深度学习神经网络训练环境配置以及演示
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
1 NVIDIA Driver and CUDA cuDNN安装配置
2 TensorRT安装配置
2.1 版本对应
2.2 环境配置解压后进入TensorRT根目录:
2.3 安装python包
2.4 测试
3 训练
1 NVIDIA Driver and CUDA cuDNN安装配置
这三者安装安装顺序是GPU Driver->CUDA->cuDNN,可以参考CUDA环境配置在Ubuntu18
注意:版本要对应
2 TensorRT安装配置
2.1 版本对应
笔者CUDA为12.1.1 因此需要找到对应的TensorRT,官网TensorRT官网
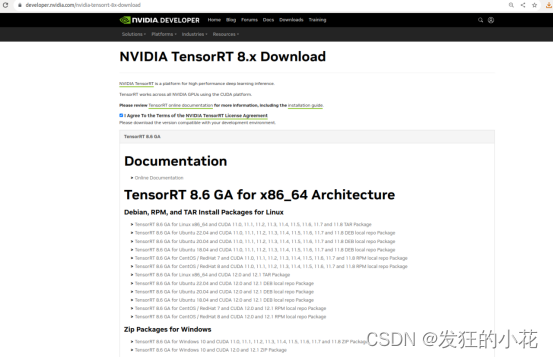
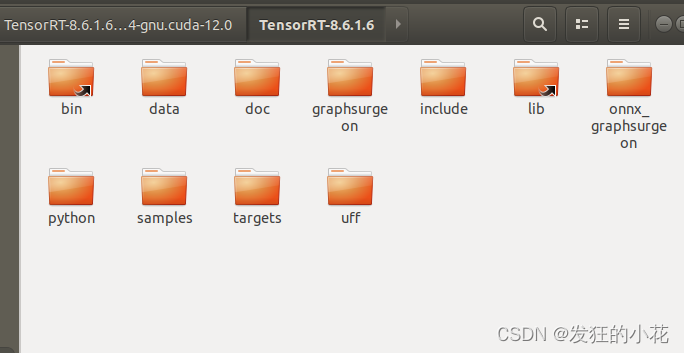
2.2 环境配置
解压后进入TensorRT根目录:
(1)环境变量
vi ~/.bashrc
在文件末尾添加一行代码:
export LD_LIBRARY_PATH=/home/hubery/lib/TensorRT-8.6.1.6/lib:$LD_LIBRARY_PATH
关闭保存
source ~/.bashrc(2)复制文件到系统路径
把TensorRT根目录中的/lib/下面的文件复制到 /usr/lib/下,
把TensorRT根目录中的/include/下面的文件复制到 /usr/include/下
2.3 安装python包
进入TensorRT根目录下的python/目录下
可以看到多个版本的python包。
因为我之前安装的是python3.10版,所以选择安装文件tensorrt_dispatch-8.6.1-cp310-none-linux_x86_64.whl
执行安装命令:
pip install --force-reinstall tensorrt_dispatch-8.6.1-cp310-none-linux_x86_64.whl
2.4 测试
执行无报错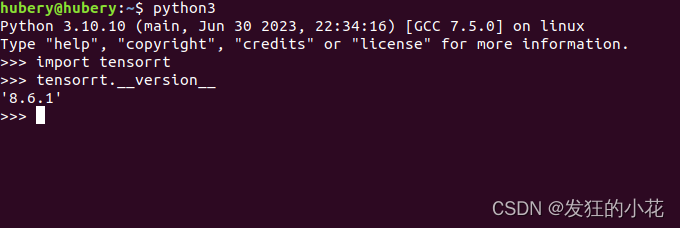
3 TensorFlow 安装配置
3.1 GPU版本
pip3 install tensorflow-gpu==2.10.03.2 CPU版本
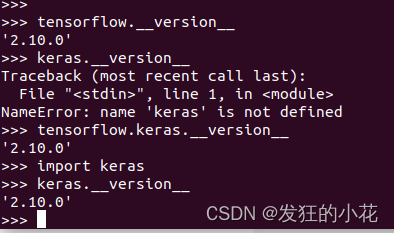
pip3 install tensorflow==2.10.0一般安装TensorFlow时会自动安装keras,如果没有,可以单独安装
pip3 install keras3.3 测试
3 训练
代码来自从零入门 AI 视觉:历时 3 个月,我的代码仓库开源了
# 导入NumPy数学工具箱
import numpy as np
# 导入Pandas数据处理工具箱
import pandas as pd
# 从 Keras中导入 mnist数据集
from keras.datasets import mnist(X_train_image, y_train_lable), (X_test_image, y_test_lable) = mnist.load_data() # 导入keras.utils工具箱的类别转换工具
from tensorflow.keras.utils import to_categorical
# 给标签增加维度,使其满足模型的需要
# 原始标签,比如训练集标签的维度信息是[60000, 28, 28, 1]
X_train = X_train_image.reshape(60000,28,28,1)
