探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(一)
本系列文章简介:
本系列文章将带领大家深入探索Nutch的世界,从其基本概念和架构开始,逐步深入到爬虫、索引和查询等关键环节。通过了解Nutch的工作原理,大家将能够更好地理解搜索引擎背后的原理,并有能力利用Nutch构建自己的搜索引擎。 欢迎大家订阅《Java技术栈高级攻略》专栏,一起学习,一起涨分!
目录
一、引言
1.1 Nutch的起源与发展
1.2 Nutch在开源搜索引擎领域的地位
1.3 Nutch的工作原理概览
二、Nutch的基本组成与工作流程
2.1 爬虫部分
2.1.1 网页抓取与解析
2.1.2 URL去重与筛选
2.1.3 链接分析与提取
2.2 索引部分
2.2.1 文本处理与分词
2.2.2 倒排索引的建立
2.2.3 索引的存储与管理
2.3 查询部分
2.3.1 用户查询接口与交互
2.3.2 查询语句的分析与处理
2.3.3 结果排序与展示
三、Nutch的工作原理深入解析
四、Nutch的无限应用可能
五、Nutch的优化与扩展
六、结论与展望
七、结语
一、引言
1.1 Nutch的起源与发展
Nutch是一个开源的Web搜索引擎,它的起源可以追溯到2002年。最初,Nutch是由美国加州大学伯克利分校的Doug Cutting开发的一个研究项目。Doug Cutting是一个知名的开源软件开发者,他后来还负责开发了Apache Hadoop。
Nutch最初的目标是建立一个可扩展的、高效的Web搜索引擎。这个搜索引擎基于分布式计算的原理,可以处理大规模的Web数据。Nutch的设计灵感来自于Google的PageRank算法和Lucene搜索引擎。
Nutch的发展经历了多个版本的迭代和改进。最初的版本是基于Java语言开发的,后来又加入了C++和Python等其他编程语言的支持。Nutch还引入了一些新的技术和工具,如分布式爬虫、页面解析、索引构建等。
随着时间的推移,Nutch逐渐成为一个成熟的搜索引擎平台,其功能也得到了大幅扩展。目前的Nutch版本已经具备了支持自定义插件、多种搜索算法、分布式计算等特性。
Nutch的成功也激发了更多人对搜索引擎的研究和开发的兴趣。它为搜索引擎的开源开发提供了一个重要的范例,同时也为后来的搜索引擎项目,如Elasticsearch和Apache Solr等提供了借鉴和参考。
1.2 Nutch在开源搜索引擎领域的地位
Nutch是一个开源的网络爬虫和搜索引擎软件。它由Apache Lucene项目的创始人Doug Cutting开发,并于2002年发布。Nutch旨在提供一个可扩展的、高度可配置的搜索引擎解决方案。它支持多种网络爬取策略和搜索算法,可以用于构建各种类型的搜索引擎。
在开源搜索引擎领域,Nutch在一定程度上被视为一个重要的参考和基础平台。Nutch具有以下特点和优势:
-
开源:Nutch是一个完全开源的项目,可以免费使用和修改。这使得它成为那些希望建立自己搜索引擎的开发者和研究人员的理想选择。
-
可扩展性:Nutch具有高度可扩展的架构,可以轻松处理大规模的网页爬取和索引。它支持分布式计算和存储,可以在多台机器上运行,从而实现更高的处理能力和更快的响应时间。
-
灵活性:Nutch提供了丰富的配置选项,允许用户根据自己的需求定制搜索引擎的行为。它支持多种网络爬取策略、索引算法和查询处理方式,可以根据具体的应用场景进行优化。
-
社区支持:Nutch是一个活跃的开源项目,拥有一个强大的用户和开发者社区。这个社区提供了丰富的文档、教程和讨论区,可以帮助用户解决问题和分享经验。
尽管Nutch在开源搜索引擎领域有一定的影响力和地位,但它并不是目前市场上最流行的搜索引擎。它主要被用于学术研究、技术实验和定制化搜索引擎开发。对于那些寻求成熟和商业化的搜索引擎解决方案的企业,通常会选择其他更成熟和稳定的商业搜索引擎产品,如Elasticsearch、Apache Solr等。
1.3 Nutch的工作原理概览
Nutch是一个开源网络搜索引擎工具,它的工作原理可以概括为以下几个步骤:
-
网页抓取:Nutch从互联网上抓取网页,通过HTTP协议发送请求获取网页内容。它可以同时抓取多个网页,并支持分布式抓取。
-
网页解析:Nutch将抓取到的网页进行解析,提取出网页中的文本内容、超链接和其他标记信息。
-
网页索引:Nutch使用倒排索引的方式将解析后的网页内容进行索引。这使得用户可以通过关键字搜索来找到相关的网页。
-
搜索处理:当用户提交搜索请求时,Nutch会根据用户提供的关键字查询索引,找出与关键字匹配的网页。
-
搜索结果展示:Nutch将匹配的网页按照相关性排序,并将搜索结果展示给用户。用户可以通过点击搜索结果来访问相应的网页。
总的来说,Nutch的工作原理是通过抓取、解析、索引和搜索等步骤,实现对互联网上的网页进行搜索和展示。
