【扩散模型(一)】综述:扩散模型在文本生成领域应用
一、论文信息
1 标题
Diffusion models in text generation: a survey
2 作者
Qiuhua Yi, Xiangfan Chen, Chenwei Zhang, Zehai Zhou, Linan Zhu, Xiangjie Kong
3 研究机构
1 College of Computer Science and Technology, Zhejiang University of Technology, HangZhou, China
2 School of Faculty of Education, University of Hong Kong, Hong Kong, China
二、主要内容
这篇论文是一项关于扩散模型在文本生成领域应用的综合调查研究。论文首先介绍了扩散模型的背景和发展,然后详细探讨了扩散模型在条件文本生成、无约束文本生成和多模态文本生成三个部分的应用。此外,论文还对扩散模型和基于自回归的预训练模型(PLMs)进行了多维度的详细比较,突出了它们各自的优势和局限性。论文认为将PLMs集成到扩散模型中是一个有价值的研究方向,并讨论了扩散模型在文本生成中面临的当前挑战,提出了潜在的未来研究方向,例如提高采样速度以解决可扩展性问题和探索多模态文本生成。
在论文的引言部分,作者详细介绍了扩散模型的发展历程,从最初的概念提出到在图像生成领域的应用,再到自然语言处理(NLP)领域的探索。以下是扩散模型发展的主要阶段:
-
起源(2015年):扩散模型的概念最早可以追溯到2015年,当时Sohl-Dickstein等人提出了扩散概率模型(DPM)。然而,在接下来的几年中,这些模型并没有得到广泛的开发和应用。
-
图像生成领域的突破(2020年):Google的研究者在2020年对模型的细节进行了改进,引入了去噪扩散概率模型(DDPM),并将它们应用于图像生成领域,逐渐将扩散模型引入了研究者的视野。
-
进一步的改进(2020年后):在DDPM之后,去噪扩散隐式模型(DDIM)进一步改进了DDPM的去噪过程,为后续的扩散模型奠定了基础。
-
在NLP领域的应用:扩散模型在图像和音频生成领域取得成功后,研究者开始探索将其应用于NLP领域。由于文本数据的离散性与图像数据的连续性不同,研究者提出了两种主要方法来解决这一挑战:一种是通过嵌入层将离散文本映射到连续表示空间;另一种是保留文本的离散性,并将扩散模型推广到处理离散数据。
-
文本生成的进展:在过去两年中,扩散模型在文本生成任务中取得了显著的成果。例如,通过条件图像生成方法,Palette展示了扩散模型在图像到图像翻译中的巨大潜力。此外,GLIDE、DALL·E 2和Imagen等模型在文本到图像生成领域取得了新的最先进结果。
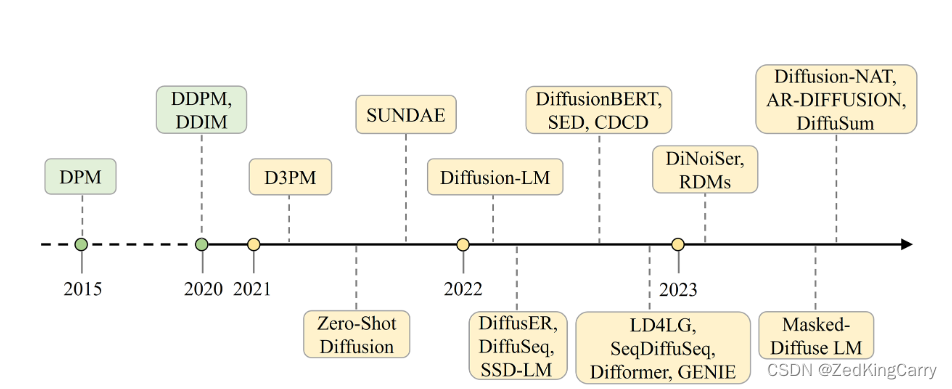
引言部分强调了扩散模型在生成连续空间内容(特别是图像和音频)方面的成功,并探讨了如何将这些模型适应于文本生成任务,指出了在NLP领域应用扩散模型所面临的挑战和取得的进展。
三、相关研究
论文提到了多种深度学习生成模型,包括变分自编码器(VAE)、生成对抗网络(GANs)、基于流的生成模型和扩散模型。特别指出,扩散模型在图像和音频生成领域取得了巨大成功,并且已经开始应用于自然语言处理(NLP)领域。
文本生成任务的细分子任务:
模式下,论文详细介绍了多种扩散模型及其在文本生成任务中的应用。以下是这些模型的详细介绍及其内容:
文本驱动的生成
-
DiffuSeq:这是一个开创性的模型,它将扩散模型应用于序列到序列(SEQ2SEQ)文本生成任务。DiffuSeq 引入了部分噪声的概念,即有选择地对目标序列施加高斯噪声,同时保留源句子嵌入的完整性。这种方法允许对目标文本进行受控的破坏,从而增强生成过程。
-
DiffuSum:DiffuSum 扩展了条件扩散模型的应用,特别是在文本摘要任务中。与 DiffuSeq 类似,DiffuSum 也使用部分噪声,但它进一步加入了匹配损失和多类别对比损失等组件,以提高生成文本的质量和相关性。
-
