【深度学习】预训练语言模型-BERT
1.BERT简介
BERT是一种预训练语言模型(pre-trained language model, PLM),其全称是Bidirectional Encoder Representations from Transformers。下面从语言模型和预训练开始展开对预训练语言模型BERT的介绍。
1-1 语言模型
语言模型 :对于任意的词序列,它能够计算出这个序列是一句话的概率。比如词序列A:“知乎|的|文章|真|水|啊”,这个明显是一句话,一个好的语言模型也会给出很高的概率,再看词序列B:“知乎|的|睡觉|苹果|好快”,这明显不是一句话,如果语言模型训练的好,那么序列B的概率就很小很小。
下面给出较为正式的定义。假设我们要为中文创建一个语言模型,V 表示词典, V = { 猫,狗,机器,学习,语言,模型,…}, 。语言模型就是这样一个模型:给定词典 V,能够计算出任意单词序列(比如:单词序列[
、
、
...]、[
、
、
])是一句话的概率。probability =
从文本生成角度来看,我们也可以给出如下的语言模型定义:给定一个短语(一个词组或一句话),语言模型可以生成(预测)接下来的一个词。
1-2 预训练模型
从字面上看,预训练模型(pre-training model)是先通过一批语料进行模型训练,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。预训练模型的训练和使用分别对应两个阶段:预训练阶段(pre-training)和 微调(fune-tuning)阶段。
预训练阶段一般会在超大规模的语料上,采用无监督(unsupervised)或者弱监督(weak-supervised)的方式训练模型,期望模型能够获得语言相关的知识,比如句法,语法知识等等。经过超大规模语料的”洗礼”,预训练模型往往会是一个Super模型,一方面体现在它具备足够多的语言知识,一方面是因为它的参数规模很大。
微调阶段是利用预训练好的模型,去定制化地训练某些任务,使得预训练模型”更懂”这个任务。例如,利用预训练好的模型继续训练文本分类任务,将会获得比较好的一个分类结果,直观地想,预训练模型已经懂得了语言的知识,在这些知识基础上去学习文本分类任务将会事半功倍。利用预训练模型去微调的一些任务(例如前述文本分类)被称为下游任务(down-stream)。
1-3 BERT的原理
从BERT的全称,Bidirectional Encoder Representation from Transformer(来自Transformer的双向编码器表征),可以看出BERT是基于Transformer模型的,只是其中的编码器。输入一个句子,Transformer的编码器会输出句子中每个单词的向量表示。而双向则是由于Transformer编码器是双向的。它的输入是完整的句子,在指定某个Token时,BERT已经读入了它两个方向上的所有单词。举个例来理解BERT是如何从Transformer中得到双向编码表示的。
假设我们有一个句子A:He got bit by Python,现在我们把这个句子输入Transformer并得到了每个单词的上下文表示(嵌入表示)作为输出。Transformer的编码器通过多头注意力机制理解每个单词的上下文,然后输出每个单词的嵌入向量。如下图所示,我们输入一个句子到Transformer的编码器,它输出句子中每个单词的上下文表示。下图中代表单词He的向量表示,每个单词向量表示的大小应当于每个编码器隐藏层的大小。假设编码器层大小为768,那么单词的向量表示大小也就是768。

