基于大模型和向量数据库的 RAG 示例
1 RAG 介绍
RAG是一种先进的自然语言处理方法,它结合了信息检索和文本生成技术,用于提高问答系统、聊天机器人等应用的性能。
2 RAG 的工作流程
-
文档加载(Document Loading)
- 从各种来源加载大量文档数据。
- 这些文档将作为知识库,用于后续的信息检索。
-
文档分割(Document Splitting)
- 将加载的文档分割成更小的段落或部分。
- 这有助于提高检索的准确性和效率。
-
嵌入向量生成(Embedding Generation)
- 对每个文档或文档的部分生成嵌入向量。
- 这些嵌入向量捕捉文档的语义信息,方便后续的相似度比较。
-
写入向量数据库(Writing to Vector Database)
- 将生成的嵌入向量存储在一个向量数据库中。
- 数据库支持高效的相似度搜索操作。
-
查询生成(Query Generation)
- 用户提出一个问题或输入一个提示。
- RAG模型根据输入生成一个或多个相关的查询。
-
文档检索(Document Retrieval)
- 使用生成的查询在向量数据库中检索相关文档。
- 选择与查询最相关的文档作为信息源。
-
上下文融合(Context Integration)
- 将检索到的文档内容与原始问题或提示融合,构成扩展的上下文。
-
答案生成(Answer Generation)
- 基于融合后的上下文,RAG生成模型产生最终的回答或文本。
- 这一步骤旨在综合原始输入和检索到的信息。
3 准备环境
3.1 向量数据库环境
已经通过百度向量数据库测试申请的才能访问创建,地址:VectorDB 向量数据库官网页-百度智能云
1 创建百度向量数据库实例,注意需要地域,可用区需要和 BCC 保持在同一个 VPC 内。 地址:百度智能云-向量数据库
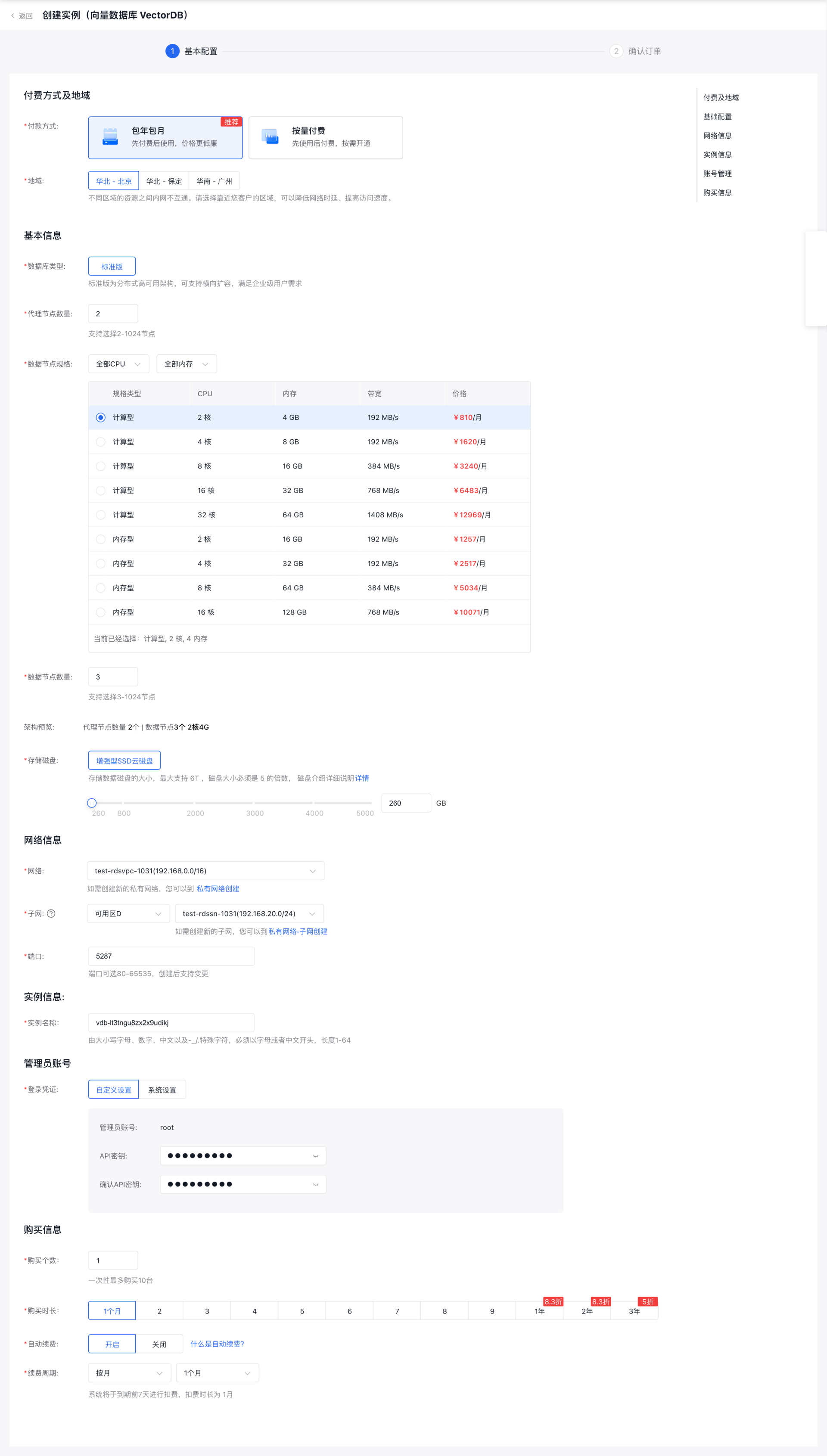
2 创建成功后,通过实例详情页查看访问的地址信息和账号信息,用于访问操作向量数据库。如例子截图,访问信息如下:
# 访问地址格式:http://${IP}:${PORT}
访问地址:http://192.168.20.4:5287
账号:root
密钥:xxxx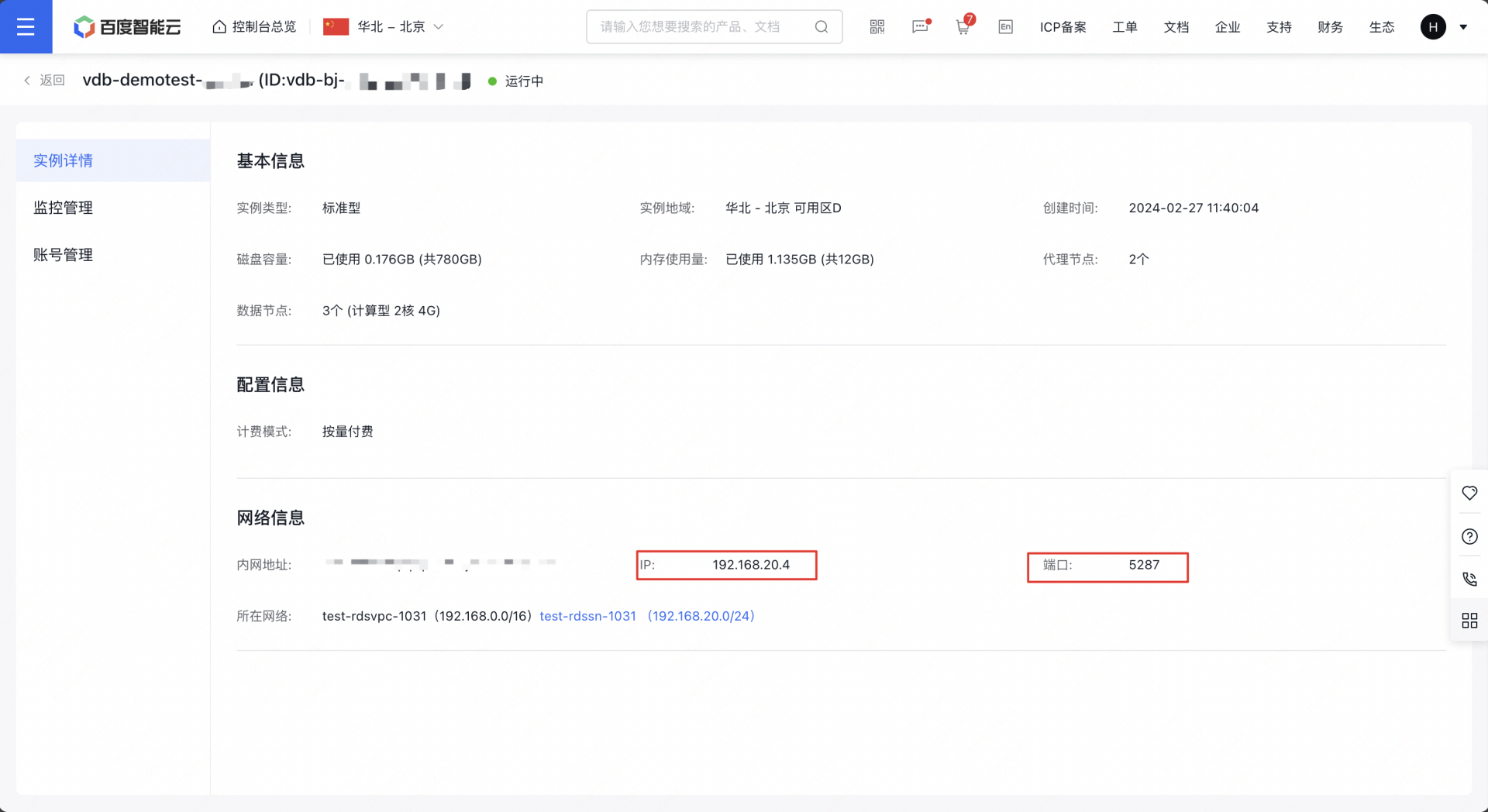
3.2 开通千帆 Embedding 模型
千帆模型开通付费之后才能使用,开通不会产生费用,且有代金券赠送
1 开通千帆 Embedding 模型的收费,地址: 百度智能云千帆大模型平台
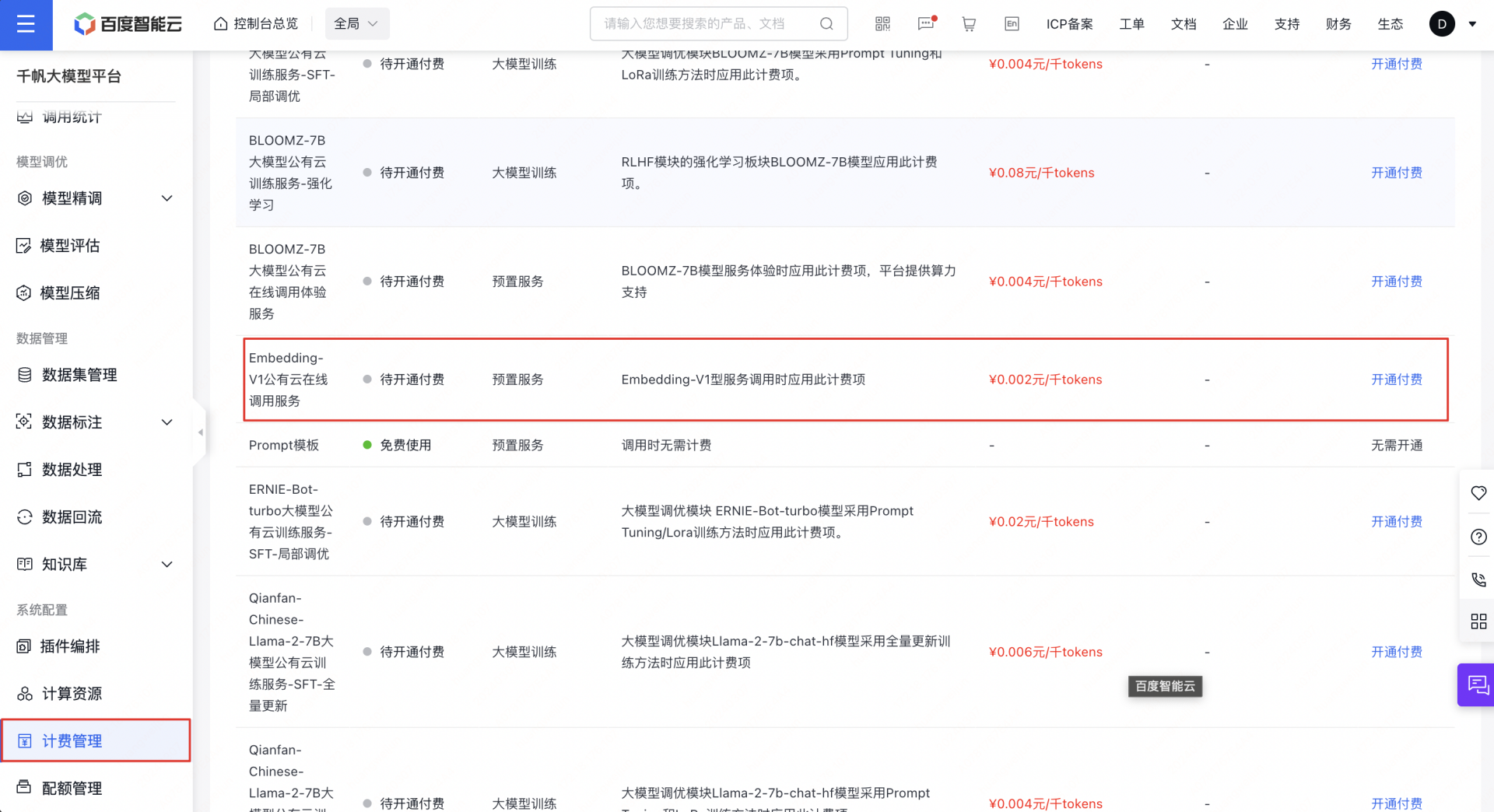
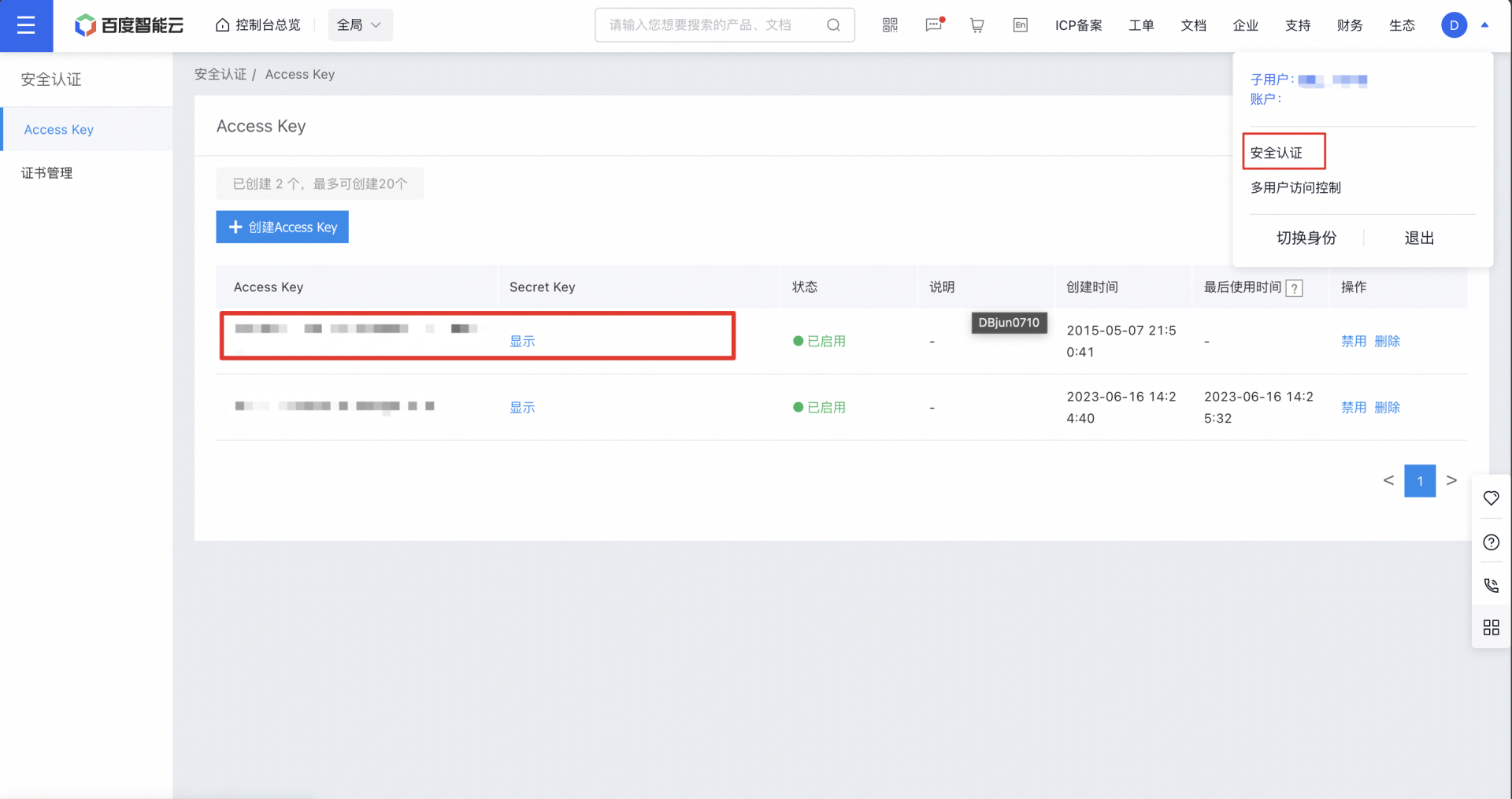
2 右上角个人中心的安全认证里面提取用于鉴权调用 Embedding 模型的 Access Key 和 Secret Key
3.3 客户端环境
3.3.1 数据准备和写入
本例子使用的是 bcc 计算型 c5 2c4g 实例基于 Centos 系统作为例子,但不仅限于 bcc,只要是同 vpc 内的服务器产品都可以。已经有 BCC 客户端的用户忽略步骤 1。
1 创建 BCC 客户端。 地址:百度智能云
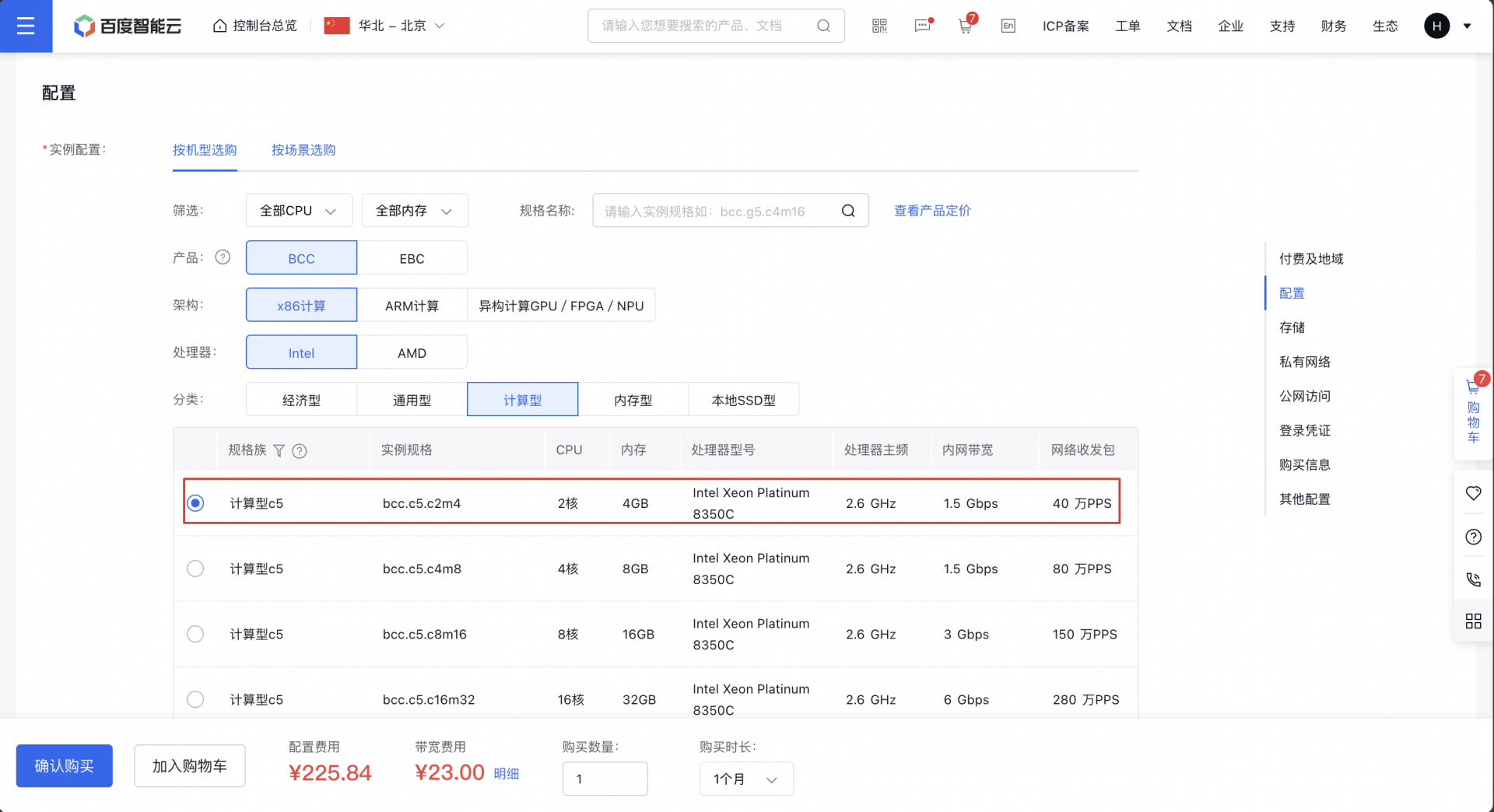
2 登录创建的实例进行环境准备,部署安装 python 环境和搭建知识库所必须的依赖包,
# 安装 python 3.9
yum install -y python39
# langchain 依赖包,用于把文本数据转化为向量数据。
pip3.9 install langchain
