GPT-3后的下一步:大型语言模型的未来方向
摘要:
本文将概述GPT-3后的下一步:大型语言模型的未来方向,包括技术发展趋势、应用场景、挑战与机遇。
引言:
GPT-3是OpenAI于2020年发布的一款大型语言模型,它在自然语言处理领域取得了突破性进展。GPT-3的出现标志着人工智能技术在自然语言处理方面的巨大进步,同时也为未来的研究和发展提供了新的方向。
基础知识回顾:
GPT-3的核心技术原理包括Transformer架构、预训练目标、微调方法等。Transformer架构是一种基于自注意力机制的神经网络结构,它能够有效地处理长距离依赖问题。预训练目标是通过在大规模语料库上进行无监督学习,使模型能够理解自然语言的语义和语法。微调方法是在特定任务上进行有监督学习,使模型能够适应不同的应用场景。
核心组件:
- 模型架构:GPT-3采用了Transformer架构,并通过增加层数和参数量来提高模型的性能。未来可能的改进方向包括优化网络结构、引入新的注意力机制等。
-
- 预训练目标:GPT-3的预训练目标是生成式预训练,即通过预测下一个词来学习语言模型。未来可能的发展趋势包括引入更多的预训练任务,如翻译、问答等。
-
- 微调方法:GPT-3的微调方法是在特定任务上进行有监督学习,使模型能够适应不同的应用场景。未来可能的应用场景包括文本生成、对话系统、文本分类等。
实现步骤:
- 数据准备:GPT-3的数据集构建方法是通过从互联网上抓取大量的文本数据,并进行清洗和预处理。未来可能的数据获取途径包括利用社交媒体、在线论坛等来源的数据。
-
- 模型训练:GPT-3的训练策略是采用分布式训练,利用大规模的计算资源进行训练。未来可能的训练方法包括采用更高效的训练算法、利用迁移学习等技术。
-
- 模型部署:GPT-3的部署方式是通过云服务提供API接口,供用户进行调用。未来可能的应用场景包括智能客服、文本生成、语音识别等。
代码示例:
import torch
import torch.nn as nn
import torch.optim as optimclass GPT3(nn.Module):def __init__(self, num_layers, num_heads, hidden_size, vocab_size):super(GPT3, self).__init__()self.num_layers = num_layersself.num_heads = num_headsself.hidden_size = hidden_sizeself.vocab_size = vocab_sizeself.embedding = nn.Embedding(vocab_size, hidden_size)self.transformer_blocks = nn.ModuleList([TransformerBlock(hidden_size, num_heads) for _ in range(num_layers)])self.fc = nn.Linear(hidden_size, vocab_size)def forward(self, input_ids):x = self.embedding(input_ids)for block in self.transformer_blocks:x = block(x)x = self.fc(x)return x
model = GPT3(num_layers=12, num_heads=12, hidden_size=768, vocab_size=50000)
optimizer = optim.Adam(model.parameters(), lr=1e-5)
criterion = nn.CrossEntropyLoss()for epoch in range(100):for batch in dataloader:input_ids = batch['input_ids']labels = batch['labels']outputs = model(input_ids)loss = criterion(outputs.view(-1, outputs.size(-1)), labels.view(-1))optimizer.zero_grad()loss.backward()optimizer.step()
技巧与实践:
在实际应用中,GPT-3的模型调优和性能优化是非常重要的。可以通过调整学习率、批量大小、层数等超参数来优化模型性能。此外,可以利用迁移学习等技术来提高模型的泛化能力。
性能优化与测试:
- 模型压缩:GPT-3的模型压缩方法包括剪枝、量化等技术。未来可能的发展趋势是利用更高效的压缩算法,如知识蒸馏、参数共享等。
-
- 模型加速:GPT-3的模型加速技术包括使用专用硬件、分布式训练等。未来可能的应用场景包括实时对话系统、语音识别等。
-
- 模型评估:GPT-3的模型评估指标包括困惑度、准确率等。未来可能的发展趋势是引入更多的评估指标,如生成质量、多样性等。
常见问题与解答:
- 如何解决GPT-3在实际应用中可能遇到的问题?
-
- 可以通过调整超参数、使用迁移学习等技术来优化模型性能。
-
- 可以利用模型压缩和加速技术来提高模型的运行效率。
-
- 可以引入更多的评估指标来全面评估模型的性能。
结论与展望:
GPT-3的技术特点和应用前景表明,大型语言模型在未来有着广阔的发展空间。未来的发展方向可能包括优化模型架构、引入更多的预训练任务、提高模型的泛化能力等。同时,随着计算资源的不断增长,大型语言模型的应用场景也将不断拓展,为人工智能技术的发展带来更多的机遇和挑战。
附录:
- 论文:https://arxiv.org/abs/2005.14165
-
- 代码:https://github.com/openai/gpt-3
-
- 数据集:https://www.kaggle.com/openai/openai-webtext-corpus
相关文章:

GPT-3后的下一步:大型语言模型的未来方向
摘要: 本文将概述GPT-3后的下一步:大型语言模型的未来方向,包括技术发展趋势、应用场景、挑战与机遇。 引言: GPT-3是OpenAI于2020年发布的一款大型语言模型,它在自然语言处理领域取得了突破性进展。GPT-3的出现标志…...
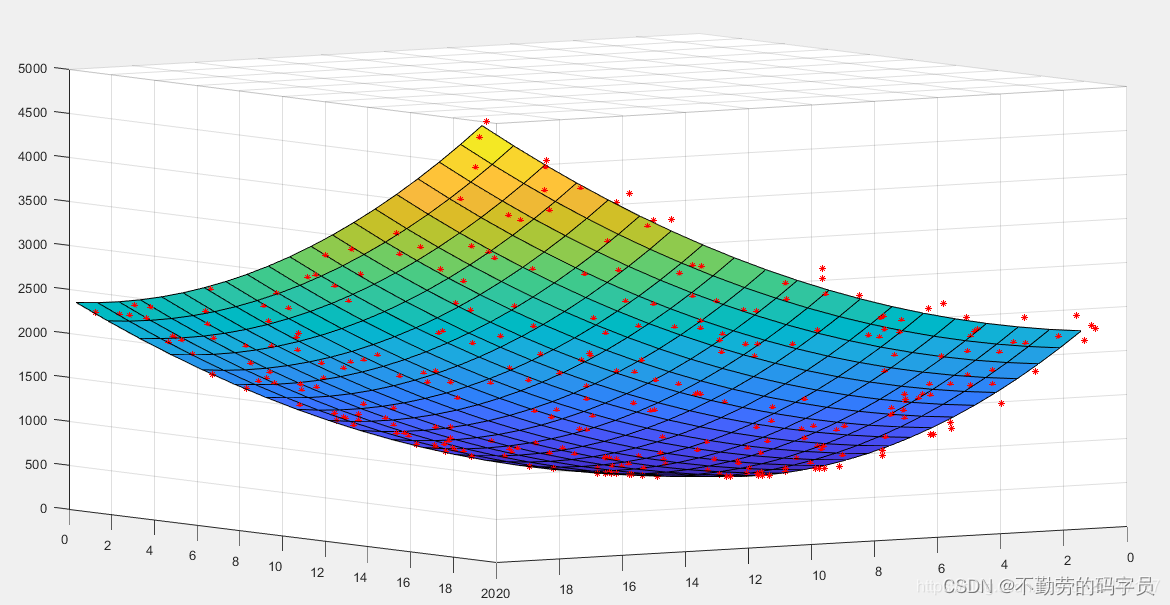
基于机器学习的曲面拟合方法
随着科技的不断发展,机器学习成为了最近最热门的技术之一,也被广泛应用于各个领域。其中,基于机器学习的曲面拟合方法也备受研究者们的关注。曲面拟合是三维模型处理中的重要技术,其目的是用一组数据点拟合出平滑的曲面࿰…...

【C++从练气到飞升】03---构造函数和析构函数
🎈个人主页:库库的里昂 ✨收录专栏:C从练气到飞升 🎉鸟欲高飞先振翅,人求上进先读书。 目录 ⛳️推荐 一、类的6个默认成员函数 二、构造函数 1. 构造函数的概念 2. 构造函数的定义 3. 构造函数的特性 三、析构函…...

mybatis转义字符
编写SQL中会用到<,>,<,> 等,但是在mybatis中不可以这么写,与xml文件的元素<>冲突,所以需要转义。整理转义字符如下: 符号原始字符转义字符大于>>大于等于>>小于<<小于等于<<和&&a…...
vue3 实现一个tab切换组件
一. 效果图 二. 代码 文件 WqTab.vue: <template><div ref"wqTabs" class"wq-tab"><template v-for"tab in tabs" :key"tab"><div class"tab-item" :class"{ ac: tabActive tab.key }" c…...