1-4 BERT的参数
BERT初期有两个版本,分为base版和large版本。base版一共有110M参数,large版有340M的参数,两个版本的BERT的参数量都是上亿的。
L:Transformer blocks 层数;H:hidden size ;A:the number of self-attention heads
2.BERT预训练任务
Bert是Transformer的encoder部分,使用大量的未标记文本数据进行预训练,从而学习并掌握某种语言的表达形式。结构上使用了基于多头注意力机制的transformer,训练中采取两种不同的训练方式:(Masked Language Model)隐蔽语言模型、(Next Sentence Prediction)下一结构预测。其中双向主要体现在bert的训练任务一中:隐蔽语言模型。
2-1 Masked Language Model
Masked LM 可以形象地称为完形填空问题,随机掩盖掉每一个句子中15%的词,用其上下文来去判断被盖住的词原本应该是什么。随机Mask语料中15%的Token,然后将masked token位置的最终隐层向量送入softmax,来预测masked token。 举例来说,有这样一个未标注句子 my dog is hairy ,我们可能随机选择了hairy进行遮掩,就变成 my dog is [mask] ,训练模型去预测 [mask] 位置的词,使预测出 hairy的可能性最大,在这个过程中就将上下文的语义信息学习并体现到模型参数中。
而在下游的NLP任务fine-tuning阶段中不存被Mask的词,为了和后续任务保持一致,作者按一定比例在需要预测的词的位置上输入了原词或输入了某个随机的词。[MASK]通过attention均结合了左右上下文的信息,这体现了双向。以下是MASK策略:
- 有80%的概率用“[mask]”标记来替换——my dog is [MASK]
- 有10%的概率用随机采样的一个单词来替换——my dog is apple
- 有10%的概率不做替换——my dog is hairy
在任何一个词都有可能是被替换掉的条件下,强迫模型在编码当前时刻不能太依赖于当前的词,而是要考虑它的上下文,甚至根据上下文进行纠错。所以训练预料中有必须正确的信息(10%)、未知的信息(80% MASK,使模型具有预测能力)、错误的信息(加入噪声10%,使模型具有纠错能力),模型才能获取全局全量的信息。
2-2 Next sentence prediction
很多下游任务(QA和natural language inference)都是基于两个句子之间关系的理解,基于此项任务,为了增强模型对句子之间关系的理解能力。 所以预测句子关系,判断两个句子之间是否是有关联,在训练过程中,BERT会抽全50%有关联的句子(这里的句子是指有联系的Token序列),百分之50的概率随机抽选两无关的句子,然后让BERT模型判断这两个句子是否相关。其输入形式是,开头是一个特殊符号[CLS],然后两个句子之间用[SEP]隔断:
Input = [CLS] the man went to [MASK] store [SEP]he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]penguin [MASK] are flight ##less birds[SEP]
Label = NotNext
3.BERT的输入和输出
3-1 BERT的输入
在把数据喂给BERT之前,通过下面三个嵌入层将输入转换为嵌入向量:词嵌入(Token embedding);段嵌入(Segment embedding);位置嵌入(Position embedding)。
以下面句子为例,展现三种嵌入向量的表示。
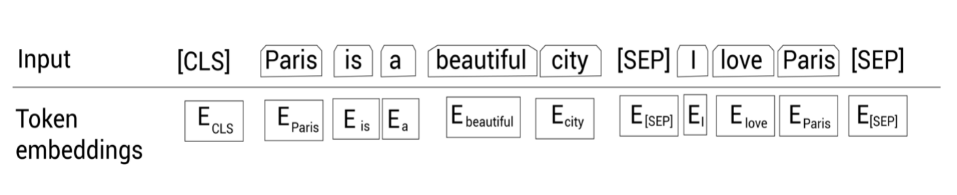
Sentence A: Paris is a beautiful city.
Sentence B: I love Paris.
1.Token Embedding(词嵌入)
表示的是词向量,既可以是原始词向量(源码中是token在词汇表中对应的索引),也可以是经过word2vector或者是glove等模型处理后的静态向量。在实际代码实现中,输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP])
第一步:使用使用WordPiece分词器分词。
#第一步:使用WordPiece分词器分词
tokens = [Paris, is, a, beautiful, city, I, love, Paris] 第二步:在一个句子前面,添加[CLS]标记。
tokens = [ [CLS], Paris, is, a, beautiful, city, I, love, Paris]
第三步:在每个句子的结尾,添加[SEP]标记。
tokens = [ [CLS], Paris, is, a, beautiful, city, [SEP], I, love, Paris, [SEP]]
特别说明:
[CLS]标记只加在第一个句子前面,而[SEP]标记加到每个句子末尾。
[CLS]标记用于分类任务,而[SEP]标记用于表示每个句子的结尾。
在把所有的标记喂给BERT之前,我们使用一个叫作标记嵌入的嵌入层转换这些标记为嵌入向量。这些嵌入向量的值会在训练过程中学习。经过学习,得到了每个token的词嵌入向量。
2.Segment Embedding (段嵌入)
段嵌入用来区别两种句子。因为Bert中存在着两个任务,一个是隐藏语言模型,另一个是预测句子关系,所以在输入时需要区分两个句子。 如果输入数据由两个句子拼接而成,如果词语是属于第一个句子A,那么该标记会映射到嵌入;反之属于句子 B,则映射到嵌入
。