DiffusER:DiffusER 与传统扩散模型不同,它将文本编辑操作(如插入、删除和编辑)视为噪声的形式。这种方法充分考虑了文本的离散特性,使得生成的文本更加灵活和多样化。
-
SeqDiffuSeq:这是一个基于编码器-解码器Transformer架构的模型,它结合了自适应噪声计划和自条件技术,显著提高了文本生成的质量和速度。自适应噪声计划允许模型根据生成过程中的需要调整噪声水平,而自条件技术则使得模型能够在生成过程中利用先前生成的文本作为条件。
-
Zero-Shot Diffusion:这个模型首次将扩散模型应用于条件文本生成任务。它受到编码器-解码器架构的启发,将源语言句子作为条件输入到Transformer编码器中,并将带噪声的目标语言句子输入到解码器中。
-
GENIE:GENIE 是一个大规模预训练的扩散语言模型,它使用掩蔽源序列作为编码器的输入,并结合了连续段落去噪训练方法。GENIE 展示了在生成高质量和多样性文本方面的有效性,为各种自然语言处理任务开辟了新的可能性。
-
RDMs (Reparameterized Diffusion Models):RDMs 引入了重参数化和随机路由机制,简化了训练过程,并提供了灵活的采样方法。然而,目前 RDMs 只能生成固定长度的句子。
-
Diffusion-NAT:Diffusion-NAT 将离散扩散模型(DDM)和 BART 结合起来,用于非自回归文本生成。它将推理和去噪过程统一为一个掩蔽标记恢复任务,专注于条件文本生成任务。
-
CDCD (Continuous Denoising Diffusion):CDCD 通过引入得分插值和时间扭曲技术,改进了扩散模型的训练过程,在语言建模和机器翻译任务中取得了优异的性能。
-
DiNoiSer:DiNoiSer 认为,仅仅通过嵌入将离散标记映射到连续空间并不足以消除文本的离散性质。因此,DiNoiSer 使用自适应噪声水平和放大噪声规模来进行反离散训练,利用源条件来提高多个条件文本生成任务的性能。
-
Difformer:Difformer 是一个基于 Transformer 架构的去噪扩散模型,它通过引入锚定损失函数、嵌入层的层归一化模块以及高斯噪声的噪声因子,解决了连续嵌入空间中扩散模型的挑战。
-
AR-DIFFUSION:AR-Diffusion提出了一个多级扩散策略和动态移动速度,能够即使在很少的解码步骤下也展现出强大的性能,它提供了一种新的视角,将传统的自回归方法与扩散模型的优势结合起来。
这些模型展示了扩散模型在条件文本生成任务中的多样性和潜力,它们通过不同的方法和技术创新地解决了生成过程中的挑战,提高了生成文本的质量和多样性。
细粒度可控文本生成
细粒度控制生成(Fine-grained control generation)是一种文本生成方法,它接受细粒度的控制条件(如情感、主题、风格等)作为输入,并且引入了一个条件变量 ( c ),用来表示控制属性:
-
Diffusion-LM:是一个基于连续扩散的可控语言模型,它已经被成功应用于六种细粒度控制生成任务。Diffusion-LM 在处理各种控制文本生成任务时,尽管在困惑度、解码速度和收敛速度方面还有优化和改进的空间,但它展示了扩散模型在提高文本生成任务中的可控性方面的潜力。
-
Masked-Diffuse LM:这个模型受到语言学特征的启发,提出了在前向过程中应用策略性软遮蔽来破坏文本,并通过对直接文本预测进行迭代去噪的方法。与 Diffusion-LM 相比,这个模型通过五项可控文本生成任务展示了更低的训练成本和更好的性能。
-
Latent Diffusion Energy-Based Model (LDEBM):这个模型结合了扩散模型和潜在空间能量模型,使用扩散恢复似然学习来解决采样质量和不稳定性问题。在多个具有挑战性的任务中,如条件响应生成和情感可控生成,LDEBM 展示了卓越的解释性文本建模性能。
这些方案展示了细粒度控制生成的多样性和灵活性,允许模型根据特定的控制条件生成具有特定属性的文本。这种方法为生成具有特定情感色彩、主题或风格的文本提供了新的可能性,并且在自然语言处理的多个领域中都有着广泛的应用前景。
无约束文本生成
