java实现计算ROUGE-L指标(一)
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 是用于评估自动文摘或机器翻译的一种评估方法,其中的ROUGE-L指标是基于最长公共子序列(Longest Common Subsequence,LCS)来计算的
我们做AI问答系统,需要一些量化指标来作为优化人工智能大模型的指导标准,经过调查Rouge-L的特征测量是量化指标的手段之一。
为了采用更精确的分词算法、词性还原和停用词处理,我借助一些自然语言处理的库,以下是我引入的maven依赖:
<dependency> <groupId>edu.stanford.nlp</groupId> <artifactId>stanford-corenlp</artifactId> <version>3.9.2</version>
</dependency>
<dependency> <groupId>edu.stanford.nlp</groupId> <artifactId>stanford-corenlp</artifactId> <version>3.9.2</version> <classifier>models</classifier>
</dependency>
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope>
</dependency>
然后是我的具体代码实现,因为词性标注和词性还原需要借助本地模型实现,为了快速落地量化指标,我暂时不使用词性标注和词性还原。
(Recall-Oriented Understudy for Gisting Evaluation) 是用于评估自动文摘或机器翻译的一种评估方法,其中的ROUGE-L指标是基于最长公共子序列(Longest Common Subsequence,LCS)来计算的。它主要关注词序列的匹配程度,不依赖于词性标注和词性还原。
因此,即使不使用词性标注和词性还原,只要确保分词正确,你仍然可以得到有效的ROUGE-L指标。
以下是我的代码具体实现:
package com.xxx.zjtest.testtest.test;import edu.stanford.nlp.ling.CoreAnnotations;
import edu.stanford.nlp.ling.CoreLabel;
import edu.stanford.nlp.pipeline.*;
import edu.stanford.nlp.util.CoreMap;import java.util.*;/**** 不使用词性标注和词性还原直接计算ROUGE-L指标本身不会产生问题。**/
public class RougeLCalculator {private static final Set<String> STOP_WORDS = new HashSet<>(Arrays.asList("的", "了", "和", "是", "就", "都", "而", "及", "与", "在")); // 中文停用词示例列表public static double calculateRougeL(String referenceText, String hypothesisText) {// 创建Stanford CoreNLP管道Properties props = new Properties();props.setProperty("annotators", "tokenize, ssplit"); //加, pos, lemma 会报错props.setProperty("ssplit.eolonly", "true");StanfordCoreNLP pipeline = new StanfordCoreNLP(props);// 处理参考答案和假设答案Annotation referenceAnnotation = new Annotation(referenceText);Annotation hypothesisAnnotation = new Annotation(hypothesisText);pipeline.annotate(referenceAnnotation);pipeline.annotate(hypothesisAnnotation);// 获取参考答案和假设答案的词性还原后的单词列表/*List<String> referenceWords = getLemmatizedWords(referenceAnnotation, STOP_WORDS);List<String> hypothesisWords = getLemmatizedWords(hypothesisAnnotation, STOP_WORDS);*/// 获取参考答案和假设答案的分词列表List<String> referenceWords = getTokenizedWords(referenceAnnotation, STOP_WORDS);List<String> hypothesisWords = getTokenizedWords(hypothesisAnnotation, STOP_WORDS);// 计算ROUGE-L指标return