如果输入仅仅只有一个句子,那么它的segment embedding只会映射到 。

3.Position Embedding(位置编码)
学习出来的embedding向量。与Transformer不同,Transformer中是预先设定好的值。

4.最终表示
如下图所示,首先我们将给定的输入序列分词为标记列表,然后喂给标记嵌入层,片段嵌入层和位置嵌入层,得到对应的嵌入表示。然后,累加所有的嵌入表示作为BERT的输入表示。

3-2 BERT的输出
bert模型的输出可以包括四个:
1. last_hidden_state
torch.FloatTensor类型的,最后一个隐藏层的序列的输出。大小是(batch_size, sequence_length, hidden_size) sequence_length是我们截取的句子的长度,hidden_size是768。
2.pooler_output
torch.FloatTensor类型的,[CLS]的这个token的输出,输出的大小是(batch_size, hidden_size)。
3.hidden_states
tuple(torch.FloatTensor)这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)。
4.attentions
这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
4.BERT代码
Transformers(以前称为pytorch-transformers和pytorch-pretrained-bert)提供用于自然语言理解(NLU)和自然语言生成(NLG)的最先进的模型(BERT,GPT-2,RoBERTa,XLM,DistilBert,XLNet,CTRL ...) ,拥有超过32种预训练模型,支持100多种语言,并且在TensorFlow 2.0和PyTorch之间具有深厚的互操作性。我们借助Transformers来实现bert的调用。
import transformers
#实例化bert模型
bert_model = transformers.BertModel.from_pretrained(pretrained_model_name_or_path = '/ssd/Spider/Baidu_NER/Pre_Model/chinese_roberta_wwm_large_ext/',output_hidden_states=True,output_attentions=True)
#bert需要的三种输入形式
