【数据结构与算法】:插入排序与希尔排序

🔥个人主页: Quitecoder
🔥专栏: 数据结构与算法
欢迎大家来到初阶数据结构的最后一小节:排序

目录
- 1.排序的基本概念与分类
- 1.1什么是排序的稳定性?
- 1.2内排序与外排序
- 内排序
- 外排序
- 2.插入排序
- 2.1实现插入排序
- 2.3稳定性分析
- 3.希尔排序
- 3.1预排序代码实现
- 3.2希尔排序代码实现
- 3.3时间复杂度分析
- 4.clock函数
- 总结
1.排序的基本概念与分类
排序是一种将一组对象按照某种特定顺序重新排列的过程。在计算机科学中,排序是数据处理中非常基本且重要的操作,它可以帮助人们更有效地理解和分析数据。排序的顺序通常是升序或降序,也可以按照数字、字母、大小或其他标准进行
常见的排序算法有冒泡排序、选择排序、插入排序、快速排序、希尔排序、堆排序等等
1.1什么是排序的稳定性?
排序的稳定性是指在排序过程中,具有相等键值的元素在排序前后保持相同顺序的特性。简单来说,如果排序前两个相等的元素A和B(A出现在B之前),在排序后A仍然出现在B之前,那么这种排序算法就是稳定的;反之,如果排序后A和B的顺序发生了变化,这种排序算法就是不稳定的。
稳定性在某些情况下很重要,尤其是当排序的键值是复合的,即基于多个字段进行排序时。在这种情况下,保持相等元素的初始顺序可能对保持数据的某种有意义的顺序非常关键。例如,在对一组人按出生日期排序时,如果有两个人出生日期相同,我们可能会希望他们在排序后保持按姓名的顺序,如果使用稳定的排序算法,就可以保证这一点。
1.2内排序与外排序
根据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序和外排序。
内排序
内排序是指所有需要排序的数据都加载到内存中进行排序的过程。这种排序方式适用于数据量不是非常大,能够一次性装入内存的情况。内排序的优点是速度快,因为内存的访问速度远高于磁盘或其他存储设备。常见的内排序算法包括快速排序、归并排序、堆排序、冒泡排序、选择排序、插入排序等。
外排序
外排序是指当需要排序的数据量非常大,一次性无法全部加载到内存中时使用的排序方法。这种情况下,数据通常存储在磁盘或其他外部存储设备上,排序过程中需要多次在内存和存储设备之间交换数据。外排序的一个典型例子是归并排序的一个变种,它将数据分成多个小块,首先对每个小块进行排序(内排序),然后将这些已排序的小块合并成一个有序的整体。外排序适用于大规模数据处理,但速度通常会比内排序慢
接下来我们来介绍两种排序:直接插入排序与希尔排序
2.插入排序
直接插入排序是一种简单的插入排序法,其基本思想是:
把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列