二、Nutch的基本组成与工作流程
2.1 爬虫部分
2.1.1 网页抓取与解析
Nutch的基本组成与工作流程之爬虫部分主要包括网页抓取和解析两个步骤。
- 网页抓取: Nutch使用一个分布式的爬虫系统来抓取互联网上的网页。这个爬虫系统由多个组件组成,包括调度器、生成器、分析器和爬取器等。
-
调度器(Scheduler):负责管理要抓取的URL队列,并将URL分配给生成器和分析器。
-
生成器(Generator):负责根据一些预设的规则和策略生成待抓取的URL列表,这些URL来自于种子URL和之前抓取的URL。
-
分析器(Parser):负责分析网页,提取网页上的原始文本和其他元数据信息,如标题、链接、页面结构等。
-
爬取器(Crawler):负责实际地下载网页的内容,并将下载的网页存储到本地的仓库中。
- 网页解析: Nutch还包括一个网页解析器,用于从抓取的网页中提取有用的数据。解析器使用一些预定义的规则和XPath表达式来解析网页,并将提取到的数据存储到Nutch的数据库中。
-
解析器(Parser):根据预定义的规则和XPath表达式,从网页中提取数据,如文章内容、日期、作者等。
-
数据库(Database):存储从网页中解析到的数据,供后续的搜索和索引使用。
在整个网页抓取和解析的过程中,Nutch还提供了灵活的配置选项,可以根据需求对各个组件进行调整和定制,以适应不同的应用场景。
2.1.2 URL去重与筛选
Nutch的爬虫部分主要负责从互联网上收集网页数据。在爬虫部分的工作流程中,URL去重与筛选是一个重要的步骤。它的目的是确保爬虫不会重复抓取相同的URL,并且只抓取符合规则的URL。
Nutch的URL去重与筛选的基本组成包括以下几个组件:
-
URL生成器(URL Generator):根据一些规则和规则生成URL。可以通过配置文件来指定URL生成规则。
-
URL过滤器(URL Filters):根据一些规则和策略筛选URL,只选择符合条件的URL进行爬取。可以通过配置文件来指定URL筛选规则。
-
URL去重器(URL Deduplicator):进行URL去重操作,确保不会重复抓取相同的URL。Nutch使用布隆过滤器(Bloom Filter)来实现URL的去重。布隆过滤器是一种高效的数据结构,它可以判断一个元素是否存在于集合中,且有很低的错误率。
URL去重与筛选的工作流程如下:
-
URL生成器生成一批URL。
-
URL过滤器对这批URL进行筛选,只选择符合条件的URL进行下一步处理。
-
对于筛选后的URL,URL去重器判断是否已经抓取过该URL。如果已经抓取过,则丢弃该URL;如果没有抓取过,则将该URL添加到待抓取队列中。
-
待抓取队列会传递给爬虫调度器,爬虫调度器会根据一定的策略从队列中取出URL并分配给下载器进行下载。
-
下载器下载完网页后将网页内容传递给网页解析器进行解析,提取出新的URL并添加到待抓取队列中。
-
重复上述步骤直到待抓取队列为空。
通过URL去重与筛选,Nutch可以高效地抓取互联网上的网页数据,并保证不会重复抓取相同的URL。这对于爬虫的性能和资源利用效率至关重要。
2.1.3 链接分析与提取
Nutch的基本组成与工作流程中,爬虫部分的链接分析与提取是非常重要的一部分。链接分析与提取的过程可以大致分为以下几个步骤:
-
网页抓取:Nutch使用网络爬虫来抓取互联网上的网页。爬虫会从给定的起始URL开始,依次下载网页,并将它们存储到本地。
-
网页解析:抓取下来的网页需要进行解析,以便提取出网页中的链接。Nutch使用了HTML解析器来解析网页,并提取出其中的链接信息。
-
链接分析:在链接分析阶段,Nutch会对提取出的链接进行一系列的处理和分析。首先,它会筛选掉一些无效的链接,比如重定向链接、错误链接等。然后,它会根据一些算法和规则来计算每个链接的重要性和优先级。
-
链接提取:在链接分析的基础上,Nutch会选择一些重要的链接,将它们添加到爬虫的待抓取队列中。这些链接将作为下一次爬取的起始URL,并重复以上的过程。
需要注意的是,Nutch在链接分析与提取的过程中,还会考虑一些其他的因素。比如,它会根据网页的更新频率和重要性来调整链接的抓取优先级;它还会根据爬虫的配置和策略来控制爬取的深度和范围。
总的来说,Nutch的链接分析与提取是一个迭代的过程,通过不断地抓取和解析网页,并分析和提取链接,来构建一个完整的网页链接图谱。这个过程将为后续的网页索引和搜索提供基础。
2.2 索引部分
2.2.1 文本处理与分词
Nutch的索引部分主要包括文本处理和分词两个主要环节。在文本处理环节,Nutch会对爬取的网页进行预处理,包括去除HTML标签、去除停用词等,以获取干净的文本内容。
