使用 OpenAI 的 text-embedding 构建知识向量库并进行相似搜索
OpenAI的embedding模型的使用
首先第一篇文章中探讨和使用了ChatGPT4的API-Key实现基础的多轮对话和流式输出,完成了对GPT-API的一个初探索,那第二步打算使用OpenAI的embedding模型来构建一个知识向量库,其实知识向量库本质上就是一个包含着一组向量的数组,然后通过查询输入文本生成的向量和数据库文本中的向量的余弦相似度来进行相似度判断,在使用的过程中还是非常舒服的。
前置文章:ChatGPT4 API-Key初探-本地调用API进行多轮对话方和流式输出
文章目录
- OpenAI的embedding模型的使用
- 1.什么是Embedding
- 2.使用OpenAI的embedding模型生成一个词向量
- 3.使用OpenAI的embedding模型获得一个知识向量库
- 3.从知识向量库中进行相似文本的查询
- 结束
1.什么是Embedding
Embedding在AI领域被翻译成词嵌入,但是光看这三个字其实不好理解,如果用一句话解释的话:embedding就是将文字转换成一个向量。

- 那为什么要转换成向量?
因为要获得两段文字在空间中的关系进行运算,例如后续需要做的计算两个词的相似度,就需要首先经过embedding模型将两端文字转换成向量,然后算两个向量的余弦相似度。
如果你不是研究自然语言处理的研究生或者算法工程师,那你只需要了解这一点就可以了,至于怎么转换的这一点可以不用深究,就像你可能不了解计算机组成原理但是你依然可以熟练的使用计算机。
2.使用OpenAI的embedding模型生成一个词向量
OpenAI为我们提供了了一个方便的API接口来将输入文本直接转换为词向量,在官方文档的代码中其实并没有新手向的代码的表达都会集成一些功能一起发布,但是为了学习和理解要把其中最简单和核心的部分抽出来。
下面的代码使用的是OpenAI的text-embedding-3-small模型将文本"父亲"转换为词向量。经过API之后得到了一个长度为1536的向量。
from openai import OpenAI
import numpy as np# client = OpenAI(api_key="your-api-key-here") # 如果想在代码中设置Api-key而不是全局变量就用这个代码
client = OpenAI()model = "text-embedding-3-small"def get_embedding(text, model=model):return client.embeddings.create(input=text, model=model).data[0].embeddingtext = '父亲'
vector = np.array(get_embedding(text))
print(vector.shape)
# (1536,)3.使用OpenAI的embedding模型获得一个知识向量库
OK那既然一条文本能转换成向量,那多条文本那就必然能转换成多个词向量,且词向量的长度是一致的,然后将这些词向量转换成数组然后保存这样就得到了一个知识向量库,本质上就是保存一个数组,返璞归真。
首先我们得有一段文本,我让ChatGPT给我生成了50个医疗词汇,每个词汇一行,文本内容我放在文章最后。接下来给出代码。
下列代码将本文中的医疗词汇逐行读取然后转换成词向量,保存到一个numpy数组当中,然后再将Numpy数组保存到本地,这样就得到了一个知识向量库。
from openai import OpenAI
import pandas as pd
import numpy as np
import time# client = OpenAI(api_key="your-api-key-here") # 如果想在代码中设置Api-key而不是全局变量就用这个代码
client = OpenAI()model = "text-embedding-3-small"with open('test.txt', 'r', encoding='utf-8') as file:lines = file.readlines()embedding = [client.embeddings.create(input=i.strip(), model=model).data[0].embedding for i in lines]t = time.time()
np.save('embedding.npy', np.array(embedding))
print(time.time() - t)
# 0.002991914749145508 (运行时间/s)
测试用的文本内容
糖尿病
高血压
抑郁症
阿尔茨海默症
慢性阻塞性肺疾病(COPD)
骨折
哮喘
乳腺癌
心肌梗塞
脑卒中
化疗
放射疗法
心脏搭桥手术
经皮冠状动脉介入治疗(PCI)
腹腔镜手术
物理疗法
认知行为疗法
血液透析
绝育手术
骨髓移植
MRI扫描仪
CT扫描仪
心电图机
超声波设备
血糖仪
血压计
吸氧机
呼吸机
脉搏血氧仪
自动体外除颤器(AED)
青霉素
阿司匹林
他汀类药物
阿片类镇痛药
抗生素
抗抑郁药
胰岛素
利尿剂
抗凝血药
抗病毒药
免疫疗法
基因编辑
微创手术
患者健康记录(PHR)
电子医疗记录(EMR)
临床试验
医疗保健大数据
精准医疗
遥感监测
医疗伦理
3.从知识向量库中进行相似文本的查询
首先在介绍查询方法之需要说一下计算相似度的余弦相似度,当两个向量夹角越小的时候两个向量的相似度越高,其计算公式如下:
cosine similarity ( A , B ) = A ⋅ B ∥ A ∥ ∥ B ∥ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ∑ i = 1 n B i 2 \text{cosine similarity}(\mathbf{A}, \mathbf{B}) = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|} = \frac{\sum_{i=1}^{n}A_iB_i}{\sqrt{\sum_{i=1}^{n}A_i^2} \sqrt{\sum_{i=1}^{n}B_i^2}} cosine similarity(A,B)=∥A∥∥B∥A⋅B=∑i=1nAi2∑i=1nBi2∑i=1nAiBi