calculateLongestCommonSubsequence(referenceWords, hypothesisWords);}//词性标注和词性还原部分,此部分需要使用大模型,无法实现/*private static List<String> getLemmatizedWords(Annotation annotation, Set<String> stopWords) {List<String> words = new ArrayList<>();for (CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class)) {for (CoreLabel token : sentence.get(CoreAnnotations.TokensAnnotation.class)) {String word = token.word(); // 获取分词后的单词String pos = token.get(CoreAnnotations.PartOfSpeechAnnotation.class); // 获取词性标注String lemma = token.get(CoreAnnotations.LemmaAnnotation.class); // 获取词性还原后的单词if (!stopWords.contains(word) && !pos.equalsIgnoreCase("PUNCT")) { // 过滤停用词和标点符号words.add(lemma);}}}return words;}*/private static List<String> getTokenizedWords(Annotation annotation, Set<String> stopWords) {List<String> words = new ArrayList<>();for (CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class)) {for (CoreLabel token : sentence.get(CoreAnnotations.TokensAnnotation.class)) {String word = token.word(); // 获取分词后的单词if (!stopWords.contains(word)) { // 过滤停用词words.add(word);}}}return words;}//计算公共最长子序列private static double calculateLongestCommonSubsequence(List<String> referenceWords, List<String> hypothesisWords) {int[][] dp = new int[referenceWords.size() + 1][hypothesisWords.size() + 1];for (int i = 1; i <= referenceWords.size(); i++) {for (int j = 1; j <= hypothesisWords.size(); j++) {if (referenceWords.get(i - 1).equals(hypothesisWords.get(j - 1))) {dp[i][j] = dp[i - 1][j - 1] + 1;} else {dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);}}}int lcs = dp[referenceWords.size()][hypothesisWords.size()];double precision = (double) lcs / hypothesisWords.size();double recall = (double) lcs / referenceWords.size();double rougeL = 2 * precision * recall / (precision + recall);System.out.println(rougeL);return rougeL;}public static double calculateAverageRougeL(List<String> referenceTexts, List<String> hypothesisTexts) {if (referenceTexts.size() != hypothesisTexts.size()) {throw new IllegalArgumentException("参考文本列表和假设文本列表的长度必须相等");}double totalRougeL = 0;for (int i = 0; i < referenceTexts.size(); i++) {totalRougeL += calculateRougeL(referenceTexts.get(i), hypothesisTexts.get(i));}return totalRougeL / referenceTexts.size();}public static void main(String[] args) {String yTest1 = "客户专用网络的使用应注意以下几点:\n" +"\n" +"实施方案应由公司网络管理员组织制定,并与客户共同协商制定实施方案。\n" +"禁止将客户要求隔离的网络与未经客户许可的网络连通。