# pymochow 依赖包,用于访问和操作百度向量数据库。
pip3.9 install pymochow
# qianfan 依赖包,用于访问千帆大模型。
pip3.9 install qianfan
# pdfplumber 依赖包,加载除了 pdf 文档。
pip3.9 install pdfplumber
# 创建项目目录
mkdir -p knowledge/example_data && cd knowledge3 上传一个 PDF 文件到 knowledge/example_data 目录下
4 创建访问的配置文件
# config.py
import os
from pymochow.auth.bce_credentials import BceCredentials# 定义配置信息
account = 'root'
api_key = '修改为你的密钥'
endpoint = '修改为之前记录的访问地址,如 http://192.168.20.4:5287'# 初始化BceCredentials对象
credentials = BceCredentials(account, api_key)# 设置千帆AI平台的安全认证信息(AK/SK),通过环境变量
# 注意替换以下参数为您的Access Key和Secret Key
os.environ["QIANFAN_ACCESS_KEY"] = "your_iam_ak"
os.environ["QIANFAN_SECRET_KEY"] = "your_iam_sk"5 创建 document 数据库
import pymochow
from pymochow.configuration import Configuration
import config # 导入配置文件config_obj = Configuration(credentials=config.credentials, endpoint=config.endpoint)
client = pymochow.MochowClient(config_obj)try:db = client.create_database("document")
except Exception as e: # 捕获所有类型的异常print(f"Error: {e}") # 打印异常信息
db_list = client.list_databases()
for db_name in db_list:print(db_name.database_name)
client.close()6 创建 chunks 数据表
import time
import pymochow # 导入pymochow库,用于操作数据库
from pymochow.configuration import Configuration # 用于配置客户端
import config # 导入配置文件,包含身份验证和终端信息# 导入pymochow模型相关的类和枚举类型
from pymochow.model.schema import Schema, Field, VectorIndex, SecondaryIndex, HNSWParams
from pymochow.model.enum import FieldType, IndexType, MetricType, TableState
from pymochow.model.table import Partition# 使用配置文件中的信息初始化客户端
