33- PyTorch实现分类和线性回归 (PyTorch系列) (深度学习)
知识要点
-
pytorch最常见的创建模型的方式, 子类
-
读取数据: data = pd.read_csv('./dataset/credit-a.csv', header=None)
-
数据转换为tensor: X = torch.from_numpy(X.values).type(torch.FloatTensor)
-
创建简单模型:
from torch import nn
model = nn.Sequential(nn.Linear(15, 1),nn.Sigmoid())-
定义损失函数: loss_fn = nn.BCELoss()
-
定义优化器: opt = torch.optim.SGD(model.parameters(), lr=0.00001)
-
把梯度清零: opt.zero_grad()
-
反向传播计算梯度: loss.backward()
-
更新梯度: opt.step()
-
-
查看最终参数: model.state_dict()
-
计算准确率: ((model(X).data.numpy() > 0.5).astype('int') == Y.numpy()).mean()
-
独热编码: data = data.join(pd.get_dummies(data.part)).join(pd.get_dummies(data.salary)) # 对每个类别的值都进行0-1编码
-
删除参数: data.drop(columns=['part', 'salary'], inplace=True)
-
函数方式执行训练:
for epoch in range(epochs):for i in range(no_of_batches):start = i*batchend = start + batchx = X[start: end]y = Y[start: end]y_pred = model(x)loss = loss_fn(y_pred, y)opt.zero_grad()loss.backward()opt.step()-
使用dataset, dataloader
HR_ds = TensorDataset(X, Y)
HR_dl = DataLoader(HR_ds, batch_size=batch)-
数据拆分: train_x, test_x, train_y, test_y = train_test_split(X_data, Y_data)
-
常用激活函数:
-
relu
-
sigmoid
-
tanh
-
leak relu
-
-
目标值: Y_data = data.left.values.reshape(-1, 1) # left 离职
-
Y = torch.from_numpy(Y_data).type(torch.FloatTensor)
-
一 逻辑回归
1.1 什么是逻辑回归
线性回归预测的是一个连续值, 逻辑回归给出的”是”和“否”的回答, 逻辑回归通过sigmoid函数把线性回归的结果规范到0到1之间.