扑克牌是我们都玩过的游戏,拿到这组牌,我们进行理牌,将3和4移动到5的左侧,再将⒉移动到最左侧,顺序就算是理好了。这里的理牌方法,就是直接插入排序法。
2.1实现插入排序
思路
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移
首先构造函数
void InsertSort(int *a,int n);
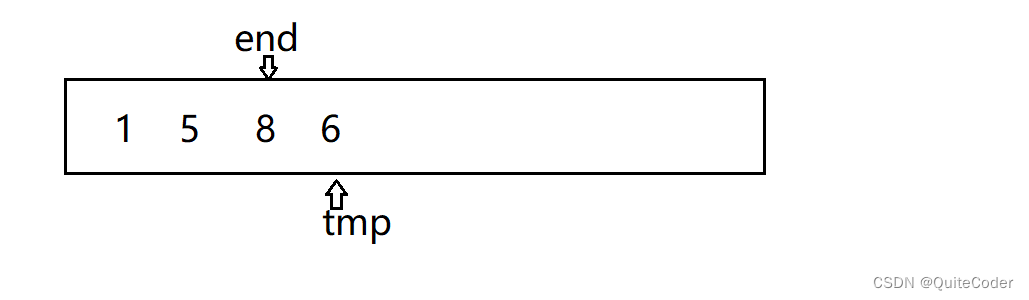
假设这里有数据1 5 8 6
我们认为在0到end这一段有序,把end+1的数插入数组
- 这里的end代表已排序序列的最后一个元素的索引。将插入的数据依次往前比较,如果比前面的数字end大,则放在end后面
- 如果比前面的数字小,则让前面的数字往后移动,则这里用变量tmp存放要插入的值
- 前面的数字移动后,end减一,继续比较
这里还有一种情况
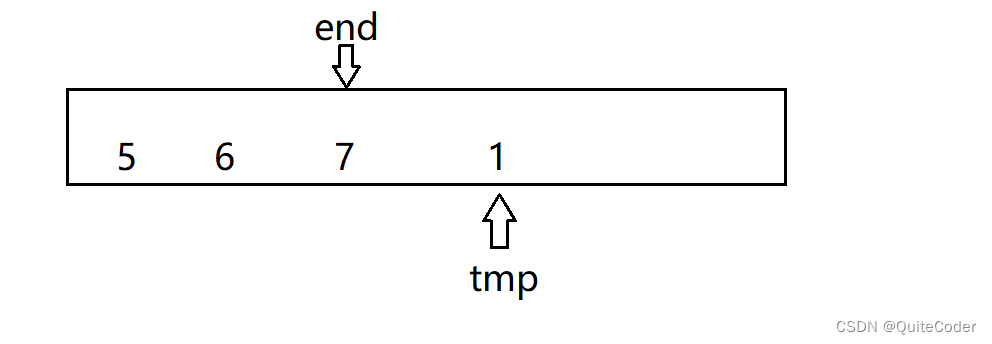
这里要插入1,遇到7,向前移动,end–,当移动到最前面的位置时,end减为-1
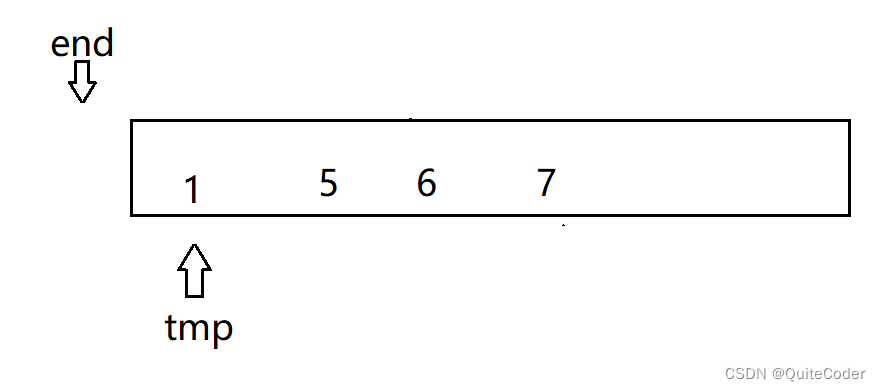
只考虑单趟排序,可实现代码如下:
int end;
int tmp = a[end + 1];
while (end >= 0)
{if (tmp < a[end]){a[end + 1] = a[end];end--;}elsebreak;
}
a[end+1]=tmp;
这里跳出循环有两种情况:
- 找到插入位置:当tmp大于等于a[end],这表明tmp应该插入在a[end]的后面,因为在tmp之前的元素(包括a[end]自己)都已经排序好了,并且都是小于等于tmp的。这就是tmp的正确位置,在这种情况下,我们执行break语句跳出循环,并将tmp放置在end + 1的位置
- 达到有序序列的起点:当循环保持进行,end值在每次迭代中不断递减,如果tmp小于所有已排序的元素,end可能会变成-1,这意味着tmp比有序序列中所有现有的元素都要小,应该被放在整个序列的最开始位置。
在这两种跳出循环的情况下,我们总是需要执行a[end + 1] = tmp;来将tmp元素放置到正确的位置上。因为无论是找到合适的插入点还是tmp成为新的最小元素,我们都需要将它实际插入到有序序列中,这就是为什么这行代码放在循环之外,确保跳出循环后,我们执行最终的插入动作。
考虑单趟排序之后,我们来进行整个过程:
void InsertSort(int *a,int n)
{for (int i = 0; i < n; i++){int end=i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];end--;}elsebreak;}a[end + 1] = tmp;}
}
通过将数组分为已排序部分和未排序部分来工作。从未排序部分取出的值被放置在已排序部分的正确位置。最初,已排序部分只包含数组的第一个元素。
end最初被设置为当前索引i,并将用于通过已排序部分向后遍历,以找到tmp值的正确插入点。
我们进行代码测试:
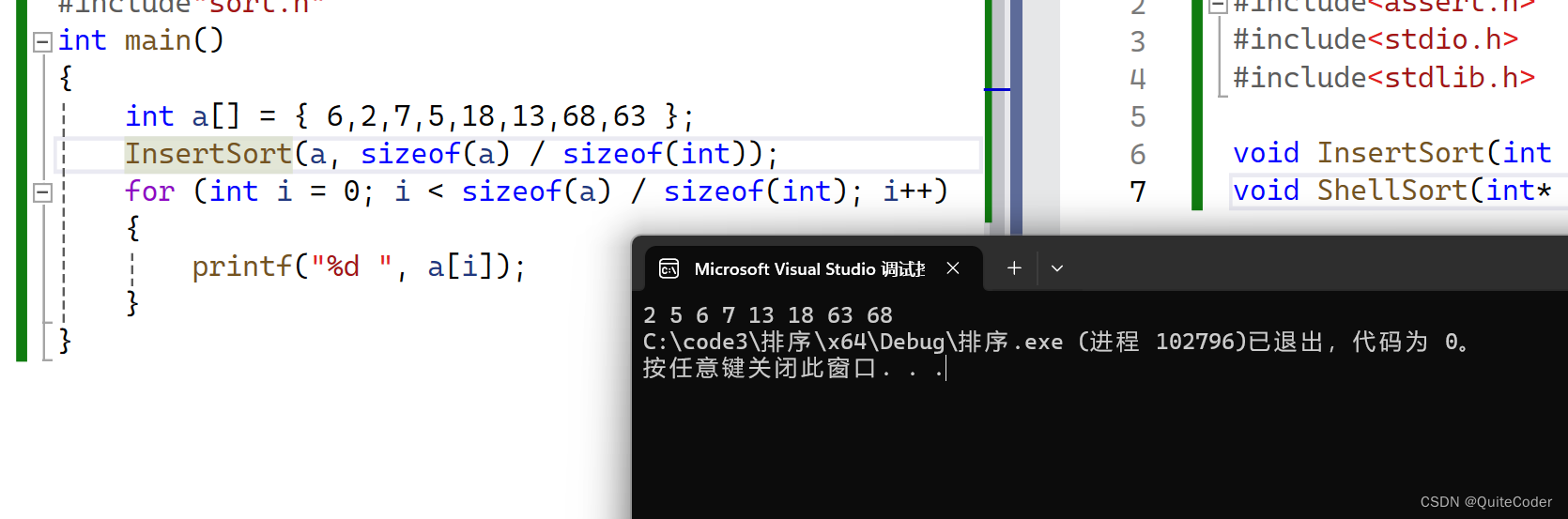
插入排序算法的时间复杂度取决于输入数组中元素的初始排序状态:
- 最坏情况 :如果数组是完全逆序的,那么每次插入操作都需要将元素移到已排序部分的开头。这就意味着对于第i个元素,可能需要进行i次比较和移动。这种情况下,算法的时间复杂度是O(N2),因为需要进行总计约1 + 2 + 3 + … + (n-1)次比较,这是一个n(n-1)/2的等差数列