config_obj = Configuration(credentials=config.credentials, endpoint=config.endpoint)
client = pymochow.MochowClient(config_obj)# 选择或创建数据库
db = client.database("document")# 定义数据表的字段
fields = [Field("id", FieldType.UINT64, primary_key=True, partition_key=True, auto_increment=False, not_null=True),Field("source", FieldType.STRING),Field("author", FieldType.STRING, not_null=True),Field("vector", FieldType.FLOAT_VECTOR, dimension=384)
]# 定义数据表的索引
indexes = [VectorIndex(index_name="vector_idx", field="vector", index_type=IndexType.HNSW, metric_type=MetricType.L2, params=HNSWParams(m=32, efconstruction=200)),SecondaryIndex(index_name="author_idx", field="author")
]# 尝试创建数据表,捕获并打印可能出现的异常
try:table = db.create_table(table_name="chunks", replication=3, partition=Partition(partition_num=1), schema=Schema(fields=fields, indexes=indexes))
except Exception as e: # 捕获所有类型的异常print(f"Error: {e}") # 打印异常信息# 轮询数据表状态,直到表状态为NORMAL,表示表已准备好
while True:time.sleep(2) # 每次检查前暂停2秒,减少对服务器的压力table = db.describe_table("chunks")if table.state == TableState.NORMAL: # 表状态为NORMAL,跳出循环breaktime.sleep(10) # 如果状态不是NORMAL,等待更长时间再次检查# 打印数据表的详细信息
print("table: {}".format(table.to_dict()))client.close() # 关闭客户端连接7 从PDF文档中加载数据、将文档内容分割为更小的文本块以及利用千帆AI平台的接口来对文本进行向量化表示,并且写到 chunks 表,本例子会用小的文档作为例子,用户可以根据实际情况加载。
# 导入必要的库
from langchain_community.document_loaders import PDFPlumberLoader # 用于加载PDF文档
from langchain.text_splitter import RecursiveCharacterTextSplitter # 用于文本分割
import os # 用于操作系统功能,如设置环境变量
import qianfan # 千帆AI平台SDK
import time # 用于暂停执行,避免请求频率过高
import pymochow