sigmoid函数是一个概率分布函数, 给定某个输入,它将输出为一个概率值.
1.2 逻辑回归损失函数
平方差所惩罚的是与损失为同一数量级的情形, 对于分类问题,我们最好的使用交叉熵损失函数会更有效, 交叉熵会输出一个更大的“损失”.
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设概率分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵, 则在pytorch 里,我们使用 nn.BCELoss() 来计算二元交叉熵.
下面我们用一个实际的例子来实现pytorch中的逻辑回归
二 逻辑回归分类实例 (信用卡反欺诈数据 )
2.1 导包
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from torch import nn2.2 数据导入
data = pd.read_csv('./dataset/credit-a.csv', header = None)
data # 前15列是特征 , 最后一列是标记
# 前15列是特征 , 最后一列是标记
X = data.iloc[:, :-1]
# series 不能作为标记
Y = data.iloc[:, -1]
print(X.shape, Y.shape) # (653, 15) (653,)- 取代Y值中的 -1, 调整为0 (方便后面求概率)
# 把标记改为0, 1, 方便后面求概率
Y.replace(-1, 0, inplace = True) # 替换值- 查看数据是否均衡
Y.value_counts() # 数据是否均衡
'''
1 357
0 296
Name: 15, dtype: int64'''- 数据转换为 tensor
X = torch.from_numpy(X.values).type(torch.FloatTensor)
Y = torch.from_numpy(Y.values.reshape(-1, 1)).type(torch.FloatTensor)
print(X.shape) # torch.Size([653, 15])2.3 定义模型
from torch import nn
# 回归和分类之间, 区别不大, 回归后面加上一层sigmoid, 就变成分类了.
model = nn.Sequential(nn.Linear(15, 1024),nn.Linear(1024, 1),nn.Sigmoid())
2.4 梯度下降
# BCE binary cross entroy 二分类的交叉熵损失
loss_fn = nn.BCELoss()
opt = torch.optim.SGD(model.parameters(), lr = 0.0001)batch_size = 32
steps = 653 // 32for epoch in range(1000):# 每次取32个数据for batch in range(steps):# 起始索引start = batch * batch_size# 结束索引end = start + batch_size# 取数据x = X[start: end]y = Y[start: end]y_pred = model(x)loss = loss_fn(y_pred, y)# 梯度清零opt.zero_grad()# 反向传播loss.backward()# 更新opt.step()model.state_dict()
# 计算正确率 # 设定阈值
# 现在预测得到概率, 根据阈值, 把概率转换为类别, 然后计算准确率
((model(X).data.numpy() > 0.5) == Y.numpy()).mean() # 0.5834609494640123三 面向对象的方式实现逻辑回归分类 (预测员工离职数据 )
3.1 导包
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt3.2 导入数据
data = pd.read_csv('./dataset/HR.csv')
data.head(10)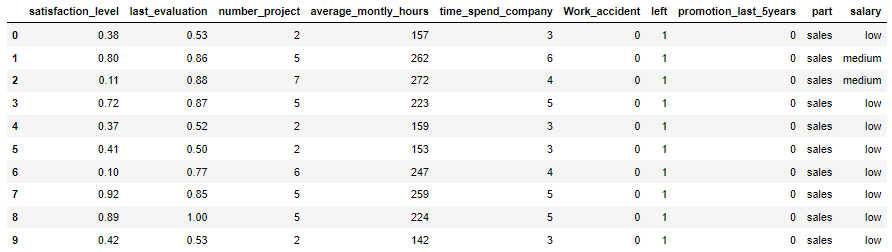
data.info()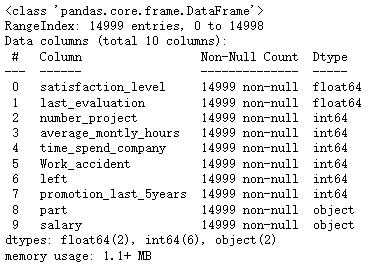
data.part.unique()
'''array(['sales', 'accounting', 'hr', 'technical', 'support', 'management','IT', 'product_mng', 'marketing', 'RandD'], dtype=object)'''3.3 数据处理
- 对于离散的字符串, 有两种处理方式: 1. 转换为数字 2. 进行one-hot编码.
- 把 part 和 salary 中的每一项单独列出来, 如果有就转换为1, 没有就转换为 0.
# 对于离散的字符串, 有两种处理方式: 1. 转换为数字 2. 进行one-hot编码.
data = data.join(pd.get_dummies(data.part)).join(pd.get_dummies(data.salary))
data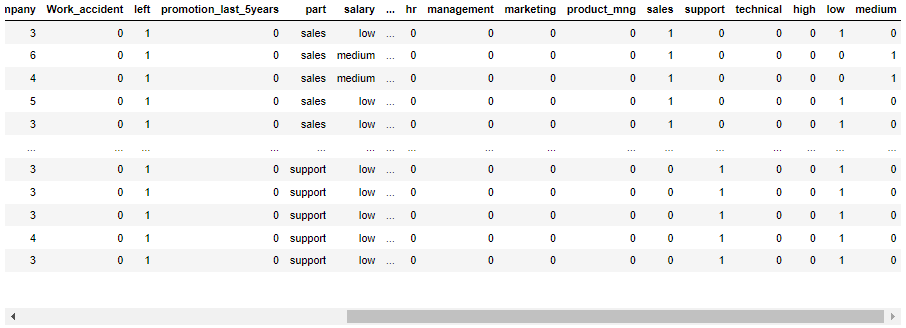
- 把 part 和 salary 删掉
# 把part和salary删掉
data.drop(columns = ['part', 'salary'], inplace = True)- 查看数据是否均衡
data.left.value_counts()
'''
0 11428
1 3571
Name: left, dtype: int64'''- 查看Y值
# SMOTE
Y_data = data.left.values.reshape(-1, 1)
Y = torch.from_numpy(Y_data).type(torch.FloatTensor)
Y 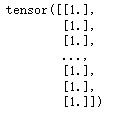
