Java基础 - 9 - 集合进阶(二)
一. Collection的其他相关知识
1.1 可变参数
可变参数就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型…参数名称;
可变参数的特点和好处
特点:可以不传数据给它;可以传一个或者同时传多个数据给它;也可以传一个数组给它
好处:常常用来灵活的接收数据
//demo
public class demo{public static void main(String[] args){//可变参数特点method(); //不传数据method(10); //传一个数据method(10,20,30); //传多个数据method(new int[]{1,2,3,4,5}); //传一个数组给可变参数}//注意事项1:一个形参列表中,只能有一个可变参数//注意事项2:可变参数必须放在形参列表的最后面public static void method(int...nums){//可变参数在方法内部本质就是一个数组System.out.println(nums.length);System.out.println(Arrays.toString(nums));System.out.println("====================");}
}1.2 Collections
Collections是一个用来操作集合的工具类
Collections提供的常用静态方法
| 方法名称 | 说明 |
| public static <T> boolean addAll(Collection<? super T>c , T…elements) | 给集合批量添加元素 |
| public static void shuffle(List<?> list) | 打乱List集合中的元素顺序 |
| public static <T> void sort(List<?> list) | 对List集合中的元素进行升序排序 |
| public static <T> void sort(List<?> list , Comparator<? super T>c) | 对List集合中元素,按照比较器对象指定的规则进行排序 |

//demo
public class demo{public static void main(String[] args){//<? super T> 接收子类及其父类的类型//public static <T> boolean addAll(Collection<? super T>c , T…elements) 给集合批量添加元素List<String> names = new ArrayList<>();Collections.addAll(names,"张三","李四","王五","二麻子"); //批量添加,不用再一个个add了System.out.println(names); //[张三, 李四, 王五, 二麻子]//public static void shuffle(List<?> list) 打乱List集合中的元素顺序(List是有序、可重复、有索引)Collections.shuffle(names);System.out.println(names); //[二麻子, 王五, 张三, 李四]//public static <T> void sort(List<?> list) 对List集合中的元素进行升序排序List<Integer> nums = new ArrayList<>();Collections.addAll(nums,1,3,7,5,2);System.out.println(nums); //[1, 3, 7, 5, 2]Collections.sort(nums);System.out.println(nums); //[1, 2, 3, 5, 7]List<Car> cars = new ArrayList<>();Car c1 = new Car("奔驰",12.8);Car c2 = new Car("宝马",14.1);Car c3 = new Car("大众",9.9);Car c4 = new Car("未来",14.1);Collections.addAll(cars,c1,c2,c3,c4);System.out.println(cars); //[Car{name='奔驰', price=12.8}, Car{name='宝马', price=14.1}, Car{name='大众', price=9.9}, Car{name='未来', price=14.1}]//编译时异常(标红报错):因为sort不知道自定义对象按照什么规则排序//修改方式:让Car类实现Comparable(比较规则)接口,然后重写compareTo方法来指定比较规则//Collections.sort(cars);//System.out.println(cars); //[Car{name='大众', price=9.9}, Car{name='奔驰', price=12.8}, Car{name='宝马', price=14.1}, Car{name='未来', price=14.1}]//public static <T> void sort(List<?> list , Comparator<? super T>c) 对List集合中元素,按照比较器对象指定的规则进行排序Collections.sort(cars, new Comparator<Car>() {@Overridepublic int compare(Car o1, Car o2) {//return Double.compare(o1.getPrice(),o2.getPrice()); //升序return Double.compare(o2.getPrice(),o1.getPrice()); //降序}});System.out.println(cars);}
}//Car
public class Car implements Comparable<Car> {private String name;private double price;//this代表主调 o是被调@Overridepublic int compareTo(Car o) {//如果认为左边对象大于右边对象返回正整数//如果认为左边对象小于右边对象返回负整数//如果认为左边对象等于右边对象返回0//需求:按照价格升序排序//return (int)(this.price-o.price); //不能这样写,返回值是int类型,两个double类型相减之后强转可能会出bug//写法1
// if(this.price>o.price){
// return 1;
// }else if(this.price<o.price){
// return -1;
// }else{
// return 0;
// }//写法2return Double.compare(this.price,o.price);}//右键->生成->equals()和hashCode()@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Car car = (Car) o;return Double.compare(car.price, price) == 0 &&Objects.equals(name, car.name);}@Overridepublic int hashCode() {return Objects.hash(name, price);}public Car() {}public Car(String name, double price) {this.name = name;this.price = price;}public String getName() {return name;}public void setName(String name) {this.name = name;}public double getPrice() {return price;}public void setPrice(double price) {this.price = price;}@Overridepublic String toString() {return "Car{" +"name='" + name + '\'' +", price=" + price +'}';}
}1.3 综合案例

