Python爬虫:原理与实战
引言
在当今的信息时代,互联网上的数据如同浩瀚的海洋,充满了无尽的宝藏。Python爬虫作为一种高效的数据抓取工具,能够帮助我们轻松地获取这些数据,并进行后续的分析和处理。本文将深入探讨Python爬虫的原理,并结合实战案例,帮助读者快速掌握爬虫技术。
一、Python爬虫原理
1、爬虫是什么?
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
2、爬虫的基本流程
Python爬虫的核心原理是通过模拟浏览器的行为,自动访问目标网站,并抓取其中的数据。这个过程主要包括以下几个步骤:
- 发送请求:使用Python中的第三方库(如requests)向目标网站发送HTTP请求,获取网页的HTML代码。
- 解析网页:利用Python的解析库(如BeautifulSoup、lxml等)对获取的HTML代码进行解析,提取出所需的数据。
- 存储数据:将解析得到的数据存储到本地文件、数据库或其他存储介质中,以便后续分析和处理。
用户获取网络数据的方式:
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2。
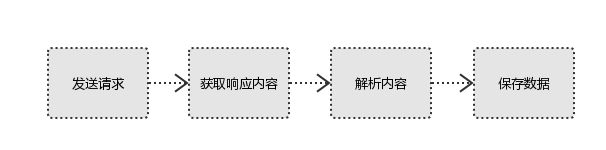
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
接下来,我们将通过一个实战案例来演示如何使用Python爬虫抓取目标网站的数据。
3、客户端HTTP请求格式
在网络传输中HTTP协议非常重要,该协议规定了客户端和服务器端请求和应答的标准。HTTP协议能保证计算机正确快速地传输超文本文档,并确定了传输文档中的哪一部分,以及哪一部分内容首先显示(如文本先于图形)等。
根据HTTP协议的规定,客户端发送了一个HTTP请求到服务器的请求消息,由请求行、请求头部、空行以及请求数据四个部分组成。


