PyTorch搭建LeNet训练集详细实现
一、下载训练集
导包
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
ToTensor()函数:
把图像[heigh x width x channels] 转换为 [channels x height x width]

Normalize() 数据标准化函数:
最后一行是标准化数值计算公式

transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 50000张训练图片
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)参数解释:
root='./data':数据集下载的路径,我下载到当前目录下的data文件夹,下载完成后会自动创建
train=True:当前为训练集
download=True:下载数据集时设置为True,下载完成后改为False
transform=transform :设置对图像进行预处理的函数
运行下载数据集结果为:

下载完成后生成了data文件夹

二、导入训练集
# 导入训练集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=36,shuffle=True, num_workers=0)参数解释:
trainset:把刚刚下载的数据导入进来
batch_size=36:一批数据的大小
shuffle=True:训练集中的数据是否打乱(一般默认打乱)
num_workers=0:载入数据的现成数,在lunix操作系统下,可以设置为别的参数,在windows操作系统系统下,默认为0.
三、下载测试集
# 10000张测试图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=10000,shuffle=False, num_workers=0)
test_data_iter = iter(testloader)
test_image, test_lable = test_data_iter.next()classes = ('plane', 'car', 'bird', 'cat', # 数据集中的分类,设置为元组,不可变类'deer', 'dog', 'frog', 'horse', 'ship', 'truck')参数解释:
test_data_iter = iter(testloader):通过iter()函数把testloader转化成可迭代的迭代器
test_image, test_lable = test_data_iter.next():通过next()方法可以获得测试的图像和图像对应的标签值。
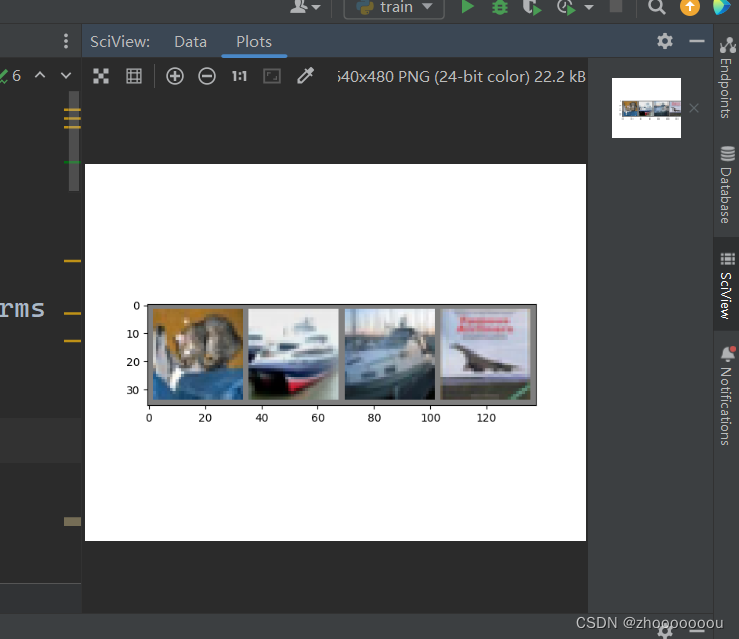
四、查看导入的图片
在中间过程打印图片进行查看,后续会注释掉
def imshow(img):img = img / 2 + 0.5nping = img.numpy()plt.imshow(np.transpose(nping, (1, 2, 0)))plt.show()# print labels
print(' '.join('%5s' % classes[test_lable[j]] for j in range(4)))
# show images
imshow(torchvision.utils.make_grid(test_image))运行结果

图片很模糊,因为像素很低。
上面识别出来的结果都对了。
我遇到的问题:
一开始有结果但是没有图片,我以为时matplotlib的问题,我重新安装并且更新了版本,但是我再运行后报错更多了,报错提示我 AttributeError: module 'numpy' has no attribute 'bool',我就知道是numpy的问题了,我重新安装并且更新了版本结果还是不行,我百度了一下,发现不是越新的版本越好,我重新下载了1.23.2这个版本的numpy,下载完成后运行就出来结果了。
pip install numpy==1.23.2这个也只是中间过程,后续会注释或者删了。
五、将创建的模型实例化
创建模型请看PyTorch搭建LeNet神经网络-CSDN博客
# 将创建的模型实例化
net = LeNet() # 实例化
loss_fuction = nn.CrossEntropyLoss() # 定义损失函数# 通过优化器将所有可训练的参数都进行训练,lr是learningrate学习率
optimizer = optim.Adam(net.parameters(), lr=0.001)#通过for循环实现训练过程,循环几次就是将训练集迭代多少次
for epoch in range(5):running_loss = 0.0 # 用来累加在学习过程中的损失for step, data in enumerate(trainloader, start=0):# get the inputs; data is a list of [inputs, labels]inputs, labels = data# zero the parameter gradientsoptimizer.zero_grad() # 历时损失梯度清零。# forward + backward + optimizeoutputs = net(inputs)loss = loss_fuction(outputs, labels) # 计算神经网络的预测值和真实标签之间的损失loss.backward()optimizer.step() # step()函数实现参数更新# print statistics 打印数据的过程running_loss += loss.item()if step % 500 == 499: # 每隔500步打印一次数据的信息with torch.no_grad(): # 上下文管理器outputs = net(test_image)predict_y = torch.max(outputs, dim=1)[1]accuracy = (predict_y == test_lable).sum().item() / test_lable.size(0)print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 500, accuracy))running_loss = 0.0print('Finished Training')# 将模型保存到文件夹中
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)详细解释:
比较重点的单独解释了,其他的在注释中。
optimizer.zero_grad() # 历时损失梯度清零。? 为什么每计算一个batch,就要调用一次 optimizer.zero_grad()函数
=> 通过清楚历史梯度,就会对计算的历史梯度进行累加。通过这个特性,能变相的实现一个很大的batch数值的训练(因为batch数值越大,训练效果越好)
with torch.no_grad(): # 上下文管理器上下文管理器: 在接下来的计算过程中,不再去计算每个节点的误差损失梯度。
如果不调用这个函数,将会在测试过程中占用更多的算力,消耗更多的资源和占用更多的内存资源,导致内存容易崩。
print函数中打印参数解释:
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 500, accuracy))epoch + 1:迭代到第几轮了
step + 1:某一轮的第几步
running_loss / 500:训练过程中500步平均训练误差
accuracy:准确率
运行结果

