浅易理解:非极大抑制NMS
什么是非极大抑制NMS
非极大值抑制(Non-Maximum Suppression,简称NMS)是一种在计算机视觉和图像处理领域中广泛使用的后处理技术,特别是在目标检测任务中。它的主要目的是解决目标检测过程中出现的重复检测问题,即对于同一个物体,算法可能会预测出多个重叠或相似的边界框(bounding boxes)。
在目标检测算法得出一系列候选边界框及其对应的类别得分(confidence score)之后,NMS过程如下:
-
排序:首先根据每个边界框的得分进行降序排序,选取得分最高的边界框作为保留的对象。
-
抑制:对于排序后的边界框列表,对每一个框i,检查其与得分低于它的所有其他框j之间的重叠程度。通常使用交并比(Intersection over Union,IoU)来量化两个框的重叠面积占它们并集面积的比例。
-
剔除:如果框i与某个框j的IoU超过预设的阈值(比如0.5),则认为框j是冗余的,将其剔除(抑制)。
-
迭代:重复上述步骤,直到处理完所有候选边界框,最终剩下的边界框集合即是经过非极大值抑制后的结果,这些框代表了各自区域内最有可能对应真实物体的检测结果。
总之,非极大值抑制确保了对同一物体只有一个最精确的边界框被保留下来,从而减少误报和重复检测,提高了目标检测的精度。
在目标检测中,NMS的目的就是要去除冗余的检测框,保留最好的一个
非极大抑制的概念只需要看这两幅图就知道了:
下图是经过非极大抑制的。

下图是未经过非极大抑制的。
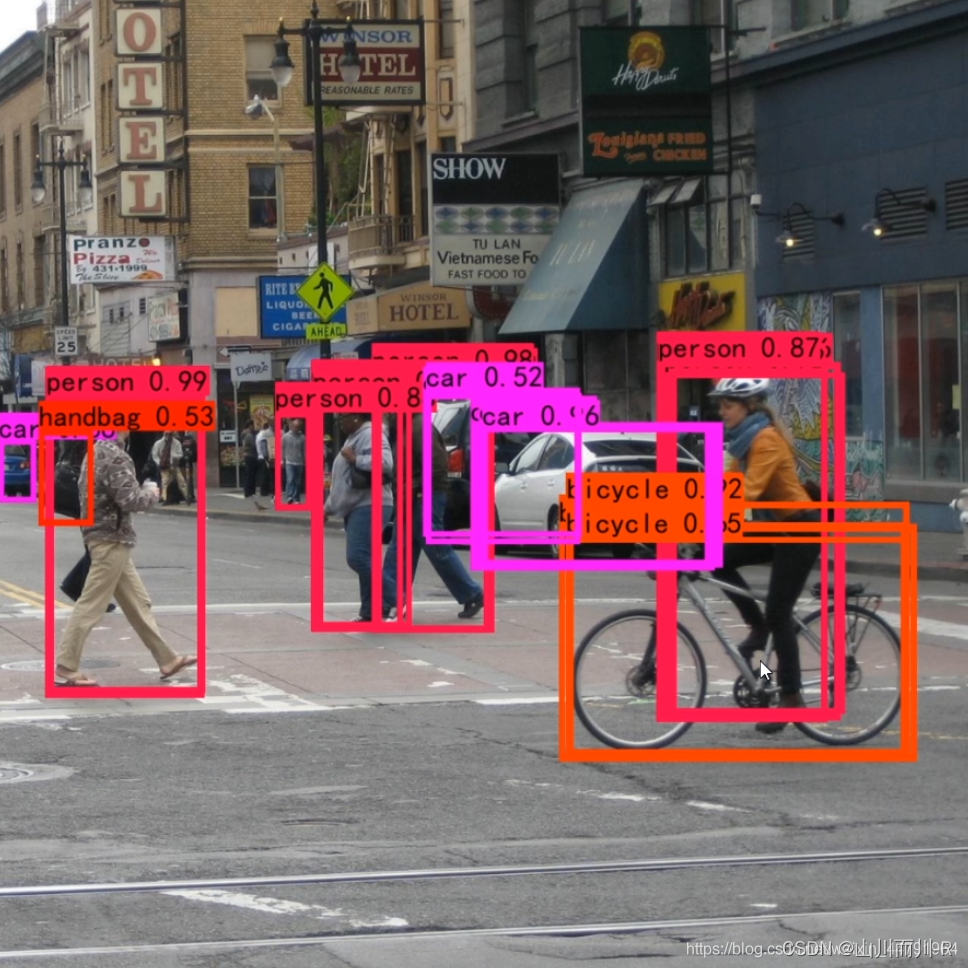
NMS的原理是对于预测框的集合S及其对应的置信度score(这里的置信度就是softmax得出的概率值,它的含义是多大的把握预测正确,也就是有多大的把握确定检测框中存在真正的目标),选择具有最大score的检测框,记为M,将其从集合S中移除并加入到最终的检测结果集合中.并且将集合S中剩余检测框中与检测框M的IoU大于阈值的框从集合S中移除.重复这个过程,直到集合S为空。
使用流程如下图所示:
首先是检测出一系列的检测框
将检测框按照类别进行分类
对同一类别的检测框应用NMS获取最终的检测结果

代码:
NMS 算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,具体的实现思路如下:
- 选取这类box中scores最大的哪一个,它的index记为 i ,并保留它;
- 计算
boxes[i]与其余的boxes的IOU值; - 如果其
IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保留分数高的哪一个); - 从最后剩余的boxes中,再找出最大scores的哪一个,如此循环往复。
def nms(boxes, scores, threshold=0.5, top_k=200):'''Args:boxes: 预测出的box, shape[M,4]scores: 预测出的置信度,shape[M]threshold: 阈值top_k: 要考虑的box的最大个数Return:keep: nms筛选后的box的新的index数组count: 保留下来box的个数'''keep = scores.new(scores.size(0)).zero_().long()x1 = boxes[:, 0]y1 = boxes[:, 1]x2 = boxes[:, 2]y2 = boxes[:, 3]area = (x2-x1)*(y2-y1) # 面积,shape[M]_, idx = scores.sort(0, descending=True) # 降序排列scores的值大小# 取前top_k个进行nmsidx = idx[:top_k]count = 0while idx.numel():# 记录最大score值的indexi = idx[0]# 保存到keep中keep[count] = i# keep 