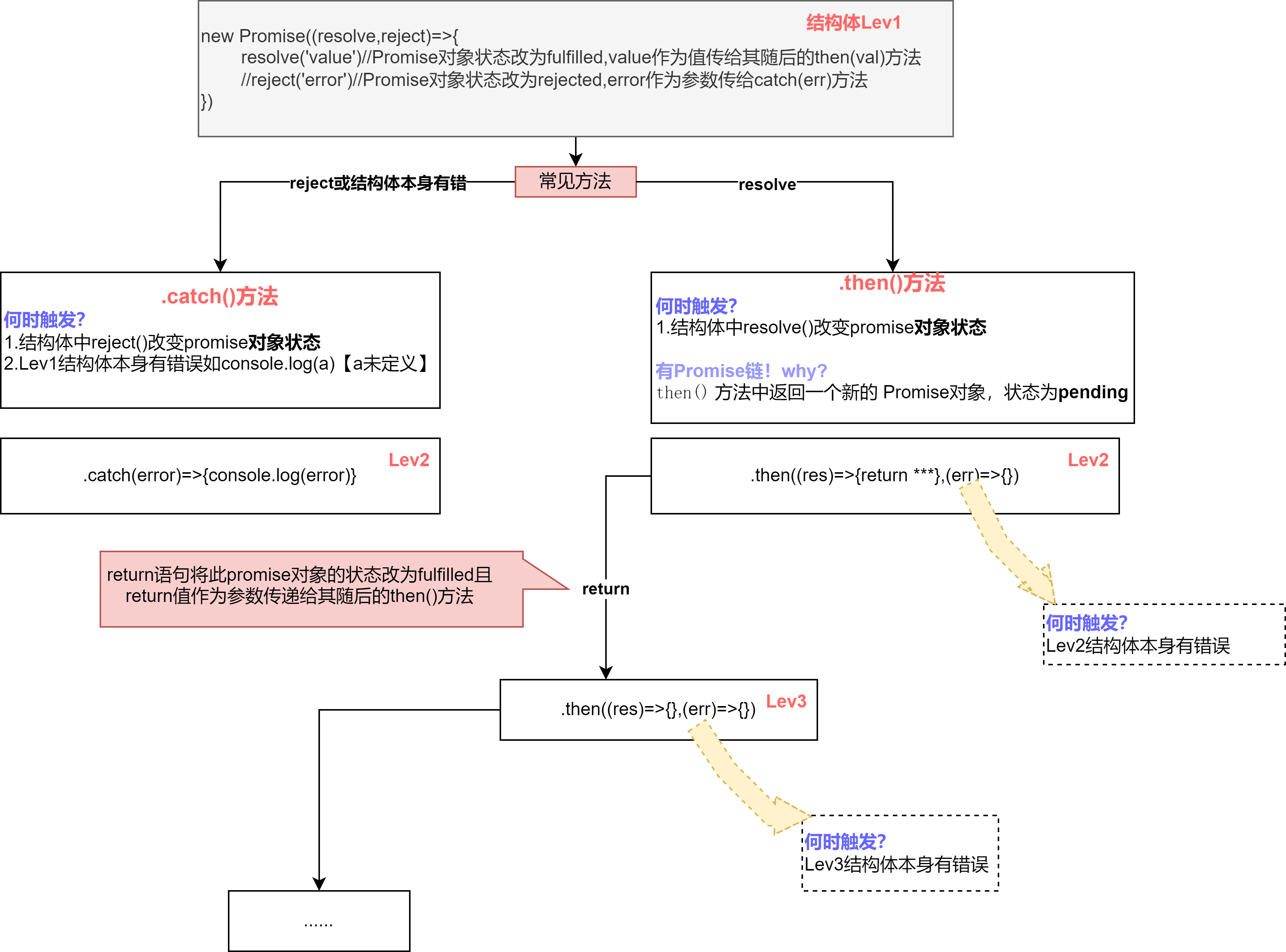
Promise其实也不难
难点图解:then()方法 ES6学习网站:ES6 入门教程 解决:回调地狱(回调函数中嵌套回调) 两个特点: (1)对象的状态不受外界影响。Promise对象代表一个异步操作&…...