import config # 导入配置文件
from pymochow.model.table import Row # 用于写入向量数据
from pymochow.configuration import Configuration# 加载PDF文档
loader = PDFPlumberLoader("./example_data/ai-paper.pdf") # 指定PDF文件路径
documents = loader.load() # 加载文档
print(documents[0]) # 打印加载的第一个文档内容# 设置文本分割器,指定分割的参数
# chunk_size定义了每个分割块的字符数,chunk_overlap定义了块之间的重叠字符数
# separators列表定义了用于分割的分隔符
text_splitter = RecursiveCharacterTextSplitter(chunk_size=384, chunk_overlap=0, separators=["\n\n", "\n", " ", "", "。", ","]
)
all_splits = text_splitter.split_documents(documents) # 对文档进行分割
print(all_splits[0]) # 打印分割后的第一个块内容emb = qianfan.Embedding() # 初始化嵌入模型对象embeddings = [] # 用于存储每个文本块的嵌入向量
for chunk in all_splits: # 遍历所有分割的文本块# 获取文本块的嵌入向量,使用默认模型Embedding-V1resp = emb.do(texts=[chunk.page_content])embeddings.append(resp['data'][0]['embedding']) # 将嵌入向量添加到列表中time.sleep(1) # 暂停1秒,避免请求过于频繁
print(embeddings[0]) # 打印第一个文本块的嵌入向量# 逐行写入向量化数据
rows = []
for index, chunk in enumerate(all_splits):row = Row(id=index,source=chunk.metadata["source"],author=chunk.metadata["Author"],vector=embeddings[index])rows.append(row)
# 打印第一个Row对象转换成的字典格式,以验证数据结构
print(rows[0].to_dict())# 读取数据库配置文件,并且初始化连接
config_obj = Configuration(credentials=config.credentials, endpoint=config.endpoint)
client = pymochow.MochowClient(config_obj)# 选择或创建数据库
db = client.database("document")try:table = db.describe_table("chunks")table.upsert(rows=rows) # 批量写入向量数据,一次最多支持写入1000条table.rebuild_index("vector_idx") # 创建向量索引,必要步骤
except Exception as e: # 捕获所有类型的异常print(f"Error: {e}") # 打印异常信息
client.close()当打印到如下的数据证明你写入成功了。