[c for c in data.columns if c != 'left']
X_data = data[[c for c in data.columns if c != 'left']].values
X = torch.from_numpy(X_data).type(torch.FloatTensor)
X.shape # torch.Size([14999, 20])3.4 通过class 定义模型 (pytorch 最常见的创建模型的方式, 子类)
# pytorch 最常见的创建模型的方式, 子类
from torch import nn
# 需要自定义类
class HRModel(nn.Module):def __init__(self):# 先调用父类的方法super().__init__()# 定义网络中会用到的东西.self.lin_1 = nn.Linear(20, 64)self.lin_2 = nn.Linear(64, 64)self.lin_3 = nn.Linear(64, 1)self.activate = nn.ReLU()self.sigmoid = nn.Sigmoid()def forward(self, input): # forward 前向传播# 定义前向传播x = self.lin_1(input)x = self.activate(x)x = self.lin_2(x)x = self.activate(x)x = self.lin_3(x)x = self.sigmoid(x)return xlr = 0.0001
# 定义获取函数, 优化器
def get_model():model = HRModel()return model, torch.optim.Adam(model.parameters(), lr=lr)# 定义损失, 定义优化过程
loss_fn = nn.BCELoss()
model, opt = get_model()batch_size = 64
steps = len(data) // batch_size
epochs = 100
# 训练过程
for epoch in range(epochs):for i in range(steps):start = i * batch_sizeend = start + batch_sizex = X[start: end]y = Y[start: end]y_pred = model(x)loss = loss_fn(y_pred, y)opt.zero_grad()loss.backward()opt.step()
print('epoch:', epoch, '-------', 'loss:', loss_fn(model(X), Y))
'''epoch: 99 ------- loss: tensor(0.5532, grad_fn=<BinaryCrossEntropyBackward0>)'''
model
- 查看参数
model.state_dict()
- 查看准确率
# 计算准确率 # 设定阈值
# 现在预测得到的是概率, 我们根据阈值, 把概率转换为类别, 就可以计算准确率
((model(X).data.numpy() > 0.5) == Y.numpy()).mean() # 0.7619174611640777四 dataset 数据重构
4.1 使用dataset进行重构
PyTorch有一个抽象的 Dataset 类。Dataset可以是任何具有 len 函数和 getitem__ 作为对其进行索引的方法的函数。 本教程将通过示例将自定义HRDataset类创建为的Dataset的子类。
PyTorch的TensorDataset 是一个包装张量的Dataset。通过定义索引的长度和方式,这也为我们提供了沿张量的第一维进行迭代,索引和切片的方法。这将使我们在训练的同一行中更容易访问自变量和因变量。
from torch.utils.data import TensorDatasetHRdataset = TensorDataset(X, Y)
model, opt = get_model()
epochs = 100
batch = 64
no_of_batches = len(data)//batch
for epoch in range(epochs):for i in range(no_of_batches):x, y = HRdataset[i * batch: i * batch + batch]y_pred = model(x)loss = loss_fn(y_pred, y)opt.zero_grad()loss.backward()opt.step()
print('epoch:', epoch, ' ', 'loss:', loss_fn(model(X), Y))
'''epoch: 99 loss: tensor(0.5202, grad_fn=<BinaryCrossEntropyBackward0>)'''4.2 使用DataLoader进行重构
Pytorch DataLoader 负责管理批次。
DataLoader从Dataset创建。
DataLoader使遍历批次变得更容易。DataLoader会自动为我们提供每个小批量。
无需使用 HRdataset[i * batch: i * batch + batch]
# dataloader可以自动分批取数据 # dataloader可以有dataset创建出来
# 有了dataloader就不需要按切片取数据
from torch.utils.data import DataLoader
HR_ds = TensorDataset(X, Y)
HR_dl = DataLoader(HR_ds, batch_size=batch)
# 现在,我们的循环更加简洁了,因为(xb,yb)是从数据加载器自动加载的:
for x,y in HR_dl:pred = model(x)model, opt = get_model()
for epoch in range(epochs):for x, y in HR_dl:y_pred = model(x)loss = loss_fn(y_pred, y)opt.zero_grad()loss.backward()opt.step()