下面结合一个典型的HTTP请求示例,详细介绍HTTP请求信息的各个组成部分:
Get https://www.baidu.com/ HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: https://www.baidu.com/link?url=8vUrPYDUaSkXWxUEOlT8QhvB5kMr1o6I27EP0NJICmG&wd=&eqid=e69078350001654000000003641051fc
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: BIDUPSID=498703BAB592E42B1A4200A2F69121AD; PSTM=1657099499; MCITY=-291%3A; BAIDUID=498703BAB592E42BC6776C4114ED28E6:SL=0:NR=10:FG=1; BD_UPN=12314753; BDUSS=J5OEFjZ3pBb05tR3QxNUo0TEVJdjVpYzQ5Q2FORC04TnlrMHhFYkhRMnNKeGxrRVFBQUFBJCQAAAAAAQAAAAEAAAAXv8pawrfIy73U1qpUYQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKya8WOsmvFjLT; BDUSS_BFESS=J5OEFjZ3pBb05tR3QxNUo0TEVJdjVpYzQ5Q2FORC04TnlrMHhFYkhRMnNKeGxrRVFBQUFBJCQAAAAAAQAAAAEAAAAXv8pawrfIy73U1qpUYQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKya8WOsmvFjLT;(1)请求行
第一行为请求行,包含了请求的方法,URL地址和协议版本。GET是请求方法,https://www.baidu.com是URL地址,HTTP/1.1指定了协议版本。
不同的请求方法含义不同,如下:
| 序号 | 方法 | 描述 |
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | POST | 向指定资源提交数据进行处理请求(如提交表单或者上传文件),数据被包含在请求体中。Post请求可能会导致新的资源的建立和已有资源的修改 |
| 3 | HEAD | 类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 4 | PUT | 这种请求方式下,从客户端向服务器传送的数据取代指定的文档的内容 |
| 5 | DELETE | 请求服务器删除指定的页面 |
| 6 | CONNECT | HTTP1.1协议中预留给能够将连接改为管道方式的代理服务器 |
| 7 | OPTIONS | 允许客服端查看服务器的性能 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
其中GET和POST请求最常用,区别在于:
GET是从服务器上获取指定页面信息,POST是向服务器提交数据并获取页面信息。
GET请求参数都显示在URL上,服务器根据该请求所包含URL中的参数来产生响应内容。由于请求参数都暴露在外,所以安全性不高。
POST请求参数在请求体中,消息长度没有限制而且采取隐式发送,通常用来向HTTP服务器提交量比骄大的数据(如请求中包含许多参数或者文件上传的操作)POST请求的参数不在URL中,而在请求体中,在安全性方面比GET请求要高。
(2)请求报头
请求行下是若干个请求报头,下面介绍常用的请求报头及含义:
Host(主机和端口号):指定被请求的资源的Internet主机和端口号,对应网址URL中的Web名称和端口号,通常属于URL的Host部分。