的序号count += 1if idx.size(0) == 1: # 保留框只剩一个breakidx = idx[1:] # 移除已经保存的index# 计算boxes[i]和其他boxes之间的iouxx1 = x1[idx].clamp(min=x1[i])yy1 = y1[idx].clamp(min=y1[i])xx2 = x2[idx].clamp(max=x2[i])yy2 = y2[idx].clamp(max=y2[i])w = (xx2 - xx1).clamp(min=0)h = (yy2 - yy1).clamp(min=0)# 交集的面积inter = w * h # shape[M-1]iou = inter / (area[i] + area[idx] - inter)# iou满足条件的idxidx = idx[iou.le(threshold)] # Shape[M-1]return keep, count其中:
- torch.numel(): 表示一个张量总元素的个数
- torch.clamp(min, max): 设置上下限
- tensor.le(x): 返回tensor<=x的判断
//+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++//
通过一个例子看些NMS的使用方法,假设定位车辆,算法就找出了一系列的矩形框,我们需要判别哪些矩形框是没用的,需要使用NMS的方法来实现。
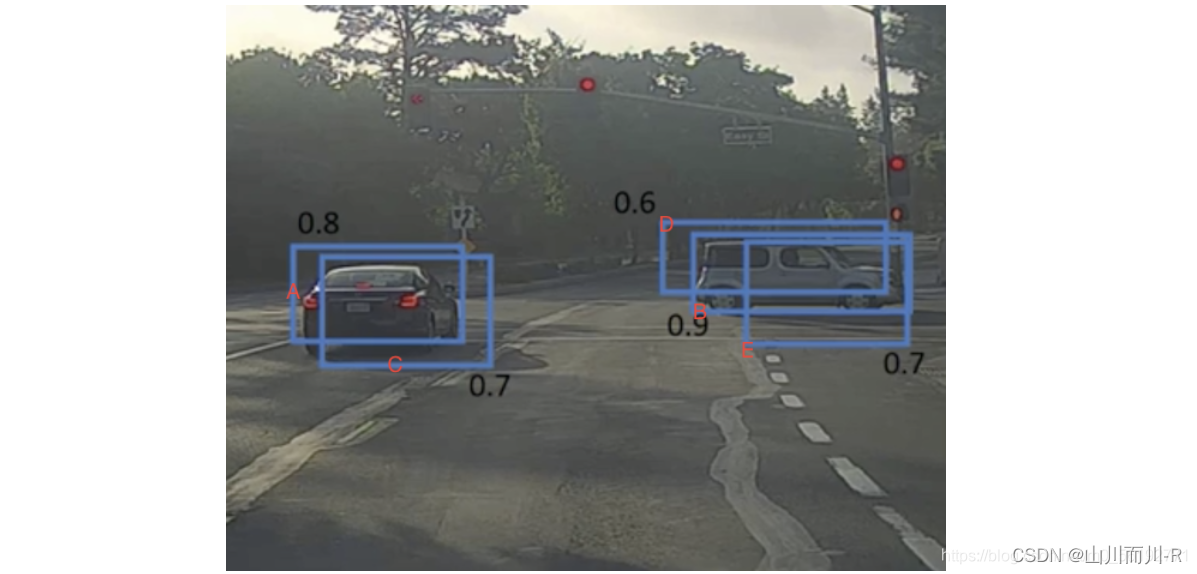
假设集合S中有A、B、C、D、E 5个候选框,每个框旁边的数字是它的置信度,我们设定NMS的iou阈值是0.5,接下来进行迭代计算:
第一轮:因为B是得分最高的(即B的置信度最高),在集合S的其余候选框中,如果与B的IoU>0.5会被删除。A,C,D,E中现在分别与B计算IoU,DE结果>0.5,剔除DE(说明BDE检测的是同一个目标,保留置信度最大的候选框;而AC可能检测的是另一个目标),B作为一个预测结果,从集合S中移除,并放入最终的检测结果集合中。此时新的集合S中只剩下候选框A,C
第二轮:在新的集合S中,A的置信度得分最高,将集合S中剩下的候选框分别与A计算IoU,因为A与C的iou>0.5,所以剔除C,A作为另外一个预测结果从集合S中移除,并放入最终的检测结果集合中,此时集合S为空,所以循环结束。
最终结果为在这个5个中检测出了两个目标为A和B。
单类别的NMS的实现方法如下所示:
import numpy as np
def nms(bboxes, confidence_score, threshold):"""非极大抑制过程:param bboxes: 同类别候选框坐标:param confidence: 同类别候选框分数(即置信度):param threshold: iou阈值:return:"""# 1、没有传入候选框则返回空列表if len(bboxes) == 0:return [], []#强制转换为numpy类型的数组,这样才可以进行切片等numpy所支持的操作bboxes = np.array(bboxes)score = np.array(confidence_score)# 取出所有候选框的左上角坐标和右下角坐标x1 = bboxes[:, 0]y1 = bboxes[:, 1]x2 = bboxes[:, 2]y2 = bboxes[:, 3]# 2、对候选框进行NMS筛选# 返回的框坐标和分数picked_boxes = []picked_score = []# 对置信度进行排序, 获取排序后的下标序号, argsort默认从小到大排序order = np.argsort(score)#计算所有候选框的面积 areas = (x2 - x1) * (y2 - y1)while order.size > 0:# 