地平线旭日x3派部署yolov5--全流程
地平线旭日x3派部署yolov5--全流程
- 前言
- 一、深度学习环境安装
- 二、安装docker
- 三、部署
- 3.1、安装工具链镜像
- 3.2、配置天工开物OpenExplorer工具包
- 3.3、创建深度学习虚拟空间,安装依赖:
- 3.4、下载yolov5项目源码并运行
- 3.5、pytorch的pt模型文件转onnx
- 3.6、最重要且最难的部分:ONNX模型转换成bin模型
- 四、上板运行
前言
原文参考:https://blog.csdn.net/Zhaoxi_Li/article/details/125516265
https://blog.csdn.net/Zhaoxi_Li/article/details/126651890?spm=1001.2014.3001.5502
这次部署的过程在windows下进行,深度学习环境和docker都是安装在windows中。
系统:win10
gpu:NVIDIA GeForce GTX 1650

简单来说就是一块性能拉跨点的笔记本电脑,可以直接插入鼠标、键盘、显示屏,当作电脑使用。这使得可以部署深度学习算法到这块板子上。
一、深度学习环境安装
如果只是想体验一下部署,不使用自己的模型的话,其实深度学习的环境都不用安装。
1、安装anaconda
anaconda的介绍看这篇:https://blog.csdn.net/weixin_56197703/article/details/124630222
下载一般两个选择,一个是官网,另一个是国内镜像网站。
①官网下载:直接下载最新就好了

