Text-to-SQL 工具Vanna + MySQL本地部署 | 数据库对话机器人
今天我们来重点研究与实测一个开源的
Text2SQL优化框架 – Vanna

1. Vanna 简介【Text-to-SQL 工具】
Vanna 是一个基于 MIT 许可的开源 Python RAG(检索增强生成)框架,用于 SQL 生成和相关功能。它允许用户在数据上训练一个 RAG “模型”,然后提问问题,这将生成在数据库上运行的 SQL 查询语句,并将查询结果通过表格和图表的方式展示给用户。
简单的说,Vanna是一个开源的、基于Python的、用于SQL自动生成与相关功能的RAG(检索增强生成)框架。
基本特点:
- 官网:https://vanna.ai/
- 开放源代码:https://github.com/vanna-ai/vanna
- 基于Python语言。可通过PyPi包vanna在自己项目中直接使用
- RAG框架。RAG最典型的应用是 私有知识库问答,通过Prompt注入私有知识以提高LLM回答的准确性。但RAG本身是一种Prompt增强方案,完全可以用于其他LLM应用场景。
2. Vanna工作原理
借助LLM实现一个最简单的、基于Text2SQL的数据库对话机器人本身原理是比较简单的:
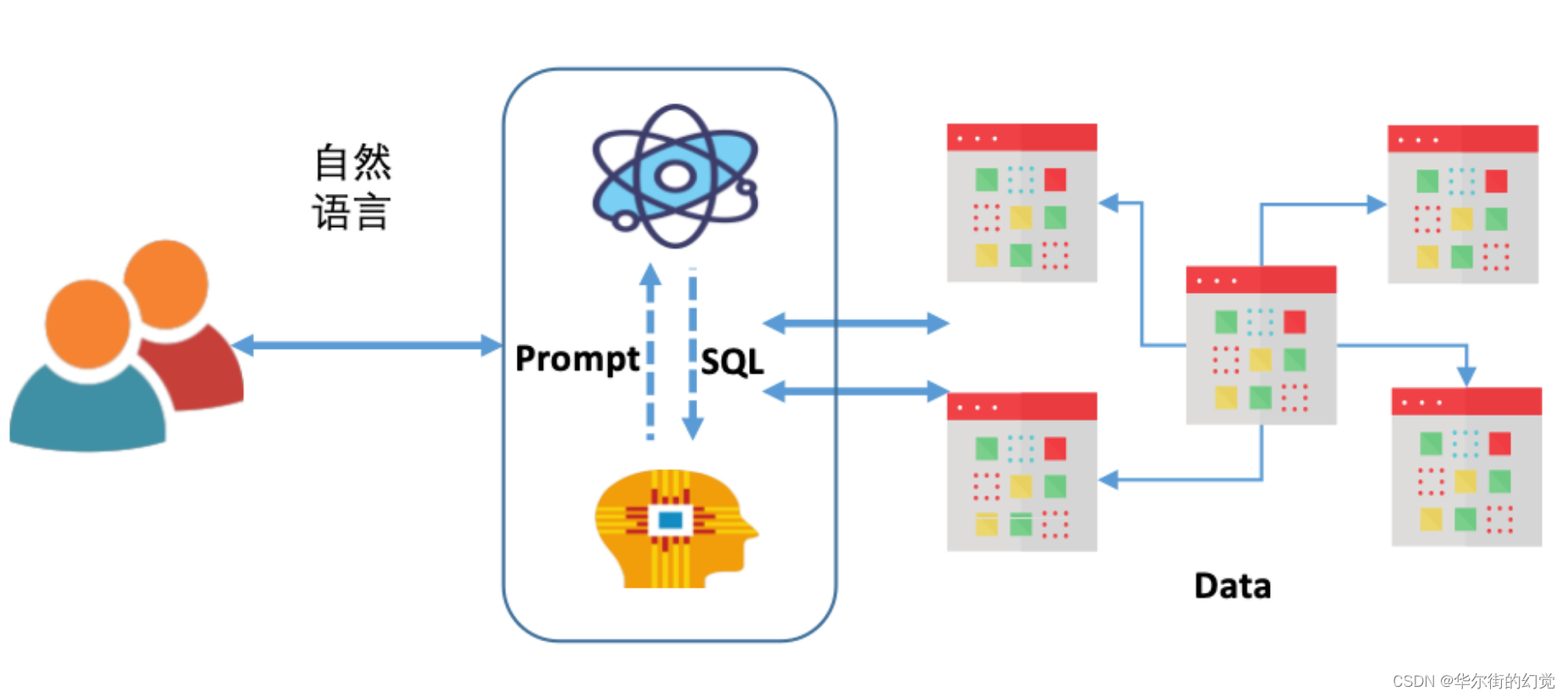
Vanna则是借助了相对简单也更易理解的RAG方法,通过检索增强来构建Prompt,以提高SQL生成的准确率:
从这张图可以了解到,Vanna的关键原理为:
借助数据库的DDL语句、元数据(数据库内关于自身数据的描述信息)、相关文档说明、参考样例SQL等
训练一个RAG的“模型”(embedding+向量库);