//demo
public class demo {public static void main(String[] args) {//创建房间Room r = new Room();//启动游戏r.start();}
}//Room
public class Room {//必须有一副牌private List<Card> allCards = new ArrayList<>();public Room(){//做出54张牌,存入到集合allCards中//点数String[] numbers = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};//花色String[] colors = {"♣","♦","♠","♥"};//遍历点数后再遍历花色,组织成牌for (int i = 0; i < numbers.length; i++) { //i不仅仅是numbers数组的索引,因为点数是按升序放在里面,所以正好还可以代表牌的大小for (int j = 0; j < colors.length; j++) {Card card = new Card(numbers[i],colors[j],i); //创建牌对象allCards.add(card); //存到集合中}}//单独存放大小王Card c1 = new Card("","👨",14); //大王Card c2 = new Card("","👩",13); //小王Collections.addAll(allCards,c1,c2); //存到集合中System.out.println("一副新牌:"+allCards);}//启动游戏public void start() {//洗牌Collections.shuffle(allCards);//创建三个玩家的手牌集合List<Card> user1 = new ArrayList<>();List<Card> user2 = new ArrayList<>();List<Card> user3 = new ArrayList<>();//发牌//最后要剩余三张for (int i = 0; i < allCards.size() - 3; i++) {if(i%3==0){user1.add(allCards.get(i));}else if(i%3==1){user2.add(allCards.get(i));}else{user3.add(allCards.get(i));}}//给玩家的牌进行降序排序sortCards(user1);sortCards(user2);sortCards(user3);//玩家手牌情况sortCards(user1);System.out.println("玩家1的手牌:" + user1);System.out.println("玩家2的手牌:" + user2);System.out.println("玩家3的手牌:" + user3);//底牌//System.out.println("底牌:" + allCards.get(51) + allCards.get(52) + allCards.get(53));List<Card> diPai = allCards.subList(allCards.size()-3,allCards.size()); //截取集合的最后三个元素System.out.println("底牌:" + diPai);//抢地主(假设抢地主的规则是:随机生成0 1 2,匹配地主)Random r = new Random();int diZhu = r.nextInt(3); //随机生成0,1,2if(diZhu==0){user1.addAll(diPai);sortCards(user1);System.out.println("玩家1抢地主后的手牌是:" + user1);}else if (diZhu==1){user2.addAll(diPai);sortCards(user2);System.out.println("玩家2抢地主后的手牌是:" + user2);}else{user3.addAll(diPai);sortCards(user3);System.out.println("玩家3抢地主后的手牌是:" + user3);}}private void sortCards(List<Card> user) {Collections.sort(user, new Comparator<Card>() {@Overridepublic int compare(Card o1, Card o2) {//return o1.getSize() - o2.getSize(); //升序排列return o2.getSize() - o1.getSize(); //降序排列}});}
}//Card
public class Card {private String number;private String color;//每张牌存在大小private int size; //0,1,2……public Card() {}public Card(String number, String color, int size) {this.number = number;this.color = color;this.size = size;}public String getNumber() {return number;}public void setNumber(String number) {this.number = number;}public String getColor() {return color;}public void setColor(String color) {this.color = color;}public int getSize() {return size;}public void setSize(int size) {this.size = size;}@Overridepublic String toString() {return color + number;}
}二. Map集合
· Map集合称为双列集合,格式:{key1=value1,key2=value2,key3=value3,…},一次需要存一对数据作为一个元素
· Map集合的每个元素“key=value”称为一个键值对/键值对对象/一个Entry对象,Map集合也被叫做“键值对集合”
· Map集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值
Map集合的应用场景
需要存储一一对应的数据时,就可以考虑使用Map集合来做
Map集合体系

Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值知识一个附属品,值是不做要求的
· HashMap(由键决定特点):无序、不重复、无索引(用的最多)
· LinkedHashMap(由键决定特点):有序、不重复、无索引
· TreeMap(由键决定特点):按照键的大小默认升序排序、不重复、无索引
//demo
public class demo{public static void main(String[] args){Map<String, Integer> map = new HashMap<>(); //多态map.put("哇哈哈",3);map.put("哇哈哈",2); //重复数据(键重复),后加的数据会覆盖前加的map.put("冰红茶",3);map.put("农夫山泉",2);map.put(null,null);System.out.println(map); //{null=null, 农夫山泉=2, 冰红茶=3, 哇哈哈=2} 无序,不重复,无索引Map<String, Integer> map2 = new LinkedHashMap<>(); //多态map2.put("哇哈哈",3);map2.put("哇哈哈",2); //重复数据(键重复),后加的数据会覆盖前加的map2.put("冰红茶",3);map2.put("农夫山泉",2);map2.put(null,null);System.out.println(map2); //{哇哈哈=2, 冰红茶=3, 农夫山泉=2, null=null} 有序,不重复,无索引Map<Integer,String> map3 = new TreeMap<>(); //多态map3.put(1,"哇哈哈");map3.put(2,"哇哈哈"); //重复数据(键重复),后加的数据会覆盖前加的map3.put(3,"冰红茶");map3.put(4,"农夫山泉");System.out.println(map3); //{1=哇哈哈, 2=哇哈哈, 3=冰红茶, 4=农夫山泉} 按照大小默认升序排序、不重复、无索引}
}2.1 Map集合常用方法
Map是双列集合的祖宗,它的功能是全部双列集合都可以继承过来使用的
| 方法名称 | 说明 |
| public V put(K key,V value) | 添加元素 |
| public int size() | 获取集合的大小 |
| public void clear() | 清空集合 |
| public boolean isEmpty() | 判断集合是否为空,为空返回true,反之返回false |
| public V get(Object key) | 根据键获取对应值 |
| public V remove(Object key) | 根据键删除整个元素(删除键会返回键的值) |
| public boolean containsKey(Object key) | 判断是否包含某个键,包含返回true,反之返回false |
| public boolean containsValue(Object value) | 判断是否包含某个值 |
| public Set<K> keySet() | 获取Map集合的全部键 |
| public Collection<V> values() | 获取Map集合的全部值 |
//demo
public class demo{public static void main(String[] args){Map<String, Integer> map = new HashMap<>(); //多态//1.添加元素map.put("哇哈哈",3);map.put("哇哈哈",2); //重复数据(键重复),后加的数据会覆盖前加的map.put("冰红茶",3);map.put("农夫山泉",2);map.put(null,null);System.out.println(map); //{null=null, 农夫山泉=2, 冰红茶=3, 哇哈哈=2} 无序,不重复,无索引//2.public int size() 获取集合的大小System.out.println(map.size()); //4//3.public void clear() 清空集合
// map.clear();
// System.out.println(map); //{}//4.public boolean isEmpty() 判断集合是否为空,为空返回true,反之返回false
// System.out.println(map.isEmpty()); //true//5.public V get(Object key) 根据键获取对应值System.out.println(map.get("哇哈哈")); //2System.out.println(map.get("冰红茶")); //3System.out.println(map.get(null)); //nullSystem.out.println(map.get("怡宝")); //null 根据键获取值的时候,如果键不存在,返回值也是null//6.public V remove(Object key) 根据键删除整个元素(删除键会返回键的值)System.out.println(map.remove(null)); //nullSystem.out.println(map); //{农夫山泉=2, 冰红茶=3, 哇哈哈=2}//7.public boolean containsKey(Object key) 判断是否包含某个键,包含返回true,反之返回falseSystem.out.println(map.containsKey("农夫山泉")); //trueSystem.out.println(map.containsKey("怡宝")); //false//8.public boolean containsValue(Object value) 判断是否包含某个值System.out.println(map.containsValue(2)); //trueSystem.out.println(map.containsValue(5)); //falseSystem.out.println(map.containsValue("2")); //false 要精确类型,整型2包含,字符2不包含//9.public Set<K> keySet() 获取Map集合的全部键 返回是set集合(无序 不重复 无索引)System.out.println(map.keySet()); //[农夫山泉, 冰红茶, 哇哈哈]//10.public Collection<V> values() 获取Map集合的全部值 返回是Collection集合(因为键值对的值是可重复)System.out.println(map.values()); //[2, 3, 2]//11.把其他Map集合的数据倒入到自己集合中来Map<String,Integer> map1 = new HashMap<>();map1.put("绿茶",3);map1.put("元气森林",5);Map<String,Integer> map2 = new HashMap<>();map2.put("脉动",5);map2.put("绿茶",4);System.out.println(map1); //{绿茶=3, 元气森林=5}System.out.println(map2); //{脉动=5, 绿茶=4}map1.putAll(map2); //把map2集合中的元素全部倒入一份到map1集合中去(map2不会改变,相当于把map2的数据复制了一份给map1)System.out.println(map1); //{脉动=5, 绿茶=4, 元气森林=5}System.out.println(map2); //{脉动=5, 绿茶=4}}
}2.2 Map集合遍历方式