- 最好情况 :这种情况发生在数组已经完全有序时。在这种情况下,每次比较后,很快就会找到插入位置(在已排序元素的末尾),不需要进行额外的移动。因此,最好情况下插入排序的时间复杂度是O(N),因为外层循环只会遍历一次数组,内层循环不会进行任何实际的比较和移动操作。
插入排序的空间复杂度为O(1),因为它是一个原地排序算法,不需要额外的存储空间来排序。
2.3稳定性分析
在插入排序中,每个新元素被"插入"到已经排序的序列中,在找到合适的插入位置之前,它不会交换到任何具有相同值的元素前面。我们来逐步分析插入排序算法来说明其稳定性:
- 排序初始时,认为第一个元素自成一个已排序的序列
- 从第二个元素开始,取出未排序的下一个元素,在已排序的序列中从后向前扫描
- 如果当前扫描到的元素大于新元素(待插入),那么将扫描到的元素向后移动一个位置
- 重复步骤3,直到找到一个元素小于或等于新元素的位置,或者序列已经扫描完毕
- 将新元素插入到这个位置后面
在步骤4中,插入排序的算法逻辑保证了如果存在相等的元素,新元素(待插入)将被放置在相等元素的后面。因此,原始顺序得以保持,插入排序被认为是稳定的
3.希尔排序
希尔排序是一种基于插入排序的算法,通过引入增量的概念来改进插入排序的性能
希尔排序的基本思想是将原始列表分成多个子列表,先对每个子列表进行插入排序,然后逐渐减少子列表的数量,使整个列表趋向于部分有序,**最后当整个列表作为一个子列表进行插入排序时,由于已经部分有序,所以排序效率高。**这个过程中,每次排序的子列表是通过选择不同的“增量”来确定的。
实现思路:
- 预排序
- 直接插入排序
预排序:
根据当前增量,数组被分为若干子序列,这些子序列的元素在原数组中间隔着固定的增量。对每个子序列应用插入排序。
假设当前增量为3:
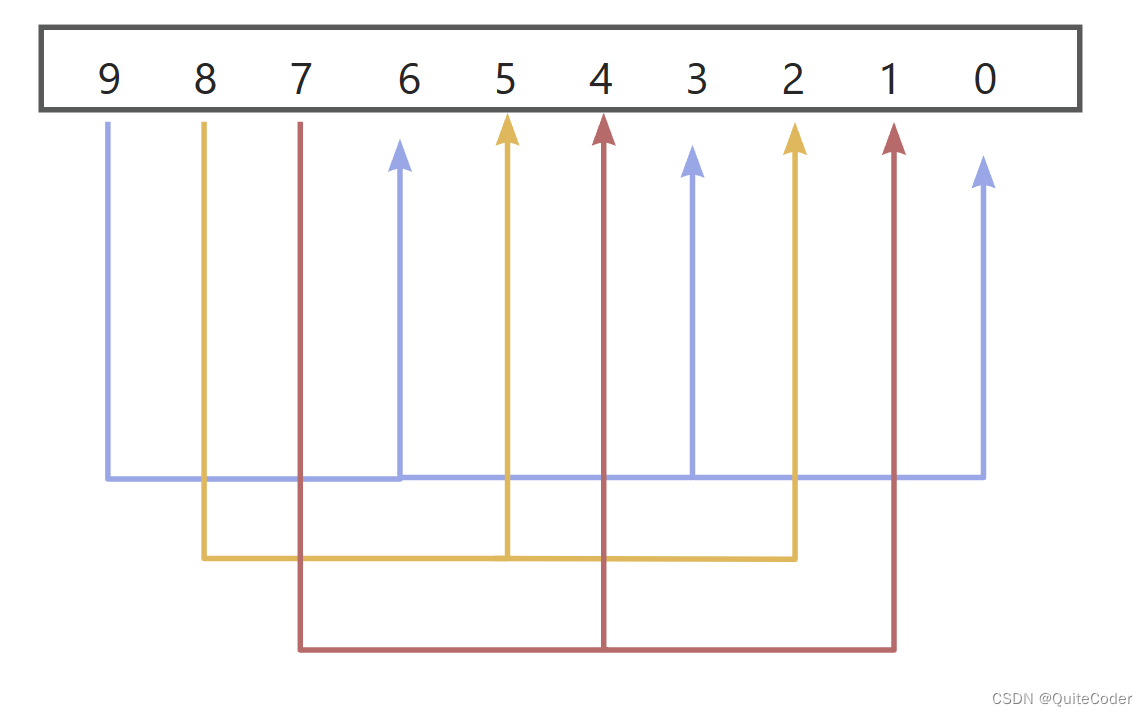
首先,增量为3,我们将数组元素分为增量(3)个子序列,每个子序列由原数组中相隔增量位置上的元素组成。所以我们有如下子序列:
- 子序列1:
9, 6, 3, 0 - 子序列2:
8, 5, 2 - 子序列3:
7, 4, 1
然后对每个子序列进行独立的插入排序:
- 子序列1排序后:
0, 3, 6, 9 - 子序列2排序后:
2, 5, 8 - 子序列3排序后:
1, 4, 7
现在将排序后的子序列放回原数组中,数组变化为:
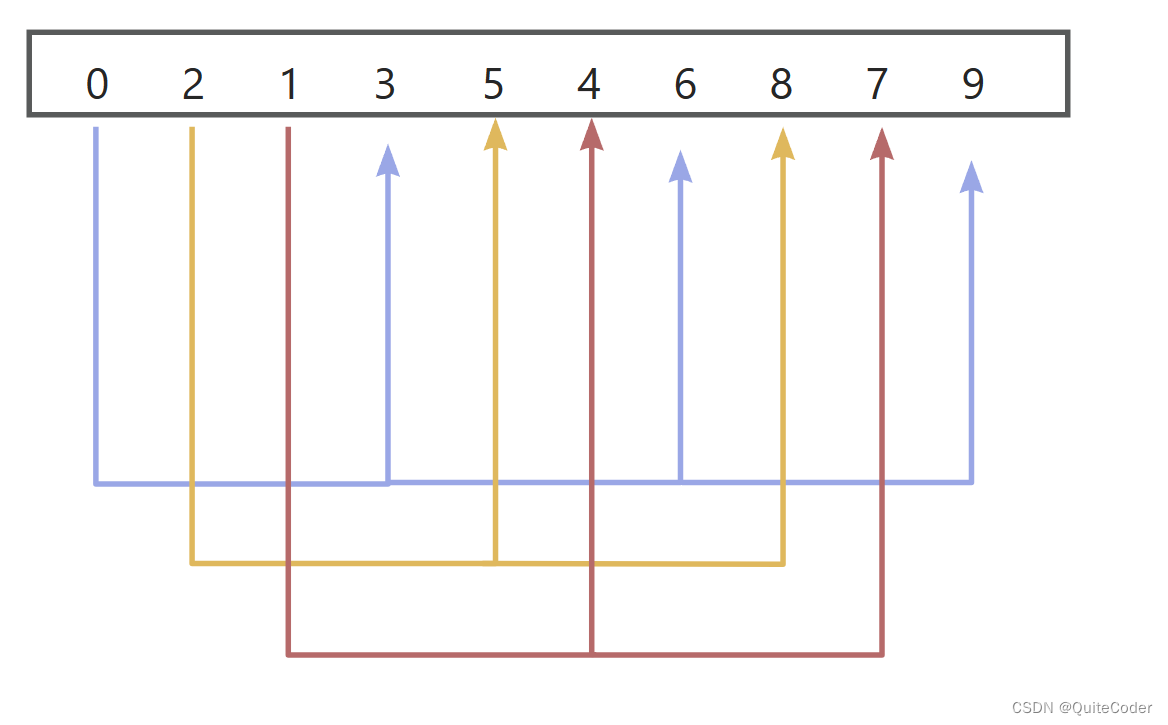
完成了一轮希尔排序,此时整个数组并不完全有序,但是已经比原始的数组更接近有序了。然后减小增量,通常是将原来的增量除以2(如果增量序列选择为原始的版本),现在选择下一个增量为 1(因为 3/2 不为整数,所以直接减到 1,进行最后的常规插入排序)。
现在,整个数组就是一个子序列,进行常规的插入排序。
0 2 1 3 5 4 6 8 7 9 <- 初始
0 2 1 3 5 4 6 8 7 9 <- 第1个元素不动,因为它已经在正确的位置
0 1 2 3 5 4 6 8 7 9 <- 将2和1交换
0 1 2 3 5 4 6 8 7 9 <- 3已经在正确位置
0 1 2 3 5 4 6 8 7 9 <- 第5个元素5不动,因为它左边的元素全部小于5
0 1 2 3 4 5 6 8 7 9 <- 将5和4交换
0 1 2 3 4 5 6 8 7 9 <- 第7个元素6不动,因为它左边的元素全部小于6
0 1 2 3 4 5 6 8 7 9 <- 第8个元素8不动,因为它左边的元素全部小于8
0 1 2 3 4 5 6 7 8 9 <- 将8和7交换