3.3.2 文档检索
1 基于标量的检索
import pymochow
from pymochow.configuration import Configuration
import config # 导入配置文件config_obj = Configuration(credentials=config.credentials, endpoint=config.endpoint)
client = pymochow.MochowClient(config_obj)# 选择或创建数据库
db = client.database("document")try:table = db.describe_table("chunks")primary_key = {'id': 0}projections = ["id", "source", "author"]res = table.query(primary_key=primary_key, projections=projections, retrieve_vector=True)
except Exception as e: # 捕获所有类型的异常print(f"Error: {e}") # 打印异常信息print(res)
client.close()结果显示如下:
2 基于向量的检索
import os
import config
import pymochow
import qianfan
from pymochow.configuration import Configuration
from pymochow.model.table import AnnSearch, HNSWSearchParams# 初始化千帆AI平台的嵌入模型对象
emb = qianfan.Embedding()# 定义待查询的问题文本
question = "讲解下大模型的发展趋势"# 获取问题文本的嵌入向量
resp = emb.do(texts=[question])
question_embedding = resp['data'][0]['embedding']# 使用配置信息初始化向量数据库客户端
config_obj = Configuration(credentials=config.credentials, endpoint=config.endpoint)
client = pymochow.MochowClient(config_obj)# 选择数据库
db = client.database("document")try:# 获取指定表的描述信息table = db.describe_table("chunks")# 构建近似最近邻搜索对象anns = AnnSearch(vector_field="vector", # 指定用于搜索的向量字段名vector_floats=question_embedding, # 提供查询向量params=HNSWSearchParams(ef=200, limit=1) # 设置HNSW算法参数和返回结果的限制数量)# 执行搜索操作res = table.search(anns=anns)# 打印搜索结果print(res)
except Exception as e: # 捕获并打印所有异常信息print(f"Error: {e}")# 关闭客户端连接
client.close()3 基于标量和向量的混合检索
import os
import config
import pymochow
import qianfan
from pymochow.configuration import Configuration
from pymochow.model.table import AnnSearch, HNSWSearchParams# 初始化千帆AI平台的嵌入模型对象
emb = qianfan.Embedding()# 定义待查询的问题文本
question = "讲解下大模型的发展趋势"# 获取问题文本的嵌入向量
resp = emb.do(texts=[question])
question_embedding = resp['data'][0]['embedding']# 使用配置信息初始化向量数据库客户端
config_obj = Configuration(credentials=config.credentials, endpoint=config.endpoint)
client = pymochow.MochowClient(config_obj)# 选择数据库
db = client.database("document")try:# 获取指定表的描述信息table = db.describe_table("chunks")# 构建近似最近邻搜索对象anns = AnnSearch(vector_field="vector", # 指定用于搜索的向量字段名vector_floats=question_embedding, # 提供查询向量params=HNSWSearchParams(ef=200, limit=1), # 设置HNSW算法参数和返回结果的限制数量filter="author='CNKI'" # 提供标量的过来条件)# 执行搜索操作res = table.search(anns=anns)# 打印搜索结果print(res)
except Exception as e: # 捕获并打印所有异常信息print(f"Error: {e}")# 关闭客户端连接
client.close()当然后续还需要上下文融合和答案生成,可以基于百度文心大模型的能力实现,本文篇幅有限就不详细展开了。
原文链接:千帆+Langchain+VectorDB 建立简单的 RAG 示例 - 向量数据库 - 设计架构
相关文章:
基于大模型和向量数据库的 RAG 示例
1 RAG 介绍 RAG是一种先进的自然语言处理方法,它结合了信息检索和文本生成技术,用于提高问答系统、聊天机器人等应用的性能。 2 RAG 的工作流程 文档加载(Document Loading) 从各种来源加载大量文档数据。这些文档…...
【C语言】比较两个字符串大小,strcmp函数
目录 一,strcmp函数 1,strcmp函数 2,函数头文件: 3,函数原型: 4,返回取值: 二,代码实现 三,小结 一,strcmp函数 1,strcmp函数 …...