在查询任务中我们需要计算输入文本的向量和知识向量库中所有文本向量的余弦相似度,然后进行排序,当然作为一个算法工程师我们当然不能直接用for循环进行计算,本文基于numpy的广播机制,自己实现了一个高效的计算一个向量和一群向量的余弦相似度的代码。同时由于算法本身使用的是numpy,基于numpy底层为C语言实现,因此本程序的效率较高,作为新手的话只需要知道输入输出是什么就行了。代码如下。
import numpy as npdef cos_similarity(target, embedding):numerator = np.sum(target * embedding, axis=1)denominator = np.sqrt(np.sum(np.square(target)) * np.sum(np.square(embedding),axis=1))return numerator / denominatorif __name__ == '__main__':x = np.array([1, 2])y = np.array([[1, 2], [1, 1]])print(cos_similarity(x, y))# [1. 0.9486833]
将知识向量库中的文本按照相似度从大到小输出,代码如下:
- 生成知识向量库和查询使用的模型得是一个模型别忘了,不然会报维度错误。
import numpy as np
from openai import OpenAImodel="text-embedding-3-small"
# client = OpenAI(api_key="your-api-key-here") # 如果想在代码中设置Api-key而不是全局变量就用这个代码
client = OpenAI()def get_embedding(text, model=model):return client.embeddings.create(input=text, model=model).data[0].embeddingdef cos_similarity(target, embedding):numerator = np.sum(target * embedding, axis=1)denominator = np.sqrt(np.sum(np.square(target)) * np.sum(np.square(embedding),axis=1))return numerator / denominatorwith open('test.txt', 'r', encoding='utf-8') as file:lines = file.readlines()# 获得文本数据
name = np.array([i.strip() for i in lines])
# 获得向量库
embedding = np.load("embedding.npy",allow_pickle=True)# 获取用户的输入文本
search_text = input("User:")
# 获取用户输入文本使用embedding模型转换得到的词向量
search_embedding = get_embedding(search_text)
# 计算用户输入文本
embedding_similarity = cos_similarity(search_embedding,embedding)# 由上到下输入相似度
for i in np.argsort(embedding_similarity)[::-1]:print(name[i],embedding_similarity[i])接下来让GPT解释一下这段代码助于理解,我看了一下基本没有问题。
-
导入所需的库:使用了
numpy库来处理数学运算和数组操作,以及OpenAI的API客户端来获取文本的嵌入向量。 -
设置模型和客户端:选择了一个特定的模型
text-embedding-3-small来从OpenAI获取文本嵌入。这里有一段被注释掉的代码,用于手动设置API密钥,但在这个例子中,默认使用了全局变量设置的API密钥。 -
定义函数获取嵌入向量:
get_embedding函数通过OpenAI的API将文本转换成嵌入向量。这个向量是文本的数学表示,用于计算相似度。 -
定义余弦相似度函数:
cos_similarity函数计算两组向量之间的余弦相似度,这是衡量向量相似度的一种方法。余弦相似度越接近1,表示两个向量越相似。 -
读取文本数据:从
test.txt文件中读取每行文本,每行代表一个可查询的项,并将其存储在名为name的数组中。 -
加载嵌入向量库:从
embedding.npy文件加载预先计算好的嵌入向量,这些向量对应于test.txt文件中的文本项。 -
获取用户输入:通过
input函数获取用户的查询文本。 -
获取查询文本的嵌入向量:使用
get_embedding函数将用户的查询文本转换为嵌入向量。 -
计算相似度:使用
cos_similarity函数计算用户查询的嵌入向量与嵌入向量库中所有向量之间的余弦相似度。
输出结果如下,这里就不全部粘贴了,把前面的几个粘贴上。
User:糖尿病
糖尿病 1.0
血糖仪 0.6027716430115105
高血压 0.4807989892102901
乳腺癌 0.46976679922966263
利尿剂 0.44671493260605705
抑郁症 0.3989793244972647
胰岛素 0.3678633339750386
心肌梗塞 0.3630205294730911
阿尔茨海默症 0.3554829250733137
血压计 0.3527248065537073
抗病毒药 0.3223748925983246