0 1 2 3 4 5 6 7 8 9 <- 第10个元素9不动,因为它左边的元素全部小于9
3.1预排序代码实现
我们现在控制实现单趟排序:
int gap = 3;
int end;
int tmp = a[end + gap];
while (end >= 0)
{if (tmp < a[end]){a[end + gap] = a[end];end-=gap;}elsebreak;
}
a[end + gap] = tmp;
与前面代码不同的是,这里对end所加减的均为gap;
单次插入完成后,我们来控制单个子序列的整个过程,以蓝为例,每实现一次排序,下一次插入的数据为end+gap
int gap = 3;for (int i = 0; i < n-gap; i += gap)
{int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;
}
这里for循环的条件为i<n-gap防止数组越界
完成单个子序列的排序后,我们再对整个子序列排序:
int gap = 3;
for (int j = 0; j < gap; j++)
{for (int i = 0; i < n - gap; i += gap){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;}
}
外层循环(for (int j = 0; j < gap; j++))意在对每个以gap为间隔的分组进行遍历。
- j=0,
这串代码三层循环的逻辑是按照每一组排序完成后再进行下一组排序的,事实上我们可以不需要最外层的循环
代码优化:
int gap = 3;for (int i = 0; i < n - gap; i++)
{int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;
}
这里我们将原先代码中的i += gap修改为i++,意味着这次不是按照一组一组进行了,是一次排序完每个组的第二个元素,再进行下一个元素的排序
3.2希尔排序代码实现
我们先对预排序的增量进行分析:
- gap越大,大的值更快调到后面,小的值更快调到前面,越不接近有序
- gap越小,大的值更慢调到后面,小的值更慢调到前面,越接近有序
当gap为1,就是直接插入排序
所以在实现希尔排序时,给gap固定值是行不通的
因此,gap的值是应该随着n来变化的,实现多次预排
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 2;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;}}
}
这里无论gap是奇数还是偶数,这里gap最终都会除以到值为1
在这里:
- gap>1时是预排序,目的让其接近有序
- gap=1时是直接插入排序,目的让其有序
在gap=1时,已经十分接近有序了
这里gap预排序次数还是有点多,因此我们可以再次进行修改,让gap每次除以3,为了使gap最后能回到1,我们进行加一处理
int gap = n;
while (gap > 1)
{gap = gap / 3+1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;}
}
测试代码
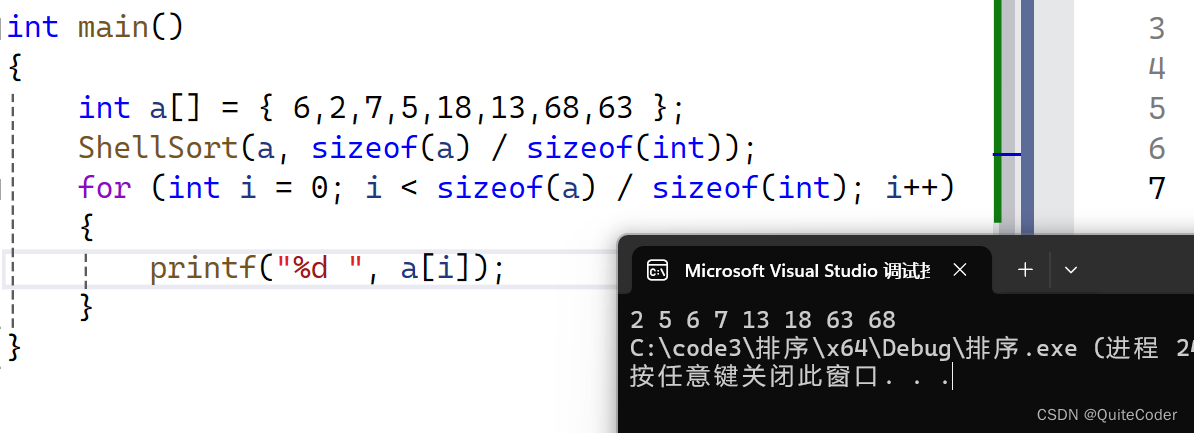
3.3时间复杂度分析
希尔排序的时间复杂度并不固定,它依赖于所选择的间隔序列(增量序列)。直到今天,已经有多种不同的间隔序列被提出来,每种都有自己的性能特点
不同的参考书中给了不同的解释


