ChatGPT 一本正经的胡说八道 那也看看原理吧

最近,ChatGPT横空出世。这款被马斯克形容为“强大到危险”的AI,不但能够与人聊天互动,还能写文章、改代码。于是,人们纷纷想让AI替自己做些什么,有人通过两分钟的提问便得到了一篇完美的论文,有人希望它能帮自己写情书、完成工作

我觉得Musk担心的应该是‘信息茧房’中的‘思考劫持’
大家可以查一下传播学中的这两个概念
几个测试案例

小学白念了,这是哪家不正经的小学教这个

你把柳传志往哪放...

这.....
总结,就这人工智障,还图灵测试...
ChatGPT基本原理
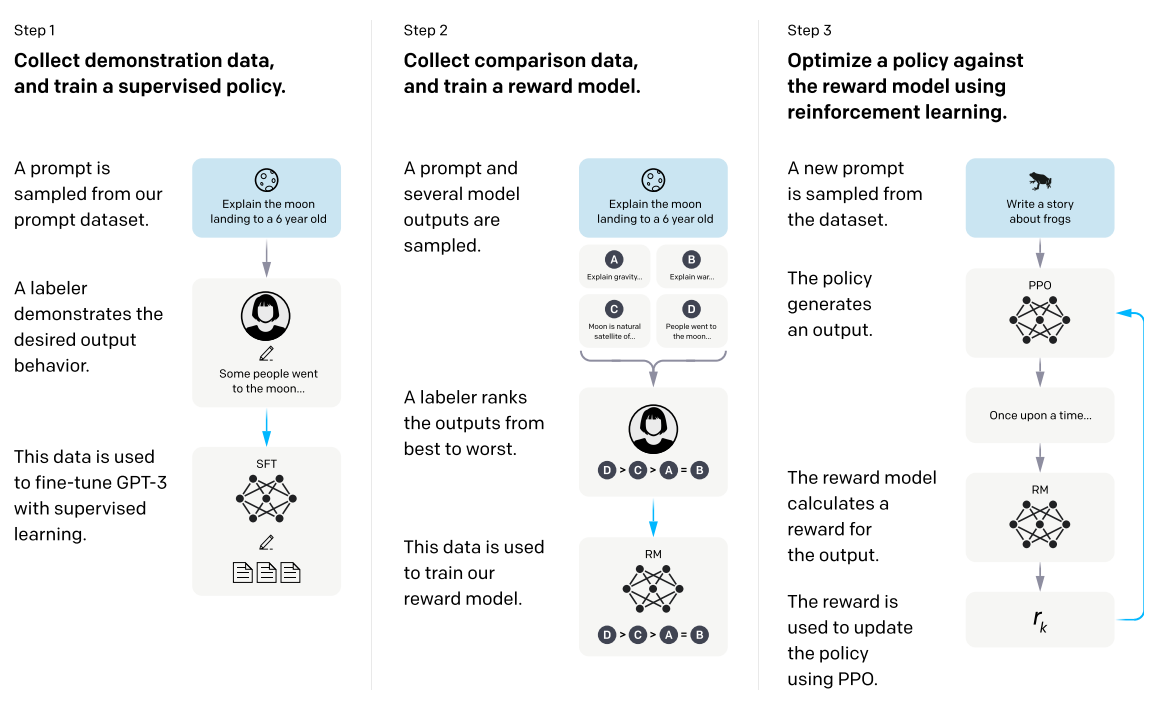
第一步 收集数据,训练有监督的策略模型
第二步 收集对比数据,训练回报模型
第三步 使用强化学习,增强回报模型优化策略
SFT:生成模型GPT的有监督精调 (supervised fine-tuning)
RM:奖励模型的训练(reward model training)
PPO:近端策略优化模型( reinforcement learning via proximal policy optimization)

