Self-supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling
文章目录
- 题目
- 摘要
- 方法
- 数据集
- 实验
题目
通过自我标记进行自我监督的上下文关键字和关键词短语检索

论文地址:https://www.preprints.org/manuscript/201908.0073/v1
项目地址:https://github.com/naister/Keyword-OpenSource-Data
摘要
在本文中,我们提出了一种通过端到端深度学习方法进行关键字和关键短语检索和提取的新型自监督方法,该方法由上下文自标记语料库进行训练。我们提出的方法是新颖的,它使用上下文和语义特征来提取关键词,并且优于现有技术。通过实验证明该方法在语义和质量上均优于现有流行的关键词提取算法。此外,我们建议使用Transform的上下文特征来自动用关键字和关键短语标记短句语料库以构建基本事实。这个过程避免了人工标记关键字的时间,并且不需要任何先验知识。据我们所知,我们在本文中发布的数据集是 NLP 社区中一个良好的、独立于领域的短句语料库,其中带有标记的关键字和关键短语。
关键词是能够简洁、准确地描述文档中全部或部分主题的词[5]。关键字是一元语法,而关键短语是 N 元语法,即多个单词,例如“家庭”是一个关键字,“家庭度假”是一个关键字短语。在可理解性方面,人们更喜欢关键短语而不是关键字,因为与关键字相比,关键短语包含上下文更多的信息和含义,而关键字的上下文含义在不同的文本环境中可能会有所不同。例如,“银行”一词可能意味着银行组织,也可能意味着河岸。因此,背景是一个重要的方面。在本文中,我们通过变压器架构利用文本语料库的上下文特征,并使用它们来开发关键字提取模型。
虽然从长语料库中提取关键词和关键短语很容易,但从较短的句子中提取相同的关键词和关键短语却有点困难。有几种提出的算法可以成功地从长句子语料库中提取关键词,但是,它们对于短句子的性能相对较差。我们将在接下来的章节中讨论一些方法。在本文中,提出的方法 SCKKRS(带有自标签的自监督上下文关键字和关键短语检索)适用于长句和短句语料库,以在语义和上下文上检索关键字和关键短语。我们提出的方法在提取关键词的同时关注上下文特征,因此优于一些现有方法。
方法
关键词和关键短语提取概述关键词和关键短语检索方法大致可分为以下几种:统计方法、基于图的方法、语言学方法、机器学习方法和混合方法。在本节中,我们将讨论每种方法及其背后的概念。
统计方法在关键词和关键短语提取的统计方法中,统计特征的频率测量用于基于语言语料库选择前n个候选者。大多数统计方法都是独立于语言的,因此如果有大型语料库,它们可以应用于每种语言。Gerard Salton 和 Christopher Buckley [3] 讨论了适当的术语权重系统对于有效的信息检索系统的重要性。使用维基百科等外部资源来确定候选短语 [4] 的重要性也是另一种可能性。此外,候选关键短语之间的统计关联可以用作语义一致性的可能代理。 M.W.Berry 等人提出的快速自动关键词提取 (RAKE) [11] 是一种流行的针对单个文档的关键词提取算法,可以扩展到多个文档。 Yutaka Matsuo 和 Mitsuru Ishizuka [5] 提出了另一种统计算法,用于从单个文档中提取关键字,而不依赖于语料库和 TF-IDF 测量。在他们提出的算法中,首先确定频繁出现的术语,然后根据一些相似性度量对它们进行聚类。研究任何术语与这些簇共现的概率分布的偏差程度。如果存在偏差,则该术语很可能是关键字。然而,我们应该注意到,大多数统计方法都是基于语料库中单词的频率度量,并且算法的输出很容易出现语料库中存在的噪声单词。
基于图的方法[18]使用具有共现度量的词袋,并为每个文档提供 N 维向量,其中 N 是语料库中所有可能单词的数量。文档可以由N维向量的余弦相似度矩阵来表示。因此,当我们建立单词和文档之间的图关系时,语料库中的单词成为顶点,而边代表计算出的相似度。最后,可以选择多种中心性算法来提取顶部节点作为关键词和关键短语,例如纯度中心性、特征向量中心性[12]和Pagerank[13]。在 PageRank [13] 中,节点的重要性由代表相关性投票的相邻节点的边决定。通过考虑这些边的权重和相邻节点的排名来递归计算排名分数。同时,textrank [14] 可以应用于文本摘要和关键词提取。 Textrank 使用网络中的声望和 Pagerank 的概念对图的节点进行排名。图中前n个关键词或句子是排名最高的节点。这样,就从句子中提取了关键字列表。
语言方法利用单词的语言特征来进行关键词检测,因此语言方法是依赖于语言的。语言学方法中使用的流行算法包括 POS 模式、n-gram、NP 块等。语言学方法广泛用于领域相关语料库 [15] [16] [17]。语言学方法流行使用规则来决定关键短语的提取。例如,形容词+名词,例如线性代数,以及名词+名词,例如电脑病毒。
关键词提取的机器学习方法与其他机器学习方法一样,都是监督学习方法,需要先验知识——训练数据来学习并输出训练好的模型。训练数据是语料库及其对应的预先标记的关键词和关键短语。
混合方法结合了上述所有方法的优点。使用启发式的方法,例如位置和围绕单词的 HTML 标签属于混合方法 [23]。
数据集
现有的数据集并不适合我们,原因如下:1)它们是特定领域的,因此不能用于通用数据集; 2)它们通常是长段落,而不是短句子长度的语料库; 3)这些数据集就体积而言不够大; 4)关键词和关键短语的标记是基于频率的方法,而不是上下文相关性,因此不太接近真实情况。为了收集数据,我们使用维基百科作为来源。维基百科 [26] 是研究界流行的文本语料库来源。由于我们需要建立一个与领域无关的语料库,我们从维基百科网页中随机收集句子,以确保收集数据的通用性,这确保了语料库不属于特定领域(例如,体育、政治)。
数据清理由于维基百科文章的句子包含特殊字符和停用词,因此上一步的数据集包含大量特殊字符和停用词。因此,我们利用传统的正则表达式和现有的工具包来预处理和清理数据。