现代更高效的增量序列可以使希尔排序达到O(N log N)时间复杂度,但是没有任何增量序列可以保证希尔排序在所有情况下都达到O(N log
N)。最低的已知上限为O(N (log N)2)。
总的来说,由于增量序列的不确定性,希尔排序的时间复杂度不容易精确描述,实际的时间复杂度取决于所选用的间隔序列以及待排序数组的初始排列状况。在实际应用中,希尔排序的性能通常介于O(N)和O(N2)之间,对于中等大小的数据集,它可以提供非常不错的速度,尤其是因为它比较简单易于实现,且对于较小的数据集,它一般比O(N
log N)复杂度的算法更快。
4.clock函数
clock() 函数是<time.h>头文件中的一个函数,用来返回程序启动到函数调用时之间的CPU时钟周期数。这个值通常用来帮助衡量程序或程序的某个部分的性能
我们可以用这个函数进一步对比两种排序占用的CPU时间
void TestOP()
{srand(time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);free(a1);free(a2);
}
这里让随机生成十万个随机数,分别用希尔排序和直接插入排序来进行排序,测试两种算法的执行时间:
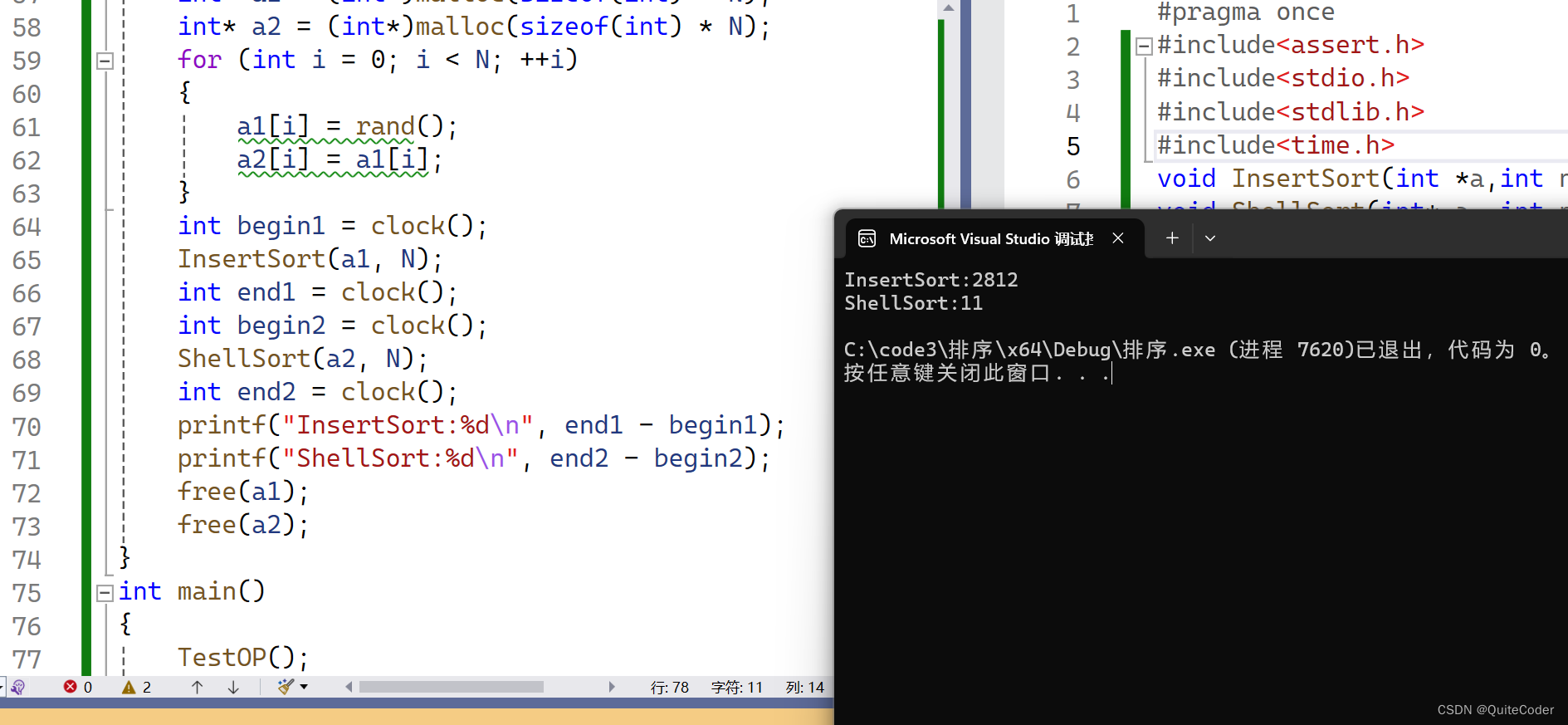
我们可以发现,希尔排序的执行时间相比于直接插入排序很有优势!
总结
希尔排序和直接插入排序都是改进和优化了简单排序算法的典型例子。直接插入排序以其简洁和对于小规模数据集的高效性而著称,特别适合几乎已经排序好的数据。而希尔排序则通过引入“增量”的概念,允许交换距离较远的元素,从而大幅度提高了对大规模数据集的排序效率。两者都在计算机科学的排序算法领域中占有重要地位,不仅展示了算法设计的基本原则,也为更复杂排序算法的发展奠定了基础。
本节内容到此结束,感谢大家的观看!!
相关文章:
【数据结构与算法】:插入排序与希尔排序
🔥个人主页: Quitecoder 🔥专栏: 数据结构与算法 欢迎大家来到初阶数据结构的最后一小节:排序 目录 1.排序的基本概念与分类1.1什么是排序的稳定性?1.2内排序与外排序内排序外排序 2.插入排序2.1实现插入排序2.3稳定性…...