JSONObject在Android Main方法中无法实例化问题
目录 前言一、Main(非安卓环境)方法下运行二、安卓坏境下运行三、why? 前言 原生的json,即org.json.JSONObject; 在Android Studio中的Main方法里运行报错,但在安卓程序运行过程正常 一、Main(非安卓环境)方法下运行 static void test() {try {// 创建一个 JSON …...

京津冀协同发展:北京·光子1号金融算力中心——智能科技新高地
京津冀协同发展是党中央在新的历史条件下提出的一项重大国家战略,对于全面推进“五位一体”总体布局,以中国式现代化全面推进强国建设、民族复兴伟业,具有重大现实意义和深远历史意义。随着京津冀协同发展战略的深入推进,区域一体…...

aspnetcore使用jwt时一直提示401 authorization
测试aspnetcore使用Jwt做认证授权的时候,一直提示401 Authorization 最后发现问题所在,希望能有所帮助 1.检查注册了认证和授权中间件 缺一不可 /*认证*/app.UseAuthentication();/*授权*/app.UseAuthorization();2.检查swagger的配置项 builder.Servic…...
三款文案自动生成器,帮你轻松生成原创文案
文案在今天已经成为了许多企业和个人推广产品和服务的重要手段。然而,对于很多人来说,写作文案并非易事。有时候,我们可能会遇到文案灵感枯竭的情况,或者花费大量时间在寻找合适的词句上。但是,别担心!现在…...

多线程并发模拟实现与分析:基于Scapy的TCP SYN洪水攻击实验研究
简介 实现基于Python实现的多线程TCP SYN洪水攻击。该实例利用Scapy库构造并发送TCP SYN数据包,通过多线程技术模拟并发的网络攻击行为。 实现原理 SYN Flood攻击是一种经典的分布式拒绝服务(DDoS)攻击方式,利用了TCP协议握手过…...
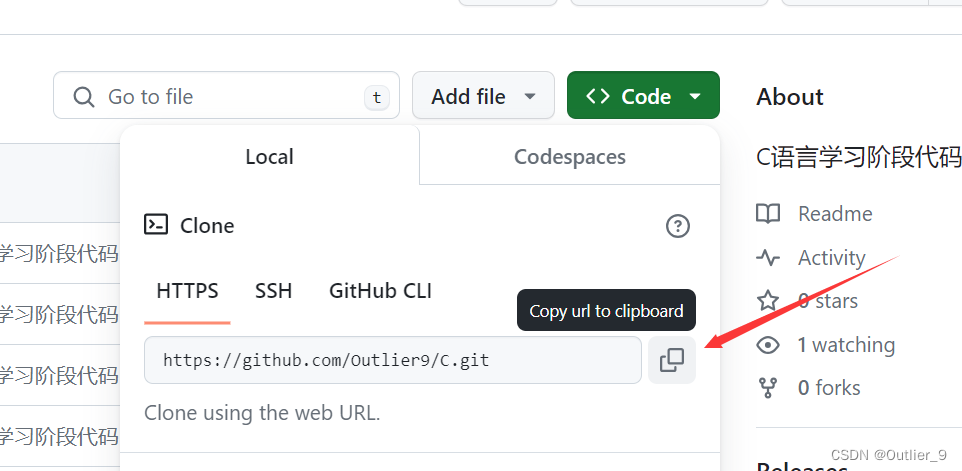
git命令行提交——github
1. 克隆仓库至本地 git clone 右键paste(github仓库地址) cd 仓库路径(进入到仓库内部准备提交文件等操作) 2. 查看main分支 git branch(列出本地仓库中的所有分支) 3. 创建新分支(可省…...
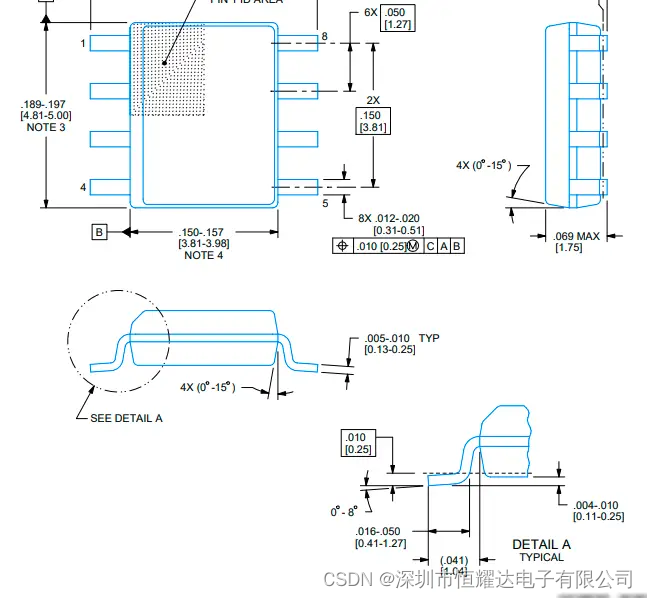
LM2903BIDR比较器芯片中文资料规格书PDF数据手册参数引脚图功能封装尺寸图
产品概述: M393B 和 LM2903B 器件是业界通用 LM393 和 LM2903 比较器系列的下一代版本。下一代 B 版本比较器具有更低的失调电压、更高的电源电压能力、更低的电源电流、更低的输入偏置电流和更低的传播延迟,并通过专用 ESD 钳位提高了 2kV ESD 性能和输…...