2.2.1 键找值
先获取Map集合全部的键,再通过遍历键来找值

2.2.2 键值对
把键值对堪称一个整体进行遍历

2.2.3 Lambda表达式
JDK1.8开始之后的新技术

//demo
public class demo{public static void main(String[] args){Map<String, Double> map = new HashMap<>(); //多态//添加元素map.put("哇哈哈",3.0);map.put("哇哈哈",2.0); //重复数据(键重复),后加的数据会覆盖前加的map.put("冰红茶",3.0);map.put("农夫山泉",2.5);map.put("脉动",5.5);System.out.println(map); //{脉动=5.5, 农夫山泉=2.5, 冰红茶=3.0, 哇哈哈=2.0} 无序,不重复,无索引System.out.println("-----------------------------");//Map集合遍历方式1——键找值//先获取Map集合全部的键Set<String> keys_Set = map.keySet();System.out.println(keys_Set); //[脉动, 农夫山泉, 冰红茶, 哇哈哈]//再通过遍历键来找值,根据键获取其对应的值for (String s : keys_Set) {double value = map.get(s);System.out.println(s+" "+value+"元");}System.out.println("-----------------------------");//Map集合遍历方式2——键值对//把键值对堪称一个整体进行遍历//输入map.entrySet()后直接ctrl+alt+v 生成 Set<Map.Entry<String, Double>> entries = map.entrySet();Set<Map.Entry<String, Double>> entries = map.entrySet();System.out.println(entries); //[脉动=5.5, 农夫山泉=2.5, 冰红茶=3.0, 哇哈哈=2.0]for (Map.Entry<String, Double> entry : entries) {String key = entry.getKey();double value = entry.getValue();System.out.println(key+" "+value+"元");}System.out.println("-----------------------------");//Map集合遍历方式3——Lambda表达式//JDK1.8开始之后的新技术map.forEach(new BiConsumer<String, Double>() {@Overridepublic void accept(String s, Double aDouble) {System.out.println(s+" "+aDouble+"元");}});//简化System.out.println("-----------------------------");map.forEach((s,aDouble) -> System.out.println(s+" "+aDouble+"元")); //map.forEach((k,v) -> System.out.println(k+" "+v+"元"));}
}2.2.4 案例

//demo
public class demo{public static void main(String[] args){List<Character> list = new ArrayList<>(); //用一个list存放学生的投票结果Random r = new Random();for (int i = 0; i < 80; i++) {int choose = r.nextInt(4); //随机生成整数0,1,2,3switch (choose){case 0:list.add('A');break;case 1:list.add('B');break;case 2:list.add('C');break;case 3:list.add('D');break;default:System.out.println("学生的选择不存在~~~");}}System.out.println(list);Map<Character,Integer> map = new HashMap<>(); //创建一个map集合存放投票统计结果for (int i = 0; i < list.size(); i++) {char key = list.get(i); //用key保存当前的字符//判断是否包含某个键(c的值)if(map.containsKey(key)){ //包含(说明这个景点统计过)map.put(key,map.get(key)+1); //get方法返回的是键对应的值}else{ //不包含(说明这个景点没统计过)map.put(key,1);}}System.out.println(map);}
}2.3 HashMap
HashMap集合的特点
HashMap(由键决定特点):无序、不重复、无索引(用的最多)
HashMap集合的底层原理
HashMap跟HashSet的底层原理是一致的,都是基于哈希表实现的(实际上,Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据)
HashMap集合是一种增删改查数据,性能都较好的集合
HashMap的键依赖hashCode方法和equals方法保证键的唯一
如果键存储的是自定义类型的对象,可以通过重写hashCode和equals方法,这样可以保证多个对象内容一样时,HashMap集合就能认为是重复的