Connection(连接类型):表示客户端与服务端的连接类型。
Upgrade-Insecure-Requests(升级为HTTPS请求):表示升级不安全的请求,会在加载HTTP资源时自动替换成HTTPS请求,让浏览器不再显示HTTPS页面中的HTTP请求警报。HTTPS时以安全为目标的HTTP通道,所以在HTTPS承载的页面上不允许出现HTTP请求,一旦出现就会提示或报错。
User-Agent(浏览器名称):表示客户端身份的名称,通常页面会根据不同的User-Agent信息自动做出适配,甚至返回不同的响应内容。
Accept(传输文件类型):指浏览器或其他客户端可以接受的MIME(Multipurpose Internet Mail Extensions,多用途因特网邮件扩展)文件类型,服务器可以根据他判断并返回适当的文件格式
Referer(页面跳转来源):表明产生请求的网页来自于哪个URL,用户是从该Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站下载下来的,有时下载某网站的图片时,需要对应的Referer,否则是无法下载图片,那是因为做了防盗链。原理就是根据Referer去判断URL是否是本网站的地址,如果不是,则拒绝,如果是,就可以下载。
4. 服务器HTTP响应格式
HTTP响应报文由四部分组成,分别是状态行,响应报头,空行和响应正文。
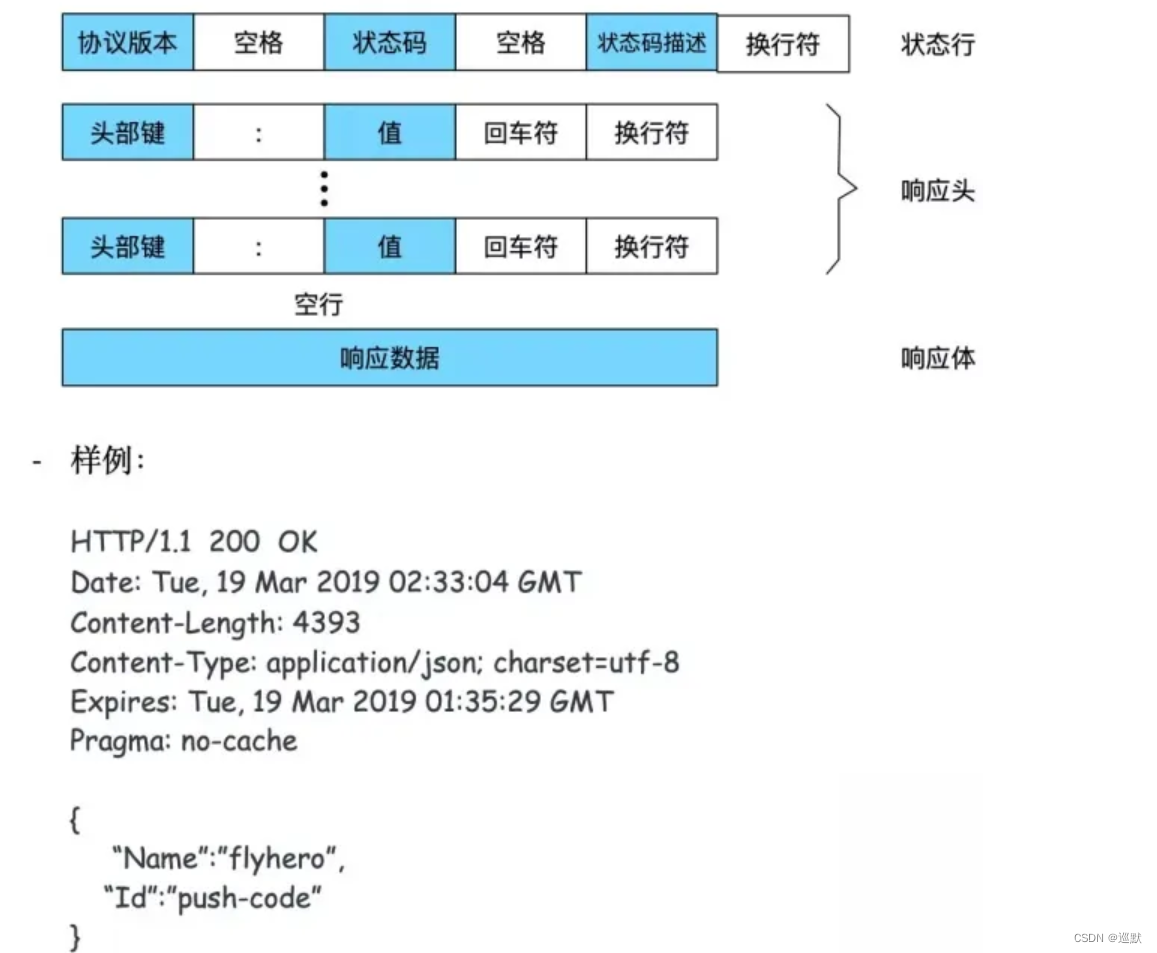
响应状态码
响应状态码由3位数字组成,其中第一位数字定义了响应的类别,有5种可能取值,常见的响应状态码如下:
100~199:表示服务器成功接收部分请求,要求客户端继续提价奥其余请求才能完成整个处理过程。
200~299:表示服务器成功接受请求并已完成整个处理过程。常用的状态码为200(表示OK,请求成功)。
200~399:为完成请求,客户需进一步细化请求。例如,请求的资源已经移动到一个新的地址。常用状态码包括302(表示所请求的页面已经临时转移至新的URL)、307和304(表示使用缓存资源)。
400~499:客户端的请求有错误,常用状态码包括404(表示服务器无法找到被请求的页面)和403(表示服务器拒绝访问,权限不够)。
500~599:服务器端出现错误,常用的状态码为500(表示请求未完成,服务器遇到不可预知的情况)。
二、Python爬虫实战
2、实战案例:抓取豆瓣电影Top250榜单
1. 发送请求
首先,我们需要向豆瓣电影Top250榜单的URL发送请求,获取网页的HTML代码。这里我们使用requests库来实现:
import requests url = 'https://movie.douban.com/top250'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
html = response.text2. 解析网页
接下来,我们需要对获取的HTML代码进行解析,提取出电影榜单的数据。这里我们使用BeautifulSoup库来实现:
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find_all('div', class_='item') for movie in movie_list: title = movie.find('span', class_='title').text info = movie.find('p').text.strip().split('\n') rating_num = float(movie.find('span', class_='rating_num').text) print(f'标题:{title}') print(f'信息:{info}') print(f'评分:{rating_num}') print('----')3. 存储数据