前端性能优化——javascript
优化处理: 讲javascript脚本文件放到body标记的后面 减少页面当中所包含的script标记的数量 课堂练习: 脚本优化处理 使用原生JavaScript完成操作过程。 document.querySelector document.querySelectorAll classList以及类的操作API Element.class…...
Docker容器化技术(使用Docker搭建论坛)
第一步:删除容器镜像文件 [rootlocalhost ~]# docker rm -f docker ps -aq b09ee6438986 e0fe8ebf3ba1第二步:使用docker拉取数据库 [rootlocalhost ~]# docker run -d --name db mysql:5.7 02a4e5bfffdc81cb6403985fe4cd6acb0c5fab0b19edf9f5b8274783…...
C# ListView 控件使用
1.基本设置 listView1.Columns.Add("序号", 60); //向 listView1控件中添加1列 同时设置列名称和宽度listView1.Columns.Add("温度", 100); //下同listView1.Columns.Add("偏移", 100);listView1.Columns.Add("分割", 50);listView1…...
【string一些函数用法的补充】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 string类对象的修改操作 我们来看 c_str 返回c格式的字符串的操作: 我们来看 rfind 和 substr 的操作: string类非成员函数 我们来看 r…...

【Go】令牌桶限流算法
1. 限流 限流,顾名思义,限制用户请求流量,避免大规模并发导致系统宕机。 2. 令牌桶算法 令牌管理员以恒定的速率向令牌桶里放置一个令牌。如果桶满,就丢弃令牌。 请求到达时,都要先去令牌桶里取一个令牌,…...