②镜像网站下载:可以下载下面圈起来的其中之一
安装过程: 建议直接安装c盘,避免不必要的错误,前提是c盘名称是英文。

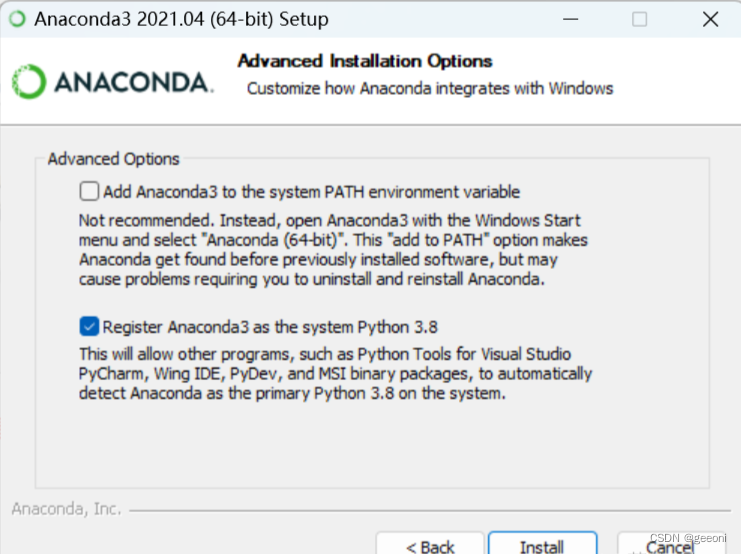
下面这里,第一个选项意思就是将安装路径填入到系统环境变量中,这里勾选,后面使用着可能会出现问题,如果这里不勾选的话,就要自己区设置环境变量。
如果前面这个没勾选的话就进行环境变量设置:
此电脑----->属性----->高级系统设置----->环境变量----->path----->编辑----->新建。
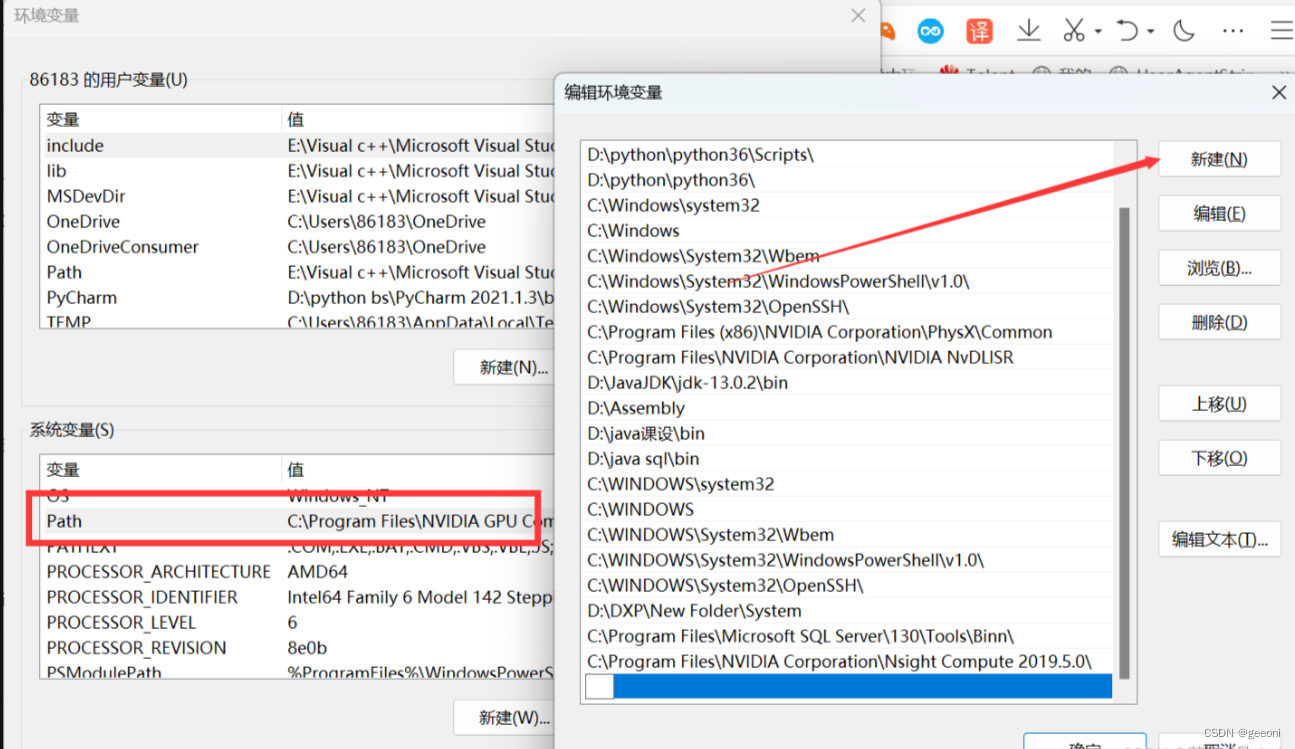
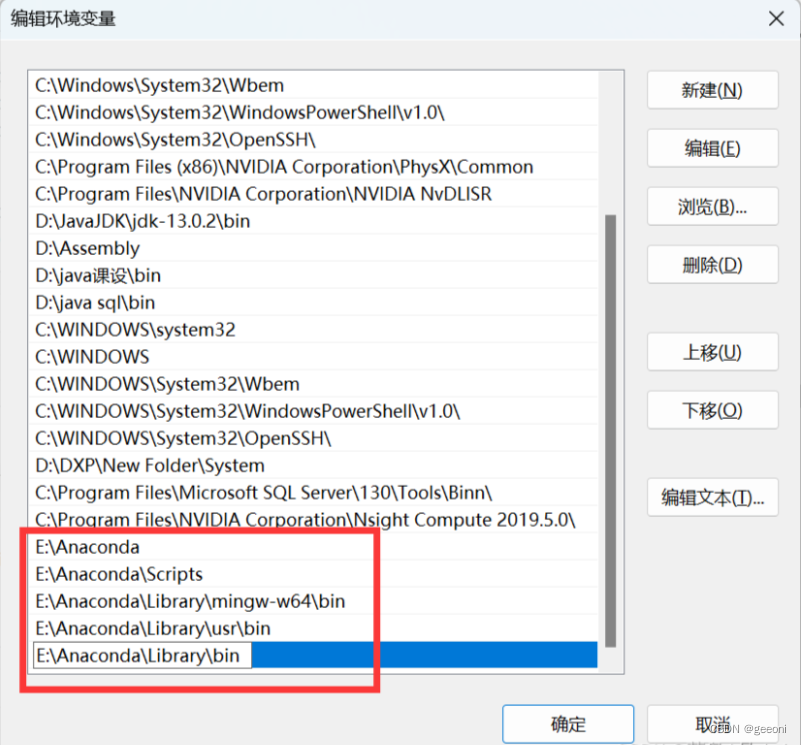
将如下指令添加到环境变量:这里要根据自己的安装位置进行更改。
E:\Anaconda
E:\Anaconda\Scripts
E:\Anaconda\Library\mingw-w64\bin
E:\Anaconda\Library\usr\bin
E:\Anaconda\Library\bin
配置完成之后测试安装是否成功:
搜索cmd或者win+r键入cmd:
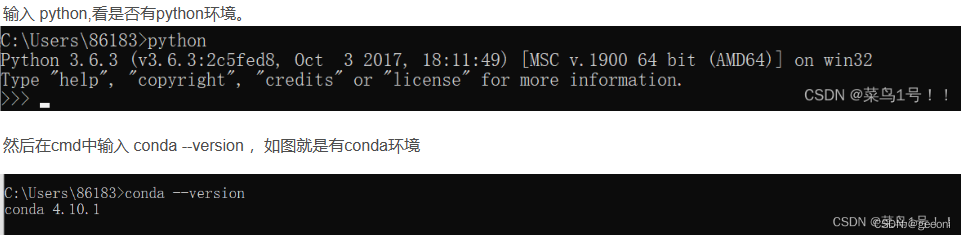
如果报错大概率是环境变量问题,认真弄。
2、安装cuda与cudnn
①查看显卡支持的最高CUDA的版本,以便下载对应的CUDA安装包:
win+R输入cmd进入命令提示符,输入:nvidia-smi
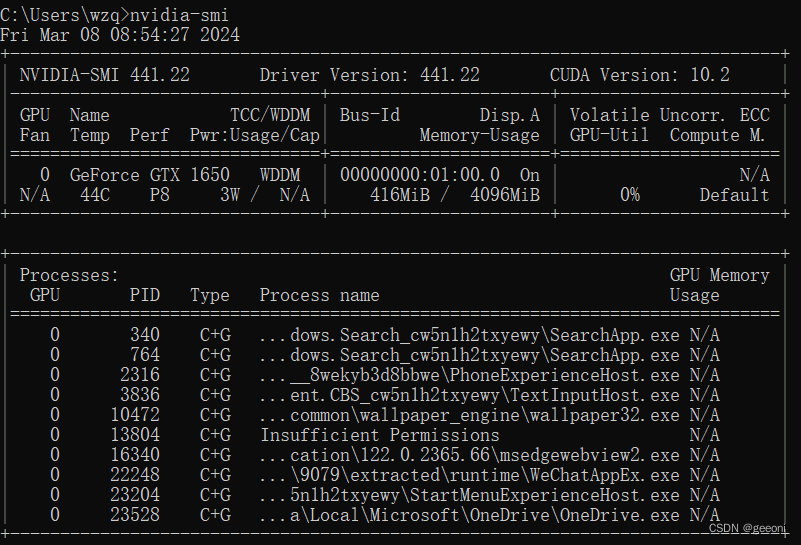
我这里在未安装之前显示的是11.6,表示最高支持11.6,不是只能下载11.6。由于电脑比较拉跨,这里选择10.2版本,在NVIDIA官方网站即可下载,地址为:https://developer.nvidia.com/cuda-toolkit-archive
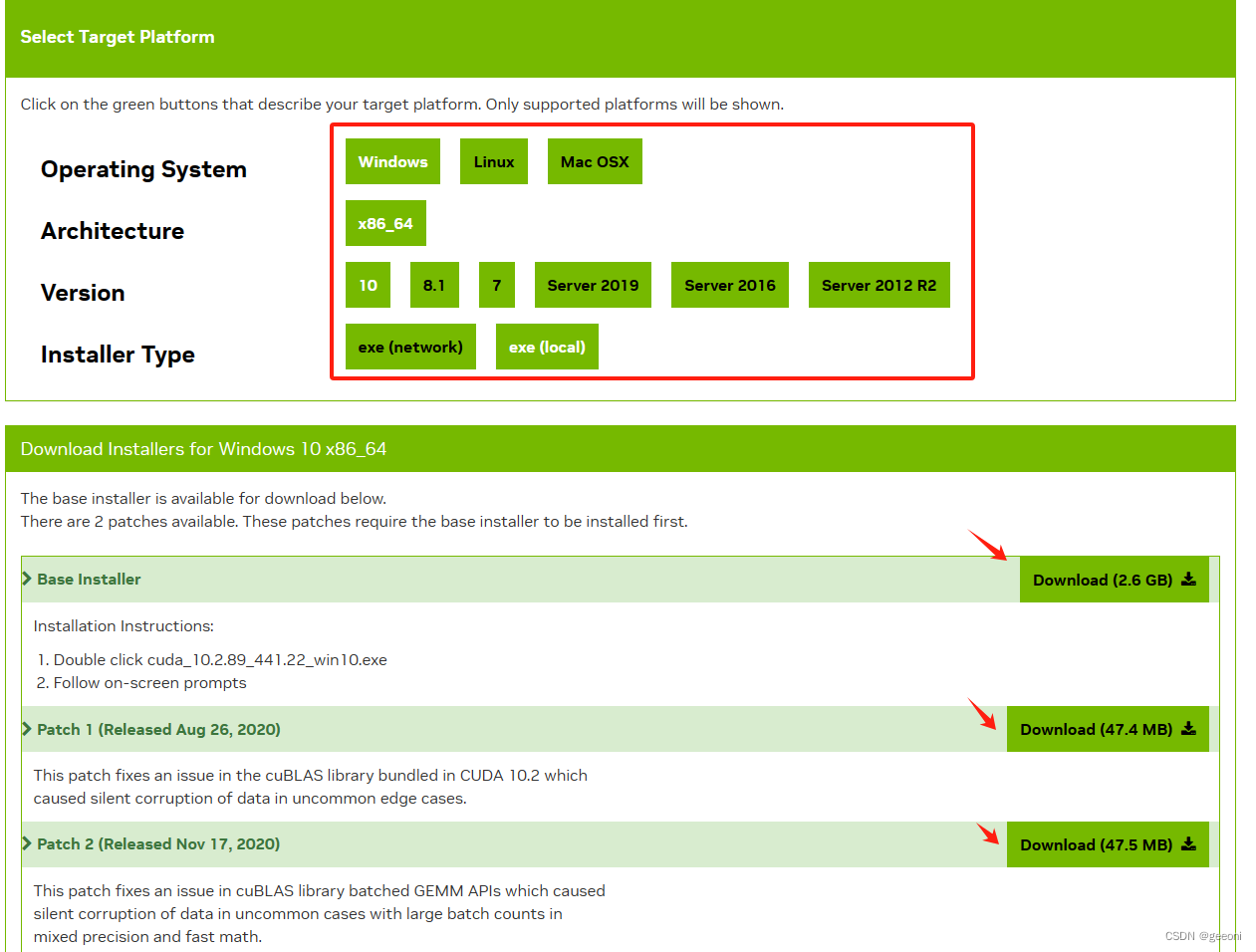