我们对句子长度段落进行关键字和关键短语标记的新颖方法使用了一种新颖的自我监督标记关键字和关键短语的方法。该方法是根据关键字与句子的上下文相关性来提取关键字。与基于频率的统计方法(严重依赖共现和术语频率来提取关键词)不同,我们提出的方法考虑了单词与句子的上下文相关性。因此,它在提取单词和短语时利用它们的语义和上下文特征。
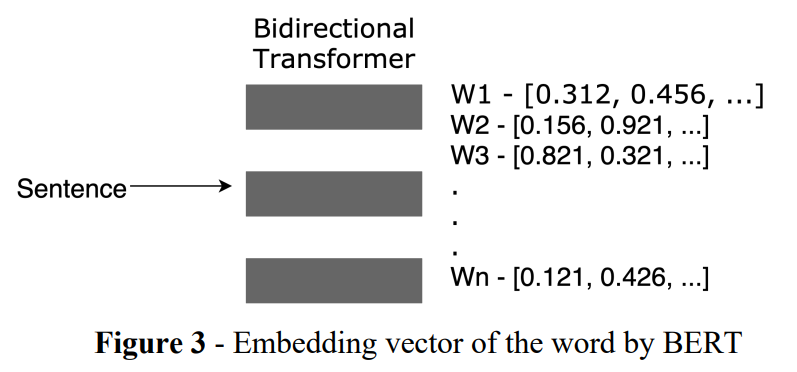
句子中单词的上下文特征是使用双向Transformers[10]提取的,它完全基于注意力机制,完全不需要递归和卷积。对两个机器翻译任务的实验表明,与序列模型相比,这些模型的质量更高。我们将句子输入 BERT,获得每个单词的上下文特征向量,如图 3 所示。对句子中单词的向量进行平均,以获得其句子嵌入向量。然后我们选择接近句子嵌入向量的单词。这个想法是关键字应该捕获句子的含义,因此应该更接近句子嵌入。嵌入与句子嵌入的相似度是使用余弦相似度度量(公式 1)获得的。
S i m i i = c o s ( w i , W ) Simi_i=cos(w_i,W) Simii=cos(wi,W)是单词𝑖 的词嵌入向量𝑤i与句子嵌入向量之间的余弦相似度。一旦提取了候选关键词,我们就可以通过相邻关键词的规则获得关键词。