X_test = X_test_image.reshape(10000,28,28,1)# 特征转换为one-hot编码
y_train = to_categorical(y_train_lable, 10)
y_test = to_categorical(y_test_lable, 10)# 从 keras 中导入模型
from keras import models
# 从 keras.layers 中导入神经网络需要的计算层
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
# 构建一个最基础的连续的模型,所谓连续,就是一层接着一层
model = models.Sequential()
# 第一层为一个卷积,卷积核大小为(3,3), 输出通道32,使用 relu 作为激活函数
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28,28,1)))
# 第二层为一个最大池化层,池化核为(2,2)
# 最大池化的作用,是取出池化核(2,2)范围内最大的像素点代表该区域
# 可减少数据量,降低运算量。
model.add(MaxPooling2D(pool_size=(2, 2)))
# 又经过一个(3,3)的卷积,输出通道变为64,也就是提取了64个特征。
# 同样为 relu 激活函数
model.add(Conv2D(64, (3, 3), activation='relu'))
# 上面通道数增大,运算量增大,此处再加一个最大池化,降低运算
model.add(MaxPooling2D(pool_size=(2, 2)))
# dropout 随机设置一部分神经元的权值为零,在训练时用于防止过拟合
# 这里设置25%的神经元权值为零
model.add(Dropout(0.25))
# 将结果展平成1维的向量
model.add(Flatten())
# 增加一个全连接层,用来进一步特征融合
model.add(Dense(128, activation='relu'))
# 再设置一个dropout层,将50%的神经元权值为零,防止过拟合
# 由于一般的神经元处于关闭状态,这样也可以加速训练
model.add(Dropout(0.5))
# 最后添加一个全连接+softmax激活,输出10个分类,分别对应0-9 这10个数字
model.add(Dense(10, activation='softmax'))# 编译上述构建好的神经网络模型
# 指定优化器为 rmsprop
# 制定损失函数为交叉熵损失
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])# 开始训练
model.fit(X_train, y_train, # 指定训练特征集和训练标签集validation_split = 0.3, # 部分训练集数据拆分成验证集epochs=5, # 训练轮次为5轮batch_size=128) # 以128为批量进行训练# 在测试集上进行模型评估
score = model.evaluate(X_test, y_test)
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率# 预测验证集第一个数据
pred = model.predict(X_test[0].reshape(1, 28, 28, 1))
# 把one-hot码转换为数字
print(pred[0],"转换一下格式得到:",pred.argmax())# 导入绘图工具包
import matplotlib.pyplot as plt
# 输出这个图片
plt.imshow(X_test[0].reshape(28, 28),cmap='Greys')
执行结果:

🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!
相关文章:
深度学习神经网络训练环境配置以及演示
🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:高性能(HPC)开发基础教程 🎀CSDN主页 发狂的小花 🌄人生秘诀:学习的本质就是极致重复! 目录 1 NVIDIA Dr…...

[嵌入式AI从0开始到入土]16_ffmpeg_ascend编译安装及性能测试
[嵌入式AI从0开始到入土]嵌入式AI系列教程 注:等我摸完鱼再把链接补上 可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。 第1期 昇腾Altas 200 DK上手 第2期 下载昇腾案例并运行 第3期 官…...
HTML5:七天学会基础动画网页11
CSS3动画 CSS3过渡的基本用法: CSS3过渡是元素从一种样式逐渐改变为另一种样式的效果。 过渡属性-transition 值与说明 transition-property 必需,指定CSS属性的name,transition效果即哪个属性发生过渡。 transition-duration 必需,t…...

考虑开发容器的 6 个理由
虽然在容器环境内进行开发的行为可以追溯到 2010 年代中期,但开发容器本身在过去一年中已经开始流行。微软在 2022 年推出了开发容器规范,推动了这一概念的发展,而 Docker 在去年夏天也紧随其后,推出了开发环境功能的测试版。 开…...

Python基础入门 --- 1-2.字面量
文章目录 Python基础入门第一章:1.1 第一个python程序 第二章 :2.1 字面量2.2 常用的值类型2.3 字符串2.3.1 三种定义方式2.3.2 引号嵌套2.3.3 字符串拼接2.3.4 字符串格式化2.3.5 格式化的精度控制数字精度控制: 2.3.6 字符串格式化方式22.3…...

华为云计算hcie认证考什么?华为hciie认证好考吗
1.理论知识:HCIE认证首先要求考生具备扎实的云计算理论基础,包括云计算的基本概念、架构、关键技术、安全管理等方面的知识。考生需要深入理解云计算的核心原理,以及华为云计算产品的特点和优势。 2.实践技能:除了理论知识外&…...

redis spring cache
数据库的数据是存储在硬盘上的,频繁访问性能较低。如果将一些需要频繁查询的热数据放到内存的缓存中,可以大大减轻数据库的访问压力。 SpringCache SpringCache提供基本的Cache抽象,并没有具体的缓存能力,需要配合具体的缓存实现…...
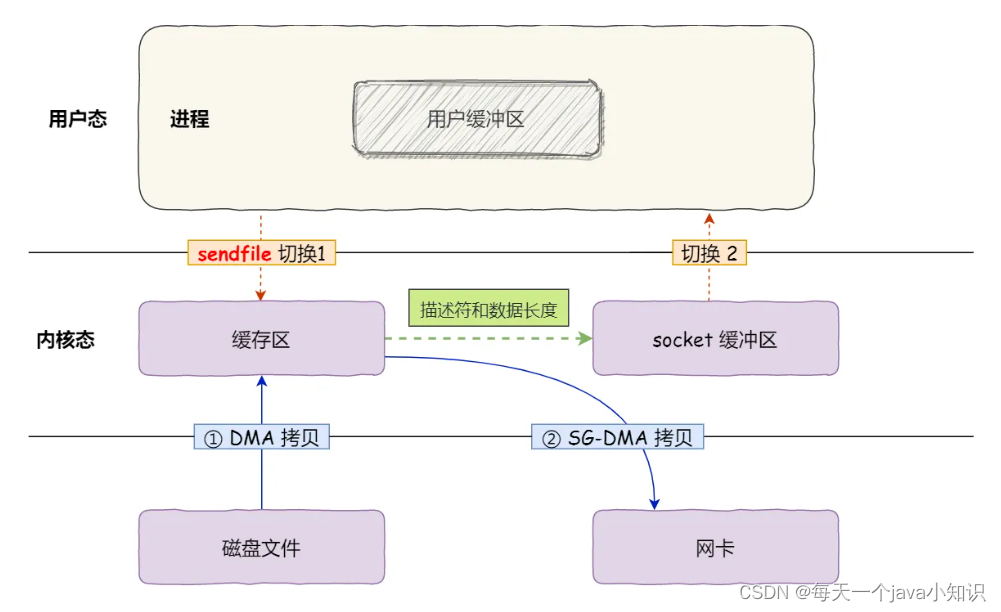
图解I/O中的零拷贝技术
什么是零拷贝? 零拷贝是一种计算机系统中的 I/O 优化技术,它的核心思想是在数据传输过程中尽可能地减少或完全避免 CPU 将数据从一个存储区域复制到另一个存储区域的操作,从而减少了上下文切换和 CPU 拷贝时间,提高了系统的性能和…...
)
【设计模式】Java 设计模式之桥接模式(Bridge)
桥接模式(Bridge Pattern)是结构型设计模式的一种,它主要解决的是抽象部分与实现部分的解耦问题,使得两者可以独立变化。这种类型的设计模式属于结构型模式,因为该模式涉及如何组合接口和它们的实现。将抽象部分与实现…...
记录dockers中Ubuntu安装python3.11
参考: docker-ubuntu 安装python3.8,pip3_dockerfile ubuntu22 python3.8-CSDN博客...
【算法专题--双指针算法】leetcode--283. 移动零、leetcode--1089. 复写零
🍁你好,我是 RO-BERRY 📗 致力于C、C、数据结构、TCP/IP、数据库等等一系列知识 🎄感谢你的陪伴与支持 ,故事既有了开头,就要画上一个完美的句号,让我们一起加油 目录 前言1. 移动零࿰…...