深入理解与应用Keepalive机制
目录 引言 一、VRRP协议 (一)VRRP概述 1.诞生背景 2.基本理论 (二)VRRP工作原理 (三)VRRP相关术语 二、keepalive基本理论 (一)基本性能 (二)实现原…...

嵌入(embedding)概念
嵌入(embedding)在数学和相关领域中的确是指将一个数学对象在保持其某些关键性质不变的前提下,注入到一个更大或更高维的空间中。这个过程不仅仅是简单的映射,而是要求注入的对象在新空间中的表现形式能够完整反映原有对象的内在结…...
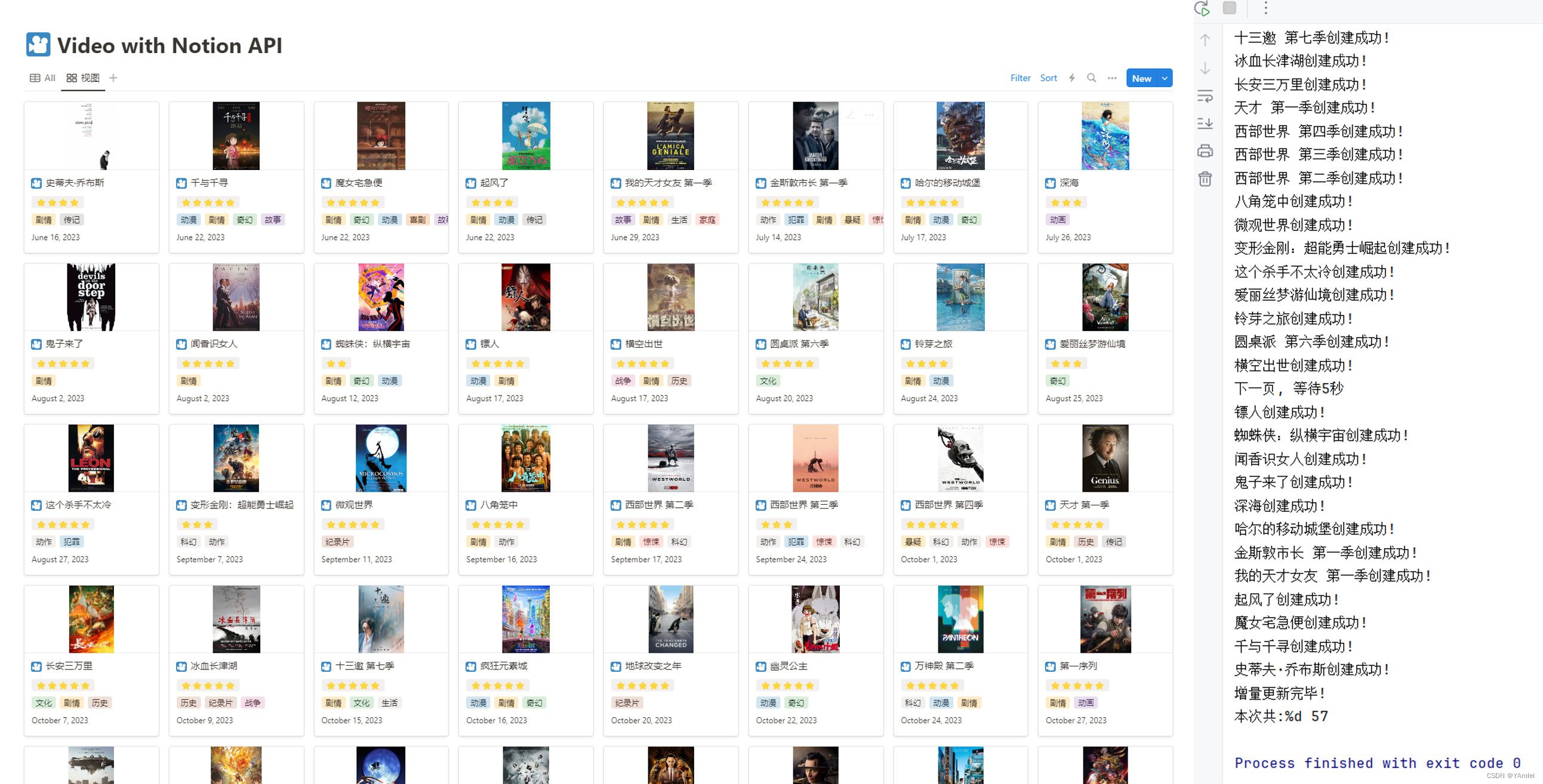
豆瓣书影音存入Notion
使用Python将图书和影视数据存放入Notion中。 🖼️介绍 环境 Python 3.10 (建议 3.11 及以上)Pycharm / Vs Code / Vs Code Studio 项目结构 │ .env │ main.py - 主函数、执行程序 │ new_book.txt - 上一次更新书籍 │ new_video.…...