吴恩达 x Open AI ChatGPT ——如何写出好的提示词视频核心笔记
核心知识点脑图如下: 1、第一讲:课程介绍 要点1: 上图展示了两种大型语言模型(LLMs)的对比:基础语言模型(Base LLM)和指令调整语言模型(Instruction Tuned LLM࿰…...
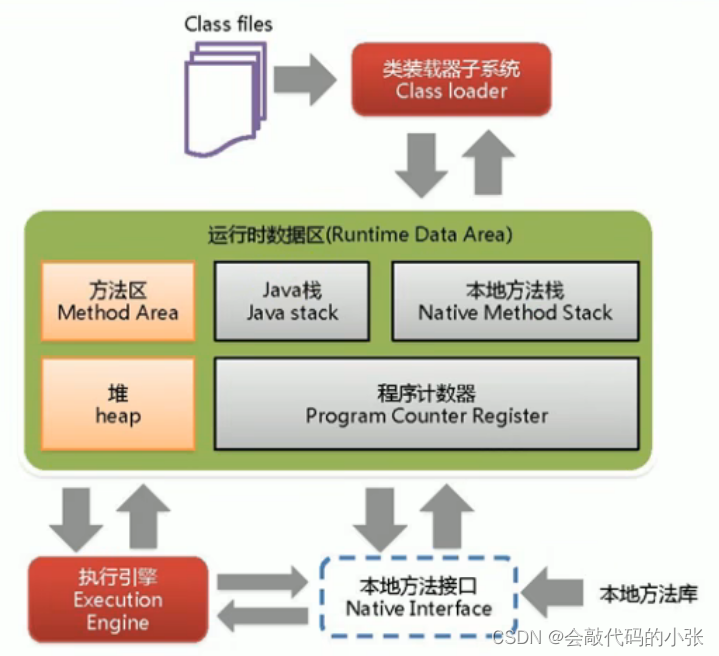
JVM从1%到99%【精选】-【初步认识】
目录 1.java虚拟机 2.JVM的位置 3.代码的执行流程 4.JVM的架构模型 5.JVM的生命周期 6.JVM的整体结构 1.java虚拟机 Java虚拟机是一台执行Java字节码的虚拟计算机,它拥有独立的运行机制,其运行的Java字节码也未必由Java语言编译而成。JVM平台的各种语言可以共享Java…...
)
pdf转图片(利用pdf2image包)
参考: pdf2image pip install pdf2image代码: from pdf2image import convert_from_path, convert_from_bytes import osoutput_folder ./xx/ dpi_value 600 pdf_start_page 1 # pdf显示的第一页 start_page 1 # 真实页码 prex # 图像前缀def to_…...

SwiftUI的转场动画
SwiftUI的转场动画 记录一下SwiftUI中的一些弹窗动画 import SwiftUIstruct TransitionBootCamp: View {State var showView falselet screenWidth UIScreen.main.bounds.widthlet screenHeight UIScreen.main.bounds.heightvar body: some View {ZStack(alignment: .botto…...

Trust Region Policy Optimization (TRPO)
Trust Region Policy Optimization (TRPO) 是一种强化学习算法,专门设计来改善策略梯度方法在稳定性和效率方面的表现。由 John Schulman 等人在 2015 年提出,TRPO 的核心思想是在策略优化过程中引入一个信任区域(trust region)&a…...
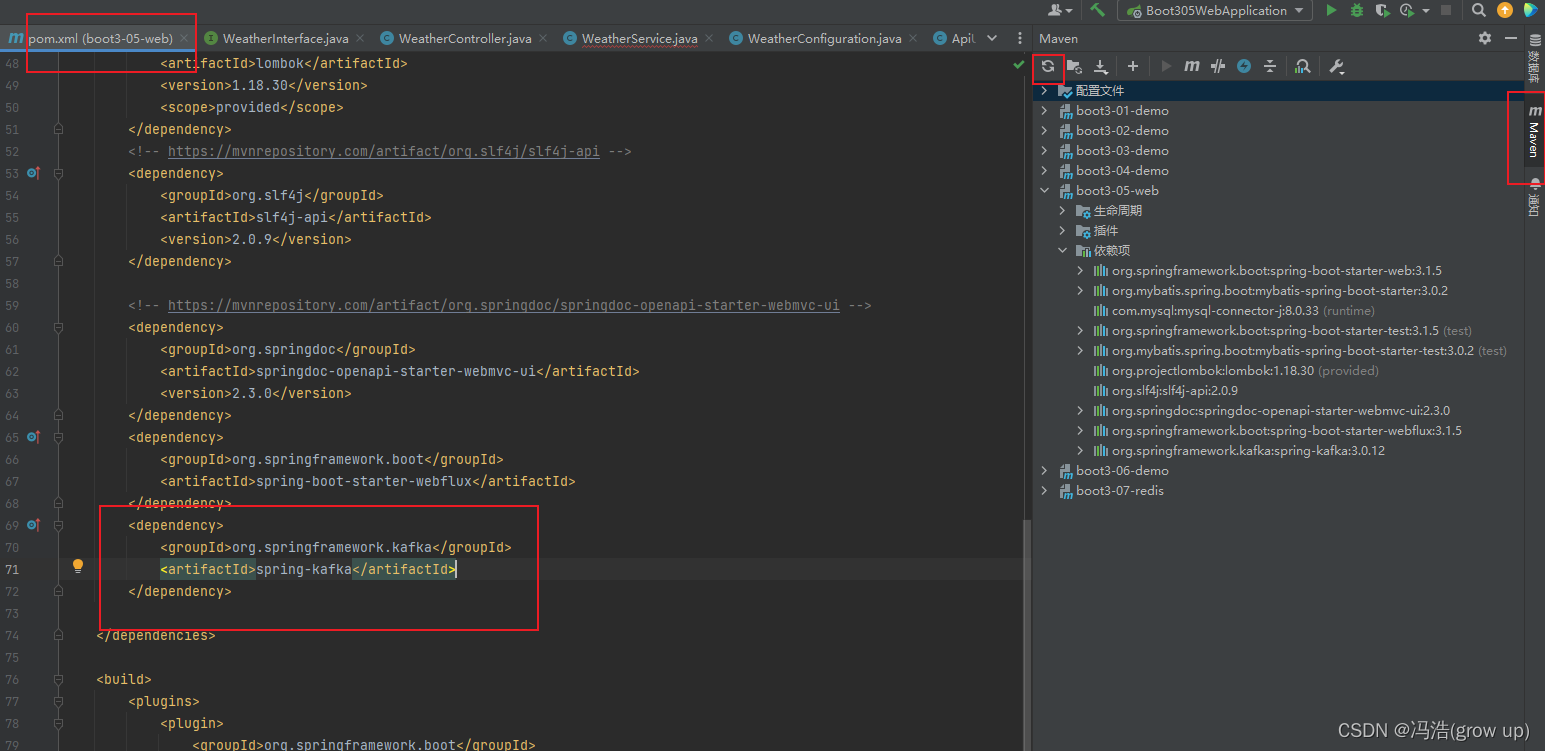
消息服务--Kafka的简介和使用
消息服务--Kafka的简介和使用 前言异步解耦削峰缓存1、消息队列2、kafka工作原理3、springBoot KafKa整合3.1 添加插件3.2 kafKa的自动配置类3.21 配置kafka地址3.22 如果需要发送对象配置kafka值的序列化器3.3 测试发送消息3.31 在发送测试消息的时候由于是开发环境中会遇到的…...