def encoder(vocab_path,sentence):#将text_list embedding成bert模型可用的输入形式tokenizer = transformers.BertTokenizer.from_pretrained(vocab_path)tokenizer = tokenizer(sentence,return_tensors='pt' # 返回的类型为pytorch tensor)input_ids = tokenizer['input_ids']token_type_ids = tokenizer['token_type_ids']attention_mask = tokenizer['attention_mask']return input_ids,token_type_ids,attention_masksentence = "中华人民共和国万岁"
#生成三种bert需要的输入形式
input_ids,token_type_ids,attention_mask = encoder(vocab_path="/ssd/Spider/Baidu_NER/Pre_Model/chinese_roberta_wwm_large_ext/vocab.txt",sentence = sentence)
#调用bert模型
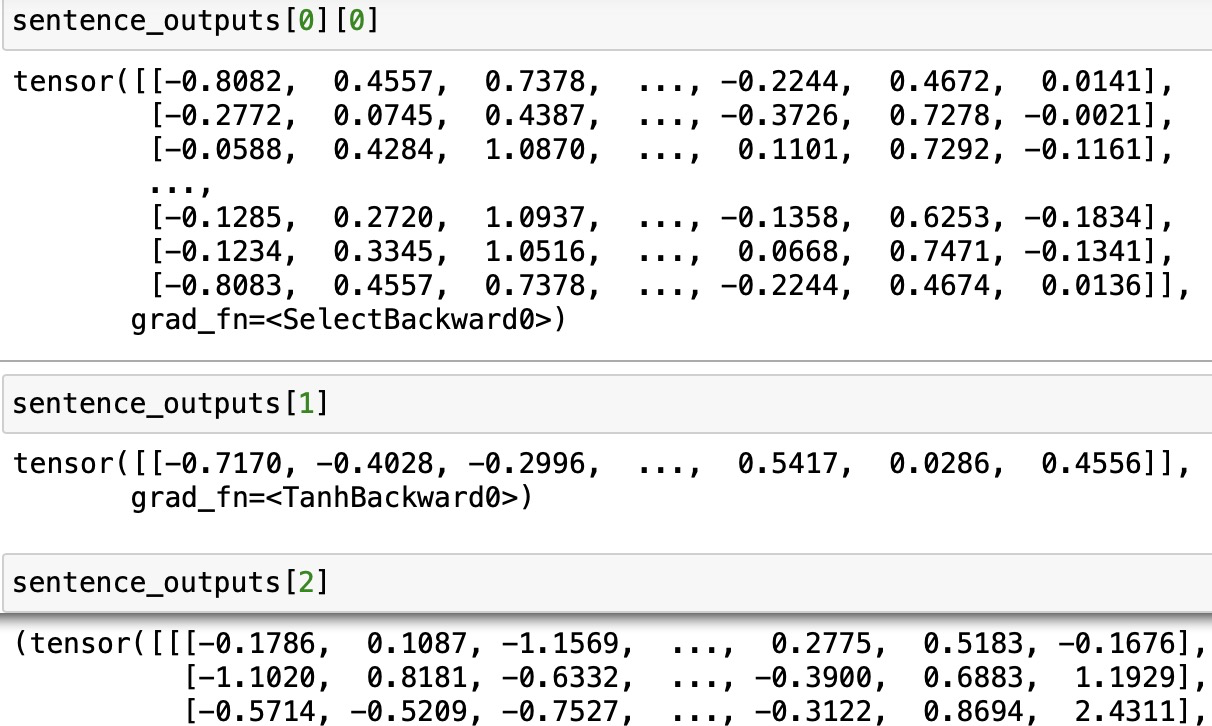
sentence_outputs = bert_model(input_ids,token_type_ids,attention_mask)如下图所示:
input_ids表示的是分词后在token中添加了[CLS]和[SEP]标记之后的id表示。token_types_ids则表示的是Segment Embeddings ,如果输入数据由两个句子拼接而成,如果词语是属于第一个句子,则Segment Embeddings 对应的位置是0,如果属于第二个句子,则segment Embeddings对应的位置为1。


相关文章:
【深度学习】预训练语言模型-BERT
1.BERT简介 BERT是一种预训练语言模型(pre-trained language model, PLM),其全称是Bidirectional Encoder Representations from Transformers。下面从语言模型和预训练开始展开对预训练语言模型BERT的介绍。 1-1 语言模型 语言模型 …...
C++类的组合
C类的组合什么是类的组合初始化参数列表使用类的组合案例分析组合构造和析构顺序问题this指针基本用法和作用什么是类的组合 类的组合就是以另一个对象为数据成员,这种情况称为类的组合 1.优先使用类的组合,而不是继承 2.组合表达式的含义 一部分关系 初…...
的配置与使用)
2.伪随机数生成器(ctr_drbg)的配置与使用
零、随机数应用 生成盐,用于基于口令的密码 生成密钥,用于加密和认证 生成一次性整数Nonce,防止重放攻击 生成初始化向量IV 构成 种子,真随机数生成器的种子来源于物理现象 内部状态,种子用来初始化内部状态 一、真随机数和伪随机数 1.区别 随机数在安全技术中通常被用于…...

