Flink StreamTask启动和执行源码分析
文章目录
- 前言
- StreamTask 部署启动
- Task 线程启动
- StreamTask 初始化
- StreamTask 执行
前言
Flink的StreamTask的启动和执行是一个复杂的过程,涉及多个关键步骤。以下是StreamTask启动和执行的主要流程:
- 初始化:StreamTask的初始化阶段涉及多个任务,包括Operator的配置、task特定的初始化以及初始化算子的State等。在这个阶段,Flink将业务处理函数抽象为operator,并通过operatorChain将业务代码串起来执行,以完成业务逻辑的处理。同时,还会调用具体task的init方法进行初始化。
- 读取数据和事件:StreamTask通过mailboxProcessor读取数据和事件。
- 运行业务逻辑:在StreamTask的beforeInvoke方法中,主要调用生成operatorChain并执行相关的业务逻辑。这些业务逻辑可能包括Source算子和map算子等,它们将被Chain在一起并在一个线程内同步执行。
- 资源清理:在执行完业务逻辑后,StreamTask会进行关闭和资源清理的操作,这部分在afterInvoke阶段完成。
值得注意的是,从资源角度来看,每个TaskManager内部有多个slot,每个slot内部运行着一个subtask,即每个slot内部运行着一个StreamTask。这意味着StreamTask是由TaskManager(TM)部署并执行的本地处理单元。
总的来说,Flink的StreamTask启动和执行是一个由多个阶段和组件协同工作的过程,涉及数据的读取、业务逻辑的执行以及资源的清理等多个方面。这些步骤确保了StreamTask能够高效、准确地处理数据流,并满足实时计算和分析的需求。
StreamTask 部署启动
当 TaskExecutor 接收提交 Task 执行的请求,则调用:
TaskExecutor.submitTask(TaskDeploymentDescriptor tdd,
JobMasterId jobMasterId,Time timeout){// 构造 Task 对象Task task = new Task(jobInformation, taskInformation, ExecutionAttemptId,AllocationId, SubtaskIndex, ....);// 启动 Task 的执行task.startTaskThread();
}
Task对象的构造方法
public Task(.....){
// 封装一个 Task信息对象 TaskInfo,(TaskInfo, JobInfo,JobMasterInfo)
this.taskInfo = new TaskInfo(....);
// 各种成员变量赋值
......
// 一个Task的执行有输入也有输出: 关于输出的抽象: ResultPartition 和
ResultSubPartition(PipelinedSubpartition)
// 初始化 ResultPartition 和 ResultSubPartition
final ResultPartitionWriter[] resultPartitionWriters =
shuffleEnvironment.createResultPartitionWriters(....);
this.consumableNotifyingPartitionWriters =
ConsumableNotifyingResultPartitionWriterDecorator.decorate(....);
// 一个Task的执行有输入也有输出: 关于输入的抽象: InputGate 和 InputChannel(从上有
一个Task节点拉取数据)
// InputChannel 可能有两种实现: Local Remote
// 初始化 InputGate 和 InputChannel
final IndexedInputGate[] gates = shuffleEnvironment.createInputGates(.....);
// 初始化一个用来执行 Task 的线程,目标对象,就是 Task 自己
executingThread = new Thread(TASK_THREADS_GROUP, this, taskNameWithSubtask);
}
Task 线程启动
Task 的启动,是通过启动 Task 对象的内部 executingThread 来执行 Task 的,具体逻辑在 run 方法中:
private void doRun() {
// 1、先更改 Task 的状态: CREATED ==> DEPLOYING
transitionState(ExecutionState.CREATED, ExecutionState.DEPLOYING);
// 2、准备 ExecutionConfig
final ExecutionConfig executionConfig =
serializedExecutionConfig.deserializeValue(userCodeClassLoader);
// 3、初始化输入和输出组件, 拉起 ResultPartition 和 InputGate
setupPartitionsAndGates(consumableNotifyingPartitionWriters,
inputGates);
// 4、注册 输出
for(ResultPartitionWriter partitionWriter :
consumableNotifyingPartitionWriters) {
taskEventDispatcher.registerPartition(partitionWriter.getPartitionId());
} /
/ 5、初始 环境对象 RuntimeEnvironment, 包装在 Task 执行过程中需要的各种组件
Environment env = new RuntimeEnvironment(jobId, vertexId, executionId,
....);
// 6、初始化 调用对象
// 两种最常见的类型: SourceStreamTask、OneInputStreamTask、
TwoInputStreamTask
// 父类: StreamTask
// 通过反射实例化 StreamTask 实例(可能的两种情况: SourceStreamTask,
OneInputStreamTask)
AbstractInvokable invokable =
loadAndInstantiateInvokable(userCodeClassLoader, nameOfInvokableClass, env);
// 7、先更改 Task 的状态: DEPLOYING ==> RUNNING
transitionState(ExecutionState.DEPLOYING, ExecutionState.RUNNING);