安装包下载完成之后先安装第一个最大的哪个:基本就是一路向下,问你啥都勾选。
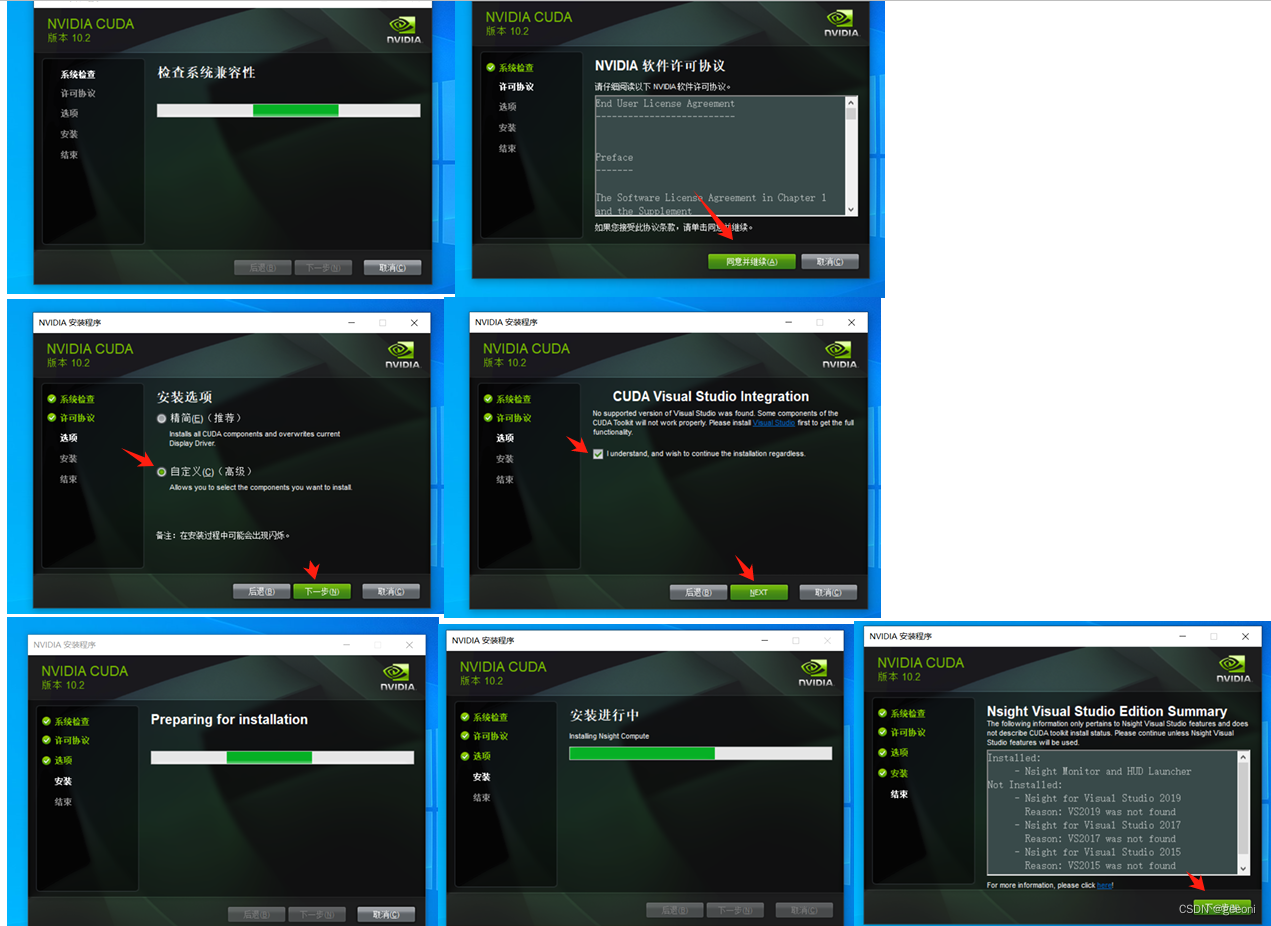
再安装两个比较小的补丁,这个补丁直接精简安装就行。
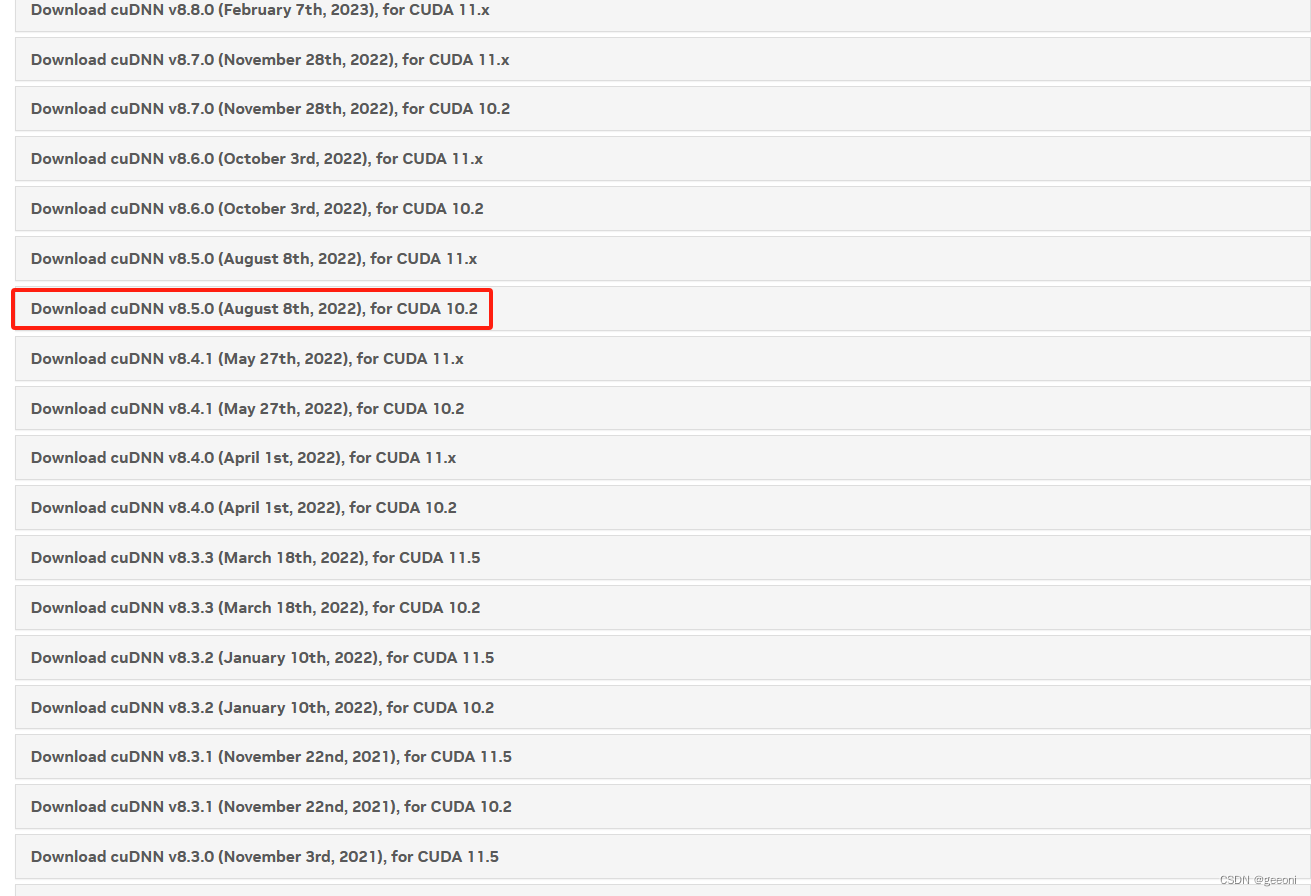
②确定CUDA版本对应的cuDNN版本并安装:
cudnn下载地址:https://developer.nvidia.com/rdp/cudnn-archive (需要注册NV账号),这里面直接写着有对应版本,我这里cuda10.2对应的有挺多版本,任选一个:
③安装pytorch
首先看pytorch与cuda的对应版本关系:
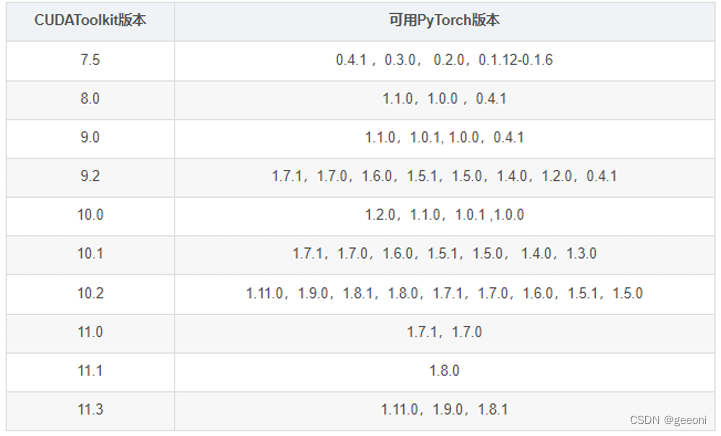
GPU版本的pytorch建议离线安装,安装包地址:https://download.pytorch.org/whl/torch_stable.html。
找到对应的cuda版本,python版本,系统版本进行安装,我这里安装anaconda时python版本是3.7,cuda是10.2,Pytorch版本选择1.9.0,所以最终下载的安装包是:
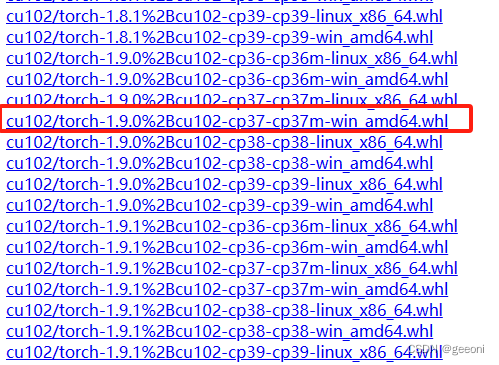
其中cu代表了cuda版本,cp代表了python版本,torch代表要安装的pytorch版本。
安装过程直接参考b站视频:https://www.bilibili.com/video/BV1Cr4y1u76N/?p=6&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=2a10d30b8351190ea06d85c5d0bfcb2a。
后续的torchvision和pycharm的安装都直接看视频来的快。
二、安装docker
进入Docker Desktop下载桌面版的docker