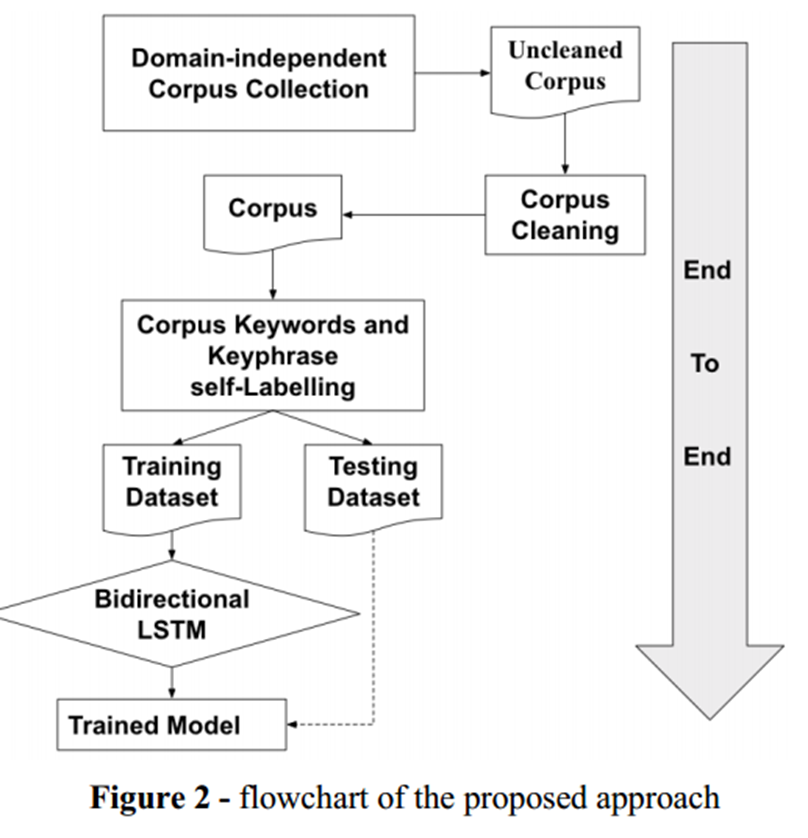
无需人工干预的自标记语料库减少了对手动构建标记良好的语料库以进行关键字和关键短语提取的主要依赖。关键词提取模型在自标记阶段之后,将标记的语料库分为训练集和验证集,然后将其输入基于深度学习的关键词提取模型。如图 2 所示,我们将关键词提取问题视为分类问题,即给定句子的上下文特征,句子中的哪些单词可以被分类为关键词的候选者。因此,将问题视为二元分类器。
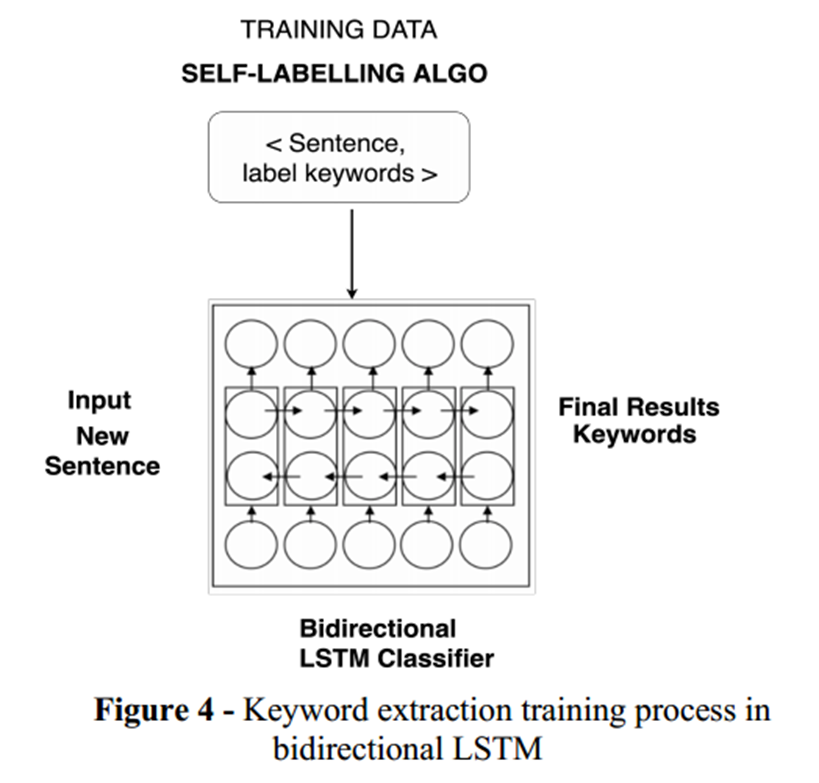
双向 LSTM [6] [7] 将句子作为序列,以及来自自标签的关键字和关键短语标签。标签是按以下方式进行one-hot编码的: 1 - 单词是关键字、0 - 单词不是关键字。然后将此 <sentence, label> 对传递给模型进行训练。采用dropout等正则化方法来避免高方差和低偏差。应该注意的是,标签是根据上下文特征提取的。我们使用图 4 来说明双向 LSTM 的训练过程。