print('epoch:', epoch, ' ', 'loss:', loss_fn(model(X), Y))
'''epoch: 99 loss: tensor(0.5310, grad_fn=<BinaryCrossEntropyBackward0>)'''五 添加验证
5.1 添加验证集
前面我们只是试图建立一个合理的训练循环以用于我们的训练数据。实际上,您始终还应该具有一个验证集,以识别您是否过度拟合。
训练数据的乱序(shuffle)对于防止批次与过度拟合之间的相关性很重要。另一方面,无论我们是否乱序验证集,验证损失都是相同的。由于shufle需要额外的开销,因此shuffle验证数据没有任何意义。我们将为验证集使用批大小,该批大小是训练集的两倍。这是因为验证集不需要反向传播,因此占用的内存更少(不需要存储梯度)。我们利用这一优势来使用更大的批量,并更快地计算损失。
# 需要分割成训练数据和测试数据
# 刚才是把所有数据作为训练数据
from sklearn.model_selection import train_test_splittrain_x, test_x, train_y, test_y = train_test_split(X_data, Y_data)
train_x = torch.from_numpy(train_x).type(torch.FloatTensor)
test_x = torch.from_numpy(test_x).type(torch.FloatTensor)
train_y = torch.from_numpy(train_y).type(torch.FloatTensor)
test_y = torch.from_numpy(test_y).type(torch.FloatTensor)train_ds = TensorDataset(train_x, train_y)
train_dl = DataLoader(train_ds, batch_size=batch, shuffle=True)valid_ds = TensorDataset(test_x, test_y)
valid_dl = DataLoader(valid_ds, batch_size=batch * 2)5.2 定义计算正确率函数
def accuracy(out, yb):preds = (out>0.5).type(torch.IntTensor)return (preds == yb).float().mean()5.3 创建fit和get_data
- 按批次计算损失
# 按批次计算损失
def loss_batch(model, loss_func, xb, yb, opt=None):loss = loss_func(model(xb), yb)if opt is not None:loss.backward()opt.step()opt.zero_grad()return loss.item(), len(xb)- 封装训练过程
# 封装训练过程
def fit(epochs, model, loss_func, opt, train_dl, valid_dl):for epoch in range(epochs):model.train()for xb, yb in train_dl:loss_batch(model, loss_func, xb, yb, opt)model.eval()with torch.no_grad(): # * 进行解包losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl])val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)print(epoch, val_loss)- 封装定义数据
def get_data(train_ds, valid_ds, bs):return (DataLoader(train_ds, batch_size=bs, shuffle=True),DataLoader(valid_ds, batch_size=bs * 2))- 整个训练校验过程可以直接使用三行代码
# 整个训练校验过程可以直接使用三行代码 # 获取数据
train_dl, valid_dl = get_data(train_ds, valid_ds, batch)
model, opt = get_model()
fit(epochs, model, loss_fn, opt, train_dl, valid_dl)
六 多层感知机
6.1简介
上一节我们学习的逻辑回归模型是单个神经元: 计算输入特征的加权和 然后使用一个激活函数(或传递函数)计算输出.
单个神经元(二分类):
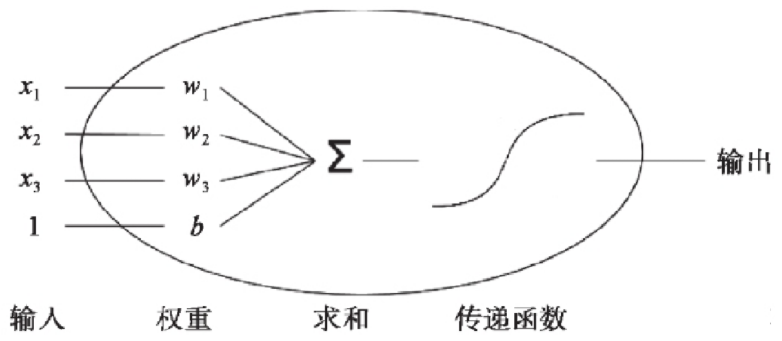
多个神经元(多分类):
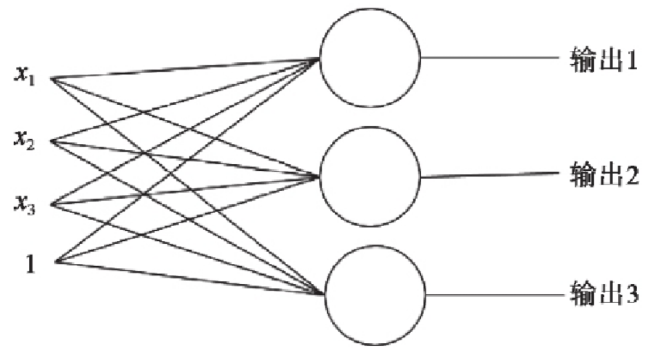
单层神经元的缺陷: 无法拟合“异或”运算 异或 问题看似简单,使用单层的神经元确实没有办法解决.神经元要求数据必须是线性可分的, 异或 问题无法找到一条直线分割两个类, 这个问题是的神经网络的发展停滞了很多年.
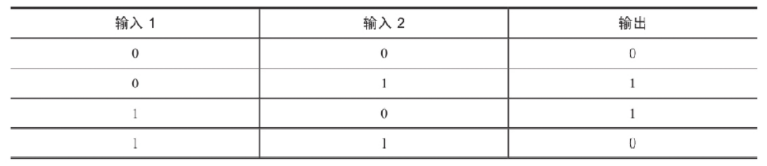
多层感知器: 生物的神经元一层一层连接起来,当神经信号达到某一个条件,这个神经元就会激活, 然后继续传递信息下去 为了继续使用神经网络解决这种不具备线性可分性的问题, 采取在神经网络的输入端和输出端之间插入更多的神经元.
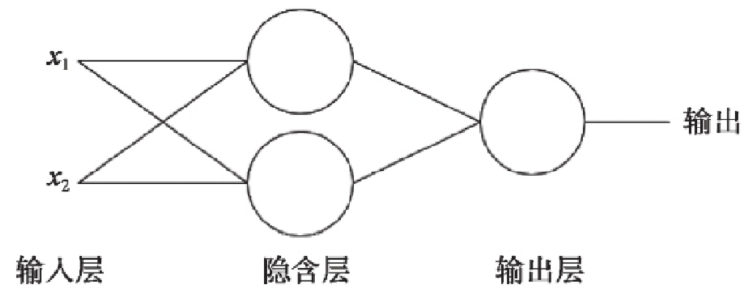
6.2 激活函数
relu:
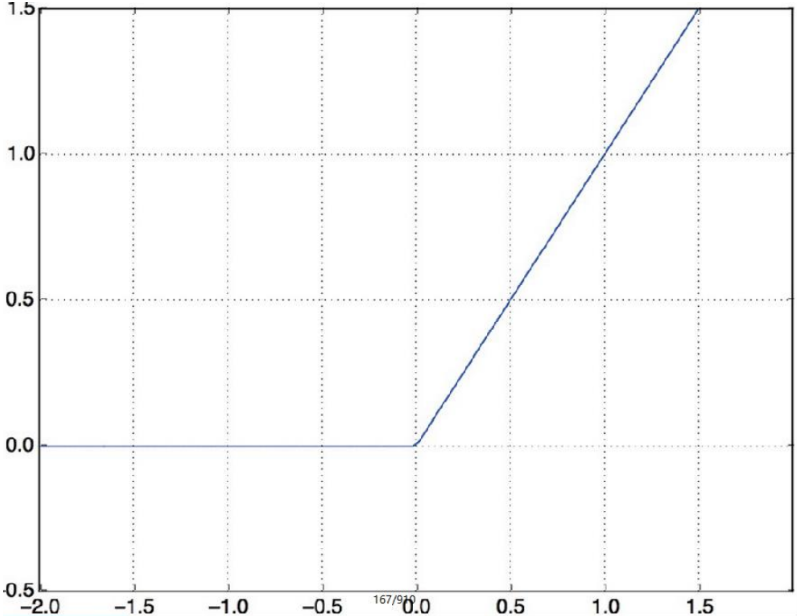
sigmoid:
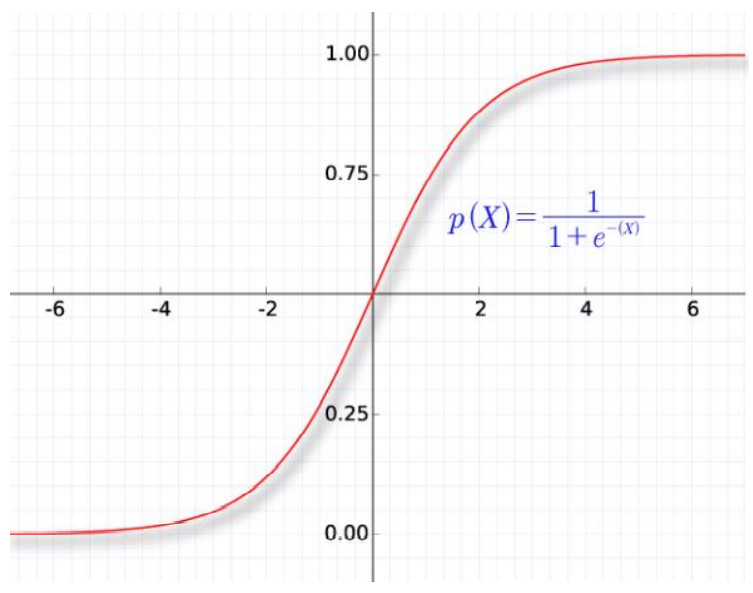
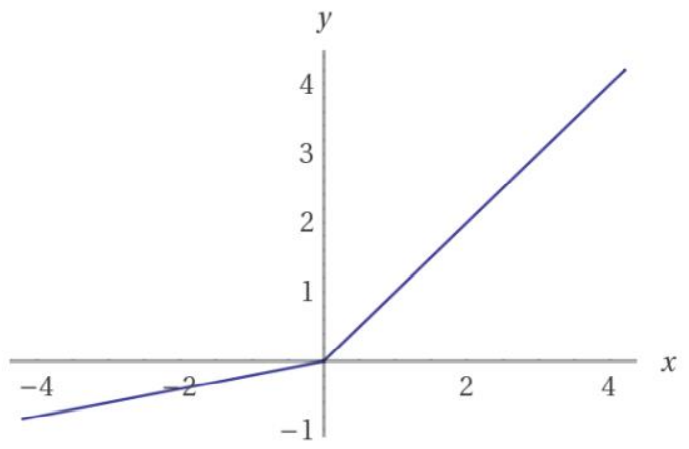
tanh:

leak relu:
6.3 我们依然使用hr数据集创建多层感知机来做分类
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from torch import nndata = pd.read_csv('dataset/HR.csv')
data = data.join(pd.get_dummies(data.salary))
del data['salary']
data = data.join(pd.get_dummies(data.part))
del data['part']Y_data = data.left.values.reshape(-1, 1)
Y = torch.from_numpy(Y_data).type(torch.FloatTensor)
X_data = data[[c for c in data.columns if c !='left']].values
X = torch.from_numpy(X_data).type(torch.FloatTensor)# 自定义模型:
# nn.Module: 继承这个类
# __init__: 初始化所有的层
# forward: 定义模型的运算过程(前向传播的过程)
class Model(nn.Module):def __init__(self):super().__init__()self.liner_1 = nn.Linear(20, 64)self.liner_2 = nn.Linear(64, 64)self.liner_3 = nn.Linear(64, 1)self.relu = nn.ReLU()self.sigmoid = nn.Sigmoid()def forward(self, input):x = self.liner_1(input)x = self.relu(x)x = self.liner_2(x)x = self.relu(x)x = self.liner_3(x)x = self.sigmoid(x)return x6.4 借助F对象改写模型, 让模型更简洁
import torch.nn.functional as F
class Model(nn.Module):def __init__(self):super().__init__()self.liner_1 = nn.Linear(20, 64)self.liner_2 = nn.Linear(64, 64)self.liner_3 = nn.Linear(64, 1)def forward(self, input):x = F.relu(self.liner_1(input))x = F.relu(self.liner_2(x))x = F.sigmoid(self.liner_3(x))return x七 线性回归实例 (收入和受教育年限的关系)
7.1 导包
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt7.2 数据导入
data = pd.read_csv('./dataset/Income1.csv')
data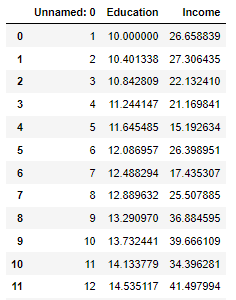
- 查看受教育年限和收入的关系
plt.scatter(data.Education, data.Income)
plt.xlabel('Education')
plt.ylabel('Incomel')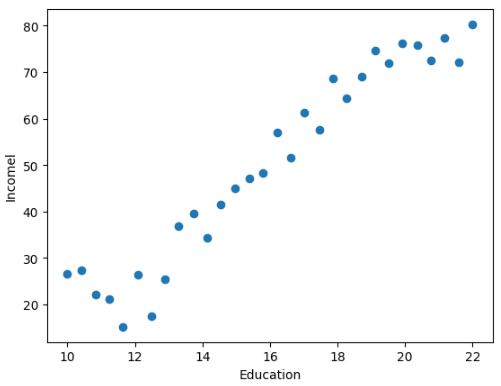
- 转换数据为 tensor
# 取数据
X = torch.from_numpy(data.Education.values.reshape(-1, 1)).type(torch.FloatTensor)
Y = torch.from_numpy(data.Income.values.reshape(-1, 1)).type(torch.FloatTensor)7.3 定义梯度下降过程
- 定义斜率w, 截距b
# 分解写法
w = torch.randn(1, requires_grad = True) # tensor([-0.5106], requires_grad=True)
b = torch.zeros(1, requires_grad = True) # tensor([0.], requires_grad=True)- 梯度下降
learning_rate = 0.001
# 定义训练过程
for epoch in range(5000):for x, y in zip(X, Y):y_pred = torch.matmul(x, w) + b# 损失函数loss = (y - y_pred).pow(2).sum() # x.pow() 求原始值的n次方# pytorch对一个变量多次求导, 求导结果会累加if w.grad is not None: # w.grad 求导 grad: 梯度# 重置w 的导数w.grad.data.zero_() # zero_ 加下划线直接更改原数据if b.grad is not None:b.grad.data.zero_()# 反向传播, 即求w, b的导数loss.backward()# 更新w, bwith torch.no_grad():w.data -= w.grad.data * learning_rateb.data -= b.grad.data * learning_rateprint('w*', w) # w* tensor([5.1266], requires_grad=True)
print('b*', b) # b* tensor([-32.6957], requires_grad=True)- 图像直观显示
plt.scatter(data.Education, data.Income)
plt.plot(X.numpy(), (torch.matmul(X, w) + b).data.numpy(), c = 'red')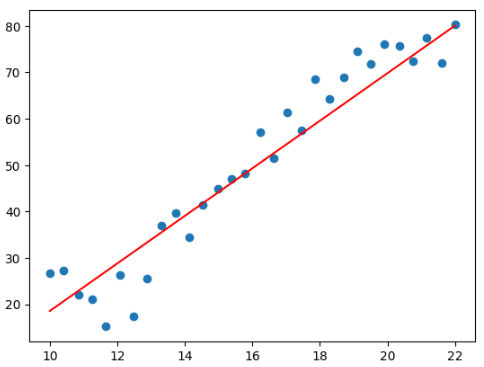
相关文章:
33- PyTorch实现分类和线性回归 (PyTorch系列) (深度学习)
知识要点 pytorch最常见的创建模型的方式, 子类 读取数据: data pd.read_csv(./dataset/credit-a.csv, headerNone) 数据转换为tensor: X torch.from_numpy(X.values).type(torch.FloatTensor) 创建简单模型: from torch import nn model nn.Sequential(nn.Linear(15, 1…...
C++基础——Ubuntu下编写C++环境配置总结(C++基本简介、Ubuntu环境配置、编写简单C++例程)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《QT开发实战》 《嵌入式通用开发实战》 《从0到1学习嵌入式Linux开发》 《Android开发实战》 《实用硬件方案设计》 长期持续带来更多案例与技术文章分享…...