找了一堆外包,可以看出人的干预有多重要
补充知识
prompt
Prompting指的是在文本上附加额外的提示(Prompt)信息作为输入,将下游的预测等任务转化为语言模型(Language Model)任务,并将语言模型的预测结果转化为原本下游任务的预测结果
对于传统的Fine-tuning范式,以BERT为例,我们会使用PLM提取[CLS]位置的特征,将其作为句子的特征,并对情感分类任务训练一个分类器,使用特征进行分类
对于Prompting,它的流程分为三步
在句子上添加Prompt。一般来说,Prompt分为两种形式,分别是完形填空(用于BERT等自编码PLM)与前缀(用于GPT等自回归PLM)
例如
I love this movie. It is a [MASK] movie. (完形填空模式)
I love this movie. The movie is (前缀模式)
2.根据Prompt的形式,在[MASK]位置或Prompt前缀的后面进行预测单词
3. 根据预先定义的Verbalizer(标签词映射)将单词转化为预测结果,若预测单词’Good’则情感倾向为正向,若预测结果为单词’Bad’则情感倾向为负向
SFT
GPT模型通过有监督的Prompt数据进行精调,其实就是做next token prediction任务。然后用精调后的模型对每个输入的[文本+prompt]进行generate,生成4~9个输出,并且进行解码操作
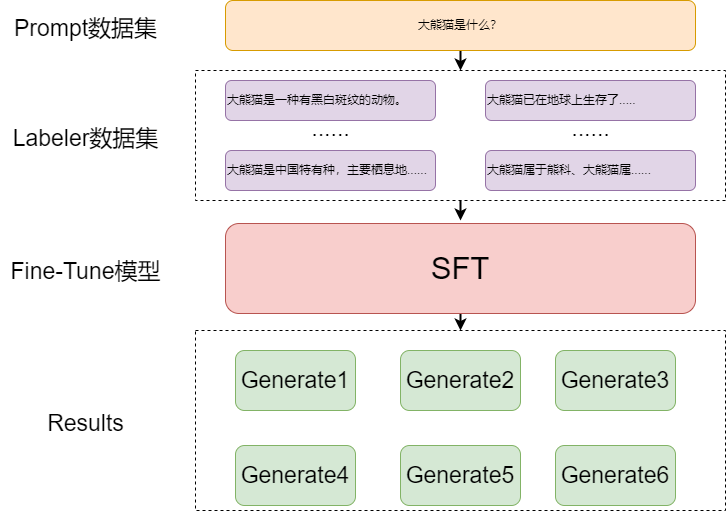
数据举例
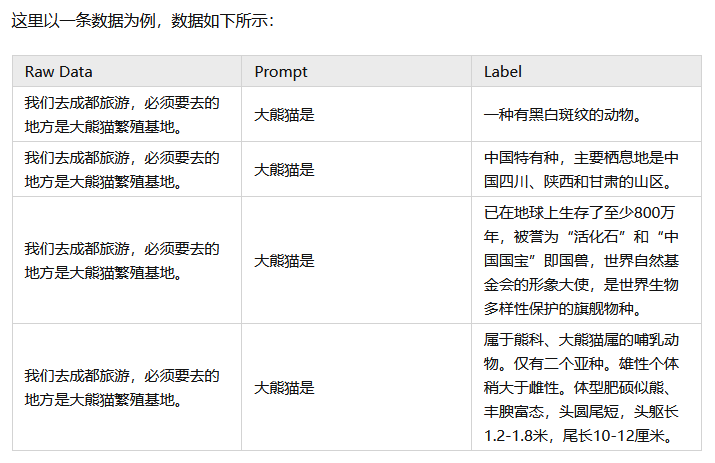
raw_data = "我们去成都旅游,必须要去的地方是大熊猫繁殖基地。"
prompt = "大熊猫是"
labels = ["一种有黑白斑纹的动物。","中国特有种,主要栖息地是中国四川、陕西和甘肃的山区。",
"已在地球上生存了至少800万年,被誉为“活化石”和“中国国宝”即国兽,世界自然基金会的形象大使,是世界生物多样性保护的旗舰物种。",
"属于熊科、大熊猫属的哺乳动物。仅有二个亚种。雄性个体稍大于雌性。体型肥硕似熊、丰腴富态,头圆尾短,头躯长1.2-1.8米,尾长10-12厘米。"]
combine_data = [raw_data+prompt+label for label in labels]RM
RM模型的作用是对生成的文本进行打分排序,让模型生成的结果更加符合人类的日常理解习惯,更加符合人们想要的答案
RM模型主要分为两个部分:训练数据获取、模型训练
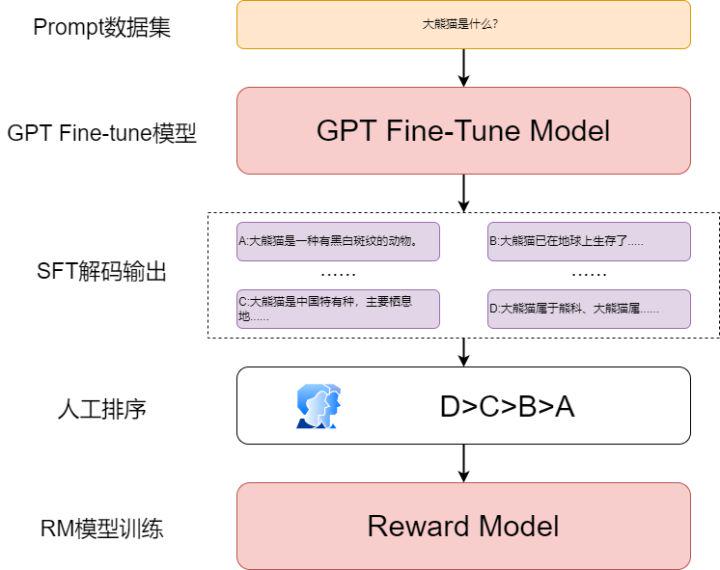
在原论文中使用GPT的架构做了一个reward model,这里需要注意的是要将模型的输出映射成维度为1的打分向量,也就是增加一个linear结构
RM模型的主要点还是在于人工参与的训练数据构建部分,将训练好的SFT模型输入Prompt进行生成任务,每个Prompt生成4~9个文本,然后人为的对这些文本进行排序
将每个Prompt生成的文本构建为排序序列的形式进行训练,得到打分模型,以此模型用来评估SFT模型生成的文本是否符合人类的思维习惯
这里尝试两种方法,这两种方法为direct score和rank score:
Direct score:一个是直接对输出的文本进行打分,通过与自定义的label score计算loss,以此来更新模型参数;
Rank score:二是使用排序的方法,对每个Prompt输出的n个句子进行排序作为输入,通过计算排序在前面的句子与排序在后面的句子的差值累加作为最终loss。
Direct score方法
这个方法就是利用Bert模型对标注数据进行编码,用linear层映射到1维,然后利用Sigmoid函数输出每个句子的得分,与人工标记的得分进行loss计算,以此来更新模型参数