无约束文本生成(Unconstrained text generation)是指模型基于训练语料库生成文本,而不依赖于特定的主题或长度限制。以下是论文中提到的无约束文本生成方法的介绍:
-
D3PM (Discrete Denoising Diffusion Models):
- D3PM 开发了一种结构化的分类腐败过程,通过使用标记之间的相似性来实现渐进式腐败和去噪。
- 该模型通过插入 (MASK) 标记来与自回归和基于掩蔽的生成模型建立联系,实现了在字符级文本生成上的强结果,并扩展到大型词汇表(如 LM1B)。
-
DiffusionBERT:
- DiffusionBERT 创造性地提出使用 BERT 作为其骨干来执行文本生成,结合了预训练模型(PLMs)与离散文本的离散扩散模型。
- 该模型针对无条件文本生成问题,特别是在非自回归模型中,展示了在困惑度和 BLEU 分数上的显著改进。
这两种方法展示了扩散模型在无约束文本生成任务中的应用,它们通过不同的技术手段来生成流畅、连贯且有意义的文本,同时也提供了对生成结果多样性的探索。这些模型的提出和应用,为未来的文本生成研究提供了新的方向,尤其是在提高生成质量和多样性方面。
多模态文本生成
多模态文本生成(Multi-mode text generation)是指能够同时处理多种文本生成任务的扩散模型,这些任务可能包括条件文本生成、无约束文本生成,以及其他可能的文本生成模式。以下是论文中提到的多模态文本生成模型的介绍:
-
Self-conditioned Embedding Diffusion (SED):
- SED 提出了一种名为自条件嵌入的连续扩散机制,这种机制学习了一个灵活且可扩展的扩散模型,适用于条件和无条件文本生成。
- 该模型支持文本填充,为探索嵌入空间设计和填充能力奠定了基础。
-
Step-unrolled Denoising Autoencoder (SUNDAE):
- SUNDAE 引入了基于自编码器的展开去噪训练机制,与常规去噪方法相比,它需要更少的迭代次数来收敛。
- 该模型在机器翻译和无条件文本生成任务中表现出良好的性能,并且打破了自回归的限制,可以填补模板中的任意空白模式,为文本编辑和文本修复开辟了新的途径。
-
Latent Diffusion for Language Generation (LD4LG):
- LD4LG 与其他将离散文本通过嵌入转换为连续空间的工作不同,它学习了在预训练语言模型的潜在空间上进行扩散的过程。
- 该框架从无条件文本生成扩展到了条件文本生成,提供了一种新的方法来处理文本生成任务。
-
Semi-autoregressive Simplex-based Diffusion Language Model (SSD-LM):
- SSD-LM 是一种半自回归的扩散语言模型,它在自然词汇空间上执行扩散,通过设计特征实现了灵活的输出长度和模块化控制。
- 在无约束和控制文本生成任务上,SSD-LM 在质量和多样性方面优于自回归基线模型。
这些多模态文本生成模型展示了扩散模型在处理多种文本生成任务方面的潜力和灵活性。它们通过结合不同的生成策略和技术,为生成多样化和高质量的文本提供了新的可能性,并为未来的文本生成研究提供了新的视角和方向。
五、文本扩散模型与预训练语言模型的对比
文本扩散模型和预训练语言模型(PLMs)是两种不同的文本生成方法,它们在多个维度上有着各自的特点和优势。以下是论文中对这两种模型进行的对比:
生成方法
- PLMs:通常采用自回归方法进行文本生成,通过时间序列预测技术,基于先前内容预测下一个可能的词。
- 扩散模型:在NLP中的生成方法与传统自回归方法不同,它们首先通过不断添加噪声(通常是高斯噪声)来获得一个完全不可见的噪声分布,然后通过迭代去噪产生词向量。
处理离散文本
- PLMs:由于文本的离散特性,将单词放入NLP模型中需要特殊处理,主要包括独热编码、分布式表示、词袋表示和词嵌入表示。
- 扩散模型:离散文本扩散模型在处理离散扩散模型时,会将不同标记映射到转换矩阵,而连续文本扩散模型则通过嵌入技术将离散文本编码到连续向量空间。
时间复杂度
- PLMs:预训练语言模型的时间复杂度与模型层数、隐藏层维度、注意力头数和训练数据大小等因素有关。
