Elastic Stack--10--QueryBuilders UpdateQuery
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- QueryBuilders
- ESUtil
QueryBuilders
package com.elasticsearch;
import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.index.query.IndicesQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
/*** Created by lw on 14-7-15.* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* elasticsearch以提供了一个完整的Java查询dsl其余查询dsl。* QueryBuilders工厂构建* API:* <a>http://www.elasticsearch.org/guide/en/elasticsearch/client/java-api/current/query-dsl-queries.html</a>* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
public class Es_QueryBuilders_DSL {/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* match query 单个匹配* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/protected static QueryBuilder matchQuery() {return QueryBuilders.matchQuery("name", "葫芦4032娃");}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* multimatch query* 创建一个匹配查询的布尔型提供字段名称和文本。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder multiMatchQuery() {//现住址和家乡在【山西省太原市7429街道】的人return QueryBuilders.multiMatchQuery("山西省太原市7429街道", // Text you are looking for"home", "now_home" // Fields you query on);
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* boolean query and 条件组合查询* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder booleanQuery() {return QueryBuilders.boolQuery().must(QueryBuilders.termQuery("name", "葫芦3033娃")).must(QueryBuilders.termQuery("home", "山西省太原市7967街道")).mustNot(QueryBuilders.termQuery("isRealMen", false)).should(QueryBuilders.termQuery("now_home", "山西省太原市"));
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* ids query* 构造一个只会匹配的特定数据 id 的查询。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder idsQuery() {return QueryBuilders.idsQuery().ids("CHszwWRURyK08j01p0Mmug", "ojGrYKMEQCCPvh75lHJm3A");
}/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* constant score query* 另一个查询和查询,包裹查询只返回一个常数分数等于提高每个文档的查询。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder constantScoreQuery() {/*return // Using with FiltersQueryBuilders.constantScoreQuery(FilterBuilders.termFilter("name", "kimchy")).boost(2.0f);*/// With Queriesreturn QueryBuilders.constantScoreQuery(QueryBuilders.termQuery("name", "葫芦3033娃")).boost(2.0f);
}/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* disjunction max query* 一个生成的子查询文件产生的联合查询,* 而且每个分数的文件具有最高得分文件的任何子查询产生的,* 再加上打破平手的增加任何额外的匹配的子查询。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder disMaxQuery() {return QueryBuilders.disMaxQuery().add(QueryBuilders.termQuery("name", "kimchy")) // Your queries.add(QueryBuilders.termQuery("name", "elasticsearch")) // Your queries.boost(1.2f).tieBreaker(0.7f);
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* fuzzy query* 使用模糊查询匹配文档查询。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder fuzzyQuery() {return QueryBuilders.fuzzyQuery("name", "葫芦3582");
}/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* has child / has parent* 父或者子的文档查询* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder hasChildQuery() {return // Has ChildQueryBuilders.hasChildQuery("blog_tag",QueryBuilders.termQuery("tag", "something"));// Has Parent/*return QueryBuilders.hasParentQuery("blog",QueryBuilders.termQuery("tag","something"));*/
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* matchall query* 查询匹配所有文件。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder matchAllQuery() {return QueryBuilders.matchAllQuery();
}/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* more like this (field) query (mlt and mlt_field)* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder moreLikeThisQuery() {// mlt QueryQueryBuilders.moreLikeThisQuery("home", "now_home") // Fields.likeText("山西省太原市7429街道") // Text.minTermFreq(1) // Ignore Threshold.maxQueryTerms(12); // Max num of Terms// in generated queries// mlt_field Queryreturn QueryBuilders.moreLikeThisFieldQuery("home") // Only on single field.likeText("山西省太原市7429街道").minTermFreq(1).maxQueryTerms(12);
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* prefix query* 包含与查询相匹配的文档指定的前缀。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder prefixQuery() {return QueryBuilders.prefixQuery("name", "葫芦31");
}/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* querystring query* 查询解析查询字符串,并运行它。有两种模式,这种经营。* 第一,当没有添加字段(使用{ @link QueryStringQueryBuilder #字段(String)},将运行查询一次,非字段前缀* 将使用{ @link QueryStringQueryBuilder # defaultField(字符串)}。* 第二,当一个或多个字段* (使用{ @link QueryStringQueryBuilder #字段(字符串)}),将运行提供的解析查询字段,并结合* 他们使用DisMax或者一个普通的布尔查询(参见{ @link QueryStringQueryBuilder # useDisMax(布尔)})。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder queryString() {return QueryBuilders.queryString("+kimchy -elasticsearch");
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* range query* 查询相匹配的文档在一个范围。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder rangeQuery() {return QueryBuilders.rangeQuery("name").from("葫芦1000娃").to("葫芦3000娃").includeLower(true) //包括下界.includeUpper(false); //包括上界
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* span queries (first, near, not, or, term)* 跨度查询* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder spanQueries() {// Span FirstQueryBuilders.spanFirstQuery(QueryBuilders.spanTermQuery("name", "葫芦580娃"), // Query// Max查询范围的结束位置);// Span Near TODO NotSolvedQueryBuilders.spanNearQuery().clause(QueryBuilders.spanTermQuery("name", "葫芦580娃")) // Span Term Queries.clause(QueryBuilders.spanTermQuery("name", "葫芦3812娃")).clause(QueryBuilders.spanTermQuery("name", "葫芦7139娃")).slop(30000) // Slop factor.inOrder(false).collectPayloads(false);// Span Not TODO NotSolvedQueryBuilders.spanNotQuery().include(QueryBuilders.spanTermQuery("name", "葫芦580娃")).exclude(QueryBuilders.spanTermQuery("home", "山西省太原市2552街道"));// Span Or TODO NotSolvedreturn QueryBuilders.spanOrQuery().clause(QueryBuilders.spanTermQuery("name", "葫芦580娃")).clause(QueryBuilders.spanTermQuery("name", "葫芦3812娃")).clause(QueryBuilders.spanTermQuery("name", "葫芦7139娃"));// Span Term//return QueryBuilders.spanTermQuery("name", "葫芦580娃");
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* term query* 一个查询相匹配的文件包含一个术语。。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder termQuery() {return QueryBuilders.termQuery("name", "葫芦580娃");
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* terms query* 一个查询相匹配的多个value* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder termsQuery() {return QueryBuilders.termsQuery("name", // field"葫芦580娃", "葫芦3812娃") // values.minimumMatch(1); // 设置最小数量的匹配提供了条件。默认为1。
}/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* top children query* 构建了一种新的评分的子查询,与子类型和运行在子文档查询。这个查询的结果是,那些子父文档文件匹配。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder topChildrenQuery() {return QueryBuilders.topChildrenQuery("blog_tag", // fieldQueryBuilders.termQuery("name", "葫芦3812娃") // Query).score("max") // max, sum or avg.factor(5).incrementalFactor(2);