最后,我们可以将解析得到的数据存储到本地文件中,以便后续分析和处理:
with open('douban_top250.txt', 'w', encoding='utf-8') as f: for movie in movie_list: title = movie.find('span', class_='title').text info = movie.find('p').text.strip().split('\n') rating_num = float(movie.find('span', class_='rating_num').text) f.write(f'标题:{title}\n') f.write(f'信息:{info}\n') f.write(f'评分:{rating_num}\n') f.write('----\n')三、注意事项与总结
在使用Python爬虫时,我们需要注意以下几点:
- 遵守robots.txt协议:在爬取网站数据时,要遵守目标网站的robots.txt协议,避免对网站造成不必要的负担。
- 设置合理的请求频率和间隔时间:为了避免对目标网站造成过大的压力,我们需要设置合理的请求频率和间隔时间。
- 处理反爬虫机制:一些网站会采用反爬虫机制来防止数据被抓取,我们需要采取相应的措施来绕过这些机制。
- 尊重数据版权:在爬取和使用数据时,要尊重数据的版权和隐私,避免侵犯他人的权益。
总结来说,Python爬虫是一种强大的数据抓取工具,通过掌握其原理和实战技巧,我们可以轻松地获取互联网上的数据,并进行后续的分析和处理。然而,在使用爬虫时,我们也需要遵守相关的规定和注意事项,确保数据的合法性和安全性。
相关文章:
Python爬虫:原理与实战
引言 在当今的信息时代,互联网上的数据如同浩瀚的海洋,充满了无尽的宝藏。Python爬虫作为一种高效的数据抓取工具,能够帮助我们轻松地获取这些数据,并进行后续的分析和处理。本文将深入探讨Python爬虫的原理,并结合实战…...
C# danbooru Stable Diffusion 提示词反推 Onnx Demo
目录 说明 效果 模型信息 项目 代码 下载 C# danbooru Stable Diffusion 提示词反推 Onnx Demo 说明 模型下载地址:https://huggingface.co/deepghs/ml-danbooru-onnx 效果 模型信息 Model Properties ------------------------- ----------------------…...
Windows系统搭建Cloudreve结合内网穿透打造可公网访问的私有云盘
目录 ⛳️推荐 1、前言 2、本地网站搭建 2.1 环境使用 2.2 支持组件选择 2.3 网页安装 2.4 测试和使用 2.5 问题解决 3、本地网页发布 3.1 cpolar云端设置 3.2 cpolar本地设置 4、公网访问测试 5、结语 ⛳️推荐 前些天发现了一个巨牛的人工智能学习网站ÿ…...
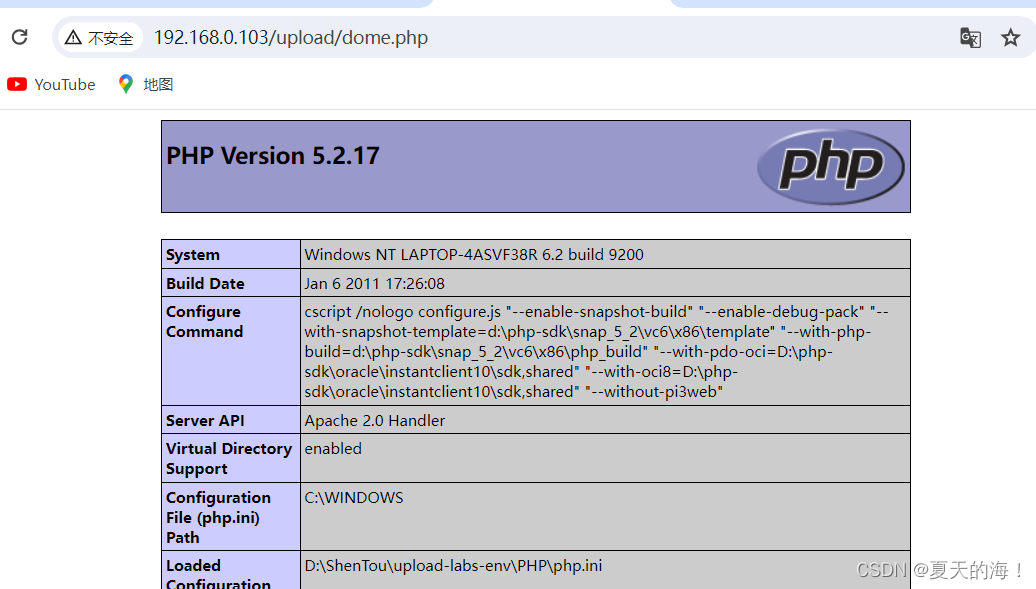
upload-labs 0.1 靶机详解
下载地址https://github.com/c0ny1/upload-labs/releases Pass-01 他让我们上传一张图片,我们先尝试上传一个php文件 发现他只允许上传图片格式的文件,我们来看看源码 我们可以看到它使用js来限制我们可以上传的内容 但是我们的浏览器是可以关闭js功能的…...
react 综合题-旧版
一、组件基础 1. React 事件机制 javascript 复制代码<div onClick{this.handleClick.bind(this)}>点我</div> React并不是将click事件绑定到了div的真实DOM上,而是在document处监听了所有的事件,当事件发生并且冒泡到document处的时候&a…...