分词是指将文本按照一定的规则切割成词语的过程。Nutch使用开源的分词工具来进行分词操作,常用的分词工具有中文分词器IKAnalyzer、中文分词器SmartChineseAnalyzer等。这些分词工具可以根据中文的特点进行智能的分词,将文本切割成具有语义的词语。
Nutch的分词过程一般是在文本处理环节之后进行的,并且分词是针对不同语言的文本进行的。分词结果会被存储在倒排索引中,用于后续的搜索操作。
总结来说,Nutch的索引部分通过文本处理和分词来处理爬取的网页,将文本内容进行清洗和切割,并将分词结果存储在倒排索引中,以供后续的搜索操作使用。
2.2.2 倒排索引的建立
Nutch的索引部分是负责将抓取到的网页内容进行处理和分析,然后构建倒排索引,以支持后续的检索功能。
倒排索引是一种将词语与其出现的位置进行映射的数据结构,它的核心是建立一个词语到文档的映射,使得可以根据词语快速地找到包含该词语的文档。
倒排索引的建立主要分为以下几个步骤:
-
分词:将抓取到的网页内容进行分词,将文本划分成一个个独立的词语。
-
词干提取:对于英文单词,可以进行词干提取,将其转化为词干形式,例如将“running”和“ran”都转化为“run”。这样可以减少冗余的索引项。
-
停用词过滤:对于一些常见的词语,例如“a”、“the”、“and”等,可以将其过滤掉。这些词语虽然出现频率高,但对于搜索来说没有太多的意义。
-
倒排索引的构建:根据分词后得到的词语,建立倒排索引表。倒排索引表一般以词语为键,以包含该词语的文档列表为值。
-
索引压缩:对于大规模的索引数据,为了减少存储空间的占用,可以对索引进行压缩。常见的压缩方法包括词典压缩、倒排列表压缩等。
-
索引的持久化存储:将建好的索引进行持久化存储,以便后续的检索操作。
以上是倒排索引的主要建立过程,Nutch会按照这个流程进行索引的构建,使得用户可以方便地根据关键词进行检索。
2.2.3 索引的存储与管理
Nutch的索引部分负责将爬取到的网页数据进行索引存储和管理。它的工作流程如下:
-
网页解析与提取:首先,Nutch使用解析器和过滤器对爬取到的网页进行解析和提取。解析器将网页的HTML代码转换为结构化数据,包括网页标题、正文、链接等信息;过滤器则根据配置的规则对网页进行过滤,例如去除重复的URL、过滤非文本内容等。
-
索引创建与更新:接下来,Nutch使用创建器和更新器将解析提取到的网页数据存储到索引中。索引创建器负责创建索引文件,并将网页数据按照一定的结构存储到索引文件中;索引更新器则负责将新爬取到的网页数据添加到已有的索引文件中。
-
索引存储与管理:Nutch的索引存储与管理部分负责管理索引文件的存储和维护。索引文件可以通过不同的存储方式来存储,例如本地文件系统、Hadoop分布式文件系统等。索引文件可以分为多个分片,每个分片存储一部分网页数据。索引存储与管理部分可以根据需要进行索引的合并、压缩、删除等操作,以优化索引的性能和存储空间。
总的来说,Nutch的索引部分通过解析和提取网页数据,并将其存储到索引文件中,实现了对爬取到的网页数据的索引和查询功能。同时,索引存储与管理部分负责对索引文件进行存储和维护,以保证索引的性能和可用性。
2.3 查询部分
2.3.1 用户查询接口与交互
Nutch的查询部分包括用户查询接口和交互。用户查询接口是用户与搜索引擎系统进行交互的入口,用户可以通过查询接口输入关键词或者其他查询条件来发起查询请求。查询接口接收用户的输入,并将其传递给搜索引擎系统的后端进行处理。
在Nutch的工作流程中,查询部分的工作流程如下:
- 用户发起查询请求,输入关键词或者其他查询条件。
- 查询接口接收到用户的请求。
- 查询接口将用户的请求传递给搜索引擎系统的后端进行处理。
- 后端根据用户的请求进行索引查询或者其他相关操作。
- 后端将查询结果返回给查询接口。
- 查询接口将查询结果呈现给用户。
查询部分的用户接口和交互可以根据具体的需求进行定制和开发。在Nutch中,用户接口可以是一个简单的网页搜索框,用户通过在搜索框中输入关键词来发起查询请求。用户也可以通过API调用来直接与搜索引擎系统进行交互。查询接口可以根据用户的输入,进行输入验证和格式化处理,确保查询请求的正确性。查询接口也可以提供查询建议和自动补全功能,帮助用户进行精确的查询。
在查询结果的交互方面,查询接口可以将查询结果进行排名和分类,并提供分页功能,以方便用户浏览和筛选结果。查询接口也可以提供相关搜索功能,根据用户的查询意图推荐相关的查询条件和搜索结果。
总之,Nutch的查询部分通过用户查询接口和交互,提供了用户与搜索引擎系统进行交互的入口,使用户能够发起查询请求并获取相关的查询结果。
2.3.2 查询语句的分析与处理
在Nutch中,查询部分负责接收用户的查询请求并根据查询语句从索引中检索出相关的文档。
首先,查询语句需要经过一系列的分析与处理来提取关键词并生成查询表达式。这个过程通常包括以下几个步骤:
-
分词:将查询语句拆分成单词或短语。这可以使用Nutch内置的分词器或第三方的分词库来实现。
-