\n" +"禁止将客户要求使用的网络与公司内部网络连通。\n" +"禁止在客户专用网络中搭建无线网络。\n" +"禁止在客户专用网络中使用笔记本电脑。\n" +"禁止在客户专用网络中未经过客户允许进行互联网访问。\n" +"禁止在客户专用网络中未按照客户要求执行设备要求。";String nTest1 = "根据已知信息,客户专用网络的注意事项有以下几点:\n" +"\n" +"禁止将客户要求隔离的网络与未经客户许可的网络连通。\n" +"禁止将客户要求使用的网络与公司内部网络连通。\n" +"禁止在客户专用网络中搭建无线网络。\n" +"禁止在客户专用网络中使用笔记本电脑。\n" +"禁止在客户专用网络中未经过客户允许进行互联网访问。\n" +"禁止在客户专用网络中未按照客户要求执行设备要求。\n" +"客户专用网络的申请与构建应由公司网络管理员组织制定,并与客户共同协商制定实施方案。\n" +"客户专用网络的规划与实施应由公司网络管理员与申请部门共同执行,如在实施过程中需要第三方参与,公司网络管理员应进行监督,并与申请部门共同验收。\n" +"若需使用客户的内部网络,必须事先获得客户批准,并严格遵守客户的网络安全规定,只能从事和业务相关的工作,不得私自查看其它计算机或客户内部网络上的任何保密信息,禁止任何令客户网络严重增加负载或容易引起网络故障的行为。\n" +"若需在客户现场访问Internet,必须事先获得客户批准,并按照客户的要求采取必要的安全措施。";String yTest2 = "禁止将公司资料、私人信息以及敏感内容存储在个人邮箱中,避免信息泄露。\n" +"及时删除接收的邮件,避免信息被他人获取。\n" +"禁止使用私人邮箱用于工作中的业务往来,避免信息泄露。\n" +"谨慎使用电子邮件,避免感染病毒,确保邮件发送保密信息。\n" +"禁止使用工作手机号码进行非工作目的的网站注册。\n" +"及时将工作手机的操作系统升级至最新版本。\n" +"工作手机信息安全管理要求,包括保密性、完整性、可用性等方面。";String nTest2="不要将公司资料、私人信息以及敏感内容存储在个人邮箱中,避免信息泄露。\n" +"及时删除接收的邮件,避免信息被他人获取。\n" +"禁止使用私人邮箱用于工作中的业务往来。\n" +"谨慎使用电子邮件,避免感染病毒,确保邮件发送保密信息。\n" +"禁止使用工作手机号码进行非工作目的的网站注册。\n" +"及时将工作手机的操作系统升级至最新版本。\n" +"遵守公司电子邮件尺寸规定,不得发送超大邮件。\n" +"收到不明电子邮件尽量不要回信,含有可疑附件时不得打开,并应立即删除该邮件。\n" +"发送电子邮件时,应认真核对收件人地址,避免误传送。\n" +"若发生电子邮件误传送时,应立即再发一封致歉信,声明发错,并请对方将已收到的邮件删除。\n" +"若邮件含有公司敏感信息,应立即向部门领导及业务安全部汇报。\n" +"当收到别人发错的电子邮件时,应立即通知提醒发件人,若该邮件含有改善敏感信息,应将邮件彻底删除。\n" +"禁止使用手机VPN进行加密。\n" +"禁止使用工作手机接收邮件。\n" +"禁止使用私人邮箱进行邮件收发。\n" +"禁止使用手机接收或发送邮件时点击或打开可疑链接或附件,避免被恶意攻击导致信息泄露。";//计算单个值//System.out.println(calculateRougeL(yTest1,nTest1));// 计算平均值List<String> referenceTexts = Arrays.asList(yTest1, yTest2);List<String> hypothesisTexts = Arrays.asList(nTest1, nTest2);double averageRougeL = calculateAverageRougeL(referenceTexts, hypothesisTexts);System.out.println("平均ROUGE-L值: " + averageRougeL);}
}
- tokenize: 这个注解器用于将文本分解成单词或标记(tokens)。例如,对于句子"Hello world!",tokenize会将其分解为两个标记:“Hello"和"world!”。
- ssplit: 这个注解器用于句子分割,即将文本分割成句子。它根据标点符号和其他线索来确定句子的边界。
- ssplit.eolonly: 这是一个特定的句子分割选项。当设置为true时,它只根据行尾(end-of-line)符号来分割句子,忽略其他标点符号。这通常用于那些每行只有一个句子的文本。
相关文章:
)
java实现计算ROUGE-L指标(一)
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 是用于评估自动文摘或机器翻译的一种评估方法,其中的ROUGE-L指标是基于最长公共子序列(Longest Common Subsequence,LCS)来计算的 我们做AI问答系统,需要一…...
LLM之RAG实战(二十九)| 探索RAG PDF解析
对于RAG来说,从文档中提取信息是一种不可避免的场景,确保从源文件中提取出有效的内容对于提高最终输出的质量至关重要。 文件解析过程在RAG中的位置如图1所示: 在实际工作中,非结构化数据比结构化数据丰富得多。如果这些海量数据无…...