实验
在社区中,大多数开源和公共语料库都是特定领域的,除此之外,带有标签的关键词和关键短语的语料库更是凤毛麟角。此外,它们大多数都是句子较长的语料库,有时甚至长达一个段落,因此这些困难使得它们不适合构建深度学习模型。因此,我们将部分句子长度的语料库开源给社区,可在此处获取:https://github.com/naister/Keyword-OpenSource-Data。据我们所知,这是社区中第一个带有标签关键词和关键短语的公共句子长度语料库。
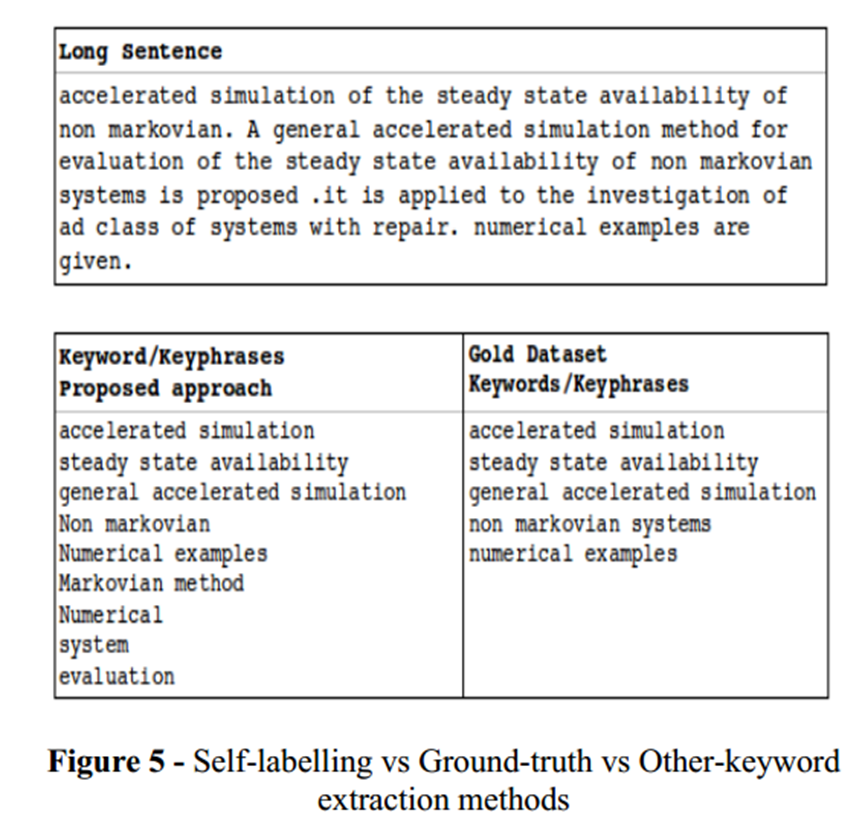
为了进行性能评估,我们使用著名的 INSPEC 数据集 [29] 和 DUC 数据集 [30] 的语料库。图 5 显示了我们提出的方法中的关键字/关键短语以及基本事实的关键字。我们可以看到我们的方法检索了所有关键词/关键短语,甚至给出了比真实情况更有用的关键词和关键短语。
结果如图 6 所示。在图 6 中,g 表示真实关键字,r 表示 RAKE 生成的关键字,t 表示 TextRank 生成的关键字,p 表示建议的自标记关键字。