哈希表
JDK8之前,哈希表=数组+链表
JDK8开始,哈希表=数组+链表+红黑树
哈希表是一种增删改查数据,性能都较好的数据结构
//demo
public class demo{public static void main(String[] args){Map<Car,String> map = new HashMap<>();map.put(new Car("奔驰",13.14),"made in C");map.put(new Car("奔驰",13.14),"made in H");map.put(new Car("宝马",13.13),"made in C");System.out.println(map);//如果不重写HashCode方法和equals方法,会保存两个Car{name='奔驰', price=13.14}数据//{Car{name='奔驰', price=13.14}=made in H, Car{name='奔驰', price=13.14}=made in C, Car{name='宝马', price=13.13}=made in C}//重写后//{Car{name='宝马', price=13.13}=made in C, Car{name='奔驰', price=13.14}=made in H}}
}//Car
public class Car implements Comparable<Car> {private String name;private double price;//this代表主调 o是被调@Overridepublic int compareTo(Car o) {//如果认为左边对象大于右边对象返回正整数//如果认为左边对象小于右边对象返回负整数//如果认为左边对象等于右边对象返回0//需求:按照价格升序排序//return (int)(this.price-o.price); //不能这样写,返回值是int类型,两个double类型相减之后强转可能会出bug//写法1
// if(this.price>o.price){
// return 1;
// }else if(this.price<o.price){
// return -1;
// }else{
// return 0;
// }//写法2return Double.compare(this.price,o.price);}//右键->生成->equals()和hashCode()@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Car car = (Car) o;return Double.compare(car.price, price) == 0 &&Objects.equals(name, car.name);}@Overridepublic int hashCode() {return Objects.hash(name, price);}public Car() {}public Car(String name, double price) {this.name = name;this.price = price;}public String getName() {return name;}public void setName(String name) {this.name = name;}public double getPrice() {return price;}public void setPrice(double price) {this.price = price;}@Overridepublic String toString() {return "Car{" +"name='" + name + '\'' +", price=" + price +'}';}
}2.4 LinkedHashMap
LinkedHashMap集合的特点
LinkedHashMap(由键决定特点):有序、不重复、无索引
LinkedHashMap集合的底层原理
LinkedHashMap集合也是基于哈希表(数组、链表、红黑树)实现的,但是它的每个元素都额外的多了一个双链表的机制记录它前后元素的位置(保证有序)
实际上,LinkedHashSet集合的底层原理就是LinkedHashMap
2.5 TreeMap
TreeMap集合的特点
TreeMap(由键决定特点):按照键的大小默认升序排序(只能对键排序)、不重复、无索引
TreeMap集合的底层原理
TreeMap和TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序
注意:
· 对于数值类型:Integer,Double,默认按照数值本身的大小进行升序排序
· 对于字符串类型:默认按照首字符的编号升序排序
· 对于自定义类型如Student对象,TreeSet默认是无法直接排序的
TreeMap集合支持两种方式来指定排序规则
方式一
· 让自定义的类实现Comparable接口,重写里面的compareTo方法来指定比较规则
方式二
· 通过调用TreeSet集合有参数构造器,可以设置Comparator对象(比较器对象),用于指定比较规则
public TreeSet(Comparator<? super E> comparator)
//demo
public class demo{public static void main(String[] args){Map<Car,String> map = new TreeMap<>(new Comparator<Car>() {@Overridepublic int compare(Car o1, Car o2) {return Double.compare(o2.getPrice(),o1.getPrice()); //降序}});// Map<Car,String> map = new TreeMap<>((o1, o2) -> Double.compare(o2.getPrice(),o1.getPrice()));map.put(new Car("奔驰",13.14),"made in C");map.put(new Car("奔驰",13.14),"made in H");map.put(new Car("宝马",13.13),"made in C");System.out.println(map);//对于自定义类型,TreeSet默认是无法直接排序的,会产生ClassCastException异常//升序:{Car{name='宝马', price=13.13}=made in C, Car{name='奔驰', price=13.14}=made in H}//降序:{Car{name='奔驰', price=13.14}=made in H, Car{name='宝马', price=13.13}=made in C}}
}//Car
public class Car implements Comparable<Car> {private String name;private double price;//this代表主调 o是被调@Overridepublic int compareTo(Car o) {//如果认为左边对象大于右边对象返回正整数//如果认为左边对象小于右边对象返回负整数//如果认为左边对象等于右边对象返回0//需求:按照价格升序排序return Double.compare(this.price,o.price);}//右键->生成->equals()和hashCode()@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Car car = (Car) o;return Double.compare(car.price, price) == 0 &&Objects.equals(name, car.name);}@Overridepublic int hashCode() {return Objects.hash(name, price);}public Car() {}public Car(String name, double price) {this.name = name;this.price = price;}public String getName() {return name;}public void setName(String name) {this.name = name;}public double getPrice() {return price;}public void setPrice(double price) {this.price = price;}@Overridepublic String toString() {return "Car{" +"name='" + name + '\'' +", price=" + price +'}';}
}2.6 集合的嵌套
集合的嵌套指的是集合中的元素又是一个集合