去停用词:去掉常见的无实际含义的单词,比如"的"、"是"等。
-
处理同义词:将查询语句中的同义词转换成标准词或原始词,以便在索引中找到相关的文档。
-
权重设置:根据查询语句中关键词的重要程度,为每个关键词设置一个权重值。这可以根据相关性算法来确定。
-
构建查询表达式:将处理后的关键词和权重组合成一个查询表达式,通常使用布尔逻辑运算符(AND、OR)来连接关键词。
完成上述分析和处理后,查询部分将使用生成的查询表达式与索引中存储的文档进行匹配,找到与查询语句相关的文档。匹配过程通常包括以下几个步骤:
-
查询解析:将查询表达式解析成可被索引库理解的格式,如Lucene查询语法。
-
查询优化:根据查询语句的特性和索引库的配置,对查询进行一些优化,例如使用缓存或索引片段合并等。
-
查询扫描:根据查询表达式,在索引库中进行扫描并找到与查询符合的文档。
-
结果排序:根据相关性算法和查询语句中关键词的权重,为查询结果进行排序,以便返回最相关的文档。
-
结果返回:将查询结果返回给用户,通常以列表或页面的形式呈现。
总的来说,Nutch的查询部分将用户的查询语句进行分析与处理,生成查询表达式后与索引库中的文档进行匹配,最终返回与查询相关的文档给用户。
2.3.3 结果排序与展示
在Nutch的查询部分,结果排序与展示是其中一个重要的环节。当用户提交一个查询时,Nutch将使用索引中的相关数据来检索与查询相匹配的文档,并根据一定的算法对结果进行排序。排序的目标是将最相关的文档排在前面,以便用户可以更快地找到他们感兴趣的内容。
Nutch使用的结果排序算法通常基于文档的相关性和其他一些因素来进行计算。常见的排序算法包括TF-IDF(词频-逆文档频率)和PageRank等。TF-IDF衡量了一个词在文档中的重要程度,PageRank则考虑了网页之间的链接关系,将链接较多、被其他网页引用的文档排在前面。
在排序后,Nutch会将排序的结果展示给用户。展示的方式通常是以搜索结果页面的形式呈现,其中包含了每个搜索结果的标题、摘要和相关链接等信息。用户可以根据这些信息来判断哪些结果是最相关的,并点击相应的链接进一步查看详细内容。
总的来说,Nutch的查询部分通过排序算法和结果展示,使用户能够获得与查询相关的最优结果,并提供便捷的方式进行导航和浏览。
三、Nutch的工作原理深入解析
详见《探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(二)》
四、Nutch的无限应用可能
详见《探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(二)》
五、Nutch的优化与扩展
详见《探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(三)》
六、结论与展望
详见《探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(三)》
七、结语
通过Nutch的工作原理和应用,我们可以看到,在当今信息爆炸的时代,搜索引擎的作用是不可忽视的。Nutch提供了一个可定制和可扩展的搜索引擎框架,可以应用于各种场景和需求。无论是企业内部的知识管理,还是互联网上的信息搜索,Nutch都具备良好的性能和灵活性。
Nutch作为一款开源搜索引擎,其工作原理和无限应用可能性正不断为我们带来新的发现和创新。通过不断地研究和改进,我们相信Nutch将在搜索引擎领域继续发挥重要作用,为用户提供更好的搜索和信息获取体验。
相关文章:
)
探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(一)
本系列文章简介: 本系列文章将带领大家深入探索Nutch的世界,从其基本概念和架构开始,逐步深入到爬虫、索引和查询等关键环节。通过了解Nutch的工作原理,大家将能够更好地理解搜索引擎背后的原理,并有能力利用Nutch构建…...
MySQL 数据库 下载地址 国内阿里云站点
mysql安装包下载_开源镜像站-阿里云 以 MySQL 5.7 为例 mysql-MySQL-5.7安装包下载_开源镜像站-阿里云...
)
【25届秋招备战C++】算法篇-贪心算法(Greedy)
【25届秋招备战C】算法篇-贪心算法 一、简介二、解题思路三、应用场景四、模板函数五、参考 一、简介 一种在每次决策时,总是采取在当前状态下的最好选择,从而希望导致结果是最好或最优的算法。通常用于解决一些最优化问题,如找零问题、霍夫…...
scrcpy远程投屏控制Android
下载 下载后解压压缩包scrcpy-win64-v2.4.zip scrcpy连接手机 1. 有线连接 - 手机开启开发者选项,并开启USB调试,连接电脑,华为手机示例解压scrcpy,在scrcpy目录下打开终端,(或添加scrcpy路径为环境变…...