go的slice学习
并发访问slice 线上出现一粒多协程并发append全局slice的情况,导致内存不断翻倍,因此对slice的使用需要重新考虑。 并发读写的情况下, 可以利用锁、channel等避免竞态 问题 func TestDemo32(t *testing.T) {var wg sync.WaitGroupvar n 1…...

软件设计师17--磁盘管理
软件设计师17--磁盘管理 考点1:存储管理 - 磁盘管理调度算法磁盘调度 - FCFS磁盘调度 - SSTF例题: 考点1:存储管理 - 磁盘管理 存取时间寻道时间等待时间,训导时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇…...

学点Java打小工——Day2Day3一点作业
1 猜数字(10次机会) 随机生成[1,1000]的一个数,输入你猜的数程序会给出反馈,直到猜对或次数用尽(10次)。 //猜数字 10次机会Testpublic void guessNumber() {Random random new Random();// [0, 1000) 1// [1, 1000]int num ra…...

【话题】2024年AI辅助研发趋势,有那些应用领域
大家好,我是全栈小5,欢迎阅读文章! 此篇是【话题达人】系列文章,这一次的话题是《2024年AI辅助研发趋势》 目录 背景概念实践医药领域汽车设计领域展望未来文章推荐 背景 随着人工智能技术的持续发展与突破,2024年AI辅…...

蓝桥杯——数组切分
数组切分 题目分析 这里要搞清楚一个点就是满足区间内数字是连续数字的区间有什么样的特点,既然数字连续重新排列后的数字为n,n1,n2,n3,n4,…nlen,则最大数字和最小数字之差恰好是区间长度减1,即nlen-nlen,同样因为下标也是连续…...

【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler---原理、应用、源码与注意事项
【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler—原理、应用、源码与注意事项 这篇文章的质量分达到了97分,虽然满分是100分,但已经相当接近完美了。请您耐心阅读,我相信您一定能从中获得不少宝贵的收获和启发~ …...