Rank score方法
这种方法与前一种方法的区别在于loss函数的设计
首先需要明白的是为什么在InstructGPT中不采用上面的方法,主要的原因在于给生成句子在打分时,不同标注人员的标准是不一样的,而且这个标准是很难进行统一的,这样会导致标注的数据评判标准不一样
即使每个标注人员的理解是一样的,但对于同一条文本给的分数也不一样的,因此在进行标注时需要把这个定量的问题转为一种更为简单的处理方法,采用排序来方法来进行数据标注可以在一定程度上解决这个问题
两种方法区别

明显的看出标注员在使用直接打分(Direct Score)时,会由于主观意识的不同,对同一个文本出现不同的分值;而使用等级排序(Rank Level)来进行数据标注时,可以统一标注结果
Rank Loss

PPO算法
邻近策略优化(Proximal Policy Optimization,PPO)算法的网络结构有两个。PPO算法解决的问题是 离散动作空间和连续动作空间 的强化学习问题,是 on-policy 的强化学习算法。
论文原文《Proximal Policy Optimization Algorithms》
涉及到强化学习的概念太多,就不在这里展开了
Reference
https://www.sohu.com/a/644391012_121124715
https://blog.csdn.net/Ntech2099/article/details/128263611
https://zhuanlan.zhihu.com/p/461825791
https://zhuanlan.zhihu.com/p/609795142
相关文章:
ChatGPT 一本正经的胡说八道 那也看看原理吧
最近,ChatGPT横空出世。这款被马斯克形容为“强大到危险”的AI,不但能够与人聊天互动,还能写文章、改代码。于是,人们纷纷想让AI替自己做些什么,有人通过两分钟的提问便得到了一篇完美的论文,有人希望它能帮…...