【c++11线程库的使用】
#include<iostream> #include<thread> #include<string> using namespace std; void hello(string msg) { for (int i 0; i < 1000; i) { cout << i; cout << endl; } } int main() { //1.创建线程 thread …...
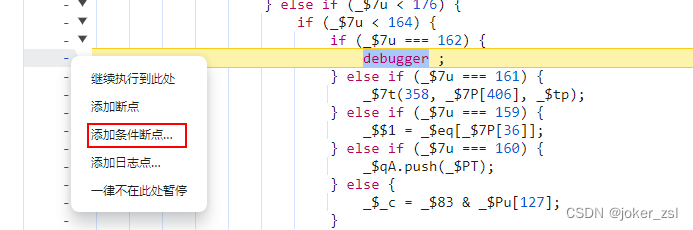
无限debugger的几种处理方式
不少网站会在代码中加入‘debugger’,使你F12时一直卡在debugger,这种措施会让新手朋友束手无策。 js中创建debugger的方式有很多,基础的形式有: ①直接创建debugger debugger; ②通过eval创建debugger(在虚拟机中…...

数据库基础理论知识
1.基本概念 数据(Data):数据库存储的基本对象。数字、字符串、图形、图像、音频、视频等数据库(DB):在计算机内,永久存储、有组织、可共享的数据集合数据库管理系统(DBMS):管理数据库的系统软件数据库系统(DBS):DBDBMSDBADBAP 数…...
)
华为OD机试真题-模拟目录管理-2024年OD统一考试(C卷)
题目描述: 实现一个模拟目录管理功能的软件,输入一个命令序列,输出最后一条命令运行结果。 支持命令: 1)创建目录命令:mkdir 目录名称,如mkdir abc为在当前目录创建abc目录,如果已存在同名目录则不执行任何操作。此命令无输出。 2)进入目录命令:cd 目录名称, 如cd …...

yield代码解释
目录 我们的post请求爬取百度翻译的代码 详细解释 解释一 解释二 再说一下callback 总结 发现了很多人对存在有yield的代码都不理解,那就来详细的解释一下 我们的post请求爬取百度翻译的代码 import scrapy import jsonclass TestpostSpider(scrapy.Spider):…...
C#四部曲(知识补充)
Unity跨平台原理 .Net相关 只要编写的时候遵循.NET的这些规则,就能在.NET平台下通用 各种源码→根据.NET规范编写→(虚拟机)生成CIL中间码(保存在程序集中)→转成操作系统原代码 跨语言← 跨平台↓ Unity跨平台原理(Mono) c#脚本→MonoC#编…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

2026年,本地精准营销高性价比服务商来袭,你还不了解一下?
在本地商业竞争日益激烈的2026年,实体店面临着诸多挑战,引流难、成本高、复购率低等问题困扰着众多商家。而中粤(广州)信息科技有限公司作为本地精准营销的高性价比服务商,正以其独特的优势和卓越的服务,为…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...