基于ElasticSearch存储海量AIS数据:AIS数据索引机制篇
文章目录 引言I 预备知识1.1 索引结构1.2 AIS信息项II AIS数据索引2.1 AIS数据静态数据索引2.2 AIS数据动态信息索引2.3 引入静态信息的AIS数据轨迹信息索引引言 AIS数据信息根据其不同更新频率可分为静态和动态信息。索引结构设计包含了静态、动态和轨迹信息索引。同时,为了…...

IDEA中返回上一步和下一步快捷键失效【Ctrl+Alt+左箭头】
原因与解决方法 快捷键失效的缘故,和其它软件的快捷键冲突。方法:改变快捷键。如果不知道哪个软件影响的,一个一个关闭软件,然后再去IDEA中尝试快捷键是否生效。 【提示:我的是QQ音乐软件打开影响的】...

Hubspot 2023年推荐使用的11个AI视频生成器
视频是任何营销活动不可或缺的一部分;然而,如果你不懂编辑或时间紧迫,它们可能会很乏味,很难创建。一只手从电脑里伸出来,拳头碰到另一只手;代表AI视频生成器。 幸运的是,你可以利用许多人工智能…...
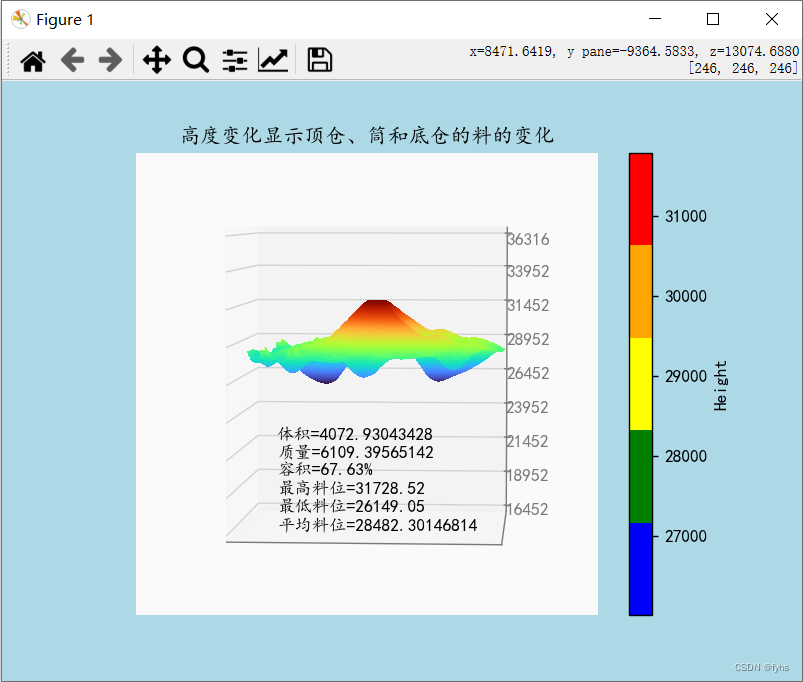
Python 导入Excel三维坐标数据 生成三维曲面地形图(体) 5-2、线条平滑曲面且可通过面观察柱体变化(二)
环境和包: 环境 python:python-3.12.0-amd64包: matplotlib 3.8.2 pandas 2.1.4 openpyxl 3.1.2 scipy 1.12.0 代码: import pandas as pd import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from scipy.interpolate import griddata fro…...
)
[2024年]-flink面试真题(四)
(上海) Flink与Spark有什么主要区别?(上海) 关于Flink的流处理和批处理,你了解多少?(上海) 你能解释一下Flink的架构吗?(上海) Flink是如何处理事件时间(Event Time)和处理时间(Processing Time…...

基于SpringBoot+Druid实现多数据源:原生注解式
前言 本博客姊妹篇 基于SpringBootDruid实现多数据源:原生注解式基于SpringBootDruid实现多数据源:注解编程式基于SpringBootDruid实现多数据源:baomidou多数据源 一、功能描述 配置方式:配置文件中实现多数据源,非…...