找机厅 洛谷 BFS
P10234 [yLCPC2024] B. 找机厅 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) #include<bits/stdc.h> #define pii pair<int,int> #define fr first #define sc second using namespace std; string maze[2000]; int vis[2000][2000]; char dirs[2005][2005]; st…...
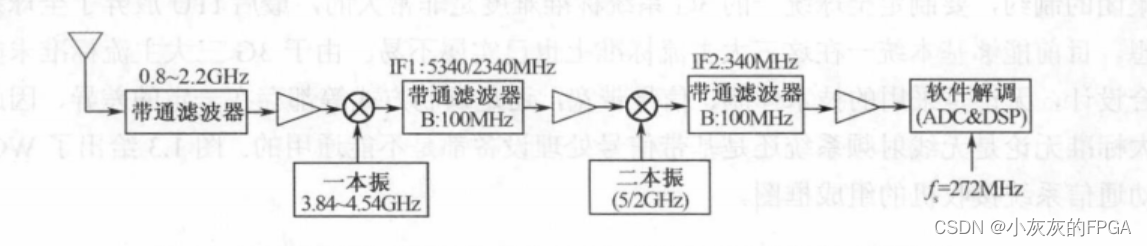
软件无线电系列——模拟无线电、数字无线电、软件无线电
本节目录 一、模拟无线电 二、数字无线电 1、窄带数字无线电 2、宽带数字无线电 三、软件无线电本节内容 一、模拟无线电 20世纪80年代的模拟体制(美国的AMPS/欧洲的TACS)被称为第一代移动通信,简称1G,主要目标是为在大范围内有限的用户提供移动电话服务。最主要的…...
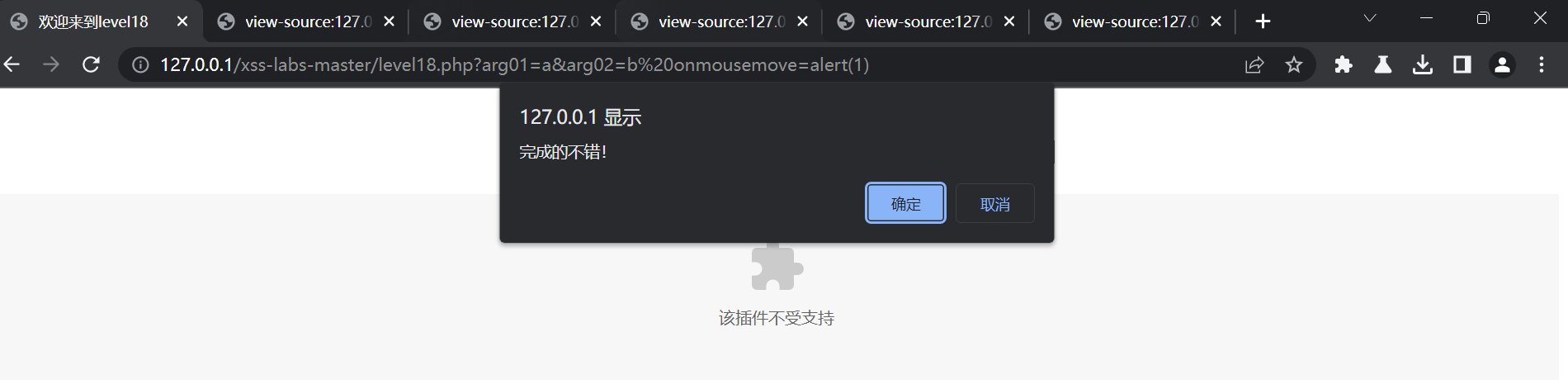
XSS_lab(level11-level18)
level11: 还是url这里,输入:<script>alert(1)</script> 与上一题相似 构建:?t_link1&t_history2&t_sort3&t_ref4 我们发现t_sort是可用的 构建:?t_sort1" type"button" οnclickalert(1) // 把双引号过滤了 这里无法使用实体编码…...