- 扩散模型:扩散模型的时间复杂度通常与采样步数和模型复杂度有关,可能需要多个迭代来从噪声中恢复文本。
生成结果的多样性
- PLMs:由于倾向于选择概率高的词,可能产生相对保守和相似的生成结果。
- 扩散模型:通过引入更多的随机性,生成的文本倾向于展示多样性。
生成方向
- PLMs:自回归模型按照从左到右、逐词的模式生成文本。
- 扩散模型:生成过程从一个原始句子开始,通过添加噪声和迭代去噪来生成句子,这种方法引入了固有的随机性,增强了生成结果的多样性。
总的来说,PLMs和扩散模型在文本生成领域都有其独特的优势和局限性。PLMs在生成质量和生成速度方面表现出色,而扩散模型则在生成多样性方面具有显著优势。根据具体的应用场景和任务需求,可以选择合适的模型来达到最佳的生成效果。
六、进一步探索点:
论文中提出了几个关于扩散模型在文本生成领域的未来研究方向,这些方向为研究者提供了进一步探索的可能性。以下是这些潜在的探索点:
-
零样本任务(Zero-shot tasks):
- 扩散模型作为一种基于概率推断的生成模型,可以在零样本问题上利用训练阶段学到的数据分布特征和先验知识来生成新样本。
- 在NLP领域,可以探索使用扩散模型进行零样本翻译问题,以及在控制生成中满足特定条件的能力。
-
多模态扩散模型(Multimodal diffusion models):
- 构建统一的多模态扩散模型,探索不同模态之间的互补性和相关性,以获得更准确和全面的信息。
- 扩散模型已经能够处理来自不同模态(文本、图像、音频等)的数据,未来的研究可以集中在如何更好地整合这些模态,以提高任务性能,如情感分析、视觉问答和图像描述。
-
与预训练语言模型的结合(Combination with PLMs):
- 探索更高效的将扩散模型与预训练模型结合的方法,例如利用上下文学习、提示学习等技术。
- 结合预训练模型的语言建模能力和扩散模型的生成多样性,可能会产生新的文本生成范式。
-
加速采样过程(Speeding up sampling):
- 设计专门的采样策略或借鉴计算机视觉领域成功的采样策略,以提高扩散模型的采样效率。
- 提高采样速度可以减少生成文本所需的时间,使模型更适合实时或高性能要求的应用场景。
-
设计嵌入空间(Designing embedding space):
- 探索更好的嵌入空间设计策略,以确保原始数据得到适当的表示,避免损失函数崩溃。
- 嵌入空间的学习对于模型性能至关重要,需要研究如何更好地指导嵌入空间的学习过程。
除了上述探索点,我认为扩散模型在文本生成上还有以下探索空间:
- 模型可解释性:提高扩散模型的可解释性,使其生成过程更加透明,用户能够理解模型的决策过程。
- 控制生成质量:研究如何在保持生成多样性的同时,提高生成文本的准确性和一致性。
- 跨语言和跨文化适应性:探索扩散模型在不同语言和文化背景下的适应性和生成能力。
- 长期依赖问题:解决在长文本生成中保持长期依赖关系的问题,确保文本的连贯性和逻辑性。
- 实时交互应用:针对实时交互式应用(如聊天机器人),优化扩散模型以满足低延迟和高响应性的需求。
扩散模型在文本生成上的研究仍处于相对早期阶段,未来有很多机会可以进一步探索和发展。随着技术的进步和新算法的提出,扩散模型有望在多种文本生成任务中发挥更大的作用。
七、总结
这篇论文提供了一个关于扩散模型在文本生成任务中应用的全面概述,总结了最新的研究进展,并从新颖的文本生成任务分类角度对研究进行了分类和总结。论文还从多个角度区分了扩散模型和预训练语言模型,并详细阐述了现有挑战和预期的未来研究方向,为相关领域的研究人员提供了有价值的见解。
相关文章:
【扩散模型(一)】综述:扩散模型在文本生成领域应用
一、论文信息 1 标题 Diffusion models in text generation: a survey 2 作者 Qiuhua Yi, Xiangfan Chen, Chenwei Zhang, Zehai Zhou, Linan Zhu, Xiangjie Kong 3 研究机构 1 College of Computer Science and Technology, Zhejiang University of Technology, HangZho…...