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* wildcard query* 实现了通配符搜索查询。支持通配符* < /tt>,<tt>* 匹配任何字符序列(包括空),<tt> ? < /tt>,* 匹配任何单个的字符。注意该查询可以缓慢,因为它* 许多方面需要遍历。为了防止WildcardQueries极其缓慢。* 一个通配符词不应该从一个通配符* < /tt>或<tt>* < /tt> <tt> ?。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder wildcardQuery() {return QueryBuilders.wildcardQuery("name", "葫芦*2娃");
}/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* nested query* 嵌套查询* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static QueryBuilder nestedQuery() {return QueryBuilders.nestedQuery("location", // PathQueryBuilders.boolQuery() // Your query.must(QueryBuilders.matchQuery("location.lat", 0.962590433140581)).must(QueryBuilders.rangeQuery("location.lon").lt(0.00000000000000000003))).scoreMode("total"); // max, total, avg or none
}/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* indices query* 索引查询* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
protected static IndicesQueryBuilder indicesQuery() {// Using another query when no match for the main oneQueryBuilders.indicesQuery(QueryBuilders.termQuery("name", "葫芦3812娃"),Es_Utils.INDEX_DEMO_01, "index2") //设置查询索引上执行时使用不匹配指数.noMatchQuery(QueryBuilders.termQuery("age", "葫芦3812娃"));// Using all (match all) or none (match no documents)return QueryBuilders.indicesQuery(QueryBuilders.termQuery("name", "葫芦3812娃"),Es_Utils.INDEX_DEMO_01, "index2") // 设置不匹配查询,可以是 all 或者 none.noMatchQuery("none");
}public static void main(String[] args) {Es_Utils.startupClient();try {searchTest(indicesQuery());} catch (Exception e) {e.printStackTrace();} finally {Es_Utils.shutDownClient();}
}private static void searchTest(QueryBuilder queryBuilder) {//预准备执行搜索Es_Utils.client.prepareSearch(Es_Utils.INDEX_DEMO_01).setTypes(Es_Utils.INDEX_DEMO_01_MAPPING).setQuery(queryBuilder).setFrom(0).setSize(20).setExplain(true).execute()//注册监听事件.addListener(new ActionListener<SearchResponse>() {@Overridepublic void onResponse(SearchResponse searchResponse) {Es_Utils.writeSearchResponse(searchResponse);}@Overridepublic void onFailure(Throwable e) {}});
}ESUtil
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.github.pagehelper.PageInfo;
import com.msb.es.dto.Document;
import com.msb.es.dto.EsDataId;
import com.msb.es.dto.enums.FieldType;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkItemResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchType;
import org.elasticsearch.action.support.IndicesOptions;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.support.replication.ReplicationResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.PutMappingRequest;
import org.elasticsearch.common.Strings;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.io.IOException;
import java.lang.reflect.Field;
import java.util.*;@Slf4j
@Component
public class ESUtil {@Resourceprivate RestHighLevelClient restHighLevelClient;private static int index_number_of_shards = 3;//默认分片数private static int index_number_of_replicas = 1;//默认副本数 单节点public void setIndexNumber(int index_number_of_shards, int index_number_of_replicas) {this.index_number_of_shards = index_number_of_shards;this.index_number_of_replicas = index_number_of_replicas;}public RestHighLevelClient getInstance() {return restHighLevelClient;}//region 创建索引(默认分片数为3和副本数为1)/*** 创建索引(默认分片数为1和副本数为0)** @param clazz 根据实体自动映射es索引* @throws IOException*/public boolean createIndex(Class clazz) throws Exception {Document declaredAnnotation = (Document) clazz.getDeclaredAnnotation(Document.class);if (declaredAnnotation == null) {throw new Exception(String.format("class name: %s can not find Annotation [Document], please check", clazz.getName()));}String indexName = declaredAnnotation.indexName();boolean flag = createRootIndex(indexName, clazz);if (flag) {return true;}return false;}/*** 创建索引(默认分片数为5和副本数为1)** @param clazz 根据实体自动映射es索引* @throws IOException*/public boolean createIndexIfNotExist(Class clazz) throws Exception {Document declaredAnnotation = (Document) clazz.getDeclaredAnnotation(Document.class);if (declaredAnnotation == null) {throw new Exception(String.format("class name: %s can not find Annotation [Document], please check", clazz.getName()));}String indexName = declaredAnnotation.indexName();boolean indexExists = isIndexExists(indexName);if (!indexExists) {boolean flag = createRootIndex(indexName, clazz);if (flag) {return true;}}return false;}private boolean createRootIndex(String indexName, Class clazz) throws IOException {CreateIndexRequest request = new CreateIndexRequest(indexName);request.settings(Settings.builder()// 设置分片数, 副本数.put("index.number_of_shards", index_number_of_shards).put("index.number_of_replicas", index_number_of_replicas));request.mapping(generateBuilder(clazz));CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);// 指示是否所有节点都已确认请求boolean acknowledged = response.isAcknowledged();// 指示是否在超时之前为索引中的每个分片启动了必需的分片副本数boolean shardsAcknowledged = response.isShardsAcknowledged();return acknowledged || shardsAcknowledged;}//endregion//region 更新索引/*** 更新索引(默认分片数为5和副本数为1):* 只能给索引上添加一些不存在的字段* 已经存在的映射不能改** @param clazz 根据实体自动映射es索引* @throws IOException*/public boolean updateIndex(Class clazz) throws Exception {Document declaredAnnotation = (Document) clazz.getDeclaredAnnotation(Document.class);if (declaredAnnotation == null) {throw new Exception(String.format("class name: %s can not find Annotation [Document], please check", clazz.getName()));}String indexName = declaredAnnotation.indexName();PutMappingRequest request = new PutMappingRequest(indexName);request.source(generateBuilder(clazz));AcknowledgedResponse response = restHighLevelClient.indices().putMapping(request, RequestOptions.DEFAULT);// 指示是否所有节点都已确认请求boolean acknowledged = response.isAcknowledged();if (acknowledged) {return true;}return false;}//endregion//region 删除索引/*** 删除索引** @param indexName* @return*/public boolean delIndex(String indexName) {boolean acknowledged = false;try {DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(indexName);deleteIndexRequest.indicesOptions(IndicesOptions.LENIENT_EXPAND_OPEN);AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);acknowledged = delete.isAcknowledged();} catch (IOException e) {e.printStackTrace();}return acknowledged;}//endregion//region 判断索引是否存在/*** 判断索引是否存在** @param indexName* @return*/public boolean isIndexExists(String indexName) {boolean exists = false;try {GetIndexRequest getIndexRequest = new GetIndexRequest(indexName);getIndexRequest.humanReadable(true);exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}return exists;}//endregion//region 添加单条数据/*** 添加单条数据* 提供多种方式:* 1. json* 2. map* Map<String, Object> jsonMap = new HashMap<>();* jsonMap.put("user", "kimchy");* jsonMap.put("postDate", new Date());* jsonMap.put("message", "trying out Elasticsearch");* IndexRequest indexRequest = new IndexRequest("posts")* .id("1").source(jsonMap);* 3. builder* XContentBuilder builder = XContentFactory.jsonBuilder();* builder.startObject();* {* builder.field("user", "kimchy");* builder.timeField("postDate", new