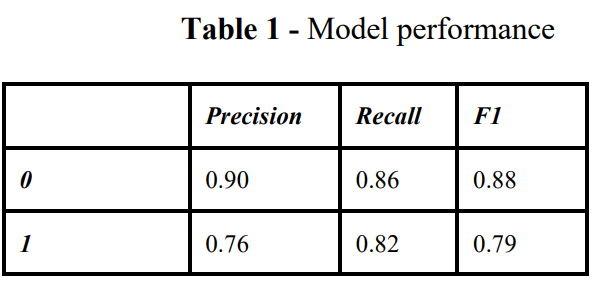
我们将自标记语料库中的训练数据输入到模型训练中并获得模型性能,即准确率、召回率、F1 分数和支持度如表 1 所示。

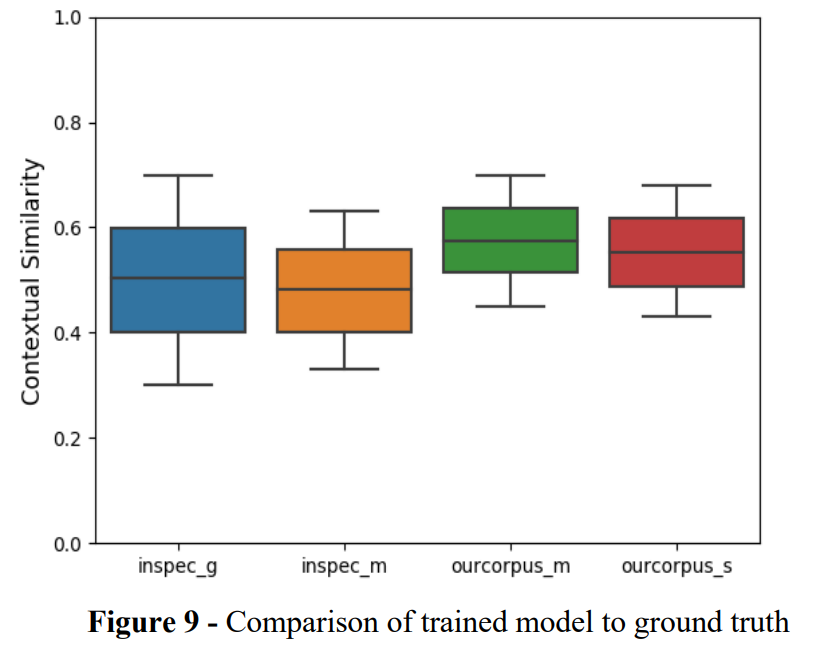
结果如图 9 所示。我们可以看到,在这两个数据集中,所提出的方法都取得了非常接近真实情况的结果,并且当我们考虑图 6 时,也获得了比其他方法更好的统计数据。我们的结果相似性也优于 INSPEC 和 DUC 的真实值,这证明了 INSPEC 和 DUC 的语义和上下文关键字提取比黄金标准更好。
在图 9 中,g 是真实值,m 表示来自我们训练模型的关键字或关键短语,s 是来自我们方法的自标记关键字或关键短语。
相关文章:
Self-supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling
文章目录 题目摘要方法数据集实验 题目 通过自我标记进行自我监督的上下文关键字和关键词短语检索 论文地址:https://www.preprints.org/manuscript/201908.0073/v1 项目地址:https://github.com/naister/Keyword-OpenSource-Data 摘要 在本文中&#x…...