结束
官方文档:https://platform.openai.com/docs/guides/embeddings/embedding-models
目前支持的Embedding模型如下。

在官方文档中还详细讲了很多的使用方式,例如如何进行可视化,如何进行机器学习技术等,但是文章中的内容是我抽出主要内容然后加上自己的理解实现的。如果有什么不对或者更好的方式非常欢迎交流。
相关文章:
使用 OpenAI 的 text-embedding 构建知识向量库并进行相似搜索
OpenAI的embedding模型的使用 首先第一篇文章中探讨和使用了ChatGPT4的API-Key实现基础的多轮对话和流式输出,完成了对GPT-API的一个初探索,那第二步打算使用OpenAI的embedding模型来构建一个知识向量库,其实知识向量库本质上就是一个包含着一…...
设计模式学习笔记 - 规范与重构 - 5.如何通过封装、抽象、模块化、中间层解耦代码?
前言 《规范与重构 - 1.什么情况下要重构?重构什么?又该如何重构?》讲过,重构可以分为大规模高层重构(简称 “大型重构”)和小规模低层次重构(简称 “小型重构”)。大型重构是对系统…...
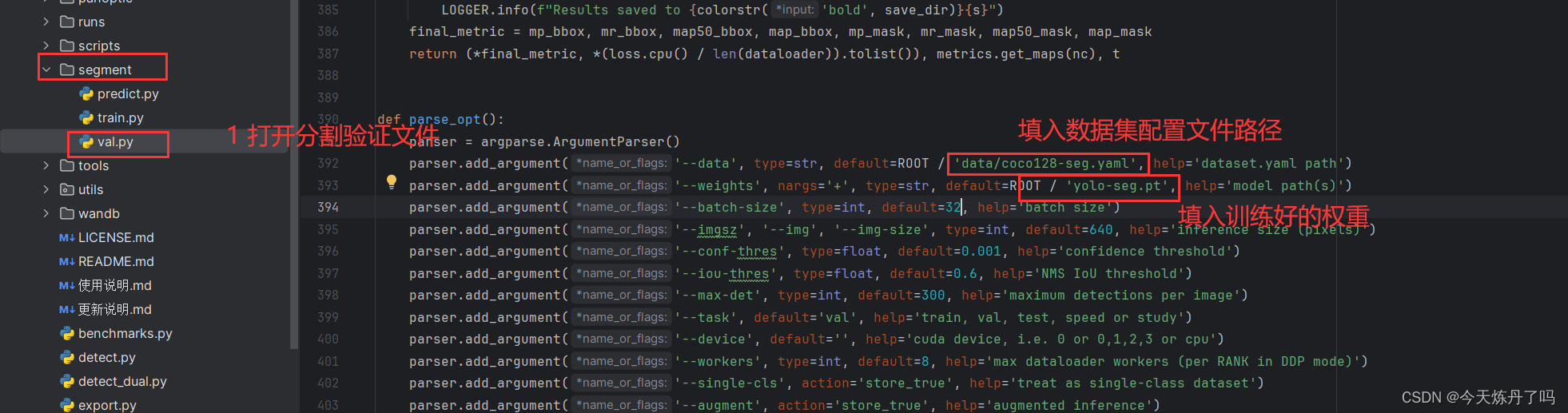
YOLOv9实例分割教程|(二)验证教程
专栏地址:目前售价售价59.9,改进点30个 专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,助力高效涨点!!! 一、验证 打开分割验证文件,填入数据集配置文件、训练好的权重文件&…...