下载完成之后双击打开安装包进行安装,安装完成之后双击打开,如果此时报错:Docker Desktop is unable to detect a Hypervisor
解决:进入控制面板->程序->启用或关闭windows功能->勾选Hyper-V,此时应该会自动重启电脑,如果没有的话手动重启。
此时再次双击打开docker,如果报另一个错,类似下面这样的:
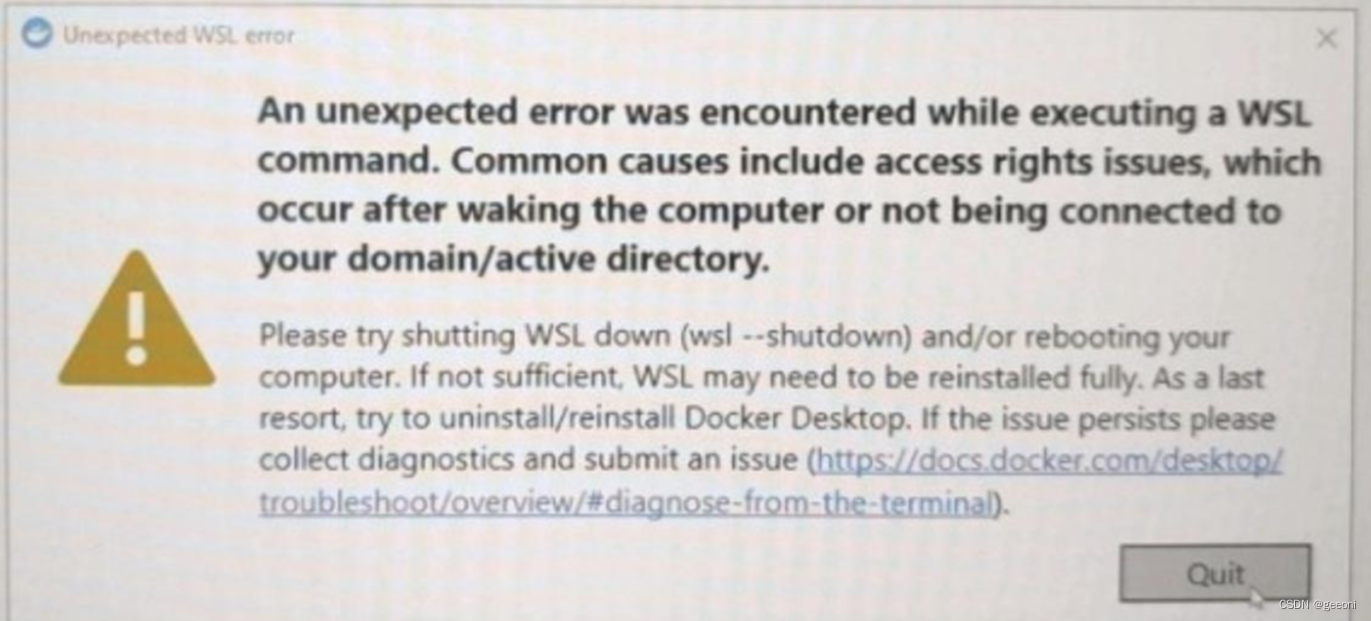
解决:以管理员权限打开powershell,输入wsl --update更新wsl,此时应该就可以了。
打开docker之后,界面应该如下:
三、部署
3.1、安装工具链镜像
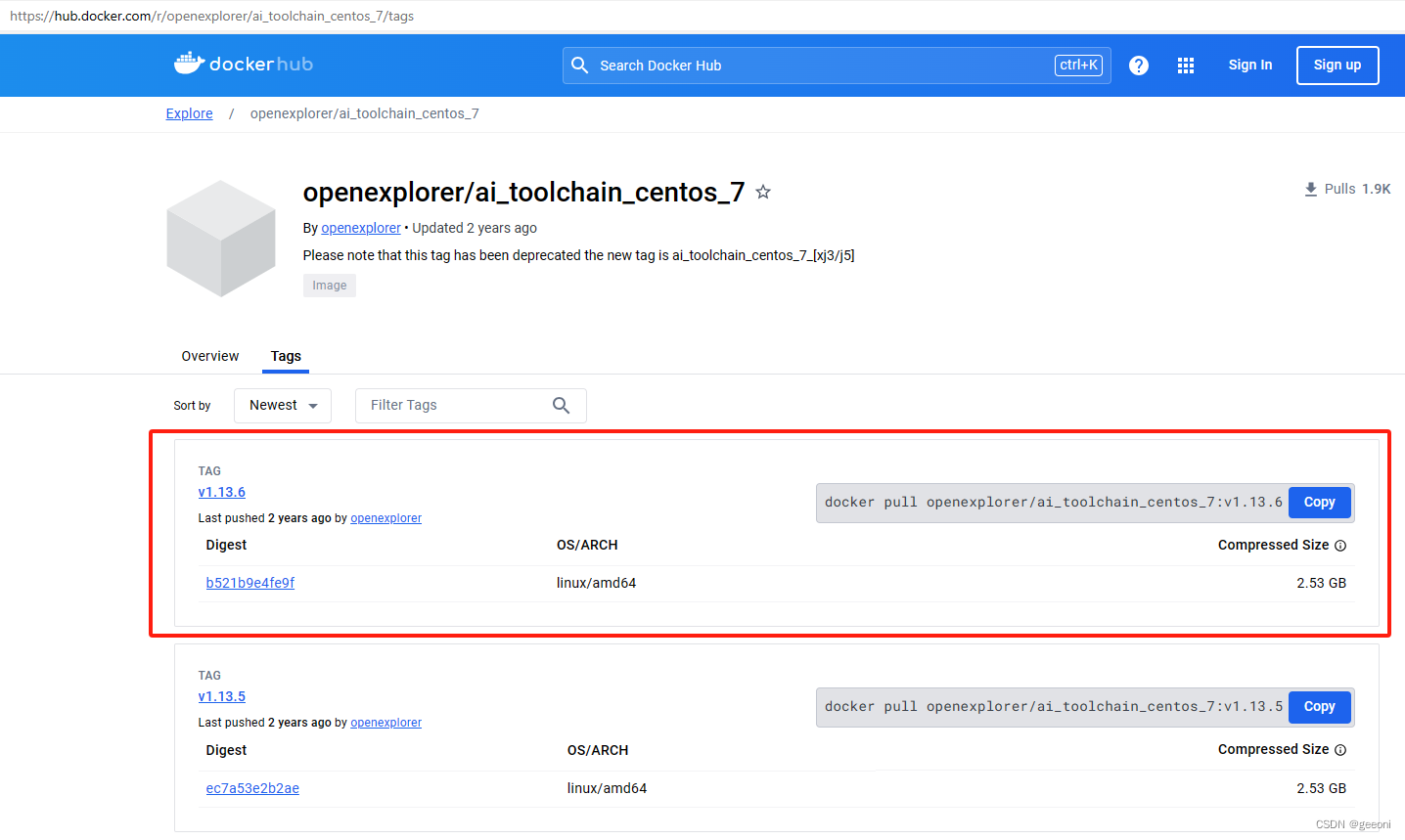
从地平线天工开物cpu docker hub获取部署所需要的CentOS Docker镜像。使用最新的镜像v1.13.6(实测需要梯子才能进这个网站)
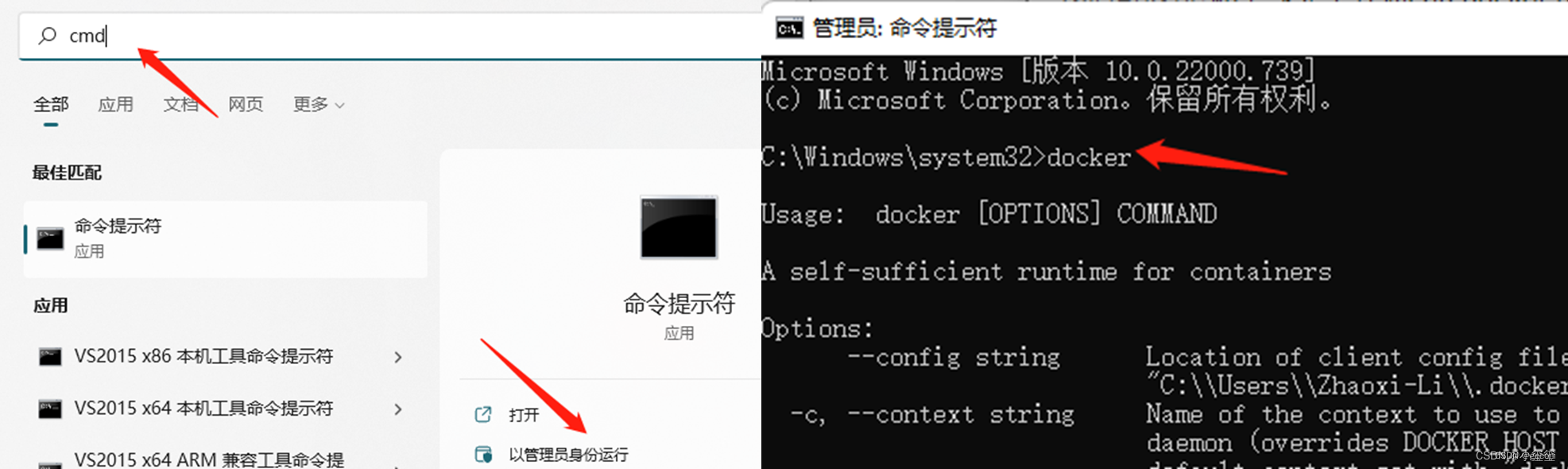
以管理员模式运行CMD,输入docker,可以显示出docker的帮助信息:
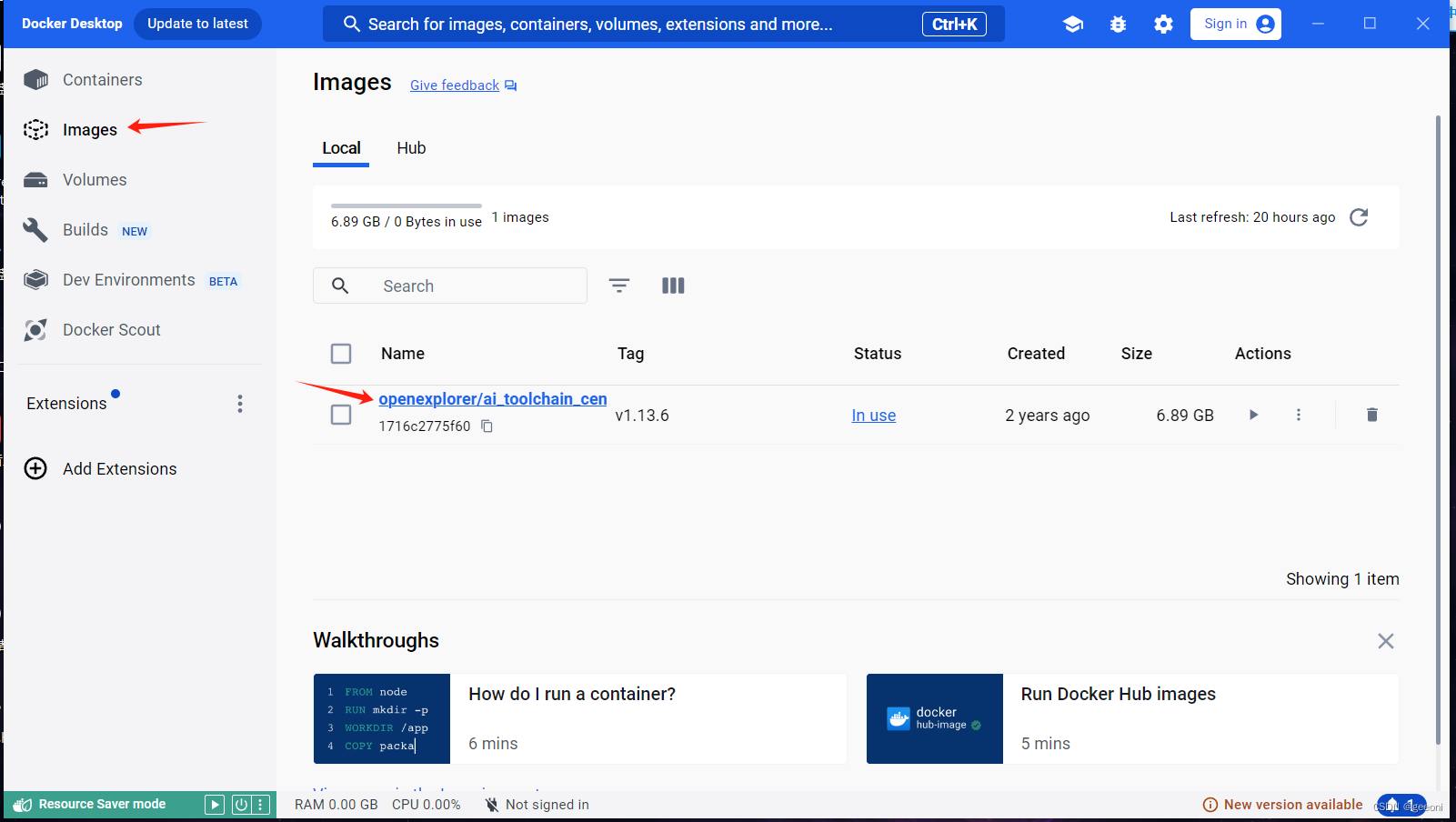
在cmd中输入命令docker pull openexplorer/ai_toolchain_centos_7:v1.13.6,之后会自动开始镜像的安装。安装成功之后,即可在docker中看到成功安装的工具链镜像:
3.2、配置天工开物OpenExplorer工具包
OpenExplorer工具包的下载,需要wget支持,wget的下载链接为:https://eternallybored.org/misc/wget/。下载x64对应的压缩包。
下载完成解压之后如下图:

然后将wget.exe复制到C:\Windows\System32下:
这样就可以了。然后win+R→cmd,输入wget,出现如下的界面说明安装成功:
安装好之后即可在cmd中通过如下命令下载OpenExplorer工具包:也可以自己选择其他版本(https://developer.horizon.ai/forumDetail/136488103547258769)
wget -c ftp://vrftp.horizon.ai/Open_Explorer_gcc_9.3.0/2.2.3/horizon_xj3_open_explorer_v2.2.3a_20220701.tar.gz
3.3、创建深度学习虚拟空间,安装依赖:
①创建虚拟环境:
打开anaconda prompt,创建虚拟环境

创建完成之后进入虚拟环境:conda activate test
②安装ONNX:
由于需要将Pytorch模型是可以转为ONNX模型,所以需要这一步
# 安装关键包ONNX
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx
③安装yolov5需要的一些包:
安装之前最好去搜一搜版本对应关系,这里是python3.7,如果版本不兼容后面会报错。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.1 Pillow>=7.1.2 PyYAML>=5.3.1 requests>=2.23.0 scipy>=1.4.1 tqdm>=4.64.0 tensorboard>=2.4.1 pandas>=1.1.4 seaborn>=0.11.0 ipython psutil thop>=0.1.1
3.4、下载yolov5项目源码并运行
本篇博客大部分参考https://blog.csdn.net/Zhaoxi_Li/article/details/126651890?spm=1001.2014.3001.5502,使用的也是他分享的源码,直接进百度网盘下载项目:https://pan.baidu.com/share/init?surl=K4WhC9vaA7p__uWS-ovn8A,提取码:0A09。
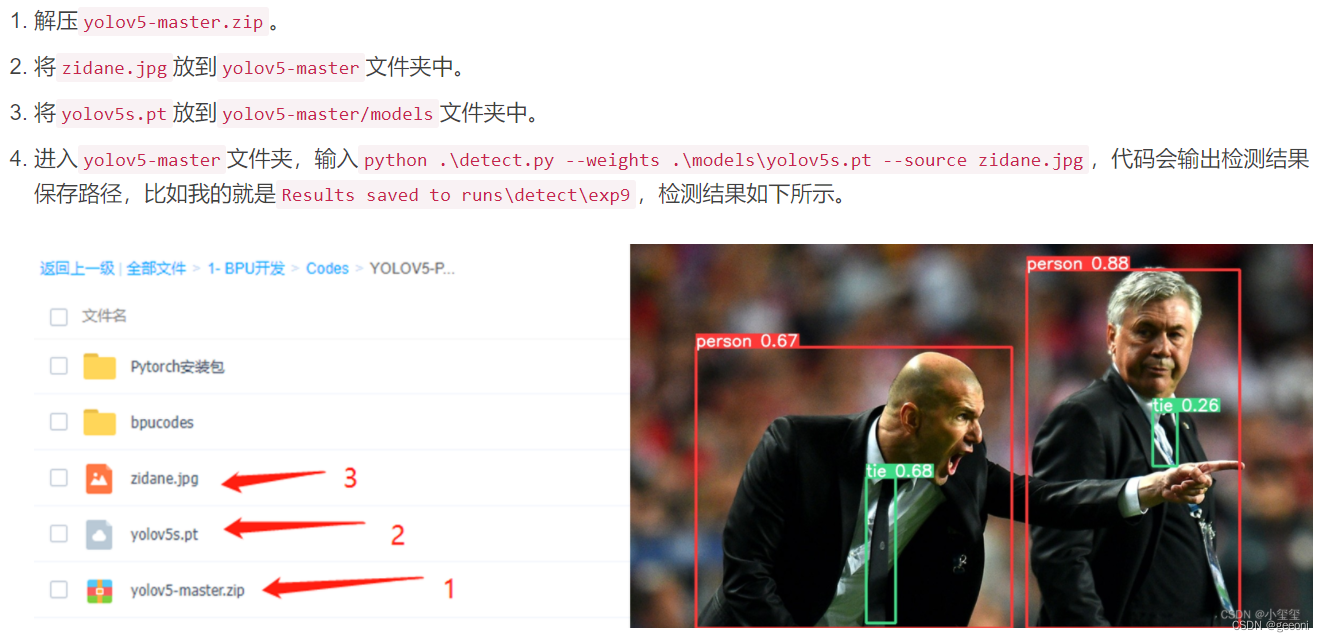
流程如下,可以看到对应目录和操作,需要进入虚拟空间:
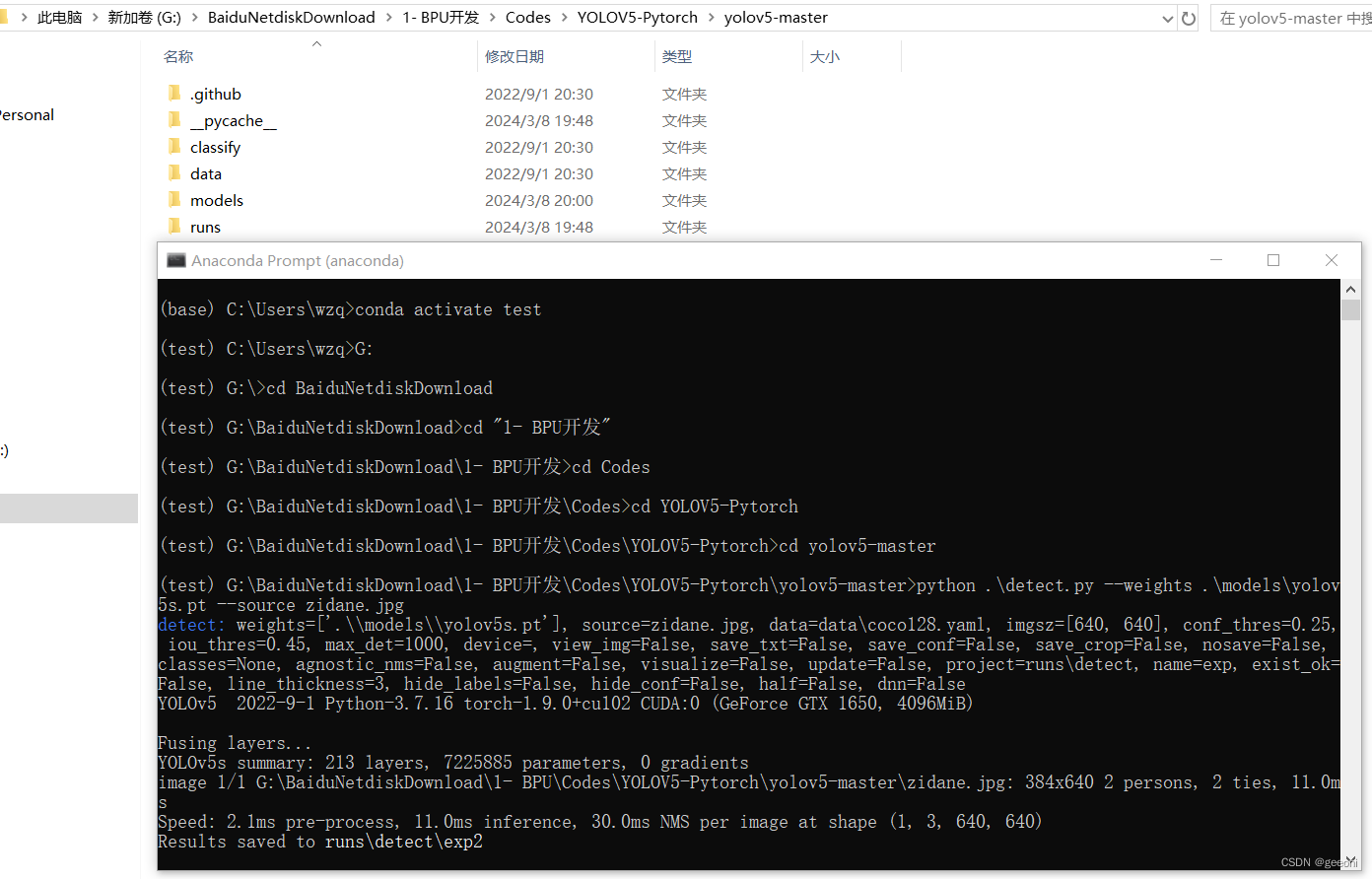
这样测试成功之后环境大概率没问题,可以进行后续,本篇不自己训练模型,直接使用原始模型进行部署。
3.5、pytorch的pt模型文件转onnx
旭日x3派当前BPU支持onnx的opset版本为11,不用这个版本就会报错:
注意所在目录,需要在yolov5-master下。
python .\export.py --weights .\models\yolov5s.pt --include onnx --opset 11
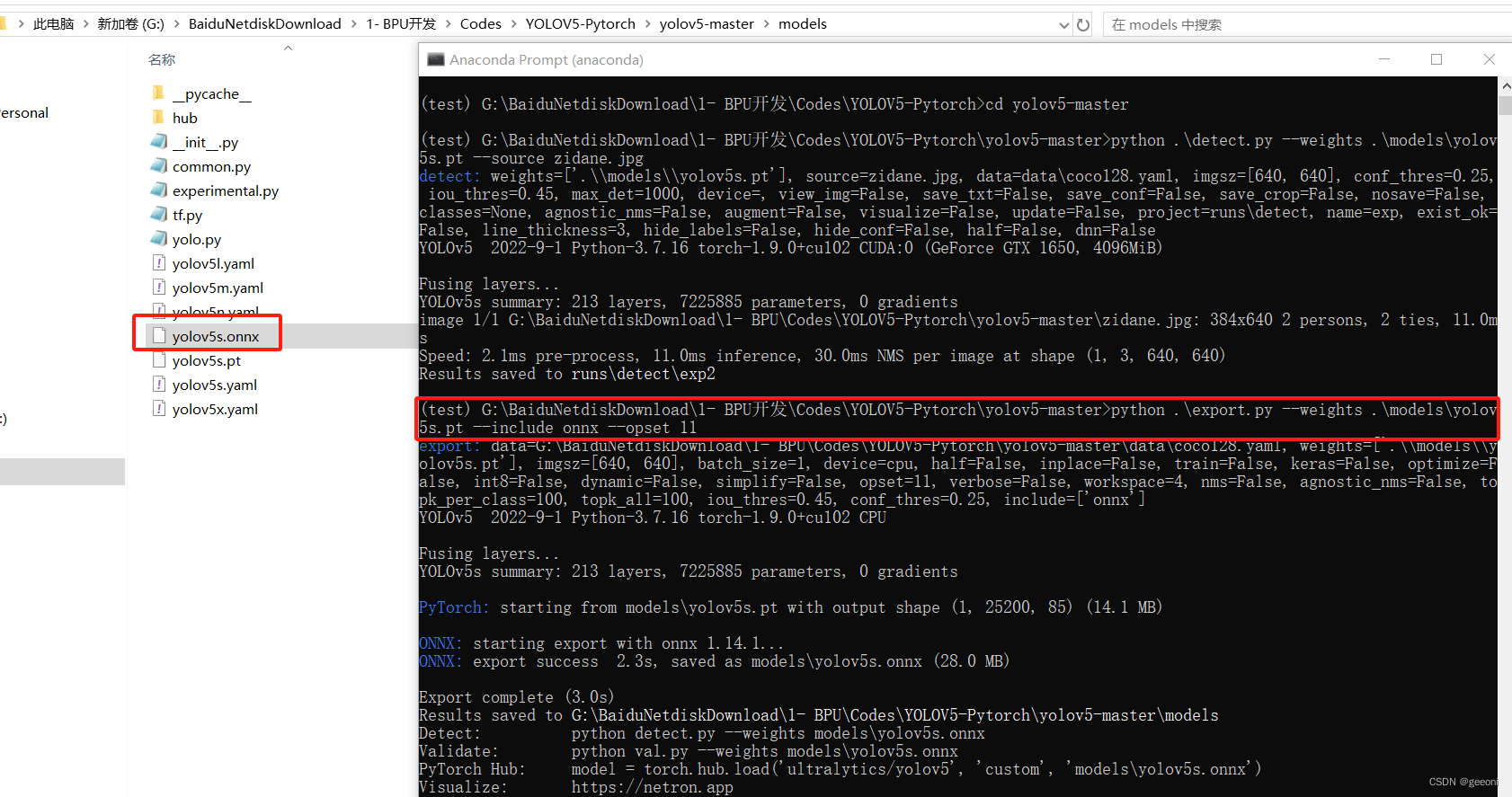
3.6、最重要且最难的部分:ONNX模型转换成bin模型
1、启动docker,将需要用到的文件夹挂载到docker中:
在进入docker之前,先确定几个内容:
******天工开物OpenExplorer根目录:我的环境下是"G:\bushu_xiangguan\horizon_xj3_open_explorer_v2.2.3a_20220701",记得加双引号防止出现空格,该目录要挂载在docker中/open_explorer目录下。
******dataset根目录(放数据集的地方,这里没用到):我的环境下是"G:\bushu_xiangguan\Codes\dateset",记得加双引号防止出现空格,该目录需要挂载在docker中的/data/horizon_x3/data目录下。
******辅助文件夹根目录:官方教程其实是没有这个过程的,把这个挂载在docker里,就是充当个类似U盘的介质。比如在我的环境下是"G:\bushu_xiangguan\BPUCodes",我可以在windows里面往这个文件夹拷贝数据,这些数据就可以在docker中使用,该目录需要挂载在docker中的/data/horizon_x3/codes目录下。
上面这些目录都需要自己建。
win+R→cmd,进入命令符,输入如下指令即可进入docker:
CMD不支持换行,记得删掉后面的\然后整理为一行
docker run -it --rm \
-v "G:\bushu_xiangguan\horizon_xj3_open_explorer_v2.2.3a_20220701":/open_explorer \
-v "G:\bushu_xiangguan\Codes\dateset":/data/horizon_x3/data \
-v "G:\bushu_xiangguan\BPUCodes":/data/horizon_x3/codes \
openexplorer/ai_toolchain_centos_7:v1.13.6
两个箭头是挂载的目标目录:其中天工开物OpenExplorer根目录挂载到了open_explorer目录下;dataset根目录和辅助文件夹根目录挂载到了data/horizon_x3下的codes和data目录下。
2、开启模型转换主流程:
首先在BPUcodes下新建yolov5目录,在yolov5中再新建一个bpucodes,将前面转换好的onnx模型放进去。
2.1、onnx模型检查:
docker中进入bpucodes目录:
输入hb_mapper checker --model-type onnx --march bernoulli2 --model yolov5s.onnx开始模型检查。如下图即检查成功。
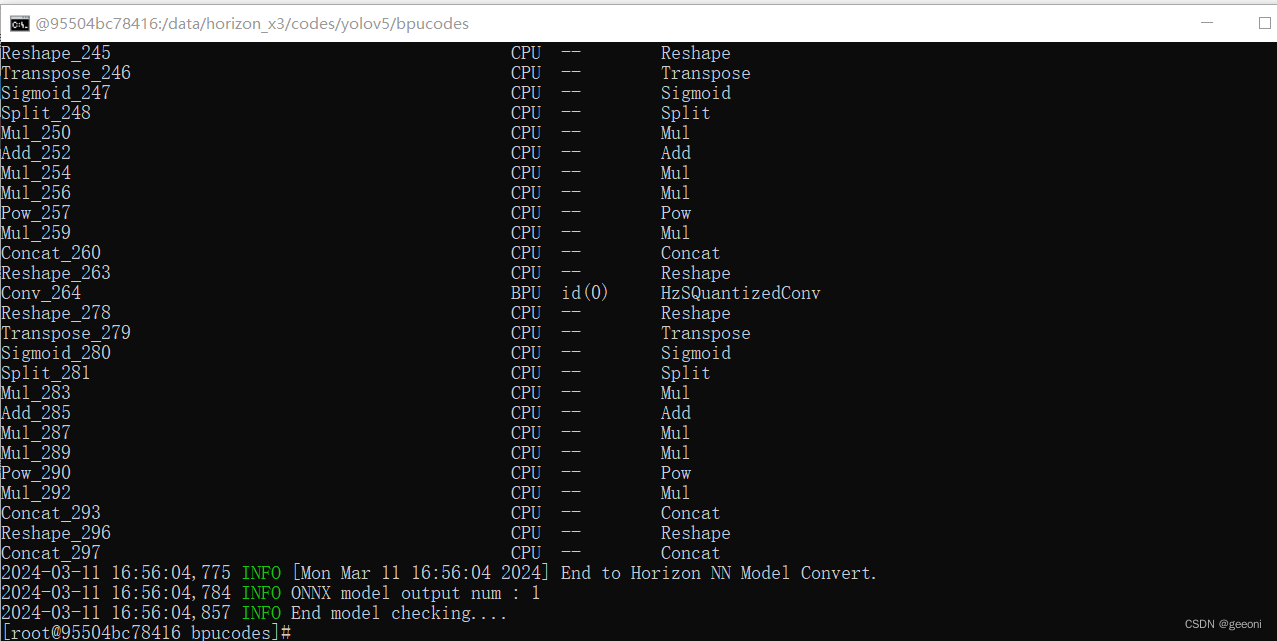
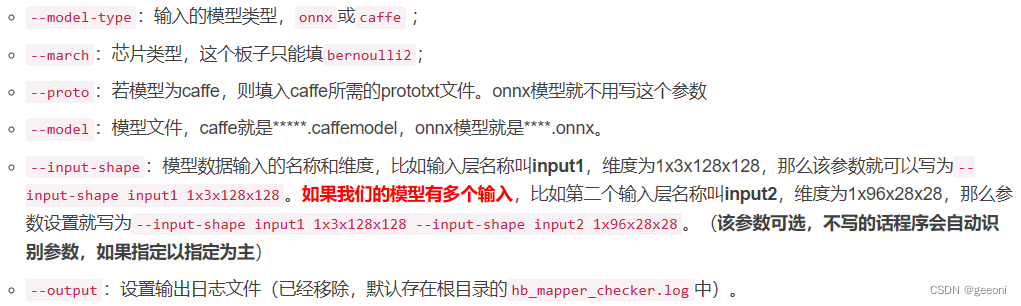
检查指令的各个参数含义如下:
实际上在天工开物工具包里提供了脚本进行模型转换各个步骤,以yolov5为例子,路径如下:
G:\bushu_xiangguan\horizon_xj3_open_explorer_v2.2.3a_20220701\ddk\samples\ai_toolchain\horizon_model_convert_sample\04_detection\03_yolov5s\mapper