//demo
public class demo{public static void main(String[] args){Set<String> set1 = new HashSet<>();
// set1.add("南京市");
// set1.add("扬州市");
// set1.add("苏州市");//用Collection批量加入Collections.addAll(set1,"南京市","扬州市","苏州市");Set<String> set2 = new HashSet<>();
// set2.add("武汉市");
// set2.add("宜昌市");
// set2.add("鄂州市");Collections.addAll(set2,"武汉市","宜昌市","鄂州市");Map<String,Set<String>> map = new HashMap<>();map.put("江苏省",set1);map.put("湖北省",set2);System.out.println(map);System.out.println("湖北省:"+map.get("湖北省"));//Lambda表达式 遍历map.forEach((k,v) -> System.out.println(k+":"+v));}
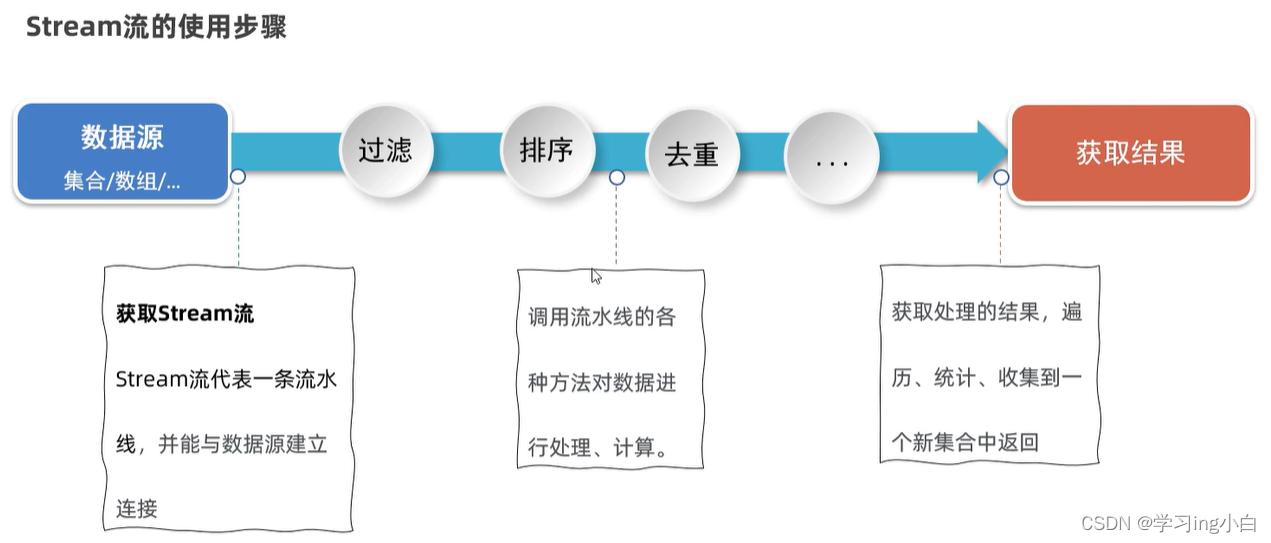
}三. Stream流
Stream也叫Stream流,是JDK8开始新增的一套API(java.util.stream.*),可以用于操作集合或者数组的数据
优势:Stream流大量的结合了Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操作集合或者数组中的数据,代码更简洁,可读性更好