ChatGPT:一个人机环境系统交互的初级产品
从人机环境系统智能的角度看,Chatgpt就是一个还没有开始上道的系统。“一阴一阳之谓道”,Chatgpt的“阴”(默会隐性的部分)尚无体现,就是“阳”(显性描述的部分)还停留在人类与大数据交互的浅层…...
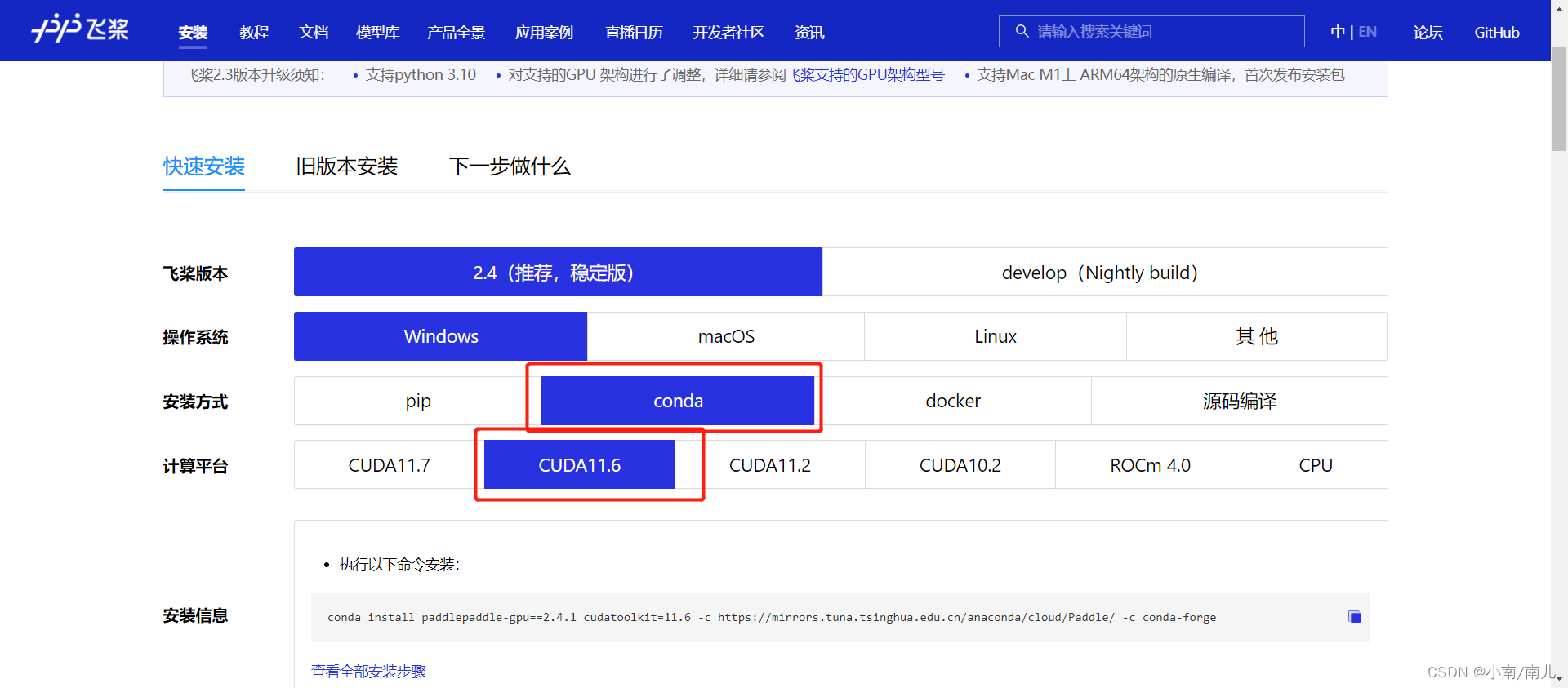
PaddlePaddle本地环境安装(windows11系统)
写在前面: 这里是关于win11安装PaddlePaddle的步骤和方法,建议参考官方的方法。截止2023年3月份,PaddlePaddle的版本是2.4.2。 官方参考:飞桨PaddlePaddle快速安装使用方法 建议使用Anaconda安装 ,关于Anaconda创建环境的可以借鉴:深度学习Anaconda环境搭建(比较全面)…...
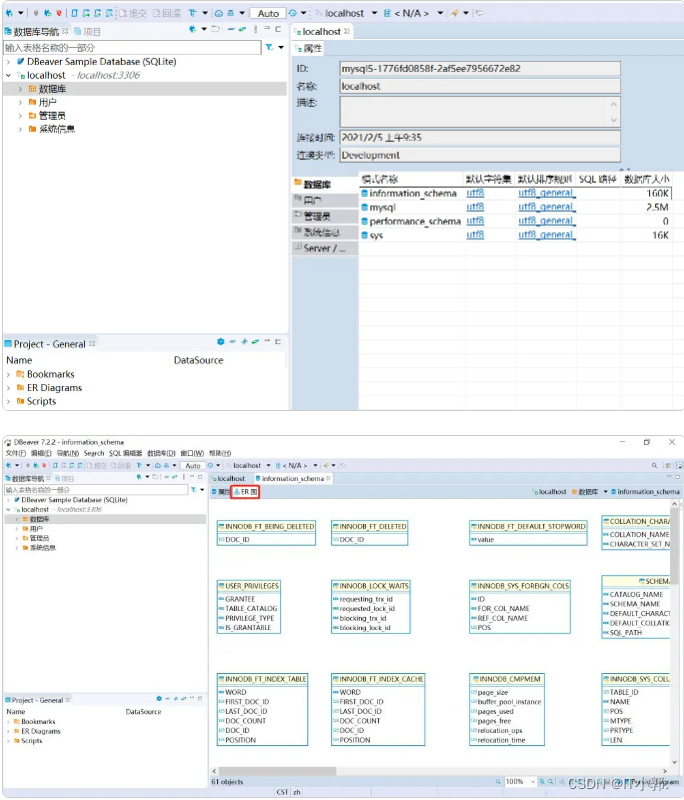
DBeaver 超级详细的安装与使用
一、下载DBeaver DBeaver是一种通用数据库管理工具,适用于需要以专业方式使用数据的每个人;适用于开发人员,数据库管理员,分析师和所有需要使用数据库的人员的免费(DBeaver Community) 的多平台数据库工具。 DBeaver支持80多个数据…...