Date());* builder.field("message", "trying out Elasticsearch");* }* builder.endObject();* IndexRequest indexRequest = new IndexRequest("posts")* .id("1").source(builder);* 4. source:* IndexRequest indexRequest = new IndexRequest("posts")* .id("1")* .source("user", "kimchy",* "postDate", new Date(),* "message", "trying out Elasticsearch");* <p>* 报错: Validation Failed: 1: type is missing;* 加入两个jar包解决* <p>* 提供新增或修改的功能** @return*/public IndexResponse index(Object o) throws Exception {Document declaredAnnotation = (Document) o.getClass().getDeclaredAnnotation(Document.class);if (declaredAnnotation == null) {throw new Exception(String.format("class name: %s can not find Annotation [Document], please check", o.getClass().getName()));}String indexName = declaredAnnotation.indexName();IndexRequest request = new IndexRequest(indexName);Field fieldByAnnotation = getFieldByAnnotation(o, EsDataId.class);if (fieldByAnnotation != null) {fieldByAnnotation.setAccessible(true);try {Object id = fieldByAnnotation.get(o);request = request.id(id.toString());} catch (IllegalAccessException e) {}}String userJson = JSON.toJSONString(o);request.source(userJson, XContentType.JSON);IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);return indexResponse;}//endregion//region queryById/*** 根据id查询** @return*/public String queryById(String indexName, String id) throws IOException {GetRequest getRequest = new GetRequest(indexName, id);// getRequest.fetchSourceContext(FetchSourceContext.DO_NOT_FETCH_SOURCE);GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);String jsonStr = getResponse.getSourceAsString();return jsonStr;}//endregion//region 查询封装返回json字符串/*** 查询封装返回json字符串** @param indexName* @param searchSourceBuilder* @return* @throws IOException*/public String search(String indexName, SearchSourceBuilder searchSourceBuilder) throws IOException {SearchRequest searchRequest = new SearchRequest(indexName);searchRequest.source(searchSourceBuilder);searchRequest.scroll(TimeValue.timeValueMinutes(1L));SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);String scrollId = searchResponse.getScrollId();SearchHits hits = searchResponse.getHits();JSONArray jsonArray = new JSONArray();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();JSONObject jsonObject = JSON.parseObject(sourceAsString);jsonArray.add(jsonObject);}return jsonArray.toJSONString();}//endregion//region 查询封装,带分页/*** 查询封装,带分页** @param searchSourceBuilder* @param pageNum* @param pageSize* @param s* @param <T>* @return* @throws IOException*/public <T> PageInfo<T> search(SearchSourceBuilder searchSourceBuilder, int pageNum, int pageSize, Class<T> s) throws Exception {Document declaredAnnotation = (Document) s.getDeclaredAnnotation(Document.class);if (declaredAnnotation == null) {throw new Exception(String.format("class name: %s can not find Annotation [Document], please check", s.getName()));}String indexName = declaredAnnotation.indexName();SearchRequest searchRequest = new SearchRequest(indexName);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHits hits = searchResponse.getHits();JSONArray jsonArray = new JSONArray();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();JSONObject jsonObject = JSON.parseObject(sourceAsString);jsonArray.add(jsonObject);}int total = (int) hits.getTotalHits().value;// 封装分页List<T> list = jsonArray.toJavaList(s);PageInfo<T> page = new PageInfo<>();page.setList(list);page.setPageNum(pageNum);page.setPageSize(pageSize);page.setTotal(total);page.setPages(total == 0 ? 0 : (total % pageSize == 0 ? total / pageSize : (total / pageSize) + 1));page.setHasNextPage(page.getPageNum() < page.getPages());return page;}//endregion//region 查询封装,返回集合/*** 查询封装,返回集合** @param searchSourceBuilder* @param s* @param <T>* @return* @throws IOException*/public <T> List<T> search(SearchSourceBuilder searchSourceBuilder, Class<T> s) throws Exception {Document declaredAnnotation = s.getDeclaredAnnotation(Document.class);if (declaredAnnotation == null) {throw new Exception(String.format("class name: %s can not find Annotation [Document], please check", s.getName()));}String indexName = declaredAnnotation.indexName();SearchRequest searchRequest = new SearchRequest(indexName);searchRequest.source(searchSourceBuilder);searchRequest.scroll(TimeValue.timeValueMinutes(1L));SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);// //配置标题高亮显示// HighlightBuilder highlightBuilder = new HighlightBuilder(); //生成高亮查询器// highlightBuilder.field(title); //高亮查询字段// highlightBuilder.field(content); //高亮查询字段// highlightBuilder.requireFieldMatch(false); //如果要多个字段高亮,这项要为false// highlightBuilder.preTags("<span style=\"color:red\">"); //高亮设置// highlightBuilder.postTags("</span>");//// //下面这两项,如果你要高亮如文字内容等有很多字的字段,必须配置,不然会导致高亮不全,文章内容缺失等// highlightBuilder.fragmentSize(800000); //最大高亮分片数// highlightBuilder.numOfFragments(0); //从第一个分片获取高亮片段String scrollId = searchResponse.getScrollId();SearchHits hits = searchResponse.getHits();JSONArray jsonArray = new JSONArray();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();JSONObject jsonObject = JSON.parseObject(sourceAsString);jsonArray.add(jsonObject);}// 封装分页List<T> list = jsonArray.toJavaList(s);return list;}//endregion//region 批量插入文档/*** 批量插入文档* 文档存在 则插入* 文档不存在 则更新** @param list* @return*/public <T> boolean batchSaveOrUpdate(List<T> list, boolean izAsync) throws Exception {Object o1 = list.get(0);Document declaredAnnotation = (Document) o1.getClass().getDeclaredAnnotation(Document.class);if (declaredAnnotation == null) {throw new Exception(String.format("class name: %s can not find Annotation [@Document], please check", o1.getClass().getName()));}String indexName = declaredAnnotation.indexName();BulkRequest request = new BulkRequest(indexName);for (Object o : list) {String jsonStr = JSON.toJSONString(o);IndexRequest indexReq = new IndexRequest().source(jsonStr, XContentType.JSON);Field fieldByAnnotation = getFieldByAnnotation(o, EsDataId.class);if (fieldByAnnotation != null) {fieldByAnnotation.setAccessible(true);try {Object id = fieldByAnnotation.get(o);indexReq = indexReq.id(id.toString());} catch (IllegalAccessException e) {}}request.add(indexReq);}if (izAsync) {BulkResponse bulkResponse = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);return outResult(bulkResponse);} else {restHighLevelClient.bulkAsync(request, RequestOptions.DEFAULT, new ActionListener<BulkResponse>() {@Overridepublic void onResponse(BulkResponse bulkResponse) {outResult(bulkResponse);}@Overridepublic void onFailure(Exception e) {}});}return true;}//endregion//region 删除文档/*** 删除文档** @param indexName: 索引名称* @param docId: 文档id*/public boolean deleteDoc(String indexName, String docId) throws IOException {DeleteRequest request = new DeleteRequest(indexName, docId);DeleteResponse deleteResponse = restHighLevelClient.delete(request, RequestOptions.DEFAULT);// 解析responseString index = deleteResponse.getIndex();String id = deleteResponse.getId();long version = deleteResponse.getVersion();ReplicationResponse.ShardInfo