AJAX 03 XMLHttpRequest、Promise、封装简易版 axios
AJAX 学习 AJAX 3 原理01 XMLHttpRequest① XHR 定义② XHR & axios 关系③ 使用 XHR④ XHR查询参数案例:地区查询(URLSearchParams)⑤ XHR数据提交 POST 02 PromisePromise 使用Promise - 三种状态案例:使用Promise XHR 获取…...
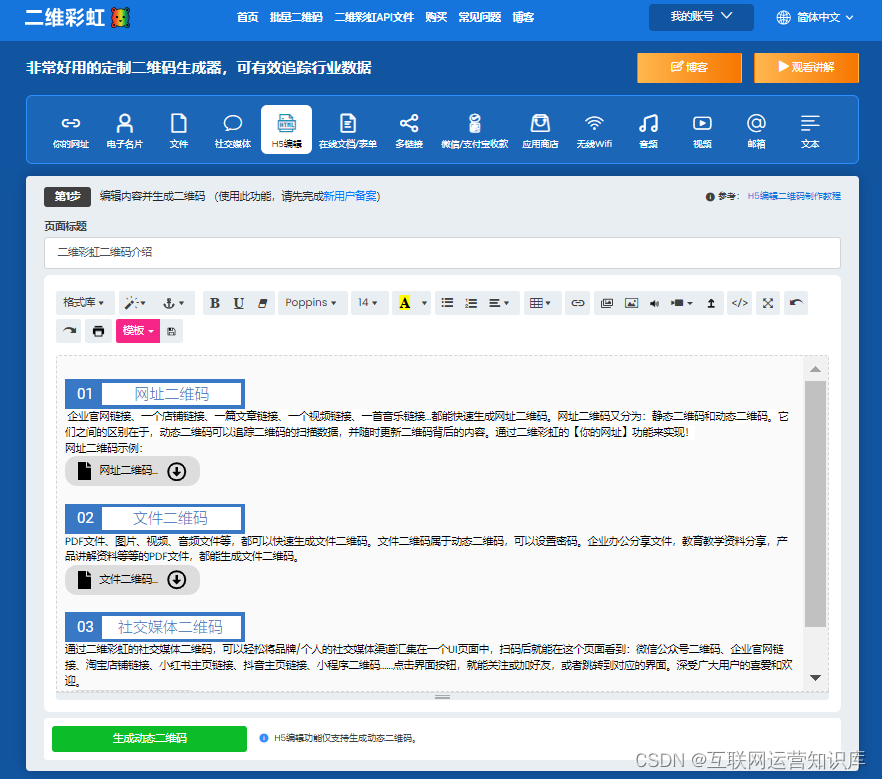
如何将办公资料文件生成二维码?扫码可看详情
日常办公的时候,经常会需要应用二维码来向同事或者客户发送和展示一些资料。比如包含企业介绍和产品介绍的资料、一些操作流程的资料、产品展示宣传视频、活动安排详情、比赛流程、会议资料… 这些都能通过一个文件二维码来展示。 文件二维码支持将PDF文件生成二维…...
【Streamlit学习笔记】实现包含多个sheet的excel文件下载
1、什么是Streamlit Streamlit是一个免费的开源框架,用于快速构建和共享漂亮的机器学习和数据科学Web应用程序,官网链接 Streamlit Streamlit API链接 API reference 实际项目中遇到的问题:包含多个sheet的excel文件下载,下面将给…...

[Redis]——主从同步原理(全量同步、增量同步)
目录 Redis集群: 主从同步原理: replid和offset: 全量同步和增量同步: repl_baklog文件: 主从集群的优化: Redis集群: 部署多台Redis我们称之为Redis集群,他有一个主节点(负责写操作)&…...
Buildroot 之二 详解构建架构、流程、external tree、示例
构建系统 Buildroot 中的构建系统使用的是从 Linux Kernel(4.17-rc2) 中移植的 Kconfig(配置) + Makefile & Kbuild(编译)这套构建系统,移植后的源码位于 support/kconfig/ 目录下。Buildroot 本身是一个构建系统,与直接编译源码不同,因此,它对这套系统进行了比较…...

牛客小白月赛61-C-小喵觅食
很经典的bfs,就是从猫咪和MM的坐标开始bfs搜索 不过这题有些小细节需要注意 1.认真审题,注意,猫一旦闻到小鱼干的味道,开始动,此时MM就不动了,一开始没仔细审题,很不好的习惯 2.注意移动的条件,vis,不是墙,距离是MM的移动距离范围内 3.这个猫咪的r2是闻味道的r2,不是移动距…...

200 名专家编写报告:AI 发展可能对人类构成「灭绝级威胁」
3 月 14 日消息,美国国务院委托编写了一份新报告,警告 AI 正呈指数级发展,可能会对人类构成「灭绝级威胁」。 这份报告全称为《提高先进人工智能安全保障的行动计划》,要求美国政府必须迅速、果断地采取行动,以避免 A…...

学习Android的第二十九天
目录 Android Service 与 Activity 通讯 范例 Android Service Alarm 定时广播 Alarm Alarm 使用流程 范例 Android IBinder Binder 为什么是 Binder ? Android Service 与 Activity 通讯 Activity 与 Service 通信的媒介就是 Service 中的 onBind() 方法࿰…...