CentOS7 切换图形模式和多用户命令行模式
备注: 主机名 hw 含义:hardware 缩写,意思是硬件(物理机) 文章目录1、查看源头2、查看当前系统运行模式3、设置系统运行模式为多用户命令行模式4、查看当前系统运行模式5、重启系统6、确认当前系统运行模式7、设置系统…...

在linux上用SDKMan对Java进行多版本管理
在linux上用SDKMan对Java进行多版本管理 有一个工具叫SDKMan,它允许我们这样做。官方网站这样描述: TIP: "SDKMan 是一个工具,用于在大多数基于Unix的系统上管理多个软件开发工具包的并行版本。它提供了一个方便的命令行接口(CLI)和API,…...
、Gson(JsonObject)区别)
JSONObject、fastJson(JsonObject)、Gson(JsonObject)区别
概述 Java中并没有内置的 JSON 解析,需要使用第三方类库 fastJson :阿里巴巴的JSON 库,优势在于解析速度快,解析效率高,可以轻松处理大量的 JSON 数据JackSon : 社区十分活跃,spring框架默认使…...

如何在CSDN中使用ChatGPT
本篇文章致力于帮助大家理解和使用ChatGPT(现在CSDN改成”C知道“了)。简介ChatGPT是OpenAI公司开发的一种大型语言模型。它是一种基于Transformer架构的深度学习模型,可以对语言进行建模和生成。它可以处理问答、对话生成、文本生成等多种任…...
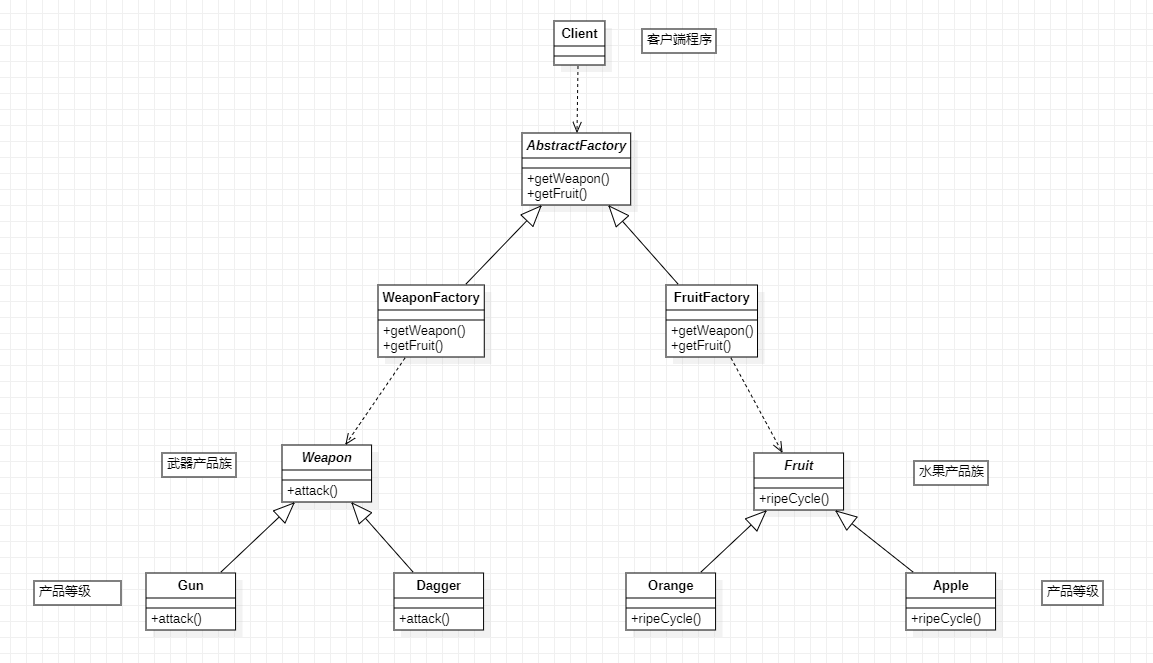
【Spring6】| GoF之工厂模式
目录 一:GoF之工厂模式 1. 工厂模式的三种形态 2. 简单工厂模式 3. 工厂方法模式 4. 抽象工厂模式(了解) 一:GoF之工厂模式 (1)GoF(Gang of Four),中文名——四人组…...