shardInfo = deleteResponse.getShardInfo();if (shardInfo.getFailed() > 0) {for (ReplicationResponse.ShardInfo.Failure failure :shardInfo.getFailures()) {String reason = failure.reason();}}return true;}//endregion//region 根据json类型更新文档/*** 根据json类型更新文档** @param indexName* @param docId* @param o* @return* @throws IOException*/public boolean updateDoc(String indexName, String docId, Object o) throws IOException {UpdateRequest request = new UpdateRequest(indexName, docId);request.doc(JSON.toJSONString(o), XContentType.JSON);UpdateResponse updateResponse = restHighLevelClient.update(request, RequestOptions.DEFAULT);String index = updateResponse.getIndex();String id = updateResponse.getId();long version = updateResponse.getVersion();if (updateResponse.getResult() == DocWriteResponse.Result.CREATED) {return true;} else if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {return true;} else if (updateResponse.getResult() == DocWriteResponse.Result.DELETED) {} else if (updateResponse.getResult() == DocWriteResponse.Result.NOOP) {}return false;}//endregion//region 根据Map类型更新文档/*** 根据Map类型更新文档** @param indexName* @param docId* @param map* @return* @throws IOException*/public boolean updateDoc(String indexName, String docId, Map<String, Object> map) throws IOException {UpdateRequest request = new UpdateRequest(indexName, docId);request.doc(map);UpdateResponse updateResponse = restHighLevelClient.update(request, RequestOptions.DEFAULT);String index = updateResponse.getIndex();String id = updateResponse.getId();long version = updateResponse.getVersion();if (updateResponse.getResult() == DocWriteResponse.Result.CREATED) {return true;} else if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {return true;} else if (updateResponse.getResult() == DocWriteResponse.Result.DELETED) {} else if (updateResponse.getResult() == DocWriteResponse.Result.NOOP) {}return false;}//endregion//region generateBuilderpublic XContentBuilder generateBuilder(Class clazz) throws IOException {// 获取索引名称及类型Document doc = (Document) clazz.getAnnotation(Document.class);System.out.println(doc.indexName());XContentBuilder builder = XContentFactory.jsonBuilder();builder.startObject();builder.startObject("properties");Field[] declaredFields = clazz.getDeclaredFields();for (Field f : declaredFields) {if (f.isAnnotationPresent(com.msb.es.dto.Field.class)) {// 获取注解com.msb.es.dto.Field declaredAnnotation =f.getDeclaredAnnotation(com.msb.es.dto.Field.class);// 如果嵌套对象:/*** {* "mappings": {* "properties": {* "region": {* "type": "keyword"* },* "manager": {* "properties": {* "age": { "type": "integer" },* "name": {* "properties": {* "first": { "type": "text" },* "last": { "type": "text" }* }* }* }* }* }* }* }*/if (declaredAnnotation.type() == FieldType.OBJECT) {// 获取当前类的对象-- ActionClass<?> type = f.getType();Field[] df2 = type.getDeclaredFields();builder.startObject(f.getName());builder.startObject("properties");// 遍历该对象中的所有属性for (Field f2 : df2) {if (f2.isAnnotationPresent(com.msb.es.dto.Field.class)) {// 获取注解com.msb.es.dto.Field declaredAnnotation2 = f2.getDeclaredAnnotation(com.msb.es.dto.Field.class);builder.startObject(f2.getName());builder.field("type", declaredAnnotation2.type().getType());// keyword不需要分词if (declaredAnnotation2.type() == FieldType.TEXT) {builder.field("analyzer", declaredAnnotation2.analyzer().getType());}if (declaredAnnotation2.type() == FieldType.DATE) {builder.field("format", "yyyy-MM-dd HH:mm:ss");}builder.endObject();}}builder.endObject();builder.endObject();} else {builder.startObject(f.getName());builder.field("type", declaredAnnotation.type().getType());// keyword不需要分词if (declaredAnnotation.type() == FieldType.TEXT) {builder.field("analyzer", declaredAnnotation.analyzer().getType());}if (declaredAnnotation.type() == FieldType.DATE) {builder.field("format", "yyyy-MM-dd HH:mm:ss");}builder.endObject();}}}// 对应propertybuilder.endObject();builder.endObject();return builder;}//endregion//region getFieldByAnnotationpublic static Field getFieldByAnnotation(Object o, Class annotationClass) {Field[] declaredFields = o.getClass().getDeclaredFields();if (declaredFields != null && declaredFields.length > 0) {for (Field f : declaredFields) {if (f.isAnnotationPresent(annotationClass)) {return f;}}}return null;}//endregion//region getLowLevelClient/*** getLowLevelClient** @return*/public RestClient getLowLevelClient() {return restHighLevelClient.getLowLevelClient();}//endregion//region 高亮结果集 特殊处理/*** 高亮结果集 特殊处理* map转对象 JSONObject.parseObject(JSONObject.toJSONString(map), Content.class)** @param searchResponse* @param highlightField*/public List<Map<String, Object>> setSearchResponse(SearchResponse searchResponse, String highlightField) {//解析结果ArrayList<Map<String, Object>> list = new ArrayList<>();for (SearchHit hit : searchResponse.getHits().getHits()) {Map<String, HighlightField> high = hit.getHighlightFields();HighlightField title = high.get(highlightField);hit.getSourceAsMap().put("id", hit.getId());Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的结果//解析高亮字段,将原来的字段换为高亮字段if (title != null) {Text[] texts = title.fragments();String nTitle = "";for (Text text : texts) {nTitle += text;}//替换sourceAsMap.put(highlightField, nTitle);}list.add(sourceAsMap);}return list;}//endregion//region 查询并分页/*** 查询并分页** @param index 索引名称* @param query 查询条件* @param size 文档大小限制* @param from 从第几页开始* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)* @param sortField 排序字段* @param highlightField 高亮字段* @return*/public List<Map<String, Object>> searchListData(String index,SearchSourceBuilder query,Integer size,Integer from,String fields,String sortField,String highlightField) throws IOException {SearchRequest request = new SearchRequest(index);SearchSourceBuilder builder = query;if (StringUtils.isNotEmpty(fields)) {//只查询特定字段。如果需要查询所有字段则不设置该项。builder.fetchSource(new FetchSourceContext(true, fields.split(","), Strings.EMPTY_ARRAY));}from = from <= 0 ? 0 : from * size;//设置确定结果要从哪个索引开始搜索的from选项,默认为0builder.from(from);builder.size(size);if (StringUtils.isNotEmpty(sortField)) {//排序字段,注意如果proposal_no是text类型会默认带有keyword性质,需要拼接.keywordbuilder.sort(sortField + ".keyword", SortOrder.ASC);}//高亮HighlightBuilder highlight = new HighlightBuilder();highlight.field(highlightField);//关闭多个高亮highlight.requireFieldMatch(false);highlight.preTags("<span style='color:red'>");highlight.postTags("</span>");builder.highlighter(highlight);//不返回源数据。只有条数之类的数据。//builder.fetchSource(false);request.source(builder);SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);if (response.status().getStatus() == 200) {// 解析对象return setSearchResponse(response, highlightField);}return null;}//endregionprivate boolean outResult(BulkResponse bulkResponse) {for (BulkItemResponse bulkItemResponse : bulkResponse) {DocWriteResponse itemResponse = bulkItemResponse.getResponse();IndexResponse indexResponse = (IndexResponse) itemResponse;if (bulkItemResponse.isFailed()) {return false;}}return true;}
}相关文章:

Elastic Stack--10--QueryBuilders UpdateQuery
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 QueryBuildersESUtil QueryBuilders package com.elasticsearch; import org.elasticsearch.action.ActionListener; import org.elasticsearch.action.search.Sea…...

腾讯云服务器CVM_云主机_云计算服务器_弹性云服务器
腾讯云服务器CVM提供安全可靠的弹性计算服务,腾讯云明星级云服务器,弹性计算实时扩展或缩减计算资源,支持包年包月、按量计费和竞价实例计费模式,CVM提供多种CPU、内存、硬盘和带宽可以灵活调整的实例规格,提供9个9的数…...

Java八股文(Spring Boot)
Java八股文のSpring Boot Spring Boot Spring Boot 什么是Spring Boot? Spring Boot是一个用于开发和构建微服务应用程序的框架,它简化了Spring应用的配置和部署。 Spring Boot的核心特性是什么? Spring Boot的核心特性包括自动配置、起步依…...

ts文件怎么无损转换mp4?这样设置转换模式~
TS格式(Transport Stream)的起源可追溯到数字电视广播领域。设计初衷是解决视频、音频等多媒体数据在传输和存储中的问题。采用一系列标准技术,TS格式让视频信号能够以流的形式传输,因此在数字电视、广播等领域得到广泛应用。 MP4…...
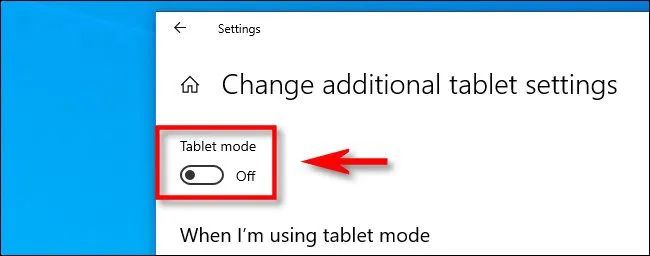
如何在Windows 10上打开和关闭平板模式?这里提供详细步骤
前言 默认情况下,当你将可翻转PC重新配置为平板模式时,Windows 10会自动切换到平板模式。如果你希望手动打开或关闭平板模式,有几种方法可以实现。 自动平板模式在Windows 10上如何工作 如果你使用的是二合一可翻转笔记本电脑࿰…...