将当前置信度最大的候选框的索引,加入返回值列表中,因为是从小到大排序,所有最后一个值最大,即 order[-1]表示最后一个元素index = order[-1]#将置信度最大的候选框及其置信度值加入返回值列表中picked_boxes.append(bboxes[index])picked_score.append(score[index])# 获取当前置信度最大的候选框与其他任意候选框的相交面积,这里的order[:-1]表示除了最后一个元素之外的所有元素,np.max和np.maximum的实现功能是不同的#np.maximum的用法:np.maximum([2,4,7],[3,1,5])输出的结果是array([3, 4, 7]);np.maximum([2],[3,1,5])的输出结果是array([3, 2, 5])#np.max的用法:np.max([2,4,7])输出结果是7x11 = np.maximum(x1[index], x1[order[:-1]])y11 = np.maximum(y1[index], y1[order[:-1]])x22 = np.minimum(x2[index], x2[order[:-1]])y22 = np.minimum(y2[index], y2[order[:-1]])# 计算相交的面积,不重叠时面积设为0w = np.maximum(0.0, x22 - x11)h = np.maximum(0.0, y22 - y11)inter_area = w * h# 计算交并比iou = inter_area / (areas[index] + areas[order[:-1]] - inter_area)# 获取IoU小于阈值的候选框的索引keep_boxes = np.where(iou < threshold)#更新order,以便保留IoU小于阈值的框,order = order[keep_boxes]# 返回NMS后的框及分类结果 return picked_boxes, picked_score假设有检测结果如下:当阈值threshold设置的越大,则保留越多的候选框
-
当threshold取0.3时:
bounding = [(187, 82, 337, 317), (150, 67, 305, 282), (246, 121, 368, 304)]
confidence_score = [0.9, 0.65, 0.8]
threshold = 0.3
picked_boxes, picked_score = nms(bounding, confidence_score, threshold)
print('阈值threshold为:', threshold)
print('NMS后得到的bbox是:', picked_boxes)
print('NMS后得到的bbox的confidences是:', picked_score)返回结果:
阈值threshold为: 0.3
NMS后得到的bbox是: [array([187, 82, 337, 317])]
NMS后得到的bbox的confidences是: [0.9]当threshold取0.5时:
bounding = [(187, 82, 337, 317), (150, 67, 305, 282), (246, 121, 368, 304)]
confidence_score = [0.9, 0.65, 0.8]
threshold = 0.5
picked_boxes, picked_score = nms(bounding, confidence_score, threshold)
print('阈值threshold为:', threshold)
print('NMS后得到的bbox是:', picked_boxes)
print('NMS后得到的bbox的confidences是:', picked_score)返回结果:
阈值threshold为: 0.5
NMS后得到的bbox是: [array([187, 82, 337, 317]), array([246, 121, 368, 304])]
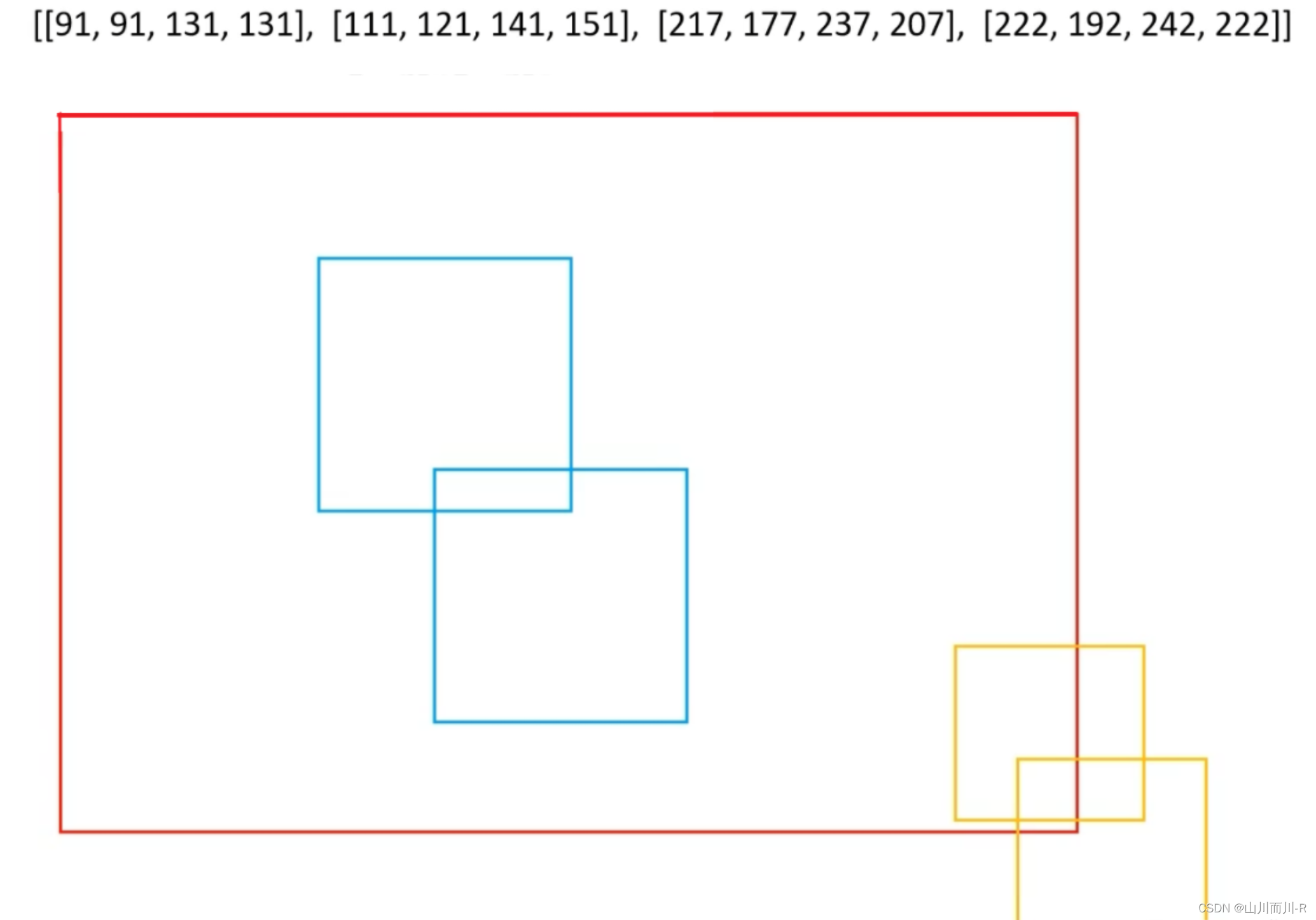
NMS后得到的bbox的confidences是: [0.9, 0.8]上述所讲的NMS方法都是先将检测框按照类别进行分类,然后对对同一类别的检测框应用NMS。但是在实际的任务中,如果所预测的类别很多时,那么这种效率非常低。所以有些时候我们会使用新的方法进行NMS:它的大致思想是先将不同类别的预测框在坐标位置上尽可能的区分开,然后就可以一次性对所有预测框进行NMS(此时不用先进行分类,然后分别对每一个类别依次做NMS)
,比如下图所示,蓝色方框的类别索引是1,黄色方框的类别索引是2,这些不同类别的预测框在位置上靠的很近,此时如果直接对所有类别同时做NMS,效果就很差。所以我们会设法将蓝色方框和黄色方框分离开,本例的方法是首先找到所有方框中坐标值最大的数值max_value,比如这里是81,

然后使用类别索引 indxs与val_value相乘,得到不同类别框的偏移量offsets,它的公式是:offsets=indxs*max_value
比如对于类别索引为1的方框,它的偏移量是offsets=indxs*max_value=1*81=81,对于类别索引为1的方框,它的偏移量是offsets=indxs*max_value=2*81=162
计算完每个类别的偏移量后,我们就得到新的预测框的坐标以及其对于的新位置,如下所示。然后就可以一次性对所有预测框进行NMS(此时不用先进行分类,然后分别对每一个类别依次做NMS)
//++++++++++++++++++++++++++++++++++++++++++++++++++++++++//
概括非极大抑制的功能就是:
筛选出一定区域内属于同一种类得分最大的框。
1、非极大抑制NMS的实现过程
本博文实现的是多分类的非极大抑制:
输入shape为[ batch_size, all_anchors, 5+num_classes ]
第一个维度是图片的数量。
第二个维度是所有的预测框。
第三个维度是所有的预测框的预测结果。
非极大抑制的执行过程如下所示:
1、对所有图片进行循环。
2、找出该图片中得分大于门限函数的框。在进行重合框筛选前就进行得分的筛选可以大幅度减少框的数量。
3、判断第2步中获得的框的种类与得分。取出预测结果中框的位置与之进行堆叠。此时最后一维度里面的内容由5+num_classes变成了4+1+2,四个参数代表框的位置,一个参数代表预测框是否包含物体,两个参数分别代表种类的置信度与种类。
4、对种类进行循环,非极大抑制的作用是筛选出一定区域内属于同一种类得分最大的框,对种类进行循环可以帮助我们对每一个类分别进行非极大抑制。
5、根据得分对该种类进行从大到小排序。
6、每次取出得分最大的框,计算其与其它所有预测框的重合程度,重合程度过大的则剔除。
视频中实现的代码是numpy形式,而且库比较久远。这里改成pytorch的形式,且适应当前的库。
实现代码如下:
def bbox_iou(self, box1, box2, x1y1x2y2=True):"""计算IOU"""if not x1y1x2y2:b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2else:b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]inter_rect_x1 = torch.max(b1_x1, b2_x1)inter_rect_y1 = torch.max(b1_y1, b2_y1)inter_rect_x2 = torch.min(b1_x2, b2_x2)inter_rect_y2 = torch.min(b1_y2, b2_y2)inter_area = torch.clamp(inter_rect_x2 - inter_rect_x1, min=0) * \torch.clamp(inter_rect_y2 - inter_rect_y1, min=0)b1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)iou = inter_area / torch.clamp(b1_area + b2_area - inter_area, min = 1e-6)return ioudef non_max_suppression(self, prediction, num_classes, input_shape, image_shape, letterbox_image, conf_thres=0.5, nms_thres=0.4):#----------------------------------------------------------## 将预测结果的格式转换成左上角右下角的格式。# prediction [batch_size, num_anchors, 85]#----------------------------------------------------------#box_corner = prediction.new(prediction.shape)box_corner[:, :, 0] = prediction[:, :, 0] - prediction[:, :, 2] / 2box_corner[:, :, 1] = prediction[:, :, 1] - prediction[:, :, 3] / 2box_corner[:, :, 2] = prediction[:, :, 0] + prediction[:, :, 2] / 2box_corner[:, :, 3] = prediction[:, :, 1] + prediction[:, :, 3] / 2prediction[:, :, :4] = box_corner[:, :, :4]output = [None for _ in range(len(prediction))]for i, image_pred in enumerate(prediction):#----------------------------------------------------------## 对种类预测部分取max。# class_conf [num_anchors, 1] 种类置信度# class_pred [num_anchors, 1] 种类#----------------------------------------------------------#class_conf, class_pred = torch.max(image_pred[:, 5:5 + num_classes], 1, keepdim=True)#----------------------------------------------------------## 利用置信度进行第一轮筛选#----------------------------------------------------------#conf_mask = (image_pred[:, 4] * class_conf[:, 0] >= conf_thres).squeeze()#----------------------------------------------------------## 根据置信度进行预测结果的筛选#----------------------------------------------------------#image_pred = image_pred[conf_mask]class_conf = class_conf[conf_mask]class_pred = class_pred[conf_mask]if not image_pred.size(0):continue#-------------------------------------------------------------------------## detections [num_anchors, 7]# 7的内容为:x1, y1, x2, y2, obj_conf, class_conf, class_pred#-------------------------------------------------------------------------#detections = torch.cat((image_pred[:, :5], class_conf.float(), class_pred.float()), 1)#------------------------------------------## 获得预测结果中包含的所有种类#------------------------------------------#unique_labels = detections[:, -1].cpu().unique()if prediction.is_cuda:unique_labels = unique_labels.cuda()detections = detections.cuda()for c in unique_labels:#------------------------------------------## 获得某一类得分筛选后全部的预测结果#------------------------------------------#detections_class = detections[detections[:, -1] == c]# #------------------------------------------## # 使用官方自带的非极大抑制会速度更快一些!# #------------------------------------------## keep = nms(# detections_class[:, :4],# detections_class[:, 4] * detections_class[:, 5],# nms_thres# )# max_detections = detections_class[keep]# 按照存在物体的置信度排序_, conf_sort_index = torch.sort(detections_class[:, 4]*detections_class[:, 5], descending=True)detections_class = detections_class[conf_sort_index]# 进行非极大抑制max_detections = []while detections_class.size(0):# 取出这一类置信度最高的,一步一步往下判断,判断重合程度是否大于nms_thres,如果是则去除掉max_detections.append(detections_class[0].unsqueeze(0))if len(detections_class) == 1:breakious = self.bbox_iou(max_detections[-1], detections_class[1:])detections_class = detections_class[1:][ious < nms_thres]# 堆叠max_detections = torch.cat(max_detections).data# Add max detections to outputsoutput[i] = max_detections if output[i] is None else