并在收到用户自然语言描述的问题时,从RAG模型中通过语义检索出相关的内容,进而组装进入Prompt,然后交给LLM生成SQL。
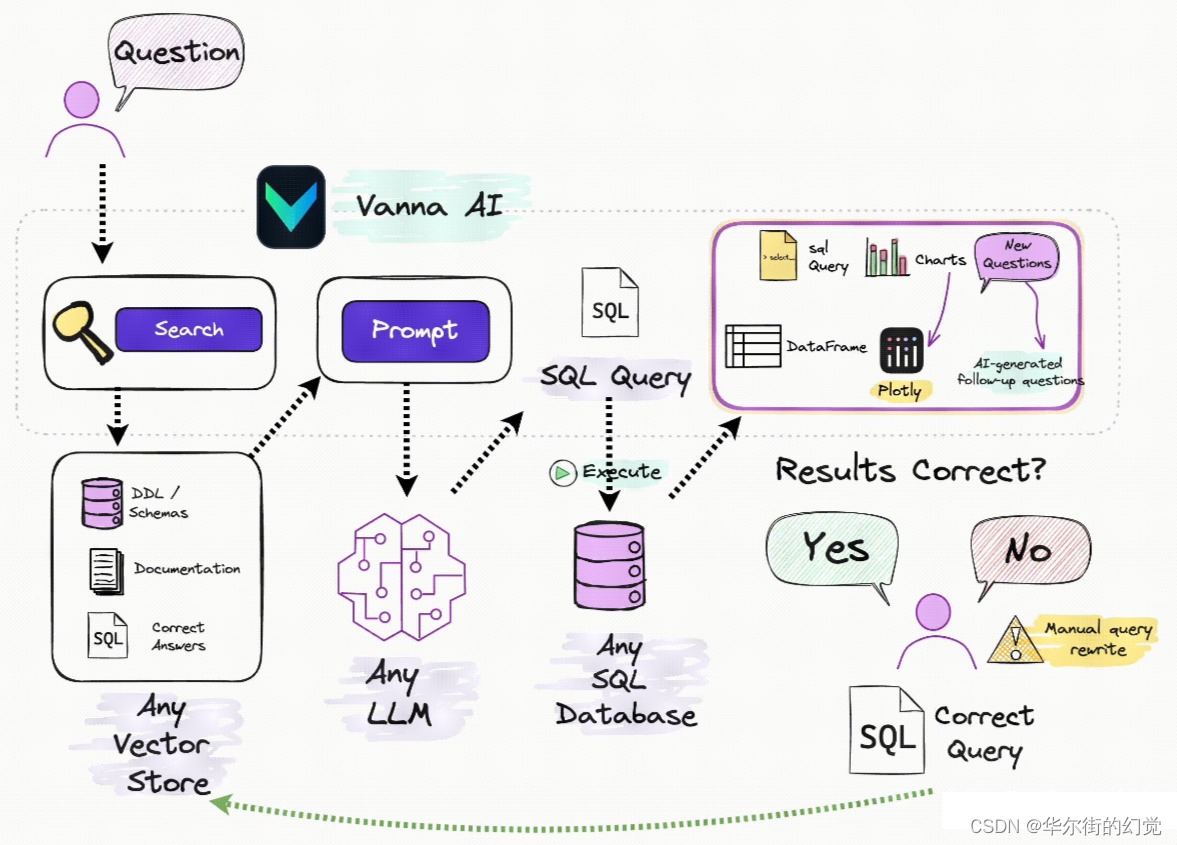
3. 使用步骤
第一步:在你的数据上训练一个RAG“模型”
把DDL/Schemas描述、文档、参考SQL等交给Vanna训练一个用于RAG检索的“模型”(向量库)。

本文尝试了1、3、4的方法,记住这几种方法,下面会用到。
第二步:提出“问题”,获得回答
RAG模型训练完成后,可以用自然语言直接提问。Vanna会利用RAG与LLM生成SQL,并自动运行后返回结果。
4. vanna的扩展与定制化
从上述的vanna原理介绍可以知道,其相关的三个主要基础设施为:
- Database,即需要进行查询的关系型数据库
- VectorDB,即需要存放RAG“模型”的向量库
- LLM,即需要使用的大语言模型,用来执行
Text2SQL任务
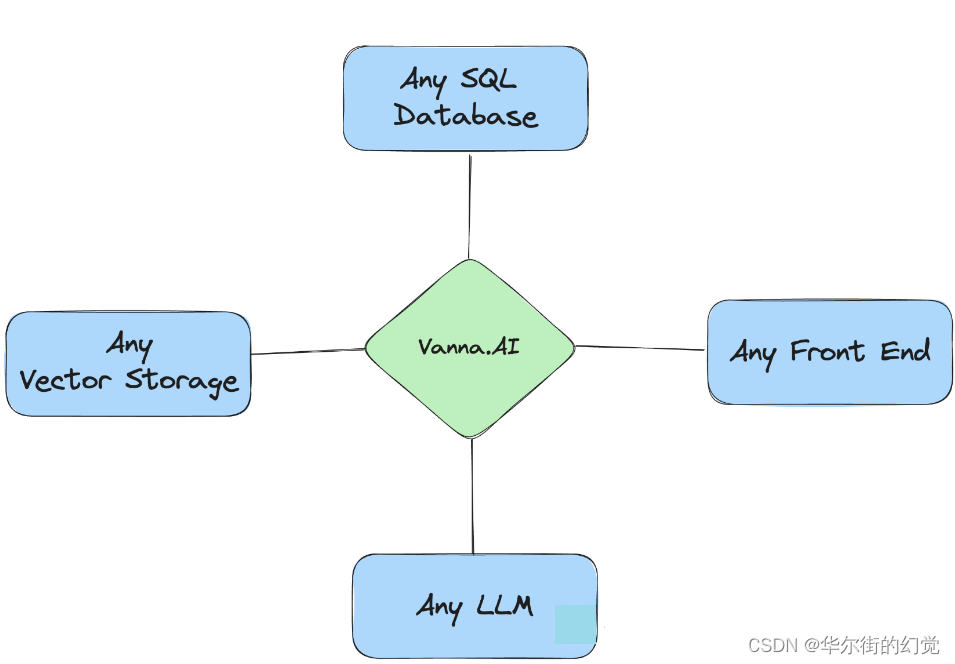
Vanna的设计具备了很好的扩展性与个性化能力,能够支持任意数据库、向量数据库与大模型。
4.1 自定义LLM与向量库
默认情况下,Vanna支持使用其在线LLM服务(对接OpenAI)与向量库,可以无需对这两个进行任何设置,即可使用。因此使用Vanna最简单的原型只需要五行代码:
import vanna
from vanna.remote import VannaDefault
vn = VannaDefault(model='model_name', api_key='api_key')
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask("What are the top 10 albums by sales?")