//demo
public class demo{public static void main(String[] args){List<String> names = new ArrayList<>();Collections.addAll(names,"张三","李四","张二二","王五","张老六");System.out.println(names); //[张三, 李四, 张二二, 王五, 张老六]//找出姓张,且是3个字的名字,存入到一个新集合中List<String> name_Zhang = new ArrayList<>();for (String name : names) {if(name.startsWith("张") && name.length()==3){name_Zhang.add(name);}}System.out.println(name_Zhang); //[张二二, 张老六]//用Stream流实现List<String> name_Z = names.stream().filter(s -> s.startsWith("张")).filter(s -> s.length()==3).collect(Collectors.toList());System.out.println(name_Z); //[张二二, 张老六]}
}
3.1 获取Stream流
获取集合的Stream流
| Collection提供的方法 | 说明 |
| default Stream<E> stream() | 获取当前集合对象的Stream流 |
获取数组的Stream流
| Arrays类提供的方法 | 说明 |
| public static <T> Stream<T> stream(T[] array) | 获取当前数组的Stream流 |
| Stream类提供的方法 | 说明 |
| public static <T> Stream<T> of(T… values) | 获取当前接收数据的Stream流 |
//demo
public class demo{public static void main(String[] args){//List集合的Stream流List<String> names1 = new ArrayList<>();Collections.addAll(names1,"张三","李四","张二二","王五","张老六");System.out.println(names1); //[张三, 李四, 张二二, 王五, 张老六]Stream<String> stream1 = names1.stream();stream1.filter(s -> s.length()==2).forEach(s -> System.out.println(s));System.out.println("====================================");//Set集合的Stream流Set<String> names2 = new HashSet<>();Collections.addAll(names2,"周一","周二","周三","周末","小周");System.out.println(names2); //[周一, 小周, 周末, 周三, 周二]Stream<String> stream2 = names2.stream();stream2.filter(s -> s.startsWith("周")).forEach(s -> System.out.println(s));System.out.println("====================================");//Map集合的Stream流Map<String,Double> map = new HashMap<>();map.put("哇哈哈",3.0);map.put("冰红茶",3.0);map.put("农夫山泉",2.5);map.put("脉动",5.5);System.out.println(map); //{脉动=5.5, 农夫山泉=2.5, 冰红茶=3.0, 哇哈哈=3.0}//不能直接map.stream(),因为stream()方法是Collection提供的Set<String> keys = map.keySet();Stream<String> ks = keys.stream();Collection<Double> values = map.values();Stream<Double> vs = values.stream();Set<Map.Entry<String, Double>> entries = map.entrySet();Stream<Map.Entry<String, Double>> kvs = entries.stream();kvs.filter(e -> e.getKey().contains("哈")).forEach(s -> System.out.println(s));System.out.println("====================================");//数组的Stream流String[] names3 = {"Nike","Nim","Mike","Helen"};System.out.println(Arrays.toString(names3));Stream<String> stream3 = Arrays.stream(names3);Stream<String> stream3_1 = Stream.of(names3);stream3.filter(s->s.contains("i")).forEach(s-> System.out.println(s));System.out.println("====================================");stream3_1.filter(s->s.length()==5).forEach(s-> System.out.println(s));}
}3.2 Stream流常见的中间方法
中间方法指的是调用完成后会返回新的Stream流,可以继续使用(支持链式编程)
| Stream提供的常用中间方法 | 说明 |
| Stream<T> filter(Predicate<? super T> predicate) | 用于对流中的数据进行过滤 |
| Stream<T> sorted() | 对元素进行升序排序 |
| Stream<T> sorted(Comparator<? super T> comparator) | 按照指定规则排序 |
| Stream<T> limit(long maxSize) | 获取前几个元素 |
| Stream<T> skip(long n) | 跳过前几个元素 |
| Stream<T> distinct() | 去除流中重复的元素 |
| <R> Stream<R> map(Function<? super T , ? extends R> mapper) | 对元素进行加工,并返回对应的新流 |
| static <T> Stream<T> concat(Stream a , Stream b) | 合并a和b两个流为一个流 |
//demo
public class demo{public static void main(String[] args){List<Double> prices = new ArrayList<>();Collections.addAll(prices,12.13,13.0,15.0,17.0,15.4,11.0);//需求:找出价格超过15的数据,并升序排序,再输出prices.stream().filter(s -> s>=15).sorted().forEach(s -> System.out.println(s));System.out.println("========================================");List<Student> students = new ArrayList<>();Student s1 = new Student("张三","男",79,22);Student s2 = new Student("张三","男",79,22);Student s3 = new Student("李四","男",89.5,21);Student s4 = new Student("王五","男",98,21);Student s5 = new Student("小美","女",57.5,21);Student s6 = new Student("小新","女",100,20);Student s7 = new Student("小海","男",88,19);Collections.addAll(students,s1,s2,s3,s4,s5,s6,s7);//需求:找出成绩在85-95(包括85和95)之间的学生,并按照成绩降序排序students.stream().filter(s -> s.getScore()>=85 && s.getScore()<=95).sorted((o1, o2) -> Double.compare(o2.getScore(),o1.getScore())).forEach(s -> System.out.println(s));System.out.println("========================================");//需求:取出成绩前三的学生,并输出//先按照成绩降序排序再取出前三名students.stream().sorted((o1,o2)->Double.compare(o2.getScore(),o1.getScore())).limit(3).forEach(s -> System.out.println(s));System.out.println("========================================");//需求:取出年纪最小的两个学生,并输出students.stream().sorted((o1,o2) -> o1.getAge()-o2.getAge()).limit(2).forEach(s -> System.out.println(s));System.out.println("========================================");//需求:取出年纪最大的两个学生,并输出students.stream().sorted((o1,o2) -> o1.getAge()-o2.getAge()).skip(students.size()-2).forEach(s -> System.out.println(s));System.out.println("========================================");//需求:找出年纪大于20岁的学生叫什么名字,要求去除重复名字,再输出students.stream().filter(s -> s.getAge() > 20).map(s -> s.getName()) //把这个流加工成只剩下名字.distinct().forEach(s -> System.out.println(s));//distinct去重复,针对自定义类型的对象,如果希望内容一样就认为重复,需要重写HashCode和equals方法,不重写就不会去重复students.stream().filter(s -> s.getAge() > 20).distinct().forEach(s -> System.out.println(s));Stream<String> st1 = Stream.of("张三","李四"); //Stream.of()获取数组的stream流Stream<String> st2 = Stream.of("王五","李四");Stream.concat(st1,st2).forEach(System.out::println);Stream<Integer> st3 = Stream.of(1,2,3);Stream<Double> st4 = Stream.of(5.2,7.7);Stream.concat(st3,st4).forEach(System.out::println);}
}//Student
public class Student {private String name; //姓名private String sex; //性别private double score; //成绩private int age; //年龄public Student() {}public Student(String name, String sex, double score, int age) {this.name = name;this.sex = sex;this.score = score;this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Double.compare(student.score, score) == 0 &&age == student.age &&Objects.equals(name, student.name) &&Objects.equals(sex, student.sex);}@Overridepublic int hashCode() {return Objects.hash(name, sex, score, age);}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getSex() {return sex;}public void setSex(String sex) {this.sex = sex;}public double getScore() {return score;}public void setScore(double score) {this.score = score;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", sex='" + sex + '\'' +", score=" + score +", age=" + age +'}';}
}3.3 Stream流常见的终结方法
终结方法指的是调用完成后,不会返回新Stream了,没有继续使用流了
| Stream提供的常用终结方法 | 说明 |
| void forEach(Consumer action) | 对此流运算后的元素执行遍历 |
| long count() | 统计此流运算后的元素个数 |
| Optional<T> max(Comparator<? super T> comparator) | 获取此流运算后的最大值元素 |
| Optional<T> min(Comparator<? super T> comparator) | 获取此流运算后的最小值元素 |
收集Stream流
收集Stream流就是把Stream流操作后的结果转回到集合或者数组中去返回
Stream流:方便操作集合/数组的手段; 集合/数组:才是开发中的目的
| Stream提供的常用终结方法 | 说明 |
| R collect(Collector collector) | 把流处理后的结果收集到一个指定的集合中去 |
| Object[] toArray() | 把流处理后的结果收集到一个数组中去 |
| Collectors工具类提供的具体的收集方法 | 说明 |
| public static <T> Collector toList() | 把元素收集到List集合中 |
| public static <T> Collector toSet() | 把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper , Function valueMapper) | 把元素收集到Map集合中 |
//demo
public class demo{public static void main(String[] args){List<Student> students = new ArrayList<>();Student s1 = new Student("张三","男",79,22);Student s2 = new Student("张三","男",79,22);Student s3 = new Student("李四","男",89.5,21);Student s4 = new Student("王五","男",98,21);Student s5 = new Student("小美","女",57.5,21);Student s6 = new Student("小新","女",100,20);Student s7 = new Student("小海","男",88,19);Collections.addAll(students,s1,s2,s3,s4,s5,s6,s7);//需求:计算出成绩>=90的学生人数//long count() 统计此流运算后的元素个数long sum = students.stream().filter(s -> s.getScore()>=90).count();System.out.println(sum); //2//需求:找出成绩最高的学生对象并输出//Optional<T> max(Comparator<? super T> comparator) 获取此流运算后的最大值元素Optional<Student> o_max = students.stream().max((o1, o2) -> Double.compare(o1.getScore(),o2.getScore()));System.out.println(o_max); //Optional[Student{name='小新', sex='女', score=100.0, age=20}]System.out.println(o_max.get()); //Student{name='小新', sex='女', score=100.0, age=20}//需求:找出成绩最低的学生对象并输出//Optional<T> min(Comparator<? super T> comparator) 获取此流运算后的最小值元素Optional<Student> o_min = students.stream().min((o1, o2) -> Double.compare(o1.getScore(),o2.getScore()));System.out.println(o_min.get()); //Student{name='小美', sex='女', score=57.5, age=21}//收集Stream流//需求:找出成绩在75-90之间的学生对象,并放到一个新集合中去返回//流只能收集一次//放到List集合中List<Student> list = students.stream().filter(s -> s.getScore()>75 && s.getScore()<90).collect(Collectors.toList());System.out.println(list);//[Student{name='张三', sex='男', score=79.0, age=22}, Student{name='张三', sex='男', score=79.0, age=22}, Student{name='李四', sex='男', score=89.5, age=21}, Student{name='小海', sex='男', score=88.0, age=19}]//放到Set集合中Set<Student> set = students.stream().filter(s -> s.getScore()>75 && s.getScore()<90).collect(Collectors.toSet());System.out.println(set);//[Student{name='李四', sex='男', score=89.5, age=21}, Student{name='张三', sex='男', score=79.0, age=22}, Student{name='小海', sex='男', score=88.0, age=19}]//Set中去把两个张三去重了(因为重写了HashCode和equals方法,不重写则不去重)//需求:找出成绩在75-90之间的学生对象,并把学生对象的名字和成绩,存放到一个Map集合中返回Map<String, Double> map = students.stream().filter(s -> s.getScore() > 75 && s.getScore() < 90).distinct().collect(Collectors.toMap(k -> k.getName(), v -> v.getScore()));System.out.println(map); //{李四=89.5, 张三=79.0, 小海=88.0}Object[] objects = students.stream().filter(s -> s.getScore() > 75 && s.getScore() < 90).toArray();System.out.println(Arrays.toString(objects));Student[] stu = students.stream().filter(s -> s.getScore() > 75 && s.getScore() < 90).toArray(len -> new Student[len]);System.out.println(Arrays.toString(stu));}
}//Student
public class Student {private String name; //姓名private String sex; //性别private double score; //成绩private int age; //年龄public Student() {}public Student(String name, String sex, double score, int age) {this.name = name;this.sex = sex;this.score = score;this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Double.compare(student.score, score) == 0 &&age == student.age &&Objects.equals(name, student.name) &&Objects.equals(sex, student.sex);}@Overridepublic int hashCode() {return Objects.hash(name, sex, score, age);}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getSex() {return sex;}public void setSex(String sex) {this.sex = sex;}public double getScore() {return score;}public void setScore(double score) {this.score = score;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", sex='" + sex + '\'' +", score=" + score +", age=" + age +'}';}
}相关文章:
Java基础 - 9 - 集合进阶(二)
一. Collection的其他相关知识 1.1 可变参数 可变参数就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型…参数名称; 可变参数的特点和好处 特点:可以不传数据给它;可以传一个或者同时传多个数据给…...
javaEE——线程的等待和结束
文章目录 Thread 类及常见方法启动一个线程中断一个线程变量型中断调用 interrupt() 方法来通知观察标志位是否被清除 等待一个线程获取当前线程引用休眠当前线程 线程的状态观察线程的所有状态观察 1: 关注 NEW 、 RUNNABLE 、 TERMINATED 状态的切换 多线程带来的风险为什么会…...