C while 和 do while 区别
while 和 do while 都是 C 语言中的循环语句,它们的主要区别在于循环体执行的顺序。 while 循环首先检查循环条件,只有当条件为真时才执行循环体。因此,如果条件一开始就为假,那么循环体将永远不会执行。而如果条件一直为真&…...
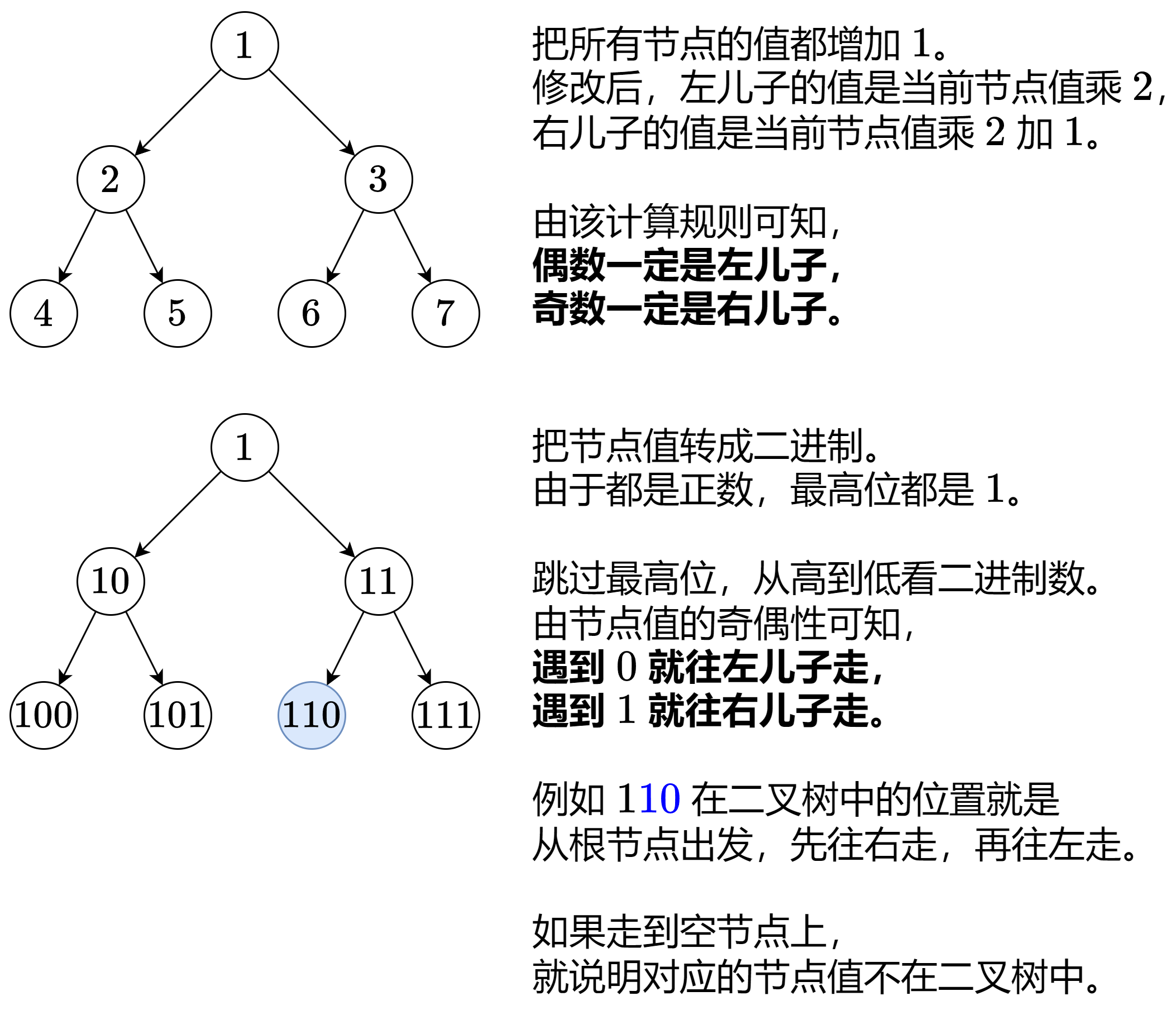
力扣每日一题 在受污染的二叉树中查找元素 哈希 DFS 二进制
Problem: 1261. 在受污染的二叉树中查找元素 思路 👨🏫 灵神题解 💖 二进制 时间复杂度:初始化为 O ( 1 ) O(1) O(1);find 为 O ( m i n ( h , l o g 2 t a r g e t ) O(min(h,log_2target) O(min(h,log2targ…...