新 树莓派4B 温湿度监测 基于debian12的树莓派OS
前言 本文旨在完成通过外接温湿度传感器至树莓派使得树莓派不断记录并存储温湿度数据 这个领域有很多文章,但是部分文章已经缺乏了时效性,在最新系统不适用,本文目前适用 硬件 硬件连接 温湿度传感器常选用DHT11和DHT22,淘宝…...
)
人工智能入门之旅:从基础知识到实战应用(一)
一、引言 人工智能(Artificial Intelligence,AI)是指利用计算机科学和技术模拟、延伸和扩展人类智能的理论、方法、技术和应用系统的学科。它的目标是使计算机系统具有类似于人类的智能,能够感知环境、学习、推理、规划、解决问题和交流。 在当今社会中,人工智能具有极其…...

GNN/GCN自己学习
一、图的基本组成 V:点(特征) E:边 U:图(全局特征) 二、用途 整合特征(embedding),做重构 三、邻接矩阵 以图像为例,每个像素点周围都有邻居,…...

honle电源维修UV电源控制器维修EVG EPS60
好乐UV电源控制器维修;honle控制器维修;UV电源维修MUC-Steuermodul 2 LΛmpen D-82166 主要维修型号: EVG EPS 60/120、EVG EPS 100、EVG EPS200、EVG EPS 220、EVG EPS 340、EVG EPS40C-HMI、EVG EPS60 HONLE好乐uv电源维修故障包括&#…...
【学习心得】Python好库推荐——websocket-client
websocket-client 是一个在 Python 中广泛使用的库,用于创建 WebSocket 客户端并实现与 WebSocket 服务器的双向通信。更多的关于websocket协议介绍,可以看看我之前写的文章哦! 【学习心得】websocket协议简介并与http协议对比http://t.csdn…...
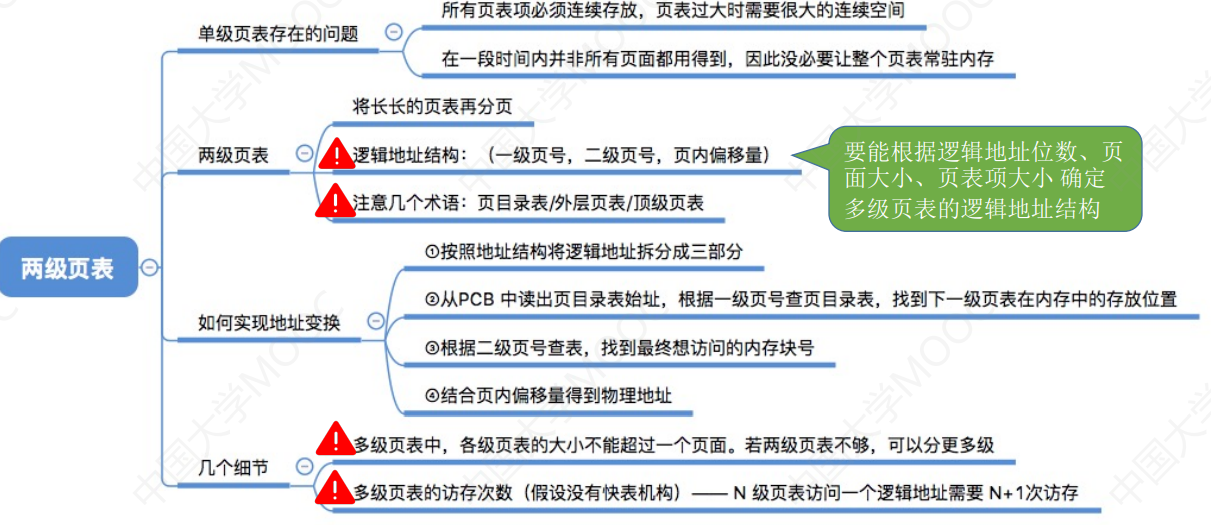
3.1_8 两级页表
文章目录 3.1_8 两级页表(一)单级页表存在的问题(二)如何解决单级页表的问题?(三)两级页表的原理、地址结构(四)如何实现地址变换(五)需要注意的几…...

【SysBench】sysbench-1.20 命令速查表
1、通用语法 The general command line syntax for sysbench is: sysbench [options]... [testname] [command] testname is an optional name of a built-in test (e.g. fileio, memory, cpu, etc.), or a name of one of the bundled Lua scripts (e.g. oltp_read_only), or…...

neo4j网页无法打开,启动一会儿后自动关闭,查看neo4j status显示Neo4j is not running.
目录 前情提要User limit of inotify watches reached无法访问此网站 前情提要 公司停电,服务器未能幸免,发现无法访问此网站,http://0.0.0.0:7474 在此之前都还好着 User limit of inotify watches reached (base) [rootlocalhost ~]# n…...

一键卸载和安装 nvidia、cuda、cudnn、tensorrt
1. 卸载 nvidia、cuda、cudnn、tensorrt sudo apt purge \"cuda*" \"libcudnn*" \"libnvinfer*" \"libnvonnxparsers*" \"libnvparsers*" \"tensorrt*" \"nvidia*&…...

LeetCode 389. 找不同
文章目录 一、题目二、C 题解 一、题目 给定两个字符串 s 和 t ,它们只包含小写字母。 字符串 t 由字符串 s 随机重排,然后在随机位置添加一个字母。 请找出在 t 中被添加的字母。 示例 1: 输入:s “abcd”, t “abcde” 输出&…...