K8S Pod
基本概念 Pod是K8S中非常重要的概念之一,是整个K8S架构的基础和核心。Pod是K8S调度的最小单位,是一个不可拆分的独立个体,K8S将多个业务上相关联的容器(Docker容器)合并到一起,组合成一个Pod,这…...

反向传播(backward propagation,BP) python实现
BP算法就是反向传播,要输入的数据经过一个前向传播会得到一个输出,但是由于权重的原因,所以其输出会和你想要的输出有差距,这个时候就需要进行反向传播,利用梯度下降,对所有的权重进行更新,这样…...

简单算命脚本
效果展示 文件内容 main.py文件 import json import random import time# 别挂配置数据 gua_data_path "data.json"# 别卦数据 gua_data_map {} fake_delay 10# 读取别卦数据 def init_gua_data(json_path):with open(gua_data_path, r, encodingutf8) as fp:gl…...

Lua-掌握Lua语言基础1
Lua是一种轻量级的脚本语言,广泛应用于游戏开发、嵌入式系统和其他领域。下面是Lua语言基础的介绍: 数据类型:Lua支持基本的数据类型,包括nil、boolean、number、string和table。其中,table是一种关联数组,…...
python-0003-pycharm开发虚拟环境中的项目
前言 在虚拟环境中创建好了python项目,使用pycharm进行开发 打开项目 使用pycharm打开项目 设置虚拟环境的解释器 File–>Settings–>Project(项目名)–>Python Interpreter–>添加解释器–>添加已经存在的解释器–>选择虚拟环境的解释器 …...
修改 MySQL update_time 默认值的坑
由于按规范需要对 update_time 字段需要对它做默认值的设置 现在有一个原始的表是这样的 CREATE TABLE test_up (id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 主键id,update_time datetime default null COMMENT 操作时间,PRIMARY KEY (id) ) ENGINEInnoDB DEF…...
基于亚马逊云EC2+Docker搭建nextcloud私有化云盘
亚马逊云科技EC2云服务器(Elastic Compute Cloud)是亚马逊云科技AWS(Amazon Web Services)提供的一种云计算服务。EC2代表弹性计算云,它允许用户租用虚拟计算资源,包括CPU、内存、存储和网络带宽࿰…...

用try...catch进行判断
在写一些提交数据的判断上,有时候会写下面的ifelse的判断方法,少一点还好,多的话就很难受也不好看。 if(!that.driverObj.contrary){this.__utils.showToast(请先上传驾驶证副页图片);return false } if(!this.driverObj.start){this.__util…...
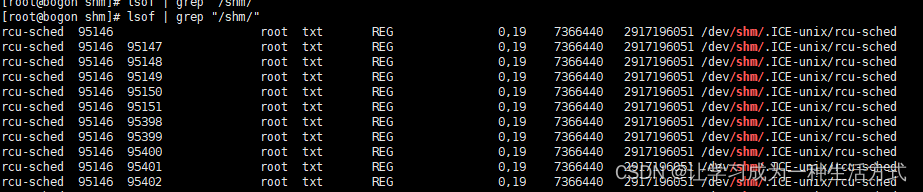
服务器遭遇挖矿病毒syst3md及其伪装者rcu-sched:原因、症状与解决方案
01 什么是挖矿病毒 挖矿病毒通常是恶意软件的一种,它会在受感染的系统上无授权地挖掘加密货币。关于"syst3md",是一种特定的挖矿病毒,它通过在受感染的Linux系统中执行一系列复杂操作来达到其目的。这些操作包括使用curl从网络下载…...