torch.cat((output[i], max_detections))if output[i] is not None:output[i] = output[i].cpu().numpy()box_xy, box_wh = (output[i][:, 0:2] + output[i][:, 2:4])/2, output[i][:, 2:4] - output[i][:, 0:2]output[i][:, :4] = self.yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image)return output
参考文章:【SSD算法】史上最全代码解析-核心篇 - 知乎
参考文章:睿智的目标检测31——非极大抑制NMS与Soft-NMS-CSDN博客
参考文章:NMS(非极大值抑制)_nms非极大值抑制-CSDN博客
相关文章:
浅易理解:非极大抑制NMS
什么是非极大抑制NMS 非极大值抑制(Non-Maximum Suppression,简称NMS)是一种在计算机视觉和图像处理领域中广泛使用的后处理技术,特别是在目标检测任务中。它的主要目的是解决目标检测过程中出现的重复检测问题,即对于…...

C语言如何进⾏字符数组的复制?
一、问题 有两个字符数组a和b,a的值是“Good Bye” ,b的值是 “Bye Bye”,现在要把b 复制到a中,使a变成“Bye Bye”,应该怎么做? 二、解答 在字符串操作中,字符串复制是⽐较常⽤的操作之⼀。在…...

Linux 中搭建 主从dns域名解析服务器
CSDN 成就一亿技术人! 作者主页:点击! Linux专栏:点击! CSDN 成就一亿技术人! ————前言———— 主从(Master-Slave)DNS架构是一种用于提高DNS系统可靠性和性能的配置方式。…...

CSS3病毒病原体图形特效
CSS3病毒病原体图形特效,源码由HTMLCSSJS组成,双击html文件可以本地运行效果,也可以上传到服务器里面 下载地址 CSS3病毒病原体图形特效代码...
Tomcat Web 开发项目构建教程
1下载Tomcat安装包,下载链接:Apache Tomcat - Welcome!,我电脑环境为JDK8,所以下载Tomcat9.0 2、下载完压缩包后,解压到指定位置 3.在intelij中新建一个项目 4.选中创建的项目,双击shift,输入add frame...然…...
 gauss的使用)
Elasticsearch(9) gauss的使用
elasticsearch version: 7.10.1 在Elasticsearch中,gauss作为衰减函数(decay function)被用于function_score查询中,用于实现基于地理位置或其他数值字段的衰减权重评分。gauss衰减函数模拟了高斯分布,即距…...

php前端和java后端数据调用流程
php前端和java后端数据调用流程 前端 1、新建php页面title.php <title>标题</title> <td width"30%" class"form-key">标题内容</td> <td width"70%"><input type"text" class"form-control…...
C语言从入门到熟悉------第四阶段
指针 地址和指针的概念 要明白什么是指针,必须先要弄清楚数据在内存中是如何存储的,又是如何被读取的。如果在程序中定义了一个变量,在对程序进行编译时,系统就会为这个变量分配内存单元。编译系统根据程序中定义的变量类型分配…...
【目标检测-数据集准备】DIOR转为yolo训练所需格式
【目标检测】DIOR遥感影像数据集,转为yolo系列模型训练所需格式。 标签文件位于Annotations下,格式为xml,yolo系列模型训练所需格式为txt,格式为 class_id x_center,y_center,w,h其中,train,textÿ…...