项目管理中,导致进度失控的五种错误
项目管理中对工期的控制主要是进度控制,在项目进行中中,由于项目时间跨度长,人员繁杂,如果管理不规范,就容易导致项目进度滞后,如何管理好施工进度是管理者需要解决的问题之一。 1、项目计划缺乏执行力 安…...

C# 中的abstract和virtual
重新理解了下关键字abstract,做出以下总结: 1.标记为abstract的类不能实例化,但是依然可以有构造函数,也可以重载构造函数,在子类中调用 2.abstract类中可以有abstract标记的方法和属性,也可以没有,被标记…...

第六十周总结——React数据管理
React数据管理 代码仓库 React批量更新 React中的批量更新就是将多次更新合并处理,最终只渲染一次,来获得更好的性能。 React18版本之前的批量更新 // react 17 react-dom 17 react-scripts 4.0.3 import * as ReactDOM from "react-dom"…...

Springboot之@Async异步指定自定义线程池使用
开发中会碰到一些耗时较长或者不需要立即得到执行结果的逻辑,比如消息推送、商品同步等都可以使用异步方法,这时我们可以用到Async。但是直接使用 Async 会有风险,当我们没有指定线程池时,他会默认使用其Spring自带的 SimpleAsync…...
- TS格式详解指南)
视频知识点(23)- TS格式详解指南
*《音视频开发》系列-总览*(点我) 一、格式简介 TS视频封装格式,是一种被广泛应用的多媒体文件格式。它的全称是MPEG2-TS,其中TS是“Transport Stream”的缩写。TS(Transport Stream)流是一种传输流,它由固定长度(188 字节)的 TS 包组成,TS 包是对PES包的一种封装方式…...
linux篇【16】:传输层协议<后序>
目录 六.滑动窗口 (1)发送缓冲区结构 (2)滑动窗口介绍 (3)滑动窗口不一定只会向右移动。滑动窗口可以变大也可以变小。 (4)那么如果出现了丢包, 如何进行重传? 这里分两种情况…...
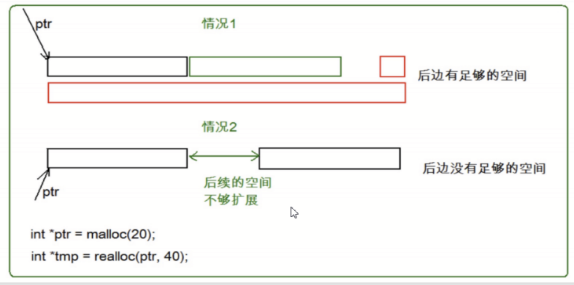
【C语言】动态内存管理
一.为什么存在动态内存分配? 我们已经掌握的内存开辟方式有:int val 20;//在栈空间上开辟四个字节 char arr[10] {0};//在栈空间上开辟10个字节的连续空间 但是上述的开辟空间的方式有两个特点: 1. 空间开辟大小是固定的。 2. 数组在申明的…...
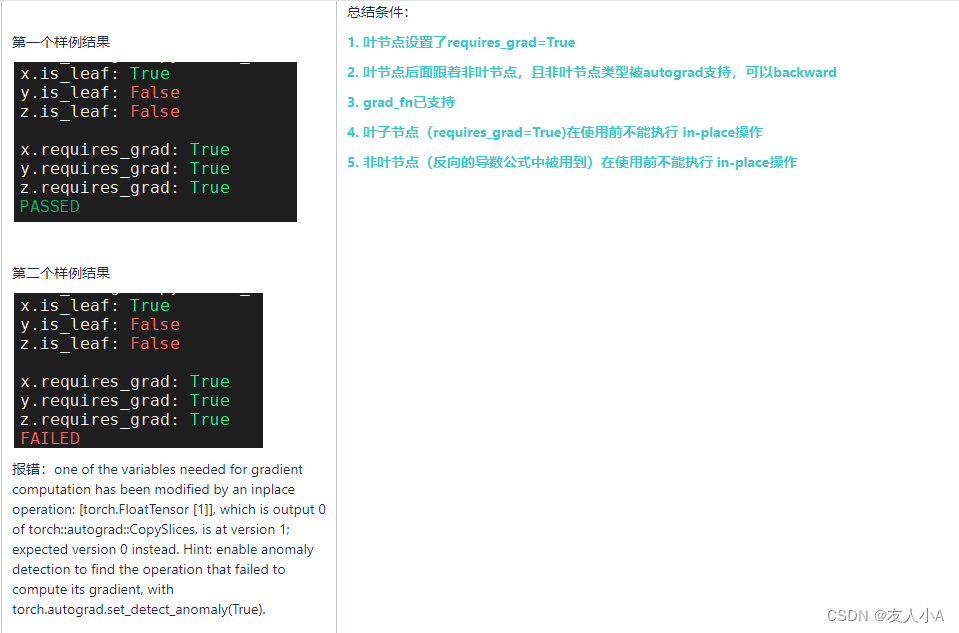
【Pytorch】AutoGrad个人理解
前提知识:[Pytorch] 前向传播和反向传播示例_友人小A的博客-CSDN博客 目录 简介 叶子节点 Tensor AutoGrad Functions 简介 torch.autograd是PyTorch的自动微分引擎(自动求导),为神经网络训练提供动力。torch.autograd需要对…...