初识Node.js
文章目录初识Node.jsNode.js简介fs模块演示路径问题path路径模块http模块创建web服务器得基本步骤req请求对象res响应对象解决中文乱码问题模块化的基本慨念1、模块化2、Node.js中模块的分类3、Node.js中的模块作用域3.1什么是模块作用域4、向外共享模块作用域中的成员4.1modul…...

C51---软件消抖
1.example #include "reg52.h" #include "intrins.h" //main.c(11): error C264: intrinsic _nop_: declaration/activation error,添加这个头文件就可了 sbit led1 P3^7;//引脚位置,根据原理图可知 sbit key1 P2^1; sbit key2 P2^0; void …...

redis数据持久化
redis备份概念 Redis所有数据都是保存在内存中,Redis数据备份可以定期的通过异步方式保存到磁盘上,该方式称为半持久化模式,如果每一次数据变化都写入aof文件里面,则称为全持久化模式。同时还可以基于Redis主从复制实现Redis备份…...

Java StringBuffer类
Java StringBuffer类是Java语言中一个非常重要的类,它提供了丰富的方法,可以方便地进行字符串操作。本文将详细介绍Java StringBuffer类的作用以及在实际工作中的用途。 StringBuffer类的作用 Java StringBuffer类是一个可变的字符串缓冲区,…...

电路模型和电路定律(2)——“电路分析”
各位CSDN的uu们你们好呀,好久没有更新电路分析的文章啦,今天来小小复习一波,之前那篇博客,小雅兰更新了电路的历史以及电压电流的参考方向,这篇博客小雅兰继续!!! 电阻元件 电压源和…...
天琊超级进程监视器的应用试验(19)
实验目的 1、了解进程概念及其基本原理; 2、掌握天琊超级进程监视器的安装与使用。预备知识 本实验要求实验者具备如下的相关知识。 操作系统的安全配置是整个系统安全审计策略核心,其目的就是从系统根源构筑安全防护体系,通过用户的一…...

使用 Pulumi 打造自己的多云管理平台
前言在公有云技术与产品飞速发展的时代,业务对于其自身的可用性提出了越来越高的要求,当跨区域容灾已经无法满足业务需求的情况下,我们通常会考虑多云部署我们的业务平台,以规避更大规模的风险。但在多云平台部署的架构下…...
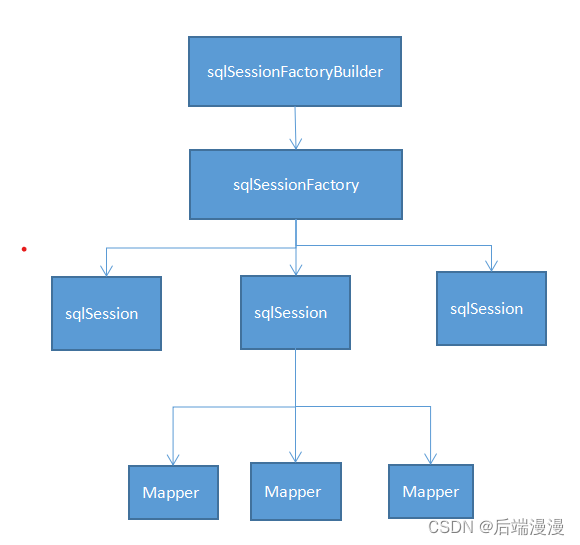
什么是MyBatis?无论是基础教学还是技术精进,你都应该看这篇MyBatis
文章目录学习之前,跟你们说点事情,有助于你能快速看完文章一、先应用再学习,代码示例1. 第一个MyBatis程序2. MyBatis整合Spring3. SpringBoot整合MyBatis二、MyBatis整体流程,各组件的作用域和生命周期三、说说MyBatis-config.xm…...
【编程基础之Python】10、Python中的运算符
【编程基础之Python】10、Python中的运算符Python中的运算符算术运算符赋值运算符比较运算符逻辑运算符位运算符成员运算符身份运算符运算符优先级运算符总结Python中的运算符 Python是一门非常流行的编程语言,它支持各种运算符来执行各种操作。这篇文章将详细介绍…...