科技云报道:两会热议的数据要素,如何拥抱新技术?
科技云报道原创。 今年全国两会上,“数字经济”再次成为的热点话题。 2024年政府工作报告提到:要健全数据基础制度,大力推动数据开发开放和流通使用;适度超前建设数字基础设施,加快形成全国一体化算力体系࿱…...
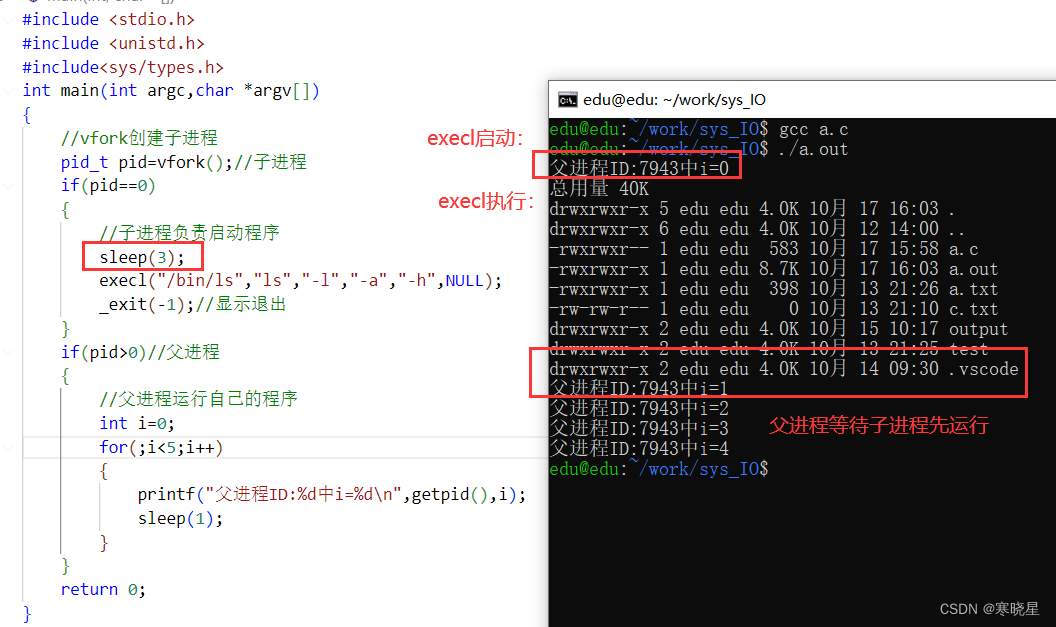
【linux】进程管理:进程控制块、进程号、fork创建进程、特殊进程及exec函数族解析
一、进程的概述 可执行程序运行起来后(没有结束之前),它就成为了一个进程。程序是存放在存储介质上的一个可执行文件,而进程是程序执行的过程。进程的状态是变化的,其包括进程的创建、调度和消亡。程序是静态的,进程是…...
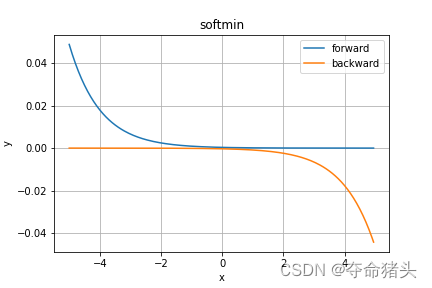
【DL经典回顾】激活函数大汇总(八)(Maxout Softmin附代码和详细公式)
激活函数大汇总(八)(Maxout & Softmin附代码和详细公式) 更多激活函数见激活函数大汇总列表 一、引言 欢迎来到我们深入探索神经网络核心组成部分——激活函数的系列博客。在人工智能的世界里,激活函数扮演着不…...

Docker进阶:深入了解 Dockerfile
Docker进阶:深入了解 Dockerfile 一、Dockerfile 概述二、Dockerfile 优点三、Dockerfile 编写规则四、Dockerfile 中常用的指令1、FROM2、LABEL3、RUN4、CMD5、ENTRYPOINT6、COPY7、ADD8、WORKDIR9、 ENV10、EXPOSE11、VOLUME12、USER13、注释14、ONBUILD 命令15、…...
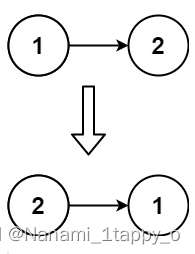
【LeetCode热题100】206. 反转链表(链表)
一.题目要求 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 二.题目难度 简单 三.输入样例 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1] 示例 2: 输入:head [1,2…...