// 8、真正把 Task 启动起来了
invokable.invoke();
// 9、StreamTask 需要正常结束,处理 buffer 中的数据
for(ResultPartitionWriter partitionWriter :
consumableNotifyingPartitionWriters) {
if(partitionWriter != null) {
partitionWriter.finish();
}
} /
/ 10、先更改 Task 的状态: RUNNING ==> FINISHED
transitionState(ExecutionState.RUNNING, ExecutionState.FINISHED);
StreamTask 初始化
StreamTask 初始化指的就是 SourceStreamTask 和 OneInputStreamTask 的实例对象的构建!Task 这个类,只是一个笼统意义上的 Task,就是一个通用 Task 的抽象,不管是批处理的,还是流式处理的,不管是 源Task, 还是逻辑处理 Task, 都被抽象成 Task 来进行调度执行!
private SourceStreamTask(Environment env, Object lock) throws Exception {super(env,null,FatalExitExceptionHandler.INSTANCE,StreamTaskActionExecutor.synchronizedExecutor(lock));this.lock = Preconditions.checkNotNull(lock);this.sourceThread = new LegacySourceFunctionThread();getEnvironment().getMetricGroup().getIOMetricGroup().setEnableBusyTime(false);}@Overrideprotected void init() {// we check if the source is actually inducing the checkpoints, rather// than the triggerSourceFunction<?> source = mainOperator.getUserFunction();if (source instanceof ExternallyInducedSource) {externallyInducedCheckpoints = true;ExternallyInducedSource.CheckpointTrigger triggerHook =new ExternallyInducedSource.CheckpointTrigger() {@Overridepublic void triggerCheckpoint(long checkpointId) throws FlinkException {// TODO - we need to see how to derive those. We should probably not// encode this in the// TODO - source's trigger message, but do a handshake in this task// between the trigger// TODO - message from the master, and the source's trigger// notificationfinal CheckpointOptions checkpointOptions =CheckpointOptions.forConfig(CheckpointType.CHECKPOINT,CheckpointStorageLocationReference.getDefault(),configuration.isExactlyOnceCheckpointMode(),configuration.isUnalignedCheckpointsEnabled(),configuration.getAlignedCheckpointTimeout().toMillis());final long timestamp = System.currentTimeMillis();final CheckpointMetaData checkpointMetaData =new CheckpointMetaData(checkpointId, timestamp, timestamp);try {SourceStreamTask.super.triggerCheckpointAsync(checkpointMetaData, checkpointOptions).get();} catch (RuntimeException e) {throw e;} catch (Exception e) {throw new FlinkException(e.getMessage(), e);}}};((ExternallyInducedSource<?, ?>) source).setCheckpointTrigger(triggerHook);}getEnvironment().getMetricGroup().getIOMetricGroup().gauge(MetricNames.CHECKPOINT_START_DELAY_TIME,this::getAsyncCheckpointStartDelayNanos);recordWriter.setMaxOverdraftBuffersPerGate(0);}
StreamTask 执行
核心步骤如下:
public final void invoke() throws Exception {
// Task 正式工作之前
beforeInvoke();
// Task 开始工作: 针对数据执行正儿八经的逻辑处理
runMailboxLoop();
// Task 要结束
afterInvoke();
// Task 最后执行清理
cleanUpInvoke();
}
总结一下要点:
- 在 beforeInvoke() 中,主要是初始化 OperatorChain,然后调用 init() 执行初始化,然后恢复状态,更改 Task 自己的状态为 isRunning = true
- 在 runMailboxLoop() 中,主要是不停的处理 mail,这里是 FLink-1.10 的一项改进,使用了mailbox 模型来处理任务
- 在 afterInvoke() 中,主要是完成 Task 要结束之前需要完成的一些细节,比如,把 Buffer 中还没flush 的数据 flush 出来
- 在 cleanUpInvoke() 中,主要做一些资源的释放,执行各种关闭动作:set false,interrupt,
shutdown,close,cleanup,dispose 等
相关文章:

Flink StreamTask启动和执行源码分析
文章目录 前言StreamTask 部署启动Task 线程启动StreamTask 初始化StreamTask 执行 前言 Flink的StreamTask的启动和执行是一个复杂的过程,涉及多个关键步骤。以下是StreamTask启动和执行的主要流程: 初始化:StreamTask的初始化阶段涉及多个…...

【MySQL 系列】MySQL 语句篇_DCL 语句
DCL( Data Control Language,数据控制语言)用于对数据访问权限进行控制,定义数据库、表、字段、用户的访问权限和安全级别。主要关键字包括 GRANT、 REVOKE 等。 文章目录 1、MySQL 中的 DCL 语句1.1、数据控制语言--DCL1.2、MySQ…...
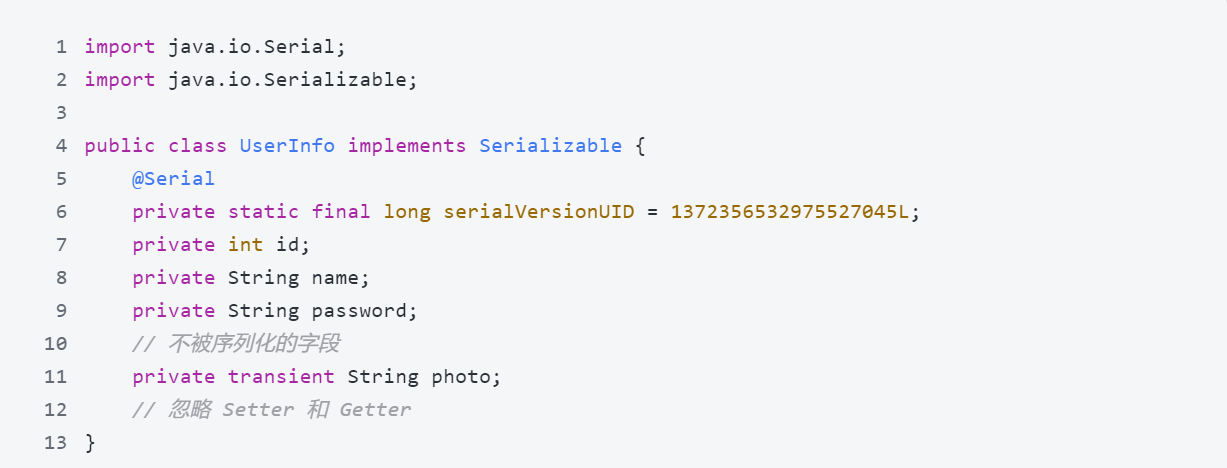
什么是序列化?为什么需要序列化?
1、典型回答 序列化(Serialization)序列化是将对象转换为可存储或传输的形式的过程(例如: 将对象转换为字节流) 反序列化(Deserialization) 是将序列化后的数据(例如: 二进制文件)转换回原始对象的过程。通过反序列化,可以从存储介质 (如磁盘、数据库) 或通过网络…...
Linux本地搭建FastDFS系统
文章目录 前言1. 本地搭建FastDFS文件系统1.1 环境安装1.2 安装libfastcommon1.3 安装FastDFS1.4 配置Tracker1.5 配置Storage1.6 测试上传下载1.7 与Nginx整合1.8 安装Nginx1.9 配置Nginx 2. 局域网测试访问FastDFS3. 安装cpolar内网穿透4. 配置公网访问地址5. 固定公网地址5.…...

docker和docker-compose安装
一、docker安装 1、移除旧版本 依次执行如下命令移除旧版本docker,如未安装过无需执行 yum -y remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-selinux docker-engine-selinux…...

深入理解Spring的ApplicationContext:案例详解与应用
深入理解Spring的ApplicationContext:案例详解与应用 在Spring框架的丰富生态中,ApplicationContext扮演着至关重要的角色。作为BeanFactory的扩展,ApplicationContext不仅继承了其所有功能,还引入了更多高级特性,使得…...
6.Java并发编程—深入剖析Java Executors:探索创建线程的5种神奇方式
Executors快速创建线程池的方法 Java通过Executors 工厂提供了5种创建线程池的方法,具体方法如下 方法名描述newSingleThreadExecutor()创建一个单线程的线程池,该线程池中只有一个工作线程。所有任务按照提交的顺序依次执行,保证任务的顺序性…...