python 基础知识点(蓝桥杯python科目个人复习计划63)
今日复习内容:做题 例题1:蓝桥骑士 问题描述: 小蓝是蓝桥王国的骑士,他喜欢不断突破自我。 这天蓝桥国王给他安排了N个对手,他们的战力值分别为a1,a2,...,an,且按顺序阻挡在小蓝的前方。对于这些对手小…...
IAB视频广告标准《数字视频和有线电视广告格式指南》之 简介、目录及视频配套广告 - 我为什么要翻译介绍美国人工智能科技公司IAB系列(2)
写在前面 谈及到中国企业走入国际市场,拓展海外营销渠道的时候,如果单纯依靠一个小公司去国外做广告,拉渠道,找代理公司,从售前到售后,都是非常不现实的。我们可以回想一下40年前,30年前&#x…...

Python网络基础爬虫-python基本语法
文章目录 逻辑语句if,else,elifforwhile异常处理 函数与类defpassclass 逻辑语句 熟悉C/C语言的人们可能很希望Python提供switch语句,但Python中并没有这个关键词,也没有这个语句结构。但是可以通过if-elif-elif-…这样的结构代替,或者使用字…...
产品推荐 - 基于星嵌 OMAPL138+国产FPGA的DSP+ARM+FPGA三核开发板
1 评估板简介 基于TI OMAP-L138(定点/浮点DSP C674xARM9) FPGA处理器的开发板; OMAP-L138是TI德州仪器的TMS320C6748ARM926EJ-S异构双核处理器,主频456MHz,高达3648MIPS和2746MFLOPS的运算能力; FPGA…...

【微服务学习笔记(一)】Nacos、Feign、Gateway基础使用
【微服务学习笔记(一)】Nacos、Feign、Gateway基础使用 总览Nacos安装配置Nacos注册中心服务多级存储模型负载均衡规则环境隔离 配置管理配置拉取配置热更新多服务共享配置 Feign远程调用配置性能优化Fegin使用 统一网关Gateway搭建网关路由断言工厂&…...