计算机网络的166个概念 你知道几个第七部分
计算机网络传输层 可靠数据传输:确保数据能够从程序的一端准确无误的传递给应用程序的另一端。 容忍丢失的应用:应用程序在发送数据的过程中可能会存在数据丢失的情况。 非持续连接:每个请求/响应会对经过不同的连接,每一个连接…...

海尔三翼鸟:生态聚拢的密度,决定场景落地速度
最近学到一个新词,叫做涌现能力。 怎么理解呢?我们以当下最火的ChatGPT为例,GPT1模型是1.17亿参数,GPT2有15亿参数,GPT3有1750亿个参数。研究人员在放大模型规模的进程中发现一个惊人的现象,模型参数达到一…...

前端基础知识
文章目录前端基础知识HTML1. html基本结构2.常见的html标签注释标签标题标签(h1~h6)段落标签p换行标签 br格式化标签图片标签:img超链接标签表格标签列表标签表单标签input标签label标签select标签textarea 标签盒子标签div&span3. html特殊字符CSS1. 基本语法2…...

LiveData 面试题库、解答、源码分析
引子LiveData 是能感知生命周期的,可观察的,粘性的,数据持有者。LiveData 用于以“数据驱动”方式更新界面。换一种描述方式:LiveData 缓存了最新的数据并将其传递给正活跃的组件。关于数据驱动的详解可以点击我是怎么把业务代码越…...

kotlin用object实现单例模式,companion object与java静态
kotlin用object实现单例模式,companion object与java静态 kotlin中很容易使用object实现java中的单例模式。由于kotlin中没有static修饰词,可以用companion object实现Java中的static效果。 //object相当于java的单例 object Singleton {var count: In…...

智慧楼宇中的“黑科技”
据不完全统计,无论是居家、办公、学习还是社交,人们有80%的时间都是在室内空间度过的。而随着社会生产力水平与人们消费理念的提升,用户对于楼宇建筑的使用要求也在不断提高,从最基本的舒适为先逐步朝着数字化、智慧化升级。 如果…...

炫云渲染质量功能测试
炫云已经支持优化渲染质量,分别是保守优化、中度优化和深度优化,使用后效果图的渲染时间会有所缩短,尤其对低版本V-Ray和参数设置不当的场景非常有效,能大幅提升渲染速度及节省渲染费用,当然最终效果图有可能有稍许差异…...