Lucene 分词 示例代码
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.TokenStream; import org...

2.18 校招 实习 内推 面经
绿*泡*泡VX: neituijunsir 交流*裙 ,内推/实习/校招汇总表格 1、自动驾驶一周资讯 - 李想回应“年终奖有点大”;智界升级为奇瑞独立事业部;小鹏汽车春节累计智驾总里程公布 自动驾驶一周资讯 - 李想回应“年终奖有点大”&…...

spring中事务失效的场景有哪些?
异常捕获处理 在方法中已经将异常捕获处理掉并没有抛出。 事务只有捕捉到了抛出的异常才可以进行处理,如果有异常业务中直接捕获处理掉没有抛出,事务是无法感知到的。 解决:在catch块throw抛出异常。 抛出检查异常 spring默认只会回滚非检…...
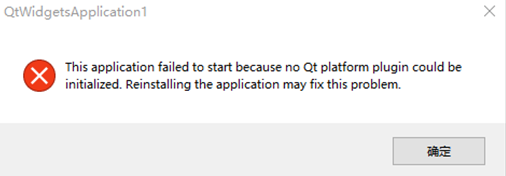
Visual Studio 2022之Release版本程序发送到其它计算机运行
目录 1、缺少dll 2、应用程序无法正常启动 3、This application failed to start because no Qt platform plugin could be initialized. 代码在Debug模式下正常运行,然后切换到Release模式下,也正常运行,把第三方平台的dll拷贝到exe所在…...
.)
Xcode下载模拟器报错Could not download iOS 17.4 Simulator (21E213).
xcode14以后最小化安装包,从而将模拟器不集中在安装包中 因此xcode14至以后的版本安装后第一次启动会加载提示安装模拟器的提示框 或者根据需要到xcode中进行所需版本|平台的模拟器进行安装 Xcode > Settings > Platforms 问题来了尝试多次都安装失败例如…...

mac在终端设置代理
前言 本篇文章介绍如何在mac终端设置代理服务器,有时候,我们需要在终端进行外网的资源访问,比如我构建v8引擎项目的时候,需要使用gclient更新组件和下载构建工具。如果单单设置了计算机的代理,依然是无法下载资源的&a…...

傅立叶之美:深入研究傅里叶分析背后的原理和数学
一、说明 T傅里叶级数及其伴随的推导是数学在现实世界中最迷人的应用之一。我一直主张通过理解数学来理解我们周围的世界。从使用线性代数设计神经网络,从混沌理论理解太阳系,到弦理论理解宇宙的基本组成部分,数学无处不在。 当然,…...
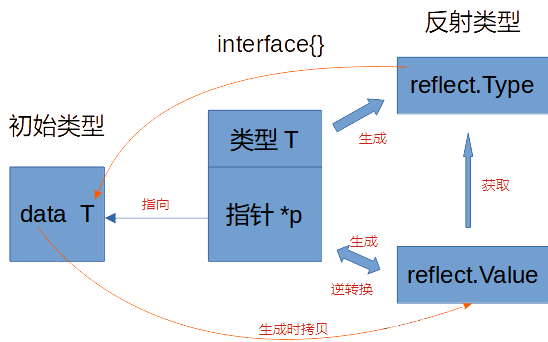
golang学习随便记16-反射
为什么需要反射 下面的例子中编写一个 Sprint 函数,只有1个参数(类型不定),返回和 fmt.Fprintf 类似的格式化后的字符串。实现方法大致为:如果参数类型本身实现了 String() 方法,那调用 String() 方法即可…...

识别恶意IP地址的有效方法
在互联网的环境中,恶意IP地址可能会对网络安全造成严重威胁,例如发起网络攻击、传播恶意软件等。因此,识别恶意IP地址是保护网络安全的重要一环。IP数据云将探讨一些有效的方法来识别恶意IP地址。 IP地址查询:https://www.ipdata…...

探索信号处理:低通滤波器的原理与应用
在信号处理领域,滤波器的应用至关重要,它能够帮助我们从复杂的信号中提取需要的信息,而低通滤波器则是其中一种被广泛应用的滤波器类型。本文旨在深入探讨低通滤波器的基本原理、主要类型以及在实际应用中的作用和实现方式。 ### 1. 低通滤波…...
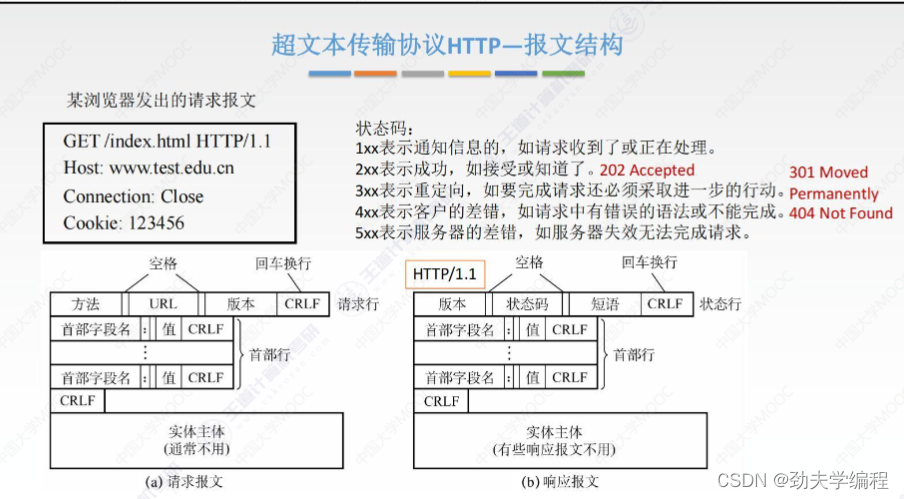
计算机网络:应用层知识点汇总
文章目录 一、网络应用模型二、域名系统(DNS)三、文本传输协议(FTP)四、电子邮件五、万维网和HTTP协议 一、网络应用模型 p2p也就是对等模型 二、域名系统(DNS) 我们知道,随着人们建立一个网站…...
金三银四!一个年薪160W+的就业方向!
前言 随着越来越多的科技大厂加入鸿蒙生态建设,鸿蒙开发人才正在市场上被争抢。资深工程师开出的年薪高达近百万,架构师更是高至160万,真可谓“鸿蒙猿年薪超百万”。如何抓住新技术红利,尽早上车?你会成为下一个鸿蒙开…...
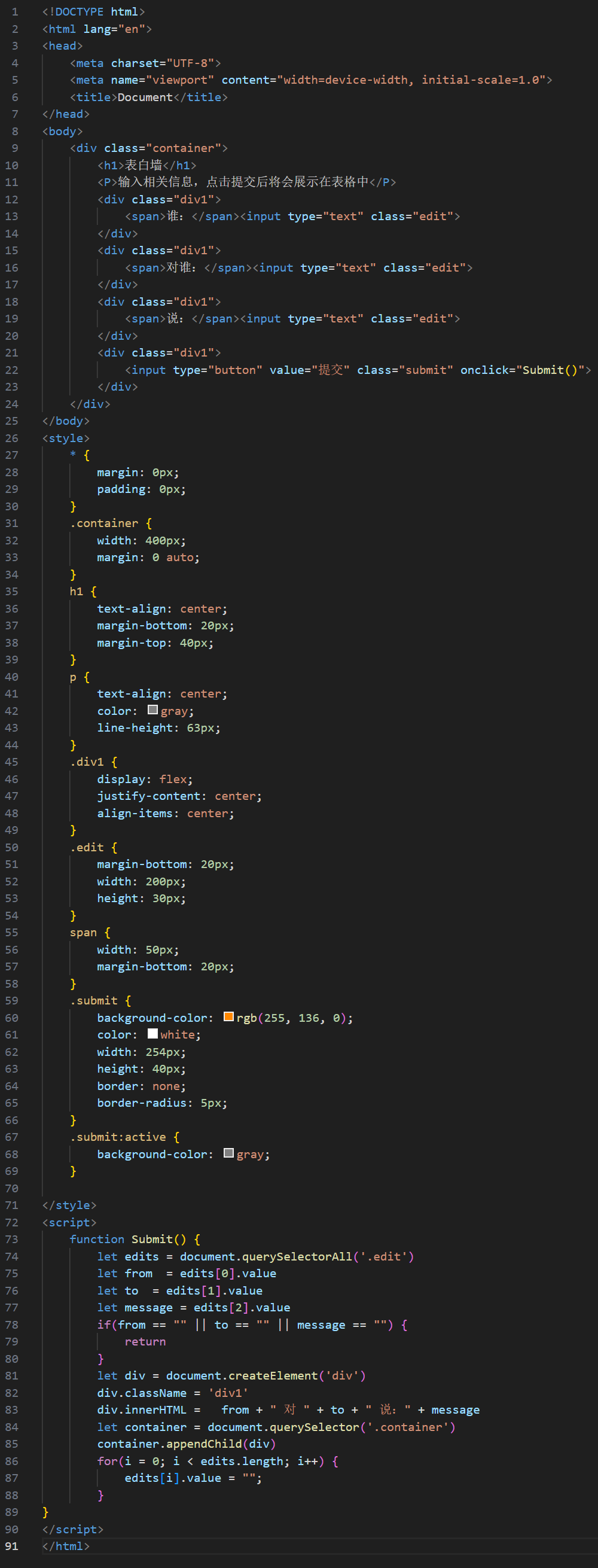
实现的一个网页版的简易表白墙
实现的一个网页版的表白墙 实现效果 代码截图 相关代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><tit…...