【git】常用操作
基础操作 git init 初始化仓库 要使用 Git 进行版本管理,必须先初始化仓库, 执行了 git init命令的目录下就会生成 .git 目录。这个 .git 目录里存储着管理当前目录内容所需的仓库数据 git status 查看仓库状态 工作树和仓库在被操作的过程中࿰…...

蓝桥杯第十一届电子类单片机组程序设计
目录 前言 单片机资源数据包_2023(点击下载) 一、第十一届比赛原题 1.比赛题目 2.赛题解读 1)计数功能 2)连续按下无效按键 二、部分功能实现 1.计数功能的实现 2.连续按下无效按键的处理 3.其他处理 1)对于…...

Java中文乱码问题解析与解决方案
在日常工作中,我们经常会遇到中文乱码的问题。乱码问题不仅影响用户体验,还可能导致数据丢失或解析错误。因此,了解和掌握中文乱码问题的原因和解决方案,对于Java开发者来说至关重要。本文将分析常见的Java中文乱码场景࿰…...
AIGC笔记--Maya提取和修改FBX动作文件
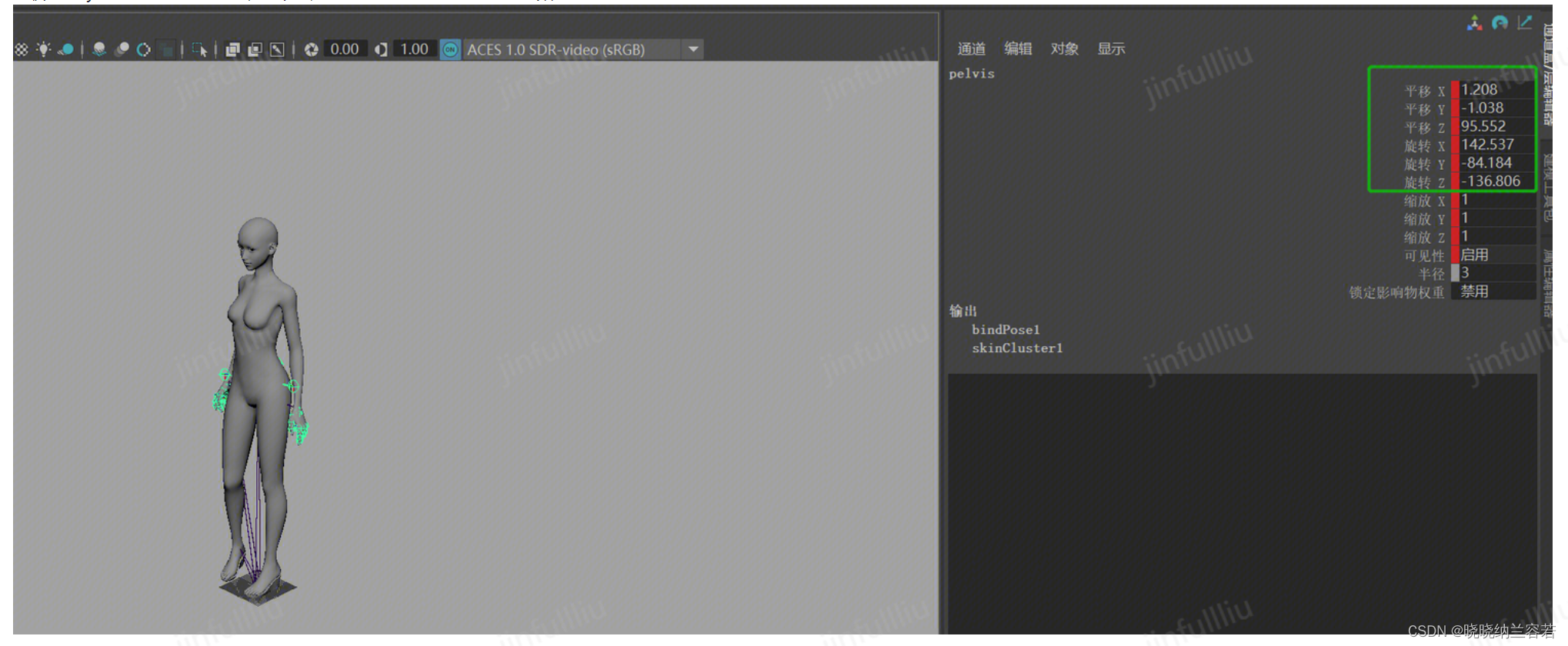
目录 1--Maya数据解析 2--FBX SDK导出6D数据 3--6D数据映射和Maya可视化 完整项目代码:Data-Processing/FBX_SDK_Maya 1--Maya数据解析 在软件Maya中直接拖入FBX文件,可以播放和查看人体各个骨骼关节点的数据: 对于上图来说,…...