注意:使用Vanna.AI的在线LLM与向量库服务,需要首先到 https://vanna.ai/ 去申请账号,具体请参考下一部分实测。
如果需要使用自己本地的LLM或者向量库,比如使用自己的OpenAI账号与ChromaDB向量库,则可以扩展出自己的Vanna对象,并传入个性化配置即可。
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStoreclass MyVanna(ChromaDB_VectorStore, OpenAI_Chat):def __init__(self, config=None):ChromaDB_VectorStore.__init__(self, config=config)OpenAI_Chat.__init__(self, config=config)vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
这里的OpenAI_Chat和ChromaDB_VectorStore是Vanna已经内置支持的LLM和VectorDB。
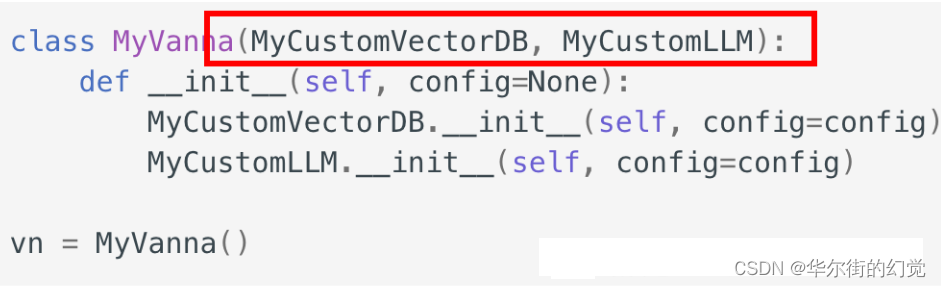
如果你需要支持 没有内置支持的LLM和vectorDB,
则需要首先 扩展出自己的LLM类与VectorDB类,
实现必要的方法(具体可参考官方文档),
然后再 扩展出自己的Vanna对象:
4.2 自定义关系型数据库
Vanna默认支持Postgres,SQL Server,Duck DB,SQLite等关系型数据库,可直接对这一类数据库进行自动访问,实现数据对话机器人。
但如果需要连接自己企业的其他数据库,比如企业内部的Mysql或者Oracle,自需要定义一个个性化的run_sql方法,并返回一个Pandas Dataframe即可。具体可参考下方的实测代码。
5. 实测:数据库对话机器人
这里我们使用Vanna快速构建一个与数据库对话的AI智能体,直观的感受Vanna的工作过程与效果。
【0 - 选择基础环境】
- LLM(大模型)
选择Vanna.AI在线提供的OpenAI服务,真实环境中建议使用自己的LLM。 - VectorDB(向量数据库)
选择Vanna.AI在线提供的VectorDB服务,真实环境中可根据条件灵活选择。 - RDBMS(关系型数据库)
我们选择本地测试环境中的一个MySQL数据库,其中存放了一些测试的社区用户信息数据customer:
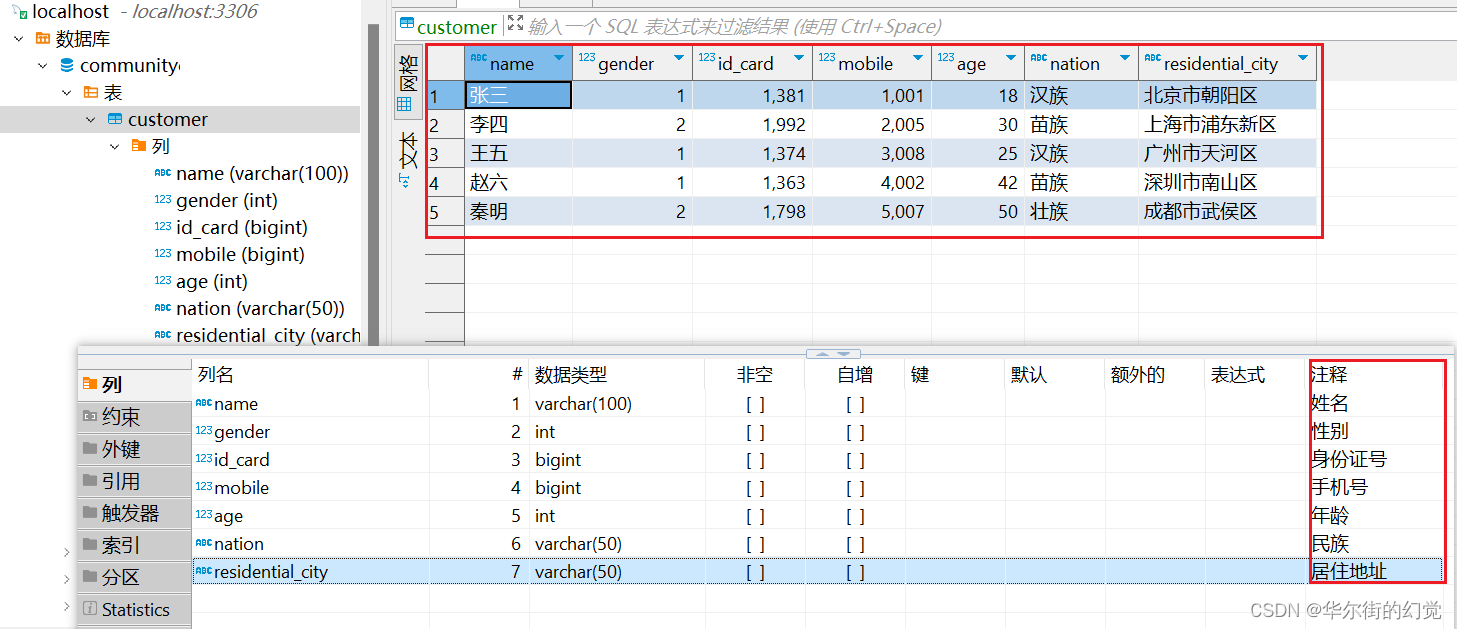
我用DBeaver工具来管理MySQL数据库,创建数据可以用SQL语句CREATE 或 导入csv
导入csv可以参考【数据库】DBeaver链接MariaDB建表,导入csv数据这篇博客
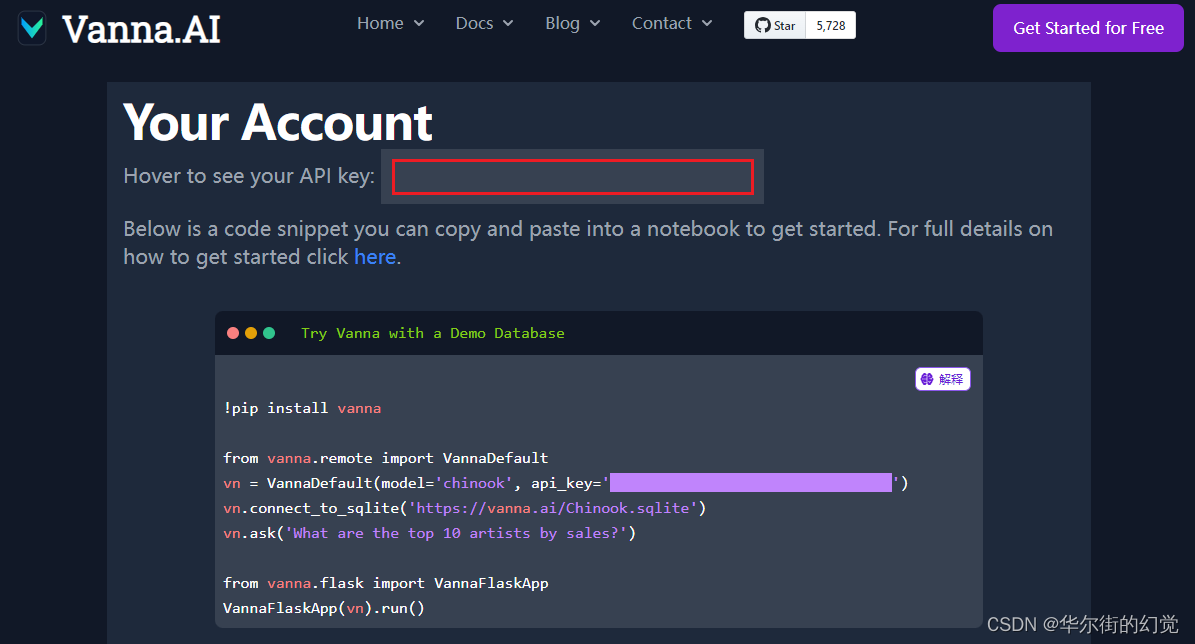
【1 - 申请Vanna账号】
由于我们使用了Vanna.AI的在线LLM与vectorDB服务。因此首先在Vanna.AI申请一个账号,并获得API-key(红框中部分 / 代码中隐藏部分):
设置一个Model name,用于在线的RAG model:
我的设置为:community
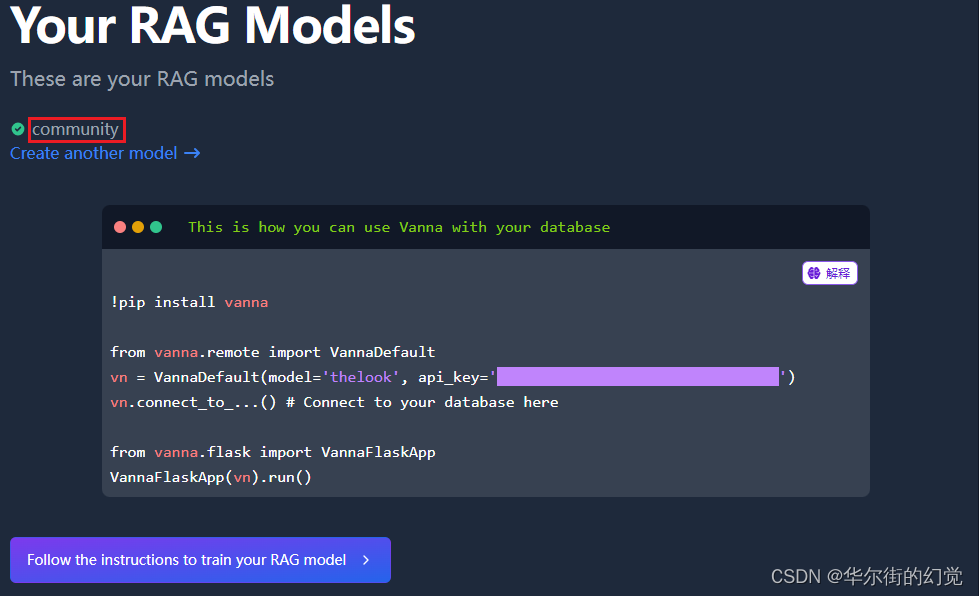
注意:与新数据库对话,需要重新设置一个Model name
【2 - 构建Vanna对象】
pip install vanna
使用pip安装vanna库后,首先使用如下代码创建默认的Vanna对象:
import vanna
from vanna.remote import VannaDefault
api_key = '上面获得的API-key'