SpringBoot入门
文章目录前言一、约定大于配置二、使用步骤1.使用IDEA创建SpringBoot项目2.引入依赖3.测试三、application.properties和application.yml配置文件四、application.yml配置多环境五、测试:总结前言 SpringBoot并不是一门新的技术栈,它的主要目的是为了去…...
)
D. Constant Palindrome Sum(差分数组维护)
Problem - D - Codeforces 题意:给定长度为n的数组,每次操作可以选择一个数令a[i]变成[1,k]范围内的一个数,问最少需要多少次操作可以让a[i]a[n-i1]x (1< i < n/2)满足。 思路:利用差分数组d[i]表示x取i需要的总操作数。 …...
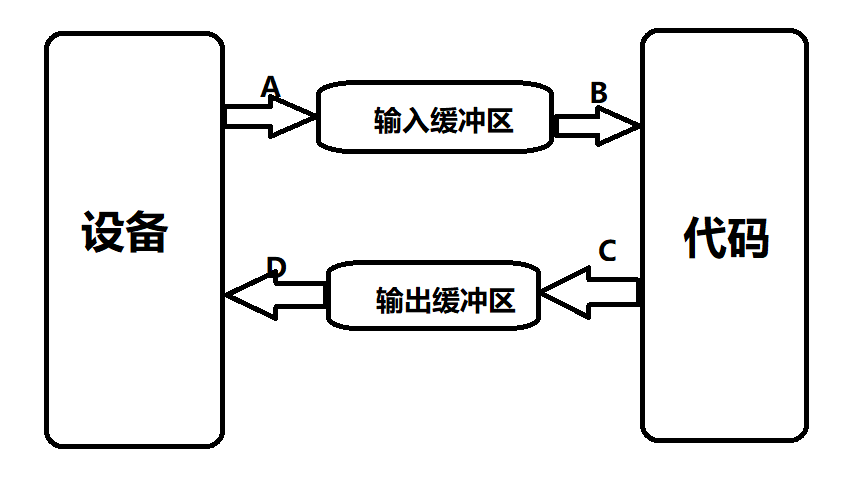
【C++】30h速成C++从入门到精通(IO流)