上面进行模型验证的命令实际上也就是01_check.sh执行的主要内容。
2.2、准备校准数据
这步实际上就是运行02_preprocess.sh这个脚本,这个脚本的核心调用的是python文件data_preprocess.py。它位于:
G:\bushu_xiangguan\horizon_xj3_open_explorer_v2.2.3a_20220701\ddk\samples\ai_toolchain\horizon_model_convert_sample。
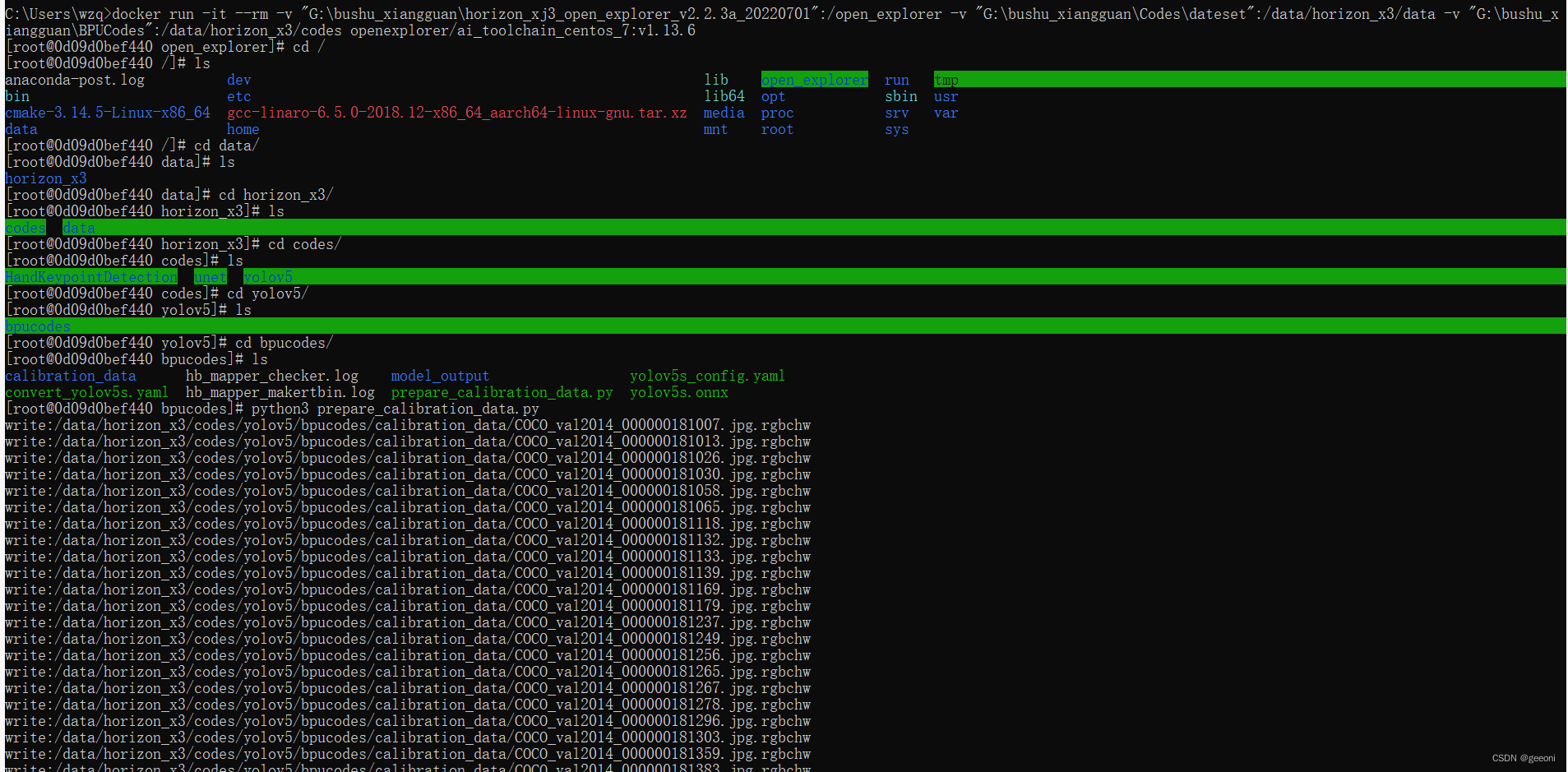
如果要部署自己训练的模型的话,这个工具包里没有对应的脚本去准备校准数据,所以这个py是比较好的选择,将写完的prepare_calibration_data.py文件也放进自己建的bpucodes文件夹中,这里面的src_root就是待校准的图片100张,这里使用coco数据集里的。dst_root就是保存校准完的图片的文件夹。
# prepare_calibration_data.py
import os
import cv2
import numpy as npsrc_root = '/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/calibration_data/coco'
cal_img_num = 100 # 想要的图像个数
dst_root = '/data/horizon_x3/codes/yolov5/bpucodes/calibration_data'## 1. 从原始图像文件夹中获取100个图像作为校准数据
num_count = 0
img_names = []
for src_name in sorted(os.listdir(src_root)):if num_count > cal_img_num:breakimg_names.append(src_name)num_count += 1# 检查目标文件夹是否存在,如果不存在就创建
if not os.path.exists(dst_root):os.system('mkdir {0}'.format(dst_root))## 2 为每个图像转换
# 参考了OE中/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/python/data/下的相关代码
# 转换代码写的很棒,很智能,考虑它并不是官方python包,所以我打算换一种写法## 2.1 定义图像缩放函数,返回为np.float32
# 图像缩放为目标尺寸(W, H)
# 值得注意的是,缩放时候,长宽等比例缩放,空白的区域填充颜色为pad_value, 默认127
def imequalresize(img, target_size, pad_value=127.):target_w, target_h = target_sizeimage_h, image_w = img.shape[:2]img_channel = 3 if len(img.shape) > 2 else 1# 确定缩放尺度,确定最终目标尺寸scale = min(target_w * 1.0 / image_w, target_h * 1.0 / image_h)new_h, new_w = int(scale * image_h), int(scale * image_w)resize_image = cv2.resize(img, (new_w, new_h))# 准备待返回图像pad_image = np.full(shape=[target_h, target_w, img_channel], fill_value=pad_value)# 将图像resize_image放置在pad_image的中间dw, dh = (target_w - new_w) // 2, (target_h - new_h) // 2pad_image[dh:new_h + dh, dw:new_w + dw, :] = resize_imagereturn pad_image## 2.2 开始转换
for each_imgname in img_names:img_path = os.path.join(src_root, each_imgname)img = cv2.imread(img_path) # BRG, HWCimg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB, HWCimg = imequalresize(img, (640, 640))img = np.transpose(img, (2, 0, 1)) # RGB, CHW# 将图像保存到目标文件夹下dst_path = os.path.join(dst_root, each_imgname + '.rgbchw')print("write:%s" % dst_path)# 图像加载默认就是uint8,但是不加这个astype的话转换模型就会出错# 转换模型时候,加载进来的数据竟然是float64,不清楚内部是怎么加载的。img.astype(np.uint8).tofile(dst_path) print('finish')更改src_root 和drt_root为自己的路径。执行python3 prepare_callbration_data.py
2.3、模型转换
模型转换的核心在于配置目标的yaml文件。官方也提供了一个yolov5s_config.yaml可供用户直接试用,每个参数都给了注释。然而模型转换的配置文件参数太多,如果想改参数都不知道如何下手。本yaml模板适用于的模型具有如下属性:无自定义层,换句话说,BPU支持该模型的所有层。输入节点只有1个,且输入是图像。
自己写的yolov5_simple.yaml文件也放到bpucodes下。
model_parameters:onnx_model: 'yolov5s.onnx'output_model_file_prefix: 'yolov5s'march: 'bernoulli2'
input_parameters:input_type_train: 'rgb'input_layout_train: 'NCHW'input_type_rt: 'nv12'norm_type: 'data_scale'scale_value: 0.003921568627451input_layout_rt: 'NHWC'
calibration_parameters:cal_data_dir: './calibration_data'calibration_type: 'max'max_percentile: 0.9999
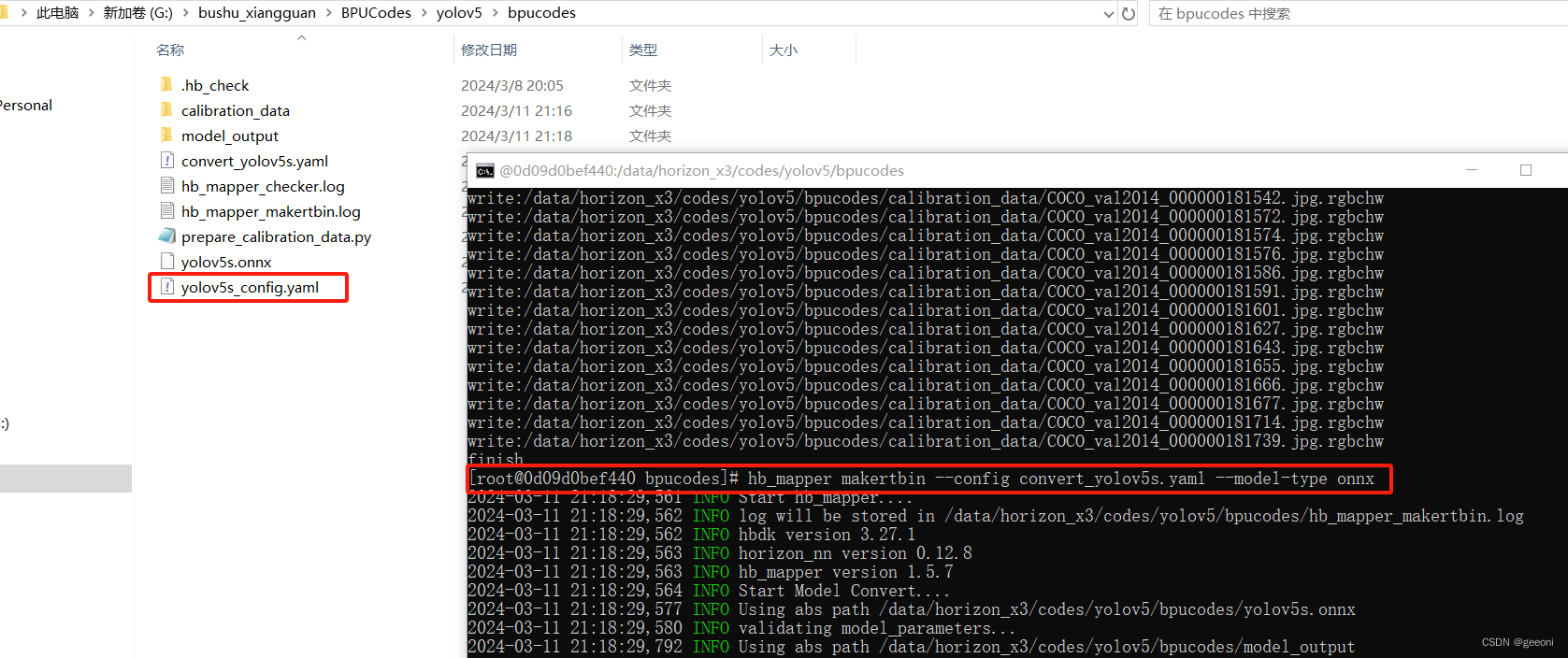
compiler_parameters:compile_mode: 'latency'optimize_level: 'O3'debug: Falsecore_num: 2 # x3p是双核BPU,所以指定为2可以速度更快输入:hb_mapper makertbin --config convert_yolov5s.yaml --model-type onnx即开始模型转换。转换成功后,得到model_output/yolov5s.bin,它就是上板运行所需要的模型文件。
四、上板运行