vanna_model_name = '上面设置的model-name( 我的是community )'
vn = VannaDefault(model=vanna_model_name, api_key=api_key)
由于我们需要使用自己的本地Mysql数据库,需要定义一个run_sql方法
设置好MySQL数据库的user 、password、host 和 database
(这个database名称是DBeaver工具customer上方的数据库名称Community,RAG model的名称是网页上设置的 community,首字母是小写的,各位别抄错啦!按自己的配置来哈!)
import pandas as pd
import mysql.connectordef run_sql(sql: str) -> pd.DataFrame:cnx = mysql.connector.connect(user='root',password='111000',host='localhost',database='Community')cursor = cnx.cursor()cursor.execute(sql)result = cursor.fetchall()columns = cursor.column_namesdf = pd.DataFrame(result, columns=columns)return df
将自定义的方法设置到上面创建的Vanna对象:
vn.run_sql = run_sql
vn.run_sql_is_set = True
【3 - 训练RAG Model】
这里我们先采用Vanna提供的一种更简单的方式:通过数据库的元数据信息构建训练计划(plan),然后交给Vanna生成RAG model:
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS where table_schema = 'chatdata'")
plan = vn.get_training_plan_generic(df_information_schema)
vn.train(plan=plan)
我构建计划(plan)的方式失败!
故通过 DDL语句 和 SQL问答对 的方式来构建。
表和列名的注释很重要!
表和列名的注释很重要!
表和列名的注释很重要!
有助于vn识别语义,有的列名英文不是那么明确,可能会导致vn生成SQL出错。
比如身份证号的英文可以是id_number,我这里是
id_card
比如性别的英文可以是sex,我这里是gender。
当时我的表还没添加注释,所以多加了CREATE TABLE的操作,如果各位同学在创建表时,已添加了注释,下面这句CREATE TABLE就可以省略了。
需要注意的是,下面的训练代码只需要执行一次即可。
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS customer (name INT PRIMARY KEY COMMENT '姓名', gender INT COMMENT '性别(男性=1/女性=2)', id_card VARCHAR(100) COMMENT '身份证',mobile VARCHAR(100) COMMENT '手机', nation VARCHAR(10) COMMENT '民族', residential_city VARCHAR(100) COMMENT '居住城市',
) COMMENT='customer' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