随身WiFi靠谱吗? 看完这篇文章你就懂了?2024随身wifi靠谱品牌推荐
在网络如此发达,随身WiFi如此普遍的2024年,仍有人在质疑随身WiFi到底靠不靠谱,有没有用处。其实只需要回答两个问题: 1、你的流量够用吗?手机的流量包和随身WiFi套餐哪个更便宜? 2、手机流量不够用&#x…...

mysql的trace追踪SQL工具,进行sql优化
trace是MySQL5.6版本后提供的SQL跟踪工具,通过使用trace可以让我们明白optimizer(优化器)如何选择执行计划。 注意:开启trace工具会影响mysql性能,所以只适合临时分析sql使用,用完之后请立即关闭。 测试数…...

通过奇异的镜子:LLM 是否像人类大脑一样记忆?
原文:通过奇异的镜子:LLM 是否像人类大脑一样记忆? |LLM|AI|人类大脑|记忆|认知| https://github.com/OpenDocCN/towardsdatascience-blog-zh-2024/raw/master/docs/img/7fcf9c5caa8b28d372dbcb4caeb706af.png 作者使用 DALL-E 创建的图片 …...

好用还专业!2026 降AIGC平台测评:最新工具推荐与对比分析
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

Windows上安装APK文件的终极指南:告别臃肿模拟器,轻松实现跨平台应用安装
Windows上安装APK文件的终极指南:告别臃肿模拟器,轻松实现跨平台应用安装 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你知道吗?…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百22)—东方仙盟
调用函数库://-----------------------------------------------------------------------------------//功能:读DLL版本,不涉及USB口操作C原型:int __stdcall GetDLLVersion(uchar *bufVer)返回:DLL版本//-----------…...

DeepSeek计费策略终极对比:RPM限制、上下文长度溢价、多模态附加费,一文讲透
更多请点击: https://codechina.net 第一章:DeepSeek计费模式分析 DeepSeek 提供的 API 服务采用按 token 用量计费的精细化模型,其计费逻辑与请求类型(输入/输出)、模型版本(如 DeepSeek-VL、DeepSeek-Co…...

高斯过程回归与离散变分原理:数据驱动的物理结构发现
1. 项目概述:当高斯过程回归遇见离散变分原理在物理信息机器学习这个交叉领域,我们常常面临一个核心挑战:如何从有限的、可能带有噪声的观测数据中,不仅还原出物理系统的动态,还能揭示其背后深刻的数学结构?…...

机器学习海气耦合模型Ola:解耦训练与滞后集合预报实战
1. 项目概述:当机器学习遇见海气耦合在气候预测这个领域里摸爬滚打了十几年,我见过太多复杂的物理模型和让人头大的耦合方案。传统的海气耦合模型,比如那些基于物理方程组的数值模式,虽然机理清晰,但计算成本高得吓人&…...

Gofile极速下载器:3倍下载速度的完整指南
Gofile极速下载器:3倍下载速度的完整指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在数字时代,文件分享已成为日常工作的一部分,但…...

Unity Android启动卡在Waiting For Debugger原因与三套解决方案
1. 这个“Waiting For Debugger”到底在等谁?——从Unity启动流程看问题本质你刚在Android设备上点开调试中的Unity App,屏幕却卡在黑屏或白屏,Logcat里反复刷出一行红色日志:Waiting For Debugger。你反复检查USB调试开关、ADB权…...

CatServer深度解析:构建高性能Minecraft模组与插件一体化服务端实战指南
CatServer深度解析:构建高性能Minecraft模组与插件一体化服务端实战指南 【免费下载链接】CatServer 高性能和高兼容性的1.12.2/1.16.5/1.18.2版本ForgeBukkitSpigot服务端 (A high performance and high compatibility 1.12.2/1.16.5/1.18.2 version ForgeBukkitSp…...