安卓Java面试题 91- 100
91. 请描述一下Intent 和 IntentFilter ?Intent是组件的通讯使者,可以在组件间传递消息和数据。 IntentFilter是intent的筛选器,可以对intent的action,data,catgory,uri这些属性进行筛选,确定符合的目标组件🚀🚀🚀🚀🚀🚀92. 阐述什么是IntentService?有何优…...

BM1684X搭建sophon c++环境
1:首先安装编译好sophon-sail 比特大陆BM1684X开发环境搭建--SOC mode-CSDN博客 2:在将之前配置的soc-sdk拷贝一份到sdk根目录,将交叉编译好的sail中的build_soc拷贝至soc-sdk文件夹内; cp -rf build_soc/sophon-sail/inlcude soc-sdk cp -rf build_soc…...

UDP通讯测试
参考资料:UNIX网络编程 实验平台:PC为client,RaspberryPi为server 基本类型和接口函数,参考man手册 #include <sys/socket.h>struct sockaddr {sa_family_t sa_family; /* Address family */char sa_data[]; /* Socket address */};#inclu…...
Linux - 进程间通信
1、进程间通信介绍 1.1、进程间通信目的 数据传输:一个进程需要将它的数据发送给另一个进程;资源共享:多个进程之间共享同样的资源;通知事件:一个进程需要向另一个或一组进程发送消息,通知它(…...

代码随想录算法训练营第七天|454. 四数相加 II
454. 四数相加 II 已解答 中等 相关标签 相关企业 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < nnums1[i] nums2[j] nums3[k] nums4[l] 0 示例 …...
)
蓝桥杯刷题(五)
[蓝桥杯 2022 省 B] 刷题统计 题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 提示 题目描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a a…...

mysql语句中想要查询某一月每一天日期的平均值 ,SSM框架如何实现
mysql语句中想要查询某一月每一天日期的平均值 为了查询某一月份每一天的平均值,你可以使用以下SQL查询语句。这里假设你有一个表格data_table,它有一个日期时间列date_column和一个需要计算平均值的数值列value_column。 SELECTDATE_FORMAT(date_colum…...

前端框架的发展历程
文章目录 前言 一、静态页面时代 二、JavaScript的兴起 三、jQuery的出现 四、前端框架的崛起 1.AngularJS 2.React 3.Vue.js 五、面向组件化的发展趋势 总结 前言 前端框架的发展史就是一个不断进化的过程,它的发展和进化一定程度…...

【LeetCode 算法专题突破】---二分查找(⭐⭐⭐)
前言 我在算法题目的海洋中畅游已久,也曾在算法竞赛中荣获佳绩。然而,我发现自己对于算法的学习,还缺乏一个系统性的总结和归类。尽管我已经涉猎过不少算法类型,但心中仍旧觉得有所欠缺,未能形成完整的算法体系。 因…...

一个简单的HTML 个人网页
<!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"widthdevice-width, initial-scale1.0"> <title>个人网页</title> <style> body { f…...

【SpringCloud微服务实战05】Feign 远程调用
Feign是一个由Netflix开发的轻量级RESTful HTTP服务客户端,用于简化和优雅地调用HTTP API。它允许用户通过Java接口注解来发起请求,而不必像传统方式那样手动构建HTTP请求报文。Feign支持Spring Cloud解决方案,使得服务消费者能够像调用本地接口方法一样调用远程服务。使得开…...

LiveGBS流媒体服务器中海康摄像头GB28181公网语音对讲、语音喊话的配置
LiveGBS海康摄像头国标语音对讲大华摄像头国标语音对讲GB28181语音对讲需要的设备及服务准备 1、背景2、准备2.1、服务端必备条件(注意)2.2、准备语音对讲设备2.2.1、不支持跨网对讲示例2.2.2、 支持跨网对讲示例 3、开启音频开始对讲4、搭建GB28181视频…...

【前端】尚硅谷Webpack教程笔记
文章目录 1. 基本使用1.1 功能介绍1.2 开始使用 参考视频:尚硅谷Webpack5入门到原理 课件地址 【前端目录贴】 1. 基本使用 1.1 功能介绍 Webpack 是一个静态资源打包工具。 它会以一个或多个文件作为打包的入口,将我们整个项目所有文件编译组合成一个或多个文件输…...

Java泛型使用及局限
Java泛型的局限和使用经验 泛型的局限 任何基本类型不能作为类型参数 经过类型擦除后,List中包含的实际上还是Object的域,而在Java类型系统中Object和基本类型是两套体系,需要通过“自动装包、拆包机制”来进行交互。 2.任何在运行时需要…...

Sklearn线性回归
Scikit-learn 中的线性回归是一个用于监督学习的算法,它用于拟合数据集中的特征和目标变量之间的线性关系。以下是使用 Scikit-learn 实现线性回归的基本步骤: 1. 导入所需库 首先,你需要导入所需的库和模块。 import numpy as np import …...
APP中互联网公司的必备知识
APP中互联网公司的必备知识 敏捷开发(scrum)模型角色工作流程 项目上线发布策略发布流程灰度发布 APP发布APP软件包类型APP客户端(内部)发布平台APP客户端(线上)发布平台 熟悉APP项目(tpshop&am…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...