""")vn.train(question='年龄最大的是哪个?',sql='SELECT name FROM customer ORDER BY age DESC LIMIT 1')
可能直接给个问答对即可。引导vn去customer表中查询。
不行的话这两句vn.train都加上。
【4 - 测试:与数据库对话】
以上的准备工作完成后,就可以与你的关系型数据库对话了:
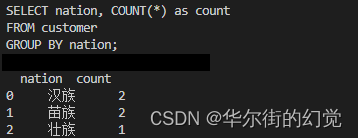
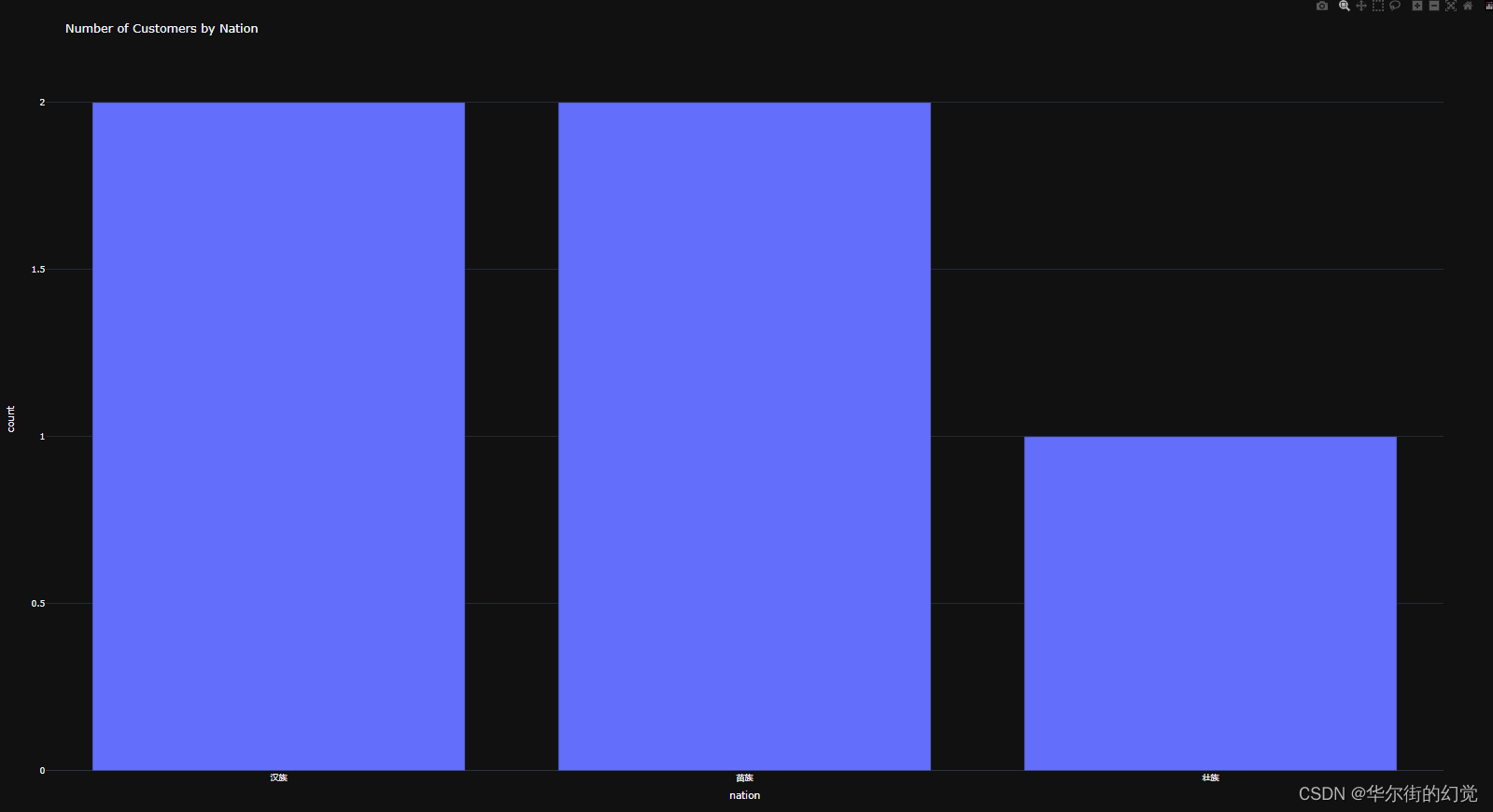
vn.ask('统计不同民族数量?')
控制台可以看到输出的结果,包含了SQL和执行结果:
并且会弹出一个网页,显示执行的结果
【5 - 前端Web APP测试】
Vanna提供了一个内置的基于Flask框架的Web APP,可以直接运行后,通过更直观的界面与你的数据库对话,并且具有图表可视化的效果,还内置了简单的RAG Model数据的管理功能。通过这种方式启动web App:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
通过默认的端口访问http://localhost:8084,即可与你的数据库对话,界面如下:
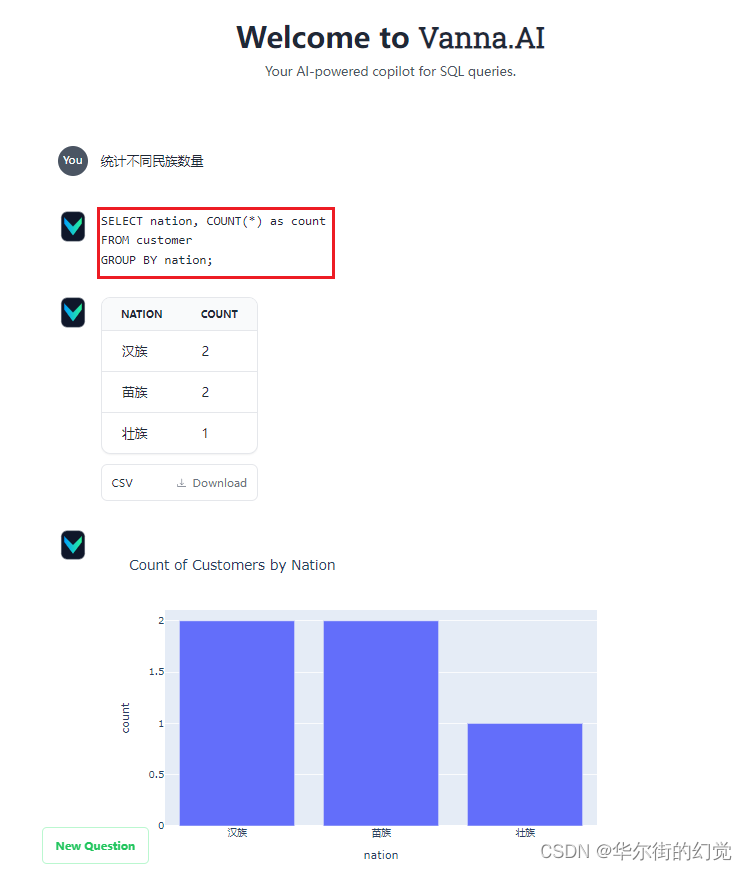
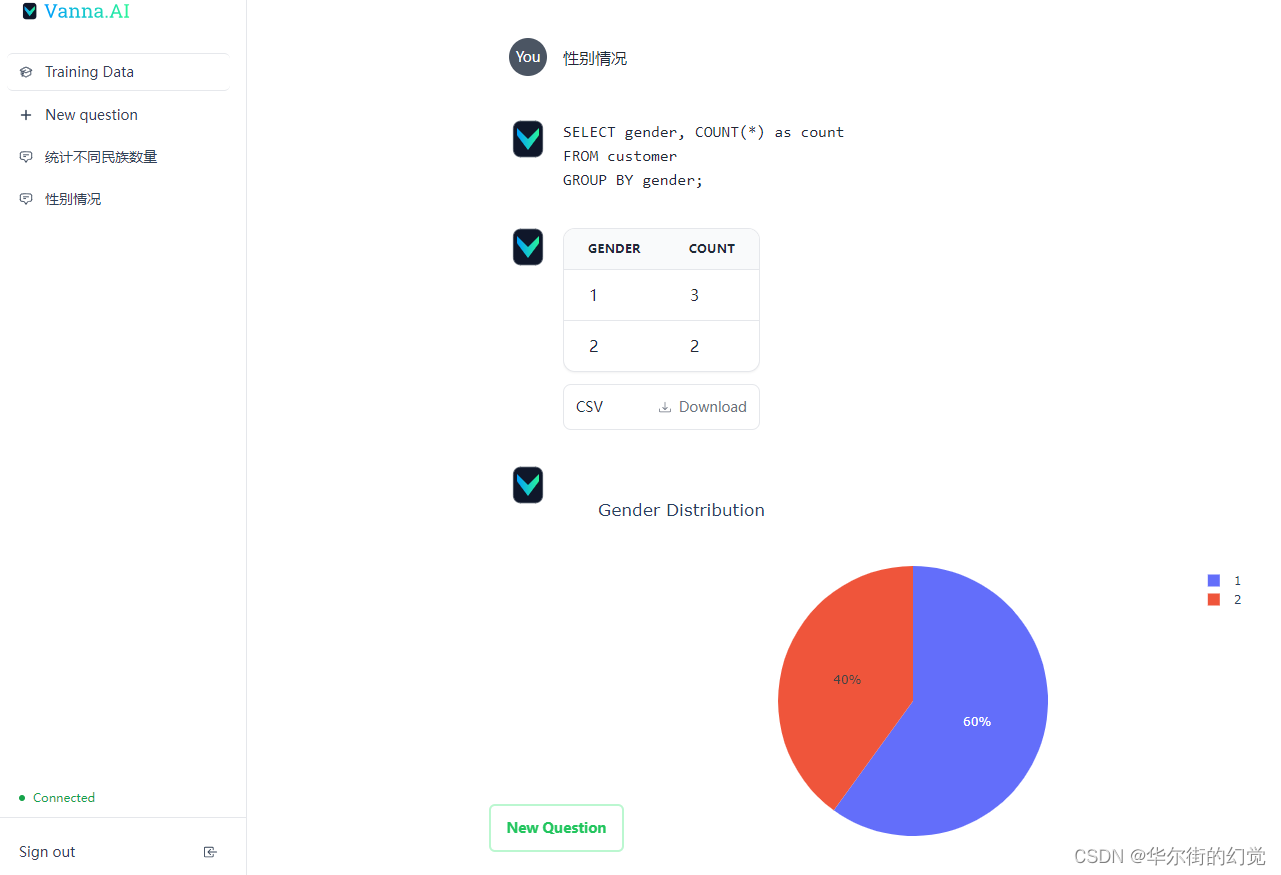
以上,我们深入了解了Vanna这样一个基于Python与RAG的Text2SQL交互式数据分析框架。借助这样的框架,我们无需太多关心Prompt的构建、组装与优化,就可以快速实现一个基于Text2SQL方案的交互式数据库对话机器人,且具备更高的正确率。
此外,Vanna也提供了一些有用的关联功能:
- RAG model数据的查询与管理API
- 基于Plotly的结果可视化API
- 前端Web APP的简单参考实现
在实际测试中,我们也发现Vanna仍然存在一些问题,
- 大部分问题和我们交给Vanna训练RAG model的信息不足
倾向于一次性生成,不便基于上一句SQL进行调优[增、删、改]
根据Vanna.ai官方的未来愿景规划,Vanna旨在成为未来创建AI数据分析师的首选工具。并在准确性(Text2SQL的最大挑战)、交互能力(能够实现交互协作,比如要人类做进一步澄清、解释答案、甚至提出后续问题),与自主性(主动访问必要的系统和数据甚至触发工作流程等)三个方面更加接近人类数据分析师,我们希望Vanna未来能够展示更强大的能力。
6. 训练技巧
利用好 SQL问答对
-
没添加SQL问答对之前
问:居住在重庆市的人有哪些?
答:SQL语句不够准确SELECT name FROM customer WHERE residential_city = '重庆';
-
添加SQL问答对之后
问:居住在重庆市的人有哪些?
答:SQL语句可以模糊匹配,可以得到准确的查询结果SELECT name FROM customer WHERE residential_city LIKE '%重庆%';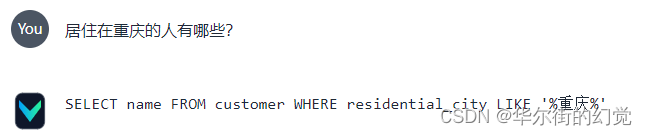
代码自取
import vanna
from vanna.remote import VannaDefault
from vanna.flask import VannaFlaskApp
import pandas as pd
import mysql.connectorapi_key = '7acxxx68c'
vanna_model_name = 'community'