电玩城游戏大厅计时软件怎么用,佳易王计时计费管理系统软件定时语音提醒操作教程
电玩城游戏大厅计时软件怎么用,佳易王计时计费管理系统软件定时语音提醒操作教程 一、前言 以下软件操作教程以 佳易王电玩计时计费软件V18.0为例 说明 软件文件下载可以点击最下方官网卡片——软件下载——试用版软件下载 1、软件计时计费,只需点击开…...

selenium也能过某数、5s盾..
文章转载于:selenium也能过某数、5s盾… 直接安装: pip install undetected_chromedriver运行代码: import undetected_chromedriver as uc import timedriver uc.Chrome(executable_pathrC:\Users\chromedriver.exe,version_main111) driver.get(网…...

mysql笔记:8. 视图
文章目录 创建视图修改视图删除视图通过视图更新数据1. 插入数据2. 更新数据3. 删除数据 查看视图信息1. DESCRIBE2. SHOW TABLE STATUS3. SHOW CREATE VIEW4. 在views表中查看 数据库中的视图是一个虚拟表。同真实的表一样,视图包含一系列带有名称的列和行数据。行…...

指针的基本概念和用法
指针的基本概念 每个变量都被存放在从某个内存地址(以字节为单位)开始的若干字节中 “指针”也被称作“指针变量”,大小为4个字节(在64位编译器中,也优肯为8个字节)的变量,其内容代表一个内存地…...

昇腾CANN ops-nn GELU 激活函数:精确版 vs tanh 近似版,选错就是 3× 慢
GELU(Gaussian Error Linear Unit)是 BERT 的灵魂激活函数,后来被 GPT-2/3 沿用。两种实现:精确版(调用 erf,慢但数学精确)和 tanh 近似版(快但误差 ~0.1%)。BERT 的训练…...

基于注意力机制的科学数据压缩:层次化架构与误差边界保证
1. 项目概述:当科学计算遇上注意力机制在计算流体动力学、气候模拟、高能物理这些前沿科学领域,每一次仿真实验都可能产生TB甚至PB级别的数据。这些数据并非杂乱无章,它们通常诞生于高度结构化的多维网格之上,每个网格点承载着一个…...

全域轨迹可回溯,高效破解煤矿灾害搜救难题 ——基于视频孪生无感定位的矿山轨迹溯源搜救技术解析方案
全域轨迹可回溯,高效破解煤矿灾害搜救难题——基于视频孪生无感定位的矿山轨迹溯源搜救技术解析方案一、方案前言煤矿井下瓦斯爆炸、顶板垮塌、透水冲击等灾害发生后,巷道结构损毁、通信供电中断、有害气体弥漫,现场环境瞬息万变。传统人员监…...

MD-Editor-V3 编辑器查找替换功能深度解析与实现原理
MD-Editor-V3 编辑器查找替换功能深度解析与实现原理 【免费下载链接】md-editor-v3 Markdown editor for vue3, developed in jsx and typescript, dark theme、beautify content by prettier、render articles directly、paste or clip the picture and upload it... 项目地…...

【行业首发】DeepSeek V3 MoE稀疏激活机制详解:如何用1/3显存跑满128K上下文?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek V3 MoE稀疏激活机制的行业意义与定位 DeepSeek V3 采用混合专家(Mixture of Experts, MoE)架构,其核心突破在于实现了动态、细粒度的稀疏激活——每次前向传…...

如何免费将PPTX转为HTML?纯JavaScript终极解决方案完整指南
如何免费将PPTX转为HTML?纯JavaScript终极解决方案完整指南 【免费下载链接】PPTX2HTML Convert pptx file to HTML by using pure javascript 项目地址: https://gitcode.com/gh_mirrors/pp/PPTX2HTML 在数字化办公和在线教育的时代,你是否经常需…...

终极鼠标抖动工具指南:告别电脑休眠困扰的简单解决方案
终极鼠标抖动工具指南:告别电脑休眠困扰的简单解决方案 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. 项…...

Monitorian终极指南:Windows多显示器亮度自动化管理完整教程
Monitorian终极指南:Windows多显示器亮度自动化管理完整教程 【免费下载链接】Monitorian A Windows desktop tool to adjust the brightness of multiple monitors with ease 项目地址: https://gitcode.com/gh_mirrors/mo/Monitorian 你是否曾经为Windows系…...

5分钟解锁Switch终极性能:Atmosphere大气层系统完全指南
5分钟解锁Switch终极性能:Atmosphere大气层系统完全指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 想让你的Nintendo Switch游戏体验彻底升级吗?Atmosphere-st…...

m4s-converter:5分钟解锁B站缓存视频,打造个人专属媒体库
m4s-converter:5分钟解锁B站缓存视频,打造个人专属媒体库 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓…...