此机非彼机,工业计算机在工业行业的特殊地位
电子计算机,称为电脑。计算机是一种利用数字电子技术,根据一系列指令指示其自动执行任意算术或逻辑操作串行的设备。通用计算机因有能遵循被称为“程序”的一般操作集的能力而使得它们能够执行极其广泛的任务,以管理各种工厂和机器自动化工业…...

Python使用lxml解析XML格式化数据
Python使用lxml解析XML格式化数据 1. 效果图2. 源代码参考 方法一:无脑读取文件,遇到有关键词的行再去解析获取值 方法二:利用lxml等库,解析格式化数据,批量获取标签及其值 这篇博客介绍第2种办法,以菜鸟教…...

CDA-LevelⅡ【考题整理-带答案】
关于相关分析中应注意的问题,下面说法错误的是:B 如果两变量间的相关系数为0,则说明二者独立 。解释:只能说明两者不存在线性相关关系现通过参数估计得到一个一元线性回归模型为y3x4,在回归系数检验中下列说法错误的是…...
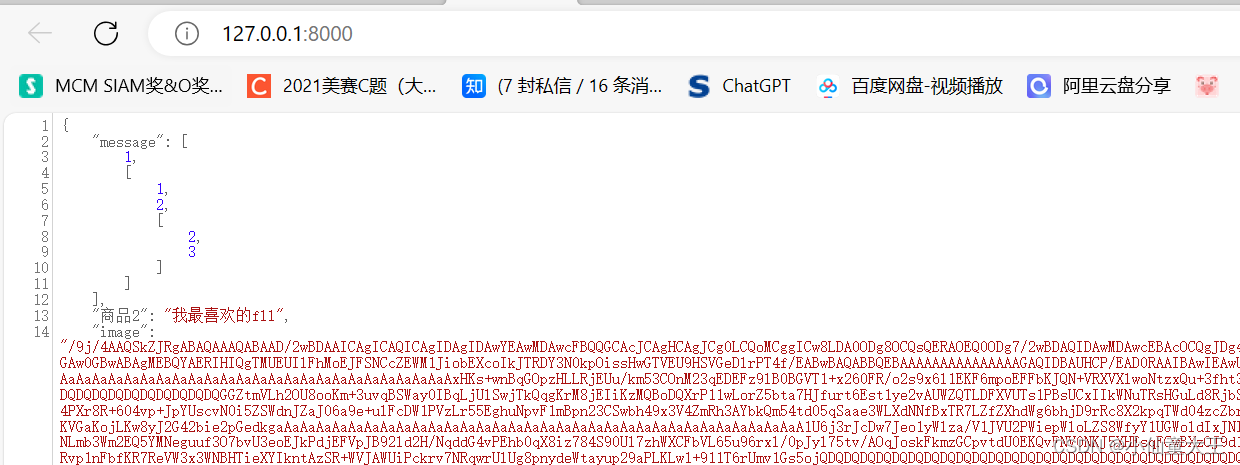
20240304 json可以包含复杂数组(数组里面套数组)
欣赏一下我的思维,它会以漫画,表格,文字。。。各种各样的形式呈现 对于问题1问题2 JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。JSON本质上是一种文本…...
算法50:动态规划专练(力扣514题:自由之路-----4种写法)
题目: 力扣514 : 自由之路 . - 力扣(LeetCode) 题目的详细描述,直接打开力扣看就是了,下面说一下我对题目的理解: 事例1: 输入: ring "godding", key "gd" 输出: 4. 1. ring的第…...
重学SpringBoot3-集成Thymeleaf
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞👍收藏⭐评论✍ 重学SpringBoot3-集成Thymeleaf 1. 添加Thymeleaf依赖2. 配置Thymeleaf属性(可选)3. 创建Thymeleaf模板4. 创建一个Controller5. 运行应用并访问页…...
【数据可视化】Echarts最常用图表
个人主页 : zxctscl 如有转载请先通知 文章目录 1. 前言2. 准备工作3. 柱状图3.1 绘制堆积柱状图3.2 绘制标准条形图3.3 绘制瀑布图 4. 折线图4.1 绘制堆积面积图和堆积折线图4.2 绘制阶梯图 5. 饼图5.1 绘制标准饼图5.2 绘制圆环图5.2 绘制嵌套饼图5.3 绘制南丁格尔…...

flink:通过table api把文件中读取的数据写入MySQL
当写入数据到外部数据库时,Flink 会使用 DDL 中定义的主键。如果定义了主键,则连接器将以 upsert 模式工作,否则连接器将以 append 模式工作 package cn.edu.tju.demo2;import org.apache.flink.streaming.api.environment.StreamExecutionE…...