vn = VannaDefault(model=vanna_model_name, api_key=api_key)def run_sql(sql: str) -> pd.DataFrame:cnx = mysql.connector.connect(user='root',password='111000',host='localhost',database='Community')cursor = cnx.cursor()cursor.execute(sql)result = cursor.fetchall()columns = cursor.column_names# print('columns:',columns)df = pd.DataFrame(result, columns=columns)return df# 将函数设置到vn.run_sql中
vn.run_sql = run_sql
vn.run_sql_is_set = True# vn.train(ddl="""
# CREATE TABLE IF NOT EXISTS customer (
# name INT PRIMARY KEY COMMENT '姓名',
# gender INT COMMENT '性别(男性=1/女性=2)',
# id_card VARCHAR(100) COMMENT '身份证',
# mobile VARCHAR(100) COMMENT '手机',
# nation VARCHAR(10) COMMENT '民族',
# residential_city VARCHAR(100) COMMENT '居住城市',
# ) COMMENT='customer' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
# """)vn.train(question='年龄最大的是哪个?',sql='SELECT name FROM customer ORDER BY age DESC LIMIT 1')
vn.train(question='居住在重庆的人有哪些?',sql="SELECT name FROM customer WHERE residential_city LIKE '%重庆%'")first_conversation_sql = vn.ask('居住在重庆的人有哪些?')
print(type(first_conversation_sql))app = VannaFlaskApp(vn)
app.run()【参考链接】
手把手教你本地部署开源 Text-to-SQL 工具:Vanna
Vanna:10分钟快速构建基于大模型与RAG的SQL数据库对话机器人
相关文章:
Text-to-SQL 工具Vanna + MySQL本地部署 | 数据库对话机器人
今天我们来重点研究与实测一个开源的Text2SQL优化框架 – Vanna 1. Vanna 简介【Text-to-SQL 工具】 Vanna 是一个基于 MIT 许可的开源 Python RAG(检索增强生成)框架,用于 SQL 生成和相关功能。它允许用户在数据上训练一个 RAG “模型”&a…...

linux最佳入门(笔记)
1、内核的主要功能 2、常用命令 3、通配符:这个在一些启动文件中很常见 4、输入/输出重定向 意思就是将结果输出到别的地方,例如:ls标准会输出文件,默认是输出到屏幕,但是用>dir后,是将结果输出到dir文…...

加速 PyTorch 模型预测常见方法梳理
目录 1. 使用 GPU 加速 2. 批量推理 3. 使用半精度浮点数 (FP16) 4. 禁用梯度计算 5. 模型简化与量化 6. 使用 TorchScript 7. 模型并行和数据并行 结论 在使用 PyTorch 进行模型预测时,可以通过多种方法来加快推理速度。以下是一些加速模型预测的常用方法&…...