Android的基础介绍
一、Android介绍 Android是一种基于Linux的自由及开放源代码的操作系统,Android 分为四个层,从高层到低层分别是应用程序层、应用程序框架层、系统运行库层和Linux内核层。 Android 是Google开发的基于Linux平台的开源手机操作系统。它包括操作系统、用户界面和应用程序——…...
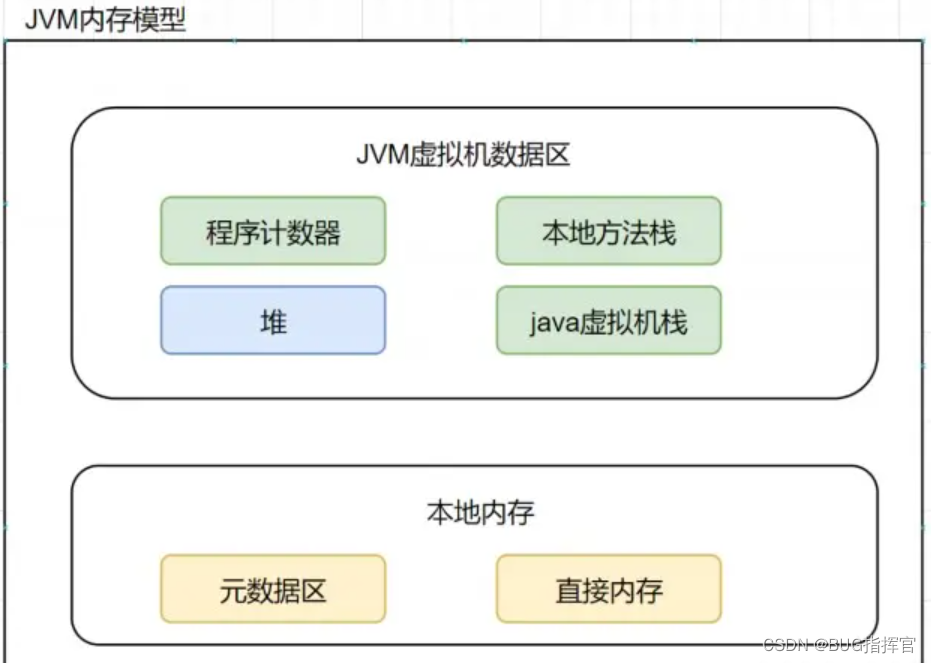
用户登录请求100w/每天, JVM如何调优
用户登录请求100w/每天, JVM如何调优 大概可以分为以下8个步骤。 Step1:新系统上线如何规划容量? 1.套路总结 任何新的业务系统在上线以前都需要去估算服务器配置和JVM的内存参数,这个容量与资源规划并不仅仅是系统架构师的随意估算的&am…...

C/C++每日一练(20230306)
目录 1. 判断素数的个数 ☆ 2. 分隔链表 ★★ 3. 数据流的中位数 ★★ 1. 判断素数的个数 在一个数组A中存放100个数据,用子函数判断该数组中哪些是素数,并统计该素数的个数,在主函数中输出该素数的个数。 代码: #includ…...