介绍kafka核心原理及底层刷盘机制,集群分片机制,消息丢失和重复消费有对应的线上解决方案
Kafka是一个高性能、分布式、持久化的消息系统,它的核心原理包括发布/订阅模型、分布式日志存储和高吞吐量的数据流处理。 发布/订阅模型:Kafka采用发布/订阅模型,消息的生产者将消息发送到一个或多个主题(Topic)&…...
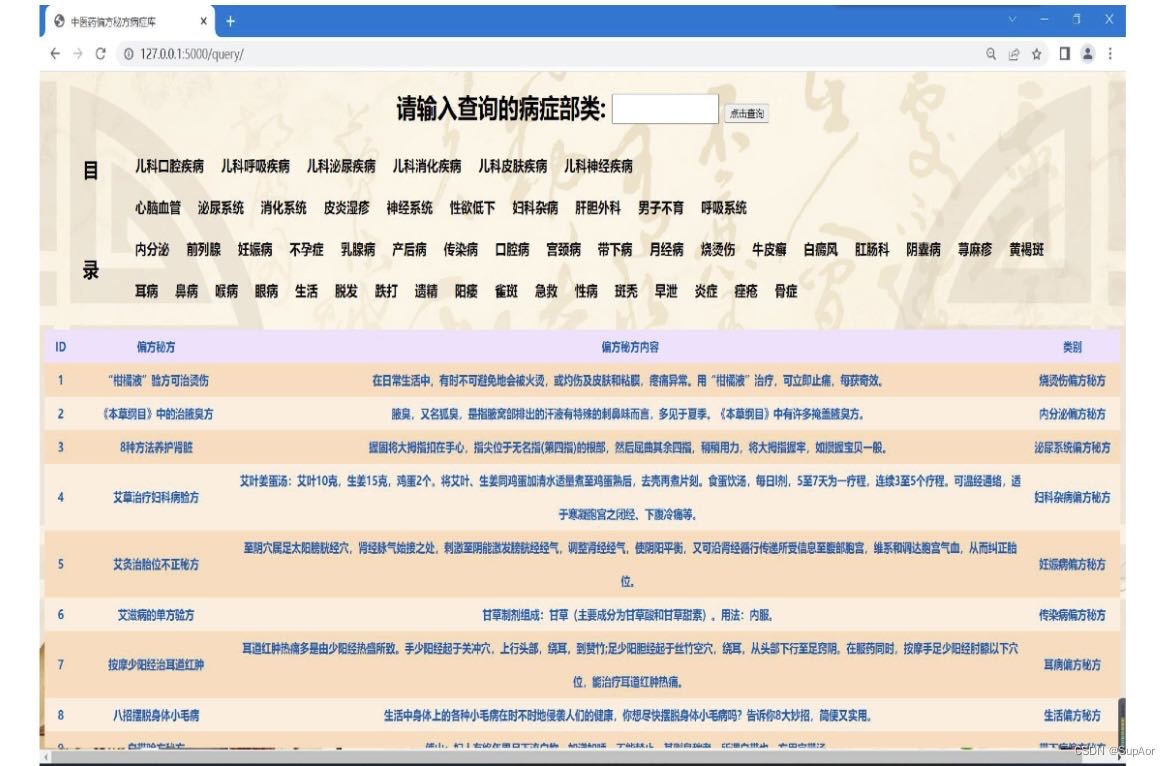
基于Python的中医药知识问答系统设计与实现
[简介] 这篇文章主要介绍了基于Python的中医药知识问答系统的设计与实现。该系统利用Python编程语言,结合中医药领域的知识和技术,实现了一个功能强大的问答系统。文章首先介绍了中医药知识的特点和传统问答系统的局限性,然后提出了设计思路…...