相关文章:
PyTorch搭建LeNet训练集详细实现
一、下载训练集 导包 import torch import torchvision import torch.nn as nn from model import LeNet import torch.optim as optim import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as npToTensor()函数: 把图像…...

R语言复现:中国Charls数据库一篇现况调查论文的缺失数据填补方法
编者 在临床研究中,数据缺失是不可避免的,甚至没有缺失,数据的真实性都会受到质疑。 那我们该如何应对缺失的数据?放着不管?还是重新开始?不妨试着对缺失值进行填补,简单又高效。毕竟对于统计师来说&#…...
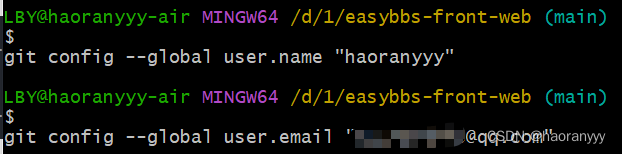
解决Git:Author identity unknown Please tell me who you are.
报错信息: 意思: 作者身份未知 ***请告诉我你是谁。 解决办法: git config --global user.name "你的名字"git config --global user.email "你的邮箱"...

Flink StreamTask启动和执行源码分析
文章目录 前言StreamTask 部署启动Task 线程启动StreamTask 初始化StreamTask 执行 前言 Flink的StreamTask的启动和执行是一个复杂的过程,涉及多个关键步骤。以下是StreamTask启动和执行的主要流程: 初始化:StreamTask的初始化阶段涉及多个…...

【MySQL 系列】MySQL 语句篇_DCL 语句
DCL( Data Control Language,数据控制语言)用于对数据访问权限进行控制,定义数据库、表、字段、用户的访问权限和安全级别。主要关键字包括 GRANT、 REVOKE 等。 文章目录 1、MySQL 中的 DCL 语句1.1、数据控制语言--DCL1.2、MySQ…...
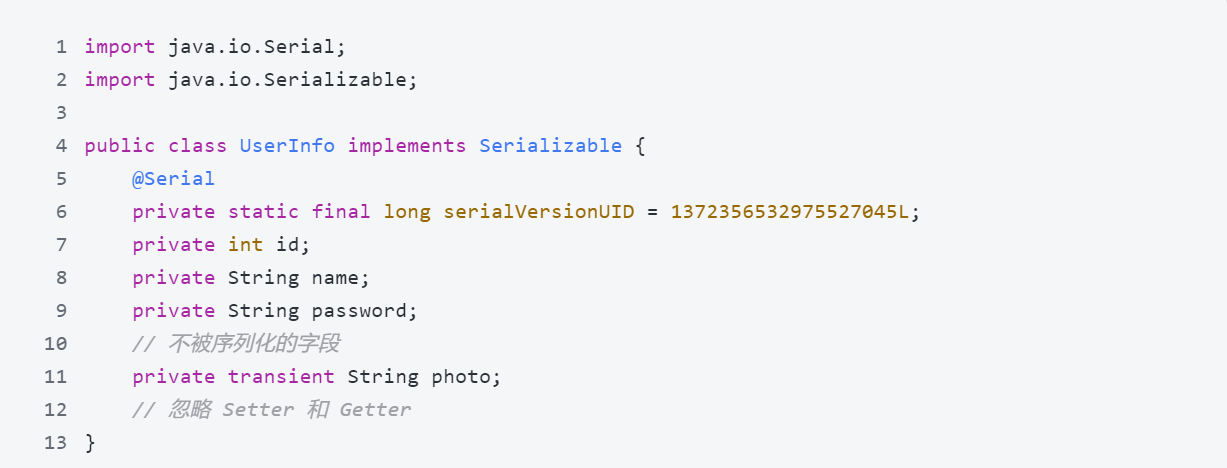
什么是序列化?为什么需要序列化?
1、典型回答 序列化(Serialization)序列化是将对象转换为可存储或传输的形式的过程(例如: 将对象转换为字节流) 反序列化(Deserialization) 是将序列化后的数据(例如: 二进制文件)转换回原始对象的过程。通过反序列化,可以从存储介质 (如磁盘、数据库) 或通过网络…...
Linux本地搭建FastDFS系统
文章目录 前言1. 本地搭建FastDFS文件系统1.1 环境安装1.2 安装libfastcommon1.3 安装FastDFS1.4 配置Tracker1.5 配置Storage1.6 测试上传下载1.7 与Nginx整合1.8 安装Nginx1.9 配置Nginx 2. 局域网测试访问FastDFS3. 安装cpolar内网穿透4. 配置公网访问地址5. 固定公网地址5.…...