将这些文件拷贝到x3派新建的测试文件夹中,一部分是要到百度网盘中获取的。
输入sudo apt-get install libopencv-dev安装opencv库,进入这里这个test_yolov5文件夹,执行:python3 setup.py build_ext --inplace编译后处理代码,得到lib/pyyolotools.cpython-38-aarch64-linux-gnu.so文件。
输入:sudo python3 inference_model_bpu.py进行推理,推理完成之后会保存结果图片:
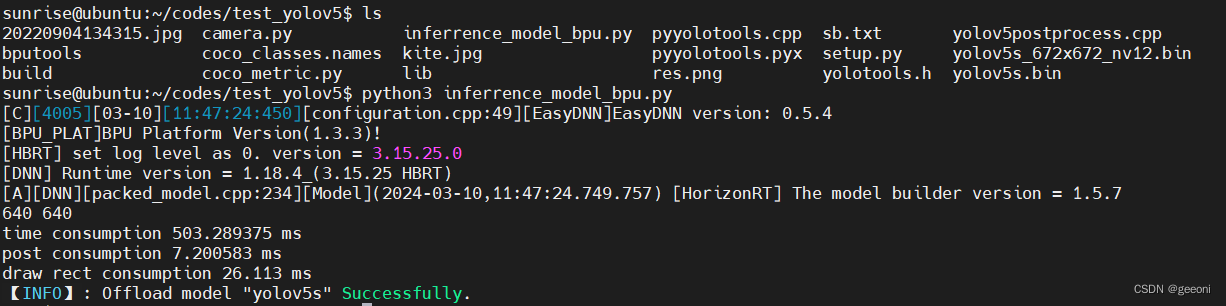
这个未优化的初始yolvv5模型还是很捞的,推理速度很慢。但是这里后处理速度很快,cython封装加速的结果。后处理就是指模型推理完成之后在图片上画出结果的过程。
相关文章:
地平线旭日x3派部署yolov5--全流程
地平线旭日x3派部署yolov5--全流程 前言一、深度学习环境安装二、安装docker三、部署3.1、安装工具链镜像3.2、配置天工开物OpenExplorer工具包3.3、创建深度学习虚拟空间,安装依赖:3.4、下载yolov5项目源码并运行3.5、pytorch的pt模型文件转onnx3.6、最…...

【Golang星辰图】Go语言云计算SDK全攻略:深入Go云存储SDK实践
Go语言云计算和存储SDK全面指南 前言 在当今数字化时代,云计算和存储服务扮演着至关重要的角色,为应用程序提供高效、可靠的基础设施支持。本文将介绍几种流行的Go语言SDK,帮助开发者与AWS、Google Cloud、Azure、MinIO、 阿里云和腾讯云等…...
深入理解TCP:序列号、确认号和自动ACK的艺术
深入理解TCP:序列号、确认号和自动ACK的艺术 在计算机网络的世界里,TCP(传输控制协议)扮演着至关重要的角色。它确保了数据在不可靠的网络环境中可靠地、按顺序地传输。TCP的设计充满智慧,其中序列号(Seq&a…...

家电工厂5G智能制造数字孪生可视化平台,推进家电工业数字化转型
家电5G智能制造工厂数字孪生可视化平台,推进家电工业数字化转型。随着科技的飞速发展,家电行业正迎来一场前所未有的数字化转型。在这场制造业数字化转型中,家电5G智能制造工厂数字孪生可视化平台扮演着至关重要的角色。本文将从数字孪生技术…...
ctf_show笔记篇(web入门---代码审计)
301:多种方式进入 从index.php页面来看 只需要访问index.php时session[login]不为空就能访问 那么就在访问index.php的时候上传login 随机一个东西就能进去从checklogin页面来看sql注入没有任何过滤 直接联合绕过 密码随意 还有多种方式可以自己去看代码分析 30…...

c语言的字符串函数详解
文章目录 前言一、strlen求字符串长度的函数二、字符串拷贝函数strcpy三、链接或追加字符串函数strcat四、字符串比较函数strcmp五、长度受限制字符函数六、找字符串2在字符串1中第一次出现的位置函数strstr七、字符串切割函数strtok(可以切割分隔符)八、…...

HarmonyOS NEXT应用开发—折叠屏音乐播放器方案
介绍 本示例介绍使用ArkUI中的容器组件FolderStack在折叠屏设备中实现音乐播放器场景。 效果图预览 使用说明 播放器预加载了歌曲,支持播放、暂停、重新播放,在折叠屏上,支持横屏悬停态下的组件自适应动态变更。 实现思路 采用MVVM模式进…...
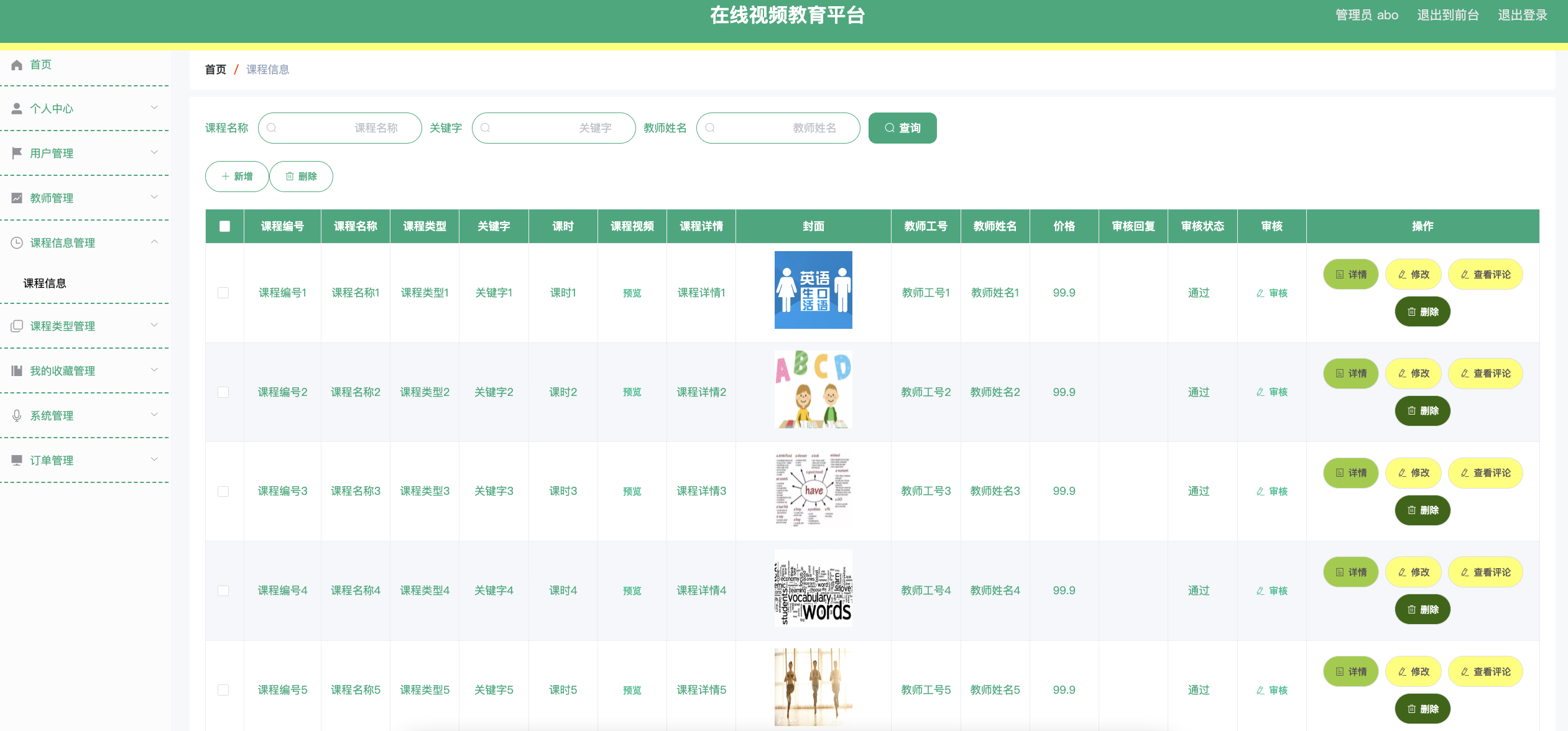
Java项目:55 springboot基于SpringBoot的在线视频教育平台的设计与实现015
作者主页:舒克日记 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 项目介绍 在线视频教育平台分为管理员和用户、教师三个角色的权限模块。 管理员所能使用的功能主要有:首页、个人中心、用户管理、教师管理、课程信…...
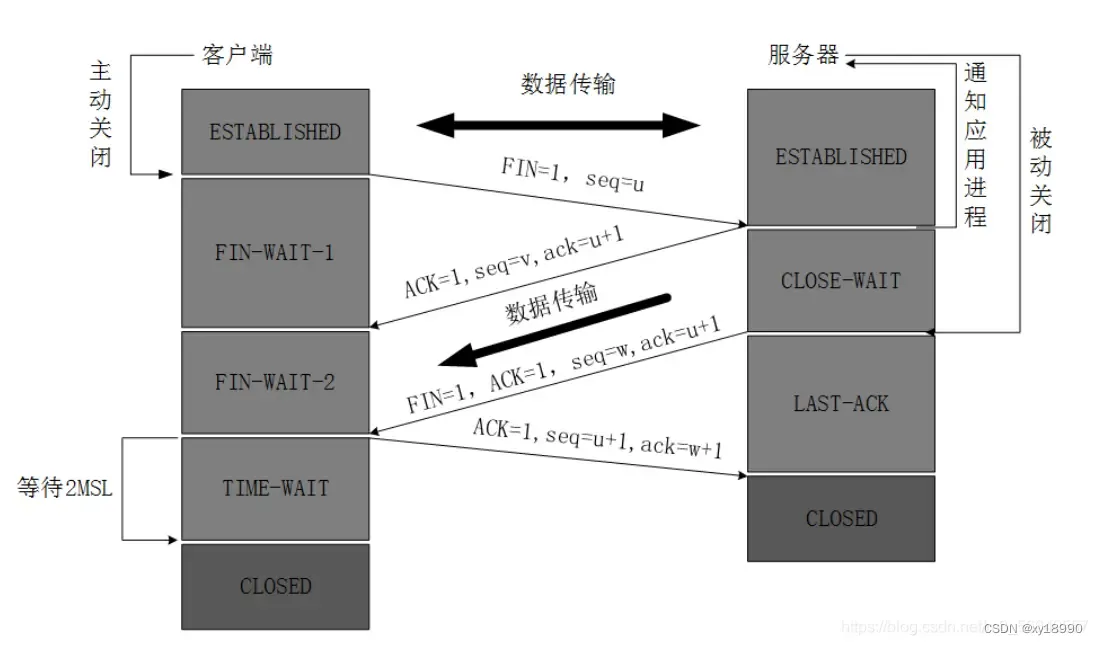
说下你对TCP以及TCP三次握手四次挥手的理解?
参考自简单理解TCP三次握手四次挥手 什么是TCP协议? TCP( Transmission control protocol )即传输控制协议,是一种面向连接、可靠的数据传输协议,它是为了在不可靠的互联网上提供可靠的端到端字节流而专门设计的一个传输协议。 面向连接&a…...