sqlplus设置提示符
作为DBA,需要管理好多数据库,经常会有一台服务器安装多个oracle实例的情况,为避免误操作实例,我们需要在执行sqkplus前,先通过$ echo $ORACLE_SID或 SQL>select name from v$database查看当前实例,这样难…...
macbook删除软件只需几次点击即可彻底完成?macbook删除软件没有叉 苹果笔记本MacBook电脑怎么卸载软件? cleanmymac x怎么卸载
在MacBook的使用过程中,软件安装和卸载是我们经常需要进行的操作。然而,不少用户在尝试删除不再需要的软件时,常常发现这个过程既复杂又耗时。尽管MacOS提供了一些基本的macbook删除软件方法,但很多时候这些方法并不能彻底卸载软件…...

Unity WebGL ios 跳转URL
需求: WebGL跳转网址 现象: Application.OpenURL("https://www.baidu.com"); 这个函数在安卓上可以用,IOS 不管用 解决方案: 编写js插件,unity调用js函数,由js跳转网址 注意事项 : 插件后缀为.jsli…...

机器学习模型—XGBoost
机器学习模型—XGBoost XGBoost(Extreme Gradient Boosting)是由陈天奇等人于2014年提出的一个高效可扩展的梯度提升库。它在梯度提升框架的基础上进行了优化和改进,被广泛应用于机器学习竞赛和实际应用中 作为GBDT(Gradient Boosting Decision Tree)的扩展版本,XGBoost在算…...

在Swift中集成Socket.IO进行实时通信
在Swift中集成Socket.IO进行实时通信 实时通信是许多现代应用程序的重要组成部分,从聊天应用程序到协作平台。Socket.IO 是一个流行的库,用于在 Web 和移动应用程序中实现实时的双向通信。在本文中,我们将讨论如何使用 Socket.IO-Client-Swi…...

vue防止用户连续点击造成多次提交
中心思想:在第一次提交的结果返回前,将提交按钮禁用。 方法一:给提交按钮加上disabled属性,在请求时先把disabled属性改成true,在结果返回时改成false 方法二:添加loading遮罩层,可以直接使用e…...
upload-labs通关方式
pass-1 通过弹窗可推断此关卡的语言大概率为js,因此得出两种解决办法 方法一 浏览器禁用js 关闭后就逃出了js的验证就可以正常php文件 上传成功后打开图片链接根据你写的一句话木马执行它,我这里采用phpinfo() 方法二 在控制台…...
本地用AIGC生成图像与视频
最近AI界最火的话题,当属Sora了。遗憾的是,Sora目前还没开源或提供模型下载,所以没法在本地跑起来。但是,业界有一些开源的图像与视频生成模型。虽然效果上还没那么惊艳,但还是值得我们体验与学习下的。 Stable Diffu…...

java 如何使用Lambda表达式实现递归和循环的替代品
java 如何使用Lambda表达式实现递归和循环的替代品 在Java中,Lambda表达式通常用于实现函数式接口,即只有一个抽象方法的接口。然而,Lambda表达式本身并不直接支持递归或循环。递归和循环是编程中的基本控制结构,通常通过方法调用…...