docker和docker-compose安装
一、docker安装 1、移除旧版本 依次执行如下命令移除旧版本docker,如未安装过无需执行 yum -y remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-selinux docker-engine-selinux…...

深入理解Spring的ApplicationContext:案例详解与应用
深入理解Spring的ApplicationContext:案例详解与应用 在Spring框架的丰富生态中,ApplicationContext扮演着至关重要的角色。作为BeanFactory的扩展,ApplicationContext不仅继承了其所有功能,还引入了更多高级特性,使得…...
6.Java并发编程—深入剖析Java Executors:探索创建线程的5种神奇方式
Executors快速创建线程池的方法 Java通过Executors 工厂提供了5种创建线程池的方法,具体方法如下 方法名描述newSingleThreadExecutor()创建一个单线程的线程池,该线程池中只有一个工作线程。所有任务按照提交的顺序依次执行,保证任务的顺序性…...

英语阅读挑战
英语阅读真是令人头痛的东西。可怜的子航想利用寒假时间突破英语难题。当他拿到一篇英语阅读时,他很好奇作者最喜欢用那些字母。 输入 一句30词以内的英语句子 输出 统计每个字母出现的次数 样例输入 复制 However,the British dont have a history of exporting th…...

备战蓝桥之思维
平台重叠真的坑 给你一句样例,如果你觉得自己的代码没问题那就试试吧 2 1 1 3 1 0 4 正确答案 0 0 0 0 P1105 平台 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) import java.awt.Checkbox; import java.awt.PageAttributes.OriginType; import java.io.B…...

09 string的实现
注意 实现仿cplus官网的的string类,对部分主要功能实现 实现 头文件 #pragma once #include <iostream> #include <assert.h> #include <string>namespace mystring {class string{friend std::ostream& operator<<(std::ostream&a…...

Git 进行版本控制时,配置 user.name 和 user.email
在使用 Git 进行版本控制时,配置 user.name 和 user.email 是一个非常重要的初始步骤,但不是绝对必须的。这两个配置项定义了当你进行提交(commit)时用于标识提交者的信息。 为什么建议配置 user.name 和 user.email 标识提交者…...

传统开发读写优化与HBase
目录: 一、传统开发数据读写性能优化 1. Mysql 分表、主从复制与读写分离 2. Redis(缓存型数据库)主从复制与读写分离 二、HBase 一、传统开发数据读写性能优化 1、Mysql 分表、主从复制与读写分离 mysql分库分表方案 一种分表方案:设置表A 表B 表A 自增列从1开始…...

【OpenGL实现 03】纹理贴图原理和实现
目录 一、说明二、纹理贴图原理2.1 纹理融合原理2.2 UV坐标原理 三、生成纹理对象3.1 需要在VAO上绑定纹理坐标3.2 纹理传递3.3 纹理buffer生成 四、代码实现:五、着色器4.1 片段4.2 顶点 五、后记 一、说明 本篇叙述在画出图元的时候,如何贴图纹理图片…...

FDU 2021 | 二叉树关键节点的个数
文章目录 1. 题目描述2. 我的尝试 1. 题目描述 给定一颗二叉树,树的每个节点的值为一个正整数。如果从根节点到节点 N 的路径上不存在比节点 N 的值大的节点,那么节点 N 被认为是树上的关键节点。求树上所有的关键节点的个数。请写出程序,并…...
精读《React Conf 2019 - Day2》
1 引言 这是继 精读《React Conf 2019 - Day1》 之后的第二篇,补充了 React Conf 2019 第二天的内容。 2 概述 & 精读 第二天的内容更为精彩,笔者会重点介绍比较干货的部分。 Fast refresh Fast refresh 是更好的 react-hot-loader 替代方案&am…...

向ChatGPT高效提问模板
PS: ChatGPT无限次数,无需魔法,登录即可使用,网页打开下面 tj4.mnsfdx.net [点击跳转链接](http://tj4.mnsfdx.net/) 我想请你XXXX,请问我应该如何向你提问才能得到最满意的答案,请提供全面、详细的建议,针对每一个建…...

android metaRTC编译
参考文章: metaRTC3.0稳定版本编译指南_metartc 编译-CSDN博客 源码下载: Releases metartc/metaRTC GitHub 版本v6.0-b4即可...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...