wsl-oracle 安装 omlutils
wsl-oracle 安装 omlutils 1. 安装 cmake 和 gcc-c2. 安装 omlutils3. 使用 omlutils 创建 onnx 模型 1. 安装 cmake 和 gcc-c sudo dnf install -y cmake gcc-c2. 安装 omlutils pip install omlutils-0.10.0-cp312-cp312-linux_x86_64.whl不需要安装 requirements.txt&…...

Python类属性和对象属性大揭秘!
在Python中,对象和类紧密相连,它们各自拥有一些属性,这些属性在我们的编程中起着至关重要的作用。那么,什么是类属性和对象属性呢?别急,让我慢慢给你解释。 类属性 首先,类属性是定义在类本…...

北斗卫星在桥隧坡安全监测领域的应用及前景展望
北斗卫星在桥隧坡安全监测领域的应用及前景展望 北斗卫星系统是中国独立研发的卫星导航定位系统,具有全球覆盖、高精度定位和海量数据传输等优势。随着卫星导航技术的快速发展,北斗卫星在桥隧坡安全监测领域正发挥着重要的作用,并为相关领域…...
如何通过堡垒机JumpServer使用VisualCode 连接服务器进行开发
前言:应用场景 我们经常会碰到需要远程登录到内网服务器进行开发的场景,一般的做法都是通过VPN登录回局域网,然后配置ftp或者ssh使用开发工具链接到服务器上进行开发。如果没有出现问题,那么一切都正常,但到了出现问题…...

【Linux】进程优先级
🌎进程的优先级 文章目录: 进程状态 优先级相关 什么是优先级 为什么要有优先级 进程的优先级 调整进程优先级 调整优先级 优先级极限测试 Linux的调度与切换 总结 前言: 进程…...
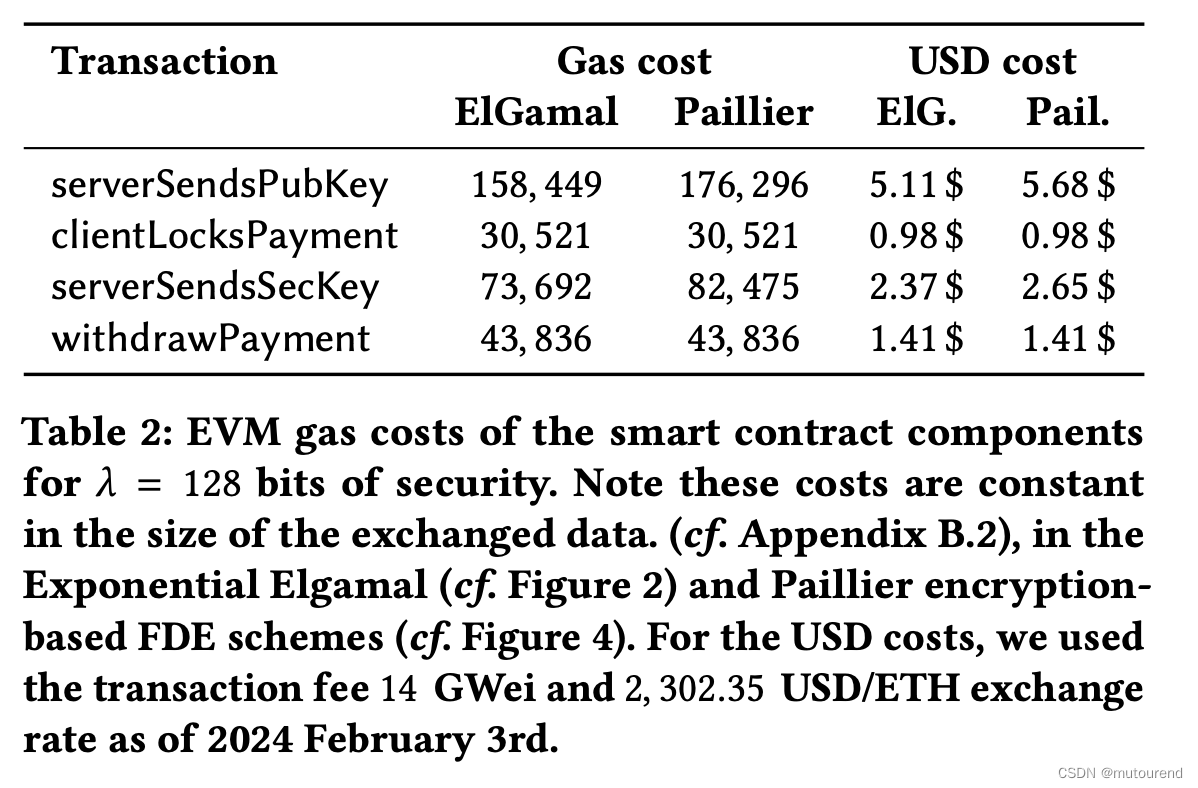
Fair Data Exchange:区块链实现的原子式公平数据交换
1. 引言 2024年斯坦福大学和a16z crypto research团队 论文 Atomic and Fair Data Exchange via Blockchain 中,概述了一种构建(包含过期EIP-4844 blobs的)fair data-markets的协议。该论文源自a16z crypto的暑期实习计划,与四名…...

详解优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器
代码示例在最后。 认识一下ThreadPoolTaskExecutor org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor这是由Sping封装的加强版线程池,其实是Spring使用装饰者模式对ThreadPoolExecutor进一步优化。 它不仅拥有ThreadPoolExecutor所有的核心参数…...
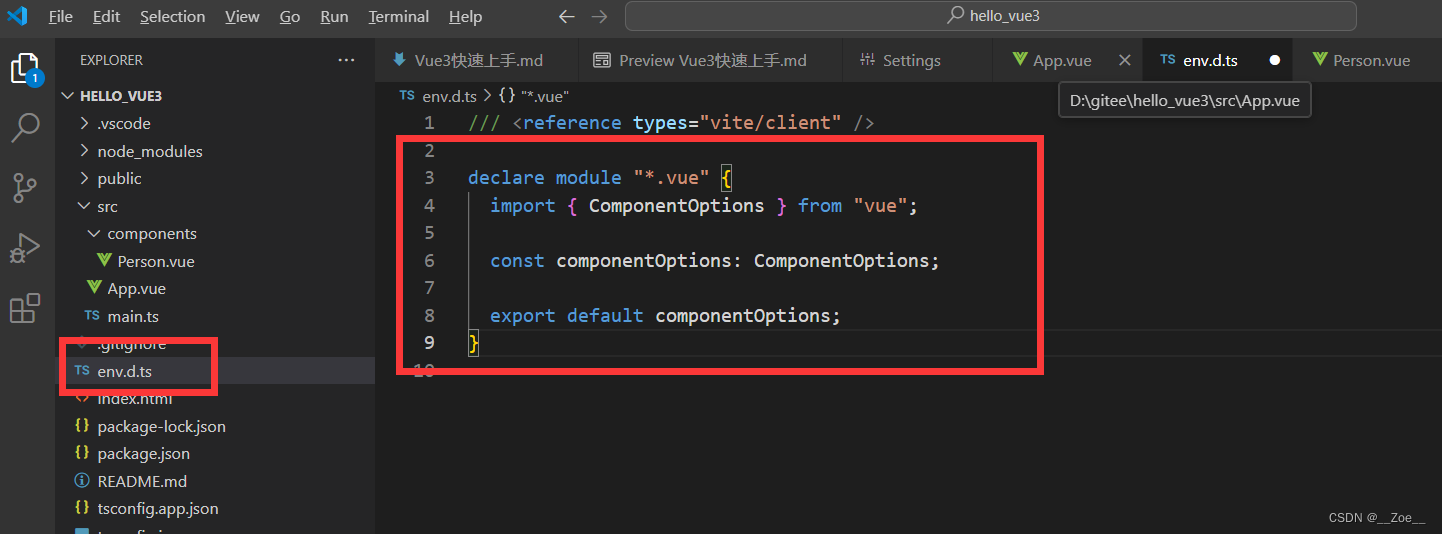
Vue3+TS+Vite 找不到模块“@/components/xxx/xxx”或其相应的类型声明
引入vue文件时文件是存在的,引入路径也是对的,报找不到模块,有一些解决方案是在tsconfig.json里面做一些配置,大家可以自行百度(不知道是不是我百度的不对,我的没有解决)还有一种是在项目根目录…...
Vue3-响应式基础:单文件和组合式文件
单文件:html <!DOCTYPE html> <html> <head><title>响应式基础</title> </head> <body><div id"app" ><!-- dynamic parameter:同样在指令参数上也可以使用一个 JavaScript 表达式,需要包…...
DVWA-File Upload文件上传
什么是文件上传漏洞? 黑客利用文件上传后服务器解析处理文件的漏洞上传一个可执行的脚本文件,并通过此脚本文件获得了执行服务器端命令的能力。 造成文件上传漏洞的原因: 1.服务器配置不当 2.开源编辑器上传漏洞 3.本地文件上传限制被绕过 4.过滤不严格被…...

python之word操作
#pip install python-docx import docx import os pathos.path.abspath(__file__) file_pathos.path.join(path,"大题.docx") print(path) print(file_path) objdocx.Document("大题.docx") #第一个段落 p1obj.paragraphs[2] # print(p1.text) #所有段落 #…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...