【JavaEE -- 多线程3 - 多线程案例】
多线程案例 1.单例模式1.1 饿汉模式的实现方法1.2 懒汉模式的实现方法 2. 阻塞队列2.1 引入生产消费者模型的意义:2.2 阻塞队列put方法和take方法2.3 实现阻塞队列--重点 3.定时器3.1 定时器的使用3.2 实现定时器 4 线程池4.1 线程池的使用4.2 实现一个简单的线程池…...

k8s的pod服务升级,通过部署helm升级
要通过Helm升级Kubernetes(k8s)中的Pod服务,你可以按照以下步骤进行操作: 安装Helm: 如果你还没有安装Helm,可以通过官方文档提供的方式进行安装。添加Helm仓库: 确保你已经添加了包含你要升级…...
复现文件上传漏洞
一、搭建upload-labs环境 将下载好的upload-labs的压缩包,将此压缩包解压到WWW中,并将名称修改为upload,同时也要在upload文件中建立一个upload的文件。 然后在浏览器网址栏输入:127.0.0.1/upload进入靶场。 第一关 选择上传文件…...

Java 内存异常
内存溢出 内存溢出指的是在程序执行过程中,申请的内存超过了系统实际可用的内存资源。 内存溢出的常见情况: 创建大量对象并持有引用:在程序中创建大量对象并持有对这些对象的引用,而没有及时释放这些引用,导致堆内存…...

Windows11去掉 右键菜单的 AMD Software:Adrenalin Edition 选项
Windows11去掉 右键菜单的 AMD Software:Adrenalin Edition 选项 运行regedit打开注册表编辑器 先定位到 计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Classes\PackagedCom\Package 计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Classes\PackagedCom\Package找到 AdvancedMicroDevicesInc-2.…...

uniapp实现我的订单页面无感 - 删除数据
在进入我们的订单页面时进行获取列表,上拉加载,下拉刷新等请求,我们在删除数据时,请求删除接口后,不要重新去请求数据,不要重新去请求数据,不要重新去请求数据 重新请求会刷新页面中的数据 方…...

MySQL—redo log、undo log以及MVCC
MySQL—redo log、undo log以及MVCC 首先回忆一下MySQL事务的四大特性:ACID,即原子性、一致性、隔离性和持久性。其中原子性、一致性、持久性实际上是由InnoDB中的两份日志保证的,一份是redo log日志,一份是undo log日志ÿ…...

13 list的实现
注意 实现仿cplus官网的list类,对部分主要功能实现 实现 文件 #pragma once #include <assert.h>namespace mylist {template <typename T>struct __list_node{__list_node(const T& x T()): _prev(nullptr), _next(nullptr), _data(x){}__lis…...

如何用client-go获取k8s因硬盘容量、cpu、内存、gpu资源不够引起的错误信息?
在Kubernetes中,你可以使用client-go库来获取Pod的状态和事件,这些信息可能包含了由于资源不足引起的错误信息。 以下是一个基本的示例,展示如何使用client-go来获取Pod的状态和事件: package mainimport ("flag"&quo…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...