【STM32定时器 TIM小总结】
STM32 TIM详解 TIM介绍定时器类型基本定时器通用定时器高级定时器常用名词时序图预分频时序计数器时序图 定时器中断配置图定时器定时 代码调试 TIM介绍 定时器(Timer)是微控制器中的一个重要模块,用于生成定时和延时信号,以及处…...

RISC-V 编译环境搭建:riscv-gnu-toolchain 和 riscv-tools
RISC-V 编译环境搭建:riscv-gnu-toolchain 和 riscv-tools 编译环境搭建以及说明 操作系统:什么系统都可以 虚拟机:VMmare Workstation Pro 17.50.x (版本不限) 编译环境:Ubuntu 18.04.5 CPU:i7-8750h(虚拟机分配4核…...
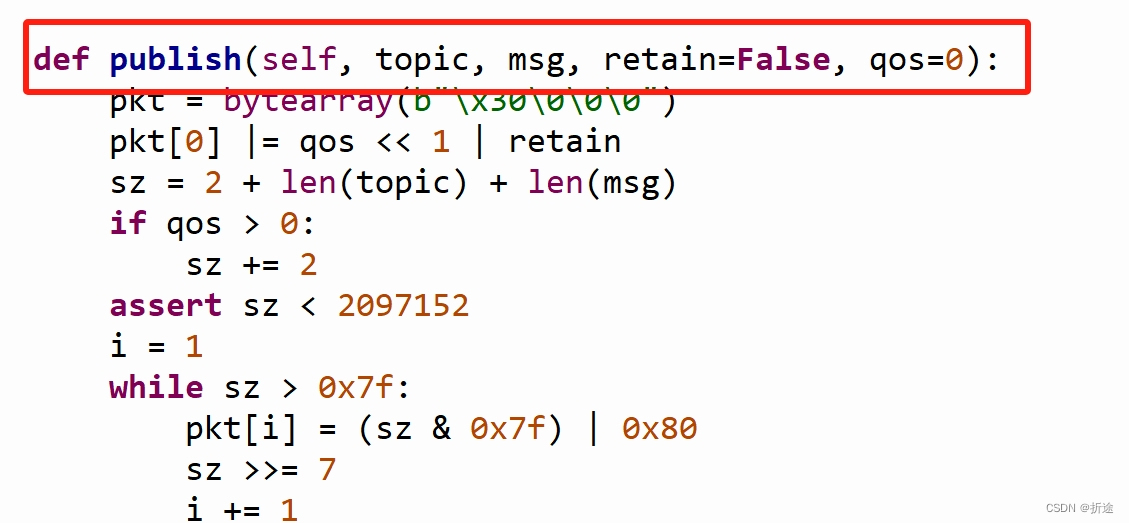
一文速通ESP32(基于MicroPython)——含示例代码
ESP32 简介 ESP32-S3 是一款集成 2.4 GHz Wi-Fi 和 Bluetooth 5 (LE) 的 MCU 芯片,支持远距离模式 (Long Range)。ESP32-S3 搭载 Xtensa 32 位 LX7 双核处理器,主频高达 240 MHz,内置 512 KB SRAM (TCM),具有 45 个可编程 GPIO 管…...

记录一次业务遇到的sql问题
刚开始工作 业务能力比较薄弱 记录一下这几天遇见的一个业务问题 场景 先简单说一下场景,有一批客户(一张表),可以根据这个客户匹配出很多明细数据(另一张表),现在需要删除明细,一个…...

代码分支管理
代码分支管理规范 一、分支管理要求 分支管理 • 将代码提交到适当的分支,遵循分支管理策略。 • 随时可以切换到线上稳定版本代码,确保可以快速回滚到稳定版本。 • 同时进行多个版本的开发工作,确保分支清晰,避免混淆。提交记录的可读性 • 提交描述准确,具有可检索性,…...

uniapp sqlite时在无法读取到已准备好数据的db文件中的数据
问题 {“code”:-1404,“message”:“android.database.sqlite.SQLiteException: no such table: user (Sqlite code 1): , while compiling: select * from user, (OS error - 2:No such file or directory),http://ask.dcloud.net.cn/article/282”} at pages/index/index.vu…...
源码编译部署LAMP
编译部署LAMP 配置apache [rootzyq ~]#: wget https://downloads.apache.org/apr/apr-1.7.4.tar.gz --2023-12-11 14:35:57-- https://downloads.apache.org/apr/apr-1.7.4.tar.gz Resolving downloads.apache.org (downloads.apache.org)... 88.99.95.219, 135.181.214.104…...

Echo框架:高性能的Golang Web框架
Echo框架:高性能的Golang Web框架 在Golang的Web开发领域,选择一个适合的框架是构建高性能和可扩展应用程序的关键。Echo是一个备受推崇的Golang Web框架,以其简洁高效和强大功能而广受欢迎。本文将介绍Echo框架的基本特点、使用方式及其优势…...
)
数据结构--七大排序算法(更新ing)
下面算法编写的均是按照由小到大排序版本 选择排序 思想: 每次遍历待排序元素的最大下标,与待排序元素中最后一个元素交换位置(此时需要设置一个临时变量来存放下标) 时间复杂度--O(n^2) 空间复杂度--O(1) 稳定性--不稳定 代码实…...
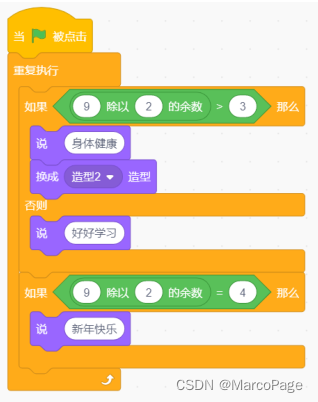
202203青少年软件编程(图形化) 等级考试试卷(二级)
第1题:【 单选题】 红框中加入哪个选项积木, 不能阻止气球下落? ( ) A: B: C: D: 【正确答案】: D 【试题解析】 : 第2题:【 单选题】 下图分别是两个角色的初始位置和“黑色圆形”的程序, 点击绿旗后, 角色显示为下列哪个选项?( ) A: B: C: D: 【正确答…...

【智能硬件、大模型、LLM 智能音箱】Emo:基于树莓派 4B DIY 能笑会动的桌面机器人
简介 Emo 是一款个人伴侣机器人,集时尚与创新于一身。他的诞生离不开最新的树莓派 4 技术和先进的设计。他不仅仅是一款机器人,更是一个活生生的存在。与其他机器人不同,他拥有独特的个性和情感,能够俘获你的心灵。 硬件部分 – 树莓派 4B – 微雪 2 英寸 IPS LCD 显示屏…...