QT 如何防止 QTextEdit 自动滚动到最下方
在往QTextEdit里面append字符串时,如果超出其高度,默认会自动滚动到QTextEdit最下方。但是有些场景可能想从文本最开始的地方展示,那么就需要禁止自动滚动。 我们可以在append之后,添加如下代码: //设置编辑框的光标位…...

【C/C++ 学习笔记】指针
【C/C 学习笔记】指针 视频地址: Bilibili 概念 可以通过指针间接访问内存用于保存地址 使用 通过 & 可以获取数据的指针 通过 * 可以取得指针的数据 指针的数据类型就是 数据类型 * int number 10;int *p &number;// 10 cout << "number: " …...
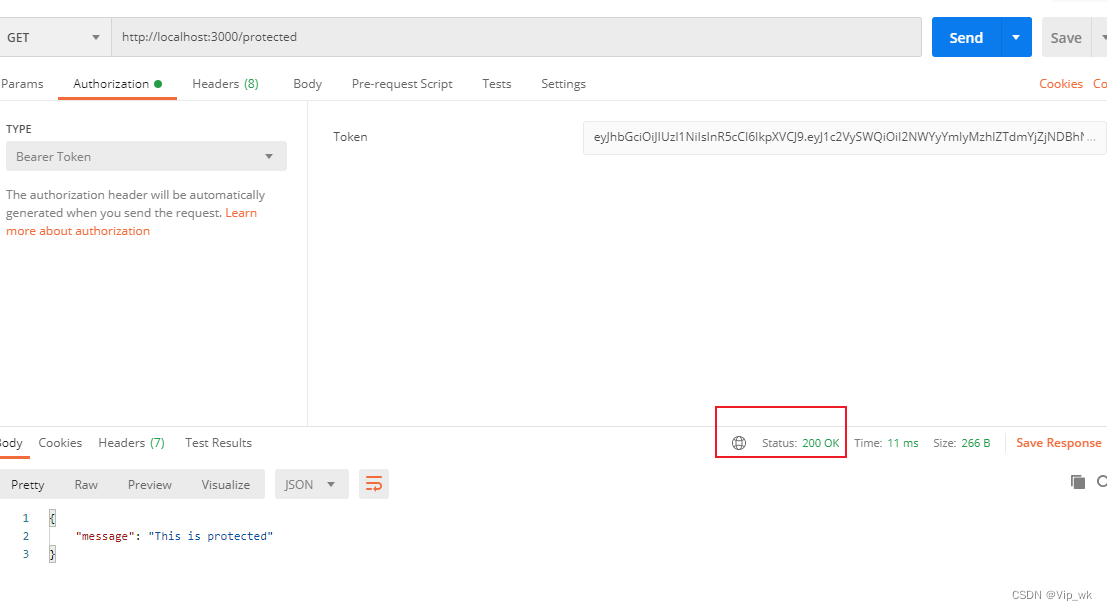
【Node.js从基础到高级运用】十二、身份验证与授权:JWT
身份验证与授权是现代Web应用中不可或缺的部分。了解如何在Node.js应用中实施这些机制,将使你能够构建更安全、更可靠的应用程序。本文将引导你通过使用JWT实现用户注册、登录和权限控制的过程。 JWT(Json Web Token) JWT是一种用于双方之间…...

蓝桥杯刷题|01入门真题
[蓝桥杯 2020 省 AB1] 解码 题目描述 小明有一串很长的英文字母,可能包含大写和小写。 在这串字母中,有很多连续的是重复的。小明想了一个办法将这串字母表达得更短:将连续的几个相同字母写成字母 出现次数的形式。 例如,连续…...

Python Django相关解答
问题:什么是django? Django是一个开源的高级web框架,皆在快速开发安全可维护的网站。他鼓励快速开发,并遵循“don’t repeat yourself”DRY原则 Django的MTV架构是什么 Django遵循MTV(模型-模板-试图)架构模式。模型(…...

在Linux/Ubuntu/Debian中使用7z压缩和解压文件
要在 Ubuntu 上使用 7-Zip 创建 7z 存档文件,你可以使用“7z”命令行工具。 操作方法如下: 安装 p7zip: 如果你尚未在 Ubuntu 系统上安装 p7zip(7-Zip 的命令行版本),你可以使用以下命令安装它:…...

设计一些策略和技术来防止恶意爬虫
当涉及到反爬虫时,我们需要设计一些策略和技术来防止恶意爬虫访问我们的网站。以下是一个简单的反爬虫框架示例,供您参考: import requests from bs4 import BeautifulSoup import timeclass AntiScrapingFramework:def __init__(self, targ…...
elasticsearch常见问题:xpack.security.transport.ssl、unknown setting [node.master]
文章目录 引言I 安装elasticsearch1.1 安装Master Node1.2 安装Slave nodeII elasticsearch常见问题2.1 invalid configuration for xpack.security.transport.ssl2.2 server ssl configuration requires a key and certificate2.3 unknown setting [node.master]III Kibana启动…...
——Springboot集成文心一言、讯飞星火、通义千问、智谱清言)
LLM(大语言模型)——Springboot集成文心一言、讯飞星火、通义千问、智谱清言
目录 引言 代码完整地址 入参 出参 Controller Service Service实现类 模型Service 入参转换类 文心一言实现类 讯飞星火实现类 通义千问实现类 智谱清言实现类 引言 本文将介绍如何使用Java语言,结合Spring Boot框架,集成国内热门大模型API&am…...