英语阅读挑战
英语阅读真是令人头痛的东西。可怜的子航想利用寒假时间突破英语难题。当他拿到一篇英语阅读时,他很好奇作者最喜欢用那些字母。 输入 一句30词以内的英语句子 输出 统计每个字母出现的次数 样例输入 复制 However,the British dont have a history of exporting th…...

备战蓝桥之思维
平台重叠真的坑 给你一句样例,如果你觉得自己的代码没问题那就试试吧 2 1 1 3 1 0 4 正确答案 0 0 0 0 P1105 平台 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) import java.awt.Checkbox; import java.awt.PageAttributes.OriginType; import java.io.B…...

09 string的实现
注意 实现仿cplus官网的的string类,对部分主要功能实现 实现 头文件 #pragma once #include <iostream> #include <assert.h> #include <string>namespace mystring {class string{friend std::ostream& operator<<(std::ostream&a…...

Git 进行版本控制时,配置 user.name 和 user.email
在使用 Git 进行版本控制时,配置 user.name 和 user.email 是一个非常重要的初始步骤,但不是绝对必须的。这两个配置项定义了当你进行提交(commit)时用于标识提交者的信息。 为什么建议配置 user.name 和 user.email 标识提交者…...

传统开发读写优化与HBase
目录: 一、传统开发数据读写性能优化 1. Mysql 分表、主从复制与读写分离 2. Redis(缓存型数据库)主从复制与读写分离 二、HBase 一、传统开发数据读写性能优化 1、Mysql 分表、主从复制与读写分离 mysql分库分表方案 一种分表方案:设置表A 表B 表A 自增列从1开始…...

【OpenGL实现 03】纹理贴图原理和实现
目录 一、说明二、纹理贴图原理2.1 纹理融合原理2.2 UV坐标原理 三、生成纹理对象3.1 需要在VAO上绑定纹理坐标3.2 纹理传递3.3 纹理buffer生成 四、代码实现:五、着色器4.1 片段4.2 顶点 五、后记 一、说明 本篇叙述在画出图元的时候,如何贴图纹理图片…...

FDU 2021 | 二叉树关键节点的个数
文章目录 1. 题目描述2. 我的尝试 1. 题目描述 给定一颗二叉树,树的每个节点的值为一个正整数。如果从根节点到节点 N 的路径上不存在比节点 N 的值大的节点,那么节点 N 被认为是树上的关键节点。求树上所有的关键节点的个数。请写出程序,并…...
精读《React Conf 2019 - Day2》
1 引言 这是继 精读《React Conf 2019 - Day1》 之后的第二篇,补充了 React Conf 2019 第二天的内容。 2 概述 & 精读 第二天的内容更为精彩,笔者会重点介绍比较干货的部分。 Fast refresh Fast refresh 是更好的 react-hot-loader 替代方案&am…...

向ChatGPT高效提问模板
PS: ChatGPT无限次数,无需魔法,登录即可使用,网页打开下面 tj4.mnsfdx.net [点击跳转链接](http://tj4.mnsfdx.net/) 我想请你XXXX,请问我应该如何向你提问才能得到最满意的答案,请提供全面、详细的建议,针对每一个建…...

android metaRTC编译
参考文章: metaRTC3.0稳定版本编译指南_metartc 编译-CSDN博客 源码下载: Releases metartc/metaRTC GitHub 版本v6.0-b4即可...

HDFS面试重点
文章目录 1. HDFS的架构2. HDFS的读写流程3.HDFS中,文件为什么以block块的方式存储? 1. HDFS的架构 HDFS的架构可以分为以下几个主要组件: NameNode(名称节点): NameNode是HDFS的关键组件之一,…...

Java中的IO流是什么?
Java中的IO流(Input/Output Stream)是Java编程语言中用于处理输入和输出操作的一种重要机制。在Java中,IO流被用来读取和写入数据,这些数据可以来自各种来源,如文件、网络连接、内存缓冲区等。Java的IO流提供了丰富的类…...
Spring boot 集成netty实现websocket通信
一、netty介绍 Netty 是一个基于NIO的客户、服务器端的编程框架,使用Netty 可以确保你快速和简单的开发出一个网络应用,例如实现了某种协议的客户、服务端应用。Netty相当于简化和流线化了网络应用的编程开发过程,例如:基于TCP和U…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术
ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI ncmdumpGUI是一款专为Windows平台设计…...