向量化计算落地难?揭秘阿里/腾讯内部正在用的7个Java Vector API高危避坑场景
第一章:Java Vector API向量化计算落地的现实困境Java Vector API(JEP 338、414、426、448)虽在JDK 16起逐步成熟,但实际工程化部署仍面临多重结构性约束。其核心矛盾在于:API设计高度抽象,而底层硬件适配、…...

7自由度开源机械臂:如何用6500美元构建AI研究新范式?
7自由度开源机械臂:如何用6500美元构建AI研究新范式? 【免费下载链接】openarm A fully open-source humanoid arm for physical AI research and deployment in contact-rich environments. 项目地址: https://gitcode.com/GitHub_Trending/op/openar…...

AIGlasses_for_navigation多场景落地:日常通勤、医院导诊、地铁站导航三场景实测
AIGlasses_for_navigation多场景落地:日常通勤、医院导诊、地铁站导航三场景实测 1. 引言:当导航从手机屏幕“走”到眼前 想象一下这样的场景:你走在陌生的城市街道,要去一个从未去过的咖啡馆。你不需要低头看手机地图ÿ…...

提升效率:用快马AI一键生成windows18-hd19风格的CSS组件库
提升效率:用快马AI一键生成windows18-hd19风格的CSS组件库 最近在做一个需要windows18-hd19设计风格的项目,这种风格的界面元素特别多,手动编写样式简直让人头大。光是调色板、阴影效果这些基础样式就要折腾半天,更别说那些复杂的…...

请解释 Linux 系统中的内核模块管理,并描述如何加载和卸载模块。
在 Linux 系统中,内核模块(Kernel Modules) 是可以在不重新编译或重启内核的情况下,动态添加到运行中内核的代码片段。它们通常用于支持新的硬件设备、文件系统或网络协议。 这种机制使得 Linux 内核保持精简(核心功能…...

Excel 根据A列标签拆分为多个列数据
举例:如下图所示将AB列内容拆分为红色框内的格式方便绘制图表Sub SplitCategoriesToColumns()Dim ws As WorksheetDim lastRow As LongDim startRow As LongDim dict As ObjectDim keyOrder As New CollectionDim i As Long, j As LongDim key As VariantDim val As…...

基于RK3506与LVGUI的CyberGear电机交互式控制台开发实践
1. 从零搭建CyberGear电机控制环境 第一次拿到RK3506开发板和小米CyberGear电机时,我花了整整两天时间才把基础环境搭好。这里分享几个关键步骤,帮你避开我踩过的坑。 硬件连接部分要注意XT30PB插头的防呆设计,插反了会烧毁接口。建议先用万用…...

保姆级避坑指南:在Ubuntu 22.04上为ROS2 Humble编译OpenCV 4.2.0和cv_bridge
深度解析:Ubuntu 22.04下ROS2 Humble与OpenCV 4.2.0的精准版本匹配实战 当视觉SLAM遇上ROS2生态,版本依赖就像一场精密的外科手术。本文将带你穿透ORB-SLAM3等视觉算法与ROS2 Humble环境整合时的核心痛点——特别是OpenCV 4.2.0与cv_bridge的版本锁定机…...

PingFangSC字体专业配置与高效应用实践指南
PingFangSC字体专业配置与高效应用实践指南 【免费下载链接】PingFangSC PingFangSC字体包文件、苹果平方字体文件,包含ttf和woff2格式 项目地址: https://gitcode.com/gh_mirrors/pi/PingFangSC 在数字设计领域,字体选择直接影响用户体验与信息传…...

[C语言]控制台扫雷游戏
用精简的代码,回顾数组、函数和游戏逻辑的核心应用。还记得Windows自带的扫雷吗?这次我们用C语言实现一个9x9的简易版,适合用来巩固函数封装、二维数组和随机数等知识点。1. 整体思路 扫雷的核心功能可以拆成几块: 打印菜单&#…...