什么是堆?什么是栈?
在计算机科学中,"堆(heap)"和"栈(stack)"是两种用于存储数据的数据结构,它们在内存管理中扮演着不同的角色。 堆(Heap): 动态分配内存:…...
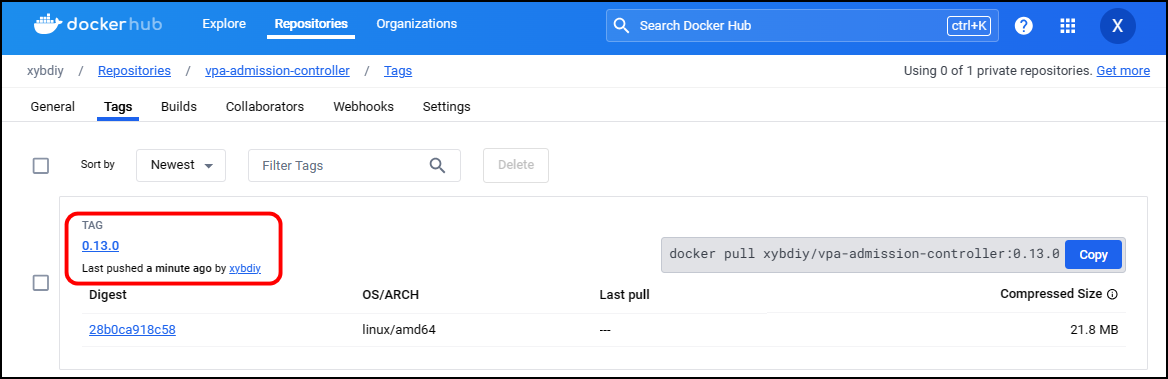
【镜像转存】利用交互式学习平台killercoda转存K8S镜像至Docker私人仓库
文章目录 1. 镜像转存需求2. 注册并登陆 killercoda URL3. 打开playground4. 在线拉取K8S镜像并打上标签5. 推送K8S镜像到Docker私有仓库6. 登陆Docker私有仓库查看 1. 镜像转存需求 因K8S镜像在不开代理的情况下,拉取超时、下载缓慢,导致镜像拉取不下来…...

ov多域名SSL数字证书1200元一年送一月
随着互联网的发展,不论是个人用户还是企事业单位都不止有一个网站,为了保护网站安全,就需要为网站安装SSL证书,而SSL证书中的通配符SSL证书和多域名SSL证书都可以同时保护多个域名站点。其中,多域名SSL证书可以同时保护…...
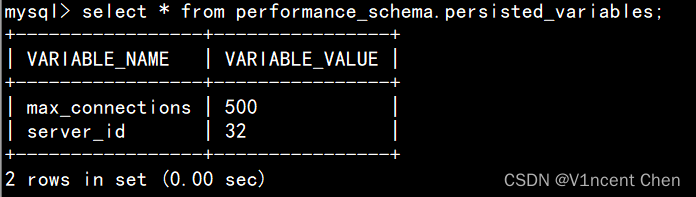
MySQL 系统变量查看与设置(System Variables Configuration)
MySQL中有大量的系统变量控制服务器的行为,大部分的系统变量是不需要我们调整的,保持默认即可。但为了获得更高的性能和稳定性,有时需要适当对部分变量进行调整,本文总结了MySQL中系统变量的查看与设置方法。 目录 一、变量的类型…...

当 Agent 的输出需要符合特定格式规范
当 Agent 的输出需要符合特定格式规范:从混乱到可控的Prompt工程与结构化交互全解一、引言 (Introduction)钩子 (The Hook) 想象一个场景:你在训练一个医疗辅助诊断Agent,告诉它“把刚才的问诊结果整理成标准的HL7 FHIR Bundle”,…...

如何用LiteIDE快速构建高效Go开发环境:完整指南
如何用LiteIDE快速构建高效Go开发环境:完整指南 【免费下载链接】liteide LiteIDE is a simple, open source, cross-platform Go IDE. 项目地址: https://gitcode.com/gh_mirrors/li/liteide LiteIDE是一款专为Go语言设计的轻量级、开源、跨平台集成开发环…...

5步搭建企业级数据中台:AllData开源解决方案终极指南
5步搭建企业级数据中台:AllData开源解决方案终极指南 【免费下载链接】alldata 🔥🔥 AllData可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为工厂,以大模型应用为上游产品&…...

重塑数字记忆:用WeChatExporter解锁微信聊天记录的永久保存方案
重塑数字记忆:用WeChatExporter解锁微信聊天记录的永久保存方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代,微信聊天记录已成为我…...

BiliBiliCCSubtitle架构解析:C++实现的B站CC字幕高效下载与转换技术方案
BiliBiliCCSubtitle架构解析:C实现的B站CC字幕高效下载与转换技术方案 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle BiliBiliCCSubtitle是一款基于C…...

医疗AI数据陷阱:ICD编码与金标准诊断的鸿沟及应对策略
1. 项目概述:当医疗AI遇上“计费标签”的陷阱在医疗人工智能领域,我们常常听到一个令人振奋的故事:利用海量的电子健康记录(EHR)数据,训练出能够预测疾病、辅助诊断的机器学习模型。这听起来像是未来医疗的…...

UnityExplorer终极调试指南:如何用游戏内UI工具提升开发效率
UnityExplorer终极调试指南:如何用游戏内UI工具提升开发效率 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplor…...

如何高效安装Adobe插件:ZXPInstaller终极指南
如何高效安装Adobe插件:ZXPInstaller终极指南 【免费下载链接】ZXPInstaller Open Source ZXP Installer for Adobe Extensions 项目地址: https://gitcode.com/gh_mirrors/zx/ZXPInstaller 还在为Adobe插件安装而烦恼吗?每次遇到.zxp文件时&…...

VirtualBox与VMware NAT模式下SSH端口转发配置全解
1. 为什么NAT模式下“连不上”是常态,而端口转发才是解题正解VirtualBox虚拟机用NAT模式上网,对绝大多数新手来说,第一反应就是“能上外网,那我从宿主机ssh连进去应该也行吧?”——结果敲下ssh user10.0.2.15ÿ…...

终极塔科夫离线存档编辑器:5步掌握SPT-AKI Profile Editor完整指南
终极塔科夫离线存档编辑器:5步掌握SPT-AKI Profile Editor完整指南 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/…...