【Java 多线程 哈希表】 HashTable, HashMap, ConcurrentHashMap 之间的区别
HashTable、HashMap和ConcurrentHashMap都是Java中用于存储键值对的集合框架的一部分,但它们之间存在一些重要的联系和区别。 联系 键值对存储:它们都用于存储键值对,并允许你根据键来检索值。基于哈希:它们内部都使用了哈希表来…...

有趣之matlab-烟花
待整合1 2 3 动态 有趣编程之11 静态 逼真 3 .m文件路径下放back1.jpg back4.jpg…背景照片 点击screen 就会有小白点升起,爆炸 function yanhuamoban()clear all;%定义全局变量global ah ;%坐标轴句柄global styleNum ;%爆炸图案样式global multiColor; %多颜色变换…...

3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南
3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi 你是否厌倦了手动记录棋局的…...

洛雪音乐音源完全指南:一键解锁全网高品质音乐资源
洛雪音乐音源完全指南:一键解锁全网高品质音乐资源 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否厌倦了在多个音乐平台间切换,只为寻找一首心仪的歌曲?…...

用Python和OpenCV实现人脸微调:从仿射变换到TPS薄板样条实战
PythonOpenCV人脸微调实战:从仿射变换到TPS薄板样条全解析 当我们需要将一张人脸自然地调整到另一张人脸的形状时,传统仿射变换的局限性就会暴露无遗。本文将从实际应用出发,带你深入理解TPS(Thin Plate Spline)薄板样…...

如何快速上手res-downloader:跨平台资源下载工具终极指南
如何快速上手res-downloader:跨平台资源下载工具终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 想要轻松…...

工业机器视觉工控机选型指南:从硬件配置到现场调试
1. 产品定位与核心价值解析在工业自动化领域,尤其是机器视觉应用场景中,稳定、可靠且性能强劲的硬件平台是整套系统能够7x24小时无间断运行的基石。朗锐智科推出的这款机器视觉工控机,从其核心配置来看,精准地瞄准了中高端视觉检测…...

基于RT-Thread与TOF传感器的智能电动滑板主动刹车系统设计
1. 项目概述:从情怀出发的硬件升级之旅几年前,我和几个同学在导师的带领下,捣鼓出了一个基于 Arduino Uno 的电动滑板。那会儿真是干劲十足,白天画图、晚上调代码,傍晚就踩着滑板在校园里飞驰。这个滑板后来成了我的“…...
)
胶片颗粒≠噪点!20年胶片扫描工程师首曝Midjourney底层噪声映射逻辑(RGB通道衰减比=1.03:0.97:1.12)
更多请点击: https://codechina.net 第一章:胶片颗粒≠噪点!20年胶片扫描工程师首曝Midjourney底层噪声映射逻辑(RGB通道衰减比1.03:0.97:1.12) 胶片颗粒是银盐晶体在显影过程中形成的物理性随机簇状结构,…...

RK3568播放RTSP摄像头实测:软解1080P直接CPU跑满,降到360P才流畅,硬解到底怎么搞?
RK3568 RTSP摄像头解码实战:从软解瓶颈到硬解优化全解析 最近在调试RK3568开发板的RTSP摄像头播放功能时,遇到了一个典型问题:1080P软解直接让CPU跑满,降到360P才能勉强流畅。这让我开始深入探索瑞芯微平台的硬解方案,…...

2026AI论文软件实测排行榜!这几款才是真神器
综合评分 TOP4 为千笔AI(99/100)、毕业之家 (96/100)、DeepSeek Scholar(89/100)、豆包学术版 (88/100)。千笔AI是全流程全能王,毕业之家专注学术合规,DeepSeek 是理工科免费神器,豆包擅长多模态与文献分析。一、测评标准说明(202…...

Poppins几何字体:如何让拉丁文与天城体在同一个视觉世界里和谐共舞?
Poppins几何字体:如何让拉丁文与天城体在同一个视觉世界里和谐共舞? 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 当你的产品需要同时面向印度用户和全…...