华硕z790让独显和集显同时工作
系统用了一段时间,现在想让显卡主要做深度学习训练,集显用来连接显示器。却发现显示器接到集显接口无信号。 打售后客服也没有解决,现在把解决方案记录一下。 这是客服给的方案: 请开机后进BIOS---Advanced---System Agent (SA)…...

提高编程思维的python代码
1.通过函数取差。举例:返回有差别的列表元素 from math import floordef difference_by(a,b,fn):b set(map(fn, b))return [i for i in a if fn(i) not in b] print(difference_by([2.1, 1.2], [2.3, 3.4], floor))2.一行代码调用多个函数 def add(a, b):return …...

CSS背景background属性整理
1.background-color background-color属性:设置元素的背景颜色 2.background-position background-position属性:设置背景图像的起始位置,需要把 background-attachment 属性设置为 "fixed",才能保证该属性在 Firefo…...
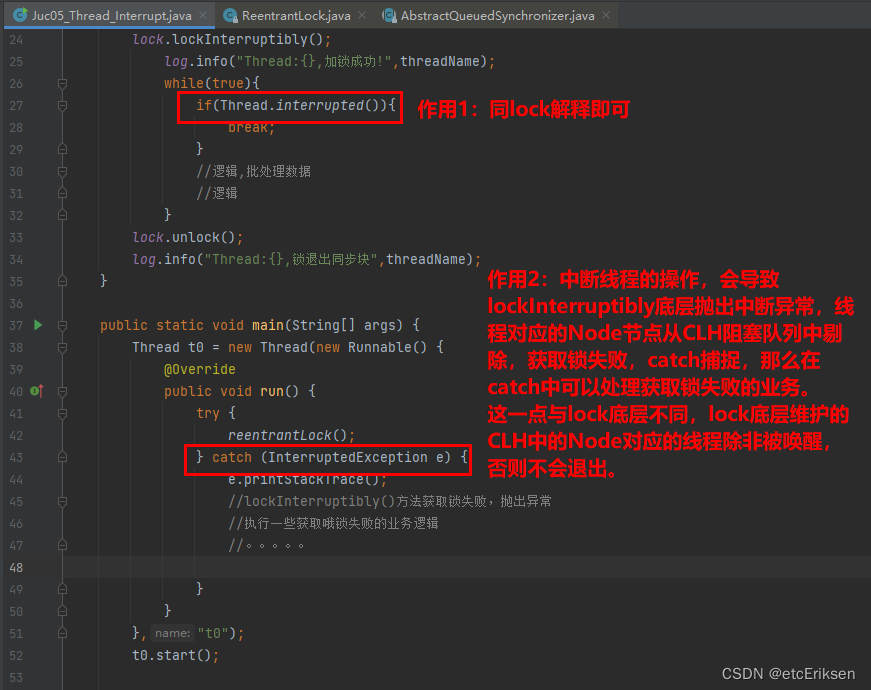
AQS底层源码深度剖析-Lock锁
目录 AQS底层源码深度剖析-Lock锁 ReentrantLock底层原理 为什么把获取锁失败的线程加入到阻塞队列中,而不是采取其它方法? 总结:三大核心原理 CAS是啥? 代码模拟一个CAS: 公平锁与非公平锁 可重入锁的应用场景&…...
网络编程(二)
6. TCP 三次握手四次挥手 HTTP 协议是 Hype Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器(sever)传输超文本到客户端(本地浏览器…...