C语言的输入与输出C语言中我们用到的最频繁的输入输出方式就是scanf ()与printf()。 scanf(): 从标准输入设备(键盘)读取数据,并将值存放在变量中。printf(): 将指定的文字/字符串输出到标准输出设备(屏幕)。注意宽度输出和精度输出控制。C语言借助了相应的缓冲区来…...
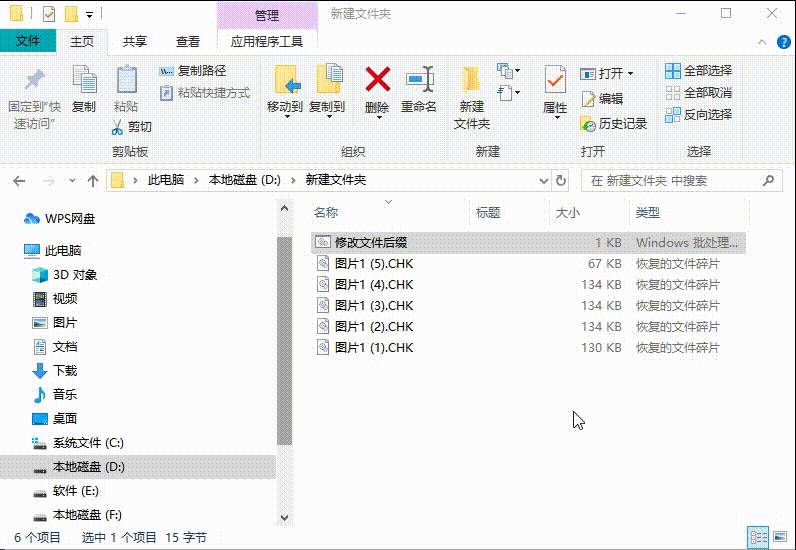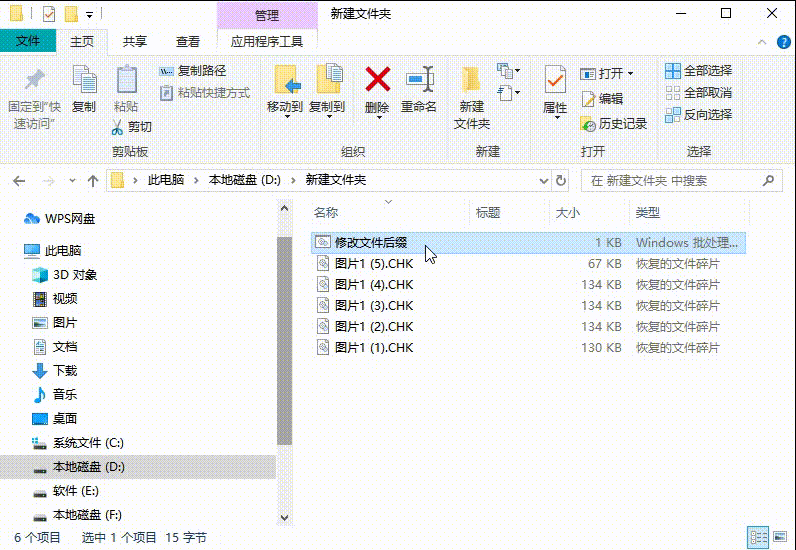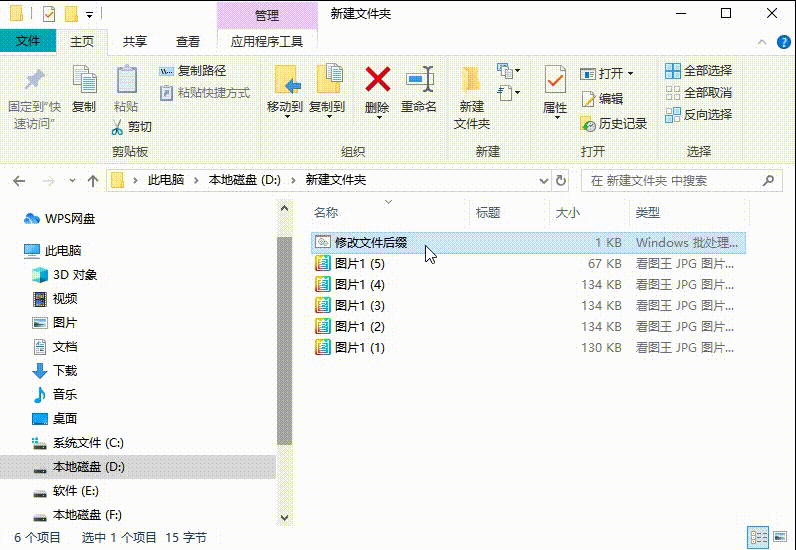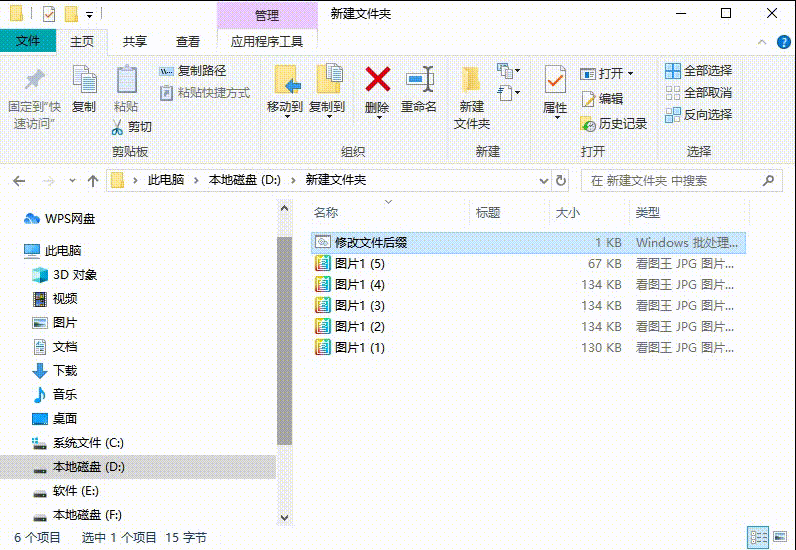
文件变成chk如何恢复正常
许多人不知道chk文件是什么?其实它是用户在使用“磁盘碎片整理程序”整理硬盘后所产生的“丢失簇的恢复文件”,而在u盘、内存卡等移动设备读取数据过程中,由于断电或强制拔出也容易产生大量的chk文件。那么文件变成chk如何恢复正常呢…...