SpringMVC重点记录
目录 1.学习重点2.回顾MVC3.回顾servlet4.初始SpringMVC4.1.为什么要学SpringMVC?4.2.SpringMVC的中重点DispatcherServlet4.3.SpringMVC项目的搭建4.4.MVC框架要做哪些事情?4.5.可能会遇到的问题 5.SpringMVC的执行原理6.使用注解开发SpringMVC7.Controller控制总结8.RestF…...

基于RTK-GPS与ResNet50的自主草坪清扫机器人系统设计与实践
1. 项目概述与核心挑战在公园维护的日常工作中,草坪垃圾清理是一项既耗费人力又效率低下的重复性劳动。传统的清扫方式要么依赖人工,要么使用大型、笨重且可能损伤草皮的设备。我们团队的目标,是设计并实现一个能够自主、高效且温和地完成这项…...

C166链接器Error L101段冲突解决方案
1. 问题现象与背景解析当使用C166开发工具链进行项目链接时,开发者可能会遇到L166链接器报出的Error L101(Section Combination Error)。这个错误通常表现为链接过程中突然中断,并显示类似以下的错误信息:L166 LINKER …...

微生物代谢建模与优化:从GEMs构建到工业应用
1. 微生物代谢建模与优化的协同设计方法在工业生物技术领域,微生物代谢建模已成为优化生物转化过程的核心工具。通过构建基因组尺度代谢模型(GEMs),研究人员能够系统分析微生物细胞内数百至数千个酶催化反应的相互作用网络。以丁酸…...

为什么你的 Agent 总是“偷懒”?大模型惰性与激励提示词研究
为什么你的 Agent 总是“偷懒”?大模型惰性与激励提示词研究 各位知识工作者、AI 产品经理、大模型开发者、编程爱好者——如果你正在开发或使用基于大语言模型(LLMs)的智能体(Agent),或者只是在日常用 ChatGPT、Claude、文心一言这类工具时,肯定遇到过这类令人抓狂的场…...

LeetCode 1424:对角线遍历 II | 前缀和分组
LeetCode 1424:对角线遍历 II | 前缀和分组 引言 对角线遍历 II(Diagonal Traverse II)是 LeetCode 第 1424 题,难度为 Medium。题目要求按照对角线顺序遍历一个二叉树数组,返回所有对角线上的节点值。这道题展示了前缀…...

3分钟解决网易云音乐格式限制:免费NCM转换工具完全指南
3分钟解决网易云音乐格式限制:免费NCM转换工具完全指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾因网易云音乐下载的NCM格式文件无法在车载音响或普通播放器中播放而烦恼?今天,我将…...
)
JDK常用类与工具(速览版)
JDK常用类与工具(速览版)JDK(Java Development Kit)提供了丰富的标准库和实用工具,它们构成了Java开发者日常工作的基石。掌握这些核心类、集合框架、并发工具、IO/NIO库、日期时间API、正则表达式、异常处理机制、日志…...

Mumu模拟器ADB连接Unity Profiler全攻略
1. 为什么连不上Mumu的ADB,90%的人卡在第一步就放弃了“ADB device not found”、“offline”、“unauthorized”,这几个词我去年在Unity项目组的晨会白板上写了整整三周。不是因为技术多难,而是因为Mumu模拟器的ADB服务默认不走标准路径&…...
 心智模型导览——《Designing Data-Intensive Applications》书介绍导航)
《设计数据密集型应用》(DDIA, 2nd ed.) 心智模型导览——《Designing Data-Intensive Applications》书介绍导航
《设计数据密集型应用》(DDIA, 2nd ed.) 心智模型导览——《Designing Data-Intensive Applications》书介绍导航写给:还没读过这本书、想先在脑子里有张地图的读者 目的:装上 6 个内容枢纽——不只是抽象概念,每个枢纽下面挂着这本书真正讲的…...

突破性升级:Windows Package Manager 1.8让软件管理效率提升300%
突破性升级:Windows Package Manager 1.8让软件管理效率提升300% 【免费下载链接】winget-cli WinGet is the Windows Package Manager. This project includes a CLI (Command Line Interface), PowerShell modules, and a COM (Component Object Model) API (Appl…...