【刷题训练】LeetCode125. 验证回文串
验证回文串 题目要求 示例 1: 输入: s “A man, a plan, a canal: Panama” 输出:true 解释:“amanaplanacanalpanama” 是回文串。 示例 2: 输入:s “race a car” 输出:false 解释:“rac…...

optee默认安全配置
OP-TEE(Open Portable Trusted Execution Environment)是一个开源的可移植的可信执行环境(TEE),用于提供安全和受保护的执行环境。它旨在为基于 ARM 架构的设备提供强大的安全性和隔离能力。 OP-TEE 主要由两部分组成…...

Arcgis新建位置分配求解最佳商店位置
背景 借用Arcgis帮助文档中的说明:在本练习中,您将为连锁零售店选择可以获得最大业务量的商店位置。主要目标是要将商店定位在人口集中地区附近,因为这种区域对商店的需求量较大。设立这一目标的前提是假设人们往往更多光顾附近的商店,而对于距离较远的商店则较少光顾。您…...
【C++初阶】C++入门(上)
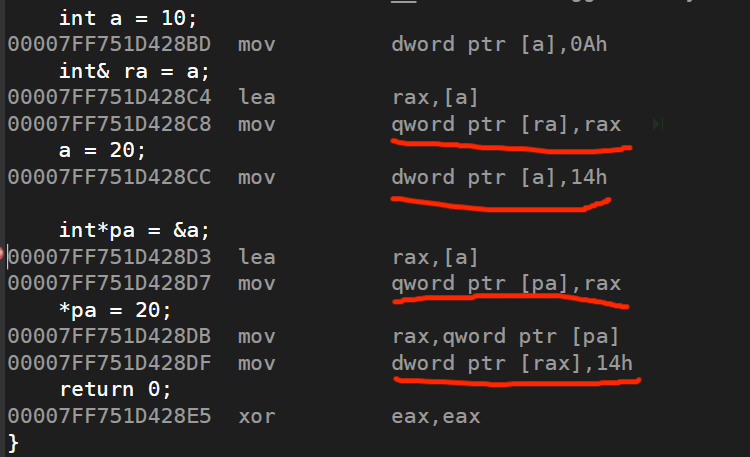
C的认识 ①什么是C? C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。 于是1982年,Bjarne Stroustrup(本…...

Vue.js+SpringBoot开发校园疫情防控管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 学生2.2 老师2.3 学校管理部门 三、系统展示四、核心代码4.1 新增健康情况上报4.2 查询健康咨询4.3 新增离返校申请4.4 查询防疫物资4.5 查询防控宣传数据 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBoot…...
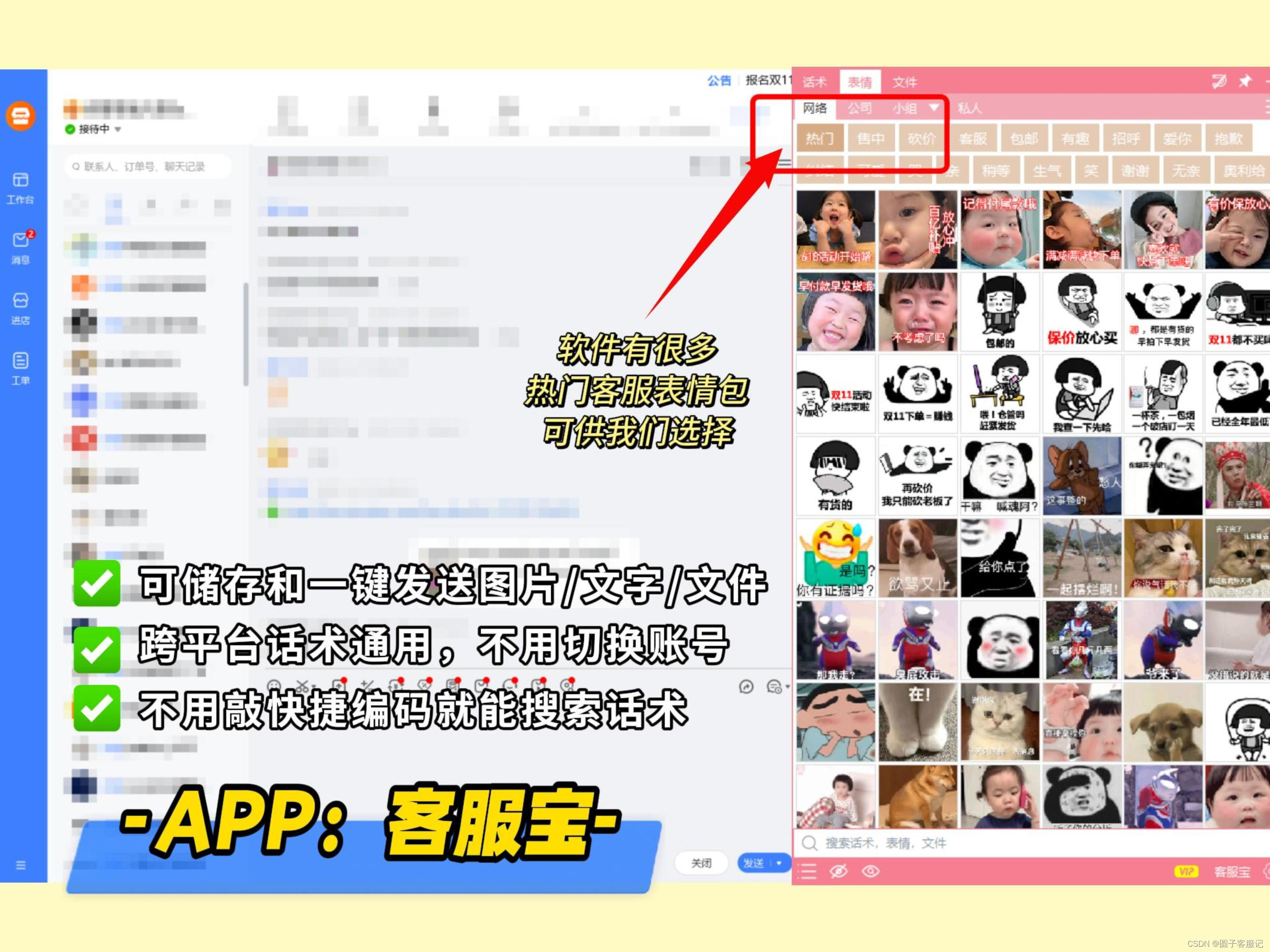
客服销冠偷偷用的提效神器!无广很实用
近期发现我的同事每天上班必登录的一款软件——客服宝聊天助手,用过才发现:真客服办公的提效神器!感兴趣的小伙伴请往下看~一、客服宝的简介:客服宝聊天助手,是一款跨平台快捷回复工具。自带多种功能,有效帮…...
蓝桥杯刷题|02入门真题
[蓝桥杯 2022 省 B] 刷题统计 题目描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a 道题目,周六和周日每天做 b 道题目。请你帮小明计算,按照计划他将在第几天实现做题数大于等于 n 题? 输入格式 输入一行包含三个整数…...