访问学者进入美国哪些东西不能带?
随着疫情的稳定,各国签证的逐步放开,成功申请到国外访问学者、博士后如何顺利的进入国外,哪些东西不能带,下面就随知识人网小编一起看一看。一、畜禽肉类(Meats, Livestock and Poultry)不论是新鲜的、干燥的、罐头的、真空包装的…...

灵巧手抓持<分类><仿真>
获取灵巧手抓取物体时的抓持类型,需要考虑:手本身的结构、被抓取物体的形状尺寸、抓持操作任务的条件。 研究方法:基于模型的方法、基于数据驱动的方法 基于模型的方法:建立灵巧手抓持相关的运动学和动力学模型建立目标函数求解…...

CENTO OS上的网络安全工具(十九)ClickHouse集群部署
一、VMware上集群部署ClickHouse (一)网络设置 1. 通过修改文件设置网络参数 (1)CentOS 在CENTOS上的网络安全工具(十六)容器特色的Linux操作_lhyzws的博客-CSDN博客中我们提到过可以使用更改配置文件的方式…...
tesseract -图像识别
下载链接:https://digi.bib.uni-mannheim.de/tesseract/如下选择最新的版本,这里我选择tesseract-ocr-w64-setup-5.3.0.20221222.exe有如下python模块操作tesseractpyocr 国内源:pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ py…...

JavaScript Math 算数对象
文章目录JavaScript Math 算数对象Math 对象Math 对象属性Math 对象方法算数值算数方法JavaScript Math 算数对象 Math(算数)对象的作用是:执行常见的算数任务。 Math 对象 Math(算数)对象的作用是:执行普…...

AI技能工程框架解析:从模块化设计到智能体构建实战
1. 项目概述:一个面向技能复现与创造的AI工具集最近在GitHub上看到一个挺有意思的项目,叫“skill-creator-pro”。光看这个名字,你可能会有点摸不着头脑,这到底是做什么的?是教人学技能的,还是生成技能的&a…...

基于知识图谱与NLP技术的小说文本结构化分析实战
1. 项目概述:当小说遇见知识图谱 如果你和我一样,既是个技术爱好者,又是个小说迷,那你肯定有过这样的体验:读完一本情节复杂、人物关系盘根错节的小说后,合上书页,脑子里却一团乱麻。谁是谁的盟…...

开源项目质量门禁实践:从代码规范到安全扫描的自动化检查
1. 项目概述:一个开源项目的“守门人”最近在整理自己的开源项目时,我一直在思考一个问题:如何确保项目仓库的“健康度”?这里的健康度,不仅仅是指代码没有Bug,更是指整个项目的协作流程、代码质量、依赖安…...

Page Assist终极指南:5分钟为浏览器安装本地AI助手,彻底告别云端依赖
Page Assist终极指南:5分钟为浏览器安装本地AI助手,彻底告别云端依赖 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist 想要…...

ReID跨镜需人工复核,镜像视界无感定位实现全自动全链路闭环
ReID跨镜需人工复核,镜像视界无感定位实现全自动全链路闭环在全域视频感知与人员动态管控行业应用落地进程中,传统依托ReID行人重识别搭建的跨镜追踪体系,长期深陷算法识别偏差大、数据容错率低、最终必须依赖人工二次复核的运营困局…...

开源数字资产管理平台OpenClaw Studio:架构设计与工程实践
1. 项目概述:一个面向创意工作者的开源数字资产管理工具最近在和一些独立开发者、小型创意团队的朋友聊天时,大家普遍提到一个痛点:项目文件、素材、版本管理越来越乱。设计稿、代码、文档、参考图散落在电脑各个角落,团队协作时经…...

代码审查时最该关注的不是语法,而是这五个“坏味道”
“这段代码能跑,但总觉得哪里不对劲。”如果你在审查代码时有过这种感觉,说明你已经嗅到了代码的坏味道。作为软件测试从业者,我们往往比开发人员更早感受到坏味道带来的痛苦——一个看似简单的变更导致回归测试大面积失败,一个边…...

Polymarket预测市场模拟交易工具:零风险学习链上金融衍生品
1. 项目概述与核心价值最近在研究链上预测市场,发现一个挺有意思的开源项目:jchimbor/polymarket-paper-trader。简单来说,这是一个针对Polymarket预测市场的“模拟交易”或“纸面交易”工具。Polymarket本身是一个基于Polygon链的去中心化预…...

开源、有文档、能上线的 .NET + Vue 通用权限系统
前言在日常项目开发中,权限管理几乎是每个系统都绕不开的基础模块。从用户登录、菜单控制到数据隔离,一套稳定、灵活、可扩展的权限体系,往往决定了整个项目的成败。然而,从零开始搭建这样的平台,不仅耗时耗力…...

Redis向量搜索实战:基于redis-vl-python构建高性能语义检索系统
1. 项目概述:当Redis遇上向量搜索如果你最近在关注数据库和AI应用开发,大概率会听到“向量数据库”这个词。传统的Redis,那个我们用来做缓存、消息队列、排行榜的“瑞士军刀”,现在也开始拥抱这个新潮流了。redis/redis-vl-python…...