遍历list过程中调用remove方法
1、普通for循环遍历List删除指定元素,list.remove(index) List<String> nameList new ArrayList<>(Arrays.asList("张三", "李四", "王五", "赵六")); nameList.add("张七"); nameList.add("…...

Java解决罗马数字转整数
Java解决罗马数字转整数 01 题目 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 …...

无忧·企业文档v2.1.9新版本发布,全新升级,新变化让文档管理更无忧!
项目介绍 JVS是企业级数字化服务构建的基础脚手架,主要解决企业信息化项目交付难、实施效率低、开发成本高的问题,采用微服务配置化的方式,提供了 低代码数据分析物联网的核心能力产品,并构建了协同办公、企业常用的管理工具等&…...

【C语言_指针[2]_复习篇】
目录 一、数组名的理解 二、使用指针访问一维数组中的每个元素 三、一维数组传参的本质 四、冒泡排序 五、二级指针 六、指针数组 七、指针数组模拟二维数组 一、数组名的理解 1. 一般情况下,数组名就是数组首元素的地址。 2. 特殊情况1:sizeof(数…...

Rust 泛型使用过程中的 <T> 和 ::<T> 的区别
Rust 的泛型语法中,<T> 和 ::<T> 有不同的用途和上下文,但它们都与泛型有关。 <T> 在类型定义中 当你在定义函数、结构体、枚举或其他类型时,使用 <T> 来表示泛型参数。例如: fn identity<T>(x:…...

C语言 ——注释
1.1 单行注释 - 语法:// 待注释的内容 - 位置:可放在代码后,称之为行尾注释; 也可放代码上一行,称作行上注释。 c // 这是单行注释文字 1.2 多行注释 - 语法:/* 待注释的内容 */ - 注意:多⾏…...

C# 协程的使用
C# 中的协程是通过使用 yield 关键字来实现的,它们允许在方法的执行中暂停和继续。协程通常用于处理异步操作、迭代和状态机等情况。以下是关于C#协程的介绍、使用场景以及优缺点的概述: 介绍: 在 C# 中,协程是通过使用 yield 语…...

程序分享--C语言字母转换大小写的3种方法
关注我,持续分享逻辑思维&管理思维; 可提供大厂面试辅导、及定制化求职/在职/管理/架构辅导; 有意找工作的同学,请参考博主的原创:《面试官心得--面试前应该如何准备》,《面试官心得--面试时如何进行自…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包
完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包 【免费下载链接】BioAge Biological Age Calculations Using Several Biomarker Algorithms 项目地址: https://gitcode.com/gh_mirrors/bi/BioAge BioAge生物年龄计算工具包是一款基于R语言开发的强…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...

WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组
WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在GOG或Epic Games Store购买了游戏࿰…...

别再只会用--nogpgcheck了!手把手教你安全修复PostgreSQL yum源的GPG密钥问题
企业级PostgreSQL部署:安全解决GPG密钥验证的完整方案 当你在生产环境中部署PostgreSQL时,遇到GPG签名验证错误直接使用--nogpgcheck绕过检查,就像因为门锁打不开就直接把门拆掉一样危险。本文将带你深入理解GPG验证机制,并提供一…...