Jenkins cron定时构建触发器
from: https://www.jenkins.io/doc/book/pipeline/syntax/#cron-syntax 以下内容为根据Jenkins官方文档cron表达式部分翻译过来,使用机翻加个人理解补充内容,包括举例。 目录 介绍举例:设置方法方法一:方法二…...

【编程向导】JavaScript-创建对象一期讲解
工厂模式 工厂模式 是用来创建对象的一种最常用的设计模式。工厂模式不暴露创建对象的具体逻辑,而是将逻辑封装在一个函数中,那么这个函数就可以被视为一个工厂。工厂模式常见于大型项目,例如 jQuery 的 $ 对象,我们创建选择器对…...

Go从零手写神经网络:纯标准库实现全连接BP网络
1. 项目概述:为什么用 Go 从零手写一个神经网络?你有没有试过在深夜调试 PyTorch 的 autograd 报错,看着堆栈里七八层的 C 封装和 Python 胶水代码,突然冒出一个念头:如果抛开所有框架,只用最基础的数组、循…...

85%企业将淘汰纯业务程序员!2026年前,大模型才是你的职业救命稻草!
文章指出传统技术岗面临淘汰风险,85%企业计划在2026年前淘汰纯业务型程序员。未来职场核心竞争力在于掌握大模型技术。文章强调大模型技术是技术人的时代红利,提供从入门到精通的全套视频教程,涵盖提示词工程、RAG、Agent等技术点。文章还分析…...
)
SeaweedFS S3网关实战:用s3cmd管理你的对象存储(从配置到常用命令)
SeaweedFS S3网关实战:从零构建高效对象存储工作流 在云原生技术蓬勃发展的今天,轻量级、高性能的对象存储解决方案正成为开发者工具箱中不可或缺的一环。SeaweedFS凭借其简洁的架构和出色的性能,逐渐在中小规模存储场景中崭露头角。本文将带…...

汽车12V电源防护:P6KE TVS二极管选型、设计与实战指南
1. 项目概述:汽车电源线上的“隐形保镖”在汽车电子系统的设计里,12V直流电源线是整车的能量动脉,从蓄电池到ECU(发动机控制单元)、从车身控制器到娱乐系统,几乎所有的电子模块都离不开它。但这条“动脉”所…...

如何用嘎嘎降AI处理土木工程论文:土木工程研究生毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理土木工程论文:土木工程研究生毕业论文降AI4.8元完整操作教程 关于土木工程论文降AI教程,有几个细节提前知道能少走很多弯路。 核心用嘎嘎降AI(www.aigcleaner.com),4.8元,达标率99.26%…...

WorldArena榜单第一名Pelican-Unify 1.0:迈向具身智能统一范式的新里程碑
北京人形机器人创新中心团队发布首个统一理解、推理、想象与行动的具身基础模型 2026年5月 | 技术解读 图1 Pelican-Unify 1.0 统一具身智能模型概览:理解、推理、想象与行动的闭环融合 一、具身智能的范式演进:从模块化到统一化 具身智能(…...

达梦数据库-收缩数据库表空间步骤及示例记录总结
1达梦数据库-收缩数据库表空间步骤及示例记录总结 注:收缩表空间,如果空闲空间都在尾部,可以直接收缩成功,如果尾部不空闲,中部空闲,则需要移走使用尾部的表后再收缩,生产环境,如果…...

避坑指南:S32K3 AUTOSAR环境安装后,如何验证MCAL配置与工程创建?
S32K3 AUTOSAR开发实战:从环境验收到MCAL配置全流程解析 当S32DS、EB tresos和RTD驱动安装完成后,许多开发者会陷入"工具链已就位,但不知从何入手"的困境。本文将带您跨越从环境安装到可编译工程的关键步骤,重点解决三个…...

终极解决方案:三分钟掌握全网资源下载神器res-downloader
终极解决方案:三分钟掌握全网资源下载神器res-downloader 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在为无…...

3分钟实现网页图片格式自由转换:Chrome扩展终极指南
3分钟实现网页图片格式自由转换:Chrome扩展终极指南 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors/sa/Save-Ima…...