Meta最新模型LLaMA细节与代码详解
Meta最新模型LLaMA细节与代码详解0. 简介1. 项目环境依赖2. 模型细节2.1 RMS Pre-Norm2.2 SwiGLU激活函数2.3 RoPE旋转位置编码3. 代码解读3.1 tokenizer3.2 model3.2.1 模型细节详解3.2.2 transformer构建3.3 generate4. 推理0. 简介 今天介绍的内容是Facebook Meta AI最新提…...

3/6考试总结
时间安排 7:30–7:50 看题,T1,T2 感觉是同类型的题,直接搜索状态然后 dp 一下,T3 估计是个独角晒。 7:50–8:20 T3,有 n^2 的式子,然后可以优化到 n ,写暴力验证一下发现不对。很迷,反复推了几遍都拍不上暴…...

产品经理必读书单
产品经理必读书单,世界变化那么快,不如静下来读读书。在这个浮躁的时代,能够安静下来读书的人太少了。古人云,“读万卷书,不如行万里路,行万里路不如阅人无数”。很多人别说阅人无数了,上学的时…...
UEFI移植LVGL
自己组装过游戏主机的应该都有看到过,进入BIOS设置,酷炫的界面便呈现在眼前,而很多BIOS,使用的还是标准的界面。现在有个趋势,phoenix和insyde也在慢慢朝这种GUI界面发展,而AMI的使用C编写的界面已经非常完…...
3.8 test命令的用法)
RK356x U-Boot研究所(命令篇)3.8 test命令的用法
平台U-Boot 版本Linux SDK 版本RK356x2017.09v1.2.3文章目录 一、test命令的介绍二、test命令的定义三、test命令的用法一、test命令的介绍 test 命令定义在cmd/test.c,需要使能以下配置: obj-$(CONFIG_HUSH_PARSER) += test.o以下介绍摘自cmd/Kconfig: config HUSH_PARS…...

3分钟掌握B站视频下载神器BilibiliDown:跨平台免费开源下载工具
3分钟掌握B站视频下载神器BilibiliDown:跨平台免费开源下载工具 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

Java笔记——Java 初识_java 版本历史
Java笔记——Java 初识_java 版本历史 Java 的发展历程 Sun 公司:Stanford University Network,斯坦福大学网络公司。 Oracle 公司。2004 年发布 Java 5.0,2014 年发布 Java 8,从 Java 9 开始每 6 个月发布一次 Java。 其实&#…...

从MC1496乘法器到DSB调制:一个经典电路的设计实践与参数解析
1. DSB调制基础与MC1496乘法器简介 第一次接触DSB调制电路时,我被那个看似简单的波形变换背后精妙的数学原理深深吸引。DSB(Double Sideband)双边带调制,本质上是用低频信号去控制高频载波的幅度,但与传统AM调制不同&a…...

3步掌握:如何用HTML转Figma工具实现网页设计稿快速转换
3步掌握:如何用HTML转Figma工具实现网页设计稿快速转换 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html 你是否曾羡慕某个网站的布局设计,却苦于无法快速将…...
)
零代码也能做游戏?用UE5蓝图系统10分钟做个会转的潜艇(附完整资产包)
零代码游戏开发:用UE5蓝图10分钟打造动态潜艇 当第一次打开虚幻引擎5时,许多初学者会被其庞大的功能体系所震撼——从影视级的光照系统到数百万面的高精度模型渲染,这款引擎几乎能实现任何你能想象到的视觉效果。但更令人惊喜的是,…...
)
Jetson AGX Orin到手后,第一件事不是装CUDA,而是先搞定这个源(附nvidia-l4t-apt-source.list配置)
Jetson AGX Orin开发板开箱必做:正确配置软件源的深度指南 当你第一次拿到Jetson AGX Orin这款强大的边缘计算设备时,兴奋之余可能会迫不及待地想要安装CUDA、cuDNN等AI开发环境。但很多开发者都会在这里踩到一个"坑"——直接运行sudo apt ins…...

终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController
终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController 【免费下载链接】SDCAlertView The little alert that could 项目地址: https://gitcode.com/gh_mirrors/sd/SDCAlertView SDCAlertView是一款强大的iOS弹窗解决方案,它为…...
 (光通信必学必会))
【信息科学与工程学】信息科学领域工程——第二篇 材料工程10 光学材料 (1) (光通信必学必会)
表1:光学材料知识库 第一部分:光学基础理论与数学模型 编号 算法/策略名称和伪代码/数学方程式 核心数学描述/规律 关键参数/变量 物理/化学/工程意义/控制目标 典型应用场景 优点与局限 关联知识连接点 1.1.1 麦克斯韦方程组 ∇D = ρ_f ∇B = 0 ∇E = -∂B/∂t ∇…...

从控制台账单看使用 Taotoken token plan 带来的实际节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从控制台账单看使用 Taotoken token plan 带来的实际节省 在管理大模型 API 调用成本时,除了关注模型单价,…...

基于OpenClaw构建智能家居环境感知系统:从传感器到自动化规则
1. 项目概述与核心价值如果你正在捣鼓一个智能家居系统,尤其是围绕着OpenClaw这类AI助手来构建,那你可能和我一样,经常遇到一个痛点:家里的设备虽然能联网、能控制,但它们大多“又聋又瞎”。空调能开能关,但…...