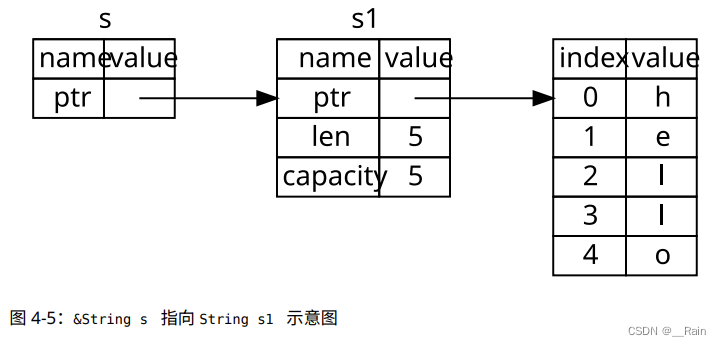
rust学习笔记(1-7)
原文 8万字带你入门Rust 1.包管理工具Cargo 新建项目 1)打开 cmd 输入命令查看 cargo 版本 cargo --version2) 使用 cargo new 项目名 在文件夹,按 shift 鼠标右键 ,打开命令行,运行如下命令,即可创建…...

vscode jupyter 如何关闭声音
网上之前搜的zen模式失败 仅仅降低sound失败 #以下是成功方式: 首先确保user和remote的声音都是0: 然后把user和remote的以下设置都设置为off就行了! 具体操作参考 https://stackoverflow.com/questions/54173462/how-to-turn-off-or-on-so…...
plt保存PDF矢量文件中嵌入可编辑字体(可illustrator编辑)
背景: 用默认 plt.savefig() 保存图片,图中文字是以瞄点保存,而不是以文字格式。在编辑矢量图中,无法调整文字大小和字体。 方法: import matplotlib.pyplot as plt import numpy as np# ------输出的图片为illustr…...
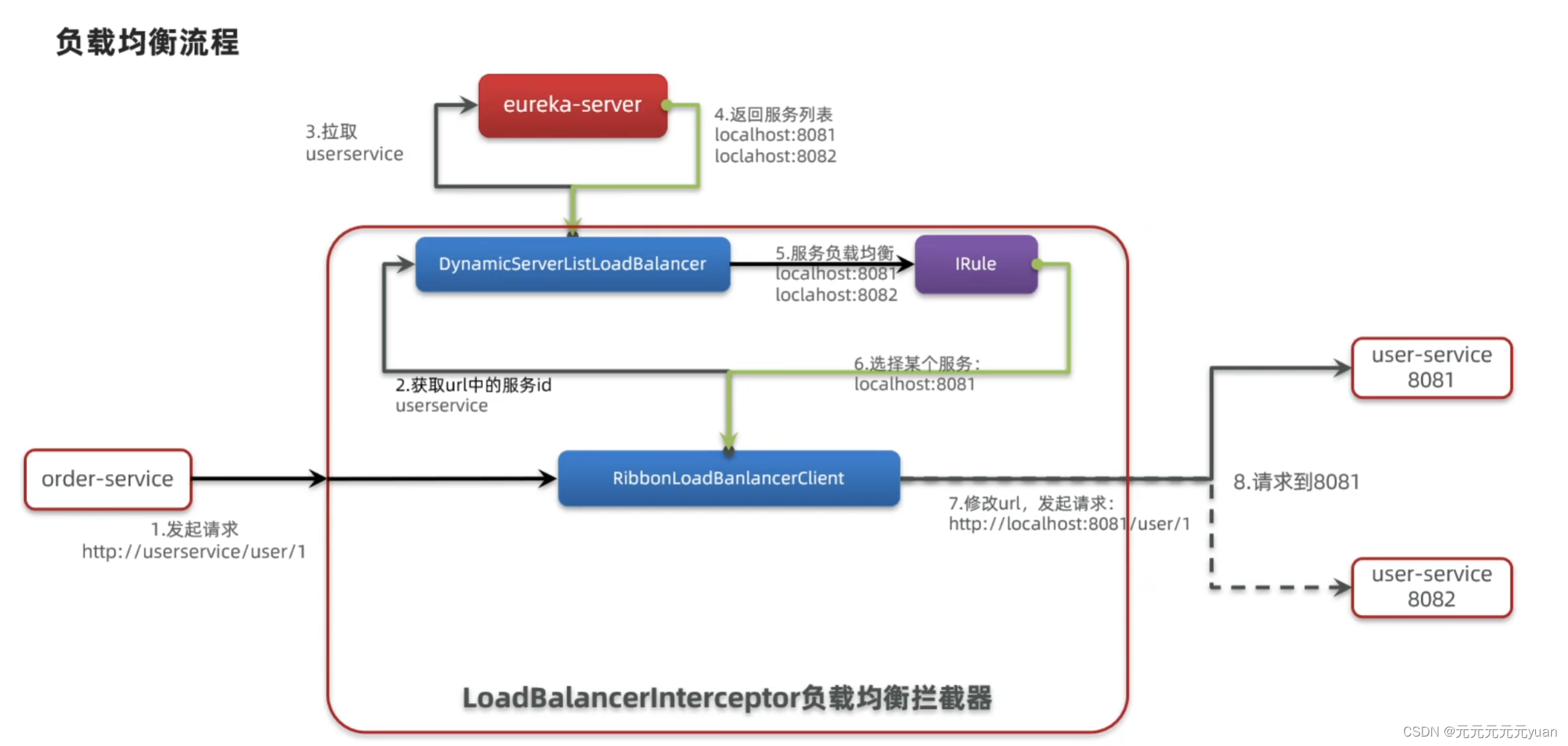
Nacos与Eureka的使用与区别
Nacos与Eureka的使用与区别 单体架构:优点缺点 分布式架构需要考虑的问题:微服务企业需求 认识SpringCloud服务的拆分与远程调用微服务调用方式 Eureka提供者和消费者架构搭建Eureka服务注册服务发现 Ribbon负载均衡饥饿加载总结 Nacos注册中心Nacos安装…...
利用express从0到1搭建后端服务
目录 步骤一:安装开发工具步骤二:安装插件步骤三:安装nodejs步骤四:搭建启动入口文件步骤五:启动服务器总结 在日常工作中,有很多重复和繁琐的事务是可以利用软件进行提效的。但每个行业又有自己的特点&…...

如何在Ubuntu中查看编辑lvgl的demo和examples?
如何在Ubuntu中查看编辑lvgl的demo和examples? 如何在 Ubuntu系统中运行查看lvgl 1、拉取代码 在lvgl的github主页面有50多个仓库,找到lv_port_pc_eclipse这个仓库,点进去 拉取仓库代码和子仓库代码 仓库网址:https://github…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

Unity项目DrawCall降不下来?试试用Mesh Baker合并贴图集,保姆级图文教程
Unity性能优化实战:用Mesh Baker合并贴图集降低DrawCall全流程解析当你的Unity项目帧率开始卡顿,Profiler里DrawCall数字居高不下时,合并贴图集往往是解决问题的关键一步。本文将以一个实际项目为例,带你从零开始使用Mesh Baker的…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...