使用maven打生产环境可执行包
一、程序为什么要打包 程序打包的主要目的是将项目的源代码、依赖库和其他资源打包成一个可执行的文件或者部署包,方便程序的发布和部署。以下是一些打包程序的重要理由: 方便部署和分发:打包后的程序可以作为一个独立的实体,方便…...
springboot+ssm基于vue.js的客户关系Crm管理系统
系统包含两种角色:管理员、用户,主要功能如下。 ide工具:IDEA 或者eclipse 编程语言: java 数据库: mysql5.7 框架:ssmspringboot都有 前端:vue.jsElementUI 详细技术:springbootSSMvueMYSQLMAVEN 数据库…...
github 中的java前后端项目整合到本地运行
前言: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 本文章未…...
:Zookeeper实现分布式ID生成)
分布式ID(7):Zookeeper实现分布式ID生成
1 原理 实现方式有两种,一种通过节点,一种通过节点的版本号 节点的特性持久顺序节点(PERSISTENT_SEQUENTIAL) 他的基本特性和持久节点是一致的,额外的特性表现在顺序性上。在ZooKeeper中,每个父节点都会为他的第一级子节点维护一份顺序,用于记录下每个子节点创建的先后顺序…...
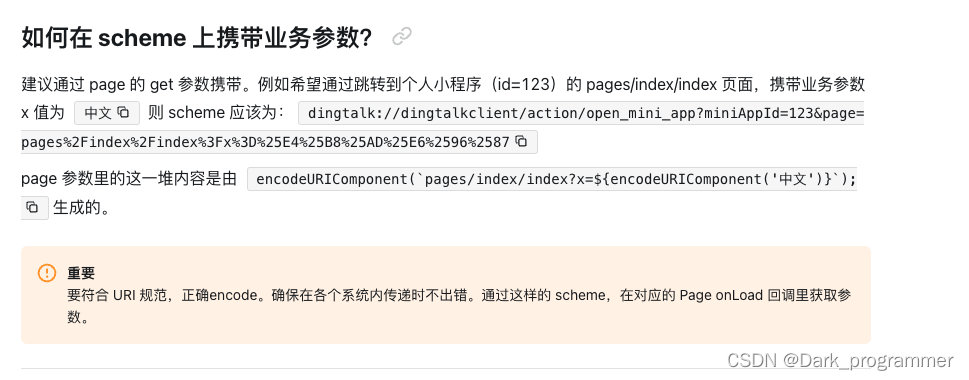
钉钉小程序 - - - - - 如何通过一个链接打开小程序内的指定页面
方式1 钉钉小程序 scheme dingtalk://dingtalkclient/action/open_mini_app?miniAppId123&pagepages%2Findex%2Findex%3Fx%3D%25E4%25B8%25AD%25E6%2596%2587 方式2 https://applink.dingtalk.com/action/open_mini_app?type2&miniAppIdminiAppId&corpIdcorpId&…...
Java代码基础算法练习---2024.3.14
其实这就是从我学校的资源,都比较基础的算法题,先尽量每天都做1-2题,练手感。毕竟离我真正去尝试入职好的公司(我指的就是中大厂,但是任重道远啊),仍有一定的时间,至少要等我升本之后…...

3月14日,每日信息差
🎖 素材来源官方媒体/网络新闻 🎄 5.5G通信网络在海南投入商用,较5G提升10倍 🌍 国务院批复同意,珠海港口岸将整合并扩大开放 🌋 同有科技:正在研究新型磁电存储技术 🎁 美国折扣零售…...

学习Android的第二十八天
目录 Android Service (服务) 线程 Service (服务) Service 相关方法 Android 非绑定 Service startService() 启动 Service 验证 startService() 启动 Service 的调用顺序 Android 绑定 Service bindService() 启动 Service 验证 BindService 启动 Service 的顺序 …...

C++等级3题
鸡兔同笼 #include<bits/stdc.h> using namespace std; void f(int n); int n; int main() {cin>>n;int x0;int ma-1;int mi1000;for(int i0;i<n;i){for(int j0;j<n;j){if(i*2j*4n){x1;mamax(ma,ij);mimin(mi,ij);}}}if(x1){cout<<mi<<" &…...

python中列表常用函数
列表list相关函数 列表相关函数 列表相关函数 汇总:. 列表: 1.list() 方法用于将序列(元组,集合,字符串等)转换为列表。 用法:list( seq ) #seq为序列:元组 集合 字符串等 2.列表定义&a…...

小程序连接蓝牙
小程序 蓝牙功能 1.授予蓝牙权限2.蓝牙初始化3.监听寻找新设备4.搜索新设备5.建立连接⭐⭐⭐⭐⭐⭐⭐6.监听蓝牙低功耗连接状态改变事件8.监听特征值变化9.发送数据 1.授予蓝牙权限 //1.蓝牙授权 const authBlue (callback, initApp) > {app initApp;//鉴定是否授权蓝牙w…...