数据库是什么?数据库连接、管理与分析工具推荐
一、数据库是什么? 数据库是一种结构化的数据存储系统,用于有效地组织、存储和管理大量的数据。它是一个集中化的数据存储库,通常由一个或多个数据表组成,每个数据表包含多个行和列,用于存储特定类型的数据。数据表中…...

【C#算法实现】可见的山峰对数量
文章目录 前言一、题目要求二、算法设计及代码实现2.1 算法思想2.2 代码实现 前言 本文是【程序员代码面试指南(第二版)学习笔记】C#版算法实现系列之一,用C#实现了《程序员代码面试指南》(第二版)栈和队列中的可见的…...
Selenium 隐藏浏览器指纹特征的几种方式
文章转载于:https://mp.weixin.qq.com/s/sXRXwMDqekUHfU2SnL-PYg 我们使用 Selenium 对网页进行爬虫时,如果不做任何处理直接进行爬取,会导致很多特征是暴露的 对一些做了反爬的网站,做了特征检测,用来阻止一些恶意爬虫…...

k8s发布nacos-server,nodeport配置注意事项
k8s发布nacos-server注册不上问题 问题描述:分析过程: 问题描述: k8s发布nacos-server做服务公用使用,nodeport暴漏服务给客户端注册, nacos:端口 8848:30601 9848:30701 分析过程:…...
伪分布式Spark集群搭建
一、软件环境 软 件 版 本 安 装 包 VMware虚拟机 16 VMware-workstation-full-16.2.2-19200509.exe SSH连接工具 FinalShell Linux OS CentOS7.5 CentOS-7.5-x86_64-DVD-1804.iso JDK 1.8 jdk-8u161-linux-x64.tar.gz Spark 3.2.1 spark-3.2.1-bin-…...

Android 监听卫星导航系统状态及卫星测量数据变化
源码 package com.android.circlescalebar;import androidx.annotation.NonNull; import androidx.appcompat.app.AppCompatActivity; import androidx.core.app.ActivityCompat; import androidx.core.content.ContextCompat; import android.Manifest; import android.conte…...

鸿蒙培训开发:就业市场的新热点~
金三银四在即,随着春节假期结束,各行各业纷纷复工复产,2024年的春季招聘市场也迎来了火爆的局面。最近发布的《2024年春招市场行情周报(第一期)》显示,尽管整体就业市场仍处于人才饱和状态,但华…...

【C++】string的底层剖析以及模拟实现
一、字符串类的认识 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数, 但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理&a…...

【DeepSeek推理加速实战指南】:20年AI系统优化专家亲授7大低开销部署技巧
更多请点击: https://kaifayun.com 第一章:DeepSeek推理加速的核心挑战与优化全景 DeepSeek系列大模型在实际部署中面临显著的推理延迟与显存压力,尤其在长上下文(如32K tokens)和高并发场景下,GPU利用率常…...

为 Hermes Agent 配置自定义模型供应商指向 Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Hermes Agent 配置自定义模型供应商指向 Taotoken Hermes Agent 是一款功能强大的 AI 智能体开发框架,它支持通过自…...

使用curl命令直接测试Taotoken大模型API连通性与功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接测试Taotoken大模型API连通性与功能 在集成大模型能力时,开发者有时需要在没有安装特定语言SDK的环境…...

企业内统一AI开发环境借助TaotokenCLI工具一键配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一AI开发环境借助Taotoken CLI工具一键配置 在中大型企业的技术团队中,为所有开发者提供统一、标准化的AI服务…...

LayerDivider:3分钟让单张插画变可编辑图层的AI魔法
LayerDivider:3分钟让单张插画变可编辑图层的AI魔法 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你知道吗?现在有超过85%的数字…...

数据不是石油,是稀土:被误读的具身智能数据竞赛
一个被反复引用的判断是——"数据是具身智能时代的石油"。 我想说的恰恰相反:这个比喻,从一开始就错了。 一、五十万小时的困境 先看一组行业账目。 某国内头部具身智能企业,在预计投入的 20 亿元科研创新费用中,仅&q…...

如何用QrazyBox修复损坏的二维码:终极修复工具指南
如何用QrazyBox修复损坏的二维码:终极修复工具指南 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾遇到过打印模糊、水渍污染或屏幕划痕导致的二维码无法扫描?…...

UnityExplorer自由视角相机完整指南:突破游戏视角限制的终极方案
UnityExplorer自由视角相机完整指南:突破游戏视角限制的终极方案 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityEx…...

macOS百度网盘终极加速方案:解锁SVIP高速下载功能
macOS百度网盘终极加速方案:解锁SVIP高速下载功能 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 对于macOS用户而言,百度网盘的…...

科学机器学习入门指南:DeepXDE物理信息学习的完整教程
科学机器学习入门指南:DeepXDE物理信息学习的完整教程 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde 你是否想要用深度学习解决复杂的物理方程&…...