由浅到深认识C语言(12):位段/位域
该文章Github地址:https://github.com/AntonyCheng/c-notes 在此介绍一下作者开源的SpringBoot项目初始化模板(Github仓库地址:https://github.com/AntonyCheng/spring-boot-init-template & CSDN文章地址:https://blog.csdn…...
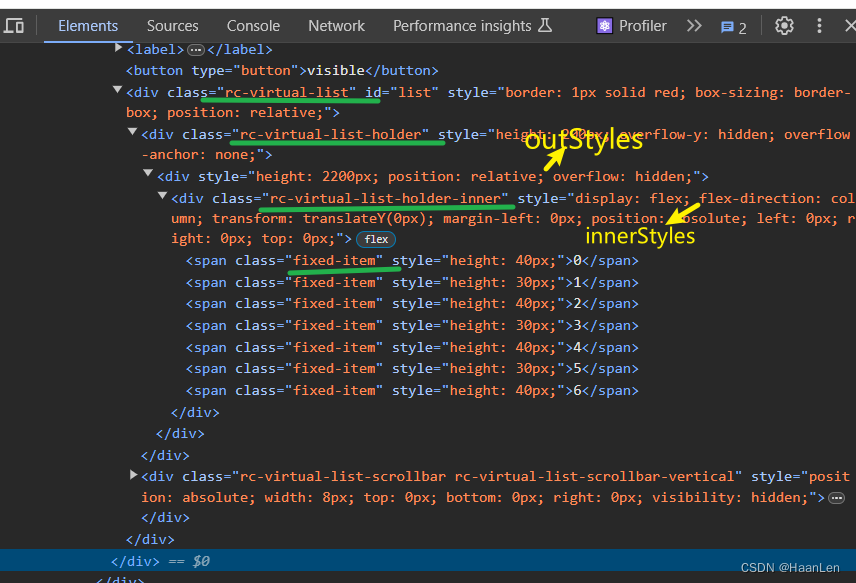
antd5 虚拟列表原理(rc-virtual-list)
github:https://github.com/react-component/virtual-list rc-virtual-list 版本 3.11.4(2024-02-01) 版本:virtual-list-3.11.4 Development npm install npm start open http://localhost:8000/List 组件接收 Props PropDescriptionTypeDefaultchildrenRender …...

机器学习-04-分类算法-03KNN算法
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中分类算法,本篇为分类算法与knn算法部分。 本门课程的目标 完成一个特定行业的算法应用全过程: 懂业务会选择合适的算法数据处理算法训练算法调优算法融合 算法评估持续调优工程化…...

Learn OpenGL 08 颜色+基础光照+材质+光照贴图
我们在现实生活中看到某一物体的颜色并不是这个物体真正拥有的颜色,而是它所反射的(Reflected)颜色。物体的颜色为物体从一个光源反射各个颜色分量的大小。 创建光照场景 首先需要创建一个光源,因为我们以及有一个立方体数据,我们只需要进行…...
springboot多模块下swaggar界面出现异常(Knife4j文档请求异常)或者界面不报错但是没有显示任何信息
继上一篇博文,我们解决了多模块下扫描不到子模块的原因,建议先看上一个博客了解项目结构: springboot 多模块启动报错Field XXX required a bean of type XXX that could not be found. 接下来我们来解决swaggar异常的原因,我们成功启动项目…...

【系统架构设计师】系统工程与信息系统基础 01
系统架构设计师 - 系列文章目录 01 系统工程与信息系统基础 文章目录 系列文章目录 前言 一、系统工程 ★ 二、信息系统生命周期 ★ 信息系统建设原则 三、信息系统开发方法 ★★ 四、信息系统的分类 ★★★ 1.业务处理系统【TPS】 2.管理信息系统【MIS】 3.决策支持系统…...

python自动化之(django)(2)
1、创建应用 python manage.py startapp apitest 这里还是从上节开始也就是命令行在所谓的autotest目录下来输入 然后可以清楚的看到 多了一个文件夹 2、创建视图 在views中加入test函数(所建应用下) from django.http import HttpResponse def tes…...

C语言 内存函数
目录 前言 一、memcpy()函数 二、memmove()函数 三、memset函数 四、memcmp()函数 总结 前言 在C语言中内存是我们用来存储数据的地址,今天我们来讲一下C语言中常用的内存函数。 一、memcpy()函数 memcpy()函数与我们之前讲的strcpy()函数类似,只…...

145 Linux 网络编程1 ,协议,C/S B/S ,OSI 7层模型,TCP/IP 4层模型,
一 协议的概念 从应用的角度出发,协议可理解为“规则”,是数据传输和数据的解释的规则。 典型协议 传输层 常见协议有TCP/UDP协议。 应用层 常见的协议有HTTP协议,FTP协议。 网络层 常见协议有IP协议、ICMP协议、IGMP协议。 网络接口层 常…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

13456
12356...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

简单学习 --> SSE
我们使用AI时,AI对我们说的话不会一次性把全部内容弹出来,而是会像流水一样,一点点吐出来,那么这种丝滑的交互体验,背后的核心就是 SSE (Server-Sent Events)。 什么是 SSE? SSE(Server-Sent …...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...