基于Python的pygame库的五子棋游戏
安装pygame pip install pygame五子棋游戏代码 """五子棋之人机对战"""import sys import random import pygame from pygame.locals import * import pygame.gfxdraw from collections import namedtupleChessman namedtuple(Chessman, Name…...

Kubernetes DaemonSet深度解析:管理集群守护进程的最佳实践
Kubernetes DaemonSet深度解析:管理集群守护进程的最佳实践 一、DaemonSet概述 DaemonSet 是Kubernetes中用于在集群的每个节点上运行一个Pod副本的控制器。它确保所有节点(或满足特定条件的节点)都运行该Pod的一个实例。 1.1 DaemonSet应…...

为什么92%的Midjourney水效渲染失败?——解析v6.1+版本流体折射权重、noise scale与--s值的黄金三角关系
更多请点击: https://codechina.net 第一章:为什么92%的Midjourney水效渲染失败?——问题现象与根本归因 大量用户在使用 Midjourney v6 生成「水效渲染」(Water Efficiency Rendering)类提示词时遭遇高频失败——表现…...

跨系统数据搬运总是要靠人工复制粘贴?2026智能体重塑企业数据流转新范式
在2026年的今天,尽管通用人工智能(AGI)已经深度介入生产力环节,但走进多数企业的财务、供应链或人力资源部门,依然能看到员工在多个窗口间频繁切换,机械地重复着CtrlC和CtrlV。这种看似原始的“数据搬运”行…...

UABEA跨平台Unity资源编辑器:安全修改AssetBundle实战指南
1. 这不是又一个AssetBundle查看器,而是Unity资源编辑的“手术刀”你有没有在调试一个Unity游戏时,突然发现某个UI按钮的贴图颜色不对,或者NPC对话框的字体大小被改得离谱,但手头只有打包后的APK或EXE文件?更糟的是&am…...

FFXIV国际服中文汉化工具:5步实现终极中文游戏体验
FFXIV国际服中文汉化工具:5步实现终极中文游戏体验 【免费下载链接】FFXIVChnTextPatch 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIVChnTextPatch 还在为《最终幻想14》国际服的英文界面而烦恼吗?想要体验国际服的最新内容,却…...

终极Windows远程桌面解锁方案:RDP Wrapper Library完整配置指南
终极Windows远程桌面解锁方案:RDP Wrapper Library完整配置指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾因Windows家庭版无法支持多人远程桌面连接而感到困扰?RDP Wrapper L…...

全球AI范式变革与中国产业的破局路径
全球AI范式变革与中国产业的破局路径摘要当前全球人工智能产业正处于范式切换的关键节点,底层技术路线的竞争已经从参数规模竞赛转向认知框架的本质性革新。本文基于2026年行业最新发展动态,系统分析当前主流AI范式的内生性缺陷,梳理中美AI产…...

联发科MT6833与MT6853 5G核心板:规格对比与产品选型实战指南
1. 项目概述:两款5G安卓核心板的定位与价值在当前的移动设备开发领域,尤其是面向中高端市场的智能手机、平板电脑以及各类智能终端,选择一颗性能强劲、功能集成度高且成本可控的核心处理器平台,是决定产品成败的关键。联发科&…...

)
紧急!2024年Q2最新:Claude 3.5 Sonnet对LaTeX/Markdown混合文档的支持边界实测报告(附绕过限制的3种军工级方案)
更多请点击: https://kaifayun.com 第一章:Claude 3.5 Sonnet对LaTeX/Markdown混合文档的原生支持能力全景评估 Claude 3.5 Sonnet 在处理 LaTeX 与 Markdown 混合文档时展现出显著增强的解析鲁棒性与语义理解深度,尤其在数学公式嵌入、交叉…...