Nacos为什么对于临时实例采用心跳检测,非临时实例采用主动询问?Nacos同时作为配置中心和注册中心有什么坏处?为什么Nacos可以抗住那么高的注册?
Nacos为什么对于临时实例采用心跳检测,非临时实例采用主动询问? Nacos 对于临时实例采用心跳检测,而对于非临时实例采用主动询问,这两种不同的健康检查机制是为了满足不同场景下的服务发现需求。具体分析如下: 临时实例的心跳检测…...

【NLP】如何实现快速加载gensim word2vec的预训练的词向量模型
1 问题 通过以下代码,实现加载word2vec词向量,每次加载都是几分钟,效率特别低。 from gensim.models import Word2Vec,KeyedVectors# 读取中文词向量模型(需要提前下载对应的词向量模型文件) word2vec_model KeyedV…...
前端实例:页面布局1(后端数据实现)
效果图 注:这里用到后端语言php(页面是.php文件),提取纯html也可以用 inemployee_index.php <?php include(includes/session.inc); $Title _(内部员工首页); $ViewTopic 内部员工首页; $BookMark 内部员工首页; include(includes/…...
【调参】如何为神经网络选择最合适的学习率lr-LRFinder-for-Keras
【调参】如何为神经网络选择最合适的学习率lr-LRFinder-for-Keras_学习率选择-CSDN博客文章浏览阅读9.2k次,点赞6次,收藏55次。keras 版本的LRFinder,借鉴 fast.ai Deep Learning course。前言学习率lr在神经网络中是最难调的全局参数&#x…...
)
【设计模式】Java 设计模式之享元模式(Flyweight)
享元模式(Flyweight)的深入分析 一、概述 享元模式是一种结构型设计模式,它提供了一种有效的方式来减少在大量对象中产生的内存开销。通过共享尽可能多的对象,享元模式可以使程序更高效地使用内存。享元模式常用于那些创建对象实…...
异次元发卡源码系统/荔枝发卡V3.0二次元风格发卡网全开源源码
– 支付系统,已经接入易支付及Z支付免签接口。 – 云更新,如果系统升级新版本,你无需进行繁琐操作,只需要在你的店铺后台就可以无缝完成升级。 – 商品销售,支持商品配图、会员价、游客价、邮件通知、卡密预选&#…...
腾讯春招后端一面(八股篇)
前言 前几天在网上发了腾讯面试官问的一些问题,好多小伙伴关注,今天对这些问题写个具体答案,博主好久没看八股了,正好复习一下。 面试手撕了三道算法,这部分之后更,喜欢的小伙伴可以留意一下我的账号。 1…...
“风口”上的量化大厂“绣球”抛向中低频人才
量化人才这几年是人才舞台上的“香饽饽”。 遵循着低频不如高频、小厂不如大厂的薪资逻辑,各路人才被各路机构“哄抢”,薪资一路走高。 但2024年的“信号”再强烈不过——量化大厂们到了改变的时候了。 而量化大厂们显然对此已“心知肚明”....... “…...

obdiag如何实现一键采集20+故障场景的诊断信息——《OceanBase诊断系列》之九
作者简介:靖顺,OcenaBase 开发工程师,专注于数据库诊断与调优 1. 前言 在2024年初,我与一线运维人员交流时,他们纷纷提及在运维过程中遭遇的难题——OceanBase出现问题时,排查工作不容易,有时需…...

Cookie和Session的获取方法
1、Cookie的简单获取方法(可以获取到所有的cookie) (1)在参数里还有HttpServletResponse response这些,这些都是内置对象需要就拿不需要就删掉就可以,在这里我们用到的是HttpServletRequest request &…...

旅游市场游客满意度调查报告
民安智库开展游客满意度调查主要通过问卷调查的方式进行,在设计问卷时,应确保问题覆盖游客在某省旅游过程中可能遇到的各个方面,包括交通、住宿、餐饮、旅游景点、导游服务等。此外,还可以设置一些开放性问题,让游客提…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

MeloTTS实战:多语言语音合成的高效解决方案
MeloTTS实战:多语言语音合成的高效解决方案 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trending/me/…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...